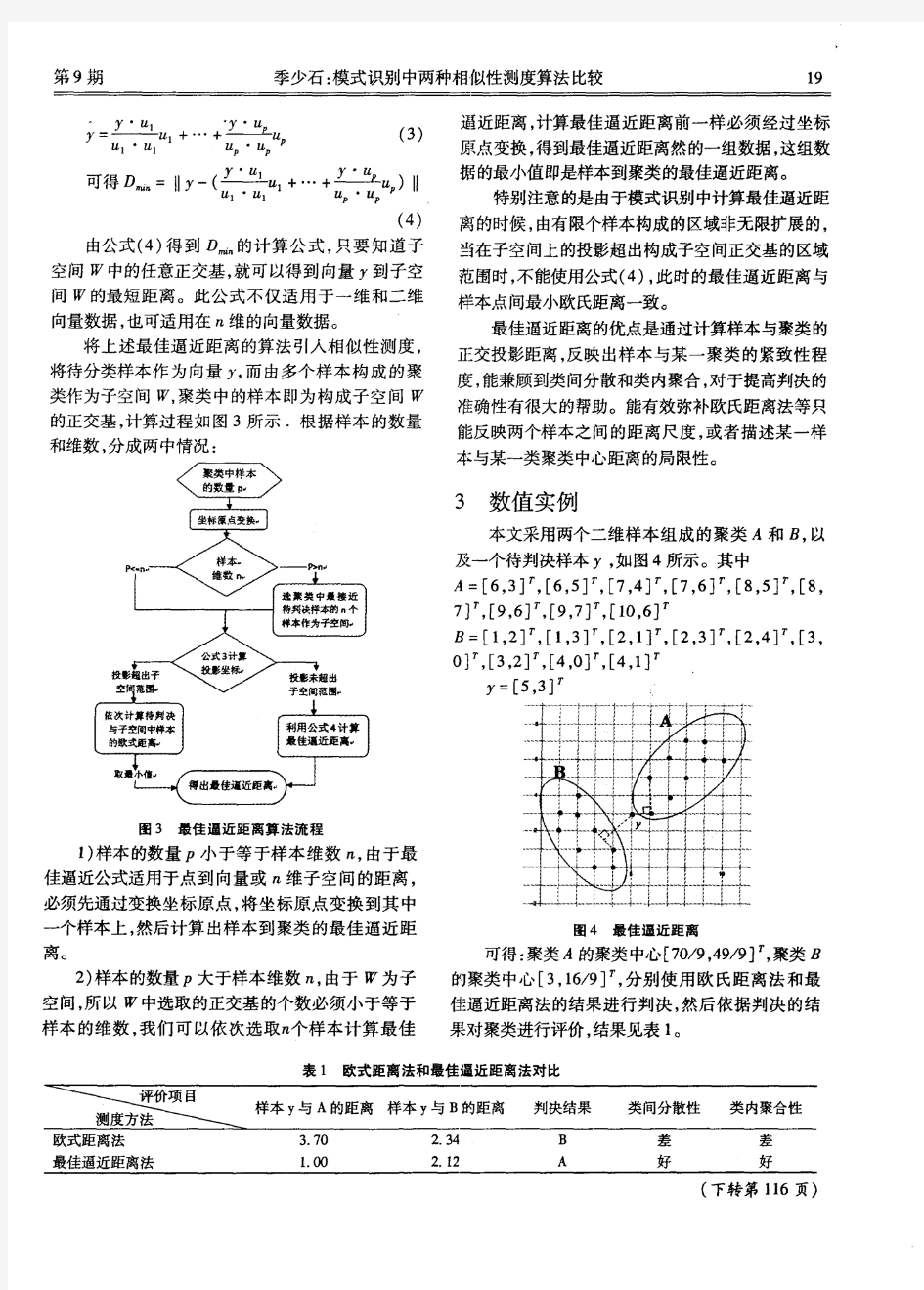
模式识别中两种相似性测度算法比较

模式识别第二章-2.K-均值分类算法
模式识别第二章 2. K-均值分类算法 1. 实验原理和步骤 以初始化聚类中心为1x 和10x 为例。 第一次迭代: 第一步:取K=2,并选T x z )00()1(11==,T x z )67()1(102==。 第二步:因)1()1(2111z x z x -<-,故)1(11S x ∈ 因)1()1(2212z x z x -<-,故)1(12S x ∈ 因)1()1(2313z x z x -<-,故)1(13S x ∈ …… 得到:},,,,,,,{)1(876543211x x x x x x x x S = },,,,,,,,,,,{)1(201918171615141312111092x x x x x x x x x x x x S =。 第三步:计算新的聚类中心: ??? ? ??=+??++==∑∈125.1250.1)(811)2(821)1(111x x x x N z S x ???? ??=+??++==∑∈333.7663.7)(1211)2(20109)1(2 22x x x x N z S x (1N 和2N 分别为属于第一类和第二类的样本的数目)。 第四步:因)2()1(z z ≠,返回第二步。 第二次迭代(步骤同上): 第二次迭代得到的???? ??=125.1250.1)3(1z ,??? ? ??=333.7663.7)3(2z ,)3()2(z z ≠,结束迭代,得到的最终聚类中心为:???? ??=125.1250.11z ,??? ? ??=333.7663.72z 。 2. 实验结果截图 (1)初始化聚类中心为1x 和10x 时:
人工智能与模式识别
人工智能与模式识别 摘要:信息技术的飞速发展使得人工智能的应用范围变得越来越广,而模式识别作为其中的一个重要方面,一直是人工智能研究的重要方向。在介绍人工智能和模式识别的相关知识的同时,对人工智能在模式识别中的应用进行了一定的论述。模式识别是人类的一项基本智能,着20世纪40年代计算机的出现以及50年代人工智能的兴起,模式识别技术有了长足的发展。模式识别与统计学、心理学、语言学、计算机科学、生物学、控制论等都有关系。它与人工智能、图像处理的研究有交叉关系。模式识别的发展潜力巨大。 关键词:模式识别;数字识别;人脸识别中图分类号; Abstract:The rapid development of information technology makes the application of artificial intelligence become more and more widely. Pattern recognition, as one of the important aspects, has always been an important direction of artificial intelligence research. In the introduction of artificial intelligence and pattern recognition related knowledge at the same time, artificial intelligence in pattern recognition applications were discussed.Pattern recognition is a basic human intelligence, the emergence of the 20th century, 40 years of computer and the rise of artificial intelligence in the 1950s, pattern recognition technology has made great progress. Pattern recognition and statistics, psychology, linguistics, computer science, biology, cybernetics and so have a relationship. It has a cross-correlation with artificial intelligence and image processing. The potential of pattern recognition is huge. Key words:pattern recognition; digital recognition; face recognition; 1引言 随着计算机应用范围不断的拓宽,我们对于计算机具有更加有效的感知“能
相似性和相异性的度量
相似性和相异性的度量 相似性和相异性是重要的概念,因为它们被许多数据挖掘技术所使用,如聚类、最近邻分类和异常检测等。在许多情况下,一旦计算出相似性或相异性,就不再需要原始数据了。这种方法可以看作将数据变换到相似性(相异性)空间,然后进行分析。 首先,我们讨论基本要素--相似性和相异性的高层定义,并讨论它们之间的联系。为方便起见,我们使用术语邻近度(proximity)表示相似性或相异性。由于两个对象之间的邻近度是两个对象对应属性之间的邻近度的函数,因此我们首先介绍如何度量仅包含一个简单属性的对象之间的邻近度,然后考虑具有多个属性的对象的邻近度度量。这包括相关和欧几里得距离度量,以及Jaccard和余弦相似性度量。前二者适用于时间序列这样的稠密数据或二维点,后二者适用于像文档这样的稀疏数据。接下来,我们考虑与邻近度度量相关的若干重要问题。本节最后简略讨论如何选择正确的邻近度度量。 1)基础 1. 定义 两个对象之间的相似度(similarity)的非正式定义是这两个对象相似程度的数值度量。因而,两个对象越相似,它们的相似度就越高。通常,相似度是非负的,并常常在0(不相似)和1(完全相似)之间取值。 两个对象之间的相异度(dissimilarity)是这两个对象差异程度的数值度量。对象越类似,它们的相异度就越低。通常,术语距离(distance)用作相异度的同义词,正如我们将介绍的,距离常常用来表示特定类型的相异度。有时,相异度在区间[0, 1]中取值,但是相异度在0和之间取值也很常见。 2. 变换 通常使用变换把相似度转换成相异度或相反,或者把邻近度变换到一个特定区间,如[0, 1]。例如,我们可能有相似度,其值域从1到10,但是我们打算使用的特定算法或软件包只能处理相异度,或只能处理[0, 1]区间的相似度。之所以在这里讨论这些问题,是因为在稍后讨论邻近度时,我们将使用这种变换。此外,这些问题相对独立于特定的邻近度度量。 通常,邻近度度量(特别是相似度)被定义为或变换到区间[0, 1]中的值。这样做的动机是使用一种适当的尺度,由邻近度的值表明两个对象之间的相似(或相异)程度。这种变换通常是比较直截了当的。例如,如果对象之间的相似度在1(一点也不相似)和10(完全相似)之间变化,则我们可以使用如下变换将它变换到[0, 1]区间:s' = (s-1)/9,其中s和s'分别是相似度的原值和新值。一般来说,相似度到[0, 1]区间的变换由如下表达式给出:s'=(s-min_s) / (max_s - min_s),其中max_s和min_s分别是相似度的最大
模式识别(K近邻算法)
K 近邻算法 1.算法思想 取未知样本的x 的k 个近邻,看这k 个近邻中多数属于哪一类,就把x 归于哪一类。具体说就是在N 个已知的样本中,找出x 的k 个近邻。设这N 个样本中,来自1w 类的样本有1N 个,来自2w 的样本有2N 个,...,来自c w 类的样本有c N 个,若c k k k ,,,21 分别是k 个近邻中属于c w w w ,,,21 类的样本数,则我们可以定义判别函数为: c i k x g i i ,,2,1,)( == 决策规则为: 若i i j k x g max )(=,则决策j w x ∈ 2.程序代码 %KNN 算法程序 function error=knn(X,Y ,K) %error 为分类错误率 data=X; [M,N]=size(X); Y0=Y; [m0,n0]=size(Y); t=[1 2 3];%3类向量 ch=randperm(M);%随机排列1—M error=0; for i=1:10 Y1=Y0; b=ch(1+(i-1)*M/10:i*M/10); X1=X(b,:); X(b,:)=[]; Y1(b,:)=[]; c=X; [m,n]=size(X1); %m=15,n=4 [m1,n]=size(c); %m1=135,n=4 for ii=1:m for j=1:m1 ss(j,:)=sum((X1(ii,:)-c(j,:)).^2); end [z1,z2]=sort(ss); %由小到大排序 hh=hist(Y1(z2(1:K)),t); [w,best]=max(hh); yy(i,ii)=t(best); %保存修改的分类结果 end
模式识别期末试题
一、填空与选择填空(本题答案写在此试卷上,30分) 1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择 和模式分类。 2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。 3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。 (1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法 4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。 (1)距离测度(2)模糊测度(3)相似测度(4)匹配测度 5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。 (1)(2) (3) (4) 6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。 (1)二维空间(2)一维空间(3)N-1维空间 7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。 (1)感知器算法(2)H-K算法(3)积累位势函数法 8、下列四元组中满足文法定义的有(1)(2)(4)。 (1)({A, B}, {0, 1}, {A→01, A→ 0A1 , A→ 1A0 , B→BA , B→ 0}, A) (2)({A}, {0, 1}, {A→0, A→ 0A}, A) (3)({S}, {a, b}, {S → 00S, S → 11S, S → 00, S → 11}, S) (4)({A}, {0, 1}, {A→01, A→ 0A1, A→ 1A0}, A) 9、影响层次聚类算法结果的主要因素有(计算模式距离的测度、(聚类准则、类间距离门限、预定的 类别数目))。 10、欧式距离具有( 1、2 );马式距离具有(1、2、3、4 )。 (1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性 11、线性判别函数的正负和数值大小的几何意义是(正(负)表示样本点位于判别界面法向量指向的 正(负)半空间中;绝对值正比于样本点到判别界面的距离。)。 12、感知器算法1。 (1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
相似度测度总结汇总
1 相似度文献总结 相似度有两种基本类别: (1)客观相似度,即对象之间的相似度是对象的多维特征之间的某种函数关系,比如对象之间的欧氏距离;(2)主观相似度,即相似度是人对研究对象的认知关系,换句话说,相似度是主观认知的结果,它取决于人及其所处的环境,主观相似度符合人眼视觉需求,带有一定的模糊性[13]。 1.1 客观相似度 客观相似度可分为距离测度、相似测度、匹配测度。它们都是衡量两对象客观上的相近程度。客观相似度满足下面的公理,假设对象 A 与B 的相似度判别为(,)A B δ,有: (1) 自相似度是一个常量:所有对象的自相似度是一个常数,通常为 1,即 (,)(,)1A A B B δδ== (2) 极大性:所有对象的自相似度均大于它与其他对象间的相似度,即 (,)(,)(,)(,)A B A A A B B B δδδδ≤≤和。 (3) 对称性:两个对象间的相似度是对称的,即(,)(,)A B B A δδ=。 (4) 唯一性:(,)1A B δ=,当且仅当A B =。 1.1.1 距离测度 这类测度以两个矢量矢端的距离为基础,因此距离测度值是两矢量各相应分量之差的函数。设{}{}'' 1212,,,,,,,n n x x x x y y y y == 表示两个矢量,计算二者之间距离测度的具体方式有多种,最常用的有: 1.1.1.1 欧氏距离:Euclidean Distance-based Similarity 最初用于计算欧几里德空间中两个点的距离,假设 x ,y 是 n 维空间的两个点,它们之间的欧几里德距离是: 1/221(,)()n i i i d x y x y x y =??=-=-????∑(1.1)
模式识别感知器算法求判别函数
感知器算法求判别函数 一、 实验目的 掌握判别函数的概念和性质,并熟悉判别函数的分类方法,通过实验更深入的了解判别函数及感知器算法用于多类的情况,为以后更好的学习模式识别打下基础。 二、 实验内容 学习判别函数及感知器算法原理,在MATLAB 平台设计一个基于感知器算法进行训练得到三类分布于二维空间的线性可分模式的样本判别函数的实验,并画出判决面,分析实验结果并做出总结。 三、 实验原理 3.1 判别函数概念 直接用来对模式进行分类的准则函数。若分属于ω1,ω2的两类模式可用一方程d (X ) =0来划分,那么称d (X ) 为判别函数,或称判决函数、决策函数。如,一个二维的两类判别问题,模式分布如图示,这些分属于ω1,ω2两类的模式可用一直线方程 d (X )=0来划分。其中 0)(32211=++=w x w x w d X (1) 21,x x 为坐标变量。 将某一未知模式 X 代入(1)中: 若0)(>X d ,则1ω∈X 类; 若0)(
类学习机模型的称呼,属于有关机器学习的仿生学领域中的问题,由于无法实现非线性分类而下马。但“赏罚概念( reward-punishment concept )” 得到广泛应用,感知器算法就是一种赏罚过程[2]。 两类线性可分的模式类 21,ωω,设X W X d T )(=其中,[]T 1 21,,,,+=n n w w w w ΛW ,[]T 211,,,,n x x x Λ=X 应具有性质 (2) 对样本进行规范化处理,即ω2类样本全部乘以(-1),则有: (3) 感知器算法通过对已知类别的训练样本集的学习,寻找一个满足上式的权向量。 感知器算法步骤: (1)选择N 个分属于ω1和 ω2类的模式样本构成训练样本集{ X1 ,…, XN }构成增广向量形式,并进行规范化处理。任取权向量初始值W(1),开始迭代。迭代次数k=1。 (2)用全部训练样本进行一轮迭代,计算W T (k )X i 的值,并修正权向量。 分两种情况,更新权向量的值: 1. (),若0≤T i k X W 分类器对第i 个模式做了错误分类,权向量校正为: ()()i c k k X W W +=+1 c :正的校正增量。 2. 若(),0T >i k X W 分类正确,权向量不变:()()k k W W =+1,统一写为: ???∈<∈>=21T ,0,0)(ωωX X X W X 若若d
黄庆明 模式识别与机器学习 第三章 作业
·在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。问该模式识别问题所需判别函数的最少数目是多少? 应该是252142 6 *74132 7=+=+ =++C 其中加一是分别3类 和 7类 ·一个三类问题,其判别函数如下: d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-1 (1)设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类别的区域。 (2)设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)= d3(x)。绘出其判别界面和多类情况2的区域。
(3)设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和每类的区域。 ·两类模式,每类包括5个3维不同的模式,且良好分布。如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。) 如果线性可分,则4个 建立二次的多项式判别函数,则102 5 C 个 ·(1)用感知器算法求下列模式分类的解向量w: ω1: {(0 0 0)T , (1 0 0)T , (1 0 1)T , (1 1 0)T } ω2: {(0 0 1)T , (0 1 1)T , (0 1 0)T , (1 1 1)T } 将属于ω2的训练样本乘以(-1),并写成增广向量的形式。 x ①=(0 0 0 1)T , x ②=(1 0 0 1)T , x ③=(1 0 1 1)T , x ④=(1 1 0 1)T x ⑤=(0 0 -1 -1)T , x ⑥=(0 -1 -1 -1)T , x ⑦=(0 -1 0 -1)T , x ⑧=(-1 -1 -1 -1)T 第一轮迭代:取C=1,w(1)=(0 0 0 0) T 因w T (1) x ① =(0 0 0 0)(0 0 0 1) T =0 ≯0,故w(2)=w(1)+ x ① =(0 0 0 1) 因w T (2) x ② =(0 0 0 1)(1 0 0 1) T =1>0,故w(3)=w(2)=(0 0 0 1)T 因w T (3)x ③=(0 0 0 1)(1 0 1 1)T =1>0,故w(4)=w(3) =(0 0 0 1)T 因w T (4)x ④=(0 0 0 1)(1 1 0 1)T =1>0,故w(5)=w(4)=(0 0 0 1)T 因w T (5)x ⑤=(0 0 0 1)(0 0 -1 -1)T =-1≯0,故w(6)=w(5)+ x ⑤=(0 0 -1 0)T 因w T (6)x ⑥=(0 0 -1 0)(0 -1 -1 -1)T =1>0,故w(7)=w(6)=(0 0 -1 0)T 因w T (7)x ⑦=(0 0 -1 0)(0 -1 0 -1)T =0≯0,故w(8)=w(7)+ x ⑦=(0 -1 -1 -1)T 因w T (8)x ⑧=(0 -1 -1 -1)(-1 -1 -1 -1)T =3>0,故w(9)=w(8) =(0 -1 -1 -1)T 因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。 第二轮迭代: 因w T (9)x ①=(0 -1 -1 -1)(0 0 0 1)T =-1≯0,故w(10)=w(9)+ x ① =(0 -1 -1 0)T
2014模式识别练习题
2013模式识别练习题 一. 填空题 1、模式识别系统的基本构成单元包括:模式采集、特征的选择和提取和模式分类。 2、统计模式识别中描述模式的方法一般使用特征矢量;句法模式识别中模式描述方法一般有串、树、 网。 3、影响层次聚类算法结果的主要因素有计算模式距离的测度、聚类准则、类间距离阈值、预定的类别数目。 4、线性判别函数的正负和数值大小的几何意义是正负表示样本点位于判别界面法向量指向的正负半空间中, 绝对值正比于样本点与判别界面的距离。 5、感知器算法1 ,H-K算法 2 。 (1)只适用于线性可分的情况;(2)线性可分、不可分都适用。 6、在统计模式分类问题中,聂曼-皮尔逊判决准则主要用于某一种判别错误较另一种判别错误更为重要的情 况;最小最大判别准则主要用于先验概率未知的情况。 7、 。一般在可 8、散度J ij越大,说明ωi类模式与ωj类模式的分布差别越大; 当ωi类模式与ωj类模式的分布相同时,J ij= 0。 二、选择题 1、影响聚类算法结果的主要因素有(B、C、D )。 A.已知类别的样本质量; B.分类准则; C.特征选取; D.模式相似性测度 2、模式识别中,马式距离较之于欧式距离的优点是(C、D)。 A.平移不变性; B.旋转不变性;C尺度不变性;D.考虑了模式的分布 3、影响基本K-均值算法的主要因素有(ABD)。 A.样本输入顺序; B.模式相似性测度; C.聚类准则; D.初始类中心的选取 4、位势函数法的积累势函数K(x)的作用相当于Bayes判决中的(B D)。 A. 先验概率; B. 后验概率; C. 类概率密度; D. 类概率密度与先验概率的乘积 5、在统计模式分类问题中,当先验概率未知时,可以使用(BD)。 A. 最小损失准则; B. 最小最大损失准则; C. 最小误判概率准则; D. N-P判决 6、散度J D是根据(C )构造的可分性判据。 A. 先验概率; B. 后验概率; C. 类概率密度; D. 信息熵; E. 几何距离 7、似然函数的概型已知且为单峰,则可用(ABCDE)估计该似然函数。 A. 矩估计; B. 最大似然估计; C. Bayes估计; D. Bayes学习; E. Parzen窗法 8、KN近邻元法较之Parzen窗法的优点是(B)。 A. 所需样本数较少; B. 稳定性较好; C. 分辨率较高; D. 连续性较好 9、从分类的角度讲,用DKLT做特征提取主要利用了DKLT的性质:(A C )。 A.变换产生的新分量正交或不相关; B.以部分新的分量表示原矢量均方误差最小; C.使变换后的矢量能量 更集中 10、如果以特征向量的相关系数作为模式相似性测度,则影响聚类算法结果的主要因素有(BC)。 A. 已知类别样本质量; B. 分类准则; C. 特征选取; D. 量纲 11、欧式距离具有(A B );马式距离具有(A B C D )。 A. 平移不变性; B. 旋转不变性; C. 尺度缩放不变性; D. 不受量纲影响的特性 12、聚类分析算法属于(A );判别域代数界面方程法属于(C )。 A.无监督分类; B.有监督分类; C.统计模式识别方法; D.句法模式识别方法 13、若描述模式的特征量为0-1二值特征量,则一般采用(D)进行相似性度量。 A. 距离测度; B. 模糊测度; C. 相似测度; D. 匹配测度 14、下列函数可以作为聚类分析中的准则函数的有(ACD)。
模式识别答案
模式识别试题二答案 问答第1题 答:在模式识别学科中,就“模式”与“模式类”而言,模式类是一类事物的代表,概念或典型,而“模式”则是某一事物的具体体现,如“老头”是模式类,而王先生则是“模式”,是“老头”的具体化。问答第2题 答:Mahalanobis距离的平方定义为: 其中x,u为两个数据,是一个正定对称矩阵(一般为协方差矩阵)。根据定义,距某一点的Mahalanobis距离相等点的轨迹是超椭球,如果是单位矩阵Σ,则Mahalanobis距离就是通常的欧氏距离。问答第3题 答:监督学习方法用来对数据实现分类,分类规则通过训练获得。该训练集由带分类号的数据集组成,因此监督学习方法的训练过程是离线的。 非监督学习方法不需要单独的离线训练过程,也没有带分类号(标号)的训练数据集,一般用来对数据集进行分析,如聚类,确定其分布的主分量等。 就道路图像的分割而言,监督学习方法则先在训练用图像中获取道路象素与非道路象素集,进行分类器设计,然后用所设计的分类器对道路图像进行分割。 使用非监督学习方法,则依据道路路面象素与非道路象素之间的聚类分析进行聚类运算,以实现道路图像的分割。 问答第4题 答:动态聚类是指对当前聚类通过迭代运算改善聚类; 分级聚类则是将样本个体,按相似度标准合并,随着相似度要求的降低实现合并。 问答第5题 答:在给定观察序列条件下分析它由某个状态序列S产生的概率似后验概率,写成P(S|O),而通过O求对状态序列的最大似然估计,与贝叶斯决策的最小错误率决策相当。 问答第6题 答:协方差矩阵为,则 1)对角元素是各分量的方差,非对角元素是各分量之间的协方差。 2)主分量,通过求协方差矩阵的特征值,用得,则,相 应的特征向量为:,对应特征向量为,对应。 这两个特征向量即为主分量。 3) K-L变换的最佳准则为: 对一组数据进行按一组正交基分解,在只取相同数量分量的条件下,以均方误差计算截尾误差最小。 4)在经主分量分解后,协方差矩阵成为对角矩阵,因而各主分量间相关消除。 问答第7题
模式识别与机器学习期末考查试题及参考答案
模式识别与机器学习期末考查 试卷 研究生姓名:入学年份:导师姓名: 试题1:简述模式识别与机器学习研究的共同问题和各自的研究侧重点。 答:(1)模式识别是研究用计算机来实现人类的模式识别能力的一门学科,是指对表征事物或现象的各种形式的信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程。主要集中在两方面,一是研究生物体(包括人)是如何感知客观事物的,二是在给定的任务下,如何用计算机实现识别的理论和方法。机器学习则是一门研究怎样用计算机来模拟或实现人类学习活动的学科,是研究如何使机器通过识别和利用现有知识来获取新知识和新技能。主要体现以下三方面:一是人类学习过程的认知模型;二是通用学习算法;三是构造面向任务的专用学习系统的方法。两者关心的很多共同问题,如:分类、聚类、特征选择、信息融合等,这两个领域的界限越来越模糊。机器学习和模式识别的理论和方法可用来解决很多机器感知和信息处理的问题,其中包括图像/视频分析(文本、语音、印刷、手写)文档分析、信息检索和网络搜索等。 (2)机器学习和模式识别是分别从计算机科学和工程的角度发展起来的,各自的研究侧重点也不同。模式识别的目标就是分类,为了提高分类器的性能,可能会用到机器学习算法。而机器
学习的目标是通过学习提高系统性能,分类只是其最简单的要 求,其研究更侧重于理论,包括泛化效果、收敛性等。模式识别技术相对比较成熟了,而机器学习中一些方法还没有理论基础,只是实验效果比较好。许多算法他们都在研究,但是研究的目标却不同。如在模式识别中研究所关心的就是其对人类效果的提高,偏工程。而在机器学习中则更侧重于其性能上的理论证明。 试题2:列出在模式识别与机器学习中的常用算法及其优缺点。答:(1) K近邻法 算法作为一种非参数的分类算法,它已经广泛应用于分类、回归和模式识别等。在应用算法解决问题的时候,要注意的两个方面是样本权重和特征权重。 优缺点:非常有效,实现简单,分类效果好。样本小时误差难控制,存储所有样本,需要较大存储空间,对于大样本的计算量大。 (2)贝叶斯决策法 贝叶斯决策法是以期望值为标准的分析法,是决策者在处理风险型问题时常常使用的方法。 优缺点:由于在生活当中许多自然现象和生产问题都是难以完全准确预测的,因此决策者在采取相应的决策时总会带有一定的风险。贝叶斯决策法就是将各因素发生某种变动引起结果变动的概率凭统计资料或凭经验主观地假设,然后进一步对期望值进行分析,由于此概率并不能证实其客观性,故往往是主观的和人为的
模式识别关于男女生身高和体重的神经网络算法
模式识别实验报告(二) 学院: 专业: 学号: 姓名:XXXX 教师:
目录 1实验目的 (1) 2实验内容 (1) 3实验平台 (1) 4实验过程与结果分析 (1) 4.1基于BP神经网络的分类器设计 .. 1 4.2基于SVM的分类器设计 (4) 4.3基于决策树的分类器设计 (7) 4.4三种分类器对比 (8) 5.总结 (8)
1)1实验目的 通过实际编程操作,实现对课堂上所学习的BP神经网络、SVM支持向量机和决策树这三种方法的应用,加深理解,同时锻炼自己的动手实践能力。 2)2实验内容 本次实验提供的样本数据有149个,每个数据提取5个特征,即身高、体重、是否喜欢数学、是否喜欢文学及是否喜欢运动,分别将样本数据用于对BP神经网络分类器、SVM支持向量机和决策树训练,用测试数据测试分类器的效果,采用交叉验证的方式实现对于性能指标的评判。具体要求如下: BP神经网络--自行编写代码完成后向传播算法,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算可以基于平台的软件包); SVM支持向量机--采用平台提供的软件包进行分类器的设计以及测试,尝试不同的核函数设计分类器,采用交叉验证的方式实现对于性能指标的评判; 决策树--采用平台提供的软件包进行分类器的设计以及测试,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算基于平台的软件包)。 3)3实验平台 专业研究方向为图像处理,用的较多的编程语言为C++,因此此次程序编写用的平台是VisualStudio及opencv,其中的BP神经网络为自己独立编写,SVM 支持向量机和决策树通过调用Opencv3.0库中相应的库函数并进行相应的配置进行实现。将Excel中的119个数据作为样本数据,其余30个作为分类器性能的测试数据。 4)4实验过程与结果分析 4.1基于BP神经网络的分类器设计 BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。其学习规则是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hidden layer)和输出层(output layer)。 在独自设计的BP神经中,激励函数采用sigmod函数,输入层节点个数为5,
中科院-模式识别考题总结(详细答案)
1.简述模式的概念及其直观特性,模式识别的分类,有哪几种方法。(6’) 答(1):什么是模式?广义地说,存在于时间和空间中可观察的物体,如果我们可以区别它们是否相同或是否相似,都可以称之为模式。 模式所指的不是事物本身,而是从事物获得的信息,因此,模式往往表现为具有时间和空间分布的信息。 模式的直观特性:可观察性;可区分性;相似性。 答(2):模式识别的分类: 假说的两种获得方法(模式识别进行学习的两种方法): ●监督学习、概念驱动或归纳假说; ●非监督学习、数据驱动或演绎假说。 模式分类的主要方法: ●数据聚类:用某种相似性度量的方法将原始数据组织成有意义的和有用的各种数据 集。是一种非监督学习的方法,解决方案是数据驱动的。 ●统计分类:基于概率统计模型得到各类别的特征向量的分布,以取得分类的方法。 特征向量分布的获得是基于一个类别已知的训练样本集。是一种监督分类的方法, 分类器是概念驱动的。 ●结构模式识别:该方法通过考虑识别对象的各部分之间的联系来达到识别分类的目 的。(句法模式识别) ●神经网络:由一系列互相联系的、相同的单元(神经元)组成。相互间的联系可以 在不同的神经元之间传递增强或抑制信号。增强或抑制是通过调整神经元相互间联 系的权重系数来(weight)实现。神经网络可以实现监督和非监督学习条件下的分 类。 2.什么是神经网络?有什么主要特点?选择神经网络模式应该考虑什么因素? (8’) 答(1):所谓人工神经网络就是基于模仿生物大脑的结构和功能而构成的一种信息处 理系统(计算机)。由于我们建立的信息处理系统实际上是模仿生理神经网络,因此称它为人工神经网络。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。 人工神经网络的两种操作过程:训练学习、正常操作(回忆操作)。 答(2):人工神经网络的特点: ●固有的并行结构和并行处理; ●知识的分布存储; ●有较强的容错性; ●有一定的自适应性; 人工神经网络的局限性: ●人工神经网络不适于高精度的计算; ●人工神经网络不适于做类似顺序计数的工作; ●人工神经网络的学习和训练往往是一个艰难的过程; ●人工神经网络必须克服时间域顺序处理方面的困难; ●硬件限制; ●正确的训练数据的收集。 答(3):选取人工神经网络模型,要基于应用的要求和人工神经网络模型的能力间的 匹配,主要考虑因素包括:
图像模式识别的方法介绍
2.1图像模式识别的方法 图像模式识别的方法很多,从图像模式识别提取的特征对象来看,图像识别方法可分为以下几种:基于形状特征的识别技术、基于色彩特征的识别技术以及基于纹理特征的识别技术。其中,基于形状特征的识别方法,其关键是找到图像中对象形状及对此进行描述,形成可视特征矢量,以完成不同图像的分类,常用来表示形状的变量有形状的周长、面积、圆形度、离心率等。基于色彩特征的识别技术主要针对彩色图像,通过色彩直方图具有的简单且随图像的大小、旋转变换不敏感等特点进行分类识别。基于纹理特征的识别方法是通过对图像中非常具有结构规律的特征加以分析或者则是对图像中的色彩强度的分布信息进行统计来完成。 从模式特征选择及判别决策方法的不同可将图像模式识别方法大致归纳为两类:统计模式(决策理论)识别方法和句法(结构)模式识别方法。此外,近些年随着对模式识别技术研究的进一步深入,模糊模式识别方法和神经网络模式识别方法也开始得到广泛的应用。在此将这四种方法进行一下说明。 2.1.1句法模式识别 对于较复杂的模式,如采用统计模式识别的方法,所面临的一个困难就是特征提取的问题,它所要求的特征量十分巨大,要把某一个复杂模式准确分类很困难,从而很自然地就想到这样的一种设计,即努力地把一个复杂模式分化为若干
较简单子模式的组合,而子模式又分为若干基元,通过对基元的识别,进而识别子模式,最终识别该复杂模式。正如英文句子由一些短语,短语又由单词,单词又由字母构成一样。用一组模式基元和它们的组成来描述模式的结构的语言,称为模式描述语言。支配基元组成模式的规则称为文法。当每个基元被识别后,利用句法分析就可以作出整个的模式识别。即以这个句子是否符合某特定文法,以判别它是否属于某一类别。这就是句法模式识别的基本思想。 句法模式识别系统主要由预处理、基元提取、句法分析和文法推断等几部分组成。由预处理分割的模式,经基元提取形成描述模式的基元串(即字符串)。句法分析根据文法推理所推断的文法,判决有序字符串所描述的模式类别,得到判决结果。问题在于句法分析所依据的文法。不同的模式类对应着不同的文法,描述不同的目标。为了得到于模式类相适应的文法,类似于统计模式识别的训练过程,必须事先采集足够多的训练模式样本,经基元提取,把相应的文法推断出来。实际应用还有一定的困难。 2.1.2统计模式识别 统计模式识别是目前最成熟也是应用最广泛的方法,它主要利用贝叶斯决策规则解决最优分类器问题。统计决策理论的基本思想就是在不同的模式类中建立一个决策边界,利用决策函数把一个给定的模式归入相应的模式类中。统计模式识别的基本模型如图2,该模型主要包括两种操作模型:训练和分类,其中训练主要利用己有样本完成对决策边界的划分,并采取了一定的学习机制以保证基于样本的划分是最优的;而分类主要对输入的模式利用其特征和训练得来的决策函数而把模式划分到相应模式类中。 统计模式识别方法以数学上的决策理论为基础建立统计模式识别模型。其基本模型是:对被研究图像进行大量统计分析,找出规律性的认识,并选取出反映图像本质的特征进行分类识别。统计模式识别系统可分为两种运行模式:训练和分类。训练模式中,预处理模块负责将感兴趣的特征从背景中分割出来、去除噪声以及进行其它操作;特征选取模块主要负责找到合适的特征来表示输入模式;分类器负责训练分割特征空间。在分类模式中,被训练好的分类器将输入模式根据测量的特征分配到某个指定的类。统计模式识别组成如图2所示。
1模式识别与机器学习思考题及参考答案
模式识别与机器学习期末考查 思考题 1:简述模式识别与机器学习研究的共同问题和各自的研究侧重点。 机器学习是研究让机器(计算机)从经验和数据获得知识或提高自身能力的科学。 机器学习和模式识别是分别从计算机科学和工程的角度发展起来的。然而近年来,由于它们关心的很多共同问题(分类、聚类、特征选择、信息融合等),这两个领域的界限越来越模糊。机器学习和模式识别的理论和方法可用来解决很多机器感知和信息处理的问题,其中包括图像/视频分析、(文本、语音、印刷、手写)文档分析、信息检索和网络搜索等。近年来,机器学习和模式识别的研究吸引了越来越多的研究者,理论和方法的进步促进了工程应用中识别性能的明显提高。 机器学习:要使计算机具有知识一般有两种方法;一种是由知识工程师将有关的知识归纳、整理,并且表示为计算机可以接受、处理的方式输入计算机。另一种是使计算机本身有获得知识的能力,它可以学习人类已有的知识,并且在实践过程中不总结、完善,这种方式称为机器学习。机器学习的研究,主要在以下三个方面进行:一是研究人类学习的机理、人脑思维的过程;和机器学习的方法;以及建立针对具体任务的学习系统。机器学习的研究是在信息科学、脑科学、神经心理学、逻辑学、模糊数学等多种学科基础上的。依赖于这些学科而共同发展。目前已经取得很大的进展,但还没有能完全解决问题。 模式识别:模式识别是研究如何使机器具有感知能力,主要研究视觉模式和听觉模式的识别。如识别物体、地形、图像、字体(如签字)等。在日常生活各方面以及军事上都有广大的用途。近年来迅速发展起来应用模糊数学模式、人工神经网络模式的方法逐渐取代传统的用统计模式和结构模式的识别方法。特别神经网络方法在模式识别中取得较大进展。理解自然语言计算机如能“听懂”人的语言(如汉语、英语等),便可以直接用口语操作计算机,这将给人们带来极大的便利。计算机理解自然语言的研究有以下三个目标:一是计算机能正确理解人类的自然语言输入的信息,并能正确答复(或响应)输入的信息。二是计算机对输入的信息能产生相应的摘要,而且复述输入的内容。三是计算机能把输入的自然语言翻译成要求的另一种语言,如将汉语译成英语或将英语译成汉语等。目前,研究计算机进行文字或语言的自动翻译,人们作了大量的尝试,还没有找到最佳的方法,有待于更进一步深入探索。 机器学习今后主要的研究方向如下: 1)人类学习机制的研究;
模式识别方法简述
XXX大学 课程设计报告书 课题名称模式识别 姓名 学号 院、系、部 专业 指导教师 xxxx年 xx 月 xx日
模式识别方法简述 摘要:模式识别(Pattern Recognition)是指对表征事物或现象的各种形式的( 数值的、文字的和逻辑关系的) 信息进行处理和分析, 以对事物或现象进行描述、辨认、分类和解释的过程, 是信息科学和人工智能的重要组成部分。模式识别研究主要集中在两方面, 一是研究生物体( 包括人) 是如何感知对象的,属于认识科学的范畴, 二是在给定的任务下, 如何用计算机实现模式识别的理论和方法。前者是生理学家、心理学家、生物学家和神经生理学家的研究内容, 后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力, 已经取得了系统的研究成果。 关键词:模式识别; 模式识别方法; 统计模式识别; 模板匹配; 神经网络模式识别 模式识别(Pattern Recognition)是人类的一项基本智能,在日常生活中,人们经常在进行“模式识别”。随着2 0 世纪4 0 年代计算机的出现以及5 0 年代人工智能的兴起,人们当然也希望能用计算机来代替或扩展人类的部分脑力劳动。(计算机)模式识别在2 0 世纪6 0 年代初迅速发展并成为一门新学科。 模式识别研究主要集中在两方面, 一是研究生物体( 包括人) 是如何感知对象的,属于认识科学的范畴, 二是在给定的任务下, 如何用计算机实现模式识别的理论和方法。前者是生理学家、心理学家、生物学家和神经生理学家的研究内容, 后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力, 已经取得了系统的研究成果。模式识别与统计学、心理学、语言学、计算机科学、生物学、控制论等都有关系。它与人工智能、图像处理的研究有交叉关系。例如自适应或自组织的模式识别系统包含了人工智能的学习机制;人工智能研究的景物理解、自然语言理解也包含模式识别问题。又如模式识别中的预处理和特征抽取环节应用图像处理的技术;图像处理中的图像分析也应用模式识别的技术。 模式识别是一种借助计算机对信息进行处理、判别的分类过程。判决分类在
机器学习在模式识别中的算法研究
机器学习在模式识别中的算法研究 摘要:机器学习是计算机开展智能操作的基础,人工智能的发展依靠机器学习 技术,而机器学习、模式识别与当前人工智能的发展密切相关。本文通过概述机 器学习机制,围绕神经网络、遗传算法、支持向量机、K-近邻法等算法研究当前 机器学习在模拟识别中的应用,为今后模拟识别与人工智能开发与研究提供借鉴。关键词:机器学习;模式识别;人工神经网络 前言: 机器学习技术覆盖了人工智能的各个部分,如自动推理、专家系统、模式识别、智能机器人等。模式识别是将计算机的不同事物划分成不同的类别。人工智 能的模式识别可以利用机器学习算法完善分类能效。因此,机器学习与模式识别 密不可分,本文就机器学习在模式识别领域的学习算法中的应用展开研究。 1、机器学习机制与系统设计 在机器学习模型中,环境可以向系统的学习部件中提供信息,学习部件根据 这些信息调整和修改知识库,提升系统内部执行文件的性能。执行文件再将获得 的信息向学习部件反馈,此过程就是机器学习系统结合外部与内部的环境信息自 动获取知识的过程。机器学习系统设计的构建过程应包含两部分:其一,模型的 选择和构建。其二,学习算法的选择与设计。不同种类的模型具有不同的目标函数,涉及到不同的学习机制,算法的复杂性与能力决定着学习系统的效率与学习 能力。此外,训练样本集的特征与大小的问题也与机器学习系统的性能相关。 2、机器学习在模式识别中的应用 2.1 遗传算法 在机器学习中,特征维数是一大难题,每一种模式中的特征反映出的事物本 质权重均不一致。部分对于分类结果并无积极作用,甚至属于冗余,因此选择特 征尤为关键。遗传算法实际上是寻优算法,可以有效的解决特征选择问题。遗传 算法可以筛选出准确反映出原模式相关信息、影响分类的结果、相互关联性较小 的特征。遗传算法实际是利用达尔文的生物进化思想,在运算领域中巧妙生成一 种寻优算法。该算法是1975年由美国Michigan大学的Holland教授提出的,遗 传算法的主要方法如下:首先,将种群中的个体作为对象,进行一系列的变异、 交叉、选择等操作。其次,利用遗传操作促进群体不断的进化,最终产生最优的 个体,最后,结合个体对于环境的适应程度选择最优良的个体,为其创造机会繁 衍后代。遗传算法程序如下:选择合适的编码策略,确定遗传策略和适应度函数。遗传策略包含种群的选择、大小、交叉概率、变异方法、变异概率等遗传参数; 利用编码策略,将特征集变为位串结构;构建初始化群体;计算整个群体的个体 适应度;结合遗传策略,将交叉、选择等作用在群体中,产生下一代群体;判别 群体性能是否到达某一标准,假若不满足将回到遗传策略阶段。 2.2 k-近邻法 k-nearest neighbor(k-近邻法)被广泛运用在无指导、基于实例的学习方法中, 可以实现线性不可分的样本识别,在之前并不了解待分样本的分布函数。当前被 广泛应用的k-近邻法主要是将待分类样本为重点形成超球体,同时扩展超球的半 径一直到球内包含着K个已知模式的样本,判别k个邻近样本属于哪一种。其主 要分类算法如下:设有c个类别,分别是w1,w2,w3,...,wc,i=1,2,3,...,c.测试样本x