ARMA模型的eviews的建立 时间序列分析实验指导
时间序列arma模型建立的流程

时间序列arma模型建立的流程时间序列ARMA模型建立的流程1. 引言时间序列分析是一种对时间序列数据进行建模、预测和分析的统计方法。
ARMA模型是一种常用的时间序列模型,它可以描述时间序列数据中的自相关和移动平均关系。
本文将从数据准备、模型选择、参数估计和模型诊断等方面,介绍建立时间序列ARMA模型的完整流程。
2. 数据准备1.收集时间序列数据,确保数据具有一定的观测频率,并且包含足够的历史观测值。
2.对数据进行可视化分析,绘制时间序列图和自相关图,初步了解数据的趋势和周期性。
3. 模型选择1.确定时间序列数据是否平稳。
对于非平稳数据,需要进行差分运算,直到得到平稳的时间序列数据。
2.根据平稳时间序列数据的自相关和偏自相关图,选择合适的ARMA模型阶数。
通过观察自相关图的截尾性和偏自相关图的截尾性,确定ARMA(p, q)模型中的p和q。
4. 参数估计1.通过最大似然估计或最小二乘法,估计ARMA模型中的参数。
最大似然估计假定模型误差服从正态分布,而最小二乘法假定误差服从零均值正态分布。
2.通过估计的参数,建立ARMA模型。
5. 模型诊断1.对残差进行自相关和偏自相关分析,验证模型的残差序列是否为纯随机序列,即不存在自相关和异方差性。
2.对模型的残差序列进行Ljung-Box检验,验证残差的独立性。
3.对模型的残差序列进行正态性检验,验证模型的残差是否符合正态分布。
4.对模型的残差序列进行异方差性检验,验证模型的残差是否存在异方差现象。
6. 模型评估和预测1.使用信息准则(如AIC、BIC)评价模型的拟合程度。
较小的AIC和BIC值表示模型的拟合程度较好。
2.使用估计的ARMA模型对未来的数据进行预测,得到预测值和置信区间。
7. 结论建立时间序列ARMA模型的流程包括数据准备、模型选择、参数估计和模型诊断等环节。
通过该流程,我们能够对时间序列数据进行建模和预测,为相关领域的决策提供科学依据。
以上为时间序列ARMA模型建立的流程,希望对读者有所帮助。
eviews实验指导(ARIMA模型建模与预测)
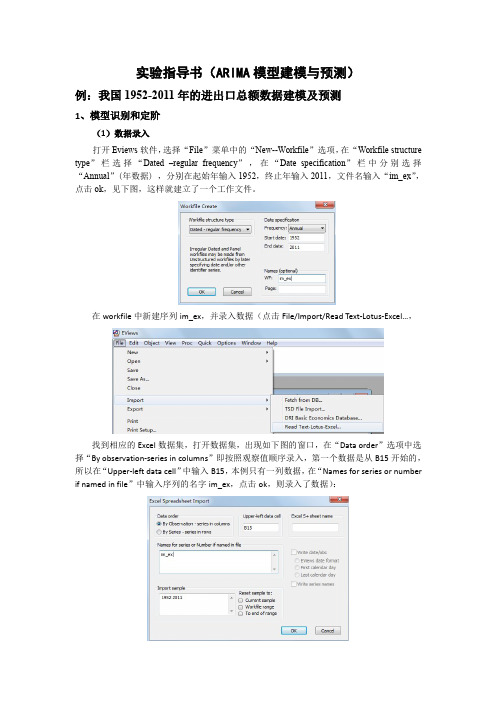
实验指导书(ARIMA模型建模与预测)例:我国1952-2011年的进出口总额数据建模及预测1、模型识别和定阶(1)数据录入打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated–regular frequency”,在“Date specification”栏中分别选择“Annual”(年数据),分别在起始年输入1952,终止年输入2011,文件名输入“im_ex”,点击ok,见下图,这样就建立了一个工作文件。
在workfile中新建序列im_ex,并录入数据(点击File/Import/Read Text-Lotus-Excel…,找到相应的Excel数据集,打开数据集,出现如下图的窗口,在“Data order”选项中选择“By observation-series in columns”即按照观察值顺序录入,第一个数据是从B15开始的,所以在“Upper-left data cell”中输入B15,本例只有一列数据,在“Names for series or number if named in file”中输入序列的名字im_ex,点击ok,则录入了数据):(2)时序图判断平稳性双击序列im_ex ,点击view/Graph/line,得到下列对话框:得到如下该序列的时序图,由图形可以看出该序列呈指数上升趋势,直观来看显著非平稳。
40,00080,000120,000160,000200,000240,000556065707580859095000510IM_EX(3)原始数据的对数处理因为数据有指数上升趋势,为了减小波动,对其对数化,在Eviews 命令框中输入相应的命令“series y=log(im_ex)”就得到对数序列,其时序图见下图,对数化后的序列远没有原始序列波动剧烈:45678910111213556065707580859095000510Y从图上仍然直观看出序列不平稳,进一步考察序列y 的自相关图和偏自相关图:从自相关系数可以看出,呈周期衰减到零的速度非常缓慢,所以断定y 序列非平稳。
Eviews中的ARMA模型操作

图
第4页/共7页
由图可以看出p = 1和q = 1,即样本数据具有 ARMA(1,1)模型过程。
(二)模型的估计 模型的理论计算过程较繁杂,我们这里仍然直接利 用EViews软件计算:
在工作文件主窗口点击Quick/Estimate Equation , 在Equation Specification 对话框中填入 y ma(1) ar(1) 便得到模型ARMA(1,1)的估计结果,如图所示:
ARMA(p,q)模型的优点是能以较少的参数描写单用 AR(p)或MA(q)过程不能经济地描写的数据生成过程。 在实际应用中,用ARMA(p,q)拟合实际数据时所需阶 数较低,p和q的数值很少超过2。因此,ARMA模型 在预测中具有很大的实用价值。
二、ARMA模型阶数的确定和模型的估计 (一)ARMA模型阶数的确定 我们如何描述一个平稳随机过程的经济系统,我们 的基本想法是从随机过程抽取样本,再根据样本数 据型、MA模型还是ARMA模型?这 就需要确定p和q的数值各是多少,为此需要计算样 本数据的自相关系数和偏自相关系数。而这个计算是 一个复杂的过程,为了实际应用的方便我们采用直接 利用计算机软件EViews来判断p和q的数值各是多少, 从而就确定了模型和模型的阶数。
在样本数据窗口,点击View/Correlogram 然后在对 话框中选择滞后期数,我们这里选取12,再点击 “OK”得到自相关系数和偏自相关系数及其图形,如 图所示:
第5页/共7页
图
由图可以知道模型为:
yˆ t yt-1+utut-1
第6页/共7页
感谢您的观看!
第7页/共7页
时间序列 eviews操作

1.打开EVIEWS新建一个工作文件,步骤如下:
出现如下对话框,选择数据频率为季度,开始日期为1989年1季度,结束日期为2004年4季度,即为工作文件的范围区间。
点击ok生成工作文件
2.若要改变工作文件的范围区间,双击Range,出现如下对话框
3.利用命令series 生成时间序列gdp
点击Edit+/-改变数据的编辑状态,打开EXCEL文件将数据复制粘贴到数据区域,查看数据序列的折线图,步骤如下:
结果:
从图中可看出时间序列有明显的季节波动。
4.对gdp序列进行描述统计分析:
5.对原GDP数据进行季节调整,调整后时间序列存为GDP_SA
6.做出折线图:
由图知序列受季节影响程度变小。
7.进行单位根检验,结果如下:
计算自相关函数和偏相关函数如下:
9.利用方程建立ARMA(3,3)模型
10.建立组,包括gdp gdp_sa dgdp
建组后展示如下:
11.将建组后的收据以EXCEL格式输出:
点击ok即可。
时间序列经济模型EVIEWS操作
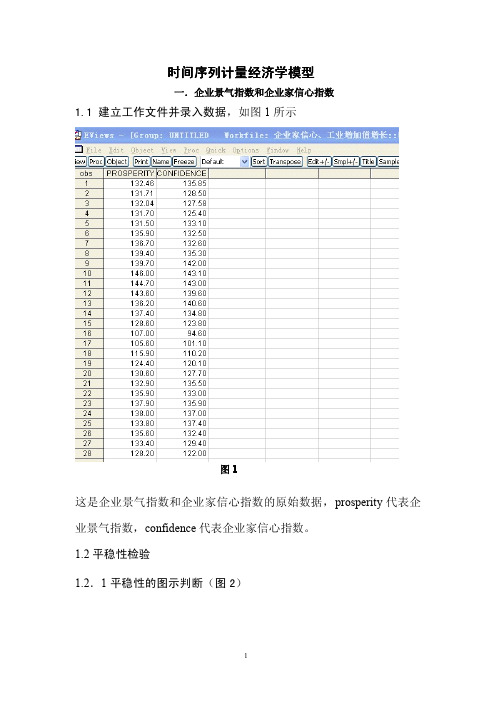
时间序列计量经济学模型一.企业景气指数和企业家信心指数1.1建立工作文件并录入数据,如图1所示图1这是企业景气指数和企业家信心指数的原始数据,prosperity代表企业景气指数,confidence代表企业家信心指数。
1.2平稳性检验1.2.1平稳性的图示判断(图2)图2从图中可以看出企业景气指数和企业家信心指数这两序列都是非平稳的。
1.2.2样本自相关图判断点击主界面Quick\Series Statistics\Correlogram...,在弹出的对话框中输入prosperity,点击OK就会弹出Correlogram Specification对话框,选择Level,并输入要输出的阶数(一般默认为24),点击OK,即可得到prosperity的样本相关函数图,如图3所示。
图3从上述样本相关函数图,可以看到企业景气指数(prosperity)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。
所以,通过企业景气指数(prosperity)的样本相关图,可初步判定该企业景气指数(prosperity)时间序列非平稳。
同理得:confidence的样本相关函数图,如图4所示图4从上述样本相关函数图,可以看到企业家信心指数(confidence)的样本相关函数是缓慢的递减趋于零的,但随着时间的推移,在0附近波动并呈发散趋势。
所以,通过企业家信心指数(confidence)的样本相关图,可初步判定该企业家信心指数(confidence)时间序列非平稳。
1.2.3单位跟检验单位跟检验((ADF检验检验))(1)企业景气指数(prosperity)采用ADF检验对prosperity序列进行平稳性的单位根检验。
点击主界面Quick\Series Statistics\Unit Root Test...,在弹出的Series对话框中输入prosperity,点击OK,就会出现UnitRoot Test对话框,如图5所示。
实验报告-时间序列

实验报告----平稳时间序列模型的建立08经济统计I60814030王思瑶一.实验目的从观察到的化工生产过程产量的70个数据样本出发,通过对模型的识别、模型的定价、模型的参数估计等步骤建立起适合序列的模型。
以下是化工生产过程的产量数据:obs BF obs BF1 47 36582 64 37453 23 38544 71 39365 38 40546 64 41487 55 42558 41 43459 59 445710 48 455011 71 466212 35 474413 57 486414 40 494315 58 505216 44 513817 80 525918 55 535519 37 544120 74 555321 51 564922 57 573423 50 583524 60 595425 45 604526 57 616827 50 623828 45 635029 25 646030 59 653931 50 665932 71 674033 56 685734 74 695435 50 7023可以明显看出序列均值显著非零,所以用样本均值作为其估计对序列进行零均值化。
obs BF 零均值化后的数据Y obs BF零均值化后的数据Y1 47 -4.12857 3658 6.871432 64 12.87143 3745-6.128573 23 -28.12857 3854 2.871434 71 19.87143 3936-15.128575 38 -13.12857 4054 2.871436 64 12.87143 4148-3.128577 55 3.87143 4255 3.871438 41 -10.12857 4345-6.128579 59 7.87143 4457 5.8714310 48 -3.12857 4550-1.1285711 71 19.87143 466210.8714312 35 -16.12857 4744-7.1285713 57 5.87143 486412.8714314 40 -11.12857 4943-8.1285715 58 6.87143 50520.8714316 44 -7.12857 5138-13.1285717 80 28.87143 52597.8714318 55 3.87143 5355 3.8714319 37 -14.12857 5441-10.1285720 74 22.87143 5553 1.8714321 51 -0.12857 5649-2.1285722 57 5.87143 5734-17.1285723 50 -1.12857 5835-16.1285724 60 8.87143 5954 2.8714325 45 -6.12857 6045-6.1285726 57 5.87143 616816.8714327 50 -1.12857 6238-13.1285728 45 -6.12857 6350-1.1285729 25 -26.12857 64608.8714330 59 7.87143 6539-12.1285731 50 -1.12857 66597.8714332 71 19.87143 6740-11.1285733 56 4.87143 6857 5.8714334 74 22.87143 6954 2.8714335 50 -1.12857 7023-28.12857二.实验步骤1.模型识别零均值平稳序列的自相关函数与偏相关函数的统计特性如下:模型 AR(n) MA(m) ARMA(n,m)自相关函数拖尾截尾拖尾偏自相关函数截尾拖尾拖尾所以,作零均值化后数据的自相关函数与偏自相关函数图Date: 04/25/11 Time: 22:35Sample: 2001 2070Included observations: 70Autocorrelation Partial Correlation AC PAC Q-Stat Prob***| . | ***| . | 1 -0.382 -0.382 10.638 0.001. |** | . |** | 2 0.325 0.209 18.444 0.000**| . | . | . | 3 -0.193 -0.018 21.234 0.000. |*. | . | . | 4 0.090 -0.049 21.857 0.000.*| . | .*| . | 5 -0.162 -0.126 23.900 0.000. | . | .*| . | 6 0.014 -0.094 23.916 0.001. | . | . | . | 7 0.012 0.065 23.928 0.001.*| . | .*| . | 8 -0.085 -0.079 24.519 0.002. | . | . | . | 9 0.039 -0.051 24.644 0.003. | . | . |*. | 10 0.033 0.080 24.736 0.006. |*. | . |*. | 11 0.090 0.125 25.426 0.008.*| . | . | . | 12 -0.077 -0.054 25.942 0.011. | . | . | . | 13 0.063 -0.045 26.291 0.016. | . | . |*. | 14 0.051 0.134 26.524 0.022. | . | . |*. | 15 -0.006 0.079 26.528 0.033. |*. | . |*. | 16 0.126 0.145 28.016 0.031.*| . | . | . | 17 -0.090 -0.040 28.792 0.036. | . | .*| . | 18 0.017 -0.084 28.820 0.051.*| . | . | . | 19 -0.099 -0.017 29.795 0.054. | . | . | . | 20 0.006 -0.036 29.798 0.073. | . | . | . | 21 0.015 0.055 29.820 0.096. | . | . | . | 22 -0.037 -0.015 29.968 0.119. | . | . | . | 23 0.013 -0.051 29.985 0.150. | . | . | . | 24 0.010 0.010 29.997 0.185. | . | . | . | 25 0.015 -0.016 30.023 0.223. | . | . | . | 26 0.036 0.023 30.172 0.261. | . | . | . | 27 -0.016 -0.036 30.202 0.305. | . | . | . | 28 0.033 0.030 30.335 0.347. | . | . | . | 29 -0.057 -0.015 30.735 0.378. | . | . | . | 30 0.051 -0.003 31.064 0.412.*| . | . | . | 31 -0.070 -0.053 31.706 0.431. | . | . | . | 32 0.057 -0.003 32.141 0.460由上图可知Autocorrelation与Partial Correlation序列均有收敛到零的趋势,可以认为Y的自相关函数与偏自相关函数均是拖尾的,所以初步判断该序列适合ARMA模型。
时间序列实验报告(ARMA模型的参数估计)
时间序列分析实验报告实验课程名称时间序列分析
实验项目名称 ARMA,ARIMA模型的参数估计年级
专业
学生姓名
成绩
理学院
实验时间:2015 年11月20日
学生所在学院:理学院专业:金融学班级:数学班
1、判断该序列的稳定性和纯随机性
该序列的时序图如下:
从图中可以看出具有很明显的下降趋势和周期性,所以通常是非平稳的。
在做它的自相关图。
由该时序图我们基本可以认为其是平稳的,再做DX自相关图和偏自相关图
自相关图显示延迟12阶自相关系数显著大于2倍标准差范围。
说明差分后序列中仍蕴含着非常显著的季节效应。
3、模型参数估计和建模
普通最小二乘法下,输入D(X,1,12) AR(1) MA(1) SAR(12) SMA(12) ,得到下图,其中,所有的参数估计量的
于0.05,均显著。
AIC为1.896653,SC为1.964273 。
普通最小二乘法,输入D(X,1,12)AR(1 )MA(1)SAR(12)SAR(24)SMA(12),
值小于0.05,均显著。
AIC为1.640316,SC为1.728672 。
4、参数估计结果
比较这两个模型,因为第二个模型的SC值小于第一个模型的SC值,所以相对而言,第二个模型是最优模型。
模型结果为:。
eviews实验指导ARIMA模型建模与预测
eviews实验指导ARIMA模型建模与预测在当今的数据分析领域,时间序列分析是一项至关重要的技术,而ARIMA 模型则是其中的一种常用且强大的工具。
通过 Eviews 软件来进行 ARIMA 模型的建模与预测,可以帮助我们更好地理解和处理时间序列数据,从而为决策提供有力的支持。
接下来,让我们一起深入了解如何使用 Eviews 进行 ARIMA 模型的建模与预测。
一、ARIMA 模型的基本原理ARIMA 模型,全称为自回归移动平均整合模型(Autoregressive Integrated Moving Average Model),它由三个部分组成:自回归(AR)、差分(I)和移动平均(MA)。
自回归(AR)部分表示当前值与过去若干个值之间的线性关系。
简单来说,如果一个时间序列在当前时刻的值受到过去若干个时刻的值的影响,那么就存在自回归关系。
移动平均(MA)部分则反映了随机干扰项对当前值的影响。
它通过将当前值表示为过去若干个随机干扰项的线性组合,来描述时间序列中的随机波动。
差分(I)操作则用于将非平稳的时间序列转化为平稳序列。
平稳性是时间序列分析中的一个重要概念,指的是时间序列的统计特性(如均值、方差等)不随时间变化而变化。
二、Eviews 软件操作环境介绍在开始建模之前,我们先来熟悉一下 Eviews 软件的操作环境。
打开 Eviews 软件,我们会看到一个简洁明了的界面。
菜单栏提供了各种功能选项,如文件操作、数据处理、模型估计等。
工作区用于显示数据、图表和分析结果。
在进行 ARIMA 模型建模时,我们主要会用到“Quick”菜单中的“Estimate Equation”选项,以及“View”菜单中的各种分析功能。
三、数据准备与导入首先,我们需要准备好要分析的时间序列数据。
数据可以以 Excel表格或其他常见的数据格式保存。
在 Eviews 中,可以通过“File”菜单中的“Import”选项将数据导入到软件中。
eviews实验指导书
计量经济学实验指导书目录实验一Eviews的基本操作与一元线性回归模型的最小二乘估计 (1)实验目的: (1)实验内容: (1)实验二:Eviews的常用函数与多元线性回归分析 (6)实验目的 (6)实验内容 (6)实验三异方差的检验与修正 (8)实验目的 (8)实验内容 (8)实验四序列相关的检验与修正 (13)实验目的 (13)实验内容 (13)实验五多重共线性的检验和修正 (18)实验目的 (18)实验内容 (18)实验六柯布-道格拉斯生产函数的求解 (22)实验目的 (22)实验内容 (22)实验一Eviews的基本操作与一元线性回归模型的最小二乘估计实验目的:1、熟悉Eviews的窗口与界面2、掌握Eviews的命令与菜单的操作3、掌握用Eviews估计与检验一元线性回归模型实验内容:1、启动Eviews双击Eviews图标,出现Eviews窗口,它由以下部分组成:标题栏“Eviews”、主菜单“File,Edit,…,Help”、命令窗口(空白处)和工作区域。
命令窗口工作区域图1-12、产生文件Eviews的操作在工作文件中进行,故首先要有工作文件,然后进行数据输入、分析等等操作。
(1)读已存在文件:File→Open→Workfile。
(2)新建文件:File→New→Workfile,出现对话框“工作文件范围”,选取或填上数据类型、起止时间。
OK后,得到一个无名字的工作文件,其中有:时间范围、当前工作文件样本范围、filter 、默认方程、系数向量C、序列RESID。
在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为工作文件,将弹出一个对话框(如图所示),由用户选择数据的时间频率(frequency)、起始期和终止期。
图1-2工作文件对话框其中, Annual——年度 Monthly——月度Semi-annual——半年 Weekly——周Quarterly——季度 Daily——日Undated or irregular——非时序数据选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日前1985和1998。
Eviews时间序列分析报告实例
Eviews时间序列分析实例时间序列是市场中经常涉与的一类数据形式,本书第七章对它进展了比拟详细的介绍。
通过第七章的学习,读者了解了是时间序列,并接触到有关时间序列分析方法的原理和一些分析实例。
本节的主要内容是说明如何使用Eviews软件进展分析。
一、指数平滑法实例所谓指数平滑实际就是对历史数据的加权平均。
它可以用于任何一种没有明显函数规律,但确实存在某种前后关联的时间序列的短期。
由于其他很多分析方法都不具有这种特点,指数平滑法在时间序列中仍然占据着相当重要的位置。
〔-〕一次指数平滑一次指数平滑又称单指数平滑。
它最突出的优点是方法非常简单,甚至只要样本末期的平滑值,就可以得到结果。
一次指数平滑的特点是:能够跟踪数据变化。
这一特点所有指数都具有。
过程中添加最新的样本数据后,新数据应取代老数据的地位,老数据会逐渐居于次要的地位,直至被淘汰。
这样,值总是反映最新的数据结构。
一次指数平滑有局限性。
第一,值不能反映趋势变动、季节波动等有规律的变动;第二,这种方法多适用于短期,而不适合作中长期的;第三,由于值是历史数据的均值,因此与实际序列的变化相比有滞后现象。
指数平滑是否理想,很大程度上取决于平滑系数。
Eviews提供两种确定指数平滑系数的方法:自动给定和人工确定。
选择自动给定,系统将按照误差平方和最小原如此自动确定系数。
如果系数接近1,说明该序列近似纯随机序列,这时最新的观测值就是最理想的值。
出于的考虑,有时系统给定的系数不是很理想,用户需要自己指定平滑系数值。
平滑系数取值比拟适宜呢?一般来说,如果序列变化比拟平缓,平滑系数值应该比拟小,比如小于0.l;如果序列变化比拟剧烈,平滑系数值可以取得大一些,如0.3~0.5。
假如平滑系数值大于0.5才能跟上序列的变化,明确序列有很强的趋势,不能采用一次指数平滑进展。
[例1]某企业食盐销售量。
现在拥有最近连续30个月份的历史资料〔见表l〕,试下一月份销售量。
表1 某企业食盐销售量单位:吨解:使用Eviews对数据进展分析,第一步是建立工作文件和录入数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
时间序列分析实验指导42-2-450100150200250统计与应用数学学院前言随着计算机技术的飞跃发展以及应用软件的普及,对高等院校的实验教学提出了越来越高的要求。
为实现教育思想与教学理念的不断更新,在教学中必须注重对大学生动手能力的培训和创新思维的培养,注重学生知识、能力、素质的综合协调发展。
为此,我们组织统计与应用数学学院的部分教师编写了系列实验教学指导书。
这套实验教学指导书具有以下特点:①理论与实践相结合,书中的大量经济案例紧密联系我国的经济发展实际,有利于提高学生分析问题解决问题的能力。
②理论教学与应用软件相结合,我们根据不同的课程分别介绍了SPSS、SAS、MATLAB、EVIEWS等软件的使用方法,有利于提高学生建立数学模型并能正确求解的能力。
这套实验教学指导书在编写的过程中始终得到安徽财经大学教务处、实验室管理处以及统计与应用数学学院的关心、帮助和大力支持,对此我们表示衷心的感谢!限于我们的水平,欢迎各方面对教材存在的错误和不当之处予以批评指正。
统计与数学模型分析实验中心2007年2月目录实验一EVIEWS中时间序列相关函数操作错误!未定义书签。
实验二确定性时间序列建模方法错误!未定义书签。
实验三时间序列随机性和平稳性检验错误!未定义书签。
实验四时间序列季节性、可逆性检验错误!未定义书签。
实验五ARMA模型的建立、识别、检验错误!未定义书签。
实验六ARMA模型的诊断性检验错误!未定义书签。
实验七ARMA模型的预测错误!未定义书签。
实验八复习ARMA建模过程错误!未定义书签。
实验九时间序列非平稳性检验错误!未定义书签。
实验一EVIEWS中时间序列相关函数操作【实验目的】熟悉Eviews的操作:菜单方式,命令方式;练习并掌握与时间序列分析相关的函数操作。
【实验内容】一、EViews软件的常用菜单方式和命令方式;二、各种常用差分函数表达式;三、时间序列的自相关和偏自相关图与函数;【实验步骤】一、EViews软件的常用菜单方式和命令方式;㈠创建工作文件⒈菜单方式启动EViews软件之后,进入EViews主窗口在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为工作文件,将弹出一个对话框,由用户选择数据的时间频率(frequency)、起始期和终止期。
选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日期,然后点击OK按钮,将在EViews软件的主显示窗口显示相应的工作文件窗口。
工作文件窗口是EViews的子窗口,工作文件一开始其中就包含了两个对象,一个是系数向量C(保存估计系数用),另一个是残差序列RESID(实际值与拟合值之差)。
⒉命令方式在EViews软件的命令窗口中直接键入CREATE命令,也可以建立工作文件。
命令格式为:CREATE 时间频率类型起始期终止期则菜单方式过程可写为:CREATE A 1985 1998㈡输入Y、X的数据⒈DATA命令方式在EViews软件的命令窗口键入DATA命令,命令格式为:DATA <序列名1> <序列名2>…<序列名n>本例中可在命令窗口键入如下命令:DATA Y X⒉鼠标图形界面方式在EViews软件主窗口或工作文件窗口点击Objects/New Object,对象类型选择Series,并给定序列名,一次只能创建一个新序列。
再从工作文件目录中选取并双击所创建的新序列就可以展示该对象,选择Edit+/-,进入编辑状态,输入数据。
㈢生成log(Y)、log(X)、X^2、1/X、时间变量T等序列在命令窗口中依次键入以下命令即可:GENR LOGY=LOG(Y)GENR LOGX=LOG(X)GENR X1=X^2GENR X2=1/XGENR T=@TREND(84)㈣选择若干变量构成数组,在数组中增加变量。
在工作文件窗口中单击所要选择的变量,按住Ctrl键不放,继续用鼠标选择要展示的变量,选择完以后,单击鼠标右键,在弹出的快捷菜单中点击Open/as Group,则会弹出数组窗口,其中变量从左至右按在工作文件窗口中选择变量的顺序来排列。
在数组窗口点击Edit+/-,进入全屏幕编辑状态,选择一个空列,点击标题栏,在编辑窗口输入变量名,再点击屏幕任意位置,即可增加一个新变量。
增加变量后,即可输入数据。
点击要删除的变量列的标题栏,在编辑窗口输入新变量名,再点击屏幕任意位置,弹出RENAME对话框,点击YES按钮即可。
㈤在工作文件窗口中删除、更名变量。
⒈在工作文件窗口中选取所要删除或更名的变量并单击鼠标右键,在弹出的快捷菜单中选择Delete(删除)或Rename(更名)即可⒉在工作文件窗口中选取所要删除或更名的变量,点击工作文件窗口菜单栏中的Objects/Delete selected…(Rename selected…),即可删除(更名)变量⒊在工作文件窗口中选取所要删除的变量,点击工作文件窗口菜单栏中的Delete按钮即可删除变量。
三、图形分析与描述统计分析㈠利用PLOT命令绘制趋势图在命令窗口中键入:PLOT Y也可以利用PLOT命令将多个变量的变化趋势描绘在同一张图中,例如键入以下命令,可以观察变量Y、X的变化趋势PLOT Y X㈡利用SCAT命令绘制X、Y的散点图在命令窗口中键入:SCAT X Y则可以初步观察变量之间的相关程度与相关类型二、各种常用差分函数表达式1 112 115 145 171 196 204 242 284 315 340 360 417 2 118 126 150 180 196 188 233 277 301 318 342 391 3 132 141 178 193 236 235 267 317 356 362 406 4194 129 135 163 181 235 227 269 313 348 348 396 461 5 121 125 172 183 229 234 270 318 355 363 420 472 6 135 149 178 218 243 264 315 374 422 435 472 5357 148 170 199 230 264 302 364 413 465 491 548 622 8 148 170 199 242 272 293 347 405 467 505 559 606 9136158 184 209 237 259 312 355 404 404 463 508 10 119 133 162 191 211 229 274 306 347 359 407 461 11 104 114 146 172 180 203 237 271 305 310 362 390 12 118 140166194201229278306306337405432(一)利用D(x)命令系列对时间序列进行差分(x 为表1-1中的数据)。
1、在命令窗口中键入:genr dx= D(x) 则生成的新序列为序列x 的一阶差分序列2、在命令窗口中键入:genr dxn= D(x,n) 则生成的新序列为序列x 的n 阶差分。
3、在命令窗口中键入:genr dxs= D(x,0,s)则生成的新序列为序列x 的对周期长度为s 一阶季节差分。
4、在命令窗口中键入:genr dxsn= D(x,n,s)则生成的新序列为对周期长度为s 的时间序列x 取一阶季节差分后的序列再取n 阶差分。
5、在命令窗口中键入:genr dlx= Dlog(x)则生成的新序列为x 取自然对数后,再取一阶差分。
6、在命令窗口中键入:genr dlxsn= Dlog(x,n,s)则生成的新序列为周期长度为s 的时间序列x 先取自然对数,再取一阶季节差分,然后再对序列取n 阶差分。
在EVIEWS 中操作的图形分别为:-150-100-50050100495051525354555657585960DX三、时间序列的自相关和偏自相关图与函数;(一)观察时间序列的自相关图。
命令方式:(1)在命令行输入命令:Ident x (x 为序列名称); (2)然后在出现的对话框中输入滞后时期数。
(可取默认数) 菜单方式:(1)双击序列图标。
菜单操作方式:View —>Correlogram ,在出现的对话框中输入滞后数。
(可取默认数)(二)练习:观察一些文件中的序列自相关函数Autocorrelation ,偏自相关函数Partial autocorrelation 的特征-150-100-50050100150495051525354555657585960-2020406080495051525354555657585960-40-200204060495051525354555657585960-0.15-0.10-0.050.000.050.100.15495051525354555657585960练习1:操作文件:Stpoor~(美国S&P500工业股票价格指数1980年1月~1996年2月)步骤:(1)打开该文件。
(2)观察序列stpoorr的趋势图,自相关图(自相关函数,偏自相关函数)的特征。
(3)对序列取一阶差分,生成新序列dsp:genr dsp=d(stpoor),并观察其趋势图,自相关图(同上,下略)的特征。
(4)对该序列的自然对数取一阶差分,生成新的序列dlnsp:genr dlnsp=dlog(stpoor),并观察其趋势图,自相关图。
练习2:操作文件:(美国1947年第一季度~1970年第四季度GNP数据)步骤:(1)打开该文件。
(2)观察序列usagdp的趋势图的特征,自相关图的特征。
(3)对该序列取一阶差分,生新的序列dgdp:Genr dgdp=d(usagdp)。
观察其趋势图,自相关图。
(4)对该序列的自然对数取一阶差分,生成新的序列dlngdp:Genr dlngdp=dlog(gdp)。
观察其趋势图,自相关图。
(5)对序列一阶季节差分,生成新序列dsgdp=d(usagdp,0,4)观察其趋势图,自相关图的特征。
(6)对该序列的自然对数取一阶季节差分,生成新的序列:dslngdp=dlog(usagdp,0,4),观察其趋势图、自相关图。
实验二确定性时间序列建模方法【实验目的】熟悉确定性时间序列模型的建模原理;掌握确定性时间序列建立模型的几种常用方法。
【实验内容】一、多项式模型和加权最小二乘法的建立;二、单参数和双参数指数平滑法进行预测的操作练习;三、二次曲线和对数曲线趋势模型建立及预测;【实验步骤】一、多项式模型和加权最小二乘法的建立;1、我国1974—1994年的发电量资料列于表中,已知1995年的发电量为亿千瓦小时,试以表中的资料为样本:据拟合优度和外推检验的结果建立最合适的多项式模型。