主成分分析操作步骤
利用Excel进行主成分分析的具体操作
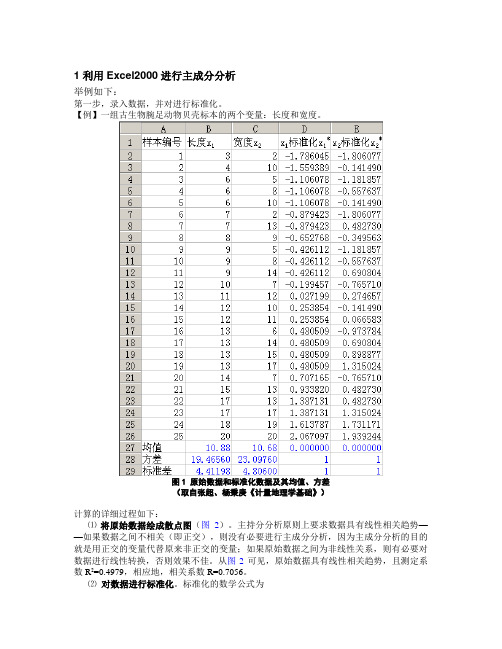
1 利用Excel2000进行主成分分析举例如下:第一步,录入数据,并对进行标准化。
【例】一组古生物腕足动物贝壳标本的两个变量:长度和宽度。
图1 原始数据和标准化数据及其均值、方差(取自张超、杨秉庚《计量地理学基础》)计算的详细过程如下:⑴将原始数据绘成散点图(图2)。
主持分分析原则上要求数据具有线性相关趋势——如果数据之间不相关(即正交),则没有必要进行主成分分析,因为主成分分析的目的就是用正交的变量代替原来非正交的变量;如果原始数据之间为非线性关系,则有必要对数据进行线性转换,否则效果不佳。
从图2可见,原始数据具有线性相关趋势,且测定系数R2=0.4979,相应地,相关系数R=0.7056。
⑵对数据进行标准化。
标准化的数学公式为j jij ij x x x σ-=*这里假定按列标准化,式中∑==ni ij ij x n x 11,)(Var )(12ij n i j ij ij x x x =-=∑=σ 分别为第j 列数据的均值和标准差,ij x 为第i 行(即第i 个样本)、第j 列(即第j 个变量)的数据,*ij x 为相应于ij x 的标准化数据,25=n 为样本数目。
图2 原始数据的散点图图3 标准化数据的散点图对数据标准化的具体步骤如下:① 求出各列数据的均值,命令为average ,语法为:average(起始单元格:终止单元格)。
如图1所示,在单元格B27中输入“=AVERAGE(B1:B26)”,确定或回车,即得第一列数据的均值88.101=x ;然后抓住单元格B27的右下角(光标的十字变细)右拖至C27,便可自动生成第二列数据的均值68.102=x 。
②求各列数据的方差。
命令为varp ,语法同均值。
如图1所示,在单元格B28中输入“=VARP(B2:B26)”,确定或回车,可得第一列数据的方差4656.19)(V ar 1=x ,右拖至C28生成第二列数据的方差0976.23)(V ar 2=x 。
主成分分析讲解范文

主成分分析讲解范文下面我们来具体讲解主成分分析的步骤和原理:1.数据预处理在进行主成分分析之前,需要对原始数据进行预处理,包括去除噪声、处理缺失值和标准化等操作。
这些操作可以使得数据更加准确和可靠。
2.计算协方差矩阵协方差矩阵是衡量各个变量之间相关性的指标。
通常,我们会对数据进行标准化处理,使得各个变量具有相同的尺度。
然后,计算标准化后的数据的协方差矩阵。
3.计算特征值和特征向量通过对协方差矩阵进行特征分解,可以得到特征值和特征向量。
其中,特征值表示新坐标系中的投影方差,特征向量表示新坐标系的方向。
4.选择主成分根据特征值的大小,我们可以按照降序的方式选择主成分。
选取一部分较大的特征值所对应的特征向量,即可得到相应的主成分。
这些主成分是原始数据中最重要的成分。
5.生成投影数据通过将原始数据投影到选取的主成分上,即可得到降维后的数据。
每个样本在各个主成分上的投影即为新的特征值。
6.重构数据在需要恢复原始数据时,可以通过将降维后的数据乘以选取的主成分的转置矩阵,再加上原始数据的均值,即可得到近似恢复的原始数据。
主成分分析在实际应用中有很广泛的用途。
首先,它可以用于数据的降维,使得复杂的数据集可以在低维空间中进行可视化和分析。
其次,它可以用于数据的简化和压缩,减少数据存储和计算的成本。
此外,主成分分析还可以用于数据的特征提取和数据预处理,辅助其他机器学习和统计分析方法的应用。
然而,主成分分析也有一些限制和注意事项。
首先,主成分分析假设数据具有线性关系,对于非线性关系的数据可能失效。
其次,主成分分析对于离群值敏感,需要对离群值进行处理。
另外,主成分分析得到的主成分往往是原始数据中的线性组合,不易解释其具体含义。
总之,主成分分析是一种常用的降维数据分析方法,通过寻找新的投影空间,使得数据的方差最大化,实现数据的降维和简化。
它可以应用于数据可视化、数据压缩和特征提取等方面,是数据分析和机器学习中常用的工具之一、在应用主成分分析时,需要注意数据的预处理和对主成分的解释和理解。
spss主成分分析法

spss主成分分析法SPSS主成分分析法(PrincipalComponentAnalysis,简称PCA)是一种常用的资料处理方法,通常被用于多种实际应用中,有助于分析资料的降维和发掘隐藏的资料特征。
SPSS是一种统计软件,它可以帮助用户处理收集的数据,例如对数据进行分析、估计、回归分析等等。
SPSS可以用来快速分析大量数据,以提取隐藏的趋势和关系,从而更充分地利用资料。
基本原理SPSS主成分分析是一种数据分析方法,它可以使研究者更有效地发掘资料中的内在规律,以获得有意义的信息。
PCA假定资料中有关变量之间存在某种相关性,并且可以根据这些变量彼此之间的相关性,利用变量之间的协方差矩阵系统地分解出新的特征变量,称为主成分。
主成分是由原有的变量的组合得到的新的变量,它是原有变量的最佳线性组合,它不含有任何原有变量的信息,而且它们的系数都是正值。
PCA的一般步骤1.据预处理:首先,用户需要整理和准备资料,其中包括检查数据中的缺失值,识别异常点,检查是否存在多重共线性(Multicollinearity)等。
2. 主成分的提取:从资料中提取主成分,这一步骤需要计算协方差矩阵,利用特征值分解对协方差矩阵进行分解,从而获得主成分的系数和权重。
3.主成分投影到新的变量空间中:通过将原始变量与主成分系数进行线性组合,将原始变量投影到新的主成分变量空间中,得到新空间上的变量。
4. 主成分变量的解释:识别主成分变量之间的关系,找到主要资料趋势,并尝试为主成分变量作出解释或提供有意义的标签。
应用SPSS主成分分析法可以用于多种应用,例如为统计预测模型提供非线性变量、降低回归模型中的自变量数、为数据可视化提供支持、帮助识别数据中的明显趋势、帮助发现隐藏的数据模式和改善数据的可读性等。
基于PCA的方法可以更好地发掘资料中的潜在规律,从而更有效地分析数据,改善数据的可读性。
结论SPSS主成分分析法是一种常用的数据分析方法,以及一种常用的资料处理技术,可以帮助用户发掘潜在的资料特征,改善数据的可读性,找到关键趋势,从而更有效地利用数据,为研究和决策获取有效的支持。
主成分分析法的原理应用及计算步骤

主成分分析法的原理应用及计算步骤1.计算协方差矩阵:首先,我们需要将原始数据进行标准化处理,即使每个特征都有零均值和单位方差。
假设我们有m个n维样本,数据集为X,标准化后的数据集为Z。
那么,计算协方差矩阵的公式如下:Cov(Z) = (1/m) * Z^T * Z其中,Z^T为Z的转置。
2.计算特征向量:通过对协方差矩阵进行特征值分解,可以得到特征值和特征向量。
特征值表示了新坐标系中每个特征的重要性程度,特征向量则表示了数据在新坐标系中的方向。
将协方差矩阵记为C,特征值记为λ1, λ2, ..., λn,特征向量记为v1, v2, ..., vn,那么特征值分解的公式如下:C*v=λ*v计算得到的特征向量按特征值的大小进行排序,从大到小排列。
3.选择主成分:从特征向量中选择与前k个最大特征值对应的特征向量作为主成分,即新坐标系的基向量。
这些主成分可以解释原始数据中大部分的方差。
我们可以通过设定一个阈值或者看特征值与总特征值之和的比例来确定保留的主成分个数。
4.映射数据:对于一个n维的原始数据样本x,通过将其投影到前k个主成分上,可以得到一个k维的新样本,使得新样本的方差最大化。
新样本的计算公式如下:y=W*x其中,y为新样本,W为特征向量矩阵,x为原始数据样本。
PCA的应用:1.数据降维:PCA可以通过主成分的选择,将高维数据降低到低维空间中,减少数据的复杂性和冗余性,提高计算效率。
2.特征提取:PCA可以通过寻找数据中的最相关的特征,提取出主要的信息,从而减小噪声的影响。
3.数据可视化:通过将数据映射到二维或三维空间中,PCA可以帮助我们更好地理解和解释数据。
总结:主成分分析是一种常用的数据降维方法,它通过投影数据到一个新的坐标系中,使得投影后的数据具有最大的方差。
通过计算协方差矩阵和特征向量,我们可以得到主成分,并将原始数据映射到新的坐标系中。
PCA 在数据降维、特征提取和数据可视化等方面有着广泛的应用。
主成分分析实验报告

一、实验目的本次实验旨在通过主成分分析(PCA)方法,对给定的数据集进行降维处理,从而简化数据结构,提高数据可解释性,并分析主成分对原始数据的代表性。
二、实验背景在许多实际问题中,数据集往往包含大量的变量,这些变量之间可能存在高度相关性,导致数据分析困难。
主成分分析(PCA)是一种常用的降维技术,通过提取原始数据中的主要特征,将数据投影到低维空间,从而简化数据结构。
三、实验数据本次实验采用的数据集为某电商平台用户购买行为的调查数据,包含用户年龄、性别、收入、职业、购买商品种类、购买次数等10个变量。
四、实验步骤1. 数据预处理首先,对数据进行标准化处理,消除不同变量之间的量纲影响。
然后,进行缺失值处理,删除含有缺失值的样本。
2. 计算协方差矩阵计算标准化后的数据集的协方差矩阵,以了解变量之间的相关性。
3. 计算特征值和特征向量求解协方差矩阵的特征值和特征向量,特征值表示对应特征向量的方差,特征向量表示数据在对应特征方向上的分布。
4. 选择主成分根据特征值的大小,选择前几个特征值对应特征向量作为主成分,通常选择特征值大于1的主成分。
5. 构建主成分空间将选定的主成分进行线性组合,构建主成分空间。
6. 降维与可视化将原始数据投影到主成分空间,得到降维后的数据,并进行可视化分析。
五、实验结果与分析1. 主成分分析结果根据特征值大小,选取前三个主成分,其累计贡献率达到85%,说明这三个主成分能够较好地反映原始数据的信息。
2. 主成分空间可视化将原始数据投影到主成分空间,绘制散点图,可以看出用户在主成分空间中的分布情况。
3. 主成分解释根据主成分的系数,可以解释主成分所代表的原始数据特征。
例如,第一个主成分可能主要反映了用户的购买次数和购买商品种类,第二个主成分可能反映了用户的年龄和性别,第三个主成分可能反映了用户的收入和职业。
六、实验结论通过本次实验,我们成功运用主成分分析(PCA)方法对数据进行了降维处理,提高了数据可解释性,并揭示了数据在主成分空间中的分布规律。
主成分分析方法

主成分分析方法在经济问题的研究中,我们常常会遇到影响此问题的很多变量,这些变量多且又有一定的相关性,因此我们希望从中综合出一些主要的指标,这些指标所包含的信息量又很多。
这些特点,使我们在研究复杂的问题时,容易抓住主要矛盾。
那么怎样找综合指标?主成分分析是将原来众多具有一定相关性的指标重新组合成一组新的相互无关的综合指标来代替原来指标的统计方法,也是数学上处理降维的一种方法. 一. 主成分分析法简介主成分分析是将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法,又称主分量分析。
在实际问题中,为了全面分析问题,往往提出很多与此有关的变量(或因素),因为每个变量都在不同程度上反映这个课题的某些信息。
但是,在用统计分析方法研究这个多变量的课题时,变量个数太多就会增加课题的复杂性。
人们自然希望变量个数较少而得到的信息较多。
在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。
主成分分析是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映问题的信息方面尽可能保持原有的信息。
信息的大小通常用离差平方和或方差来衡量。
主成分分析的基础思想是将数据原来的p 个指标作线性组合,作为新的综合指标(P F F F ,,,21 )。
其中1F 是“信息最多”的指标,即原指标所有线性组合中使)var(1F 最大的组合对应的指标,称为第一主成分;2F 为除1F 外信息最多的指标,即0),cov(21 F F 且)var(2F 最大,称为第二主成分;依次类推。
易知P F F F ,,,21 互不相关且方差递减。
实际处理中一般只选取前几个最大的主成分(总贡献率达到85%),达到了降维的目的。
主成分的几何意义:设有n 个样品,每个样品有两个观测变量,,21X X 二维平面的散点图。
n 个样本点,无论沿着1X 轴方向还是2X 轴方向,都有较大的离散性,其离散程度可以用1X 或2X 的方差表示。
使用主成分分析进行特征抽取的步骤
使用主成分分析进行特征抽取的步骤主成分分析(Principal Component Analysis,简称PCA)是一种常用的数据降维技术,它可以将高维数据转换为低维数据,保留数据中最重要的特征。
在机器学习和数据分析领域,PCA被广泛应用于特征抽取和数据可视化等任务。
本文将介绍使用主成分分析进行特征抽取的步骤。
1. 数据预处理在进行主成分分析之前,需要对数据进行预处理。
首先,需要对数据进行标准化,即将每个特征的均值调整为0,方差调整为1。
这是因为PCA是一种基于方差的分析方法,如果特征之间的尺度不一致,会导致主成分分析的结果不准确。
其次,如果数据中存在缺失值,需要进行缺失值处理,可以选择删除带有缺失值的样本或者使用插补方法进行填充。
2. 计算协方差矩阵在进行主成分分析之前,需要计算原始数据的协方差矩阵。
协方差矩阵描述了数据中各个特征之间的相关性。
协方差矩阵的计算公式为:Cov(X,Y) = E[(X-μX)(Y-μY)]其中,Cov(X,Y)表示X和Y的协方差,E表示期望,μX和μY分别表示X和Y的均值。
协方差矩阵是一个对称矩阵,对角线上的元素表示各个特征的方差,非对角线上的元素表示各个特征之间的协方差。
3. 计算特征值和特征向量通过对协方差矩阵进行特征值分解,可以得到特征值和特征向量。
特征值表示了数据中的方差,而特征向量表示了数据中的主要方向。
特征值和特征向量的计算可以使用各种数值计算库或者线性代数工具进行。
4. 选择主成分根据特征值的大小,可以选择保留最大的k个特征值对应的特征向量作为主成分。
一般来说,可以根据特征值的累计贡献率来确定保留的主成分个数。
累计贡献率表示了前k个主成分所解释的方差占总方差的比例。
通常情况下,可以选择累计贡献率大于80%或90%的主成分。
5. 数据投影将原始数据投影到选取的主成分上,得到降维后的数据。
投影的计算公式为:Y = XW其中,Y表示降维后的数据,X表示原始数据,W表示选取的主成分。
主成分分析
主成分分析法主成分分析是多元统计分析的一个分支。
20世纪30年代,由于费希尔、霍特林、许宝禄及罗伊等人的一系列奠基工作,多元统计分析成为应用数学的一个重要分支。
主成分分析法是处理多元变量数据的一种数学方法,它从众多的观测变量中找出几个相互独立的因素来解释原有的变量,这些因素称为主成分。
通过主成分分析法的数学处理,可以将互相间有联系的多变量复杂系统简化成几个可以解释这些变量的综合因素,这样可以清楚的解释系统的本质及相互间的关系。
抽取抽取综合因素及如何定义要按综合因素与原变量的关系而定,即按综合和因素对变量的影响程度,称为变量在综合因素上的“负荷”。
最终还可以计算出受测样本在综合因素上的水平,称为主成分分析。
主成分分析发广泛应用于复杂系统的相互比较研究中。
设一个系统共有P个指标表示,而且这P个指标中可能有些指标互相有影响。
主成分分析法就是要用几个综合因素反映原来几个指标的信息,而且这些因素又是相互无关的。
一基本原理现实生活中,人们常常遇到多指标问题。
在大多数情况下,不同指标之间具有一定的相关性,这就增加了分析处理问题的难度。
于是统计学家们就设法将指标重新组合成一组相互独立的少数几个综合指标来代替原有指标,并且反映原有指标的主要信息。
这种将多指标化为少数独立的综合指标的方法就称为主成分分析法。
主成分分析(Principal Component Analysis,PCA),首先是由英国的皮尔生(Karl Pearosn)对非随机变量引入的,而后美国的数理统计学家霍特林在1933年将此法推广到随即向量的情形。
主成分分析法的降维思想从一开始就很好的为综合评价提供了有力的理论和技术支持。
主成分分析是研究如何将多指标问题转化为较少的综合指标的一种重要统计方法,它能将高维空间的问题转化到低维空间去处理,使问题变得比较简单、直观,而且这些较少的综合指标之间互不相关,又能提供原有指标的绝大部分信息。
主成分分析除了降低多变量数据系统的维度外,同时还简化了变量系统的统计数字特征。
主成分分析完整版
X的两个主成分分别为 第一主成分的贡献率为
Y1 0.040X1 0.999X2, Y2 0.999X1 0.040X2.
1 100.16 99.2% 1 2 101
R 型分析
R型分析的概念
为消除量纲影响,在计算之前先将原始数据标准化。标准
4. 由此我们可以写出三个主成分的表达式:
F1 0.56(x1 161 .2) 0.42(x2 77.3) 0.71(x3 51.2) F2 0.81(x1 161 .2) 0.33(x2 77.3) 0.48(x3 51.2) F3 0.03(x1 161 .2) 0.85(x2 77.3) 0.53(x3 51.2)
主 旋转坐标轴
x 2
F 1
成 分 分 析 的 几 何 解
F 2
•
•••
•••
• •
•
•••••••••••••••••••••••
• •
F1 x1 cos x2 sin
F2 x1 sin x2 cos
F1
F2
cos sin
sin x1
cos
x2
x2
旋转变换的目的是为了使得n个
很显然,识辨系统在一个低维空间要比在一个高维空间容 易得多。
在力求数据信息丢失最少的原则下,对高维的变量空间降 维,即研究指标体系的少数几个线性组合,并且这几个线性 组合所构成的综合指标将尽可能多地保留原来指标变异方面 的信息。这些综合指标就称为主成分。要讨论的问题是:
(1) 基于相关系数矩阵/协方差矩阵做主成分分析? (2) 选择几个主成分? (3) 如何解释主成分所包含的实际意义?
2. 求解协方差矩阵的特征方程 S I 0
主成分分析的实施步骤与应用领域
主成分分析的实施步骤与应用领域主成分分析(Principal Component Analysis,简称PCA)是一种常用的多变量数据分析方法,它通过线性变换将原始数据转换为一组新的无关联线性变量,称为主成分。
这些主成分按照方差的大小依次排列,其中第一个主成分具有最大的方差。
在实践中,主成分分析被广泛应用于数据降维、特征选择和数据探索等领域。
本文将介绍主成分分析的实施步骤,并探讨其在不同应用领域中的具体应用。
一、主成分分析的实施步骤1. 数据预处理在进行主成分分析之前,首先需要对原始数据进行预处理。
这包括数据清洗、数据标准化和数据缺失值处理等步骤。
数据清洗可以剔除异常值和噪声数据,使得分析结果更加准确可靠。
数据标准化可以将数据转换为均值为0、方差为1的标准正态分布,消除不同变量之间的量纲差异。
对于存在缺失值的数据,可以使用插补方法进行处理。
2. 计算协方差矩阵协方差矩阵是主成分分析的基础,它描述了变量之间的线性相关关系。
通过计算原始数据的协方差矩阵,可以得到各个变量之间的相关性。
协方差矩阵的元素表示两个变量之间的协方差,对角线上的元素表示各个变量的方差。
3. 计算特征值和特征向量通过对协方差矩阵进行特征值分解,可以得到特征值和对应的特征向量。
特征值表示主成分的方差,特征向量表示主成分的方向。
特征向量是由归一化的协方差矩阵的特征向量组成。
4. 选择主成分选择主成分的原则是保留方差较大的主成分,以保留最多的原始数据信息。
可以通过特征值的大小进行排序,选择前几个特征值对应的特征向量作为主成分。
5. 计算主成分得分主成分得分是原始数据在主成分上的投影。
通过将原始数据乘以所选择的主成分的特征向量,可以计算得到各个样本在主成分上的得分。
主成分得分可以用于数据降维和分类等应用。
二、主成分分析的应用领域1. 数据降维主成分分析可以用于将高维数据降低到低维空间,减少数据的维度。
通过选择保留的主成分数量,可以实现数据的降维。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主成分分析操作步骤
1)先在spss中录入原始数据。
2)菜单栏上执行【分析】——【降维】——【因子分析】,打开因素分析对话
框,将要分析的变量都放入【变量】窗口中。
3)设计分析的统计量
点击【描述】:选中“Statistics”中的“原始分析结果”和“相关性矩阵”中的
“系数”。(选中原始分析结果,SPSS自动把原始数据标准差标准化,但不显
示出来;选中系数,会显示相关系数矩阵)然后点击“继续”。
点击【抽取】:“方法”里选取“主成分”;“分析”、“输出”、“抽取”均选中各自的
第一个选项即可。
点击【旋转】:选取第一个选项“无”。(当因子分析的抽取方法选择主成分法时,且不进
行因子旋转,则其结果即为主成分分析)
点击【得分】:选中“保存为变量”,方法中选“回归”;再选中“显示因子得分系数矩阵”。
点击【选项】:选择“按列表排除个案”。
4)结果解读
5)A. 相关系数矩阵:是6个变量两两之间的相关系数大小的方阵。通过相关系
数可以看到各个变量之间的相关,进而了解各个变量之间的关系。
相關性矩陣
食品 衣着 燃料 住房 交通和通讯 娱乐教育文化
相關 食品
.692 .319 .760 .738 .556
衣着
.692 .663 .902 .389
燃料
.319 .267
住房
.760 .663 .831 .387
交通和通讯
.738 .902 .831 .326
娱乐教育文化
.556 .389 .267 .387 .326
B. 共同度:给出了这次主成分分析从原始变量中提取的信息,可以看出交通和
通讯最多,而娱乐教育文化损失率最大。
Communalities
起始 擷取
食品
.878
衣着
.825
燃料
.841
住房
.810
交通和通讯
.919
娱乐教育文化
.584
擷取方法:主體元件分析。
C. 总方差的解释:系统默认方差大于1的为主成分。如果小于1,说明这个主因
素的影响力度还不如一个基本的变量。所以只取前两个,且第一主成分的方差为,
第二主成分的方差为,前两个主成分累加占到总方差的%。
說明的變異數總計
元件 起始特徵值 擷取平方和載入 總計 變異的 % 累加 % 總計 變異的 % 累加 %
1
2
3 .600
4 .358
5 .142
6 .043 .712
擷取方法:主體元件分析。
D.主成分载荷矩阵:
元件矩陣a
元件
1 2
食品
.902 .255
衣着
.880
燃料
.093 .912
住房
.878
交通和通讯
.925
娱乐教育文化
.588 .488
擷取方法:主體元件分析。
a. 擷取 2 個元件。
特别注意:
该主成分载荷矩阵并不是主成分的特征向量,即不是主成分1和主成分2的系数。
主成分系数的求法:各自主成分载荷向量除以各自主成分特征值得算数平方根。
则第1主成分的各个系数是向量(,,,,,)除以568.3后才得到的,即(,,,,,)
才是主成分1的特征向量,满足条件是系数的平方和等于1,分别乘以6个原始
变量标准化之后的变量即为第1主成分的函数表达式(作业中不用写公式):
Y1=*Z交+*Z食+*Z衣+*Z住+*Z娱+*Z燃
同理可求出第2主成分的函数表达式。
E.主成分得分系数矩阵
元件評分係數矩陣
元件
1 2
食品
.253 .198
衣着
.247
燃料
.026 .708
住房
.246
交通和通讯
.259
娱乐教育文化
.165 .379
擷取方法:主體元件分析。
元件評分。
该矩阵是主成分载荷矩阵除以各自的方差得来的,实际上是因子分析中各个因子
的系数,在主成分分析中可以不考虑它。
元件評分共變異數矩陣
元件
1 2
1 .000
2 .000
擷取方法:主體元件分析。
元件評分。
6)因子得分
在之前的“得分”对话框中,由于选中了
“保存为变量”,方法中的“回归”;又选
中了“显示因子得分系数矩阵”,因此SPSS的输出结果和原始数据一起显示在数据窗口里:
7)主成分得分
特别提醒:
后两列的数据是北京等16个地区的因子1和因子2的得分,不是主成分1和主
成分2的得分。主成分的得分是相应的因子得分乘以相应的方差的算数平方根。
即:主成分1得分=因子1得分乘以的算数平方根
主成分2得分=因子2得分乘以的算数平方根
得出各地区主成分1和主成分2的得分如下表:
后两列就是16个地区主成分1和主成分2的得分。(有兴趣的同学可以验证一下:上面推
导出来的主成分的函数关系式计算出来的主成分得分是否与该数据栏的的得分一致)
8)综合得分及排序:
每个地区的综合得分是按照下列公式计算的:
Y=*主成分1得分+*主成分2得分
按照此公式计算出各地区的综合得分Y为:
按照综合得分Y的大小进行16个地区的排序:
点击【数据】——【排序个案】
特别提醒:
1.若主成分分析中有n个变量,则特征值(或方差)之和就等于n;
2.特征向量(或主成分的系数)中各个数值的平方和等于1,否则就不是特征向量,也不是
主成分系数;
3.主成分载荷向量各系数的平方和等于其对应的主成分的方差;
本例中 + + + + + =
4.SPSS没有专门的主成分分析模块,是在因子分析模块进行的。它只输出主成分载荷矩阵和
因子得分值,而我们最想得到的主成分的系数(特征向量)和主成分则需要另外计算。
5.若计算没有错误,因子1、因子2、主成分1、主成分2和综合得分Y,它们各自的数值之
和都等于0;
6.主成分分析应该计算出综合得分并排序。