spss 第2次作业 2016105246-王斯
《统计分析与SPSS的应用(第五版)》课后练习答案(第2章)

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?产品类型体重变化情况明显减轻无明显变化第一种产品27 19第二种产品20 33问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System MissingValue)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
研究生SPSS考试题目
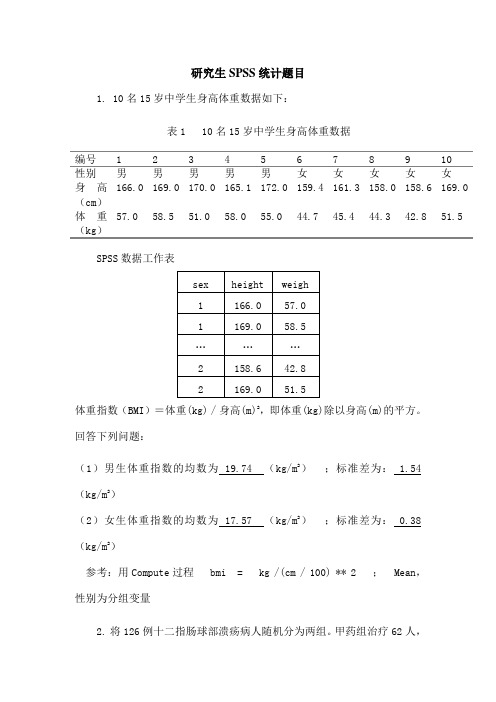
研究生SPSS统计题目1. 10名15岁中学生身高体重数据如下:表1 10名15岁中学生身高体重数据编号12345678910性别男男男男男女女女女女166.0169.0170.0165.1172.0159.4161.3158.0158.6169.0身高(cm)57.058.551.058.055.044.745.444.342.851.5体重(kg)SPSS数据工作表体重指数(BMI)=体重(kg) / 身高(m)2,即体重(kg)除以身高(m)的平方。
回答下列问题:(1)男生体重指数的均数为 19.74 (kg/m2);标准差为: 1.54(kg/m2)(2)女生体重指数的均数为 17.57 (kg/m2);标准差为: 0.38(kg/m2)参考:用Compute过程 bmi = kg /(cm / 100) ** 2 ; Mean,性别为分组变量2. 将126例十二指肠球部溃疡病人随机分为两组。
甲药组治疗62人,54人有效;乙药组治疗64人,44人有效。
问两种药物的治疗效果有无差别?(1)SPSS数据工作表group effect fre115412821442220(2)选用SPSS过程:Weight cases;Analyze Descriptive Statistics Crosstabs 。
(3)SPSS的结果与解释(包括检验方法、统计量、P值和统计推断):经2检验,2=6.13,P = 0.013。
可认为两种药物的治疗效果有差别,即甲药有效率(87.1%)高于乙药(68.8%)。
3. 某医师研究物理疗法、药物疗法和外用膏药三种疗法治疗周围性面神经麻痹的疗效,资料见表3。
问三种疗法的有效率有无差别?表3 三种疗法治疗周围性面神经麻痹的疗效数数20619996.6物理疗法18216490.1药物疗法14411881.9外用膏药(1)SPSS数据工作表group effect fre11199127211642218311183226(2)选用SPSS过程:Weight cases;Analyze Descriptive Statistics Crosstabs 。
SPSS操作实验作业1(附答案)

SPSS操作实验 (作业1)作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。
然而,当代大学生对华夏文明究竟知道多少呢某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。
调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。
调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。
请利用这些资料,分析以下问题。
问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。
问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。
要求:直接导出查看器文件为.doc后打印(导出后不得修改)对分析结果进行说明,另附(手写、打印均可)。
于作业布置后,1周内上交本次作业计入期末成绩答案问题一操作过程1.打开数据文件作业。
同时单击数据浏览窗口的【变量视图】按钮,检查各个变量的数据结构定义是否合理,是否需要修改调整。
2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对话框。
在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。
3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字“5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。
接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。
再单击【继续】按钮,返回【频率】对话框。
4.单击【图表】按钮,勾选【直方图】和【显示正态曲线】复选框,即直方图中附带正态曲线。
再单击【继续】按钮,返回【频率】对话框。
最后,单击【确定】按钮,操作完成。
《统计分析与SPSS的应用(第五版)》课后练习答案(第2章)
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?产品类型体重变化情况明显减轻无明显变化第一种产品27 19第二种产品20 33问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System MissingValue)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
SPSS教程2: 利用SPSS进行量表分析

SPSS教程2:利用SPSS进行量表分析2006-9-5 18:40:12信息来源:生物谷SPSS教程2:利用SPSS进行量表分析 生物谷网站本节将介绍利用SPSS软件对量表进行处理分析。
在获取原始数据后,我们利用SPSS对量表可以作出三种分析,即项目分析、因素分析和信度分析。
项目分析,目的是找出未达显著水准的题项并把它删除。
它是通过将获得的原始数据求出量表中题项的临界比率值——CR值来作出判断。
通常,量表的制作是要经过专家的设计与审查,因此,题项一般均具有鉴别度,能够鉴别不同受试者的反应程度。
故往往在量表处理中可以省去这一步。
因素分析,目的是在多变量系统中,把多个很难解释,而彼此有关的变量,转化成少数有概念化意义而彼此独立性大的因素,从而分析多个因素的关系。
在具体应用时,大多数采用“主成份因素分析”法,它是因素分析中最常使用的方法。
信度分析,目的是对量表的可靠性与有效性进行检验。
如果一个量表的信度愈高,代表量表愈稳定。
也就表示受试者在不同时间测量得分的一致性,因而又称“稳定系数”。
根据不同专家的观点,量表的信度系数如果在0.9以上,表示量表的信度甚佳。
但是对于可接受的最小信度系数值是多少,许多专家的看法也不一致,有些专家定为0.8以上,也有的专家定位0.7以上。
通常认为,如果研究者编制的量表的信度过低,如在0.6以下,应以重新编制较为适宜。
在本节中,主要介绍利用SPSS软件对量表进行因素分析。
一、因素分析基本原理因素分析是通过求出量表的“结构效度”来对量表中因素关系作出判断。
在多变量关系中,变量间线性组合对表现或解释每个层面变异数非常有用,主成份分析主要目的即在此。
变量的第一个线性组合可以解释最大的变异量,排除前述层次,第二个线性组合可以解释次大的变异量,最后一个成份所能解释总变异量的部份会较少。
主成份数据分析中,以较少成份解释原始变量变异量较大部份。
成份变异量通常用“特征值”表示,有时也称“特性本质”或“潜在本质”。
智慧树知到《SPSS统计工具应用》章节测试答案

智慧树知到《SPSS统计工具应用》2020章节测试答案--(二)第一章单元测试1、问题:结果输出窗口保存的文件以什么为后缀()选项:A:sav●B:spoC:spsD:rtf答案: 【spo】2、问题:下面不属于SPSS的缺点是()选项:●A:与OFFICE等办公软件兼容性差B:非专业统计软件C:数据收集和数据清洗功能弱D:处理数据量级较低答案: 【与OFFICE等办公软件兼容性差】3、问题:下面不属于SPSS的优点是()选项:A:基本统计方法较全面B:易用性强●C:编程能力强D:帮助功能强大答案: 【编程能力强】4、问题:IBM SPSS品牌中的计数功能产品是()选项:A:SPSS Modeler●B:SPSS StatisticC:SPSS AmosD:PASW答案: 【SPSS Statistic】5、问题:SPSS中的“统计辅导”帮助功能以个案的形式讲解各模块的主要分析方法的基本操作和结果解释。
选项:A:对●B:错答案: 【错】6、问题:SPSS可以同时打开多个结果输出窗口,并将输出结果同时输出在所有输出窗口中。
选项:A:对●B:错答案: 【错】7、问题:SPSS的结果输出窗口中也有分析菜单,所以统计分析操作可以在输出窗口执行。
选项:●A:对B:错答案: 【对】8、问题:社会经济问题研究中常用采用的统计数据分析方法是严格设计支持下的统计方法。
选项:A:对●B:错答案: 【错】第二章单元测试1、问题:SPSS数据变量类型不包括()选项:A:数值型B:字符型C:日期型●D:逻辑型答案: 【逻辑型】2、问题:同学们的考核等级变量属于什么计量尺度()选项:A:定类尺度B:定距尺度●C:定序尺度D:定比尺度答案: 【定序尺度】3、问题:SPSS中定义变量尺度属性称为()选项:A:变量值标签●B:度量C:变量类型D:变量角色答案: 【度量】4、问题:将EXCEL的xlsx文件录入SPSS的方式不包括()选项:A:复制、粘贴B:直接打开C:数据库导入●D:文本数据导入答案: 【文本数据导入】5、问题:如果性别变量用1和2表示男和女,那么可以直接计算平均性别和性别差。
《统计分析与SPSS的应用(第五版)》课后练习答案(第2章)
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?产品类型体重变化情况明显减轻无明显变化第一种产品27 19第二种产品20 33问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System MissingValue)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
SPSS题目及答案汇总版

《SPSS原理与运用》练习题数据对应关系:06-均值检验;07-方差分析;08-相关分析;09-回归分析;10-非参数检验;17-作图1、以data06-03为例,分析身高大于等于155cm的与身高小于155cm的两组男生的体重和肺活量均值是否有显著性。
分析:一个因素有2个水平用独立样本t检验,此题即身高因素有155以上和以下2个水平,因此用独立样本t检验(analyze->compare means->independent-samples T test)。
报告:一、体重①m+s:>=155cm 时, m= 40.838kg; s= 5.117;<155cm 时, m= 34.133kg;s= 3.816;②方差齐性检验结果:P=0.198>0.05,说明方差齐性。
③t=4.056; p=0.001< 0.01,说明身高大于等于155cm 的与身高小于155cm的两组男生的体重有极显著性差异。
二、肺活量①m+s: >=155cm 时,m=2.404; s=0.402;<155cm 时, m=2.016;s=0.423;②方差齐性检验结果:P=0.961>0.05,说明方差齐性。
③t=2.512; p=0.018 < 0.05,说明说明身高大于等于155cm的与身高小于155cm的两组男生的体重有显著性差异。
2、以data06-04为例,判断体育疗法对降低血压是否有效。
分析:比较前后2种情况有无显著差异,用配对样本t检验,(analyze->compare means-> paired-samples T test).报告:①m+s 治疗前舒展压:m=119.50; s=10.069;治疗后舒展压:m=102.50; s=11.118;②相关系数correlation=0.599; p=0.067>0.05,说明体育疗法与降低血压相关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
-16.50
2.799
-5.895
9
.000
不假设等方差
1
-16.50
2.700
-6.110
6.577
.001
又对应的概率p值-0.000,小于显著性水平0.05,拒绝原假设,则认为三者的整体效果存在显著性差异。
实验小结
三者的整体效果存在显著性差异。
【基本格式】
三者的整体效果存在显著性差异。
实验分析
方差齐性检验,对前提条件进行分析检验
方差齐性检验
亩产量
Levene统计量
df1
df2
显著性
.056
2
9
.946
Levene统计量为0.056,应的概率p值为0.946,大于显著性水平0.05,不应该拒绝原假设,则认为三种不同品种的水稻的亩产量的总体方差无显著性差异,满足方差分析的前提条件。
.035
-15.31
-.69
3
17.000*
3.232
.001
9.69
24.31
2
1
8.000*
3.232
.035
.69
15.31
3
25.000*
3.232
.000
17.69
32.31
3
1
-17.000*
3.232
.001
-24.31
-9.69
2
-25.000*
3.232
.000
-32.31
-17.69
1.000
1.000
1.000
将显示同类子集中的组均值。
a.将使用调和均值样本大小= 4.000。
且形成3个相似性子集,且组内的相似性概率为1,则品种3最差。
对比系数
对比
水稻品种
1
2
3
1
.5
-1
.5
由多重比较分析知,品种3最差,最好为品种2.
对比检验
对比
对比值
标准误
t
df
显著性(双侧)
亩产量
假设方差相等
ANOVA
亩产量
平方和
df
均方
F
显著性
组间
(组合)
1304.000
2
652.000
31.213
.000
线性项
对比
578.000
1
578.000
27.670
.001
偏差
726.000
1
726.000
34.755
.000
组内
188.000
9
20.889
总数
1492.000
11
其为不同品种对亩产量单因素分析结果:观测变量亩产量的总离差平方和=1492,其中不同品种对亩产量产生的离差平方和=1304,对应的方差为=652,抽样误差所引起的离差平方和=188,对应方差=20.889,
实验项目
水稻单因素方差分析
实验日期
2018.4.4
实验地点
教室
实验目的
检验样本均值之间的差异是否具有统计学意义,分析各类差异对其影响。
实验内容
先找出不同水稻品种的亩产量对比实验数据,再对其进行一定的分析,再得出结论。
实验步骤
1.方差分析前提条件检验
2.多重比较检验
3.同类子集
4.趋势检验
实验结果
品种3最差,最好为品种2.
*.均值差的显著性水平为0.05。
多重比较分析,品种1与22的概率p值为0.035,小于显著性水平0.05,两者具有差异性,同上,1与3,2与3都具有差异性。
亩产量
水稻品种
N
alpha = 0.05的子集
1
2
3
Student-Newman-Keulsa
3
4
86.00
1
4
103.00
2
4பைடு நூலகம்
111.00
显著性
F统计量为31,213,对应概率p值为0.000,小于显著性水平0.05,则拒绝原假设,认为这是三不同品种对亩产量产生了显著性影响,或不同品种对亩产量的影响效应不全为0.
多重比较
因变量:亩产量
(I)水稻品种
(J)水稻品种
均值差(I-J)
标准误
显著性
95%置信区间
下限
上限
LSD
1
2
-8.000*
3.232