模式识别实验指导书
模式识别实验一

, n 是 n 维均值
向 量 , C i 是 n n 协 方 差 矩 阵 ; Ci 为 矩 阵 Ci 的 行 列 式 。 且 i Ei x ,
Ci Ei
x
i
x
i , Ei x 表示对类别属于 i 的模式作数学期望运算。
T
因此判别函数可表示为 J i ( x) P( x | i ) P(i ) 对判别函数取自然对数
1 1 J i ( x) ( x i ) Ci1 ( x i ) ln P(i ) ln Ci 2 2
然后根据(1)中所述最大后验准则判断样本所属类别。 三、实验过程 实验数据: IRIS 数据集 实验假设: 各类数据服从正态分布 实验方法: 最大后验概率 实验环境: MATLAB 2010b (1)数据导入
A , B 可设置每种类型的先验概率 P A , P B 。针对某一训练数据 x 计
算其判别函数 J A x , J B x ,比较两个值的大小,哪个最大,就可判断该数据 属于哪一类。最后统计分类器判决结果,设置矩阵存储被错误分类的数据,统计 A,B 两类测试数据的误判数,计算误判率。 %---------分类器测试----------% %选择分类组(w1,w2)(w1,w3)(w2,w3) %test = 1代表(w1,w2)分类 %test = 2代表(w1,w3)分类 %test = 3代表(w2,w3)分类 test = 1; if test==1 avr_A = avr_w1';var_A = var_w1'; avr_B = avr_w2';var_B = var_w2'; %合并待测数据 data_test = [data_test_w1;data_test_w2]; end if test==2 avr_A = avr_w1';var_A = var_w1'; avr_B = avr_w3';var_B = var_w3'; %合并待测数据 data_test = [data_test_w1;data_test_w3]; end if test==3 avr_A = avr_w2';var_A = var_w2'; avr_B = avr_w3';var_B = var_w3'; %合并待测数据 data_test = [data_test_w2;data_test_w3]; end %s设置先验概率 P_wA = 1/2; P_wB = 1/2;
模式识别实验指导书

四、 实验组织运行要求
集中授课,统一实验时间
五、 实验条件
一人一机;学生应通过指导书,事先有初步设想;正式实验由实验室教师指导, 并适当安排讲解;部分参考资料由教师根据实际情况和学生程度不同考虑提供;
六、 实验步骤
1、提取分类特征,确定特征值值域,确定特征空间; 2、确定分类的限定错误率; 3、编写分类决策程序; 4、输入考试样本的分类特征,验证分类规则; 5、分析分类成功与失败样本,找出分类失败的原因。
为了统计类间的划分是否合理,需要观察两类间最为接近处的近邻函数值。如 果该数值较小,则表示本来很有可能连接起来的近邻没有被“连接”起来,这意味着 要冒较大风险,付出较大代价。用定量关系描述,需先定义两类间的最小近邻函数
值 ,它是 与 邻值 ri 定义为
间各对样本近邻函数值的最小值,而 对所有 c-1 类的最小近
实验一 势函数算法的迭代训练
实验学时:2 学时 实验类型:设计 实验要求:必修
一、 实验目的
通过本实验的学习,使学生了解或掌握模式识别的基本内容在限定一类错误率 条件下使另一类错误率为最小的两类别决策的有关知识,通过选用此种分类方法进 行分类器设计实验,从而强化学生对在限定一类错误率条件下使另一类错误率为最 小的两类别决策的了解和应用,为模式识别课程的后续环节奠定基础。
这种决策要求可看成是在 P2(e)=ε0 条件下,求 P1(e)极小值的条件极值问题,因 此可以用求条件极值的拉格朗日乘子法解决。为此我们写出如下算式
模式识别实验指导书

实验一、基于感知函数准则线性分类器设计1.1 实验类型:设计型:线性分类器设计(感知函数准则)1.2 实验目的:本实验旨在让同学理解感知准则函数的原理,通过软件编程模拟线性分类器,理解感知函数准则的确定过程,掌握梯度下降算法求增广权向量,进一步深刻认识线性分类器。
1.3 实验条件:matlab 软件1.4 实验原理:感知准则函数是五十年代由Rosenblatt 提出的一种自学习判别函数生成方法,由于Rosenblatt 企图将其用于脑模型感知器,因此被称为感知准则函数。
其特点是随意确定的判别函数初始值,在对样本分类训练过程中逐步修正直至最终确定。
感知准则函数利用梯度下降算法求增广权向量的做法,可简单叙述为: 任意给定一向量初始值)1(a ,第k+1次迭代时的权向量)1(+k a 等于第k 次的权向量)(k a 加上被错分类的所有样本之和与k ρ的乘积。
可以证明,对于线性可分的样本集,经过有限次修正,一定可以找到一个解向量a ,即算法能在有限步内收敛。
其收敛速度的快慢取决于初始权向量)1(a 和系数k ρ。
1.5 实验内容已知有两个样本空间w1和w2,这些点对应的横纵坐标的分布情况是:x1=[1,2,4,1,5];y1=[2,1,-1,-3,-3];x2=[-2.5,-2.5,-1.5,-4,-5,-3];y2=[1,-1,5,1,-4,0];在二维空间样本分布图形如下所示:(plot(x1,y1,x2,y2))-6-4-20246-6-4-2246w1w21.6 实验任务:1、 用matlab 完成感知准则函数确定程序的设计。
2、 请确定sample=[(0,-3),(1,3),(-1,5),(-1,1),(0.5,6),(-3,-1),(2,-1),(0,1),(1,1),(-0.5,-0.5),( 0.5,-0.5)];属于哪个样本空间,根据数据画出分类的结果。
3、 请分析一下k ρ和)1(a 对于感知函数准则确定的影响,并确定当k ρ=1/2/3时,相应的k 的值,以及)1(a 不同时,k 值得变化情况。
模式识别实验

模式识别实验
一、实验任务
本次实验任务是模式识别,主要包括形式化的目标追踪、字符流分类和语音识别等。
二、所需软件
本实验所需软件包括MATLAB、Python等。
三、实验步骤
1. 首先需要安装MATLAB 和Python等软件,并建立实验环境。
2. 然后,通过MATLAB 进行基于向量量化(VQ) 的目标追踪实验,搭建端到端的系统,并使用Matlab编程实现实验内容。
3. 接着,使用Python进行字符流分类的实验,主要包括特征提取、建模和识别等,并使用Python编程实现实验内容。
4. 最后,使用MATLAB 进行语音识别的实验,主要是使用向量量化方法识别语音,并使用Matlab编程实现实验内容。
四、结果分析
1.在基于向量量化的目标追踪实验中,我们通过计算误差,确定了最优参数,最终获得了较高的准确率。
2.在字符流分类实验中,我们通过选择最佳分类器,得到了较高的准确率。
3.在语音识别实验中,我们使用向量量化方法,最终也获得了不错的准确率。
五、总结
本次实验研究了基于向量量化的目标追踪、字符流分类和语音识别等三项模式识别技术,经实验,探讨了不同方法之间的优劣,并获得了较高的准确率。
本次实验的结果为日常模式识别工作提供了有价值的参考。
模式识别实验指导书2014

实验一、基于感知函数准则线性分类器设计1.1 实验类型:设计型:线性分类器设计(感知函数准则)1.2 实验目的:本实验旨在让同学理解感知准则函数的原理,通过软件编程模拟线性分类器,理解感知函数准则的确定过程,掌握梯度下降算法求增广权向量,进一步深刻认识线性分类器。
1.3 实验条件:matlab 软件1.4 实验原理:感知准则函数是五十年代由Rosenblatt 提出的一种自学习判别函数生成方法,由于Rosenblatt 企图将其用于脑模型感知器,因此被称为感知准则函数。
其特点是随意确定的判别函数初始值,在对样本分类训练过程中逐步修正直至最终确定。
感知准则函数利用梯度下降算法求增广权向量的做法,可简单叙述为: 任意给定一向量初始值)1(a ,第k+1次迭代时的权向量)1(+k a 等于第k 次的权向量)(k a 加上被错分类的所有样本之和与k ρ的乘积。
可以证明,对于线性可分的样本集,经过有限次修正,一定可以找到一个解向量a ,即算法能在有限步内收敛。
其收敛速度的快慢取决于初始权向量)1(a 和系数k ρ。
1.5 实验内容已知有两个样本空间w1和w2,这些点对应的横纵坐标的分布情况是:x1=[1,2,4,1,5];y1=[2,1,-1,-3,-3];x2=[-2.5,-2.5,-1.5,-4,-5,-3];y2=[1,-1,5,1,-4,0];在二维空间样本分布图形如下所示:(plot(x1,y1,x2,y2))-6-4-20246-6-4-2246w1w21.6 实验任务:1、 用matlab 完成感知准则函数确定程序的设计。
2、 请确定sample=[(0,-3),(1,3),(-1,5),(-1,1),(0.5,6),(-3,-1),(2,-1),(0,1),(1,1),(-0.5,-0.5),( 0.5,-0.5)];属于哪个样本空间,根据数据画出分类的结果。
3、 请分析一下k ρ和)1(a 对于感知函数准则确定的影响,并确定当k ρ=1/2/3时,相应的k 的值,以及)1(a 不同时,k 值得变化情况。
实验课程-091042-模式识别
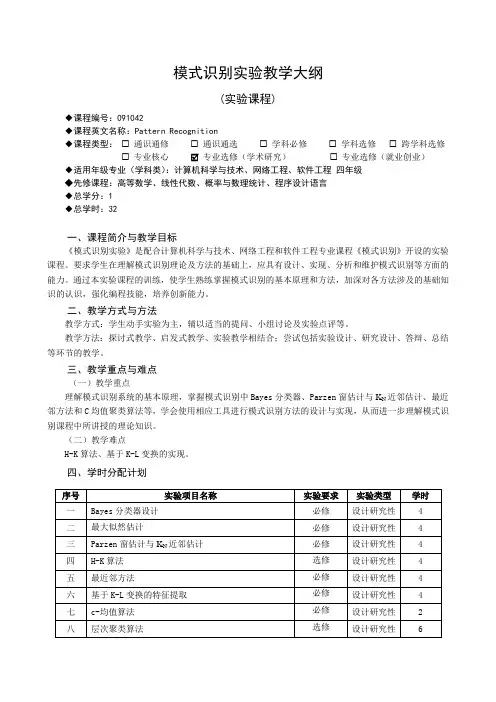
模式识别实验教学大纲(实验课程)◆课程编号:091042◆课程英文名称:Pattern Recognition◆课程类型:☐通识通修☐通识通选☐学科必修☐学科选修☐跨学科选修☐专业核心 专业选修(学术研究)☐专业选修(就业创业)◆适用年级专业(学科类):计算机科学与技术、网络工程、软件工程四年级◆先修课程:高等数学、线性代数、概率与数理统计、程序设计语言◆总学分:1◆总学时:32一、课程简介与教学目标《模式识别实验》是配合计算机科学与技术、网络工程和软件工程专业课程《模式识别》开设的实验课程。
要求学生在理解模式识别理论及方法的基础上,应具有设计、实现、分析和维护模式识别等方面的能力。
通过本实验课程的训练,使学生熟练掌握模式识别的基本原理和方法,加深对各方法涉及的基础知识的认识,强化编程技能,培养创新能力。
二、教学方式与方法教学方式:学生动手实验为主,辅以适当的提问、小组讨论及实验点评等。
教学方法:探讨式教学、启发式教学、实验教学相结合;尝试包括实验设计、研究设计、答辩、总结等环节的教学。
三、教学重点与难点(一)教学重点理解模式识别系统的基本原理,掌握模式识别中Bayes分类器、Parzen窗估计与K N近邻估计、最近邻方法和C均值聚类算法等,学会使用相应工具进行模式识别方法的设计与实现,从而进一步理解模式识别课程中所讲授的理论知识。
(二)教学难点H-K算法、基于K-L变换的实现。
四、学时分配计划五、教材与教学参考书(一)教材1.《模式识别(第2版)》,边肇祺,张学工等,清华大学出版社,2000。
(二)教学参考书1.《模式识别导论》,齐敏、李大健、郝重阳,清华大学出版社,2009;2.《模式识别原理》,孙亮,北京工业大学出版社,2009;3.《模式识别(第3版)》,张学工,清华大学出版社,2010;4.《模式识别(英文版·第3版)(经典原版书库)》,(希腊)西奥多里迪斯等著,机械工业出版社,2006。
模式识别实验【范本模板】
《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
模式识别实验指导书2014版
cpmean(i,:)=mean(meas(strmatch(char(sta(i,1)),species,'exact'),:));
4 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
− −
5 6
⎟⎟⎠⎞, ⎜⎜⎝⎛
− −
6 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 4
⎟⎟⎠⎞,
⎜⎜⎝⎛
4 5
⎟⎟⎠⎞,
⎜⎜⎝⎛
5 6
⎟⎟⎠⎞,
⎜⎜⎝⎛
6 5
⎟⎟⎠⎞⎭⎬⎫
,计算样本协方
差矩阵,求解数据第一主成分,并重建原始数据。
(2)使用 Matlab 中进行主成分分析的相关函数,实现上述要求。
有 c 个不同的水平,表示 c 个不同的类。
表 1-1 fit 方法支持的参数名与参数值列表
参数名
参数值
说明
'normal'
正态分布(默认)
核密度估计(通过‘KSWidth’参数设置核密度估计的窗宽
'kernel'
(默认情况下自动选取窗宽;通过‘KSSupport’参数设置
‘Distribution’ 'mvmn'
信息与电气工程学院专业实验中心 二〇一四年八月
《模式识别》实验一 贝叶斯分类器设计
一、实验意义及目的
掌握贝叶斯判别原理,能够利用 Matlab 编制程序实现贝叶斯分类器设计,熟悉基于 Matlab 的 算法处理函数,并能够利用算法解决简单问题。
模式识别实验指导书2015
6
深圳大学研究生课程“模式识别理论与方法”实验指导书(4th Edition 裴继红编)
(c) 用(b)中设计的分类器对测试点进行分类: (1, 2,1) , (5,3, 2) , (0, 0, 0) , (1, 0, 0) , 并且利用式(45)求出各个测试点与各个类别均值之间的 Mahalanobis 距离。 (d) 如果 P ( w1 ) 0.8, P ( w2 ) P ( w3 ) 0.1 ,再进行(b)和(c)实验。 (e) 分析实验结果。 表格 1
深圳大学研究生课程:模式识别理论与方法
课程作业实验指导
(4th Edition) (分数:5%10=50%) (共 10 题)
实验参考教材:
a) 《Pattern Classification》by Richard O.Duda, Peter E.Hart, David G.Stork, 2nd Edition Wiley-Interscience, 2000. (机械工业出版社,2004 年, 影印版)。 b) 《模式分类》Richard O.Duda, Peter E.Hart, David G.Stork 著;李宏东, 姚天翔等译;机械工业出版社和中信出版社出版,2003 年。(上面 a 的 中文翻译版) c) 《模式识别(英文第四版)》Sergios Theodoridis, Konstantinos Koutroumbas 著;机械工业出版社,2009 年,影印版。 d) 《神经网络与机器学习(原书第三版)》Simon Haykin 著;申富 饶等译,机械工业出版社,2013 年。
裴继红 编
2015 年 2 月 深圳大学 信息工程学院
深圳大学研究生课程“模式识别理论与方法”实验指导书(4th Edition 裴继红编)
模式识别实验报告
二、实验步骤 前提条件: 只考虑第三种情况:如果 di(x) >dj(x) 任意 j≠ i ,则判 x∈ωi 。
○1 、赋初值,分别给 c 个权矢量 wi(1)(i=1,2,…c)赋任意的初
值,选择正常数ρ ,置步数 k=1;
○2 、输入符号未规范化的增广训练模式 xk, xk∈{x1, x2… xN} ,
二、实验步骤
○1 、给出 n 个混合样本,令 I=1,表示迭代运算次数,选取 c
个初始聚合中心 ,j=1,2,…,c;
○2 、 计 算 每 个 样 本 与 聚 合 中 心 的 距 离
,
。
若
, ,则
。
○3 、 计 算 c 个 新 的 聚 合 中 心 :
,
。
○4 、判断:若
,
,则 I=I+1,返回
第二步 b 处,否则结束。 三、程序设计
聚类没有影响。但当 C=2 时,该类别属于正确分类。 而类别数目大于 2 时,初始聚合中心对聚类的影响非常大,仿真
结果多样化,不能作为分类标准。 2、考虑类别数目对聚类的影响: 当类别数目变化时,结果也随之出现变化。 3、总结 综上可知,只有预先分析过样本,确定合适的类别数目,才能对
样本进行正确分类,而初始聚合中心对其没有影响。
8
7
6
5
4
3
2
1
0
0
1
2
3
4
5
6
7
8
9
初始聚合中心为(0,0),(2,2),(5,5),(7,7),(9,9)
K-均 值 聚 类 算 法 : 类 别 数 目 c=5 9
8
7
6
5
4
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
类别1234样本x 1x 2x 1x 2x 1x 2x 1x 210.1 1.17.1 4.2-3.0-2.9-2.0-8.42 6.87.1-1.4-4.30.58.7-8.90.23-3.5-4.1 4.50.0 2.9 2.1-4.2-7.74 2.0 2.7 6.3 1.6-0.1 5.2-8.5-3.25 4.1 2.8 4.2 1.9-4.0 2.2-6.7-4.06 3.1 5.0 1.4-3.2-1.3 3.7-0.5-9.27-0.8-1.3 2.4-4.0-3.4 6.2-5.3-6.780.9 1.2 2.5-6.1-4.1 3.4-8.7-6.49 5.0 6.48.4 3.7-5.1 1.6-7.1-9.710 3.9 4.0 4.1-2.2 1.9 5.1-8.0-6.3实验一 感知器准则算法实验一、实验目的:贝叶斯分类方法是基于后验概率的大小进行分类的方法,有时需要进行概率密度函数的估计,而概率密度函数的估计通常需要大量样本才能进行,随着特征空间维数的增加,这种估计所需要的样本数急剧增加,使计算量大增。
在实际问题中,人们可以不去估计概率密度,而直接通过与样本和类别标号有关的判别函数来直接将未知样本进行分类。
这种思路就是判别函数法,最简单的判别函数是线性判别函数。
采用判别函数法的关键在于利用样本找到判别函数的系数,模式识别课程中的感知器算法是一种求解判别函数系数的有效方法。
本实验的目的是通过编制程序,实现感知器准则算法,并实现线性可分样本的分类。
二、实验内容:实验所用样本数据如表2-1给出(其中每个样本空间(数据)为两维,x 1表示第一维的值、x 2表示第二维的值),编制程序实现1、 2类2、 3类的分类。
分析分类器算法的性能。
2-1 感知器算法实验数据具体要求1、复习感知器算法;2、写出实现批处理感知器算法的程序1)从a=0开始,将你的程序应用在和的训练数据上。
记下收敛的步数。
2)将你的程序应用在和类上,同样记下收敛的步数。
3)试解释它们收敛步数的差别。
3、提高部分:和的前5个点不是线性可分的,请手工构造非线性映射,使这些点在映射后的特征空间中是线性可分的,并对它们训练一个感知器分类器。
分析这个分类器对剩下的(变换后的)点分类效果如何?三、参考例程及其说明:针对、和的分类程序如下:clear%original dataw1=[.1 6.8 -3.5 2.0 4.1 3.1 -0.8 0.9 5.0 3.9; 1.1 7.1 -4.1 2.7 2.8 5.0 -1.3 1.2 6.4 4.0];w2=[7.1 -1.4 4.5 6.3 4.2 1.4 2.4 2.5 8.4 4.1;4.2 -4.3 0.0 1.6 1.9 -3.2 -4.0 -6.1 3.7 -2.2];w3=[-3.0 0.5 2.9 -0.1 -0.4 -1.3 -3.4 1 -5.1 1.9; -2.9 8.7 2.1 5.2 2.2 3.7 6.2 3.4 1.6 5.1];%normalizedww1=[ones(1,size(w1,2)); w1];ww2=[ones(1,size(w2,2)); w2];ww3=[ones(1,size(w3,2)); w3];w12=[ww1,-ww2];y=zeros(1,size(w12,2));a=[1;1;1];k=0;while any(y<=0)for i=1:size(y,2)y(i)=a'*w12(:,i);enda=a+(sum((w12(:,find(y<=0)))'))';k=k+1;endakfigure(1)plot(w1(1,:),w1(2,:),'r.')hold onplot(w2(1,:),w2(2,:),'*')xmin=min(min(w1(1,:)),min(w2(1,:)));xmax=max(max(w1(1,:)),max(w2(1,:)));ymin=min(min(w1(2,:)),min(w2(2,:)));这段程序的作用是什么?ymax=max(max(w1(2,:)),max(w2(2,:)));xindex=xmin-1:(xmax-xmin)/100:xmax+1;yindex=-a(2)*xindex/a(3)-a(1)/a(3);plot(xindex,yindex)w12=[ww2,-ww3];y=zeros(1,size(w12,2));a=[1;1;1];k=0;while any(y<=0)for i=1:size(y,2)y(i)=a'*w12(:,i);enda=a+(sum((w12(:,find(y<=0)))'))';k=k+1;endakfigure(2)plot(w2(1,:),w2(2,:),'r.')hold onplot(w3(1,:),w3(2,:),'*')xmin=min(min(w2(1,:)),min(w3(1,:)));xmax=max(max(w2(1,:)),max(w3(1,:)));xindex=xmin-1:(xmax-xmin)/100:xmax+1;yindex=-a(2)*xindex/a(3)-a(1)/a(3);plot(xindex,yindex)上述程序运行后,可以得到线性分类器如图2-1和图2-2所示。
图2-1感知器训练算法得到、的分类线图2-2感知器训练算法得到、的分类线类别12样本x 1x 2x 3x 1x 2x 31-0.40.580.0890.83 1.6-0.0142-0.310.27-0.04 1.1 1.60.483-0.380.055-0.035-0.44-0.410.324-0.150.530.0110.047-0.45 1.45-0.350.470.0340.280.35 3.160.170.690.1-0.39-0.480.117-0.0110.55-0.180.34-0.0790.148-0.270.610.12-0.3-0.22 2.29-0.0650.490.0012 1.1 1.2-0.4610-0.120.054-0.0630.18-0.11-0.49 类别3样本x 1x 2x 31 1.58 2.32-5.820.67 1.58-4.783 1.04 1.01-3.634-1.49 2.18-3.395-0.41 1.21-4.736 1.39 3.61 2.877 1.2 1.4-1.89思考问题:感知器算法最终得到的权值W 有什么用途?有了权值后如何得到分类面?实验二 Fisher 线性判别实验二、实验要求:1、改写例程,编制用Fisher 线性判别方法对三维数据求最优方向W 的通用函数。
2、对下面表3-1样本数据中的类别ω1和ω2计算最优方向W 。
3、画出最优方向W 的直线,并标记出投影后的点在直线上的位置。
表3-1 Fisher 线性判别实验数据4、选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类。
5、设某新类别3数据如表3-2所示,用自己的函数求新类别3分别和1、2分类的投影方向和分类阈值。
表3-2 新类别样本数据三、参考例程及其说明求取数据分类的Fisher 投影方向的程序如下:其中w 为投8-0.92 1.44-3.22 90.45 1.33-4.38 10-0.760.84-1.96影方向。
clearclcw1=[-0.4,0.58,0.089;-0.31,0.27,-0.04;-0.38,0.055,-0.035;-0.15,0.53,0.011;-0.35,.47,0.034;0.17 w2=[0.83,1.6,-0.014;1.1,1.6,0.48;-0.44,-0.41,0.32;0.047,-0.45,1.4;0.28,0.35,3.1;-0.39,-0.48,0.1 xx1=[-0.7,0.58,0.089];xx2=[0.047,-0.4,1.04];s1= cov(w1,1);m1= mean(w1);s2= cov(w2,1);m2= mean(w2);sw= s1 + s2;w= inv(sw)*(m1-m2)';h1=figure(1)for i=1:10plot3(w1(i,1),w1(i,2),w1(i,3),'r*')hold onplot3(w2(i,1),w2(i,2),w2(i,3),'bo')endy1=w'*w1';y2=w'*w2';figure(2)for i=1:10plot3(y1(i)*w(1),y1(i)*w(2),y1(i)*w(3),'rx')hold onplot3(y2(i)*w(1),y2(i)*w(2),y2(i)*w(3),'bp')end程序运行结果如图3-1和图3-2所示。
图3-1 原始数据分布图图3-2 线性投影后图形思考问题:空间中一点向某方向投影后(可以以二维空间为例体会这个问题),投影点到坐标原点的距离应是多少?图3-2是否为投影后的样本在直线上的位置?若不是,请重新作图,得到该投影直线和位置。