一种改进的多属性模型压缩算法
模型压缩的步骤和流程(Ⅰ)

模型压缩是指通过一系列技术手段,将原有的大规模模型精简为适用于特定场景或设备的小规模模型。
在人工智能领域,模型压缩是非常重要的话题,因为大规模模型往往需要庞大的计算资源和存储空间,不利于在一些资源受限的设备上部署和运行。
本文将从模型压缩的步骤和流程出发,简要介绍模型压缩的相关知识。
首先,模型压缩的步骤可以分为几个关键环节:选择模型、剪枝、量化、蒸馏和微调。
选择模型是指在开始压缩之前,需要明确选定要压缩的原始模型。
剪枝是指通过去除模型中一些冗余的连接或参数,来减小模型的规模。
量化是指将模型中的参数从浮点数转换为定点数或低精度浮点数,以减小模型的存储空间和计算复杂度。
蒸馏是指通过训练一个小模型来近似一个大模型,以达到压缩模型的目的。
微调是指在压缩后的模型上进行一定的调整和优化,以保证模型的性能。
其次,模型压缩的流程一般包括以下几个步骤:首先是数据收集和准备阶段,这一阶段需要收集并准备用于训练和评估模型的数据集。
然后是模型选择和设计阶段,需要选择适合目标任务的模型,并设计相应的压缩策略。
接着是模型训练和评估阶段,这一阶段需要使用准备好的数据集对模型进行训练和评估。
最后是模型压缩和部署阶段,需要对训练好的模型进行压缩,并将压缩后的模型部署到目标设备上。
除了以上的步骤和流程外,模型压缩还涉及到一些关键技术和方法。
例如,剪枝技术有很多种,包括结构剪枝、参数剪枝、通道剪枝等。
量化技术也有很多种,包括对称量化、非对称量化、混合精度量化等。
蒸馏技术也有不同的实现方式,包括知识蒸馏、数据蒸馏、模型蒸馏等。
这些技术和方法在模型压缩的过程中起着至关重要的作用。
总的来说,模型压缩是一个重要且复杂的任务,它涉及到多个步骤和环节,需要综合运用多种技术和方法。
对于人工智能领域的研究者和从业者来说,掌握模型压缩的步骤和流程,了解相关的技术和方法,对于进行模型压缩工作是非常有帮助的。
希望本文对大家有所启发,也希望人工智能领域的研究者和从业者们能够在模型压缩的道路上不断探索和创新,为推动人工智能技术的发展做出更大的贡献。
模型压缩方法

模型压缩方法
模型压缩是指通过降低模型的复杂度和参数量,减小模型的存储和计算资源需求,提高模型的运行效率。
模型压缩方法通常可以分为以下几种:
1. 剪枝:剪枝是一种常见的模型压缩方法,它通过删除一些冗余的连接或神经元来减小模型的规模。
剪枝可以分为结构剪枝和权重剪枝两种方式,其中结构剪枝主要删除冗余的神经元或层,权重剪枝则是删除小于预定义阈值的权重值。
2. 量化:量化是通过降低变量的精度来减少模型大小和计算量。
通常使用的量化方法包括二值化、定点化和浮点数量化等方式。
3. 分组卷积:分组卷积是通过将输入和输出通道分组来降低计算量和参数量。
通常使用的分组卷积方式包括基于深度可分离卷积的分组卷积和基于通道划分的分组卷积。
4. 知识蒸馏:知识蒸馏是通过将一个大型模型的知识传递给一个小型模型来减少模型大小和计算量。
通常使用的知识蒸馏方法包括基于软标签的知识蒸馏和基于模型输出的知识蒸馏。
5. 神经网络压缩:神经网络压缩是一种基于自编码器或变分自编码器的神经网络模型压缩方法。
它通过将模型参数用较少的参数来表示,从而达到压缩模型的目的。
6. 低秩分解:低秩分解是一种通过将卷积层和全连接层的权重分
解成小型的矩阵来减少参数数量的方法。
常见的低秩分解方式包括SVD分解、CP分解和TT分解等。
无损数据压缩算法的历史

⽆损数据压缩算法的历史引⾔有两种基本的压缩算法: 有损和⽆损。
有损压缩算法通过移除在保真情形下须要⼤量的数据去存储的⼩细节,从⽽使⽂件变⼩。
在有损压缩⾥,因某些必要数据的移除。
恢复原⽂件是不可能的。
有损压缩主要⽤来存储图像和⾳频⽂件。
同⼀时候通过移除数据能够达到⼀个⽐較⾼的压缩率,只是本⽂不讨论有损压缩。
⽆损压缩,也使⽂件变⼩,但相应的解压缩功能能够精确的恢复原⽂件,不丢失不论什么数据。
⽆损数据压缩被⼴泛的应⽤于计算机领域,从节省你个⼈电脑的空间。
到通过web发送数据。
使⽤Secure Shell交流,查看PNG或GIF图⽚。
⽆损压缩算法可⾏的基本原理是,随意⼀个⾮随机⽂件都含有反复数据。
这些反复数据能够通过⽤来确定字符或短语出现概率的统计建模技术来压缩。
统计模型能够⽤来为特定的字符或者短语⽣成代码,基于它们出现的频率,配置最短的代码给最经常使⽤的数据。
这些技术包含熵编码(entropy encoding),游程编码(run-length encoding),以及字典压缩。
运⽤这些技术以及其他技术,⼀个8-bit长度的字符或者字符串能够⽤⾮常少的bit来表⽰,从⽽⼤量的反复数据被移除。
历史直到20世纪70年代,数据压缩才在计算机领域開始扮演重要⾓⾊。
那时互联⽹变得更加流⾏,Lempel-Ziv算法被发明出来,但压缩算法在计算机领域之外有着更悠久的历史。
发明于1838年的Morse code。
是最早的数据压缩实例,为英语中最经常使⽤的字母⽐⽅"e"和"t"分配更短的Morse code。
之后。
随着⼤型机的兴起,Claude Shannon和Robert Fano发明了Shannon-Fano编码算法。
他们的算法基于符号(symbol)出现的概率来给符号分配编码(code)。
⼀个符号出现的概率⼤⼩与相应的编码成反⽐,从⽽⽤更短的⽅式来表⽰符号。
两年后,David Huffman在MIT学习信息理论并上了⼀门Robert Fano⽼师的课,Fano给班级的同学两个选项,写⼀篇学期论⽂或者參加期末考试。
一种改进的自动机压缩算法在深度包检测中的应用

1深度 包检 测技 术
当前 日 复杂的安全威胁 中,很多恶意 行为都 隐藏在 数据包中,可能充斥着蠕虫病毒 、垃圾邮件 、 益 漏洞利用等恶意代码 ,在
各种电子商务程序 的 We 数 据中也可能夹带着后 门和木马程序在 网络中传递。所 以, 网络应用和网络威胁都高速增长的今天 , b 在 仅仅依照数据包 网络层信息的安全检测技术 ,已经无法满足信息安全 的要求。
2传统算法存在的 问题
图 1 深 度 包 检 测
传统 的基于 自动机的深度包 检测算法,将给定的正则表达式集合 中的所有正 则表 达式构造成一 个 D A F 。理论上,此方 法可
以达到最好的运算时间。然而多个正则表达式对应一 个 D A的状态数要远远 大于一个正则表达式对应一个 D A状态 数的总和。 F F
引入了 D A膨胀率之后我们就可 以正式进入我们的算法。 F
本算法 的 目的是在有 限运算空间内尽快 的增 大 DF A的运算速 度。 即,在允许 的 内存 范围 内,尽量 把多个正 则表 达式 组合
针对这种问题 ,本文 提出了一种构造最 优 DF A状态数 压 缩 法,该算 法 保证 在有 限 的运算 空间 下,时间复 杂度 最 小。 DF A所 占据的运算空 间的大小 ,取决 于状 态的数量 和每 个状 态 的转换的数量的乘积。为了表述方便 , 面运算空间 ( 下 内存 )
同的状态来 区分歧 义 ,从 而状 态数增 多。图 1 中,RE 、RE 2 3 和 R 4的识 别能 力依 次变 强且 都存在 歧 义匹配 ,其 D A状 E F 态数依次增多。 我们 引用一 个 D A膨胀率 的概 念,用来表 述 N A转化 F F
情况下系统会使用虚拟 内存 作为补充 ,但是虚拟内存是操作系
模型压缩:量化、剪枝和蒸馏
模型压缩:量化、剪枝和蒸馏导读:近年来,BERT 系列模型成了应用最广的预训练语言模型,随着模型性能的提升,其参数规模不断增大,推理速度也急剧提升,导致原始模型必须部署在高端的GPU 显卡上,甚至部分模型需要多块显卡才能正常运行。
在移动智能终端品类越发多样的时代,为了让预训练语言模型可以顺利部署在算力和存储空间都受限的移动终端,对预训练语言模型的压缩是必不可少的。
本文将介绍针对BERT(以Transformer Block 堆叠而成的深度模型)的压缩方法。
01BERT模型分析想要深度压缩BERT,必须对模型各部分有更为深入的了解,前面的章节已经详细介绍过Transformer 和BERT 的结构,此处不再解释各模块的具体功能。
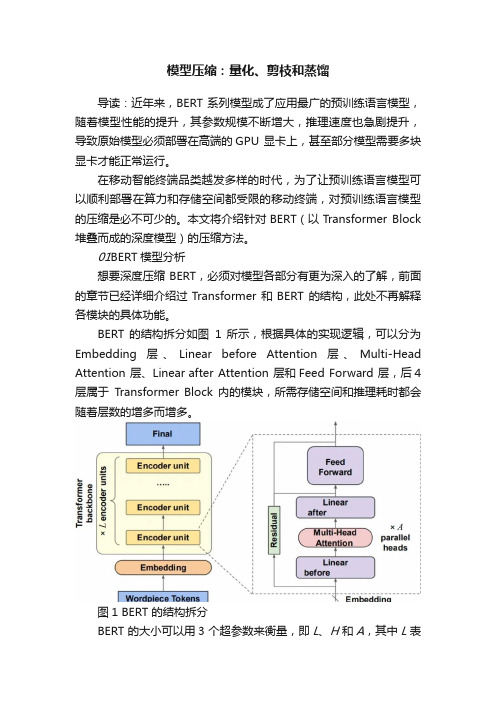
BERT 的结构拆分如图1 所示,根据具体的实现逻辑,可以分为Embedding 层、Linear before Attention 层、Multi-Head Attention 层、Linear after Attention 层和Feed Forward 层,后4 层属于Transformer Block 内的模块,所需存储空间和推理耗时都会随着层数的增多而增多。
图1 BERT 的结构拆分BERT 的大小可以用3 个超参数来衡量,即L、H和A,其中L表示Transformer Block 的层数,H表示隐层向量的维数(等于Embedding 层输出向量的维数),A 表示Self-Attention 层的头数。
通过这3 个超参数,可以基本知晓BERT 的各模块大小,L 和H 决定了模型的宽度和深度,A决定了模型Attention 的多样性。
以为例分析3 个超参数,其中L为12,H为768,A为12,模型各层所占存储空间和算力,如图2所示。
图2 BERTBASE 各层所占存储空间和算力显然,在数据存储空间方面,Feed Forward 层占据了约一半的空间,Embedding层和Linear before Attention 层分别占据约四分之一的空间,而最核心的Multi-Head Attention 层几乎不占存储空间,这里所谓的存储空间可以等效为模型参数的数量。
一种改进的压缩频繁模式挖掘算法

基 金项 目: 四川 省 教 育 厅 科 研 资 助 项 目( ¨Z B 2 1 9 ) .
作 者 简介 :赖
性, 该 集 合 中最长 的模式 被称 为 闭频 繁模式 .S中 的其 他模 式 均 为该 最 长 的模 式 的子 集 ,具 有这 个 性 质 的
模 式 被认 为能 代表 s集 合所 有 的频繁模 式 .该 算法 在一 定程度 上缩 小 了频繁 模 式挖 掘结 果 集合 的规模 , 但
①
收稿 日期 :2 0 1 3— 0 1 —1 3
如果 模式 X 的支持 度 的大 小 超 过 了用 户 事 先 设 置 的 最 小 支 持 度 mi n — s u p 的 大小 ,那 么 模 式 X 就 是 频 繁 模式 . 频繁模 式 有个 属性 ,即如果模 式 X 是频 繁模 式 , 那 么 组成它 的项 构成 的任 意子 集形成 的模 式 y也是 频
2 0 1 3年 7月
J u 1 . 2 0 1 3
文章编号0 0 9 3— 0 7
一
种 改进 的压 缩频 繁模 式 挖 掘 算 法①
赖 娟 , 金 澎 , 洪 艳 伟
1 .乐 山师 范 学 院 智 能 信 息 处 理 及 应 用 实 验 室 , 四J l I 乐山 6 1 4 0 0 0 ; 2 . 乐 山 师范 学 院 计 算 机 科 学 学 院 ,四川 乐 山 6 1 4 0 0 0
来 ,国内一些 学者 也在 该领 域有 了初 步进 展l _ 4 ] . 早在 1 9 9 3 年 Ag r a wa l 等l 9 ] 就 提 出了该 问题 , 频 繁模式 挖掘 通 常是基 于一个 事务 集合 D一 { t l , t l ,… ,
t n} ,其 中事 务 t j是构 成事 务集 合 D 的一个 项 的集合 , J∈ [ 1 , ” ] .项 的集 合 一 { 以, 2 , …, } , 其 中模
一种改进的无线多媒体传感器网络分布式图像压缩算法

近 年来 , 重叠 变换 技 术 在 WMS s图像 压 缩 中 的应 N 用受 到越 来越 多 的关 注 , 文 献 『 — ] 出 的 图像 如 78提 压 缩算 法均通 过节 点 间共 享任 务处 理进 程来解 决单 个 节点计 算 、 储 能力 以及能 量受 限 的问题 。 存
像 压缩 效率 的关键 。
( I A) a poe g o pes nagrh ae ni-ls r ir ue rcsig I D )s rp sdi D C ,ni rvd i ecm rs o l i m b sdo cut s i t poes (C P i pooe m ma i ot n e d tb d n n
案如 图 1 所示 。
较 高 , 法往 往需 要 将 多级 小 波 变 换 的计 算 量 分 布 算 到多个 节点 中去 完成 , 而平 衡节 点能耗 . 分布式 从 但 处 理需 要节 点 间进行 数 据 交 换 . 在 一定 程 度 上 增 这
加 了节 点 能耗 , 因此 如 何设 计 一 个 有效 的分 布 式 处 理机 制 是 这 类 算 法 需 要 着 重 考 虑 的 问 题 。文 献 [ 2 提 出了 一 种典 型 的无 线 多 媒 体 传 感 器 网络 分 1]
r s u c — o sr i e MS t i h n de e st e o r e c n ta n d W Nswi h g o s d n i h y.
模型压缩的方法

模型压缩的方法
模型压缩指对于深度神经网络进行优化,减少其所需的计算资源和存储空间,使之能够在有限的硬件设备上运行和部署。
常用的模型压缩方法包括:
1. 参数下降:通过去除模型中冗余和不必要的参数,减少模型的大小和复杂度,较少计算量和存储光盘使用。
2. 知识蒸馏:将一个较为复杂的大模型所学习到的知识,通过训练一个较为简单的小模型来迁移,从而使得小型模型在满足一定精度要求的同时具有更高的计算效率。
3. 剪枝:通过去除一定数量的无用连接,来降低网络中的参数量和计算量。
剪枝方法包括结构剪枝、按照通道剪枝和按照元素剪枝等。
4. 量化:将网络中的参数和激活值从浮点数转换为定点数和整数,从而减少存储和计算量。
量化主要包括定点量化和二值量化。
5. 分享权重:将多个子网络的权重共享,从而减少网络的参数量和计算量。
以上是常见的模型压缩方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
An I pr v d Su f c i p i c to g rt m o e r a e S m lf a i n Al o ihm i wih u t— t i e t M li— rbuts At
t a h e a g rt m o l v r o o e s o to n s a d be i e r d c d b t r i tg ai n o sse c o h tt e n w o h l i c u d o e c me t s h rc mi g n sd s p o u e e t n e r l y a d c n it n y c mp rn t r d - h e t a g wi t i i h a t n la g rt ms i a l o i o h .
1 背 景 介 绍
随着各 际模型简化 中的效果 , 现其 在应用 中存在 一定 发
的不足 ; 主要体现在拟 合的新 生成 点的几何 坐标 可能 存在较大的视觉误差 , 这个 问题将 在第三节 进行详 细
F NG Q n N u- i g L i - i E i , IG iqa , UO J n xn n a
(ntueo o Is tt f mmadAuo t n P A U i ri fSine& T cn lg , nig2 00 , hn ) i C n tma o 。L nv syo c c i e t e ehoo y Naj 10 7 C ia n
冯 钦 , 桂 强 , 倪 罗健 欣
( 解放 军X _ 大学 指 挥 自动化 学院 , 苏 南京 20 0 ) z - 江 107
摘
要: 传统 的压 缩算法 在实 际模 型 L 应用 时经 常 出现“ 洞 ” 面重 叠等 问题 , 过 在 . 、oj.d、m x等模 型 实例 上 空 和 通 x.b、3 s. a
Ke r s s ra e s l c t n; u d c e r rme rc ; l - t b t s p o r si e me h y wo d : u c i i ai q a r ro t s mu t a t u e ; r g e sv s f mp f i o i i i i r
第2 2卷
第 4期
计 算 机 技 术 与 发 展
C 0MP ER ECHNOI UF T OGY AND DEVEL MENT OP
21 0 2年 4月
V0 . 2 N . 12 o 4 Apr . 2 2 01
一
种 改进 的 多属 性 模 型压 缩 算 法
Absr c : p y n r d t n la g r h i e lmo es o t n l a s t o r b e u h a a e v ra s a d“h ls . o n i S t a t Ap l i g ta i o a o t m n r a d l f d o s me p o l mss c s f c so e lp n i l i e e o e ” F u d t sWa h b c u e o o e g o t c l i l r p i t i h o tn r s td i o g p st n u n i l c t n h n p o o e a n w l o e a s ft s e me r a l smi o n s wh c fe e ul n wr n o i o s d r g smp i a o .T e r p s e ag — h i y a e i i i f i r m. i g rt m e r h s g o t c ly smia o n sb e wa fp ri o i g s a e wi c o ay te t e u l e h s s o i h t h T sa o h l i s ac e e me r al i l p i t y t y o a t i n n p c t o t n r r e, n p ta mp a e n i r h t h h l h s e t o e g omerc l i l o n s a d man a n t e rg o ti o t u t u n i l c t n fo s me s a e i s E p r n ss o d tia l smia p i t n i t i h i e me r c n n i d r g smp i ai r m o t tg e . x e me t h we y r c i y i i f o r i
实 验发 现 , 出现 L述 题 的主要 原 因在 于 几何相 似 点 , 些 点 在压 缩 过程 中 出现 了偏 差 。文 中提 出了 ~种 改 进 的压 缩 算 1 这
法 , 法 首先利 用八 叉树 切分 空间 确定 几何 相似 点 , 后针对 几何 相似 点采 用 一系 列 策略 , 它们 在 压缩 过程 中仍然 保 该算 然 使 持 良好的几 何连 续性 。对 比实验 表 明 , 法不 仅 能 克服 传统 算法 出现 的 问题 , 能更 好地 保持模 型 的整体 性与 连贯性 。 该算 还