多元统计分析作业一第三题.doc
多元统计分析课后练习答案

第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。
《多元统计分析》习题

《多元统计分析》习题分为三部分:思考题、验证题和论文题思考题第一章绪论1﹑什么是多元统计分析?2﹑多元统计分析能解决哪些类型的实际问题?第二章聚类分析1﹑简述系统聚类法的基本思路。
2﹑写出样品间相关系数公式。
3﹑常用的距离及相似系数有哪些?它们各有什么特点?4﹑利用谱系图分类应注意哪些问题?5﹑在SAS和SPSS中如何实现系统聚类分析?第三章判别分析1﹑简述距离判别法的基本思路,图示其几何意义。
2﹑判别分析与聚类分析有何异同?3﹑简述贝叶斯判别的基本思路。
4﹑简述费歇判别的基本思路。
5﹑简述逐步判别法的基本思想。
6﹑在SAS和SPSS软件中如何实现判别分析?第四章主成分分析1﹑主成分分析的几何意义是什么?2﹑主成分分析的主要作用有那些?3﹑什么是贡献率和累计贡献率,其意义何在?4﹑为什么说贡献率和累计贡献率能反映主成分中所包含的原始变量的信息?5﹑为什么要用标准化数据去估计V的特征向量与特征值?6﹑证明:对于标准化数据有S=R。
7﹑主成分分析在SAS和SPSS中如何实现?第五章因子分析1﹑因子得分模型与主成分分析模型有何不同?2﹑因子载荷阵的统计意义是什么?3﹑方差旋转的目的是什么?4﹑因子分析有何作用?5﹑因子模型与回归模型有何不同?6﹑在SAS和SPSS中如何实现因子分析?第六章对应分析1﹑简述对应分析的基本思想。
2﹑简述对应分析的基本原理。
3﹑简述因子分析中Q型与R 型的对应关系。
4﹑对应分析如何在SAS和SPSS中实现?第七章典型相关分析1﹑典型相关分析适合分析何种类型的数据?2﹑简述典型相关分析的基本思想。
3﹑典型变量有哪些性质?4﹑典型相关系数和典型变量有何意义?5﹑典型相关分析有何作用?6 ﹑在SAS和SPSS中如何实现典型相关分析?验证题第二章聚类分析1、为了更深入了解我国人口的文化程度,现利用1990年全国人口普查数据对全国30个省、直辖市、自治区进行聚类分析。
分析选用了三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ);(2)初中文化程度的人都占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ),分别用来反映较高、中等、较低文化程度人口的状况。
多元统计分析作业1
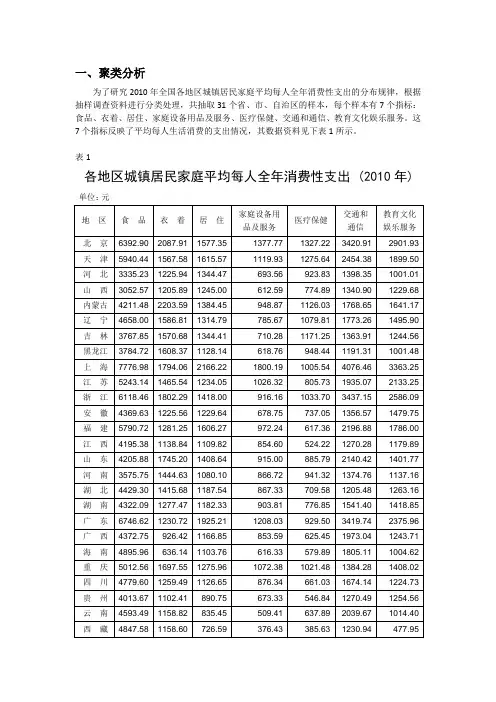
一、聚类分析为了研究2010年全国各地区城镇居民家庭平均每人全年消费性支出的分布规律,根据抽样调查资料进行分类处理,共抽取31个省、市、自治区的样本,每个样本有7个指标:食品、衣着、居住、家庭设备用品及服务、医疗保健、交通和通信、教育文化娱乐服务。
这7个指标反映了平均每人生活消费的支出情况,其数据资料见下表1所示。
表1定义变量及标签:设:X1:地区X2:食品支出X3:衣着支出X4:居住支出X5:家庭设备用品及服务支出X6:医疗保健支出X7:交通和通信支出X8:教育文化娱乐服务支出通过SPSS软件操作,得到如下输出结果见表2—表5所示。
表2表3表4表4给出了聚类的凝聚过程情况。
表5给出了样品聚为三类时的样品归类情况。
C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+甘肃 28 -+青海 29 -+新疆 31 -+河北 3 -+---+山西 4 -+ |河南 16 -+ |宁夏 30 -+ |黑龙江 8 -+ +-------+陕西 27 -+ | |云南 25 -+-+ | |西藏 26 -+ | | |广西 20 -+ +-+ |海南 21 -+ | |江西 14 -+-+ |贵州 24 -+ +-----------------------------------+ 湖北 17 -+ | | 湖南 18 -+ | | 四川 23 -+ | | 安徽 12 -+ | | 江苏 10 -+-+ | | 福建 13 -+ | | | 辽宁 6 -+ +---------+ | 吉林 7 -+ | | 山东 15 -+-+ | 重庆 22 -+ | 内蒙古 5 -+ | 天津 2 -+ | 浙江 11 -+-+ | 北京 1 -+ +-+ | 广东 19 ---+ +-------------------------------------------+ 上海 9 -----+图1图1是聚类全过程的树形图。
应用多元统计分析试题及答案

一、填空题:1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法.2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著.3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为 Q型聚类和 R型聚类。
4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。
5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。
6、若()(,), Px N αμα∑=1,2,3….n且相互独立,则样本均值向量x服从的分布为_x~N(μ,Σ/n)_。
二、简答1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。
在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。
选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
2、简述相应分析的基本思想。
相应分析,是指对两个定性变量的多种水平进行分析。
设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。
对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。
要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。
相应分析即是通过列联表的转换,使得因素 A 和因素B具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。
把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A、B的联系。
3、简述费希尔判别法的基本思想。
从k个总体中抽取具有p个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数系数:确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。
将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。
多元统计分析第三版课后练习题含答案

多元统计分析第三版课后练习题含答案1. 组间差异比较题目有两组数据,分别为A组和B组,经过检验发现两组数据的方差不相等,则应该使用那种方法进行比较?答案当两组数据的方差不相等时,应该使用Welch’s t检验方法进行比较,而不是常规的Student’s t检验方法。
2. 主成分分析题目主成分分析(PCA)是一种常用的数据降维方法。
在PCA分析中,如何选择主成分的个数?答案选择主成分的个数要根据实际情况而定。
一般来说,我们可以参考数据的累计方差贡献率,将累计贡献率大于80%的主成分选出来作为数据的主要特征,进而进行后续的数据分析处理。
3. 线性回归模型题目在线性回归模型中,如何衡量模型的拟合程度?答案模型的拟合程度可以通过R方(R-squared)值来衡量。
R方值越接近1,说明模型越拟合数据,反之则说明拟合程度不高。
但需要注意的是,仅仅使用R方值来衡量一个模型的好坏还不够,也需要考虑其它因素的影响,如是否存在共线性等问题。
4. 混淆矩阵题目什么是混淆矩阵(Confusion Matrix)?在分类问题中,混淆矩阵的作用是什么?答案混淆矩阵是用来评估分类模型的准确度,它可以将分类问题的结果与实际结果进行比较分析。
一般来说,混淆矩阵包含4个参数:真阳性(True Positive, TP)、假阳性(False Positive, FP)、真阴性(True Negative, TN)和假阴性(False Negative, FN)。
在分类问题中,混淆矩阵的作用主要有以下三个:1.衡量模型的质量。
通过混淆矩阵,我们可以计算出分类模型的准确率、精度、召回率等指标来评估模型的质量。
2.选择模型的阈值。
分类模型的阈值是指将不同的样本劃分到不同的分类中的界限值。
通过混淆矩阵,我们可以选择不同的阈值,以获得更好的模型表现。
3.确定模型需要改进的方面。
通过混淆矩阵,我们可以识别出模型中需要改进的方面,从而进一步优化模型。
多元统计分析试卷答案

课程名称: 多元统计分析 试卷类型: 答案 考试形式:开 授课专业: 数学与应用数学题号 一二三总分得分 阅卷人一、 填空题:(每空2分,共30分)1、设(1)(2)(,)p N ⎡⎤=⎢⎥⎣⎦:X X μX ∑(2)p ≥,(1)(2)⎡⎤=⎢⎥⎣⎦μμμ,11122122⎡⎤=⎢⎥⎣⎦∑∑∑∑∑,其中(1)X ,(1)μ为1r ⨯,11∑为r r ⨯,则(1):X (1)11(,)r N μ∑,(2):X (2)22(,)p r N -μ∑2、系统聚类分析的方法很多,其中的五种分别为最短距离法、最长距离法、重心法、类平均法、离差平方和法。
3、若p 维随机向量~(,)p X N μ∑,~(,)p W W n ∑,且X 与W 相互独立,则1()()~n X W X μμ-'--2(,)T p n ,21(,)~n p T p n pn-+(,1)F p n p -+。
4、i X 与前个主成分的全相关系数的平方和21(,)mk i k Y X ρ=∑称为12,,,m Y Y Y L 对原始变量i X 的方差贡献率,在因子分析中也称之为共同度。
5、Q 型因子分析研究样品之间的相关关系,R 型因子分析研究变量之间的相关关系。
6、Fisher 判别法的基本思想是投影,并利用方差分析的思想来导出判别函数。
二、 判断题(每题2分,共10分)1、( √ )随机向量12(,,,)p X X X 'L 的协方差阵()D X =∑是对称非负定阵。
2、( × )因子载荷矩阵A 是对称阵。
3、( × )聚类分析中快速聚类法指的就是模糊聚类法。
4、( √ )设(,)p N :X μ∑,(,)p W n :W ∑,且X 与W 相互独立,则12()()(,)n T p n -':X μW X μ--。
5、( × )主成分分析中,从相关矩阵出发求解的主成分一定会比从协方差矩阵出发求解的主成分更可信。
多元统计分析
多元统计分析多元统计分析习题集(⼀)⼀、填空题1.若()(,),(1,2,,)p X N n αµα∑= 且相互独⽴,则样本均值向量X 服从的分布是____________________。
2.变量的类型按尺度划分为___________、____________、_____________。
3.判别分析是判别样品_____________的⼀种⽅法,常⽤的判别⽅法有_____________、_____________、_____________、_____________。
4.Q 型聚类是指对_____________进⾏聚类,R 型聚类指对_____________进⾏聚类。
5.设样品12(,,,),(1,2,,)i i i ip X X X X i n '== ,总体(,)p X N µ∑ ,对样品进⾏分类常⽤的距离有____________________、____________________、____________________。
6.因⼦分析中因⼦载荷系数ij a 的统计意义是_________________________________。
7.主成分分析中的因⼦负荷ij a 的统计意义是________________________________。
8.对应分析是将__________________和__________________结合起来进⾏的统计分析⽅法。
9.典型相关分析是研究__________________________的⼀种多元统计分析⽅法。
⼆、计算题 1.设3(,)X N µ∑ ,其中410130002?? ?∑= ? ??,问1X 与2X 是否独⽴?12(,)X X '与3X 是否独⽴?为什么?2.设抽了5个样品,每个样品只测了⼀个指标,它们分别是1,2,4.5,6,8。
若样品间采⽤绝对值距离,试⽤最长距离法对其进⾏分类,要求给出聚类图。
多元统计分析课后练习答案.doc
第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。
多元统计分析方法练习题
附录B习题第一章1- 1设20~60岁的男子大脑莹量与头颅长度(Y, cm)服从二元正态分布.已知X与Y的相关系数为;X的均数和标准差分别为:和。
试写出X与Y的二元正态分布函数。
并绘制二元正态分布的正态曲面。
1- 2已知成年女子的胸围、腰围和臀围服从三元正态分布,均数分别为:,八协方差矩阵为:‘30.530、25.536 39.859J9.532 20.703 27.363,试写出相应的三元正态分布函数。
1- 3证明,若变量心花服从二元正态分布MN(从 of;心 b;; p),对州內作线性变换:则Z],®亦服从二元正态分布。
并分别求出乙]也2的均数.方差及石与6的相关系数。
1-4就例资料,图示二元分布的90%参考值范囲。
1-5设S和R分别是随机向量X的方差-协方差矩阵和相关系数矩阵,证明:|S|二佝込2…%)岡.第二幸2-1对20名健康女性的汗水进行测量和化脸,数据如下,其中.Xi为排汗董,X2为汗水中钾的含量,X3为汗水中钠的含量。
试检验,样本是否来自Uo‘ =(4,50,10)的总体。
试验者X, X2X3试验者Xi <2 X31・ 2.3. 4.5. 6.7. 8・9. 10.11. 12.13. 14.15. 16.17. 18.19.20.资料来濂:王学仁.王松桂.《实用多元统计分析》,上海科学技术出版社.1232- 2以两均向量比较为例,证明,队数据阵作线性变换,不改变假设检验的结果。
2-3脸证:当m=1时,Hotel I ing T?检验与t检验等价。
状况有无差别。
男生女生编号编号身高体重胸国身高体莹胸国1 12 23 34 45 56 67 78 89 910 101112为了解某溶栓药对脑梗塞患者血压的影响,观察10名患者,分别与疗前、溶后5分钟、10 分钟.20分钟测定患者的收缩压(X,mmHg)和舒张压(Y,mniHg),结果如下表,问该溶栓药对血压有无影响?1 175 115 175 110 170 110 170 902 136 93 130 90 135 95 135 973 142 89 138 99 138 99 142 1084 180 100 180 100 180 100 180 905 170 90 170 80 180 70 170 706 125 70 114 67 111 64 112 687 140 100 140 90 140 90 140 908 150 70 144 81 166 87 151 919 150 98 150 98 150 98 143 8310 105 75 113 75 113 75 113 75许料来源:陈清棠,九五攻关项目。
《应用多元统计分析》各章作业题及部分参考答案
60.6
16.5
2 76
58.1
12.5
3 92
63.2
14.5
4 81
59.0
14.0
5 81
60.8
15.5
6 84
59.5
14.0
解:作如下假设 H0 : μ = μ0 , H1 : μ ≠ μ0
经计算,求的样本均值向量 x = (82.0, 60.2,14.5) ' ,x − μ0 = (−8, 2.2, −1.5) ' ,样本协差阵
x2
+
1 2
x3
+
1 2
x4 。
(2)第一主成分的贡献率为
λ1
+
λ2
λ1 +
λ3
+ λ4
= 1+ 3ρ 4
≥ 95% ,得 ρ
≥ 0.933 。
第 7 章 因子分析
1、设 x = (x1, x2 , x3 )′ 的相关系数矩阵通过因子分析分解为
⎛ ⎜
1
⎜
R
=
⎜ ⎜
−1 3
⎜ ⎜⎜⎝
2 3
−1 3 1
54.58
11.67
产品净值率 10.7
6.2
21.41
11.67
7.90
2、 设 G1, G2 , G3 三个组,欲判别某样品 x0 属于何组,已知 p1 = 0.05, p2 = 0.65, p3 = 0.3,
应用多元统计分析
pofeel@
3
f1 (x0 ) = 0.10, f2 (x0 ) = 0.63, f3 (x0 ) = 2.4 ,假定误判代价矩阵为:
⎢⎣ 4.5 ⎥⎦
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4.029b
5.000
4.000
.101
Roy的最大根
5.037
4.029b
5.000
4.000
.101
a.设计:截距+分类
b.精确统计量
上面第一张表是样本数据分别来自边远及少数民族聚居区社会经济发展水平、全国的个数。第二张表是多变量检验表,该表给出了几个统计量。由Sig.值可以看到,无论从哪个统计量来看,两个分类的经济发展水平是无显著差别的。实际上,GLM模型是拟合了下面的模型:
边远及少数民族聚居区社会经济发展水平的指标数据
地区
人均GDP(元)
三产比重(%)
人均消费(元)
人口增长(%)
文盲半文盲(%)
内蒙古
5068
31.1
2141
8.23
15.83
广西
4076
34.2
2040
9.01
13.32
贵州
2342
29.8
1551
14.26
28.98
云南
4355
31.3
2059
12.1
式中
(人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲)
分类
上面多变量检验表实际上是对该线性模型显著性的检验,此处有常数项 是因为不能肯定模型过原点。而模型没有通过显著性检验,意味着分类中的不同取值对Y的取值无显著影响,也就是说,不同分类的经济发展水平是相同的。
但是,在实际中,我们往往更希望知道差别主要来自哪些分类,或者不同分类经济发展水平的比较。对此,对GLM模块的选项作如下设置:在GLM主对话框中点击Contrasts…按钮进入Contrasts对话框,在Change Contrasts框架中打开Contrasts右侧的下拉框并选择Simple,此时下侧的Reference Category被激活,默认是Last被选中,表明边远及少数民族聚居区社会经济发展水平与全国平均发展水平作比较,点击Change按钮,Continue继续,OK进行,得到如下结果(见输出结果1-3)
.145
9
.200*
.925
9
.437
人均消费
.209
9
.200*
.873
9
.131
人口增长
.150
9
.200*
.949
9
.682
文盲半文盲
.246
9
.124
.898
9
.242
*.这是真实显著水平的下限。
a. Lilliefors显著水平修正
上表给出了对每一个变量进行正态性检验的结果,因为该例中样本数n=9,所以此处选用Shapiro-Wilk统计量。则Sig.值分别为0.781、0.437、0.131、0.682、0.242均大于显著性水平,由此可以知道,人均GDP、三产比重、人均消费、人口增长、文盲半文盲这五个变量组成的向量均服从正态分布,即我们认为这五个指标可以较好对各地区社会经济发展水平做出近似的度量。
五项指标的全国平均水平为:
3.实验步骤及结果:
解:(1)先利用SPSS软件检验各变量是否遵从多元正态分布(见输出结果1-1)
输出结果1-1
正态性检验
Kolmogorov-Smirnova
Shapiro-Wilk
统计量
Df
Sig.
统计量
df
Sig.
人均GDP
.219
9
.200*
.958
9
.781
三产比重
课 程 名 称:多元统计回归分析
实 验 项 目:边远及少数民族聚居区和会经济发展水平
实 验 类 型:验证性
学 生 学 号:
学 生 姓 名:
学 生 班 级:
课 程 教 师:
实 验 日 期:2016-03-28
1.实验目的:
利用spss软件验证一下边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异。
输出结果1-3
对比结果(K矩阵)
分类简单对比a
因变量
人均GDP
三产比重
人均消费
人口增长
文盲半文盲
级别1和级别2
对比估算值
-2003.232
2.274
-1006.111
2.712
12.014
假设值
0
0
0
0
0
差分(估计-假设)
-2003.232
2.274
-1006.111
2.712
12.014
标准误差
1129.265
Hotelling的跟踪
102.482
81.986b
5.000
4.000
.000
Roy的最大根
102.482
81.986b
5.000
4.000
.000
分类
Pillai的跟踪
.834
4.029b
5.000
4.000
.101
Wilks的Lambda
.166
4.029b
5.000
4.000
.101
Hotelling的跟踪
4.g.
.114
.656
.035
.355
.466
差分的95%置信区间
下限
-4607.321
-9.053
-1918.967
-3.655
-24.162
上限
600.857
13.602
(2)提出原假设及备选假设
(3)做出统计判断,最后对统计判断作出具体的解释
SPSS的GLM模块可以完成多元正态分布有关均值与方差的检验。依次点选Analyze General Linear Mode lMultivariate……进入Multivariate对话框,将人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口等这五项指标选入Dependent列表框,将分类指标选入Fixed Factor(s)框,点击OK运行,则可以得到如下结果(见输出结果1-2)。
2.实验内容:
现选取内蒙古、广西、贵州、云南、西藏、宁夏、新疆、甘肃和青海等9个内陆边远省区。选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口等五项能够较好的说明各地区社会经济发展水平的指标,验证一下边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异。
输出结果1-2
主体间因子
值标签
N
分类
1.00
边远及少数民族聚居区社会经济发展水平
9
2.00
全国经济平均发展水平
1
多变量检验a
效应
值
F
假设df
误差df
Sig.
截距
Pillai的跟踪
.990
81.986b
5.000
4.000
.000
Wilks的Lambda
.010
81.986b
5.000
4.000
.000
25.48
西藏
3716
43.5
1551
15.9
57.97
宁夏
4270
37.3
1947
13.08
25.56
新疆
6229
35.4
2745
12.81
11.44
甘肃
3456
32.8
1612
10.04
28.65
青海
4367
40.9
2047
14.48
42.92
资料来源:《中国统计年鉴(1998)》,北京,中国统计出版社,1998。