第7章 图B
第7章图像处理 课后答案

7.1.1 图像金字塔
一系列以金字塔形状排列的分辨率逐步降低的图集合。 金字塔的底部是待处理图像的高分辨率表示,而顶部 是低分辨率的近似。基级J的尺寸是2J×2J或N×N (J=log2N), 中间级j的尺寸是2j×2j ,其中0<= j <=J。
图7.2b表示,各级的近似值和预测残差金字塔都是以 一种迭代的方式进行计算的。第一次迭代和传递时, j = J ,并且2J×2J的原始图像作为J级的输入图像,从 而产生J-1级近似值和J级预测残差,而J-1级近似值又 作为下一次迭代的输入,得到J-2级近似值和J-1级预 测残差。 迭代算法:
1, 0 x 0.5 ψ( x) 1, 0.5 x 1 0,在,有了尺度函数和小波函数,可以正式定义小 波变换了,它包括:一般小波序列展开、离散小波 变换和连续小波变换。
7.3.1 小波序列展开
首先根据小波函数ψ( x)和尺度函数 ( x)为函数f(x)定 义小波序列展开:
高斯近似值和预测残差金字塔
基级,第9级
第8级 第7级 第6级
图像重建
7.1.2 子带编码
另一种与多分辨率分析相关的重要图像技术是子带 编码。在子带编码中,一幅图像被分解成为一系列 限带分量的集合,称为子带,它们可以重组在一起 无失真地重建原始图像。最初是为语音(一维信号) 和图像压缩而研制的,每个子带通过对输入进行带 通滤波而得到(相当于分解一个频段为若干个子频 段)。因为得到的子带的带宽要比原始图像的带宽 小,子带可以无信息损失的抽样。 原始图像的重建可以通过内插、滤波和叠加单个子 带来完成。
k
V Spk an{k ( x)}
7.2.2 尺度函数
现在来考虑由整数平移和实数二值尺度、平方可积 函数 ( x) 组成的展开函数集合,即集合{ j ,k ( x)} : j/2 j j ,k ( x) 2 (2 x k ) 式7.2.10 k决定了 j ,k ( x)在x轴的位置(平移k个单位),j决定 了 j ,k ( x) 的宽度,即沿x轴的宽或窄的程度,而2j/2 控制其高度或幅度。由于 j ,k ( x)的形状随j发生变化, ( x) 被称为尺度函数。 如果为赋予一个定值,即j = j0,展开集合 { j0 ,k ( x)} 将是 { j ,k ( x)}的一个子集,一个子空间:
第7章 图-有向无环图

算法的执行步骤: 算法的执行步骤: 1、用一个数组记录每个结点的入度。将入度为零的 、用一个数组记录每个结点的入度。 结点进栈。 结点进栈。 2、将栈中入度为零的结点V输出。 、将栈中入度为零的结点 输出 输出。 3、根据邻接表找到结点 的所有的邻接结点, 并将 、根据邻接表找到结点V的所有的邻接结点 的所有的邻接结点, 这些邻接结点的入度减一。 这些邻接结点的入度减一 。 如果某一结点的入度变 为零,则进栈。 为零,则进栈。
3
2
3、找到全为零的第 k 列,输出 k 、 4、将第 k 行的全部元素置为零 、 行的全部元素置为零
…………………
7
53、4;直至所有元素输出完毕。 、 ;直至所有元素输出完毕。
1 2 3 4 5 6 7
0 1 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0
template<class T> int BinaryTree <T>:: NumOfOne ( node <T> *t )
{ int k=0; if (t==NULL ) //空二叉树 //空二叉树 return 0; if (t所指结点 的度为 k=1 所指结点 的度为1) k=1; d1= NumOfOne ( t->lchild); //递归求左子树叶结点数 //递归求左子树叶结点数 d2= NumOfOne ( t->rchild); } //递归求右子树叶结点数 //递归求右子树叶结点数 return (d1+d2+k);
A B
AOE网络:结点为事件,有向边指向表示事件的执行次序。 网络:结点为事件,有向边指向表示事件的执行次序。 网络 有向边定义为活动,边的权值为活动进行所需要的时间。 有向边定义为活动,边的权值为活动进行所需要的时间。
第7章电路

型号:JLXK、 LX19等系列 类型:
按钮式 旋转式 单轮旋转式 双轮旋转式
外形图:
行程开关
(a) 按钮; (b) 单轮旋转式; (c) 双轮旋转式
第7章 继电-接触器控制
1-弹簧;
7.自动开关(又称自动空气短路器)
特点:刀开关、 熔断器、热继电器和欠电
压继电器的组合。在电路中能起到欠压、失 压、过载、短路保护的作用.既能自动控制, 也能手动控制.
开启式负荷开关
封闭式负荷开关
2)封闭式负荷开关(又称铁壳开关)
特点:内装有速断弹簧,使闸刀快速接通和断开,以消除电弧 还设有联锁装置,即在闸刀闭合状态时,开关盖不能开启,以 保证安全。 型号: HH10、 HH11 系列。 外形图:
第7章 继电-接触器控制
3)组合开关(又转换开关)
特点:刀片(动触片)是转动的,能组成 各种不同的线路,动触片装在有手柄的 绝缘方轴上,方轴可90°旋转,动触片 随方轴的旋转使其与静触片接通或断开. 型号: HZ5、 HZ10、 HZ15 系列。
具有电气联锁的控路
第7章 继电-接触器控制
机械联锁(或按钮联锁):利用按钮的常开、 常闭触点,在电 路中互相牵制的接法.
有双重联锁的控制电路
第7章 继电-接触器控制
2.行程控制电路
行程控制(或位置控制,或限位控制):-----利用生产机械运动部 件上的挡铁与行程开关碰撞,使其触点动作来接通或断开电路,以达 到控制生产机械运动部件位置或行程的控制.
组合开关
2.熔断器(俗称保险丝):作短路或严重过载保护.
1)磁插式熔断器
特点:结构简单、价廉、外形小、更换熔丝方便等优点,被 广泛地用于中、小容量的控制系统中。
第7章 图论 [离散数学离散数学(第四版)清华出版社]
![第7章 图论 [离散数学离散数学(第四版)清华出版社]](https://img.taocdn.com/s3/m/58b7923143323968011c9244.png)
6/27/2013 6:02 PM
第四部分:图论(授课教师:向胜军)
21
例:
a j i h c g d
1(a)
无 向 图
b
f
e
2(b)
7(j) 8(g) 9(d) 10(i)
6(e)
3(c) 4(h)
5(f)
6/27/2013 6:02 PM
第四部分:图论(授课教师:向胜军)
22
例:
1(b)
有向图
第四部分:图论(授课教师:向胜军)
6
[定义] 相邻和关联
在无向图G中,若e=(a, b)∈E,则称a与 b彼此相邻(adjacent),或边e关联 (incident) 或联结(connect) a, b。a, b称为边e的端点或 结束顶点(endpoint)。 在有向图D中,若e=<a, b>∈E,即箭头 由a到b,称a邻接到b,或a关联或联结b。a 称为e的始点(initial vertex),b称为e的终点 (terminal/end vertex)。
证明思路:将图中顶点的度分类,再利用定理1。
6/27/2013 6:02 PM 第四部分:图论(授课教师:向胜军) 9
[定理3] 设有向图D=<V, E>有n个顶点,m 条边,则G中所有顶点的入度之和等于所 有顶点的出度之和,也等于m。
即:
d ( v i ) d ( v i ) m.
i 1 i 1
n
n
证明思路:利用数学归纳法。
6/27/2013 6:02 PM
第四部分:图论(授课教师:向胜军)
10
一些特殊的简单图:
(1) 无向完全图Kn(Complete Graphs)
过程控制系统第7章 思考题与习题
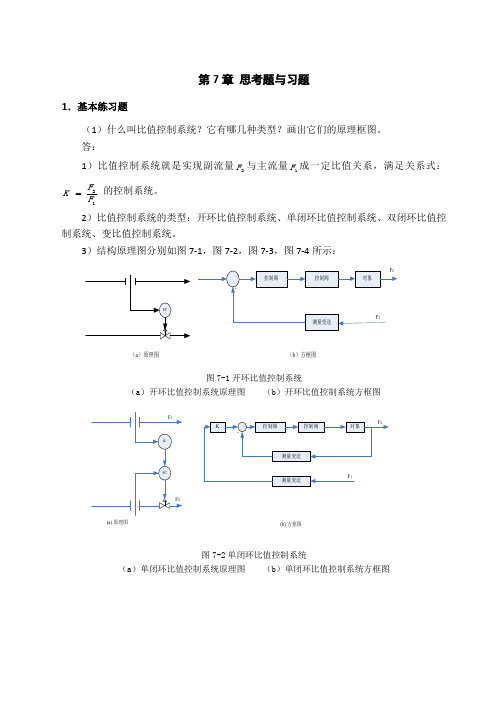
第7章 思考题与习题1.基本练习题(1)什么叫比值控制系统?它有哪几种类型?画出它们的原理框图。
答:1)比值控制系统就是实现副流量2F 与主流量1F 成一定比值关系,满足关系式:21F K F的控制系统。
2)比值控制系统的类型:开环比值控制系统、单闭环比值控制系统、双闭环比值控制系统、变比值控制系统。
3)结构原理图分别如图7-1,图7-2,图7-3,图7-4所示:图7-1开环比值控制系统(a )开环比值控制系统原理图(b )开环比值控制系统方框图图7-2单闭环比值控制系统(a)单闭环比值控制系统原理图 (b )单闭环比值控制系统方框图(a )原理图(b )方框图(a) 原理图(b) 方框图(b)方框图图7-3双闭环比值控制系统(a)双闭环比值控制系统原理图(b)双闭环比值控制系统方框图(b)方框图图7-4变比值控制系统(a)变比值控制系统原理图(b)变比值控制系统方框图(2)比值控制中的比值与比值系数是否是一回事?其关系如何?答:1)工艺要求的比值系数K,是不同物料之间的体积流量或重量流量之比,而比值器参数K’,则是仪表的读数。
它与实际物料流量的比值K,一般情况下并不相等。
因此,在设计比值控制系统时,必须根据工艺要求的比值系数K计算出比值器参数K’。
当使用单元组合仪表时,因输入-输出参数均为统一标准信号,所以比值器参数K’必须由实际物料流量的比值系数K折算成仪表的标准统一信号。
2)当物料流量的比值K一定、流量与其检测信号呈平方关系时,比值器的参数与物料流量的实际比值和最大值之比的乘积也呈平方关系。
当物料流量的比值K一定,流量与其检测信号呈线性关系时,比值器的参数与物料流量的实际比值和最大值之比的乘积也呈线性关系。
(3)什么是比值控制中的非线性特性?它对系统的控制品质有何影响?在工程设计中如何解决?答:1)比值控制系统中的非线性特性是指被控过程的静态放大系数随负荷变化而变化的特性。
2)非线性特性使系统的动态特性变差。
第7章_库内作业

C.梅花形垛:需要立直存放的大桶装货物,将第 一排货物排成单排,第二排的每件靠在第一排的 两件之间卡位,第三排同第一排一样,以后每排 依次卡缝排放,形成梅花形垛。 特点:摆放紧凑,充分利用了货件之间的空隙, 节约库场面积。 货量计算:A=(2B-1)L/2 A:总件数 L:宽度方向件数 B:长度方向件数
F.行列垛:将每票货物按件进行或列排放,每行 或列一层或数层高。垛形呈长方形。 适用于存放批量较小货物库场码垛使用。 特点:每垛货量较少,垛与垛之间都需要留有空 隙,垛基小而不能堆高,占用库场面积大,利用 率低。
4.堆码方式 (1)散堆法:适用于露天存放的没有包装的大宗 货物
(2)货架存放:适用于小件、品种规格复杂且数 量较少,包装简易或脆弱、易损害、不便于堆垛 的货物,或用托盘集合后的货物,特别是价值较 高而需要经常查数的货物仓储存放。 (3)货垛牌:为使保管中及时掌握货物资料,在 货垛上张挂有关该垛货物的资料标签。 内容:货位号、货物名称、规格、批号、来源、 进货日期、存货人、该垛数量、接货人等。
2.苫盖 (1)概念:采用专用苫盖材料对货垛进行遮盖, 以减少自然环境中的阳光、雨雪、刮风、尘土等 对物品的侵蚀、损害,并使物品由于自身理化性 质所造成的自然损耗尽可能地减少,保护物品在 储存期间的质量。 (2)常用的苫盖材料:帆布、芦席、竹席、塑料 膜、铁皮铁瓦、玻璃钢瓦、塑料瓦等。
(3)苫盖的要求 ① 选择合适苫盖材料 ② 苫盖牢固 ③ 苫盖的接口要紧密 ④ 苫盖的底部应与垫垛平齐 ⑤ 要注意苫盖的材质和季节
(三)仓库商品盘点的范围
(1)存货盘点:对原材料、辅助材料、燃 料、低值易耗品、包装品、在制品、半成 品、产成品的清查核点。 (2)财产盘点:对生产性财产和非生产性 财产的清查核点。
机械制图 第7章 零 件 图

图7–17 泵体的尺寸标注
第7章 零件图
7.4 零件图的技术要求
7.4.1 表面粗糙度
1. 表面粗糙度的概念
无论用何种方法加工的表面,都不会是绝对光滑 的,在显微镜下可看到表面的峰、谷状(如图 7–18 所 示)。表面粗糙度是指零件加工表面上具有的较小间 距和峰、谷组成的微观几何形状特性。
(3) 工作位置原则。主视图应尽量表示零件在机器上
的工作位置或安装位置。如图7–4所示吊钩。
第7章 零件图
轴
尾座
图7–3 轴类零件的加工位置
第7章 零件图
图7–4 吊钩的工作位置
第7章 零件图
零件主视图的选择并不一定要完全符合上述三条原 则,而应根据零件的工作位置、安装位置或加工位置, 选择最能反映零件结构形状特征的视图作为主视图。 2. 其它视图的选择 主视图确定后,再按完整、清晰地表达零件各部分
计基准或工艺基准,如图7–9所示。
第7章 零件图
2. 标注定位、定形尺寸 从基准出发,标注定位、定性尺寸有以下几种形式。
1) 链状式
零件同一方向的几个尺寸依次首尾相连,称为链状 式。链状式可保证各端尺寸的精度要求,但由于基准 依次推移,使各端尺寸的位置误差受到影响。如图 7– 10所示
第7章 零件图
① 基本尺寸:根据零件设计要求所确定的尺寸。 ② 实际尺寸:通过测量得到的尺寸。 ③ 极限尺寸:允许尺寸变动的两个界限值。 ④ 上、下偏差:最大、最小极限尺寸与基本尺寸的 代数差分别称为上偏差、下偏差。国标规定:孔的上、
称为开口环),以保证其它重要尺寸的精度。因此,图
7–12中注出零件总长c±0.1,而e±0.1是不应标注的。
第7章 零件图
2. 满足工艺要求 (1) 按加工顺序标注尺寸,既便于看图,又便于加 工测量,从而保证工艺要求,如表7–1所示齿轮轴的加 工顺序及尺寸标注。齿轮轴的尺寸标注如图 7–14 所示。
《数据结构》第 7 章 图

v3
v4 v5 v4
v3
v5 v4
v3
v5 v4
v3
v5 v4
v3
v5
注
一个图可以有许多棵不同的生成树。 所有生成树具有以下共同特点: 生成树的顶点个数与图的顶点个数相同; 生成树是图的极小连通子图; 一个有 n 个顶点的连通图的生成树有 n-1 条边; 生成树中任意两个顶点间的路径是唯一的; 在生成树中再加一条边必然形成回路。 含 n 个顶点 n-1 条边的图不一定是生成树。
A1 = {< v1, v2>, < v1, v3>, < v3, v4>, < v4, v1>} v1 v2
有向图
v3
v4
制作:计算机科学与技术学院 徐振中
数据结构 边:若 <v, w>∈VR 必有<w, v>∈VR,则以 无序对 (v, w) 代表这两个有序对,表示 v 和 w 之 间的一条边,此时的图称为无向图。 G2 = (V2, E2) V2 = {v1, v2, v3, v4, v5}
第七章 图
E2 = {(v1, v2), (v1, v4), (v2, v3), (v2, v5) , (v3, v4), (v3, v5)} v1
G2
v3
v2
无向图
v4
v5
制作:计算机科学与技术学院 徐振中
数据结构
第七章 图
例:两个城市 A 和 B ,如果 A 和 B 之间的连线的涵义是 表示两个城市的距离,则<A, B> 和 <B, A> 是相同的, 用 (A, B) 表示。 如果 A 和 B 之间的连线的涵义是表示两城市之 间人口流动的情况,则 <A, B> 和 <B, A> 是不同的。 北京 <北京,上海> (北京,上海) <上海,北京> <北京,上海> 北京 上海 上海
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
v0 → v1 → v2 →v3
注意:在邻接表中,并非每个 注意:在邻接表中, 链表元素(表结点) 链表元素(表结点)都被扫描 因此遍历速度很快。 到,因此遍历速度很快。
8
——仍用递归算法 仍用递归算法 (书上没有,02级同学编,仅供参考) 书上没有,02级同学编,仅供参考) 级同学编 //初始化辅助数组 元素均为0 初始化辅助数组, Int visited[]; //初始化辅助数组,元素均为0 DFS(List,v,p //设 Void DFS(List,v,p) //设p为v的头指针 //访问起点 { visit(v); //访问起点 //起点已访问,0变 起点已访问,0 visited[v]=1; //起点已访问,0变1 while(p//当存在起点的第一个邻接点时 while(p->link) //当存在起点的第一个邻接点时 p=p{ p=p->link; v=pv=p->data; //进行递归 if(!visited[v])DFS(List,v,p); //进行递归 } return; }
for( j=1; j<=n; j++)
//从 所在行从头搜索邻接点 //从v所在行从头搜索邻接点 从头
if ( A[v, j] && ! visited[j] ) DFS1(A, n, j); return; } // DFS1
A[v,j] =1 visited [n ]=0
有邻接点
未访问过
(教材上DFS递归算法见P169) 教材上DFS递归算法见P169) DFS递归算法见P169
BFS 算法效率分析: 算法效率分析: 个顶点, 条边) (设图中有 n 个顶点,e 条边)
• 如果使用邻接表来表示图,则BFS循环的总时间代价为 如果使用邻接表来表示图, 循环的总时间代价为 d0 + d1 + … + dn-1 = O(e),其中的 di 是顶点 i 的度。 的度。 , • 如果使用邻接矩阵,则BFS对于每一个被访问到的顶点, 如果使用邻接矩阵, 对于每一个被访问到的顶点, 对于每一个被访问到的顶点 都要循环检测矩阵中的整整一行( 个元素), ),总的 都要循环检测矩阵中的整整一行( n 个元素),总的 时间代价为O(n2)。 时间代价为 。
方案三:哈夫曼编/ 方案三:哈夫曼编/译码器的设计与实现
具体内容:参见严题集 实习5.2要求 要求, 具体内容:参见严题集P149 实习 要求,或参见自测卷
1
第 7章
图
7.1 基本术语 7.2 存储结构 7.3 图的遍历 7.4 图的其他运算 7.5 图的应用
2
7.3
图的遍历
遍历定义:从已给的连通图中某一顶点出发,沿着一些边, 遍历定义:从已给的连通图中某一顶点出发,沿着一些边,访 遍图中所有的顶点,且使每个顶点仅被访问一次, 遍图中所有的顶点,且使每个顶点仅被访问一次,就叫做 图的遍历,它是图的基本运算。 图的基本运算 图的遍历,它是图的基本运算。 遍历实质:找每个顶点的邻接点的过程。 遍历实质:找每个顶点的邻接点的过程。 图的特点:图中可能存在回路, 图的特点:图中可能存在回路,且图的任一顶点都可能与其它 回路 顶点相通, 顶点相通,在访问完某个顶点之后可能会沿着某些边又回 到了曾经访问过的顶点。 怎样避免重复访问? 怎样避免重复访问? 解决思路:可设置一个辅助数组 解决思路:可设置一个辅助数组 visited [n ],用来标记每个被 , 访问过的顶点。它的初始状态为0 在图的遍历过程中, 访问过的顶点。它的初始状态为0,在图的遍历过程中, 一旦某一个顶点i 被访问, 一旦某一个顶点 被访问,就立即改 visited [i]为1,防止 为 它被多次访问。 它被多次访问。 图常用的遍历: 图常用的遍历:
第7章 图 作业
7.1
7.3
实
验
二
方案一: 方案一:二叉树的Fra bibliotek立和遍历具体内容:先生成一棵二叉树, 具体内容:先生成一棵二叉树,再用中序遍历方式打印每个结 点值, 点值,并统计其叶子结点的个数。
方案二: 方案二:哈夫曼树的建立和编码器的实现
具体内容:先生成一棵哈夫曼树, 具体内容:先生成一棵哈夫曼树,再打印各字符对应的哈夫曼 编码。 编码。
1 1 5 0 0 0 0 0 0 6 0 0 0 1 0 0 0
起点
DFS 结果
v2→ v1→ v3 →v5 →v4 →v6 v2→
请注意逐级回退是递归概念
6
可以用递归算法! 可以用递归算法 讨论2 讨论2: DFS算法如何编程? ——可以用递归算法! DFS算法如何编程 算法如何编程? //A[n][n]为邻接矩阵 为邻接矩阵, 为起始顶点(编号) DFS1(A, n, v) //A[n][n]为邻接矩阵,v为起始顶点(编号) { visit(v); ( ) //访问(例如打印)顶点v //访问(例如打印)顶点v 访问 visited[v]=1; //访问后立即修改辅助数组标志 //访问后立即修改辅助数组标志
5
开辅助数组 ! 讨论1 计算机如何实现DFS? 讨论1:计算机如何实现DFS? ——开辅助数组 visited [n ]! 例: 邻 接 矩 阵 A 1 2 3 1 1 1 0 0 0 1 2 0 0 0 1 3 0 0 0 1 4 0 0 0 4 5 6 1 0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 1 2 3 4 5 6 辅助数组 visited [n ] 1 1 0 0 1 1 1 1 0 1 1 1 1 1 0 0 0 1 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1
应退回到V8,因为V2已有标记 应退回到V8,因为V2已有标记 V8 V2
例2 :
起点
DFS 结果 v2 → v1 → v3 → v5 → v4 → v6
应退回到V3,因为V2已有标记 应退回到V3,因为V2已有标记 V3 V2
4
深度优先搜索(遍历)步骤: 深度优先搜索(遍历)步骤:
简单归纳: 简单归纳: • 访问起始点 v; 的第1个邻接点没访问过 • 若v的第 个邻接点没访问过,深度遍历此邻接点; 的第 个邻接点没访问过,深度遍历此邻接点; • 若当前邻接点已访问过,再找 的第 个邻接点重新遍历。 若当前邻接点已访问过,再找v的第 个邻接点重新遍历。 的第2个邻接点重新遍历
例2 :
11
广度优先搜索(遍历)步骤: 广度优先搜索(遍历)步骤: 简单归纳: 简单归纳:
• • • 在访问了起始点v之后, 的邻接点; 在访问了起始点 之后,依次访问 v的邻接点; 之后 的邻接点 顺序) 下一层) 然后再依次(顺序)访问这些点(下一层)中未被 访问过的邻接点; 访问过的邻接点; 直到所有顶点都被访问过为止。 直到所有顶点都被访问过为止。 广度优先搜索是一种分层的搜索过程,每向前走一 广度优先搜索是一种分层的搜索过程, 步可能访问一批顶点, 步可能访问一批顶点,不像深度优先搜索那样有回 退的情况。 退的情况。 因此,广度优先搜索不是一个递归的过程, 因此,广度优先搜索不是一个递归的过程,其算法 也不是递归的。 也不是递归的。
讨论4: 邻接表的DFS算法如何编程? 算法如何编程? 讨论 : 邻接表的 算法如何编程
9
DFS 算法效率分析: 算法效率分析: 个顶点, 条边) (设图中有 n 个顶点,e 条边) 如果用邻接矩阵来表示图, 如果用邻接矩阵来表示图,遍历图中每一个顶点都 邻接矩阵来表示图 要从头扫描该顶点所在行,因此遍历全部顶点所需 从头扫描该顶点所在行, 该顶点所在行 的时间为O(n2)。 的时间为 。 如果用邻接表来表示图, 个表结点, 如果用邻接表来表示图,虽然有 2e 个表结点,但 邻接表来表示图 个结点即可完成遍历, 只需扫描 e 个结点即可完成遍历,加上访问 n个头 个头 结点的时间,因此遍历图的时间复杂度为O(n+e)。 结点的时间,因此遍历图的时间复杂度为 。
结 论: 稠密图适于在邻接矩阵上进行深度遍历 适于在邻接矩阵上进行深度遍历; 稠密图适于在邻接矩阵上进行深度遍历; 稀疏图适于在邻接表上进行深度遍历 适于在邻接表上进行深度遍历。 稀疏图适于在邻接表上进行深度遍历。
10
二、广度优先搜索( BFS ) 广度优先搜索(
v1 v2 v4 v5 v8 v6
一、深度优先搜索 二、广度优先搜索
3
一、深度优先搜索( DFS ) 深度优先搜索(
Depth_First Search
基本思想: 仿树的先序遍历过程。 基本思想:——仿树的先序遍历过程。 遍历步骤 例1 :
v2 v4 v8 v5 v6 v1
起点
DFS 结果
v3 v7
v1→ v2→ v4 →v8 → v5 → v3 →v6 →v7
12
讨论1:计算机如何实现 讨论 :计算机如何实现BFS? 宽度优先搜索要借助队列! ? 宽度优先搜索要借助队列!