解处奇异凸的极小化问题的正规化牛顿法
牛顿法推导

牛顿法推导(一)牛顿法推导的概念牛顿法,又被称为牛顿-拉夫逊方法,是17世纪由艾萨克·牛顿提出的一种在实数域和复数域上近似求解方程的方法。
牛顿法的基本思想是用迭代点的梯度信息和二阶导数对目标函数进行二次函数逼近,然后将这个二次函数的极小值或极大值作为新的迭代点。
这个过程会不断重复进行,直至找到满足要求的迭代解。
在实际应用中,例如机器学习领域,牛顿法和梯度下降法等都是主要的优化算法。
假设我们需要求解函数f(x)在某区间[a, b]上的零点,初始点为x0。
迭代公式如下:x_{k+1} = x_k - f(x_k)/f'(x_k)其中,f'(x_k)表示的是函数在x_k处的一阶导数,f''(x_k)表示的是函数在x_k 处的二阶导数。
而我们要求的就是使得上述公式趋向于零的解x,也就是极小值点或者极大值点。
然而在实际应用中,由于海塞矩阵的逆矩阵计算较为复杂,因此有了拟牛顿法用来简化这一过程。
(二)牛顿法推导的优缺点牛顿法的优点主要包括收敛速度快,具有二阶收敛性。
对于二次正定函数,迭代一次便可以得到最优解,对于非二次函数,若函数二次性较强或迭代点已经进入最优点的较小邻域,则收敛速度也很快。
然而,牛顿法也存在一些缺点。
首先,牛顿法是迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
此外,如果目标函数的海森矩阵无法保持正定,牛顿法可能会失效。
其次,牛顿法对函数要求较为苛刻,函数必须具有连续的一、二阶偏导数,并且海森矩阵必须正定。
另外,当初始点离最优解较远时,可能会导致牛顿法发散或者效率降低。
最后,由于牛顿法是一种基于二次近似的算法,可能产生一定的误差,这就需要反复进行迭代。
为了克服这些问题,拟牛顿法被提出,通过不直接使用二阶偏导数而构造出可以近似海森矩阵或者海森矩阵的逆的正定对称阵,来优化目标函数。
(三)牛顿法推导的意义牛顿法的意义在于,它是一种强大的数学工具,可以求解函数的极值问题以及方程的根。
最优化理论方法——牛顿法
牛顿法牛顿法作为求解非线性方程的一种经典的迭代方法,它的收敛速度快,有内在函数可以直接使用。
结合着matlab 可以对其进行应用,求解方程。
牛顿迭代法(Newton ’s method )又称为牛顿-拉夫逊方法(Newton-Raphson method ),它是牛顿在17世纪提出的一种在实数域和复数域上近似求解方程的方法,其基本思想是利用目标函数的二次Taylor 展开,并将其极小化。
牛顿法使用函数()f x 的泰勒级数的前面几项来寻找方程()0f x =的根。
牛顿法是求方程根的重要方法之一,其最大优点是在方程()0f x =的单根附近具有平方收敛,而且该法还可以用来求方程的重根、复根,此时非线性收敛,但是可通过一些方法变成线性收敛。
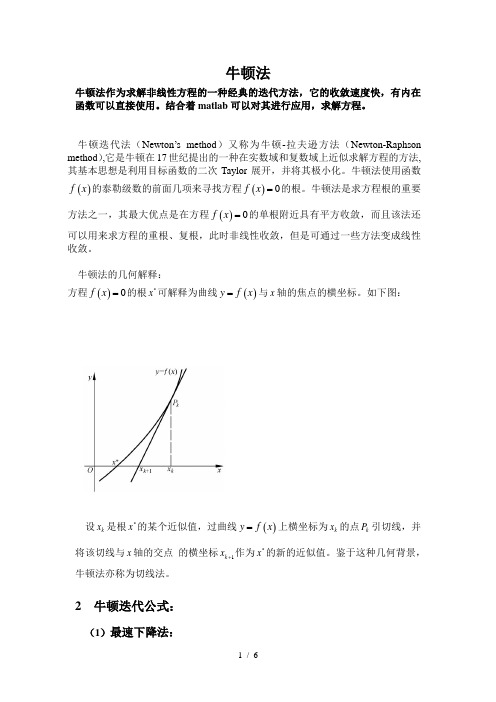
牛顿法的几何解释:方程()0f x =的根*x 可解释为曲线()y f x =与x 轴的焦点的横坐标。
如下图:设k x 是根*x 的某个近似值,过曲线()y f x =上横坐标为k x 的点k P 引切线,并将该切线与x 轴的交点 的横坐标1k x +作为*x 的新的近似值。
鉴于这种几何背景,牛顿法亦称为切线法。
2 牛顿迭代公式:(1)最速下降法:以负梯度方向作为极小化算法的下降方向,也称为梯度法。
设函数()f x 在k x 附近连续可微,且()0k k g f x =∇≠。
由泰勒展开式: ()()()()()Tk k k k fx f x x x f x x x ο=+-∇+- (*)可知,若记为k k x x d α-=,则满足0Tk k d g <的方向k d 是下降方向。
当α取定后,Tk k d g 的值越小,即T kk d g -的值越大,函数下降的越快。
由Cauchy-Schwartz 不等式:T k k kk d g d g ≤,故当且仅当k k d g =-时,Tk k d g 最小,从而称k g -是最速下降方向。
最速下降法的迭代格式为: 1k k k k x x g α+=-。
牛顿法求极值

牛顿法求极值极值理论是拉格朗日在1897年发表的《拉格朗日函数原理与极值问题》中首次提出的,是数学分析中最重要的主题之一。
它涉及多元函数中的极大值和极小值的求解问题。
牛顿法是现代数值分析的一种重要的方法,它主要用来解决非线性方程组和极值问题。
它是在17世纪由英国数学家牛顿首先提出的,因此得名“牛顿法”。
二、牛顿法的基本原理牛顿法是一种迭代算法,它的基本原理是:以某点为基点,求解点处的极大值和极小值时,首先考虑函数在该点处的切线,然后计算出该切线与x轴之间的交点,并用这个交点做新的基点,再求出它的切线,重复以上过程,直至切线的斜率不再发生变化,即收敛,得到极值点。
牛顿法主要用于求解一元函数的极值问题,当然也可以用于求解多元函数的极值问题,但是由于较复杂,使用起来就比较麻烦。
三、牛顿法的优缺点(1) 优点:牛顿法比其他计算方法效率更高,有时可以求得更接近极值的值。
(2)点:牛顿法对函数的限制较多,它只能处理可导函数,且函数的二阶导数不能出现奇点。
四、牛顿法的步骤(1)定初始点:用x0作为初始点,求原函数f(x0)的一阶导数和二阶导数;(2)造牛顿迭代式:计算牛顿步长Δx=-f′(x0)/f″(x0;(3)新点:x1=x0+Δx;(4)测是否满足收敛条件:确定是否满足要求的收敛条件,如果满足,则将x1作为极值点,否则本次计算结束,将x1作为下一次计算的初始点,重复以上步骤。
五、应用实例以f(x) = x3 - 4x2 + x + 2为例,用牛顿法求极值:令x0 = 1,求f′(x0)和f″(x0),得f′(x0) = 3 - 8 + 1 = -4,f″(x0) = 6;根据牛顿迭代式,计算Δx=-f′(x0)/f″(x0)=-4/6=-2/3;确定新点x1=x0+Δx=1+(-2/3)=-1/3;检测收敛条件,计算f′(x1)和f″(x1),得f′(x1) = -2/3,f″(x1) = 6,可知条件满足,x1=-1/3就是函数f(x)的极值点。
修正牛顿法详解

修正牛顿法(Modified Newton's Method)是一种优化算法,通常用于解决非线性最小化问题。
它是基于牛顿法(Newton's Method)的一种变种,用于解决牛顿法可能会出
现的一些问题。
在牛顿法中,我们希望通过在每一步迭代中
求解一个二阶导数矩阵(Hessian Matrix)的逆来寻找函数
的最小值。
然而,在某些情况下,这个二阶导数矩阵可能不
是正定的,这会导致算法出现问题。
为了克服这个问题,修
正牛顿法使用了一个修正项来调整牛顿法中的二阶导数矩阵
的逆。
这个修正项可以保证矩阵的正定性,从而确保算法的
稳定性和可靠性。
修正牛顿法的每一次迭代都需要计算函数的一阶导数和二
阶导数矩阵,因此它的计算复杂度比其他一些优化算法高,
但是它通常能够更快地收敛到最小值,并且可以处理更广泛
的优化问题。
在具体实现上,修正牛顿法通常包括以下步骤:
初始化:选择一个初始点x_0,以及一个足够小的正数ε。
计算一阶导数:计算函数在x_0点的一阶导数。
判断是否满足牛顿条件:如果一阶导数的范数小于ε,则
认为已经找到了最小值,结束算法。
计算修正项:如果一阶导数的范数大于ε,则计算修正项,使得矩阵正定。
更新迭代点:使用修正项更新迭代点,然后返回步骤2。
需要注意的是,修正牛顿法虽然能够保证算法的稳定性和可靠性,但是在某些情况下可能收敛较慢或者无法收敛到最小值。
因此,在实际应用中,需要结合具体问题选择合适的优化算法。
牛顿法原理

牛顿法原理
牛顿法是一种可以将非线性收敛到最小值的迭代法,是以传统意义上的函数最小值求解和极值求解具有重要意义的数值解法之一。
牛顿法(Newton's Method)或称牛顿迭代法,由英国数学家牛顿提出。
它是一种以逐步逼近的方式来求解极值,也就是最优求解法。
它可以帮助求解数学中连续函数极值及根的值,是近代数值分析的重要组成部分,也是当今最重要的最优方法之一。
牛顿法的基本思想是,如果一个连续函数的图像在某一点处有极值,那么该点处函数的导数为零,它即为函数的极值点。
根据这一思想,牛顿法寻找极值点,即就是不断从起点开始,计算梯度并根据梯度计算新的点,然后继续重复上面的步骤,直到收敛为止。
牛顿法的具体步骤有:
(1)确定变量的初始值,使用方程组求解;
(2)计算变量的一阶偏导数;
(3)根据一阶偏导数的函数值更新变量的值;
(4)用新值计算梯度,若精度满足要求,则可结束;若未满足要求,则重复步骤2和3。
在求解函数极值时,牛顿法优于迭代法。
牛顿法不仅使函数值逐渐收敛到极值,而且保持精度高。
其收敛速度快,收敛精度高,且稳定性好,而迭代法则收敛缓慢,而且收敛精度也不高。
总之,牛顿法是通过不断迭代计算求取函数极值的一种简便有效的求解方法,利用它求解特定类型函数的极值及其根可以弥补非线性方程其他求解方法的盲点,大大的提高了求解的效率。
牛顿法、拟牛顿法、高斯-牛顿法、共轭梯度法推导总结

牛顿法、拟牛顿法、高斯-牛顿法、共轭梯度
法推导总结
一、牛顿法
牛顿法是一种求解非线性方程的迭代方法。
牛顿法的基本思想是:在当前点附近,用一次泰勒展开式近似原函数,然后求解近似函数的极值点。
牛顿法每次迭代所需要的计算量较大,但其收敛速度较快。
二、拟牛顿法
拟牛顿法是一种求解无约束极值问题的优化算法。
拟牛顿法是将牛顿法中Hessian矩阵用近似Hessian矩阵Bk表示的算法。
拟牛顿法的计算量比牛顿法小,但是收敛速度较牛顿法慢。
三、高斯-牛顿法
高斯-牛顿法是求解非线性最小二乘问题的一种迭代算法。
该算法假设误差服从高斯分布,利用牛顿法求解目标函数的局部极小值,以最小化残差平方和。
高斯-牛顿法在处理非线性最小二乘问题时具有很好的收敛性。
四、共轭梯度法
共轭梯度法是解决对称正定线性方程组的迭代算法。
该算法通过对一个对称正定矩阵进行迭代求解,寻找线性方程组的解。
共轭梯度法的优点是可以使用较少的内存和计算量实现高效的求解。
以上算法都是数值优化中比较常用的算法,它们各自具有不同的优缺点,可根据实际问题的特点来选择合适的算法。
牛顿法

牛顿法牛顿法(英语:Newton's method)又称为牛顿-拉弗森方法(英语:Newton-Raphson method),它是一种在实数域和复数域上近似求解方程的方法。
方法使用函数的泰勒级数的前面几项来寻找方程的根。
起源:牛顿法最初由艾萨克·牛顿在《流数法》(Method of Fluxions,1671年完成,在牛顿去世后的1736年公开发表)中提出。
约瑟夫·鲍易也曾于1690年在Analysis Aequationum中提出此方法。
原理:二阶逼近牛顿法对局部凸函数找到极小值,对局部凹函数找到极大值,对局部不凸不凹函数可能找到鞍点牛顿法要求估计二阶导数。
牛顿法据称比直接计算要快了4 倍。
其中的两次迭代(第二步迭代被注释掉了)就是用的牛顿法来求解方程,也就是的根。
牛顿法的思想其实很简单,给定一个初始点,使用在该点处的切线来近似函数,然后寻找切线的根作为一次迭代。
比如对于这个例子,令,给定初始点,在该点处的导数是,由此可以得到该处的切线为,求解得到正是代码中的迭代。
当然代码的重点其实不在这里,而在0x5f3759df这个奇怪的magic number,用于得到一个好的初始点。
这个神奇的数字到底是谁发现的,根据wikipedia 上的说法似乎至今还没有定论。
xkcd 还为此画了一条漫画,讽刺说每次我们惊奇地发现工业界里不知道哪个无名人士写出了0x5f3759df之类的神奇数字,背后都有成千上万的其他无名人士我们无从知晓,说不定他们中的某一个人已经解决了P=NP 的问题,但是那人却还在调某个自动打蛋器的代码所以我们至今仍无知晓。
:D回到我们今天的话题,从这段代码中我们可以看到两点:牛顿法收敛非常快,对于精度要求不是特别高的情况,比如上面的图形学相关的计算中,甚至只用了一次计算迭代。
另一方面,初始值的选取非常重要,我们接下去将会看到,初始值选得不好有可能会直接导致算法不收敛。
牛顿法

牛顿法以伟大的英国科学家牛顿命名,牛顿不仅是伟大的物理学家,是近代物理的奠基人,还是伟大的数学家,他和德国数学家莱布尼兹并列发明了微积分,这是数学历史上最有划时代意义的成果之一,奠定了近代和现代数学的基石。
在数学中,也有很多以牛顿命名的公式和定理,牛顿法就是其中之一。
牛顿法不仅可以用来求解函数的极值问题,还可以用来求解方程的根,二者在本质上是一个问题,因为求解函数极值的思路是寻找导数为0的点,这就是求解方程。
在本文中,我们介绍的是求解函数极值的牛顿法。
在SIGAI之前关于最优方法的系列文章“理解梯度下降法”,“理解凸优化”中,我们介绍了最优化的基本概念和原理,以及迭代法的思想,如果对这些概念还不清楚,请先阅读这两篇文章。
和梯度下降法一样,牛顿法也是寻找导数为0的点,同样是一种迭代法。
核心思想是在某点处用二次函数来近似目标函数,得到导数为0的方程,求解该方程,得到下一个迭代点。
因为是用二次函数近似,因此可能会有误差,需要反复这样迭代,直到到达导数为0的点处。
下面我们开始具体的推导,先考虑一元函数的情况,然后推广到多元函数。
牛顿法在每次迭代时需要计算出Hessian矩阵,然后求解一个以该矩阵为系数矩阵的线性方程组,这非常耗时,另外Hessian矩阵可能不可逆。
为此提出了一些改进的方法,典型
的代表是拟牛顿法(Quasi-Newton)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
where µk > 0 is a parameter and I is the identity matrix, and proved that if g (x ) provides a local error bound for problem (1.3) and µ is chosen as µk = g (xk ) 2 , then the LevenbergMarquardt method retains a quadratic convergence property. The concept of a local error bound is defined as follows. Definition 1.1. A function F : R n → R is said to provide a local error bound for problem ¯ ∈ X is there exist a neighborhood (x ¯ ) of x ¯ and a constant m > 0 such that (1.2) near x ¯) for all x ∈ (x F (x ) ≥ m dist(x , X ), where dist(x , X ) denotes the distance from point x to the solution set X . In the remaining part of the paper, we will omit the phrase “for problem (1.2)” when ¯ }, and we talk about a local error bound. It is clear that if X is a singleton, i.e., X = {x ¯ ) is nonsingular, then g (x ) provides a local error bound near x ¯. the Hessian matrix G (x However, the converse is not true in general. An example is given in [1], which shows that (1.5)
The classical Newton method is quite a way of solving (1.2) and (1.3). An attractive feature ¯ ) is nonsingular at a of Newton’s method lies in its local quadratic convergence when G (x ¯ . We call a solution x ¯ of problem (1.2) or (1.3) nonsingular if G (x ¯ ) is a nonsingular solution x ¯ singular. It is clear that a nonsingular solution is locally isolated. matrix. Otherwise we call x We are particularly interested in the case where problem (1.2) may have singular solutions. When Newton’s method is applied to such a problem, the quadratic rate of convergence may no longer be guaranteed. Recently, there has been some progress in convergence analysis of Newton-type methods for problem (1.3) with singular solutions. Yamashita and Fukushima [5] studied the Levenberg-Marquardt method for solving (1.3), in which the subproblem is the system of linear equations (G (xk )T G (xk ) + µk I )d + G (xk )T g (xk ) = 0, (1.4)
132 for all x , y ∈ S . Consider the minimization problem min f (x ), x ∈ R n .
LI ET AL.
(ppose that f is convex and that the solution set X of (1.2) is nonempty and contained in S . It is clear that X is convex. Denote by g (x ) = ∇ f (x ) and G (x ) = ∇ 2 f (x ) the gradient and the Hessian matrix of f at x , respectively. It is well-known that f is convex if and only if G (x ) is positive semidenfinite for all x ∈ R n . Moreover, if f is convex, then x is a solution of (1.2) if and only if it is a solution of the system of nonlinear equations g (x ) = 0. (1.3)
REGULARIZED NEWTON METHODS FOR CONVEX MINIMIZATION PROBLEMS
133
¯ ). Note also that the the local error bound condition is weaker than nonsingularity of G (x ¯ . More specifically, let the condition in Definition 1.1 depends on a particular choice of x function f : R 2 → R be defined by f (x ) = with 4 (x2 − 1) φ (x2 ) = 0 (x2 + 1)4 if x2 ∈ [1, +∞) if x2 ∈ (−1, 1) if x2 ∈ (−∞, −1]. 1 2 x + φ (x2 ) 2 1
Abstract. This paper studies convergence properties of regularized Newton methods for minimizing a convex function whose Hessian matrix may be singular everywhere. We show that if the objective function is LC2 , then the methods possess local quadratic convergence under a local error bound condition without the requirement of isolated nonsingular solutions. By using a backtracking line search, we globalize an inexact regularized Newton method. We show that the unit stepsize is accepted eventually. Limited numerical experiments are presented, which show the practical advantage of the method. Keywords: minimization problem, regularized Newton methods, global convergence, quadratic convergence, unit step
∗ The author is partially supported by the National Natural Science Foundation of China via Grant 10171030 and a Hong Kong Polytechnic University Postdoctoral Fellowship. ∗∗ The author is partially supported by a Grant-in-Aid for Scientific Research from the Ministry of Education, Science, Sports and Culture of Japan. † The author is partially supported by the Research Grant Council of Hong Kong. ‡ The author is partially supported by a Grant-in-Aid for Scientific Research from the Ministry of Education, Science, Sports and Culture of Japan.
Computational Optimization and Applications, 28, 131–147, 2004 c 2004 Kluwer Academic Publishers. Manufactured in The Netherlands.
Regularized Newton Methods for Convex Minimization Problems with Singular Solutions