svmtrain和svmpredict简介回归、分类
matlab二分类算法

matlab二分类算法二分类算法是机器学习领域中的一种常见算法,它将数据集划分为两个类别,并预测新样本属于哪一类。
MATLAB作为一种强大的数值计算和数据分析工具,提供了多种用于二分类问题的算法。
本文将介绍一些常用的MATLAB二分类算法,并说明其原理和使用方法。
一、支持向量机(Support Vector Machine,SVM)是一种非常流行的二分类算法。
其核心思想是将数据集转换为高维空间,然后找到一个超平面,使得两个类别的数据点在该超平面上的投影最大化。
在MATLAB中,可以使用fitcsvm函数来训练SVM模型,并使用predict函数进行预测。
该函数提供了多种参数配置选项,如核函数类型、惩罚系数等。
二、逻辑回归(Logistic Regression)是另一种常用的二分类算法。
它通过将线性回归模型的输出映射到一个概率值(0~1之间),然后根据阈值进行分类预测。
在MATLAB中,可以使用fitglm函数进行逻辑回归模型的训练,并使用predict函数进行预测。
fitglm函数支持多种模型配置选项,如正则化类型、损失函数类型等。
三、随机森林(Random Forest)是一种基于集成学习的二分类算法。
它由多个决策树组成,每棵树对数据集进行随机采样,并在每个节点上选择最佳的特征进行分割。
最终,通过对多棵树的结果进行投票或平均,得到最终的预测结果。
在MATLAB中,可以使用TreeBagger类来实现随机森林算法。
通过创建TreeBagger对象,设置参数并调用train函数来训练模型,然后使用predict函数进行预测。
四、神经网络(Neural Network)是一种通过模拟人脑中的神经元网络来解决问题的方法。
在二分类问题中,神经网络可以通过多个神经元和多个隐藏层构建一个复杂的模型,并通过调整权重和偏置来训练模型。
在MATLAB中,可以使用patternnet函数来创建神经网络模型,并使用train函数进行训练。
sklearn中的svm用法

sklearn中的svm用法SVM用于机器学习的模型,是一种有监督的学习算法,可以用于分类和回归问题。
在scikit-learn库中,我们可以使用sklearn.svm模块来实现SVM模型。
要使用sklearn中的svm模块,首先需要导入相应的类和函数。
下面是一些常用的类和函数:1. SVC类:用于支持向量分类。
可以根据训练数据找到一个最佳的超平面(也称为决策边界),将不同类别的样本分开。
2. SVR类:用于支持向量回归。
与SVC类似,但用于解决回归问题,预测连续的目标变量而不是分类。
3. LinearSVC类:用于线性支持向量分类。
适用于线性可分的分类问题。
4. NuSVC类:用于支持向量分类。
与SVC类似,但使用不同的参数表示支持向量。
除了上述类之外,sklearn.svm模块还提供了一些辅助函数和类,例如:1. kernel:用于指定SVM模型中使用的核函数,如线性核(linear)、多项式核(poly)、RBF核(rbf)等。
2. C:用于控制分类器的惩罚参数。
较小的C值会生成较大的间隔,但可能会导致分类误差增加。
3. gamma:在使用RBF核函数时,用于控制数据点的影响范围。
较高的gamma值会导致训练样本的影响范围更小。
接下来,我们可以使用这些类和函数来构建SVM模型并进行训练和预测。
以下是一个使用SVC类的示例:```pythonfrom sklearn import svm# 创建一个SVC分类器clf = svm.SVC(kernel='linear', C=1)# 使用训练数据进行模型拟合clf.fit(X_train, y_train)# 使用训练好的模型进行预测y_pred = clf.predict(X_test)```在上述示例中,我们使用线性核函数(kernel='linear')和惩罚参数C等于1来创建一个SVC分类器。
然后,我们使用训练数据(X_train和y_train)来进行模型拟合,并使用训练好的模型对测试数据(X_test)进行预测,预测结果存储在y_pred中。
SVM模式识别与回归软件包(LibSVM)详解
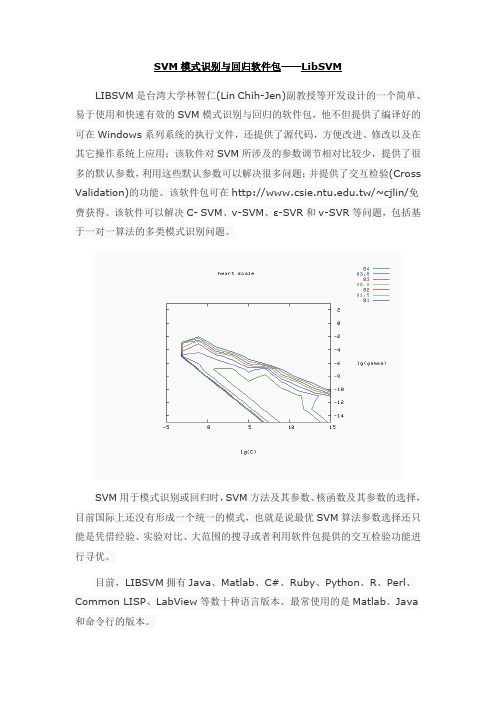
SVM模式识别与回归软件包——LibSVMLIBSVM是台湾大学林智仁(Lin Chih-Jen)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验(Cross Validation)的功能。
该软件包可在.tw/~cjlin/免费获得。
该软件可以解决C- SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
目前,LIBSVM拥有Java、Matlab、C#、Ruby、Python、R、Perl、Common LISP、LabView等数十种语言版本。
最常使用的是Matlab、Java 和命令行的版本。
就要做有关SVM的报告了!由于SVM里面的有关二次优化的不是那么容易计算得到的,最起码凭借我现在的理论知识和编程能力是不能达到!幸好,现在又不少的SVM工具,他可以帮助你得到支持向量(SV),甚至可以帮助你得到预测结果,归一化数据等等。
其中SVM-light,LibSVM是比较常用的!SVM-light我们实验室有这方面的代码,而我自己就学习了下怎么使用LIBSVM(来自台湾大学林智仁)。
实验步骤如下:1:首先安装LIBSVM,这个不用多说,直接去他的官网上看:.tw/~cjlin/libsvm/index.html2:处理数据,把数据制作成LIBSVM的格式,其每行格式为:label index1:value1 index2:value2 ...其中我用了复旦的分类语料库,当然我先做了分词,去停用词,归一化等处理了3:使用svm-train.exe训练,得到****.model文件。
LIBSVM使用方法

LIBSVM1 LIBSVM简介LIBSVM是台湾大学林智仁(Lin Chih-Jen)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows 系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件还有一个特点,就是对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数就可以解决很多问题;并且提供了交互检验(Cross -SVM回归等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
ν-SVM回归和ε-SVM分类、νValidation)的功能。
该软件包可以在.tw/~cjlin/免费获得。
该软件可以解决C-SVM分类、-SVM回归等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
2 LIBSVM使用方法LibSVM是以源代码和可执行文件两种方式给出的。
如果是Windows系列操作系统,可以直接使用软件包提供的程序,也可以进行修改编译;如果是Unix类系统,必须自己编译,软件包中提供了编译格式文件,我们在SGI工作站(操作系统IRIX6.5)上,使用免费编译器GNU C++3.3编译通过。
2.1 LIBSVM 使用的一般步骤:1) 按照LIBSVM软件包所要求的格式准备数据集;2) 对数据进行简单的缩放操作;3) 考虑选用RBF 核函数;4) 采用交叉验证选择最佳参数C与g;5) 采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;6) 利用获取的模型进行测试与预测。
libsvm安装方法

安装libsvm-mat(林智仁版)方法2011-10-14 10:00:33| 分类:无线视频传输仿真| 标签:|字号大中小订阅安装libsvm-mat是在MATLAB平台下使用libsvm的前提,如果没有安装好也就无法使用,在MATLAB平台下安装libsvm-mat一般有以下几个大步骤:1. 将libsvm-mat所在工具箱添加到matlab工作搜索目录(File ——》Set Path… ——》Add with Subfolders...);2. 选择编译器(mex -setup);3. 编译文件(make)。
每一步都很重要【我就不在每一步前面说这一步很重要了~】,下面我将掰饽饽说馅【一句东北俚语i.e.翔实详尽】的给大家详细说明。
1. 将libsvm-mat所在文件夹目录添加到MATLAB工作搜索目录(File ——》Set Path…——》Add with Subfolders...)这第一步很重要,如果没有将libsvm-mat所在文件夹目录正确的添加到MATLAB工作搜索目录,使用的时候就会出现??? Undefined function or variable 'XXX'.等等报错。
首先明晰一下MATLAB工作搜索目录(路径)和当前目录(路径)这两个概念:当前目录[Current Folder]是指MATLAB当前所在的路径,MATLAB菜单栏下面有一个Current Folder可以在这里进行当前所在目录的更改。
工作搜索目录(路径)是指当你使用某一个函数的时候,MATLAB可以进行搜索该函数的所有的目录集合。
注:当你使用某一个函数的时候,MATLAB首先会从当前目录搜索调用该函数,如果当前目录没有该函数,MATLAB就会从工作搜索目录按照从上到下的顺序进行搜索调用该函数,如果工作搜索目录中也没有该函数,就会给出??? Undefined function or variable 'XXX' 这个报错。
自然语言处理技术中常用的机器学习算法介绍

自然语言处理技术中常用的机器学习算法介绍自然语言处理(Natural Language Processing,NLP)是人工智能领域中研究人类语言与计算机之间交互的一门学科。
在NLP领域中,机器学习算法被广泛应用于语言模型、文本分类、命名实体识别、情感分析等任务中。
本文将介绍NLP中常用的机器学习算法,包括支持向量机(Support Vector Machine,SVM)、朴素贝叶斯(Naive Bayes)、隐马尔可夫模型(Hidden Markov Model,HMM)和递归神经网络(Recurrent Neural Network,RNN)。
支持向量机(SVM)是一种常用的监督学习算法,广泛用于文本分类、情感分析等NLP任务中。
其核心思想是将数据映射到高维空间,通过构建一个最优的超平面,来实现数据的分类。
SVM在处理小样本、非线性和高维特征等问题上具有较好的性能。
朴素贝叶斯(Naive Bayes)是一种基于概率的分类算法,常用于文本分类任务。
它基于贝叶斯定理和特征间的条件独立性假设,可以在给定训练数据的条件下,通过计算后验概率来进行分类。
朴素贝叶斯算法简单、计算效率高,并且对输入数据的特征空间进行了较弱的假设,适用于处理大规模的文本分类问题。
隐马尔可夫模型(HMM)是一种统计模型,常用于语音识别、机器翻译等NLP任务中。
HMM假设系统是一个由不可观察的隐含状态和观测到的可见状态组成的过程,通过观察到的状态序列来估计最可能的隐含状态序列。
HMM广泛应用于词性标注、命名实体识别等任务中,具有较好的效果。
递归神经网络(RNN)是一种具有记忆能力的神经网络,适用于处理序列数据,如语言模型、机器翻译等NLP任务。
RNN通过引入循环结构,可以对序列中的上下文信息进行建模。
长短期记忆网络(Long Short-Term Memory,LSTM)是RNN的一种改进,通过引入门控机制解决了传统RNN存在的长期依赖问题,更适合处理长文本和复杂语义。
svmtrain函数

svmtrain函数svmtrain函数是用于训练支持向量机(Support Vector Machine, SVM)模型的函数。
SVM是一种监督学习算法,广泛应用于分类和回归问题。
此函数在MATLAB中实现了支持向量机模型的训练过程。
```matlabsvmStruct = svmtrain(training, group);```除了上述基本语法,svmtrain函数还支持以下扩展格式来自定义SVM模型的属性:```matlabsvmStruct = svmtrain(training, group, 'PropertyName', PropertyValue, ...);```其中,`PropertyName`是属性名称,可用于设置SVM模型的各种参数,`PropertyValue`是属性值。
下面是一些常用的属性和参数,用于自定义svmtrain函数的行为:- `'KernelFunction'`:设置核函数,用于将数据映射到高维空间。
可选的核函数有线性核函数(`'linear'`)、多项式核函数(`'polynomial'`)、径向基核函数(`'rbf'`)等。
默认值为线性核函数。
- `'BoxConstraint'`:设置软间隔的约束参数C。
较大的C会使分类器更关注错误样本的数量,而较小的C会使得分类器更关注错误样本的程度。
默认值为1- `'KernelScale'`:设置径向基核函数的尺度参数。
当使用径向基核函数时,可以通过该参数控制数据点的作用范围。
默认值为1.0。
- `'KernelScale'`:设置径向基核函数的尺度参数。
当使用径向基核函数时,可以通过该参数控制数据点的作用范围。
默认值为1.0。
- `'Method'`:设置优化求解方法。
支持向量机(SVM)简述

第1 2章12.1 案例背景12.1.1 SVM概述支持向量机(Support Vector Machine,SVM)由Vapnik首先提出,像多层感知器网络和径向基函数网络一样,支持向量机可用于模式分类和非线性回归。
支持向量机的主要思想是建立一个分类超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化;支持向量机的理论基础是统计学习理论,更精确地说,支持向量机是结构风险最小化的近似实现。
这个原理基于这样的事实:学习机器在测试数据上的误差率(即泛化误差率)以训练误差率和一个依赖于VC维数(Vapnik - Chervonenkis dimension)的项的和为界,在可分模式情况下,支持向量机对于前一项的值为零,并且使第二项最小化。
因此,尽管它不利用问题的领域内部问题,但在模式分类问题上支持向量机能提供好的泛化性能,这个属性是支持向量机特有的。
支持向量机具有以下的优点:①通用性:能够在很广的各种函数集中构造函数;②鲁棒性:不需要微调;③有效性:在解决实际问题中总是属于最好的方法之一;④计算简单:方法的实现只需要利用简单的优化技术;⑤理论上完善:基于VC推广性理论的框架。
在“支持向量”x(i)和输入空间抽取的向量x之间的内积核这一概念是构造支持向量机学习算法的关键。
支持向量机是由算法从训练数据中抽取的小的子集构成。
支持向量机的体系结构如图12 -1所示。
图12-1 支持向量机的体系结构其中K为核函数,其种类主要有:线性核函数:K(x,x i)=x T x i;多项式核函数:K(x,x i)=(γx T x i+r)p,γ>0;径向基核函数:K(x,x i )=exp(-γ∥x −x i ∥2), γ>0;两层感知器核函数:K(x,x i )=tanh(γx T x i+r )。
1.二分类支持向量机C - SVC 模型是比较常见的二分类支持向量机模型,其具体形式如下:1)设已知训练集:T ={(x 1,y 1),…,(x i ,y i )}∈(X ×Y )ι其中,x i ∈X =R n ,y i ∈Y ={1,-1}( i =1,2,…,ι);x i 为特征向量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
svmtrain和svmpredict简介
分类:SVM
本文主要介绍了SVM工具箱中svmtrain和svmpredict两个主要函数:
(1)model= svmtrain(train_label, train_matrix,
['libsvm_options']);
其中:
train_label表示训练集的标签。
train_matrix表示训练集的属性矩阵。
libsvm_options是需要设置的一系列参数,各个参数可参见《libsvm 参数说明.txt》,里面介绍的很详细,中英文都有的。
如果用
回归的话,其中的-s参数值应为3。
model:是训练得到的模型,是一个结构体(如果参数中用到-v,得到的就不是结构体,对于分类问题,得到的是交叉检验下的平均分类准确
率;对于回归问题,得到的是均方误差)。
(2)[predicted_label,
accuracy/mse,decision_values/prob_estimates]
=svmpredict(test_label, test_matrix, model,
['libsvm_options']);
其中:
test _label表示测试集的标签(这个值可以不知道,因为作预测的时候,本来就是想知道这个值的,这个时候,随便制定一个值就可以
了,只是这个时候得到的mse就没有意义了)。
test _matrix表示测试集的属性矩阵。
model 是上面训练得到的模型。
libsvm_options是需要设置的一系列参数。
predicted_label表示预测得到的标签。
accuracy/mse是一个3*1的列向量,其中第1个数字用于分类问题,表示分类准确率;后两个数字用于回归问题,第2个数字
表示mse;第三个数字表示平方相关系数(也就是说,如
果分类的话,看第一个数字就可以了;回归的话,看后两
个数字)。
decision_values/prob_estimates:第三个返回值,一个矩阵包含决策
的值或者概率估计。
对于n个预测样本、k类的问题,如果指
定“-b 1”参数,则n x k的矩阵,每一行表示这个样本分别
属于每一个类别的概率;如果没有指定“-b 1”参数,则为n
x k*(k-1)/2的矩阵,每一行表示k(k-1)/2个二分类SVM
的预测结果。
(3) 训练的参数
LIBSVM训练时可以选择的参数很多,包括:
-s svm类型:SVM设置类型(默认0)
0 —C-SVC; 1 –v-SVC; 2 –一类SVM; 3 —e-
SVR;4 —v-SVR
-t 核函数类型:核函数设置类型(默认2)
0 –线性核函数:u’v
1 –多项式核函数:(r*u’v + coef0)^degree
2 –RBF(径向基)核函数:exp(-r|u-v|^2)
3 –sigmoid核函数:tanh(r*u’v + coef0)
-d degree:核函数中的degree设置(针对多项式核函数)(默认3)-g r(gamma):核函数中的gamma函数设置(针对多项式
/rbf/sigmoid核函数)(默认1/k,k为总类别数)
-r coef0:核函数中的coef0设置(针对多项式/sigmoid核函数)((默认0)
-c cost:设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1)
-n nu:设置v-SVC,一类SVM和v- SVR的参数(默认0.5)
-p p:设置e -SVR 中损失函数p的值(默认0.1)
-m cachesize:设置cache内存大小,以MB为单位(默认40)
-e eps:设置允许的终止判据(默认0.001)
-h shrinking:是否使用启发式,0或1(默认1)
-wi weight:设置第几类的参数C为weight*C (C-SVC中的C) (默认1)
-v n: n-fold交互检验模式,n为fold的个数,必须大于等于2
以上这些参数设置可以按照SVM的类型和核函数所支持的参数进行任意组合,如果设置的参数在函数或SVM类型中没有也不会
产生影响,程序不会接受该参数;如果应有的参数设置不正确,参数将采用默认值。