SPSS实验简单线性回归分析11
SPSS如何进行线性回归分析操作 精品

SPSS如何进行线性回归分析操作本节内容主要介绍如何确定并建立线性回归方程。
包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。
为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。
也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。
另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。
一、一元线性回归分析用SPSS进行回归分析,实例操作如下:1.单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。
从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。
在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。
所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。
具体如下图所示:2.请单击Statistics…按钮,可以选择需要输出的一些统计量。
如RegressionCoefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。
Model fit 项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。
上述两项为默认选项,请注意保持选中。
设置如图7-10所示。
设置完成后点击Continue返回主对话框。
回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。
由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。
3.用户在进行回归分析时,还可以选择是否输出方程常数。
线性回归spss分析

线性回归分析的具体步骤SPSS软件中进行线性回归分析的选择项为Analyze→Regression→Linear。
如图3.9所示。
下面通过例题介绍线性回归分析的操作过程。
图3.9 Regression 分析功能菜单例3. 仍然用例2的数据,考察火柴销售量与各影响因素之间的相关关系,建立火柴销售量对于相关因素煤气户数、卷烟销量、蚊香销量、打火石销量的线性回归模型,通过对模型的分析,找出合适的线性回归方程。
解:建立线性回归模型的具体操作步骤如下:1、打开数据文件SY-9,单击Analyze ®Regression ® Linear打开Linear 对话框如图3.10所示。
2、从左边框中选择因变量Y进入Dependent 框内,选择一个或多个自变量进入Independent框内。
从Method 框内下拉式菜单中选择回归分析方法,有强行进入法(Enter),消去法(Remove),向前选择法(Forward),向后剔除法(Backward)及逐步回归法(Stepwise)五种。
本例中选择逐步回归法(Stepwise)。
图3.10 Linear Regression对话框3、单击Statistics,打开Linear Regression: Statistics对话框,可以选择输出的统计量如图3.11所示。
●Regression Coefficients栏,回归系数选项栏。
Estimates (系统默认): 输出回归系数的相关统计量:包括回归系数,回归系数标准误、标准化回归系数、回归系数检验统计量(t值)及相应的检验统计量概率的P值(sig)。
本例中只选择此项。
Confidence intervals:输出每一个非标准化回归系数95%的置信区间。
Covariance matrix: 输出协方差矩阵。
●与模型拟合及拟合效果有关的选择项。
Model fit是默认项。
能够输出复相关系数R、R2及R2修正值,估计值的标准误,方差分析表。
《SPSS统计分析》第11章 回归分析

返回目录
多元逻辑斯谛回归
返回目录
多元逻辑斯谛回归的概念
回归模型
log( P(event) ) 1 P(event)
b0
b1 x1
b2 x2
bp xp
返回目录
多元逻辑斯谛回归过程
主对话框
返回目录
多元逻辑斯谛回归过程
参考类别对话框
保存对话框
返回目录
多元逻辑斯谛回归过程
收敛条件选择对话框
创建和选择模型对话框
返回目录
曲线估计
返回目录
曲线回归概述
1. 一般概念 线性回归不能解决所有的问题。尽管有可能通过一些函数
的转换,在一定范围内将因、自变量之间的关系转换为线性关 系,但这种转换有可能导致更为复杂的计算或失真。 SPSS提供了11种不同的曲线回归模型中。如果线性模型不能确 定哪一种为最佳模型,可以试试选择曲线拟合的方法建立一个 简单而又比较合适的模型。 2. 数据要求
线性回归分析实例1输出结果2
方差分析
返回目录
线性回归分析实例1输出结果3
逐步回归过程中不在方程中的变量
返回目录
线性回归分析实例1输出结果4
各步回归过程中的统计量
返回目录
线性回归分析实例1输出结果5
当前工资变量的异常值表
返回目录
线性回归分析实例1输出结果6
残差统计量
返回目录
线性回归分析实例1输出结果7
返回目录
习题2答案
使用线性回归中的逐步法,可得下面的预测商品流通费用率的回归系数表:
将1999年该商场商品零售额为36.33亿元代入回归方程可得1999年该商场 商品流通费用为:1574.117-7.89*1999+0.2*36.33=4.17亿元。
线性回归—SPSS操作

线性回归(异方差的诊断、检验和修补)—SPSS操作首先拟合一般的线性回归模型,绘制残差散点图。
步骤和结果如下:为方便,只做简单的双变量回归模型,以当前工资作为因变量,初始工资作为自变量。
(你们自己做的时候可以考虑加入其他的自变量,比如受教育程度等等)Analyze——regression——linear将当前工资变量拉入dependent框,初始工资进入independent点击上图中的PLOTS,出现以下对话框:以标准化残差作为Y轴,标准化预测值作为X轴,点击continue,再点击OK第一个表格输出的是模型拟合优度2R,为。
调整后的拟合优度为.第二个是方差分析,可以说是模型整体的显着性检验。
F统计量为,P值远小于,故拒绝原假设,认为模型是显着的。
第三个是模型的系数,constant代表常数项,初始工资前的系数为,t检验的统计量为,通过P值,发现拒绝原假设,认为系数显着异于0。
以上是输出的残差对预测值的散点图,发现存在喇叭口形状,暗示着异方差的存在,故接下来进行诊断,一般需要诊断异方差是由哪个自变量引起的,由于这里我们只选用一个变量作为自变量,故认为异方差由唯一的自变量“初始工资”引起。
接下来做加权的最小二乘法,首先计算权数。
Analyze——regression——weight estimation再点击options,点击continue,再点击OK,输出如下结果:由于结果比较长,只贴出一部分,第二栏的值越大越好。
所以挑出来的权重变量的次数为。
得出最佳的权重侯,即可进行回归。
Analyze——regression——linear继续点击save,在上面两处打勾,点击continue,点击ok这是输出结果,和之前同样的分析方法。
接下需要绘制残差对预测值的散点图,首先通过transform里的compute计算考虑权重后的预测值和残差。
以上两个步骤后即可输出考虑权重后的预测值和残差值然后点击graph,绘制出的散点图如下:。
线性回归—SPSS操作

线性回归—SPSS操作线性回归是一种用于研究自变量和因变量之间的关系的常用统计方法。
在进行线性回归分析时,我们通常假设误差项是同方差的,即误差项的方差在不同的自变量取值下是相等的。
然而,在实际应用中,误差项的方差可能会随着自变量的变化而发生变化,这就是异方差性问题。
异方差性可能导致对模型的预测能力下降,因此在进行线性回归分析时,需要进行异方差的诊断检验和修补。
在SPSS中,我们可以使用几种方法进行异方差性的诊断检验和修补。
第一种方法是绘制残差图,通过观察残差图的模式来判断是否存在异方差性。
具体的步骤如下:1. 首先,进行线性回归分析,在"Regression"菜单下选择"Linear"。
2. 在"Residuals"选项中,选择"Save standardized residuals",将标准化残差保存。
3. 完成线性回归分析后,在输出结果的"Residuals Statistics"中可以看到标准化残差,将其保存。
4. 在菜单栏中选择"Graphs",然后选择"Legacy Dialogs",再选择"Scatter/Dot"。
5. 在"Simple Scatter"选项中,将保存的标准化残差添加到"Y-Axis",将自变量添加到"X-Axis"。
6.点击"OK"生成残差图。
观察残差图,如果残差随着自变量的变化而出现明显的模式,如呈现"漏斗"形状,则表明存在异方差性。
第二种方法是利用Levene检验进行异方差性的检验。
具体步骤如下:1. 进行线性回归分析,在"Regression"菜单下选择"Linear"。
SPSS的线性回归分析分析

SPSS的线性回归分析分析SPSS是一款广泛用于统计分析的软件,其中包括了许多功能强大的工具。
其中之一就是线性回归分析,它是一种常用的统计方法,用于研究一个或多个自变量对一个因变量的影响程度和方向。
线性回归分析是一种用于解释因变量与自变量之间关系的统计技术。
它主要基于最小二乘法来评估自变量与因变量之间的关系,并估计出最合适的回归系数。
在SPSS中,线性回归分析可以通过几个简单的步骤来完成。
首先,需要加载数据集。
可以选择已有的数据集,也可以导入新的数据。
在SPSS的数据视图中,可以看到所有变量的列表。
接下来,选择“回归”选项。
在“分析”菜单下,选择“回归”子菜单中的“线性”。
在弹出的对话框中,将因变量拖放到“因变量”框中。
然后,将自变量拖放到“独立变量”框中。
可以选择一个或多个自变量。
在“统计”选项中,可以选择输出哪些统计结果。
常见的选项包括回归系数、R方、调整R方、标准误差等。
在“图形”选项中,可以选择是否绘制残差图、分布图等。
点击“确定”后,SPSS将生成线性回归分析的结果。
线性回归结果包括多个重要指标,其中最重要的是回归系数和R方。
回归系数用于衡量自变量对因变量的影响程度和方向,其值表示每个自变量单位变化对因变量的估计影响量。
R方则反映了自变量对因变量变异的解释程度,其值介于0和1之间,越接近1表示自变量对因变量的解释程度越高。
除了回归系数和R方外,还有其他一些统计指标可以用于判断模型质量。
例如,标准误差可以用来衡量回归方程的精确度。
调整R方可以解决R方对自变量数量的偏向问题。
此外,SPSS还提供了多种工具来检验回归方程的显著性。
例如,可以通过F检验来判断整个回归方程是否显著。
此外,还可以使用t检验来判断每个自变量的回归系数是否显著。
在进行线性回归分析时,还需要注意一些统计前提条件。
例如,线性回归要求因变量与自变量之间的关系是线性的。
此外,还需要注意是否存在多重共线性,即自变量之间存在高度相关性。
SPSS线性回归分析

SPSS分析技术:线性回归分析相关分析可以揭示事物之间共同变化的一致性程度,但它仅仅只是反映出了一种相关关系,并没有揭示出变量之间准确的可以运算的控制关系,也就是函数关系,不能解决针对未来的分析与预测问题。
回归分析就是分析变量之间隐藏的内在规律,并建立变量之间函数变化关系的一种分析方法,回归分析的目标就是建立由一个因变量和若干自变量构成的回归方程式,使变量之间的相互控制关系通过这个方程式描述出来。
回归方程式不仅能够解释现在个案内部隐藏的规律,明确每个自变量对因变量的作用程度。
而且,基于有效的回归方程,还能形成更有意义的数学方面的预测关系。
因此,回归分析是一种分析因素变量对因变量作用强度的归因分析,它还是预测分析的重要基础。
回归分析类型回归分析根据自变量个数,自变量幂次以及变量类型可以分为很多类型,常用的类型有:线性回归;曲线回归;二元Logistic回归技术;线性回归原理回归分析就是建立变量的数学模型,建立起衡量数据联系强度的指标,并通过指标检验其符合的程度。
线性回归分析中,如果仅有一个自变量,可以建立一元线性模型。
如果存在多个自变量,则需要建立多元线性回归模型。
线性回归的过程就是把各个自变量和因变量的个案值带入到回归方程式当中,通过逐步迭代与拟合,最终找出回归方程式中的各个系数,构造出一个能够尽可能体现自变量与因变量关系的函数式。
在一元线性回归中,回归方程的确立就是逐步确定唯一自变量的系数和常数,并使方程能够符合绝大多数个案的取值特点。
在多元线性回归中,除了要确定各个自变量的系数和常数外,还要分析方程内的每个自变量是否是真正必须的,把回归方程中的非必需自变量剔除。
名词解释线性回归方程:一次函数式,用于描述因变量与自变量之间的内在关系。
根据自变量的个数,可以分为一元线性回归方程和多元线性回归方程。
观测值:参与回归分析的因变量的实际取值。
对参与线性回归分析的多个个案来讲,它们在因变量上的取值,就是观测值。
SPSS操作:简单线性回归(史上最详尽的手把手教程)
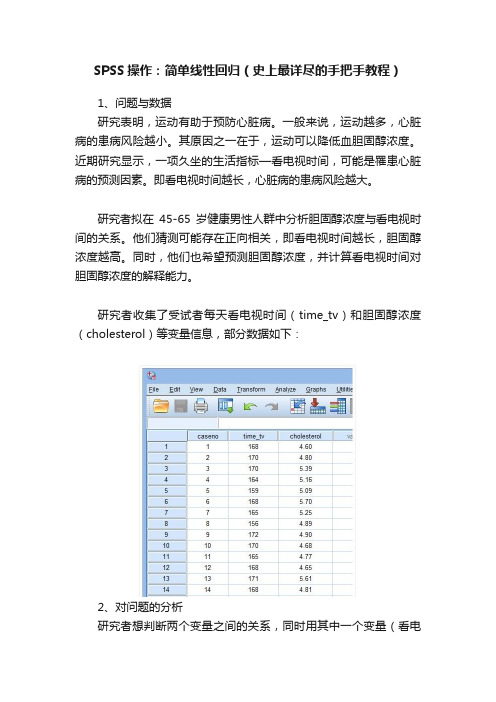
SPSS操作:简单线性回归(史上最详尽的手把手教程)1、问题与数据研究表明,运动有助于预防心脏病。
一般来说,运动越多,心脏病的患病风险越小。
其原因之一在于,运动可以降低血胆固醇浓度。
近期研究显示,一项久坐的生活指标—看电视时间,可能是罹患心脏病的预测因素。
即看电视时间越长,心脏病的患病风险越大。
研究者拟在45-65岁健康男性人群中分析胆固醇浓度与看电视时间的关系。
他们猜测可能存在正向相关,即看电视时间越长,胆固醇浓度越高。
同时,他们也希望预测胆固醇浓度,并计算看电视时间对胆固醇浓度的解释能力。
研究者收集了受试者每天看电视时间(time_tv)和胆固醇浓度(cholesterol)等变量信息,部分数据如下:2、对问题的分析研究者想判断两个变量之间的关系,同时用其中一个变量(看电视时间)预测另一个变量(胆固醇浓度),并计算其中一个变量(看电视时间)对另一个变量(胆固醇浓度)变异的解释程度。
针对这种情况,我们可以使用简单线性回归分析,但需要先满足7项假设:假设1:因变量是连续变量假设2:自变量可以被定义为连续变量假设3:因变量和自变量之间存在线性关系假设4:具有相互独立的观测值假设5:不存在显著的异常值假设6:等方差性假设7:回归残差近似正态分布那么,进行简单线性回归分析时,如何考虑和处理这7项假设呢?3、思维导图(点击图片可查看清晰大图)4、对假设的判断4.1 假设1和假设2因变量是连续变量,自变量可以被定义为连续变量。
举例来说,我们平时测量的反应时间(小时)、智力水平(IQ分数)、考试成绩(0到100分)以及体重(千克)都是连续变量。
在线性回归中,因变量(dependent variable)一般是指研究的成果、目标或者标准值;自变量(independent variable)一般被看作预测、解释或者回归变量。
假设1和假设2与研究设计有关,需要根据实际情况判断。
4.2 假设3简单线性回归要求自变量和因变量之间存在线性关系,如要求看电视时间(time_tv)和胆固醇浓度(cholesterol)存在线性关系。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Partial
Part
1
(Constant)
27.396
5.210
5.258
.000
16.449
38.342
期中成绩
.713
.061
.940
11.724
.000
.585Biblioteka .840.940.940
.940
a. Dependent Variable:总成绩
注释:这个表给出了包括常数项在内所有系数的检验结果并用了t检验同时给出了标准系数和非标准系数,由相应的P值可知道这些系数都是显著的。具有统计意义。拟合的 , ,所以所拟合的简单线性回顾方程为:
Variables Entered/Removedb
Model
Variables Entered
Variables Removed
Method
1
期中成绩a
.
Enter
a. All requested variables entered.
b. Dependent Variable:总成绩
注释:从这张表可以得出所选的自变量期中成绩是符合要求能够作为我们回归方程的自变量的。
Residual
105.204
18
5.845
Total
908.550
19
a. Predictors: (Constant),期中成绩
b. Dependent Variable:总成绩
由表可见回归模型的F统计量F=137.449,相应的P值为0.000,因此我们可以用的这个模型是显著的是有统计意义的。由于这里我们只用了一个自变量,所以模型的检验等价于系数的检验。
注释:从表中可得线性回归出来的相关系数为R=0.940,方程拟合优度R方为0.884,调整后的R方为0.878,说明所做的回归方程拟合度较好。
ANOVAb
Model
Sum of Squares
df
Mean Square
F
Sig.
1
Regression
803.346
1
803.346
137.449
.000a
Model Summaryb
Model
R
R Square
AdjustedR Square
Std. Error of the Estimate
Durbin-Watson
1
.940a
.884
.878
2.418
1.493
a. Predictors: (Constant),期中成绩
b. Dependent Variable:总成绩
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t
Sig.
95% Confidence Interval for B
Correlations
B
Std. Error
Beta
Lower Bound
Upper Bound
利用SPSS可以得出以下结果:
1,绘制散点图,判断变量之间是否存在相关关系:
由此我们可以初步判断出总成绩与期中成绩呈线性关系,该数据是适合建立简单线性回归模型的。
2,确定因变量与自变量,初步设定回归方程
以总成绩作为因变量,期中成绩作为自变量,建立简单的线性回归方程:
3,估计参数,确定估计的简单线性回归方程
简单线性回归分析(第十一个实验报告)
实验数据:
期中成绩
总成绩
93
89
62
70
84
89
89
92
94
93
93
95
94
96
82
84
86
84
75
83
72
80
76
83
91
91
83
82
90
93
80
86
91
94
79
85
94
96
97
98
问题提出:有上个实验结论我们可以知道期中成绩和总成绩有高度相关性但是具体的定量关系还没确定。是利用简单线性回归分析来定量的估计两者之间的回归方程。