第四章基本统计分析
SPSS第四章基本统计分析

中 0 500 0
高 0 0 600
一致
1 - 29
青 中 老
低 0 0 400
中 0 600 0
高 500 0 0
应用举例
受教育程度越高通信支出越高吗? 受教育程度越高通信支出比例越高吗?
1 - 30
多选项分析
什么是多选项问题?
(1)即:在回答某些问题时,答案在两个以上 例如:请问您平时主要的休闲娱乐方式是: a.看电视、听广播 b.玩游戏 c.体育运动 d.逛街购物e.经常去港澳游玩 f.看书学习 g.喝酒聊天 h.工作太忙,没时间休闲娱乐 又如:您经常浏览的网站?在下列品牌中您信任哪些 品牌? (2)多选项问题不能直接处理。因为SPSS中的一个变 量对每一个答案只能取一个值。
2 2
2
C
2
1 - 27
分析列联表中变量间的关系
Ordinal(定序变量)
反映定序变量一致性指标 行变量等级越高,列变量等级也越高或越低 ——一致性高 行变量等级越高,列变量等级不定——不一 致 指标绝对值越大越相关,越接近0越无关
1 - 28
定序变量一致性检验
年龄与工资收入交叉列联表 低 青 400 一致 中 0 老 0
n 3
3
计算描述统计量
描述陡峭程度的统计量
峰度(kurtosis):描述某变量所有变量值 分布形态陡缓程度的统计量。
峭度为0表示与正态分布峭度相同。 大于0表示比正态分布陡,尖峰。 小于0表示比正态分布缓;平峰。
Kurtosis
1 - 12
1 n -1
i 1 ( xi x) / SD 3
n 4 4
计算描述统计量
第4章-SPSS基本统计分析课件

– 通过频数分析,了解变量取值的状况,把握分布特 征。
– 通过频数分析,能够在一定程度上反映出样本是否 具有总体代表性,抽样是否存在系统偏差等,并以 此证明以后相关问题分析的代表性和可信性。
第4章-SPSS基本统计分析
目标一:计算存(取)款金额的基本描述统计量,并对 城镇储户和农村储户进行比较 (数据拆分)
目标二:分析储户一次存(取)款的数量是否存在不均 衡现象。
第4章-SPSS基本统计分析
目标二
基本描述统计
分析储户一次存(取)款的数量是否存在不均衡现象,
可以从分析金额是否有大量异常值入手。
实现方法:
数据标准化处理: zi (xi x)/S
第4章-SPSS基本统计分析
异常值的检测
99.73% 95.45% 68.27%
3 2
2 3 第4章-SPSS基本统计分析
2021/1/24
28
基本描述统计量
l 其他统计量
– 均值标准误差(S.E means)
l 中心极限定理认为:样本均值~N(u,2/n) l 反映样本均值与总体真值间的平均离散程度 l 样本数越大,样本均值的离散程度越小,对真
中 趋 势 栏
可反复操作键入多个百分
位数;
按Remove:删除已键入
的数值
离散趋
分布形态栏
按Change:重新输入新 数
势栏 输出统计量对话框 第4章-SPSS基本统计分析
频数分析
l 频数分析中的其他分析
– 分位数的应用
l 从一个侧面刻画了变量的取值分布状况
– 例:( QL=50,QU=75)
统计学-第四章 总量指标和相对指标

统计工作的第四个阶段——统计分析的基础
2020/1/10
引例
统计指标,无处不在。如≪中华人民共和国 2017年国民经济和社会发展统计公报≫中所说: “初步核算,全年国内生产总值827122亿元,比 上年增长6.9%。其中,第一产业增加值65468亿 元,增长3.9%;第二产业增加值334623亿元, 增长6.1%;第三产业增加值427032亿元,增长 8.0%。第一产业增加值占国内生产总值的比重为 7.9%,第二产业增加值比重为40.5%,第三产业 增加值比重为51.6%。如图4-1、图4-2所示。
50
第五年第3季至第四年第4季:52;
第五年第2季至第四年第3季:51;
第五年第1季至第四年第2季:50。
提前三个季度完成五年计划。
2(重点)
3.中长期计划任务的检查
累计法:计划任务数以累计数形式出现。可用于检查计 划执行情况。计算公式为:
计划完成相对指标
A.总产量520万元
B.净产值320万元
C.职工人数160万人
D.工人占职工人数的80%
5.2001年我国发行长期建设国债1500亿元;2001年末,居民个 人储蓄存款 余额突破75000亿元。这两个指标()
A.都是时期数 B.都是时点数 C.都是绝对数
D.前者是时点数,后者是时期数 E.前者是时期数,后者是 时点数
这些指标数据说明了2017年我国经济总量及增长速度、 价格情况、粮食产量、人口及就业等构成的发展状况。而这 些指标的涵义就是我们本章要学习的总量指标和相对指标所 涉及的内容。
2020/1/10
学习内容
1.总量指标 2.相对指标
学习重点
1.掌握绝对数和相对数的 特点及相应的计算方法
《统计分析与SPSS的应用(第五版)》课后练习答案解析(第4章)
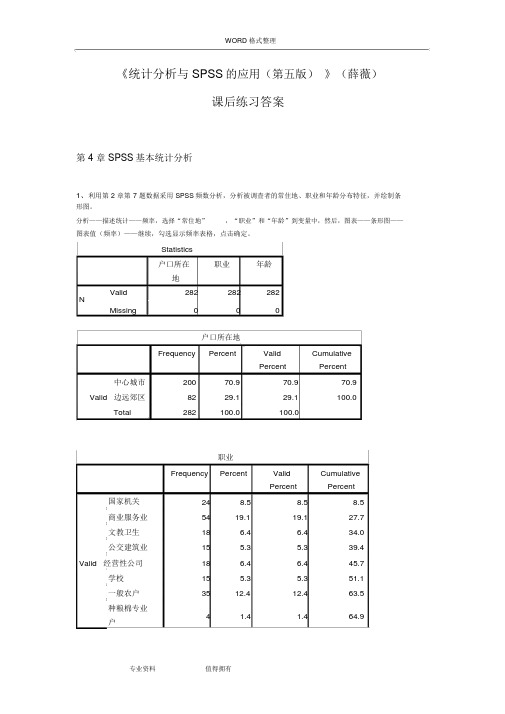
WORD 格式整理《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第 4 章 SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在职业年龄地Valid282282282NMissing000户口所在地Frequency Percent Valid CumulativePercent Percent中心城市20070.970.970.9 Valid 边远郊区8229.129.1100.0Total282100.0100.0职业Frequency Percent Valid CumulativePercent Percent 国家机关248.58.58.5商业服务业5419.119.127.7文教卫生18 6.4 6.434.0公交建筑业15 5.3 5.339.4Valid 经营性公司18 6.4 6.445.7学校15 5.3 5.351.1一般农户3512.412.463.5种粮棉专业4 1.4 1.464.9户WORD 格式整理种果菜专业10 3.5 3.568.4户工商运专业3412.112.180.5户退役人员17 6.0 6.086.5金融机构3512.412.498.9现役军人3 1.1 1.1100.0Total282100.0100.0年龄Frequency Percent Valid CumulativePercent Percent20 岁以下4 1.4 1.4 1.420~35 岁14651.851.853.2 Valid 35~50 岁9132.332.385.550 岁以上4114.514.5100.0Total282100.0100.0分析:本次调查的有效样本为282 份。
统计学基础第四章

4.2.4 比较相对指标
(一)概念 (二)计算公式
(一)概念
比较相对指标是将不同空间条件下同类 指标数值进行对比,反映同类事物在同 一时期不同空间条件下数量对比关系, 一般用百分数表示。也可以用倍数。
(二)计算公式
比较相对指标=某地区某一指标数值另一地区 同类指标数值×100%
随着研究目的的改变,比较指标的分子和分母 的数值可以对换。在经济管理工作中,将各单 位的技术经济指标与同类的先进水平对比,或 与规定的标准水平对比,便可找出差距。比较 相对指标的特点有:对比的分子与分母必须是 同质现象;分子、分母可互换。
2.时点指标(又称存量指标) 是反映现象处于某一时点上(某一时刻或某一瞬间)的数量水平。
例如,人口数、学校数、企业数、商店数、物资库存数量、银行 储蓄余额、牲畜存栏数等。时点指标有以下特点: (1)时点指标不能累计相加。因为,这种累计总量的重复计算没有 实际意义。例如,某班有学生45人。第一天统计实有45人,第二 天统计实有45人,但不能把两天实有人数加在一起说该班实有人 数为90人。 (2)时点指标数值的大小与时点的间隔长短没有直接关系。虽然时 点指标数值也会随着时间的变化而出现增减变动,但它与相邻时 点的间隔长短无关。例如,某种原材料的库存量多少只与原材料 的购进、拨出、消费等有关而与时间间隔无直接关系。 (3)时点指标是通过专门组织的一次性的全面调查所取得的标准时 点上的数值。
4.2 相对分析
4.2.1 相对指标 4.2.2 结构相对指标 4.2.3 比例相对指标 4.2.4 比较相对指标 4.2.5 强度相对指标 4.2.6 动态相对指标 4.2.7 计划完成相对指标
4.2.1 相对指标
(一)概念 (二)表现形式
(一)概念
第4章 SPSS基本统计分析(课后练习参考)

第4章 SPSS基本统计分析(课后练习参考)1、利用习题二第6题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用习题二第6题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用习题二第4题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用习题二第4题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用习题二第6题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
根据存款金额排序,观察其最大值与最小值,算出组数和组距。
统计学第四章 总量指标与相对指标分析

4 - 13
2、时点指标
时点指标是反映社会经济现象在某一时点(瞬间)上所 处状况的总量指标。如某一时点上的人口数、商品库存 数、牲畜存栏数、土地面积数等。 时点指标的特点 第一,不能累计相加。时点指标是表明现象在某一 时点上的状况,只能按时点所表示的瞬间计数, 若累计相加,所得到的结果包含着大量重复计算, 不仅脱离实际而且也没有任何意义。 第二,时点指标的大小与时点的间隔长短无直接关 系。如资产负债表中年末资产总额并不一定大于 月末资产总额。
资金 占用
资金利 润率
500 3000 16.7% 万元 万元 不可比 不可比 可比 5000 万元 40000 12.5% 万元
乙企业
4 - 28
比较两厂经济效益
3、相对指标的表现形式
无名数 分母 为1 有名数
4 - 29
用倍数、系数、成数、﹪、‰等表示
分母为 1.00
分母 为10
分母 为100
4 - 14
第三,时点指标数值是间断计数的。
14
2014-4-23
时 点 指 标
2009年年末国家外汇储备23992亿美元,比上年末增加4531亿美元。
4 - 15
时期指标和时点指标的区别:
⑴时期指标连续计数,时点指标间断计数 ⑵时期指标具有累加性,时点指标不具有累加性 ⑶时期指标数值大小与时期长短有直接关系,时点 指标数值大小与时期长短无直接关系。
第四章 总量指标和相对指标分析
4-1
第一节
总量指标分析
一、总量指标的概念和作用
二、总量指标的分类 三、总量指标的计算方法
4-2
一、总量指标的概念和作用
1、总量指标的概念 总量指标又称统计绝对数:是用来反映社会 经济现象在一定条件下的总规模、总水平 或工作总量的统计指标。 总产值、总人数 、国民生产总值等
统计学第4章综合指标

直接观察数据中出现次数最多的数。
平均指标在统计分析中应用
描述统计
用平均指标描述数据的集中 趋势和一般水平,如用算术 平均数描述班级学生的平均 成绩。
比较分析
通过比较不同组数据的平均 指标,揭示它们之间的差异 和联系,如比较不同班级的 平均成绩以评估教学效果。
推断统计
在总体分布未知的情况下, 利用样本平均指标对总体进 行推断,如通过样本均值推 断总体均值。
总量指标的作用
作为计算相对指标和平均指标的基础
描述社会经济现象的总规模和总水平
总量指标种类与计算方法
总量指标的种类
01
时点指标:反映现象在某一时刻上的总量 ,如年末人口数、股票价格等。
03
02
时期指标:反映现象在一段时期内的总量, 如国内生产总值、人口数等。
04
总量指标的计算方法
直接计数法:对总体单位进行逐一计数, 然后汇总得到总量指标。
相对指标种类与计算方法
结构相对指标
部分与总体之比,反映总
总体中不同部分数量之比,反映各部分之间的 比例关系。
比较相对指标
同一现象在不同空间条件下的数量对比,反映现象在不同地区的差异程度。
相对指标种类与计算方法
强度相对指标
两个性质不同但有一定联系的总量指标之比,反映现象的强度、密度和普遍程度。
平均指标种类与计算方法
算术平均数
$bar{x} = frac{sum x}{n}$,其中$sum x$为所有数值之和,$n$为 数值个数。
几何平均数
$G = sqrt[n]{prod x_i}$,其中$prod x_i$为所有数值之积,$n$为 数值个数。
中位数
将数据从小到大排列,若数据量为奇数则取中间数,若数据量为偶数 则取中间两数的平均值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
卡方检验的要求: 卡方检验的要求:
一般要求列联表中期望频数小于5 一般要求列联表中期望频数小于5的格子数 不超过20%,否则会夸大卡方值,容易得 不超过20%,否则会夸大卡方值,容易得 20% 出拒绝结论,可以采用精确检验。 N>=40, T>=5, Pearson卡方检验,若 Pearson卡方检验,若 P≈α,改用确切概率法检验 改用确切概率法检验 N<40,或 N<40,或T<5, 确切概率法检验
1-4
频数分析
应用举例
移动通话的漫游类型分析 特点:定类数据 使用频数、百分比、总数(不可缺少的) 不使用频数表中给出的累计频数和累计百分比 移动通话时间分析、移动客户话费分析 特点:定序数据、数量数据 除使用频数、百分比、总数外,还可以充分使 用累计频数和累计百分比
1-5
频数分析
数据中存在缺失值 使用有效百分比(分母为有效样本数) 例:学生成绩得优率、得良率 Frequencies->Format 频数分布表输出按变量值、频数升序、降 序输出
第四章 SPSS的基本统计分析 SPSS的基本统计分析
1-1
SPSS的基本统计分析 SPSS的基本统计分析
频数分析频数分析-对应表格法 计算描述统计量计算描述统计量-对应数值法 探索性描述分析探索性描述分析-结合 交叉分组下的频数分析 多选项分析 统计图统计图-对应图形法
1-2
频数分析
目的
粗略把握变量的总体分布状况。
1 - 11
n 1 Skewness = (xi x)3 / SD3 ∑i=1 n -1
计算描述统计量
描述陡峭程度的统计量
峰度(kurtosis):描述某变量所有变量值 峰度(kurtosis):描述某变量所有变量值 分布形态陡缓程度的统计量。
峭度为0 峭度为0表示与正态分布峭度相同。 大于0 大于0表示比正态分布陡,尖峰。 小于0 小数分析中的其他分析
计算中位数、分位数:适用于定序、定距数据 – 数据按升序排序后,找到若干个分位点上的变 量值 – quartiles:计算四分位数25%(QL)、50%(中位数)、 75%(QU) – cut points for n equal groups: n等份 – percentile: 自定义百分位点 计算众数:适用于定类数据(但必须是数值型)
数据标准化处理应用举例
快速找到移动话费出众的客户 网通集团企业效益评价
1 - 15
探索性描述分析
目的:在未知数据分布特点情况下,通过计算详尽描述统计量, 目的:在未知数据分布特点情况下,通过计算详尽描述统计量, 辅助全面的统计图, 辅助全面的统计图,认识数据分布。 基本操作步骤 (1)菜单选项:analyze->descriptive statistics->Explore (1)菜单选项:analyzestatistics(2)选择将参加计算的数值型变量名到Dependent list框 (2)选择将参加计算的数值型 数值型变量名到Dependent list框 (3)进行分组描述分析时,将分组变量选入Fact list框 (3)进行分组描述分析时,将分组变量选入Fact list框 描述统计量: M统计量:集中趋势的估计值,不受极端值影响。用于判断 有无异常值。
例:女生的学习成绩比男生好吗?(两变量) 例:女生的学习成绩比男生好吗?(两变量) 不同专业的女生学习成绩都比男生好吗? (三变量) 三变量)
分析的主要步骤
产生交叉列联表 分析列联表中变量间的关系
1 - 19
产生交叉列联表 产生交叉列联表
什么是列联表 多个变量在不同取值下的数据分布频数表
控制变量 列变量
例: 对某个问题的总体看法,如新业务的使用愿望、教学效 果等 对某事物的客观描述,如通话的漫游类型、大客户的行 业分布
采用的方法
制作频数分布表:包括计算 频数、累计频数、 百分比、累计百分比 绘制统计图形:条形图(品质数据)、饼图、 直方图(数量数据)
1-3
频数分析
基本操作步骤
(1)菜单选项:Analyze->Descriptive (1)菜单选项:AnalyzeStatistics->Frequencies tatistics(2)选择几个待分析的变量到variables框. (2)选择几个待分析的变量到variables框 (3)chart选项,选择所需要的图形 (3)chart选项,选择所需要的图形 例:班级男女生频数分布表、成绩分布表
(3)计算卡方统计量的值,并得到该统计量值 (3)计算卡方统计量的值,并得到该统计量值 的概率P 的概率P值 (4)决策。概率P与显著性水平比较,小于等 (4)决策。概率P 于则拒绝H 于则拒绝H0,否则不能拒绝
实现步骤
statistics选项 statistics选项 cells选项 cells选项
1 - 26
分析列联表中变量间的关系
行列变量相关性的其他测度指标 χ2 = n Nominal: phi系数:在2 phi系数:在2×2列联表中 ,通常[-1,1],负号 通常[ 1,1],负号 无实际意义 χ 列联C系数( 列联C系数(contingency coefficient), 通常 coefficient) χ +n 为[0,1) χ V= V系数 [0,1] n m r 1), (c 1)] in[( 值越大表示行列变量的相关性越大
1 - 13
计算描述统计量
基本操作步骤
(1)菜单选项:Analyze->Descriptive Statistics (1)菜单选项:AnalyzeStatistics ->Descripive (2)选择将参加计算的数值型变量名到Variables框。 (2)选择将参加计算的数值型 数值型变量名到Variables框。 ——仅适用于数值型 ——仅适用于数值型变量 数值型变量
1 - 21
产生交叉列联表 产生交叉列联表 定距数据可做适当分组后再产生列联表 仅利用频数,信息利用不充分
进一步计算
cells选 cells选项:选择在频数分析表中输出各种百 分比. 分比. row:行百分比( row:行百分比(Row pct); column:列百分比( column:列百分比(Col pct); total:总百分比( total:总百分比(Tot pct);
购买流行服装
交叉分组下的频数分析
针对定类数据和定序数据的频数分析( 针对定类数据和定序数据的频数分析(用于定类 定序数据分析有custom table\logistic\ 定序数据分析有custom table\logistic\loglinear) 目的: 目的:通过了解不同变量在不同水平下的数据 分布情况 ,判断水平对变量是否有影响
1 - 16
探索性描述分析
相关图形
箱线图 茎叶图 直方图 正态分布图:检验变量是否符合正态分布 方差齐性检验:各组离散程度是否相同
H0:方差相等 H0:方差相等
举例:两班学生成绩分布情况,离散程度 是否相同。
1 - 17
购买数量 多 少 列总计 个案数
全部样本 37.3% 62.7% 100% 1000
分析比较男生和女生的学习成绩
比较集中趋势 比较离散趋势 比较偏斜程度 比较陡峭程度 实现方式:数据拆分
1 - 14
计算描述统计量
其他功能
数据标准化处理
zi = (xi x) / SD
新变量的均值为0,标准差为1; 新变量的均值为0,标准差为1; 小于0表示在平均水平下,大于0反之. 小于0表示在平均水平下,大于0反之. 正态分布的数据标准化后呈标准正态分布(68%, 正态分布的数据标准化后呈标准正态分布(68%, 95%,99%) 95%,99%) save standardized values as variables选项 variables选项 将变量作标准化后,结果存入名为“Z+原变量名” 将变量作标准化后,结果存入名为“Z+原变量名” 的新变量中. 的新变量中.
购买数量 多 少 列总计 个案数
已婚者 31% 69% 100% 700
单身者 52% 48% 100% 300
男性 购买数量 已婚者 单身者 多 35% 40% 少 65% 60% 列总计 100% 100% 400 120 个案数
女性 已婚者 单身者 25% 60% 75% 40% 100% 100% 300 180
n 1 Kurtosis = ( xi x)4 / SD4 3 ∑i=1 n -1
1 - 12
计算描述统计量
其他统计量
均值标准误差( 均值标准误差(S.E means)
中心极限定理认为:样本均值~N(u,σ 中心极限定理认为:样本均值~N(u,σ2/n) 反映样本均值与总体真值间的平均离散 程度 样本数越大,样本均值的离散程度越小 ,对真值的估计越准确
计算描述统计量 描述对称程度的统计量
偏度(skewness):描述某变量所有变量 偏度(skewness):描述某变量所有变量 值分布形态的偏斜程度和方向的统计 量.
偏度为0表示对称; 偏度为0表示对称; 大于0表示正偏差大(右偏),众数比均值小, 大于0表示正偏差大(右偏),众数比均值小, 极值大于均值; 极值大于均值; 小于0表示负偏差大(左偏) 小于0表示负偏差大(左偏)。
1-7
频数分析
频数分析中的其他分析
分位数的应用
从一个侧面比较两组样本数据的集中趋势
– 例:( QL=50,QU=80) 和 (QL=70,QU=75) 的比较
在排除极端值影响的条件下,通过计算分位数差,比 较两组样本数据的离散程度
– 例: ( QL=50,QU=80) 和 (QL=70,QU=75) 的比较
(期望频数反映的是H0成立 情况下的数据分布特征)