第11章多重线性回归分析案例辨析及参考答案
线性回归分析与应用例题和知识点总结

线性回归分析与应用例题和知识点总结线性回归分析是一种广泛应用于统计学和机器学习领域的方法,用于研究两个或多个变量之间的线性关系。
它不仅在学术研究中发挥着重要作用,在实际生活中的各种领域,如经济、金融、医学、工程等,也有着广泛的应用。
接下来,让我们通过一些具体的例题来深入理解线性回归分析,并总结相关的知识点。
一、线性回归的基本概念简单来说,线性回归就是试图找到一条直线(在多个变量的情况下是一个超平面),使得数据点到这条直线的距离之和最小。
这条直线的方程通常可以表示为:y = b0 + b1x1 + b2x2 ++ bnxn ,其中 y是因变量,x1、x2、、xn 是自变量,b0 是截距,b1、b2、、bn 是回归系数。
二、线性回归的假设条件在进行线性回归分析时,通常需要满足以下几个假设条件:1、线性关系:自变量和因变量之间存在线性关系。
2、独立性:观测值之间相互独立。
3、正态性:误差项服从正态分布。
4、同方差性:误差项的方差在各个观测值上相同。
三、线性回归的参数估计常用的估计回归参数的方法是最小二乘法。
其基本思想是通过使观测值与预测值之间的误差平方和最小来确定回归系数。
例如,假设有一组数据:| x | y ||||| 1 | 2 || 2 | 4 || 3 | 5 || 4 | 7 || 5 | 8 |我们要建立 y 关于 x 的线性回归方程。
首先,计算 x 和 y 的均值:x= 3,ȳ= 5。
然后,计算 b1 =Σ(xi x)(yi ȳ) /Σ(xi x)²,b0 =ȳ b1x。
经过计算,b1 = 16,b0 =-08 ,所以回归方程为 y =-08 +16x 。
四、线性回归的评估指标1、决定系数(R²):表示回归模型对数据的拟合程度,取值范围在 0 到 1 之间,越接近 1 表示拟合越好。
2、均方误差(MSE):反映预测值与真实值之间的平均误差大小。
五、应用例题假设我们想要研究学生的学习时间(x)与考试成绩(y)之间的关系。
第11章第3成对数据的统计分析

基本思想、方法及其简单应用.
出线性回归直线
3.回归分析
(2)利用独立性检验判
了解回归的基本思想、方法及其简单应 断两个变量是否有关
用.
讲
课
人
:
邢
启
强
2
两个变量有关系,但又没有确切到可由其中的一个去精确地决
定另一个的程度,这种关系称为相关关系.
不一定是因果关系,也可能是伴随关系
3
1.散点图:成对样本数据都可用直角坐标系中的点表示出来,由这些点组
成了统计图.我们我们把这样的统计图叫做散点图
2.两个变量的线性相关
(1)正相关
在散点图中,点散布在从 左下角 到 右上角 的区域,对于两个变量的
这种相关关系,我们将它称为正相关.
(2)负相关
在散点图中,点散布在从 左上角 到 右下角 的区域,两个变量的这种
2
ˆ
(
y
y
)
i i
i 1
n
2
(
y
y
)
i
残差平方和
1
。
总偏差平方和
i 1
在使用经验回归方程进行预测时,需要注意下列问题:
(1)经验回归方程只适用于所研究的样本的总体,例如,根据我国父亲身高与儿子身高
的数据建立的经验回归方程,不能用来描述美国父亲身高与儿子身高之间的关系,同
样,根据生长在南方多雨地区的树高与胸径的数据建立的经验回归方程,不能用来描
,利用 χ2 的取值推断分类
(a+b)(c+d)(a+c)(b+d)
变量 X 和 Y 是否独立 的方法称为 χ2 独立性检验.
多元线性回归分析例题.doc
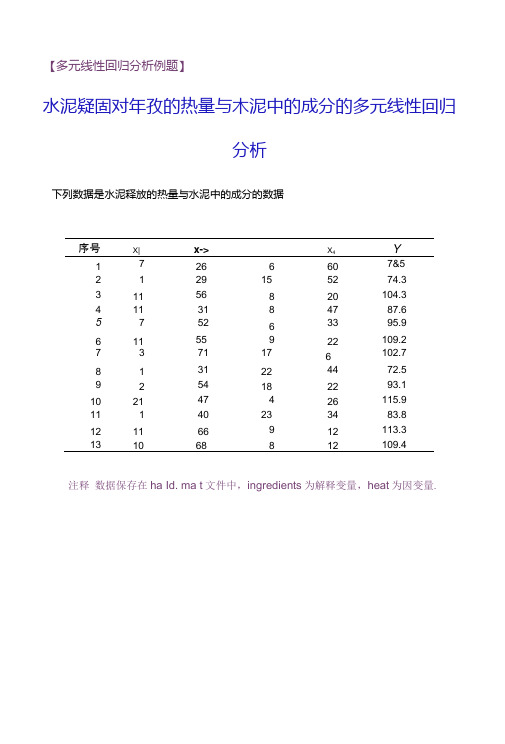
【多元线性回归分析例题】水泥疑固对年孜的热量与木泥中的成分的多元线性回归分析下列数据是水泥释放的热量与水泥中的成分的数据序号X|x->XY417266607&52129155274.331156820104.34113184787.6575263395.961155922109.27371176102.78131224472.59254182293.1102147426115.911140233483.8121166912113.3131068812109.4注释数据保存在ha Id. ma t文件中,ingredients为解释变量,heat为因变量.MATLAB数据处理与分析h MATLAB逐步回归法建模的交互式图形环境介绍【函数名称】st epwi se【函数功能】创 < 多元徭性回归分析的逐步回归廉建槌的交互式图形环疣.【调用格式】st epwi se( X. y)st epwi se( X. y, i nmodeI , pent er, pr emove)【参数说明】X 一p元线性樸型鮮释变量的n个观测值的nxp矩阵.y —p元筑性倏燮因变童的n个观删值的nxl向置.i nmodel 标量或向量(由X的列号构成J ,用来指明最初引入回归方程的鮮猝炙量(缺省设置为空丿.pent er —棋型松脸的显著性水平上喂值(缺不役11为O.O5丿.pr emcveb 一模型检验的显著性水平下限值(缺不设置为0.10丿.【案例中的应用】I oad hal dst epwi se( i ngr edi ent s, heat)【交互式图形界面的说明】窗口I Coef f i ci ent s wi t h Er r or Bar s绘岀各个解粹变量回归糸数的估计,圖点在示点估计值,横线表示置信区闷(冇色线段表示90%査信区间,黑色线段表示95%置信区间丿•窗口的右側给出回归糸数的点估计(Coeff).里著性检脸的t统计量的<i(t-stet)和显箸性觇半p <t(p-val).窗口U Model Hi story该窗口绘出的囿点表示禺次建核的模型标准差a的佶计.两个窗口中间输出的是当前模型的有关信息,包括:I nt er cept —栈燮對距(常数项丿的估计.RMSE —槿型标准弟(T的估计.R- squar e 可决糸数.Ad i - R- q n 提齐殆可池绕•站R- squar e 可决糸救.Adj・R- sq 校正的可决糸救.F —模型整体性检验的F统计量的值.p —槟型整体性松脸的显著性概札窗口I右侧的三个按钮:Next St ep 谥回归方程中按机关余数绝对值交小逐次列入解猝变量,如无解可狗入肘按钮不可用.Al I St eps 一直摟给出“只进不岀”方式建栈的最终结果(垃意,此对的回归方程未必是最优回归方程丿.Expor t ...-选择向Workspace传输的计算结果(有关变童老可由用户勺定义丿.2、MATLAB逐步回归冻建模的集成令令介绍【函数名称】st epwi set i t【函数功能】用還步回归空创建多元线性回归分析的最优回归方程..【调用格式】b = st epwi sef i t ( X, y)[b. se, pval ; i n mo del , stats, nextstep, hi story] = t epwi sef i t (...)[...]=stepwi sefit(X,y,' Paraml' ,val ue1,' Para m2' ,val ue2,...)【参数说明】输入参教.X与y的意义同出数stepwise.其它引用多数的用法请用doc命令调闻糸统犁助.输出多数b —僕型糸数.se —槌型糸救的标進祺農.pval —各个鮮释变量显著性松验的显著性覘率.i nmodel —各个解释jti•右.最终®归方租中地住的说明(1表示農方程中,0农示不再方程中丿・stats 一是一个构架数殂,包括:source :理.朕方法的说, 'stepwisefit'在示逐.步®7归出;source :建核方法的说朗,Mtepwisefit农示遵.步回归廉;dfe:最优回归方程的乗|余自由度;dfO:最优回归方程的回归勺由度;SStotal:最优回归方程的总偏差平方和;SSresid:最优回归方程的剩余平方和;fstat:最优冋归方程的P统计量的值;pval:最优回归方程的显著性概率;rmse:最优®归方程的标進谋差估计;B:模型糸数;SE:模型糸致的标准课差;TSTAT:毎金自变量显箸性检验的T统计量的值;PVAL:毎个自变量显著性检验的显著性概車;intercept:帝数项的A估计;等等.next st ep 对是否还有芻要引入他归方程的勺支童的说朗(0表示没有丿history —是一个构架数组,包括:rmse:务一步的棋型标;隹锲差越计;dfO:每一步引入方程的变量个教;in:记录了按和关纟救绝对值交小逐步引入回归方程的支童的次序.【案例中的应用】load hald;se,pval,inmodel,stats,nextstep,history]^stepwisefit(ingredients, heat, *penter*,・10)Initial columns 5eluded: noneStep 1.added column 4. p w0.000576232Step 2,added column 1. p=l.10528e-006Step 3.added column 2,p・0・0516873Step 4. removed column 4. p-0.205395 Final columns included: 1 2Columns 1 through 3•C oeff•f Std.Err.1•Status* [1.4683][0.1213]•Tn' [0.6623]【0.0459]•In1 [0.2500][0.1847]•Out* [■0.2365](0.1733]•Out1 Column 4•P'[2.6922e-007][5.0290e-008][ 0.2089][ 0.2054]b ■1.46830.66230・2500-0.2365se =0.12130.04590.18470.1733pval «0.00000.00000.20890.2054inmodel ■1 10 0stats -source:•stepwisefit'dfe:10dfC:2SStotal: 2.7158e*003SSresid:57.9045fst229.5037at:pval: 4 ・4066e-G09rmse: 2.4063xi:[13x2 double]y“[13x1 double]B|4xl double):SE[z lxl double]:TSTAT:I 4x1 double]PVAL(4x1 double):intercept:52.5773wasnar:113x1 logical) nextstep =history =rmse: 18.9639 2.7343 2.3087 2.4063)dfO: (1232]0.2089 in: (4x4 logical]。
管理统计学习题参考答案第十一章

十一章1. 解:回归分析是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;在线性回归中,按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多元线性回归分析。
相关分析,相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。
相关分析和回归分析是研究客观现象之间数量联系的重要统计方法。
既可以从描述统计的角度,也可以从推断统计的角度来说明。
所谓相关分析,就是用一个指标来表明现象间相互依存关系的密切程度。
所谓回归分析,就是根据相关关系的具体形态,选择一个合适的数学模型,来近似地表达变量间的平均变化关系。
它们具有共同的研究对象,在具体应用时,相关分析需要依靠回归分析来表明现象数量相关的具体形式,而回归分析则需要依靠相关分析来表明现象数量变化的相关程度。
只有当变量之间存在着高度相关时,进行回归分析寻求其相关的具体形式才有意义。
由于相关分析不能指出变量间相互关系的具体形式,所以回归分析要对具有相关关系的变量之间的数量联系进行测定,从而为估算和预测提供了一个重要的方法。
在有关管理问题的定量分析中,推断统计加具有更加广泛的应用价值。
需要指出的是,相关分析和回归分析只是定量分析的手段。
通过相关与回归分析,虽然可以从数量上反映现象之间的联系形式及其密切程度,但是现象内在联系的判断和因果关系的确定,必须以有关学科的理论为指导,结合专业知识和实际经验进行分析研究,才能正确解决。
因此,在应用时要把定性分析和定量分析结合起来,在定性分析的基础上开展定量分析。
线性回归方程.附答案docx

线性回归方程一、考点、热点回顾一、相关关系:1、⎩⎨⎧<=1||1||r r 不确定关系:相关关系确定关系:函数关系2、相关系数:∑∑∑===-⋅---=ni ini ini iiy y x x y y x x r 12121)()())((,其中:(1)⎩⎨⎧<>负相关正相关00r r ;(2)相关性很弱;相关性很强;3.0||75.0||<>r r3、散点图:初步判断两个变量的相关关系。
二、线性回归方程:1、回归方程:a x b yˆˆˆ+= 其中2121121)())((ˆxn x yx n yx x x y yx x bn i i ni ii n i i ni ii--=---=∑∑∑∑====,x b y aˆˆ-=(代入样本点的中心) 2、残差:(1)残差图:横坐标为样本编号,纵坐标为每个编号样本对应的残差。
(2)残差图呈带状分布在横轴附近,越窄模型拟合精度越高。
(3)残差平方和∑=-ni i iyy12)ˆ(越小,模型拟合精度越高。
3、相关指数:∑∑==---=n i ini i iy yyyR 12122)()ˆ(1(1)其中:∑=-ni i iyy12)ˆ(为残差平方和;∑=-ni i y y 12)(为总偏差平方和。
(2))1,0(2∈R ,越大模型拟合精度越高。
二、典型例题+拓展训练典型例题1:在一组样本数据),,,2)(,(),,(),,(212211不全相等n n n x x x n y x y x y x ≥的散点图中,若所有样本点),2,1)(,(n i y x i i =都在直线121+-=x y 上,则样本相关系数为( ) 21.21.1.1.--D C B A典型例题2:设某大学的女生体重)(kg y 与身高)(cm x 具有线性相关关系,根据一组样本数据)2,1)(,(n i y x i i =,用最小二乘法建立的回归方程为71.8585.0ˆ-=x y ,则不正确的是( )A.y 与x 具有正的线性相关关系;B.回归直线过样本点的中心),(y xC.若该大学某女生身高增加1cm,则其体重约增加0.85kgD.若该大学某女生身高为170cm,则可断定其体重必为58.79kg扩展2.一台机器使用时间较长,但还可以使用.它按不同的转速生产出来的某机械零件有一些会有缺点,每小时生产有缺点零件的多少,随机器运转的速度而变化,下表为抽样试(1)对变量y 与x 进行相关性检验;(2)如果y 与x 有线性相关关系,求回归直线方程;(3)若实际生产中,允许每小时的产品中有缺点的零件最多为10个,那么,机器的运转速度应控制在什么范围内?典型例题3.为了对x 、Y 两个变量进行统计分析,现有以下两种线性模型: 6.517.5y x =+,717y x =+,试比较哪一个模型拟合的效果更好.52211521()155110.8451000()i i i ii y y R yy ==-=-=-=-∑∑,221R =-521521()18010.821000()ii i ii yy y y ==-=-=-∑∑,84.5%>82%,所以甲选用的模型拟合效果较好.扩展1.下列说法正确的是( )(1)残差平方和越小,相关指数2R 越小,模型拟合效果越差; (2)残差平方和越大,相关指数2R 越大,模型拟合效果越好; (3)残差平方和越小,相关指数2R 越大,模型拟合效果越好; (4)残差平方和越大,相关指数2R 越小,模型拟合效果越差;A.(1)(2)B.(3)(4)C.(1)(4)D.(2)(3)扩展2.关于某设备的使用年限x (年)和所支出的维修费用y (万元)有下表所示的资料:若由资料知,y 对x 呈线性相关关系,求:(1)线性回归方程a x b yˆˆˆ+=中的回归系数b a ˆ,ˆ; (2)残差平方和与相关指数2R ,作出残差图,并对该回归模型的拟合精度作出适当判断; (3)使用年限为10年时,维修费用大约是多少?三、典型例题4.非线性回归模型:某公司为确定下一年度投入某种产品的宣传费,需了解年宣传费x (单位:千元)对年销售量y (单位:t )和年利润z (单位:千元)的影响,对近8年的年宣传费和年销售量(i=1,2,···,8)数据作了初步处理,得到下面的散点图及一些统计量的值。
多元线性回归模型的案例讲解
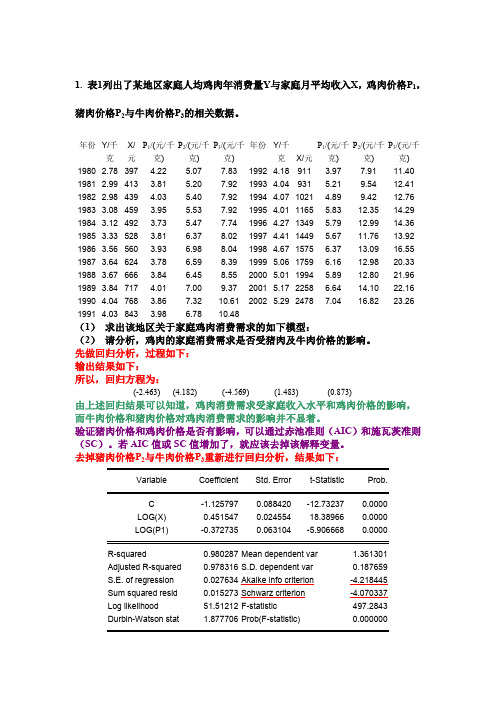
1. 表1列出了某地区家庭人均鸡肉年消费量Y与家庭月平均收入X,鸡肉价格P1,猪肉价格P2与牛肉价格P3的相关数据。
年份Y/千克X/元P1/(元/千克)P2/(元/千克)P3/(元/千克)年份Y/千克X/元P1/(元/千克)P2/(元/千克)P3/(元/千克)1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48(1)求出该地区关于家庭鸡肉消费需求的如下模型:(2)请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。
多元线性回归实习实际例题分析
多元线性回归分析实习线性回归过程(Linear Regression)可用于分析一个或多个自变量与一个因变量之间的线性数量关系,并可进行回归诊断分析。
●[例题3.1]某地29名13岁男童身高x1(cm),体重x2(kg),肺活量y(L)的实测值数据见表3.1,试建立肺活量与身高、体重的回归关系。
[ 操作过程]①[ 数据格式] 见数据文件< 多元线性回归例题.sav >该数据库有4列29行,即4个变量、29个记录(Observation),每个变量占1列,每个记录占1行,该数据格式为一般多元分析的数据格式。
②[ 过程]单击后可弹出线性回归对话框。
该对话框内有诸多选项,现分别介绍。
③[ 选项]◆因变量。
只能选入1个因变量,本例选入变量“肺活量”。
◆自变量。
可以是1个或多个,本例选入变量“身高、体重”。
◆当选择不同组合的自变量进行回归分析时,可保存每次选择的自变量,用按钮和按钮可分别向前、向后翻找各种自变量的组合。
◆选择回归模型拟合的分析方法,有5种可供选择。
Enter 强迫引入法,即一般回归分析,所选自变量全部进入方程,为系统默认方式。
Stepwise 逐步回归法,加入有显著性意义的变量和剔除无显著性意义的变量,直到所建立的方程式中不再有可加入和可剔除的变量为止。
Remove 强迫剔除法。
根据设定的条件剔除自变量。
Backward向后逐步法。
所选自变量全部进入方程,根据Options对话框中设定的标准在计算过程中逐个剔除变量,直到所建立的方程式中不再含有可剔除的变量为止。
Forward:向前逐步法。
根据Options对话框中设定的标准在计算过程中逐个加入单个变量,直到所建立的方程式中不再有可加入的变量为止。
◆选择符合某变量条件的观察单位进行分析,每次只能选入1位范围,有6种方式供选择,在Value框内输入设定值。
equal to 等于设定值。
not equal to不等于设定值。
less than小于设定值。
第11章多重线性回归分析思考与练习参考答案
0.674
5
0.795
0.809
1.734
1.715
0.549
0.654
6
0.787
0.779
1.509
1.474
0.782
0.571
7
0.933
0.880
1.695
1.656
0.737
0.803
8
0.799
0.851
1.740
1.777
0.618
0.682
9
0.945
0.876
1.811
三、计算题
为确定老年妇女进行体育锻炼还是增加营养会减缓骨骼损伤,一名研究者用光子吸收法测量了骨骼中无机物含量,对三根骨头主侧和非主侧记录了测量值,结果见教材表11-20。分别用两种桡骨测量结果作为反应变量对其他骨骼测量结果作多重线性回归分析,提出并拟合适当的回归模型,分析残差。
解:答案提示,需要对自变量进行筛选,而且要考虑是否存在多重共线性,如果存在,应进行适当的处理。
5.如何判断、分析自变量间的交互作用?
答:基于专业背景知识,构造可能的交互作用项,并检验交互作用项是否有统计学意义。
6.多重线性回归模型的基本假定有哪些?如何判断资料是否满足这些假定?如果资料不满足假定条件,常用的处理方法有哪些?
答:多重线性回归的前提条件是线性、独立性、正态性和等方差性,可以借助残差分析等方法判断资料是否满足条件。如果资料不满足前提条件,可以采用变量变换和非线性回归等方法处理。
19
0.856
0.786
1.390
1.324
0.578
0.610
20
0.890
0.950
2.187
多元线性回归参考答案
多元线性回归参考答案多元线性回归是统计学中一种常用的数据分析方法,它可以用来建立多个自变量与一个因变量之间的关系模型。
在实际应用中,多元线性回归被广泛用于预测、预测和解释变量之间的关系。
本文将介绍多元线性回归的基本概念、模型建立和解释结果的方法。
多元线性回归的基本概念是建立一个线性方程,其中有多个自变量和一个因变量。
方程的形式可以表示为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y表示因变量,X1、X2、...、Xn表示自变量,β0、β1、β2、...、βn表示回归系数,ε表示误差项。
回归系数表示自变量对因变量的影响程度,而误差项则表示模型无法解释的部分。
在建立多元线性回归模型之前,需要满足一些前提条件。
首先,自变量之间应该是线性关系,即自变量与因变量之间的关系可以用一条直线来表示。
其次,误差项应该是独立同分布的,并且服从正态分布。
最后,自变量之间不应该存在多重共线性,即自变量之间不应该有高度相关性。
建立多元线性回归模型的方法有很多,其中最常用的是最小二乘法。
最小二乘法的思想是通过最小化实际观测值与模型预测值之间的残差平方和来确定回归系数的估计值。
具体而言,通过求解最小化目标函数来得到回归系数的估计值。
目标函数可以表示为:min Σ(yi - (β0 + β1xi1 + β2xi2 + ... + βnxin))^2其中,yi表示第i个观测值的因变量的值,xi1、xi2、...、xin表示第i个观测值的自变量的值,β0、β1、β2、...、βn表示回归系数的估计值。
在得到回归系数的估计值之后,我们可以进行模型的解释和预测。
模型的解释可以通过回归系数的显著性检验来进行。
显著性检验可以判断回归系数是否与因变量存在显著的关联。
常用的显著性检验方法包括t检验和F检验。
t检验用于检验单个回归系数是否显著,而F检验用于检验整个模型是否显著。
模型的预测可以通过将自变量的值代入回归方程来进行。
贾俊平第四版统计学-第十一章一元线性回归练习答案
第十一章一元线性回归练习题答案二.填空题 1. 不能;因为该相关系数为样本计算出的相关系数,它的大小受样本数据波动的影响,它是否显著尚需检验;t 检验;2.图1;不能;因为图1反映的是线性相关关系,图2反映的是非线性性相关关系,相关系数只能反映线性相关变量间的相关性的强弱,不能反映非线性相关性的强弱。
三.计算题1.(1) SSR 的自由度是1,SSE 的自由度是18。
(2)2418/6080220/1/==-=SSE SSR F(3)判定系数%14.57140802===SST SSR R 在y 的总变差中,由57.14%的变差是由于x 的变动说引起的。
(4)7559.05714.02-=-=-=R r相关系数为-0.7559。
(5)线性关系显著和:线性关系不显著和y x y x H 10H :因为414.424=>=αF F,所以拒绝原假设,x 与y 之间的线性关系显著。
2.(1)方差分析表df SS MS F Significance F回归分析 1 425 425 85 0.017 残差 15 75 5 - - 总计16500---(2)判定系数%8585.05004252====SST SSR R表明在维护费用的变差中,有85%的变差可由使用年限来解释。
(3)9220.085.02===R r二者相关系数为0.9220,属于高度相关(4)x y248.1388.6ˆ+= 分布;显著。
的自由度为t n r n r t 2);12||2---=回归系数为1.248,表示每增加一个单位的产量,该行业的生产费用将平均增长1.248个单位。
(5)线性关系显著性检验:线性关系显著:生产费用和产量之间性关系不显著生产费用和产量之间线10:H H因为Significance F=0.017<05.0=α,所以线性关系显著。
(6)348.3120248.1388.6248.1388.6ˆ==⨯++=x y当产量为10时,生产费用为31.348万元。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第11章多重线性回归分析
案例辨析及参考答案
案例11-1预测人体吸入氧气的效率。
为了解和预测人体吸入氧气的效率,某人收集了31名中年男
性的健康调查资料。
一共调查了 7个指标,分别是吸氧效率(Y , %)、年龄(X1,岁)、体重(X2, kg )、
跑1.5 km所需时间(X3, min )、休息时的心跳频率(X4,次/min )、跑步时的心跳频率(X5,次/min)
和最高心跳频率(X6,次/min )(教材表11-9)。
试用多重线性回归方法建立预测人体吸氧效率的模型。
教材表11 -9 吸氧效率调查数据
Y X1 X2X3 X4 X5 X6 Y X1 X2X3 X4 X5 X6
44.609 44 89.47 11.37 62 178 182 40.836 51 69.63 10.95 57 168 172
45.313 40 75.07 10.07 62 185 185 46.672 51 77.91 10.00 48 162 168
54.297 44 85.84 8.65 45 156 168 46.774 48 91.63 10.25 48 162 164
59.571 42 68.15 8.17 40 166 172 50.388 49 73.37 10.08 67 168 168
49.874 38 89.02 9.22 55 178 180 39.407 57 73.37 12.63 58 174 176
44.811 47 77.45 11.63 58 176 176 46.080 54 79.38 11.17 62 156 165
45.681 40 75.98 11.95 70 176 180 45.441 56 76.32 9.63 48 164 166
49.091 43 81.19 10.85 64 162 170 54.625 50 70.87 8.92 48 146 155
39.442 44 81.42 13.08 63 174 176 45.118 51 67.25 11.08 48 172 172
60.055 38 81.87 8.63 48 170 186 39.203 54 91.63 12.88 44 168 172
50.541 44 73.03 10.13 45 168 168 45.790 51 73.71 10.47 59 186 188
37.388 45 87.66 14.03 56 186 192 50.545 57 59.08 9.93 49 148 155
44.754 45 66.45 11.12 51 176 176 48.673 49 76.32 9.40 56 186 188
47.273 47 79.15 10.60 47 162 164 47.920 48 61.24 11.50 52 170 176
51.855 54 83.12 10.33 50 166 170 47.467 52 82.78 10.50 53 170 172
49.156 49 81.42 8.95 44 180 185
资料来自:张家放主编•医用多元统计方法•武汉:华中科技大学出版社,2002。
该研究员采用后退法对自变量进行筛选,最后得到结果如教材表11-10所示。
教材表11-10 多重线性回归模型的参数估计
Table 11-10 Parameter estimati on of regressi on model
Variable
Un sta ndardized Coefficie nts Stan dardized
Coefficie nts t P
B Std. Error
In tercept 100.079 11.577 8.644 0.000 X1 -0.213 0.091 -0.214 -2.337 0.027 X3 -2.768 0.331 -0.721 -8.354 0.000 X5 -0.339 0.116 -0.653 -2.939 0.007 X6 0.255 0.132 0.439 1.936 0.064
* F 34.90, P 0.001 R2 0.843
对模型进行方差分析的结果认为模型有统计学意义(P<0.05),确定系数的数值(0.843)也说明模型
拟合的效果较好。
考察各个自变量的偏回归系数,研究者发现,X6的偏回归系数符号为正,认为最高心
跳频率越大,人的吸氧效率就越高,这与专业结论相反。
出现这种悖论的原因是什么呢?
案例辨析我们先分析一下各个自变量之间的简单相关系数,结果发现X5和X6存在有较强的相关
(r=0.930, P<0.001),对回归模型进行共线性诊断,结果发现自变量X5的容忍度为0.122,方差膨胀因子
等于8.188,自变量X6的容忍度为0.117,方差膨胀因子等于 8.522,说明自变量之间存在多重共线性,所以出现了与专业结论相反的现象。
正确做法在这里,我们可以把自变量X6从模型中删除以消除多重共线性的影响,应重新建立多重
线性回归方程。
最好多用几种筛选自变量的方法(如前进法、后退法、逐步回归分析、最优回归子集法等)筛选自变量,结合专业知识和统计学知识,综合分析和比较,从而得到比较优的多重回归方程。
案例11-2医院住院人数的预测石磊(1991)发表了其所在医院1970-1989年期间历年门诊人次X1、病床利用率X2、病床周转次数X3和住院人数Y的数据(教材表11-11),建立由X1、X2、X3预测Y的线性回归方程[中国卫生统计,1991,8(6)]。
下面列出了多重线性回归分析的主要结果(教材表11-12)。
教材表11-11 重庆医科大学附属第二医院1970-1989年若干统计资料
年份住院人数
Y
门诊人数/万人
X1
病床利用率/ %
X2
病床周转次数
X3
1970 6 349 49.8 94.25 19.84 1971 6 519 38.1 98.50 20.37
1972 5 952 36.6 89.86 18.80 1973 5 230 36.0 86.00 16.34
1974 5 411 32.3 83.29 16.91 1975 5 277 37.8 77.88 18.07
1976 3 772 34.1 92.62 17.96 1977 3 846 42.2 86.57 18.31
1978 3 866 38.1 84.29 18.41 1979 5 142 39.5 89.29 20.61
1980 7 724 55.8 97.63 21.72
1981 8 167 63.0 96.53 23.33 1982 8 107 65.2 93.43 21.91
1983 7 998 66.1 94.45 21.05 1984 7 331 65.4 93.03 19.96 1985 6 447 60.1 91.79 18.81 1986 4 869 56.9 88.94 15.82 1987 5 506 57.7 91.79 16.01
1988 5 741 53.4 99.03 16.59 1989 5 568 48.7 94.93 19.09
教材表11-12 多重线性回归模型的参数估计
Table 11-12 Parameter estimation of regression model
Variable -
Un sta ndardized Coefficie nts
Stan dardized P
Coefficie nts t
B Std. Error In tercept
-3219.628 1505.165
-2.139
0.047 X 1 59.834 15.780 0.512 3.792 0.001 X 3
327.553
85.725
0.515
3.821
0.001
* F 24.39, P 0.001
R 2
0.861
作者采用逐步回归的方法建立了门诊人数和病床周转次数关于住院人数的多重回归方程,得到表 11-12的结果,认为回归效果很好。
但是,读者小明作了残差分析图(教材图 11-4 ),认为回归效果不好。
请仲裁一下,到底谁对谁错?
1 5C0 - 1 000 - 50D -
0 -
-500 -
OCO -
-1 500
4 000
5000 6OT 7003
8000
r 的预测值
教材图11-4
残差分析图
案例辨析
作者采用逐步回归的方法建立了门诊人数和病床周转次数关于住院人数的多重回归方程。
从结果中可以看出,整个方程是有统计学意义的,各个总体偏回归系数不为零,确定系数等于
0.861,说
明回归的效果也很好。
但是,回头考虑资料是否适合进行多重线性回归分析,也就是资料是否满足多重回 归分析的前提条件 LINE ?于是,对回归分析的结果进行残差分析,
上面的残差图提示资料不满足方差齐性
的要求。
Durbin-Watson 统计量等于0.580,结果提示资料不满足独立性的要求。
其实,常识也认为同一 医院不同年份之间的数据不是独立的。
因此,可以认为本资料不满足多重线性回归分析的前提条件,不宜 进行多重线性回归分析。
正确做法 由于各年数据前后可能存在关联性,即其取值与时间有关,故可以考虑采用时间序列等分 析方法,此处从略。