TC数据模型
TC步骤-基于现状路段调查交通量进行OD反推的交通分配
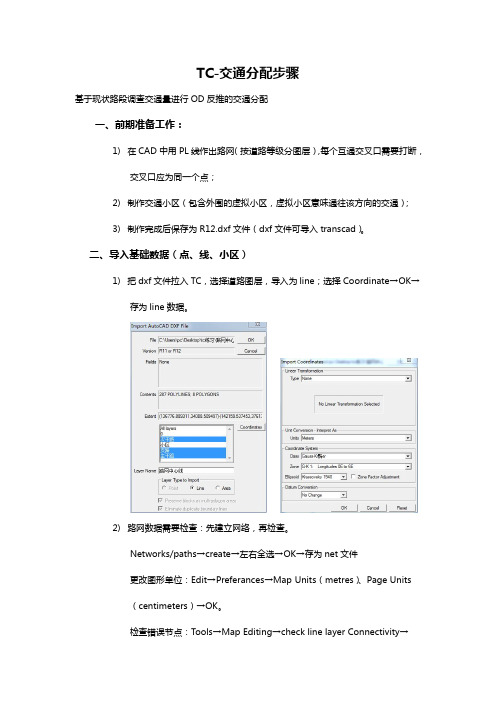
TC-交通分配步骤基于现状路段调查交通量进行OD反推的交通分配一、前期准备工作:1)在CAD中用PL线作出路网(按道路等级分图层),每个互通交叉口需要打断,交叉口应为同一个点;2)制作交通小区(包含外围的虚拟小区,虚拟小区意味通往该方向的交通);3)制作完成后保存为R12.dxf文件(dxf文件可导入transcad)。
二、导入基础数据(点、线、小区)1)把dxf文件拉入TC,选择道路图层,导入为line;选择Coordinate→OK→存为line数据。
2)路网数据需要检查:先建立网络,再检查。
Networks/paths→create→左右全选→OK→存为net文件更改图形单位:Edit→Preferances→Map Units(metres)、Page Units(centimeters)→OK。
检查错误节点:Tools→Map Editing→check line layer Connectivity→Threshold(1)→OK,发现错误节点。
错误节点一般在CAD中修改,少量可在TC中修改。
3)导入小区,把dxf文件拉入TC,选择小区图层,导入为area→取消Preserveblocks as multi-polygon area→OK→存为area数据。
关闭面图,留下线图,在线图里右键选择Layers→Add Layers→选择area 文件。
4)道路属性输入并分类:在线图层中选择属性表→Modify Table→Add field→道路名称/车速/行程时间/通行能力/型心ID/现状路段交通量(以现状调研为准)→OK。
Selection→Select by Condition→主干路/次干路/支路→选择主干路→车速(右键)→Fill→Single Value→设计速度→OK→行程时间(右键)→Formula→length/[车速]*3.6→OK。
5)小区编号输入:选择area图层→属性表→Modify Table→Add field(小区编号)→Tools里面选择→写入每个小区编号三、建立型心连杆1)这个过程要在线层和点层中新加元素,而且新的元素和旧的元素无差别,需要通过型心ID来相关联;2)选取点层和线层,增加型心ID属性(属性表→Modify→Add field(型心ID)),再保存net数据(路网数据实时更新);3)选取面层→Tools→Map Editing→Connect→Fill→Node field(型心ID)→line field(型心ID)→IDs from zone layer4)型心连杆可以自动连接,也需要手动添加:选取线层→移动型心→添加型心连杆→改写所添加连杆的型心ID→Tools里面选择→写入所添加连杆的型心编号点层→select→select by condition→型心ID>0.1→型心(name)线层→select→select by condition→型心ID>0.1→型心(name)5)编写型心连杆属性,个人建议型心连杆的属性参照支路标准,不要给的太高(防止经过性交通流取道连杆)。
TC解决方案

01.UG NX 和Teamcenter集成在装配导航器上显示列的方法02.如何将NX模板导入Teamcenter03.不能在My Teamcenter启动NX04.在MyTeamcenter Home树下如何列出数据集下命名的引用对象05.迁移NX PAX文件到Teamcenter站点06.在 Teamcenter与 NX集成环境中合并装配中相同的零部件到BOM07.高亮编辑结构管理器08.从“发送到”隐藏应用程序09.如何清理Teamcenter的数据库?10.Teamcenter临时卷的用途是什么?11.如何剔除已登录到Teamcenter系统的用户?12.登陆teamcenter后,点击模块无响应的解决方法13.Teamcenter和NX集成环境下,打开图纸报GD&T错误14.如何使用资源池和通用组 ID 指派任务到多个组?15.如何使用Dispatcher从NX中创建PDF16.如何删除被早期的装配零组件版本的序列使用的零组件或版本17.如何查看数据集命名引用文件的完整的文件卷路径18.登录teamcenter报错,不能正常加载模块19.NX8中产生的零件无法在TC9.1中打开,PLMXML could not be loaded20.如何设置多个应用程序共享一个TcServer进程21.在零件规划器中工艺关联产品22.怎样在安装完成 Teamcenter 后切换不同的语言?23.登录Teamcenter系统报错 IOException的解决方法24.如何向 Teamcenter 中导入 Non-Master非主模型数据集文件25.如果更改Teamcenter中使用的oracle用户infodba的密码26.如何使用最新版本的getcid.exe(V6.4)获取所有CID27.如何在windows服务器上配置JBoss服务?28.如何将大于 500 项的 LOV 的显示从组合框变为下拉列表29.Teamcenter中使用BMIDE如何定义度量单位30.Teamcenter BMIDE外部管理LOV( Batch LOV)管理教程31.在另存为或者修订零组件版本时,如何重命名数据集名字32.Teamcenter 登录报错,没有找到卷文件XXX.bin解决方案33.如何从Teamcenter中以NX Viewer的模式启动NX集成?34.使用dataset_cleanup和purge_datasets清理数据库35.在TC9以后的版本中如何启用和禁用客户端缓存36. 升级Teamcenter出错:Unable to unzip37.设置WhereReferencePOMPref=1 查看内部对象关系38. 设置teamcenter的Bebug选项,调用更多有用的信息39.如何在四层环境中,删除特定的用户的tcserver进程40.对所有的teamcenter用户设置UG NX装配加载选项41.teamcenter 如何通过一个 FCC 来连接多个 FSC42.Teamcenter站点重新restore时候发现install -ayt报错43.登录Teamcenter报错“'SOA_MaxOperationBracketTime'”44.如何为两层 IIOP 通信指定端口号45.从 Teamcenter10.1 开始移除 AIFDesktop.postPerspective46.查看已经安装的teamcenter模版的两种方法47.在汇总 XRT 中显示的关系/数据集类型/文件的优先顺序48.如何更改,配置,安装 FSC ID?49.用户登陆到teamcenter后, 发现 home 目录找不到解决方案50.Teamcenter 廋客户端报错 U000453:Unable to get managed connection51.teamcenter如何配置我的收藏夹查询52.使用fscadmin命令来查看fms的相关设置和状态 New53.如何在瘦客户端中列出所有的版本 New。
TC基础概念及应用
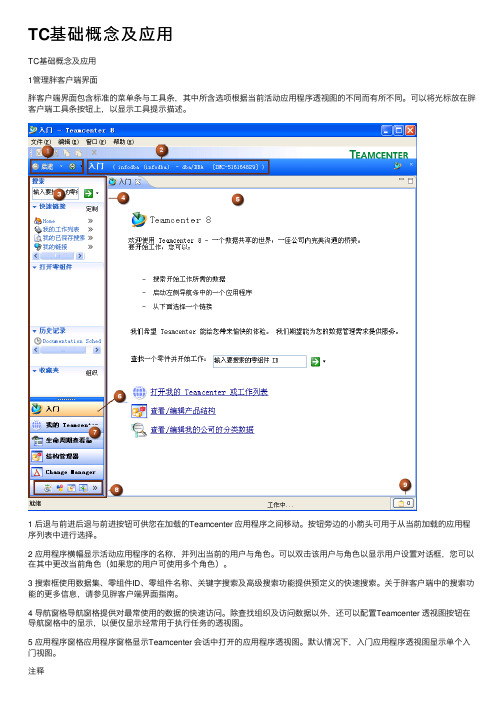
TC基础概念及应⽤TC基础概念及应⽤1管理胖客户端界⾯胖客户端界⾯包含标准的菜单条与⼯具条,其中所含选项根据当前活动应⽤程序透视图的不同⽽有所不同。
可以将光标放在胖客户端⼯具条按钮上,以显⽰⼯具提⽰描述。
1 后退与前进后退与前进按钮可供您在加载的Teamcenter 应⽤程序之间移动。
按钮旁边的⼩箭头可⽤于从当前加载的应⽤程序列表中进⾏选择。
2 应⽤程序横幅显⽰活动应⽤程序的名称,并列出当前的⽤户与⾓⾊。
可以双击该⽤户与⾓⾊以显⽰⽤户设置对话框,您可以在其中更改当前⾓⾊(如果您的⽤户可使⽤多个⾓⾊)。
3 搜索框使⽤数据集、零组件ID、零组件名称、关键字搜索及⾼级搜索功能提供预定义的快速搜索。
关于胖客户端中的搜索功能的更多信息,请参见胖客户端界⾯指南。
4 导航窗格导航窗格提供对最常使⽤的数据的快速访问。
除查找组织及访问数据以外,还可以配置Teamcenter 透视图按钮在导航窗格中的显⽰,以便仅显⽰经常⽤于执⾏任务的透视图。
5 应⽤程序窗格应⽤程序窗格显⽰Teamcenter 会话中打开的应⽤程序透视图。
默认情况下,⼊门应⽤程序透视图显⽰单个⼊门视图。
注释应⽤程序透视图由多个视图组成,这些视图可以移到Teamcenter 窗⼝的其他位置,也可以被拖⾄桌⾯。
这些拆离的视图仍然连接到Teamcenter,并与其他视图⼀起继续起作⽤。
6 ⼊门应⽤程序按钮提供对⼊门应⽤程序的访问。
7 主要应⽤程序主要应⽤程序按钮提供对最常⽤的Teamcenter 应⽤程序透视图的访问。
8 次要应⽤程序次要应⽤程序按钮提供对不常⽤的Teamcenter 应⽤程序透视图的访问。
9 剪贴板剪贴板包含对已从⼯作区剪切或复制的对象的引⽤。
剪贴板上的对象数量显⽰在图标右侧。
关于胖客户端中的剪贴板的更多信息,请参见胖客户端界⾯指南。
注释在Teamcenter 胖客户端应⽤程序中选择信息对象(如零组件)时,关于所选对象的信息显⽰在信息中⼼。
智能电网的数据模型标准

智能电网的数据模型标准
智能电网的数据模型标准
数据模型标准可以在智能电网架构模型的信息层表示。
将数据模型从通信协议和技术中解耦的概念,被越来越多地应用于电力系统相关的标准化工作中.通过引入的数据模型和通信服务之间的适配层[如IEC61850标准中的抽象通信服务接口(ACSI)],这使得可以灵活地应用不同的通信技术。
这一技术的独立性可确保数据模型的长期稳定,也为配合和利用通信技术的发展提供了可能性。
智能电网的数据模型标准可以分为四个语义域,其中包括收益计量和需求响应。
1)公共信息模型(CIM)的语义域,涵盖一系列标准,例如IEC61970,IEC61968和IEC62325(最后一个是特定的能源市场交易模型)。
2)IEC61850的语义域,覆盖现场层面的整个供电侧,在不久的将来,也将包括电动汽车充电站和智能用户接口的连接.
3)电量计量配套规范(COSEM—IEC62056)的数据交换模型主要为收益计量。
4)需求响应的数据交换模型,目前由IECTC57WG21工作组开发,致力于智能电网的智能用户接口。
智能电网中的应用案例越来越多地涉及不同语义域的数据交换。
为了使用标准来支持这个现象,IEC成立了专门的联合工作组,以便开发在IEC61850、CIM和COSEM数据模型之间进行互操作的规范。
thermo-calc(TC)模块介绍

Thermo-Calc
Thermo-Calc软件是由瑞典皇家工学院在Hillert, Sundman, Jansson等人的工作基础上,于1981年推出的相图和热力学计算软件。
经过将近30年的发展,Thermo-Calc软件现已成为数据齐全、功能强大、结构较为完整的计算系统,是目前世界上享有相当声誉的热力学计算软件。
利用Thermo-Calc软件可以做相平衡计算(如液相线及固相线温度、各相的成分及比例等)、相图计算及热力学量的计算,还可以将热力学数据制成表格、计算化学反应的热力学函数变化及驱动力、评价化学系统的相平衡及相转换,并且通过自动绘图程序绘制各种相图。
Thermo-Calc软件包括8个基本功能模块,6个特殊功能模块。
这些模块的名称及其主要功能见下表。
Thermo-Calc软件的模块和主要功能。
TCPIP四层模型

TCP /IP四层模型TCP/IP就是一组协议得代名词,它还包括许多协议,组成了TCP/IP协议簇。
TC P /IP协议簇分为四层,IP位于协议簇得第二层(对应OS I得第三层),TCP位于协议簇得第三层(对应OSI得第四层)。
TCP/ I P通讯协议采用了4层得层级结构,每一层都呼叫它得下一层所提供得网络来完成自己得需求。
这4层分别为:应用层:应用程序间沟通得层,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等。
传输层:在此层中,它提供了节点间得数据传送服务,如传输控制协议(TCP).用户数据报协议(UDP)等,TCP与UDP给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确左数据已被送达并接收。
互连网络层:负责提供基本得数据封包传送功能,让每一块数据包都能够到达目得主机(但不检查就是否被正确接收),如网际协议(1 P)。
网络接口层:对实际得网络媒体得管理,泄义如何使用实际网络(如Ether net、Seri a 1 Line等)来传送数据。
0 S I七层模型OSI(Open s y stem I n t erconn e ction,开放系统互连)七层网络模型称为开放式系统互联参考模型,就是一个逻辑上得泄义,一个规范,它把网络从逻借上分为了7层。
每一层都有相关、相对应得物理设备,比如路由器,交换机。
OSI七层模型就是一种框架性得设讣方法,建立七层模型得主要目得就是为解决异种网络互连时所遇到得兼容性问题,其最主要得功能使就就是帮助不同类型得主机实现数据传输。
它得最大优点就是将服务、接口与协议这三个概念明确地区分开来,通过七个层次化得结构模型使不同得系统不同得网络之间实现可靠得通讯。
图1 osi 七层结构模型优点建立七层模型得主要目得就是为解决异种网络互连时所遇到得兼容性问题。
它得最大 优点就是将服务、接口与协议这三个概念明确地区分开来:服务说明某一层为上一层提供一 些什么功能,接口说明上一层如何使用下层得服务,而协议涉及如何实现本层得服务;这样各 层之间具有很强得独立性,互连网络中各实体采用什么样得协议就是没有限制得,只要向上 提供相同得服务并且不改变相邻层得接口就可以了。
第3章关系数据模型(基本概念和ER转换)

返回
22
2.3关系的重要性质
1. 关系中属性的顺序是无关紧要的,即列的顺序可以任意交换。 交换时,应连同属性名一起交换,否则将得到不同的关系。
例如:关系T1作如下交换时,无任何影响,如下表所 示:
性别 男 女 男 姓名 李力 王平 刘伟
返回
23
而作如下交换时,不交换属性名,只交换属性列中的 值,则得到不同的关系,如下表:
一是只能表示1:N联系,虽然系统有多种辅助手段实现M:N联系但较复 杂,用户不易掌握; 二是由于层次顺序的严格和复杂,引起数据的查询和更新操作很复杂, 因此应用程序的编写也比较复杂。
返回
3
网状模型
用有向图结构表示实体类型及实体间联系的数据模型称为网状模 型(network model)。 网状模型的特点是:记录之间联系通过指针实现,M:N联系也容 易实现(一个M:N联系可拆成两个1:N联系),查询效率较高。 网状模型的缺点是:数据结构复杂和编程复杂。
返回
18
(5)域(Domain) 属性的取值范围,如年龄的域是(14~40),性别的域 是(男,女)。 (6)分量 每一行对应的列的属性值,即元组中的一个属性值, 如学号、姓名、年龄等均是一个分量。 (7)关系模式 对关系的描述,一般表示为:关系名(属性1,属性 2,……属性n),如:学生(学号,姓名,性别,年 龄,系别)。
姓名 男 女 男
性别 李力 王平 刘伟
返回
24
2. 同一属性名下的各个属性值必须来自同一个域,是同一类型的 数据(职业属性下面就应该是教师工人等,不能是男人女人)。 3. 关系中各个属性必须有不同的名字,不同的属性可来自同一个 域,即它们的分量可以取自同一个域。
TC知识点复习

TC知识点复习Chapter 11.产品数据管理(Product Data Management,PDM)是在现代产品开发环境中成长起来的一项以软件为基础的管理产品数据的新技术。
(Page1)2.PDM系统基本功能:电子仓库与文档管理、工作流与过程管理、系统定制与集成工具、零件分类管理、项目管理、产品结构与配置管理。
Page43.电子仓库与文档管理是PDM最核心的模块。
Page44.Teamcenter提供了两层(Two-Tier)和四层(Four-Tier)两种体系结构。
5.TC的两层结构包括客户端层和资源层。
客户端层包括以下几部分:胖客户端(RichClient)、Teamcenter服务和可执行程序、可选择的集成在胖客户端的应用程序。
资源层是通过运行环境存储持久数据和进行文件管理,包括以下三部分:数据库服务器和数据库、卷(Volumes)服务器、文件服务器。
6.TC四层结构包括客户端层(Client Tier)、Web层(Web Tier)、企业层(EnterpriseTier)和资源层(Resource Tier)。
每一层为其上一层提供所需的服务。
操作系统与数据库为最下层提供系统功能,而最上层则通过Web介面提供最终用户功能。
7.在四层结构中的客户端可以包括以下几部分:瘦客户端(Thin Client)、胖客户端(RichClient)、Teamcenter的网络文件夹、其他应用程序。
8.在四层机构中的Web层,通过Teamcenter服务器提供所有的Teamcenter功能,包括文档管理、产品结构管理、业务流程管理、文件输出等。
9.在四层结构中的资源层,即数据存取层,直接与操作系统和数据库进行交互操作,为Web层提供可靠的和高效能的数据存取、对象管理、文本搜索等基本功能。
资源层存储TC的持久数据和文件管理。
资源层包括:数据库服务器和数据库、标准件(Standard Volumes)、用于共享配置和二进制执行的文件服务。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
面板数据模型一、 面板数据的概念面板数据是时间序列数据和截面数据相结合的二维数据,为方面起见,暂且将之统称为TC 数据(即时间截面二维数据的意思),以我国31个省份1991-1999年的GDP 数据为例,则每一个年度称为一个截面,每个省份称为一个个体,每一个年度的31个省份的GDP 数据(31个)就是截面数据,每一个省份的9年的GDP 数据(9个)就是时间序列数据,即GDP 这个变量在时间维度有9个取值,在截面维度有31个取值,这些数据合在一起就是TC 数据,共31*9=279个。
如果每个截面包含相同数量的个体,则称之为平衡TC 数据,否则为非平衡TC 数据。
面板数据的主要优点有:1. 有利于降低多重共线性程度。
增加数据纬度的同时也增加了样本容量,样本容量增加可以增加变量之间的差异,降低变量间的相关程度,从而降低共线性程度。
2. 可以进行模型效应分析,更准确地理解统计结果的实际含义。
二、 面板数据模型的种类面板数据模型分为Pooled Data 模型和Panel Data 模型二类,Pooled Data 模型适用于研究时期较多个体较少的TC 数据,须为每个个体命名,研究目的侧重于个体差异或时期趋势;Panel Data 模型适用于研究个体较多、时期较少的TC 数据,不须为每个个体命名,研究目的侧重于由时期差异或个体推断总体。
另外,Pooled Data 模型允许各时期的个体不相同,Panel Data 模型要求各时期的个体相同。
例如: pooled datat=1:A B C D F t=2:A B D E panel datat=1:A B C D E t=2:A B C D E 三、 模型的基本形式 1. Pooled Data 模型it it it it it x y εβα++=,T t N i ,,1;,,1 ==…………① 2. Panel Data 模型()it it it it x f y εβα++=,T t N i ,,1;,,1 ==…………① 其中,()it x f β可以是非线性的。
比较分析:由于研究目的不同,所以前者允许系数可变,后者假定系数不变。
四、 模型形式的分类根据模型是否存在个体效应(即不同的个体是否有不同的模型),可分为效应模型和无效应模型两类,其中,Pooled Data 模型的效应模型又分为变系数模型和变截距模型两种;Panel Data 模型的效应模型只有变截距模型一种。
所以,Pooled Data 模型有3种,Panel Data 模型只有2种。
1. 效应模型(1) 变系数模型 如果对不同的i (t ),it α和it β都不相同,则称为个体(时期)效应变系数模型,可表示为:it it i i it x y εβα++=…………② 或:it it t t it x y εβα++=变系数模型等价于在模型中纳入“单独的个体哑变量项”和“个体哑变量与自变量的交叉项”来体现个体差异。
该模型用于描述:x 和y 的关系不仅在个体之间存在显著差异,而且x 对这种差异有显著影响,或者说,x 是产生这种差异的影响因素。
这种结论是普通回归模型难以得到的(因为代表个体的哑变量须设置很多“二分变量”)。
(2) 变截距模型 如果对不同的i (t ),只是it α不相同,但it β相同,则称为个体(时期)效应变截距模型,可表示为: it i it it y x u αβ=++…………③ 或:it it t it x y εβα++= 变截距模型等价于在模型中纳入“单独的个体哑变量项”来体现个体差异。
该模型用于描述:x 和y 的关系在不同个体存在显著差异。
2. 无效应模型如果对不同的i (t ),it α和it β都相同,则称为混合模型,可表示为: it it it y x u αβ=++…………④该模型用于描述:x 和y 的关系与个体或时期均无关。
模型效应包括固定效应和随机效应2种,当个体就是总体时,则称之为固定效应模型(FE );当个体是来自总体的随机样本时,则称之为随机效应模型(RE )。
对于平衡数据,Eviews 可以估计“双向FE”或“双向R E”,非平衡数据则不能。
五、 模型选择1. 模型形式选择(1) Pooled Data 模型形式选择-F 检验 1) 假设:01H :假设模型为变截距模型 02H :假设模型为混合模型 2) 统计量()()()2111/1/1S S N K F S N T K --⎡⎤⎣⎦=--⎡⎤⎣⎦~()()1,1F N K N T K ---⎡⎤⎣⎦()()()()3121/11/1S S N K F S N T K --+⎡⎤⎣⎦=--⎡⎤⎣⎦~()()()11,1F N K N T K -+--⎡⎤⎣⎦ 其中,S 1、S 2、S 3分别表示变系数模型、变截距模型和混合模型的残差平方和,N 是样本个数,K 是外生变量个数,T 是时期总数。
(注:S 1和S 2均采用FE 模型计算,可从回归结果中取得,然后手工计算F 1和F 1) 3) 检验规则 (A ) 如果F 2小于临界值(p 值大于0.05),则不否定H 02,应选择混合模型; (B ) 如果F 2、F 1均大于临界值(两个p 值均小于0.05),则否定H 02和H 01,应选择FE 变系数模型; (C ) 如果F 2大于临界值但F 1小于临界值(F 2的p 值小于0.05,但F 1FE 变截距模型。
[参考]F 检验的Eviews 操作:◊ 估计变系数模型(无约束模型),做F 检验(View/Fixed/Random Effects Testing/Redundant Fixed Effects- Likelihood Ratio 下同),P 值记为p1;估计变截距模型(相对混合模型而言,也是无约束模型),做F 检验,P 值记为p2。
◊ 当p1<临界值时,则否定“约束”,故采用变系数模型◊ 当p1>临界值,但p2<临界值时,则否定“截距”约束,但不否定“斜率”约束,故采用变截距模型 ◊ 当p1、p2都>临界值时,则不否定“截距”约束,也不否定“斜率”约束,故采用混合模型(2) Panel Data 模型形式选择- Likelihood Ratio 检验Panel Data 模型形式包括变截距模型(效应模型)和混合模型(无效应模型)两种。
1) 假设0H :模型为混合模型(约束模型),1H :模型为FE 变截距模型(未约束模型)2) 统计量()()()()k n nT n F k n nT S n S S F -------=,1~/1/112 式中,S 1、S 2分别表示FE 变截距模型和混合模型的残差平方和。
如果p 值小于0.05,则拒绝原假设,选择FE 变截距模型,反之则选择混合模型。
Eviews 操作:先估计FE 变截距模型,然后做Likelihood Ratio 检验(View/Fixed/Random Effects Testing/Redundant Fixed Effects – Likelihood Ratio.)。
如果P 值<0.05,则拒绝混合模型,接受FE 变截距模型。
注:(1)Panel data 模型的混合模型是在Panel Options 页的效应定义菜单中选择“None ”选项来设置。
(2)该检验也适合于Pooled Data 模型中的混合模型和FE 变截距模型之间的选择。
由于变系数模型太复杂,实际应用很少采用,因此一般只考虑是采用混合模型还是FE 变截距模型。
该检验也称为“F 检验”、“FE 显著性检验”等。
2. 模型效应选择前面在选择模型种类时都是按照FE 计算的,而RE 模型的含义更具有普遍性,所以如果可能的话,应尽量采用RE 模型的结果。
由于软件的局限,模型效应的选择目前只适合于变截距模型,不适合于变系数模型,变系数模型就不用选择了,一律采用FE 。
变截距模型效应可按照下列步骤选择: (1) 根据研究对象和目的不同作定性选择如果研究对象就是样本/个体本身,目的也是比较样本之间的特点,或样本量和时期数都较小时,则应选择FE ;如果研究对象是总体,目的是通过样本推断总体,则应选用RE 。
(2) Hausman 检验(RE 合理性检验)Eviews 操作:先估计RE 模型,然后做Hausman 检验(View/Fixed/Random Effects Testing/Correlated Random Effects - HausmanTest.)。
如果P值<0.05,则拒绝原假设“RE与解释变量不相关”,即拒绝采用RE模型。
参考:不相关的假设下,固定效应和随机效应模型是一致的,但固定效应不具有效性;反之,则随机效应模型不具一致性,而应采用固定效应模型。
六、模型估计1.异方差如果存在个体/时期异方差(例如,个体/时期个数大于时期/个体个数时),在Eviews中可选用“个体/时期加权回归法”(cross-section/period weight)估计模型。
2.自相关如果同时存在个体/时期异方差和自相关,在Eviews中可选用“个体/时期近似不相关加权回归法”(cross-section/period SUR)估计模型。
七、单位根检验和协整检验1.单位根检验共6种检验方法,按照原假设不同可分为三类:(1)假设存在相同单位根。
LLC(Levin, Lin & Chu),Breitung(2)假设存在不同的单位根。
IPS(Im, Pesaran, Shin),ADF-Fisher,PP-Fisher(3)假设不存在相同的单位根。
Hadri参考:只要有两种不同的单位根检验方法(相同根与不同根检验)检验结果不存在单位根就可以接受“序列平稳”,不要求所有检验都通过。
Eviews操作:在pool对象窗口中,View\Unit Root Test2.协整检验如果基于单位根检验的结果发现变量之间是同阶单整的,即可进行协整检验。
通过了协整检验,说明变量之间存在着长期稳定的均衡关系,其方程回归残差是平稳的。
因此可以在此基础上直接对原方程进行回归,此时的回归结果是较精确的。
Pedroni、Kao、Johansen的方法。
零假设是没有协整关系Eviews操作:在pool对象窗口中,View\Cointegration Test八、Eviews操作举例[例1]建立我国城镇居民消费函数的面板数据模型(数据文件:E:\zy\统计学\时间序列\ pooldata.wf1或paneldata.wf1)。
在excel中按如下格式输入数据,并保存为paneldata.xls。