SNN算法总结
脉冲神经网络研究进展综述

脉冲神经网络研究进展综述一、本文概述随着和机器学习的飞速发展,神经网络作为其中的核心组件,已经得到了广泛的研究和应用。
然而,传统的神经网络模型在处理复杂、动态和实时的任务时,由于其计算复杂度高、能耗大等问题,面临着巨大的挑战。
脉冲神经网络(Spiking Neural Networks,SNNs)作为一种新型的神经网络模型,以其独特的脉冲编码和传输机制,为解决这些问题提供了新的思路。
本文旨在全面综述脉冲神经网络的研究进展,包括其基本原理、模型设计、训练方法以及应用领域等方面。
我们将详细介绍脉冲神经网络的基本概念和脉冲编码机制,阐述其与传统神经网络的主要区别和优势。
然后,我们将回顾脉冲神经网络模型的发展历程,分析各种模型的特点和应用场景。
接着,我们将探讨脉冲神经网络的训练方法和学习机制,包括监督学习、无监督学习和强化学习等。
我们将展示脉冲神经网络在各个领域的应用实例,如图像识别、语音识别、机器人控制等,并展望其未来的发展方向。
通过本文的综述,我们希望能够为研究者提供一个清晰、全面的脉络,以了解脉冲神经网络的研究现状和发展趋势,为未来的研究提供有益的参考和启示。
我们也期望能够激发更多研究者对脉冲神经网络的兴趣和热情,共同推动这一领域的发展。
二、脉冲神经网络的基本原理脉冲神经网络(Spiking Neural Networks,SNNs)是一种模拟生物神经网络中神经元脉冲发放行为的计算模型。
与传统的人工神经网络(Artificial Neural Networks,ANNs)不同,SNNs的神经元通过产生和传递脉冲(或称为动作电位)来进行信息的编码和传输。
这种模型更接近生物神经元的实际运作机制,因此具有更强的生物可解释性和更高的计算效率。
在SNNs中,神经元的状态通常由膜电位(Membrane Potential)来表示。
当膜电位达到某个阈值时,神经元会发放一个脉冲,并将膜电位重置为静息状态。
脉冲的发放时间和频率都可以作为信息的编码方式。
各种聚类算法的比较

各种聚类算法的比较聚类的目标是使同一类对象的相似度尽可能地小;不同类对象之间的相似度尽可能地大。
目前聚类的方法很多,根据基本思想的不同,大致可以将聚类算法分为五大类:层次聚类算法、分割聚类算法、基于约束的聚类算法、机器学习中的聚类算法和用于高维度的聚类算法。
摘自数据挖掘中的聚类分析研究综述这篇论文。
1、层次聚类算法1.1聚合聚类1.1.1相似度依据距离不同:Single-Link:最近距离、Complete-Link:最远距离、Average-Link:平均距离1.1.2最具代表性算法1)CURE算法特点:固定数目有代表性的点共同代表类优点:识别形状复杂,大小不一的聚类,过滤孤立点2)ROCK算法特点:对CURE算法的改进优点:同上,并适用于类别属性的数据3)CHAMELEON算法特点:利用了动态建模技术1.2分解聚类1.3优缺点优点:适用于任意形状和任意属性的数据集;灵活控制不同层次的聚类粒度,强聚类能力缺点:大大延长了算法的执行时间,不能回溯处理2、分割聚类算法2.1基于密度的聚类2.1.1特点将密度足够大的相邻区域连接,能有效处理异常数据,主要用于对空间数据的聚类1)DBSCAN:不断生长足够高密度的区域2)DENCLUE:根据数据点在属性空间中的密度进行聚类,密度和网格与处理的结合3)OPTICS、DBCLASD、CURD:均针对数据在空间中呈现的不同密度分不对DBSCAN作了改进2.2基于网格的聚类2.2.1特点利用属性空间的多维网格数据结构,将空间划分为有限数目的单元以构成网格结构;1)优点:处理时间与数据对象的数目无关,与数据的输入顺序无关,可以处理任意类型的数据2)缺点:处理时间与每维空间所划分的单元数相关,一定程度上降低了聚类的质量和准确性2.2.2典型算法1)STING:基于网格多分辨率,将空间划分为方形单元,对应不同分辨率2)STING+:改进STING,用于处理动态进化的空间数据3)CLIQUE:结合网格和密度聚类的思想,能处理大规模高维度数据4)WaveCluster:以信号处理思想为基础2.3基于图论的聚类2.3.1特点转换为组合优化问题,并利用图论和相关启发式算法来解决,构造数据集的最小生成数,再逐步删除最长边1)优点:不需要进行相似度的计算2.3.2两个主要的应用形式1)基于超图的划分2)基于光谱的图划分2.4基于平方误差的迭代重分配聚类2.4.1思想逐步对聚类结果进行优化、不断将目标数据集向各个聚类中心进行重新分配以获最优解1)概率聚类算法期望最大化、能够处理异构数据、能够处理具有复杂结构的记录、能够连续处理成批的数据、具有在线处理能力、产生的聚类结果易于解释2)最近邻聚类算法——共享最近邻算法SNN特点:结合基于密度方法和ROCK思想,保留K最近邻简化相似矩阵和个数不足:时间复杂度提高到了O(N^2)3)K-Medioids算法特点:用类中的某个点来代表该聚类优点:能处理任意类型的属性;对异常数据不敏感4)K-Means算法1》特点:聚类中心用各类别中所有数据的平均值表示2》原始K-Means算法的缺陷:结果好坏依赖于对初始聚类中心的选择、容易陷入局部最优解、对K值的选择没有准则可依循、对异常数据较为敏感、只能处理数值属性的数据、聚类结构可能不平衡3》K-Means的变体Bradley和Fayyad等:降低对中心的依赖,能适用于大规模数据集Dhillon等:调整迭代过程中重新计算中心方法,提高性能Zhang等:权值软分配调整迭代优化过程Sarafis:将遗传算法应用于目标函数构建中Berkh in等:应用扩展到了分布式聚类还有:采用图论的划分思想,平衡聚类结果,将原始算法中的目标函数对应于一个各向同性的高斯混合模型5)优缺点优点:应用最为广泛;收敛速度快;能扩展以用于大规模的数据集缺点:倾向于识别凸形分布、大小相近、密度相近的聚类;中心选择和噪声聚类对结果影响大3、基于约束的聚类算法3.1约束对个体对象的约束、对聚类参数的约束;均来自相关领域的经验知识3.2重要应用对存在障碍数据的二维空间按数据进行聚类,如COD(Clustering with Obstructed Distance):用两点之间的障碍距离取代了一般的欧式距离3.3不足通常只能处理特定应用领域中的特定需求4、用于高维数据的聚类算法4.1困难来源因素1)无关属性的出现使数据失去了聚类的趋势2)区分界限变得模糊4.2解决方法1)对原始数据降维2)子空间聚类CACTUS:对原始空间在二维平面上的投影CLIQUE:结合基于密度和网格的聚类思想,借鉴Apriori算法3)联合聚类技术特点:对数据点和属性同时进行聚类文本:基于双向划分图及其最小分割的代数学方法4.3不足:不可避免地带来了原始数据信息的损失和聚类准确性的降低5、机器学习中的聚类算法5.1两个方法1)人工神经网络方法自组织映射:向量化方法,递增逐一处理;映射至二维平面,实现可视化基于投影自适应谐振理论的人工神经网络聚类2)基于进化理论的方法缺陷:依赖于一些经验参数的选取,并具有较高的计算复杂度模拟退火:微扰因子;遗传算法(选择、交叉、变异)5.2优缺点优点:利用相应的启发式算法获得较高质量的聚类结果缺点:计算复杂度较高,结果依赖于对某些经验参数的选择。
军事情报智能推荐算法综述

第12卷第2期2021年4月指挥信息系统与技术Command Information System and TechnologyVol.12No.2Apr.2021军事情报智能推荐算法综述王适之黄志良申远赵博(空军预警学院4系武汉430019)摘要:面对现代战场上复杂环境和海量情报信息,综述了军事情报推荐系统中应用的各种推荐算法的研究现状。
首先,阐述了目前在军事情报智能推送中应用的协同过滤推荐、基于内容的推荐和组合推荐3种推荐算法,介绍了各个算法的研究思路、算法模型和处理流程,分析了各个算法在军事情报智能推送中存在的问题;然后,探讨了深度学习在该类系统上的多种应用思路和不足;最后,在分析已有研究基础上,对未来的研究趋势进行了展望。
关键词:情报服务;推荐系统;协同过滤;基于内容;混合推荐中图分类号:TN957.51文献标志码:A文章编号:1674‑909X(2021)02‑0007‑09Review of Intelligent Recommendation Algorithm for Military Intelligence WANG Shizhi HUANG Zhiliang SHEN Yuan ZHAO Bo(The4th Department,Air Force Early Warning Academy,Wuhan430019,China)Abstract:Oriented to the complex environment of the modern battlefield and the massive informa‑tion,the research status of types of recommendation algorithms applied in the recommendation system for the military intelligence is summarized.Firstly,three kinds of present recommendation algorithms applied in the intelligent push of the military intelligence are expounded,including the collaborative fil‑tering recommendation,the content-based recommendation,and the hybrid recommendation.The re‑search idea,the model of the algorithm and the processing flow of each type of the algorithm are intro‑duced,and the problems of each type of the algorithm in the intelligent push of the military intelli‑gence are analyzed.Then,types of the application ideas and the deficiencies of the deep learning in the systems are discussed.Finally,based on the above analysis on the present research,the future devel‑op trend is expected.Key words:information service;recommendation system;collaborative filtering;content-based;hy‑brid recommendation0引言在情报服务过程中,情报分发位于情报收集和情报处理之后,属于情报服务流程的最末端,负责将生成好的情报送到情报用户手中。
基于随机森林和投票机制的大数据样例选择算法

2021⁃01⁃10计算机应用,Journal of Computer Applications 2021,41(1):74-80ISSN 1001⁃9081CODEN JYIIDU http ://基于随机森林和投票机制的大数据样例选择算法周翔1,2,翟俊海1,2*,黄雅婕1,2,申瑞彩1,2,侯璎真1,2(1.河北大学数学与信息科学学院,河北保定071002;2.河北省机器学习与计算智能重点实验室(河北大学),河北保定071002)(∗通信作者电子邮箱mczjh@ )摘要:针对大数据样例选择问题,提出了一种基于随机森林(RF )和投票机制的大数据样例选择算法。
首先,将大数据集划分成两个子集,要求第一个子集是大型的,第二个子集是中小型的。
然后,将第一个大型子集划分成q 个规模较小的子集,并将这些子集部署到q 个云计算节点,并将第二个中小型子集广播到q 个云计算节点。
接下来,在各个节点用本地数据子集训练随机森林,并用随机森林从第二个中小型子集中选择样例,之后合并在各个节点选择的样例以得到这一次所选样例的子集。
重复上述过程p 次,得到p 个样例子集。
最后,用这p 个子集进行投票,得到最终选择的样例子集。
在Hadoop 和Spark 两种大数据平台上实现了提出的算法,比较了两种大数据平台的实现机制。
此外,在6个大数据集上将所提算法与压缩最近邻(CNN )算法和约简最近邻(RNN )算法进行了比较,实验结果显示数据集的规模越大时,与这两个算法相比,提出的算法测试精度更高且时间消耗更短。
证明了提出的算法在大数据处理上具有良好的泛化能力和较高的运行效率,可以有效地解决大数据的样例选择问题。
关键词:大数据;样例选择;决策树;随机森林;投票机制中图分类号:TP181文献标志码:AInstance selection algorithm for big data based onrandom forest and voting mechanismZHOU Xiang 1,2,ZHAI Junhai 1,2*,HUANG Yajie 1,2,SHEN Ruicai 1,2,HOU Yingzhen 1,2(1.College of Mathematics and Information Science ,Hebei University ,Baoding Hebei 071002,China ;2.Hebei Key Laboratory of Machine Learning and Computational Intelligence (Hebei University ),Baoding Hebei 071002,China )Abstract:To deal with the problem of instance selection for big data ,an instance selection algorithm based on RandomForest (RF )and voting mechanism was proposed for big data.Firstly ,a dataset of big data was divided into two subsets :the first subset is large and the second subset is small or medium.Then ,the first large subset was divided into q smaller subsets ,and these subsets were deployed to q cloud computing nodes ,and the second small or medium subset was broadcast to q cloud computing nodes.Next ,the local data subsets at different nodes were used to train the random forest ,and the random forest was used to select instances from the second small or medium subset.The selected instances at different nodes were merged to obtain the subset of selected instances of this time.The above process was repeated p times ,and p subsets of selected instances were obtained.Finally ,these p subsets were used for voting to obtain the final selected instance set.The proposed algorithm was implemented on two big data platforms Hadoop and Spark ,and the implementation mechanisms of these two big data platforms were compared.In addition ,the comparison between the proposed algorithm with the Condensed Nearest Neighbor (CNN )algorithm and the Reduced Nearest Neighbor (RNN )algorithm was performed on 6large datasets.Experimental results show that compared with these two algorithms ,the proposed algorithm has higher test accuracy and smaller time consumption when the dataset is larger.It is proved that the proposed algorithm has good generalization ability and high operational efficiency in big data processing ,and can effectively solve the problem of big data instance selection.Key words:big data;instance selection;decision tree;Random Forest (RF);voting mechanism0引言在信息技术飞速发展的时代,不仅技术在快速发展,数据也在呈指数型上升。
基本算法2-递推法实例

一般地,设原来的符合题意的n-1条直线把这平面分成 个区域,再增加一条直线l,就变成n条直线,按题设条 件,这l必须与原有的n-1条直线各有一个交点, 且这n-1个交点 及原有的交点互不重合。这n-1个交点把l划分成n个区间,每 个区间把所在的原来区域一分为二,所以就相应比原来另增 了n个区域,即:
const max=100; var
f1,f2,s:array[1..max] of longint; i,j,k,l,n:longint; begin readln(n); f1[max]:=0 ; f1[max-1]:=1; {F0=10} for i:= 1 to n do
begin f2:=f1; k:=0; { ×7 } for j:= max downto 1 do begin k:=k+f1[j]*7; f1[j]:=k mod 10; k:=k div 10; end;
end.
var a,b:array[1..100] of longint; i,j,n:longint;
begin readln(n); a[100]:=4 ; b[100]:=1; for i:= 2 to n do begin for j:= 100 downto 1 do b[j]:=b[j]*2; for j:= 100 downto 2 do if b[j]>=10 then begin b[j-1]:=b[j-1]+b[j] div 10 ; b[j]:=b[j] mod 10; end; for j:= 100 downto 1 do begin a[j]:=a[j]+b[j]; if a[j]>=10 then begin a[j-1]:=a[j-1]+a[j] div 10 ; a[j]:=a[j] mod 10; end; end; end; j:=1; while a[j]=0 do j:=j+1; for i:= j to 100 do write(a[i]) ;
基于局部密度和相似度的自适应SNN算法
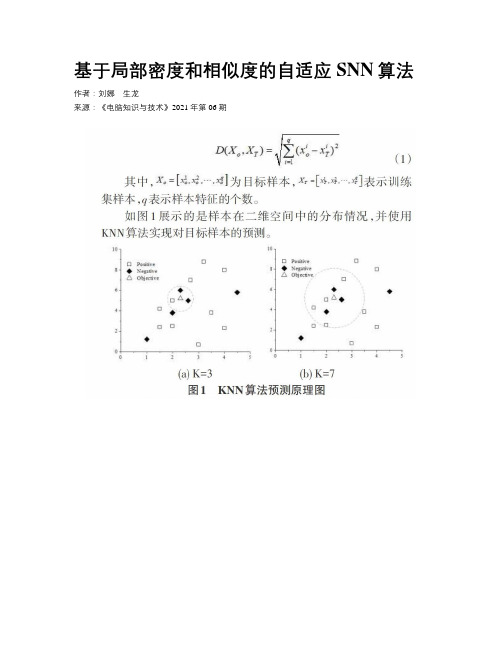
基于局部密度和相似度的自适应SNN算法作者:刘娜生龙来源:《电脑知识与技术》2021年第06期摘要:在近邻算法中,近邻样本和目标样本之间的绝对距离和相似性为目标样本类别的判断提供重要的决策依据,K值的大小也会直接决定了近邻算法的预测效果。
然而,SNN算法在预测过程中,使用固定的经验K值来预测不同局部密度的目标样本,具有一定的片面性。
因此,为实现SNN算法中K值的合理调节,提高算法的预测准确度和稳定性,提出一种基于局部密度和相似度的自适应SNN算法(AK-SNN)。
算法的性能在UCI数据集上进行验证,结果显示该算法取得优于KNN和SNN的预测效果和鲁棒性。
关键词:KNN;SNN;相似度计算;局部密度;自适应;AK-SNN中图分类号: TP301 文献标识码:A文章编号:1009-3044(2021)06-0006-04Abstract:In the nearest-neighbor algorithm, the absolute distance and similarity between the nearest-neighbor samples and the object sample provide significant decision basis for judging class of the object sample, and the size of K directly determines the prediction effect of the nearest-neighbor algorithm. However, in prediction process of SNN algorithm, it uses empirical K value selection topredict target samples with different local densities, which has some one-sidedness. Therefore, an adaptive SNN algorithm (AK-SNN) based on local density and similarity is proposed to realize reasonable adjustment of K in the SNN algorithm and improve the prediction accuracy and stability of the algorithm. The performance of the algorithm is verified on the UCI dataset, and the results show that the proposed algorithm achieves better prediction effect and robustness than KNN and SNN.Key words:KNN; SNN; similarity calculation; local density; AK-SNN引言近邻算法具有容易实现、训练时间短等特点,是一种高效实用的分类算法。
共享最近邻聚类算法流程
共享最近邻聚类算法流程
共享最近邻(Shared Nearest Neighbor, SNN)聚类算法是一种基于密度的聚类方法,其流程概要如下:
1. 计算样本间的距离,构建邻近矩阵,统计每个样本与其他样本的共享最近邻数目。
2. 根据预先设定的阈值,判断样本间的共享最近邻数量,若超过阈值则认为两者属于同一密度相连区域。
3. 逐步扩展密度相连区域,将紧密相连的样本聚为一类,形成聚类簇。
4. 在这个过程中不断更新邻近信息,直至所有样本都被分配至相应的聚类簇中。
该算法利用样本间的共享最近邻关系来发现数据集中的自然聚类结构,适用于发现任意形状和大小的聚类,但因其时间复杂度较高,不太适合大规模数据集。
脉冲强化学习总结(持续更新)
脉冲强化学习总结(持续更新)引⾔ 要将脉冲强化学习进⾏分类,⾸先要了解SNN学习算法以及强化学习本⾝的类别。
现代RL中⼀种⾮详尽但有⽤的算法分类法。
图⽚源⾃:OpenAI Spinning Up ()强化学习算法:参考⽂献:Model-Free vs Model-Based RL RL算法中最重要的分⽀点之⼀是智能体是否能够访问(或学习)环境模型的问题。
我们所说的环境模型是指预测状态转换和奖励的函数。
拥有⼀个模型的主要好处是,它允许智能体通过提前思考、看到⼀系列可能的选择会发⽣什么,并明确地在其选项之间做出决定来进⾏规划。
然后,智能体可以将预先规划的结果提取到⼀个学到的策略中。
这种⽅法的⼀个特别著名的例⼦是AlphaZero。
当这种⽅法起作⽤时,与没有模型的⽅法相⽐,它可以⼤⼤提⾼样本效率。
主要的缺点是,智能体通常⽆法使⽤环境的真实模型。
如果⼀个智能体想要在这种情况下使⽤⼀个模型,它必须完全从经验中学习模型,这会带来⼀些挑战。
最⼤的挑战是,模型中的偏差可以被智能体利⽤,从⽽导致智能体在学习模型⽅⾯表现良好,但在真实环境中表现得次优(或超级糟糕)。
模型学习从根本上说是很难的,所以即使是愿意投⼊⼤量时间和计算的巨⼤努⼒也可能没有回报。
使⽤模型的算法称为基于模型(model-based)的⽅法,不使⽤模型的算法称为⽆模型(model-free)⽅法。
虽然⽆模型⽅法放弃了使⽤模型在样本效率⽅⾯的潜在收益,但它们往往更易于实现和调整。
截⾄⽬前,与基于模型的⽅法相⽐,⽆模型⽅法更受欢迎,并且得到了更⼴泛的开发和测试。
What to Learn RL算法的另⼀个关键分⽀点是学习什么的问题。
通常的候选名单包括:策略,⽆论是随机的还是确定性的,动作-价值函数(Q函数),价值函数,和/或环境模型。
What to Learn in Model-Free RL 本⽂主要考虑⽆模型RL,使⽤⽆模型RL表⽰和训练智能体有两种主要⽅法:Policy Optimization. 这个族中的⽅法将策略显式表⽰为πθ(a|s)。
上交snn与目标检测的中文综述
上交SNN与目标检测的中文综述一、简介1.1 SNN(Spiking Neural Network)简介SNN是一种脉冲神经网络,与传统的神经网络模型不同,它采用了神经元的脉冲输出形式,模拟大脑中神经元的工作方式。
由于其良好的生物学实现性质和低功耗特性,SNN近年来受到了广泛关注。
1.2 目标检测简介目标检测是计算机视觉领域的一项重要任务,其目标是在图像或视频中识别并定位出特定物体的位置和类别。
目标检测技术在自动驾驶、智能视频监控、智能机器人等领域有着重要的应用价值。
二、 SNN在目标检测中的应用2.1 SNN与传统卷积神经网络(CNN)的比较传统的目标检测算法多基于CNN模型,而SNN作为一种新型的神经网络模型在目标检测任务中也有着独特的优势。
SNN具有较低的计算复杂度和功耗,更适合在嵌入式设备上部署,这使得SNN在移动端目标检测应用中具有巨大的潜力。
2.2 SNN在目标检测中的性能近年来,研究者们针对SNN在目标检测任务中展开了大量的实验与研究。
通过针对SNN架构的优化和改进,其在目标检测性能上取得了显著的提升,并逐渐逼近甚至超越了传统CNN模型在目标检测任务中的表现。
三、 SNN与目标检测的挑战与未来3.1 挑战尽管SNN在目标检测任务中取得了一定的进展,但其在精度、鲁棒性等方面仍然存在一定的挑战。
如何进一步优化SNN模型,提高其在目标检测中的性能,仍然是当前研究的重要课题。
3.2 未来随着人工智能和深度学习技术的不断发展,SNN作为一种新兴的神经网络模型必将迎来更多的关注和应用。
未来,SNN在目标检测领域的研究将会更加深入,相信其在该领域的应用潜力将会得到更好的发挥。
结语作为新兴的脉冲神经网络模型,SNN在目标检测任务中展现出了巨大的潜力。
随着研究者们对SNN模型的不断优化和改进,相信它将会在目标检测领域发挥重要的作用,为该领域的发展带来全新的机遇与挑战。
希望本篇综述能够对读者了解SNN与目标检测的相关内容有所帮助。
snn训练方法
snn训练方法SNN训练方法简介SNN(Spiking Neural Network)是一种仿真神经网络模型,模拟了生物神经元的放电过程。
它在神经科学研究以及人工智能领域具有广泛的应用。
本文将介绍一些常见的SNN训练方法。
方法一:Spike Time Dependent Plasticity (STDP)•STDP是一种基于突触前后神经元的活跃性时间差异调整突触连接权重的方法。
•当突触前神经元在突触后神经元放电之前激活时,突触的连接权重增加;反之则减少。
•STDP模型可以在模拟真实生物神经网络的时空特性的同时,提高SNN的学习能力。
方法二:Surrogate Gradient Learning (SGL)•SGL通过定义激活函数的形式,将SNN的离散时间信号转化为连续时间信号,从而使得可以使用基于梯度的训练算法。
•常用的激活函数包括Sigmoid、ReLU等。
•SGL让SNN可以借助常见的优化算法(例如梯度下降)进行训练,大大提高了训练效率。
方法三:Recurrent Spiking Network (RSNN)•RSNN是一种具有反馈连接的SNN模型,允许神经元之间的状态信息传递。
•通过引入反馈连接,RSNN可以处理序列数据以及非线性动力学任务。
•RSNN在时间序列预测、图像处理等领域有着广泛的应用前景。
方法四:Deep Spiking Neural Network (DSNN)•DSNN是一种深度结构的SNN模型,通过堆叠多个SNN层实现高级特征的抽取和多级的决策过程。
•DSNN可以通过逐层预训练和微调的方式进行训练,从而有效地解决梯度消失问题。
•DSNN在图像识别、自然语言处理等领域取得了令人瞩目的成果。
方法五:Liquid State Machine (LSM)•LSM是一种基于SNN的结构,模拟了大脑中的液态神经网络。
•LSM通过选择性地启用一部分神经元,并将输出通过一组固定的突触连接传递到下一层,来处理信息流。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Levent Ertoz等人提出了一种基于共享型邻居聚类算法SNN。
该算法的基本思想为:先构造相似度矩阵,再进行最近k邻居的稀疏处理,并以此构造出最近邻居图,使得具有较强联系的样本间才有链接。
然后统计出所有样本点的链接力度,以此确立聚类中心和噪声数据,将噪声数据从样本点中排除出来,并再次对图中的链接进行一次过滤。
最后依据确定的聚类中心和剩下的最近邻居图来进行聚类处理。
该算法有效地实现了对交通时空数据集的聚类,并具有很高的可伸缩性和处理噪音的能力,同时也具有对输入样本的顺序不敏感、输入参数的领域知识最小化等特点,但也存在以下不足之处:
(1) 孤立点的预处理不够,导致计算增多。
SNN算法对于孤立点的处理非常有限,必须直到对所有样本点建立了SNN图,并计算了所有样本点的链接力度之后才开始判断是否孤立点。
经过算法的复杂度分析,计算相似度矩阵和构造SNN图所需的复杂度最大,都是O(M2)。
因此,对孤立点的预处理不足,直接导致了过多的无谓计算。
(2) 用来确定代表点、孤立点、以及用于过滤链接力度的阈值没有明确定义。
虽然经过对样本数据的统计,能得出用于确定代表点、孤立点等的阈值,但由于统计步骤本身具有较大的时空复杂度,这无疑额外增加了整个算法的复杂度。
(3) 代表点的确定过程不够全面。
直接通过阈值来确定代表点的方法,存在一个问题:确定出来的代表点极有可能同属于或者部分同属于同一聚类中。
也就是说,几个代表点可能处于同一稠密区域内。
但对后期聚类来说,代表点最好能分散一点。
DBSCAN算法是一种基于密度的聚类算法,算法思想为:用户指定扫描半径eps和核心点阈值minpts,对于数据集中的任一个点a,计算该点与其他点的距离,计算距离的方法采用欧氏距离,如果在扫描半径范围内(以a为中心)点的个数超过minpts则该点为核心点,领域向该点a聚类。
其中a的邻域是指与a的距离不超过eps的点的集合。
DBSCAN算法适用于低维度的数据集,对于netflow这样多特征的数据类型,采用欧式距离显然不合适。
因为对于多维数据很可能存在距离较近但完全不相关的情况,比如(3,0,0,0,0,0,0,0)和(0,0,0,0,0,0,0,4)欧式距离为5,但没有相同的特征,如果聚类在一起则对结果分析产生误导。
因此对于多维数据不能将距离作为聚类的依据。
SNN算法适合多维数据的聚类,SNN算法是JP算法和DBSCAN算法的结合体,JP算法提供聚类的依据即SNN密度,DBCAN算法则根据SNN密度聚类。
SNN算法流程为:数据集→相似度矩阵→KNN算法稀疏矩阵→构造SNN图→计算SNN密度→DBSCAN聚类。