神经网络及应用第四章径向基函数神经网络
径向基函数神经网络模型及其在预测系统中的应用

径向基函数神经网络模型及其在预测系统中的应用传统的神经网络模型在处理非线性问题时存在一定的限制,而径向基函数神经网络(Radial Basis Function Neural Network,RBFNN)模型则能够有效地处理这类问题。
本文将介绍径向基函数神经网络模型的基本原理,并探讨其在预测系统中的应用。
1. 径向基函数神经网络模型的基本原理径向基函数神经网络模型是一种三层前馈神经网络,包含输入层、隐含层和输出层。
该模型通过将输入向量映射到高维特征空间,并利用径向基函数对输入数据进行非线性变换。
其基本原理如下:1.1 输入层:输入层接收原始数据,并将其传递给隐含层。
1.2 隐含层:隐含层中的神经元使用径向基函数对输入数据进行非线性变换。
径向基函数通常采用高斯函数,其形式为:φ(x) = exp(-(x-c)^2/2σ^2)其中,x为输入向量,c为径向基函数的中心,σ为径向基函数的宽度。
隐含层神经元的输出由径向基函数计算得到,表示了输入数据距离每个径向基函数中心的相似度。
1.3 输出层:输出层根据隐含层的输出和相应的权值进行计算,并生成最终的预测结果。
2. 径向基函数神经网络模型在预测系统中的应用径向基函数神经网络模型在各种预测系统中具有广泛的应用,包括金融预测、气象预测、股票价格预测等。
2.1 金融预测径向基函数神经网络模型能够对金融市场进行有效预测,例如股票价格、外汇汇率等。
通过输入历史数据,可以训练神经网络模型,利用其中的非线性变换能力来预测未来的价格走势。
实验表明,基于径向基函数神经网络模型的金融预测系统能够提供较高的准确度和稳定性。
2.2 气象预测径向基函数神经网络模型在气象预测中的应用也取得了良好的效果。
通过输入历史气象数据,神经网络模型可以学习到不同变量之间的关系,并预测未来的天气情况。
与传统的统计模型相比,径向基函数神经网络模型能够更好地捕捉到非线性因素对气象变化的影响,提高了预测的准确性。
BP神经网络和径向基神经网络

iii) Layer 1 Number of Neurons——隐层的神经元个 数,这是需要经验慢慢尝试并调整的,大致上由输入向 量的维数、样本的数量和输出层(Layer2)的神经元 个数决定。一般来说,神经元越多,输出的数值与目标 值越接近,但所花费的训练时间也越长,反之,神经元 越少,输出值与目标值相差越大,但训练时间会相应地 减少,这是由于神经元越多其算法越复杂造成的,所以 需要自己慢慢尝试,找到一个合适的中间点。 比如输入是3行5000列的0-9的随机整数矩阵,在一开 始选择1000个神经元,虽然精度比较高,但是花费的 训练时间较长,而且这样神经网络的结构与算法都非常 复杂,不容易在实际应用中实现,尝试改为100个,再 调整为50个,如果发现在50个以下时精度较差,则可 最后定为50个神经元,等等。
-0.024 0.344 0.2 2.344 0.3 3.262
为了比较径向基网络和BP网络设计所花费的时间, 程序如下。 创建和训练BP 网络的MATLAB 程序 %Example53Tr clear all ; p=-1:0.1:0.9; t=[-0.832 -0.423 -0.024 0.344 1.282 3.456 4.02 3.232 2.102 1.504 0.248 1.242 2.344 3.262 2.052 1.684 1.022 2.224 3.022 1.984]; tl = clock ;%计时开始 net = newff([-1 1],[15 1],{ 'tansig' 'purelin'},'traingdx','learngdm') ;
函数y=f(x) 的部分对应关系 x y x y -1 -0.832 0 0.248 -0.9 -0.423 0.1 1.242 -0.8 -0.7 -0.6 1.282 0.4 2.052 -0.5 3.456 0.5 1.684 -0.4 4.02 0.6 1.022 -0.3 3.232 0.7 2.224 -0.2 2.102 0.8 3.022 -0.1 1.504 0.9 1.984
径向基神经网络RBF介绍

径向基神经网络RBF介绍径向基神经网络(Radial Basis Function Neural Network,以下简称RBF神经网络)是一种人工神经网络模型。
它以径向基函数为激活函数,具有快速学习速度和较高的逼近能力,被广泛应用于函数逼近、模式识别、时间序列预测等领域。
下面将详细介绍RBF神经网络的基本原理、结构和学习算法。
1.基本原理:RBF神经网络由输入层、隐藏层和输出层组成。
输入层接收外部输入数据,隐藏层由一组径向基函数组成,输出层计算输出值。
其基本原理是通过适当的权值与径向基函数的线性组合,将输入空间映射到高维特征空间,并在该空间中进行线性回归或分类。
RBF神经网络的关键在于选择合适的径向基函数和隐藏层节点的中心点。
2.网络结构:隐藏层是RBF神经网络的核心,它由一组径向基函数组成。
每个径向基函数具有一个中心点和一个半径。
典型的径向基函数有高斯函数和多项式函数。
高斯函数的形式为:φ(x) = exp(-β*,x-c,^2)其中,β为控制函数衰减速度的参数,c为径向基函数的中心点,x为输入向量。
隐藏层的输出由输入向量与每个径向基函数的权值进行加权求和后经过激活函数得到。
输出层通常采用线性激活函数,用于输出预测值。
3.学习算法:RBF神经网络的学习算法包括两个步骤:网络初始化和权值训练。
网络初始化时需要确定隐藏层节点的中心点和半径。
常用的方法有K-means 聚类和最大极大算法。
权值训练阶段的目标是通过输入样本和对应的目标值来调整权值,使得网络的输出尽可能接近目标值。
常用的方法有最小均方误差算法(Least Mean Square,LMS)和最小二乘法。
最小均方误差算法通过梯度下降法修改权值,使网络输出的均方误差最小化。
最小二乘法则通过求解线性方程组得到最优权值。
在训练过程中,需要进行误差反向传播,根据输出误差调整权值。
4.特点与应用:RBF神经网络具有以下特点:-输入输出非线性映射能力强,可以逼近复杂的非线性函数关系;-学习速度较快,只需通过非线性映射学习输出函数,避免了反向传播算法的迭代计算;-具有较好的泛化能力,对噪声和异常数据有一定的鲁棒性。
径向基函数神经网络
入输出映射时,在相同逼近精度要求下,RBF所需的时间要比 MLP少。 具有唯一最佳逼近的特性,无局部极小。 合适的隐层节点数、节点中心和宽度不易确定。
径向基函数(RBF)
1.
Gauss(高斯)函数:r
exp
r2
2 2
2. 3.
反演S型函数: r
径向基函数 取统一的扩展常数
径向基函数的扩展常数 不再统一由训练算法确定
没有设置阈值
输出函数的线性中包含阈值参数, 用于补偿基函数在样本集上的
平均值与目标值之平均值之间的差别。
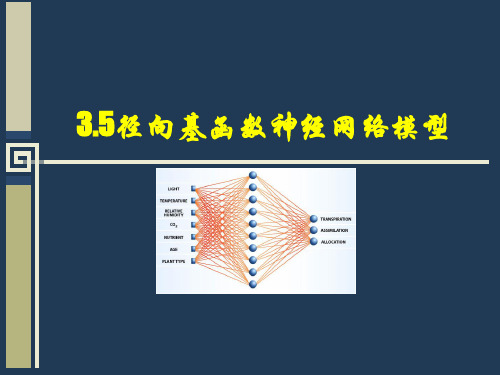
3.5.1 RBF神经网络模型
径向基神经网络的神经元结构
激活函数采用径向基函数
以输入和权值向量之间的 dis距t 离作为自变量
R ( dist )=e- dist 2
径向基神经网络结构
RBF网络与BP网络比较:
➢RBF网络的输出是隐单元输出的线性加权和, 学习速度加快
➢BP网络使用sigmoid()函数作为激活函数,这 样使得神经元有很大的输入可见区域
➢径向基神经网络使用径向基函数(一般使用 高斯函数)作为激活函数,神经元输入空间区 域很小,因此需要更多的径向基神经元
局部逼近网络 学习速度快,有可能满足有实时性要求的应用
对网络输入空间的某个局 部区域只有少数几个连接 权影响网络的输出,则称
该网络为局部逼近网络
RBF网络的工作原理
函数逼近: 以任意精度逼近任一连续函数。一般函数都可表示成一组 基函数的线性组合,RBF网络相当于用隐层单元的输出构 成一组基函数,然后用输出层来进行线性组合,以完成 逼近功能。
2.网络设计:设计一个径向基函数网络,网络有两层,隐含层 为径向基神经元,输出层为线性神经元。
径向基函数(RBF)神经网络

径向基函数(RBF)神经⽹络RBF⽹络能够逼近任意的⾮线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能⼒,并有很快的学习收敛速度,已成功应⽤于⾮线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。
简单说明⼀下为什么RBF⽹络学习收敛得⽐较快。
当⽹络的⼀个或多个可调参数(权值或阈值)对任何⼀个输出都有影响时,这样的⽹络称为全局逼近⽹络。
由于对于每次输⼊,⽹络上的每⼀个权值都要调整,从⽽导致全局逼近⽹络的学习速度很慢。
BP⽹络就是⼀个典型的例⼦。
如果对于输⼊空间的某个局部区域只有少数⼏个连接权值影响输出,则该⽹络称为局部逼近⽹络。
常见的局部逼近⽹络有RBF⽹络、⼩脑模型(CMAC)⽹络、B样条⽹络等。
径向基函数解决插值问题完全内插法要求插值函数经过每个样本点,即。
样本点总共有P个。
RBF的⽅法是要选择P个基函数,每个基函数对应⼀个训练数据,各基函数形式为,由于距离是径向同性的,因此称为径向基函数。
||X-X p||表⽰差向量的模,或者叫2范数。
基于为径向基函数的插值函数为:输⼊X是个m维的向量,样本容量为P,P>m。
可以看到输⼊数据点X p是径向基函数φp的中⼼。
隐藏层的作⽤是把向量从低维m映射到⾼维P,低维线性不可分的情况到⾼维就线性可分了。
将插值条件代⼊:写成向量的形式为,显然Φ是个规模这P对称矩阵,且与X的维度⽆关,当Φ可逆时,有。
对于⼀⼤类函数,当输⼊的X各不相同时,Φ就是可逆的。
下⾯的⼏个函数就属于这“⼀⼤类”函数:1)Gauss(⾼斯)函数2)Reflected Sigmoidal(反常S型)函数3)Inverse multiquadrics(拟多⼆次)函数σ称为径向基函数的扩展常数,它反应了函数图像的宽度,σ越⼩,宽度越窄,函数越具有选择性。
完全内插存在⼀些问题:1)插值曲⾯必须经过所有样本点,当样本中包含噪声时,神经⽹络将拟合出⼀个错误的曲⾯,从⽽使泛化能⼒下降。
径向基函数神经网络课件

小批量梯度下降算法
01
总结词
小批量梯度下降算法是一种折中的方法,每次使用一小批 样本来更新模型参数,既保持了计算量小的优点,又提高 了模型的稳定性。
02 03
详细描述
小批量梯度下降算法的核心思想是在每次迭代时,随机选 择一小批样本来计算损失函数,并使用梯度下降法或其他 优化方法来更新模型参数。这种方法可以平衡计算量和训 练时间的关系,同时提高模型的稳定性。
径向基函数神经网络课件
目 录
• 径向基函数神经网络概述 • 径向基函数神经网络的基本结构 • 径向基函数神经网络的学习算法 • 径向基函数神经网络的优化策略 • 径向基函数神经网络的实现细节 • 径向基函数神经网络的实例展示 • 总结与展望
01
径向基函数神经网络概述
神经网络简介
神经网络的定义
神经网络是一种模拟人脑神经元网络结构的计算模型,通过学习样 本数据来自动提取特征和规律,并完成分类、回归等任务。
02 03
详细描述
随机梯度下降算法的核心思想是在每次迭代时,随机选择一个样本来计 算损失函数,并使用梯度下降法或其他优化方法来更新模型参数。这种 方法可以大大减少计算量和训练时间。
优缺点
随机梯度下降算法的优点是计算量小,训练时间短,适用于大规模数据 集。但是,由于只使用一个样本进行更新,可能会造成模型训练的不稳 定,有时会出现训练效果不佳的情况。
2
输出层的节点数通常与输出数据的维度相等。
3
输出层的激活函数通常采用线性函数或softmax 函数。
训练过程
01
神经网络的训练过程是通过反向 传播算法实现的。
02
通过计算损失函数对网络权重的 梯度,更新权重以减小损失函数
径向基函数神经网络
11
径向基函数神经网络
内容提要
• 6.1 概述
• 6.2 径向基函数数学基础 • 6.3 径向基函数网络结构 • 6.4 RBF网络算法分析
RBF神经网络
• 径向基函数神经网络(radial basis function neural network,RBFNN) • RBF神经网络是基于人脑的神经元细胞对外界 反应的局部性而提出的新颖的、有效的前馈式 神经网络,具有良好的局部逼近特性。它的数 学理论基础成形于1985年由Powell首先提出的 多变量插值的径向基函数,1988年被 Broomhead和Lowe应用到神经网络设计领域 ,最终形成了RBF神经网络。
10
RBFNN的结构
RBFNN的Matlab实现
clear all clc x=0:0.1:5; y=sqrt(x); net=newrb(x,y); t=sim(net,x); plot(x,y-t,'+-') figure x1=5:0.1:9; y1=sqrt(x1); t1=sim(net,x1); plot(x1,y1-t1,'*-')
7
RBF神经网络的学习算法
RBF神经网络的学习算法分为两步:
第一步是确定隐含层神经元数目、中心和 宽度,第二步是确定隐含层和输出层之间的连 接权值。 径向基函数中心的选取方法主要有随机选 取法、K-均值聚类算法、梯度训练方法和正交 最小二乘法等。隐含层和输出层之间的连接权 值的训练方法主要包括最小均方差、递推最小 方差、扩展卡尔曼滤波等方法。
4
RBFNN的结构
图8.1 RBF神经网络的结构
5常用的Biblioteka 向基函数• 高斯函数(Gaussian Function)
径向基神经网络
径向基神经网络1985年,Powell提出了多变量插值的径向基函数(Radical Basis Function,RBF)方法。
1988年,Moody和Darken提出了一种神经网络结构,即RBF神经网络,属于前向神经网络类型,它能够以任意精度逼近任意连续函数,特别适合于解决分类问题。
RBF网络的结构与多层前向网络类似,它是一种三层前向网络。
输入层由信号源节点组成;第二层为隐含层,隐单元数视所描述问题的需要而定,隐单元的变换函数RBF是对中心点径向对称且衰减的非负非线性函数;第三层为输出层,它对输入模式的作用做出响应。
从输入空间到隐含层空间的变换是非线性的,而从隐含层空间的输出层空间变换是线性的。
RBF网络的基本思想是:用RBF作为隐单元的“基”构成隐含层空间,这样就可以将输入向量直接映射到隐空间。
当RBF的中心点确定以后,这种映射关系也就确定了。
而隐含层空间到输出空间的映射是线性的,即网络的输出是隐单元输出的线性加权和。
此处的权即为网络可调参数。
由此可见,从总体上看,网络由输入到输出的映射是非线性的,而网络的输出对可调参数而言却是线性的。
这烟大哥网络的权就可由线性方程直接解出,从而大大加快学习速度并避免局部极小问题。
一、RBF神经元模型径向基函数神经元的传递函数有各种各样的形式,但常用的形式是高斯函数(radbas)。
与前面介绍的神经元不同,神经元radbas的输入为输入向量p和权值向量ω之间的距离乘以阈值b。
径向基传递函数可以表示为如下形式:二、RBF网络模型径向基神经网络的激活函数采用径向基函数,通常定义为空间任一点到某一中心之间欧氏距离的单调函数。
径向基神经网络的激活函数是以输入向量和权值向量之间的距dist为自变量的。
径向神经网络的激活函数一般表达式为随着权值和输入向量之间距离的减少,网络输出是递增的,当输入向量和权值向量一致时,神经元输出1。
b为阈值,用于调整神经元的灵敏度。
利用径向基神经元和线性神经元可以建立广义回归神经网络,该种神经网络适用于函数逼近方面的应用;径向基神经元和竞争神经元可以组件概率神经网络,此种神经网络适用于解决分类问题。
径向基函数
,
i 1
通过学习,设法得到相应的参数
Radial Basis Functions: •Radial-basis functions were introduced in the solution of the real multivariate interpolation problem. • Basis Functions: A set of functions whose linear combination can generate an arbitrary function in a given function space. • Radial: Symmetric around its center
14
二、RBF Network 性能
RBF网络是一个两层前馈网 隐层对应一组径向基函数,实现非线性映射 每一个隐层单元Ok的输出:
μ
是高斯分布的期望值,又称中心值;σ k是宽度,控制围绕中心 的分布
k
每个隐单元基函数的中心可以看作是存储了一个已知的输入。当输
入 X 逼近中心时,隐单元的输出变大。这种逼近的测度可采用 Euclidean距离: || x-μ ||²
(c1,x) = 1 if distance of x from c1 less than r1 and 0 otherwise (c2,x) = 1 if distance of x from c2 less than r2 and 0 otherwise
:Hyperspheric radial basis function
17
二、RBF Network 性能
Center of the function
8
一、概述
RBF(径向基)神经网络
RBF(径向基)神经⽹络 只要模型是⼀层⼀层的,并使⽤AD/BP算法,就能称作 BP神经⽹络。
RBF 神经⽹络是其中⼀个特例。
本⽂主要包括以下内容:什么是径向基函数RBF神经⽹络RBF神经⽹络的学习问题RBF神经⽹络与BP神经⽹络的区别RBF神经⽹络与SVM的区别为什么⾼斯核函数就是映射到⾼维区间前馈⽹络、递归⽹络和反馈⽹络完全内插法⼀、什么是径向基函数 1985年,Powell提出了多变量插值的径向基函数(RBF)⽅法。
径向基函数是⼀个取值仅仅依赖于离原点距离的实值函数,也就是Φ(x)=Φ(‖x‖),或者还可以是到任意⼀点c的距离,c点称为中⼼点,也就是Φ(x,c)=Φ(‖x-c‖)。
任意⼀个满⾜Φ(x)=Φ(‖x‖)特性的函数Φ都叫做径向基函数,标准的⼀般使⽤欧⽒距离(也叫做欧式径向基函数),尽管其他距离函数也是可以的。
最常⽤的径向基函数是⾼斯核函数 ,形式为 k(||x-xc||)=exp{- ||x-xc||^2/(2*σ)^2) } 其中x_c为核函数中⼼,σ为函数的宽度参数 , 控制了函数的径向作⽤范围。
⼆、RBF神经⽹络 RBF神将⽹络是⼀种三层神经⽹络,其包括输⼊层、隐层、输出层。
从输⼊空间到隐层空间的变换是⾮线性的,⽽从隐层空间到输出层空间变换是线性的。
流图如下: RBF⽹络的基本思想是:⽤RBF作为隐单元的“基”构成隐含层空间,这样就可以将输⼊⽮量直接映射到隐空间,⽽不需要通过权连接。
当RBF的中⼼点确定以后,这种映射关系也就确定了。
⽽隐含层空间到输出空间的映射是线性的,即⽹络的输出是隐单元输出的线性加权和,此处的权即为⽹络可调参数。
其中,隐含层的作⽤是把向量从低维度的p映射到⾼维度的h,这样低维度线性不可分的情况到⾼维度就可以变得线性可分了,主要就是核函数的思想。
这样,⽹络由输⼊到输出的映射是⾮线性的,⽽⽹络输出对可调参数⽽⾔却⼜是线性的。
⽹络的权就可由线性⽅程组直接解出,从⽽⼤⼤加快学习速度并避免局部极⼩问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
将原来N维空间的P个模式点映射到新的M维空间 (M>N)的相应点上,如果在该M维 ϕ 空间存在M维 向量W,使得
W T ϕ ( X ) > 0, T W ϕ ( X ) < 0, X ∈ F1 X ∈F2
6
4.3 广义RBF网络
例:XOR问题
XOR问题的4个模式在二维输入空间的分布是非线性可分的,设 计一个单隐层神经网络,定义其2个隐节点的激活函数为Gauss函 数 2 ϕ1 ( X ) = e − X −C1 , C1 = (1,1)T
2
3
1 1 − −0.5 +1 2 / 2 e 2π − 1+1 2 / 2 e 0.2 = 0.5 -0.5
e
− −1−1 / 2
2
2
2
1
e
− 0.5 −1 / 2
1
0
-1
-2 -3
-2
-1
0
1
2
3
3
4.1 径向基函数技术
正问题( 正问题(direct problem) – 根据物理规律由已知参数来推测及计算观测得到的 资料与数据 – 输入 系统 输出 反问题( 反问题(inverse problem) – 由结果推测原因
4.3 广义RBF网络
则由线性方程 W T ϕ ( X ) = 0 确定了M维ϕ 空间中的一个分 界超平面,这个超平面使得映射到M维ϕ 空间中的P个 点在 ϕ 空间是线性可分的。 而在N维X空间,方程 W T ϕ ( X ) = 0 描述的是X空间的一 个超曲面,这个超曲面使得原来在X空间非线性可分 的P个模式点分为两类,此时称原空间的P个模式点是 可分得。
令Φ Φ表示元素为 ϕip的P*P阶矩阵,W和d分别表示系数向 量和期望输出向量,则有 ΦW =d Φ被称为插值矩阵,若Φ Φ可逆,则 W = Φ-1d
Hale Waihona Puke ϕ (r ) =1
σ2 3) Inverse multi-quadrics (拟多二次)函数
ϕ (r ) =
1
1 + exp(
r2
)
(r
2
+σ 2 )
4.1 径向基函数技术
p = 1, 2,..., P
Micchelli定理:对于一大类函数,如果X1,X2,…, Xp 各不相同,则P*P阶插值矩阵是可逆的。 满足Micchelli定理的部分函数:
1) Gauss (高斯)函数 r2 ϕ (r ) = exp( − 2 ) 2σ 2) Reflected Sigmoidal (反演S型)函数
第4章径向基函数神经网络
径向基函数技术 正则化RBF网络 广义RBF网络 RBF网络常用算法 RBF网络的设计与应用实例
全局逼近与局部逼近
全局逼近网络:神经网络的一个或多个可调参数(权 全局逼近网络 值和阈值)对任何一个输出都有影响 – 学习速度慢,不适合有实时性要求的应用 局部逼近网络:对网络输入空间的某个局部区域只有 局部逼近网络 少数几个连接权影响网络的输出 – 学习速度快
根据全部或部分已知系统和输出求输入 在全部或部分已知输入与输出的情况下求系统
4.1 径向基函数技术
适定的( 适定的(well-posed) – 如果f重建问题满足下面3个条件:
解的存在性 解的唯一性 解的联系性
不适定的( 不适定的(ill-posed) – 如果有一个条件不满足,则为不适定的
* 如果使用对解的先验知识作为约束,很多不适定问题是可以解答 的
XOR问题的4个模式在输入空间和隐空间的分布
4.3 广义RBF网络
4.3.2 广义RBF网络 由于正则化网络的训练样本与“基函数”是一一对应 的,当样本数P很大时,实现网络的计算量将大得惊 人。 此外,P很大则权值矩阵也很大,求解网络的权值时 容易产生病态问题(ill conditioning)。 为解决这一问题,可减少隐节点的个数,即N<M<P, N为样本维数,P为样本个数,从而得到广义RBF网络
4.3 广义RBF网络
广义RBF网络的基本思想 基本思想: 基本思想 用径向基函数作为隐单元的“基”,构成隐层空间。隐 层对输入向量进行变换,将低维空间的模式变换到高 维空间内,使得在低维空间内的线性不可分问题在高 维空间内线性可分。
输出层选用线性激活函数 基函数,一般选用格林函数
1)
2)
广义RBF网络
− −1+ 0.5 / 2
2
4.1 径向基函数技术
F(x) using Gaussian rbfs
4.1.3 完全内插方案存在的问题
1)由于插值曲面必须通过所有训练数据点,当训练数 据中存在噪声时,神经网络将拟合出一个错误的插值 曲面,从而使其泛化能力下降 2)由于径向基函数的数量与训练样本数量相等,当训 练样本数远远大于物理过程中固有的自由度时,问题 就成为超定的。
4.3 广义RBF网络
ϕ 2 ( X ) = e − X −C , C 2 = (0, 0)T
2
2
轮流以XOR问题的4个问题作为2个隐节点激活函数的输入,其对 应的4个输出为 (0, 0) (0.1353, 1) (0, 1) (0.3678, 0.3678) (1, 0) (0.3678, 0.3678) (1, 1) (1, 0.1353)
2
4.2 正则化RBF网络
为格林函数,如果D具有平移不变性和旋转不 变性,则
G ( X, X p )
G ( X, X p ) = G ( X − X p )
λ是正实数,称为正则化参数,控制着正则化项的相 对重要性,从而也控制着函数的光滑程度。 直接给出插值问题的正则化的解为:
F ( X ) = ∑ w p G ( X, X p )
∑ w ϕ( X
p p =1 P
P
1
− X p ) = d1 − X p ) = d2
–
ϕ 为以输入空间的点X与中心Xp的距离作为函数自 变量非线性函数,训练数据点Xp是ϕ 的中心。
基于径向基函数技术的插值函数定义为基函数的线 性组合 P
F ( X ) = ∑ w pϕ ( X − X p )
p =1
4.4 RBF网络常用学习算法
结构设计
–
如何确定网络隐节点数
4.2 正则化RBF网络
N-P-l 结构的正则化RBF网络
5
4.2 正则化RBF网络
正则化网络的3个性质: 个性质: 1)正则化网络是一种通用币近期,只要有足够的隐节 点,可以以任意精度逼近紧集上的任意多元连续函 数; 2)具有最佳逼近特性,即任给一个未知的非线性函数 f,总可以找到一组权值使得正则化网络对于f的逼 近优于其他可能的选择; 3)正则化网络得到的解是最佳的,所谓“最佳”体现在 同时满足对样本的逼近误差和逼近曲线平滑性。
–
正则化方法则在标准误差项基础上增加了一个控制逼 近函数光滑程度的项,称为正则化项,该正则化项体 现了逼近函数的“几何”特性,即
1 2 DF 2 D是线性微分算子,代表了对F (X )的先验知识,D与所解问题相关 Ec ( F ) =
4
4.2 正则化RBF网络
正则化理论要求
Min 1 P1 1 E ( F ) = Es ( F ) + λ Ec ( F ) = ∑ ( d p − F ( X p )) 2 + λ DF 2 p =1 2
7
4.3 广义RBF网络
广义RBF网络与正则化RBF网络的几点不同: 1)径向基函数的个数M与样本的个数N不相等,且M常 常小于 N; 2)径向基函数的中心不再限制在数据点上,而是由训 练算法确定; 3)各径向基函数的扩展函数不再统一,其值由训练算 法确定; 4)输出函数的线性中包含阈值函数,用于补偿基函数 在样本集上的平均值与目标值之平均值之间的差 别。
1/ 2
2
4.1 径向基函数技术
4.1 径向基函数技术
例:F(–1) = 0.2, F(–0.5) = 0.5, F(1) = –0.5. 1. 使用三角基函数 0.6 ϕ (r ) = (1 − r )[u (r ) − u ( r − 1)]
1 r ≥ 0 u (r ) = 0 r < 0 F ( x) = w1ϕ ( x + 1 ) + w2ϕ ( x + 0.5 ) + w3ϕ ( x − 1) 1 0.5 0 w1 0.2 0.5 1 0 w = 0.5 2 0 -0.5 0 1 w3 ⇒ w = [-1/15 8/15 -1/2]
4.1 径向基函数技术
1963年,Davis提出高维空间的多变量插值理 论 20世纪80年代,Powell在解决“多变量有限点 严格(精确)插值问题”时引入径向基函数技 术 径向基函数(Radial Basis Function,RBF )
4.1 径向基函数技术
4.1.1 插值问题
–
–
– –
设N维空间有P个输入向量Xp,p=1,2,…,P, 他们在输 出空间相应的目标值为dp, p=1,2,…,P, P对输入-输出 样本构成了训练样本集 插值的目的:寻找一个非线性映射函数 F(X),使其 插值的目的 满足下述插值条件 F(Xp)= dp, p=1,2,…,P, 函数F描述了一个插值曲面 严格插值( 严格插值(精确插值) 精确插值):是一种完全内插,即该插 值曲面必须通过所有训练数据点
1
4.1 径向基函数技术
4.1.2 径向基函数技术解决插值问题
–
4.1 径向基函数技术
代入插值条件F(Xp)= dp, p=1,2,…,P,有如下关于P个未 知系数wp的线性方程组
选择P个基函数,每个基函数对应一个训练数据, 各基函数形式为: