实验报告二 数据的表示1
计算机网络实验二实验报告讲解

计算机网络实验二实验报告讲解实验二:网络传输性能的测试与评估实验目的:1.掌握网络传输性能的测试方法;2.了解网络传输性能评估的参数;3. 学会使用JPerf工具进行网络传输性能测试。
实验环境:1. JPerf软件;2. 两台运行Windows操作系统的计算机;3.以太网交换机;4.网线,以连接两台计算机及交换机。
实验步骤:1.配置网络环境连接两台计算机和交换机,保证网络连接正常。
2. 安装JPerf软件在两台计算机上分别安装JPerf软件。
3. 运行JPerf服务器选择一台计算机作为服务器,打开JPerf程序,选择“Server”模式,并设置端口号。
4. 运行JPerf客户端打开另一台计算机的JPerf程序,选择“Client”模式,并输入服务器的IP地址和端口号。
5.设置测试参数在JPerf客户端上,设置传输模式(TCP/UDP)、传输时长和数据包大小等参数,并点击“Start”按钮开始测试。
6.分析结果测试结束后,JPerf会输出传输性能测试的结果,包括带宽、丢包率、延迟等参数。
根据这些参数可以评估网络的传输性能。
实验结果与分析:在测试过程中,我们选择了TCP传输模式,传输时长设置为30秒,数据包大小为1MB。
根据测试结果,我们得到了以下性能参数:带宽:100Mbps丢包率:0%延迟:10ms根据带宽和延迟,我们可以评估网络的传输性能。
带宽表示单位时间内能够传输的数据量,带宽越大,传输速度越快。
延迟表示数据从发送方到接收方的传输延时,延迟越小,传输速度越快。
丢包率表示发送的数据在传输过程中丢失的比例,丢包率越小,数据传输越可靠。
在这个实验中,我们得到了较高的带宽和较低的延迟,说明网络的传输性能较好。
同时,丢包率为0%,说明数据传输的可靠性也很高。
根据这些结果,我们可以对网络的传输性能进行评估。
如果带宽较小、延迟较大或丢包率较高,就会影响数据的传输速度和可靠性,从而降低网络的传输性能。
因此,在设计和配置网络时,需要考虑这些因素,以提高网络的传输性能。
实验分析报告三数据的表示

实验报告三数据的表示————————————————————————————————作者:————————————————————————————————日期:计算机系统基础实验报告学院信电学院专业计算机科学与技术班级计算机1401 学号140210110 姓名段登赢实验时间:一、实验名称:数据的表示2二、实验目的和要求:(1)实验目的:熟悉数值数据在计算机内部的表示方式,掌握相关的处理语句。
(2)实验要求:说明你做实验的过程(重要步骤用屏幕截图表示);提交源程序;分析并回答问题。
三、实验环境(软、硬件):要求:详细描述实验用的操作系统,源代码编辑软件,相关硬件环境及所使用的GCC 编译器的信息。
四、实验内容:(1)请说明下列赋值语句执行后,各个变量对应的机器数和真值各是多少?编写一段程序代码并进行编译,观察默认情况下,编译器是否报warning。
如果有warning信息的话,分析为何会出现这种warning信息。
int a = 2147483648;int b = -2147483648;int c = 2147483649;unsigned short d = 65539;short e = -32790;(2)完成书上第二章习题中第40题,提交代码,并在程序中以十六进制形式打印变量u 的机器数。
(3)编译运行以下程序,并至少重复运行3次。
void main(){double x=23.001, y=24.001, z=1.0;for (int i=0; i<10; i++) {if ((y-x)==z)printf("equal\n");elseprintf("not equal\n");x += z;y += z;printf("%d, %f , %f\n”, i, x, y);}}要求:(1)给出每次运行的结果截图。
(2)每次运行过程中,是否每一次循环中的判等结果都一致?为什么?(3)每次运行过程中,每一次循环输出的i、x和y的结果分别是什么?为什么?五、实验结果及分析:(1)实验分析:机器数就是数字在计算机中的二进制表示形式,其特点一是符号数字化,二是其数的大小受机器字长的限制。
数据与分析实验报告

数据与分析实验报告1. 引言数据分析是一种通过分析和解释数据来确定模式、关系以及其他有价值信息的过程。
在现代社会中,数据分析已经成为各个领域中不可或缺的工具。
本实验旨在通过对一个特定数据集的分析,展示数据分析的过程以及结果的解读和应用。
本实验选择了一组关于学业表现的数据进行分析,并探讨了学生的各项指标与其学习成绩之间的关系。
2. 数据集描述本次实验所使用的数据集是一个包含了1000名学生的学术成绩和相关指标的数据集。
数据集中包含了每位学生的性别、年龄、是否拥有本科学历、成绩等信息。
数据集以CSV格式提供。
3. 数据清洗与预处理在进行数据分析之前,首先需要进行数据清洗和预处理的工作,以保证后续分析的准确性和可靠性。
本实验中的数据集在经过初步检查后,发现存在一些缺失值和错误值。
为了保证数据的完整性,我们采取了以下措施进行数据清洗:- 删除缺失值:对于存在缺失值的数据,我们选择了删除含有缺失值的行。
- 纠正错误值:通过对每个指标的合理范围进行了限定,排除了存在明显错误值的数据。
此外,还进行了数据的标准化处理,以确保各项指标具有可比性。
4. 数据探索与分析4.1 性别与学习成绩的关系为了探究性别与学习成绩之间的关系,我们进行了如下分析:- 绘制了性别与学习成绩的散点图,并使用不同的颜色进行了标记。
通过观察散点图,我们可以初步得出性别与学习成绩之间存在一定的关系。
但由于性别只是一个二分类变量,为了更加准确地探究性别与学习成绩之间的关系,我们使用了ANOVA分析进行了验证。
4.2 年龄与学习成绩的关系为了探究年龄与学习成绩之间的关系,我们进行了如下分析:- 将学生按年龄分组,计算每个年龄组的平均成绩,并绘制了年龄与学习成绩的折线图。
通过观察折线图,我们可以发现年龄与学习成绩之间存在一定的曲线关系。
年龄在一定范围内的增长会对学习成绩产生积极影响,但随着年龄的增长,学习成绩会逐渐下降。
4.3 学历与学习成绩的关系为了探究学历与学习成绩之间的关系,我们进行了如下分析:- 计算了不同学历组的平均学习成绩,并绘制了学历与学习成绩的柱状图。
实验二 实验报告表(1)
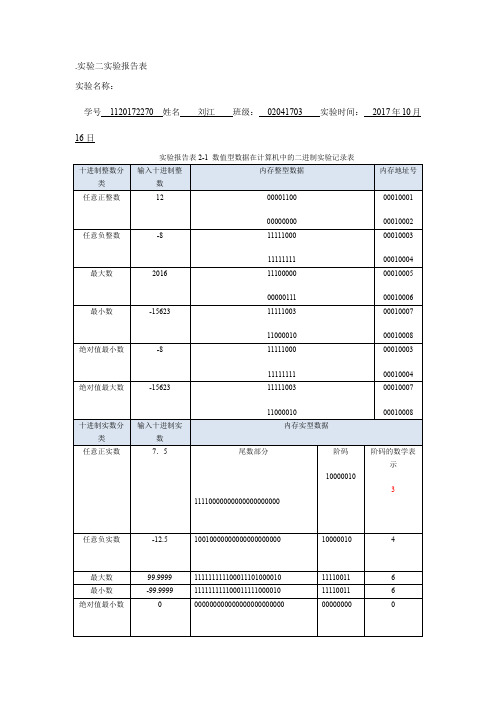
.实验二实验报告表
实验名称:
学号1120172270 姓名刘江班级:02041703 实验时间:2017年10月16日
实验报告表2-1 数值型数据在计算机中的二进制实验记录表
说明:本实验对计算机内存数据的存放拟定为:①整数用两个字节存储,并负数只考虑原码;②实数用4个字节存储,其中阶码部分占一个字节。
实验报告表2-2 其他进制数据与二进制转化实验记录表
实验报告表2-3 数据的原码、补码和反码表示实验记录表
实验报告表2-4 二进制算术运算实验记录表
实验报告表2-5溢出实验记录表
实验报告表2-6浮点数的小数点浮动实验记录表
实验报考表2-7 表示浮点数的二进制串中阶码位数改变实验记录表。
北理大学计算机实验基础 实验二 实验报告表答案精编版
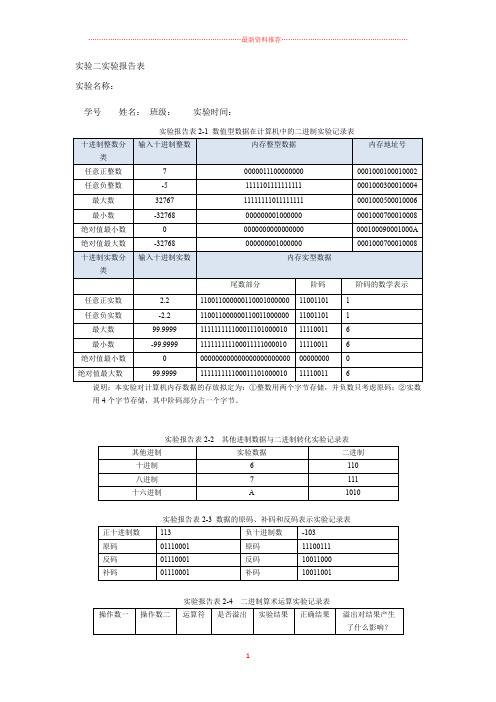
实验二实验报告表
实验名称:
学号姓名:班级:实验时间:
实验报告表2-1 数值型数据在计算机中的二进制实验记录表
说明:本实验对计算机内存数据的存放拟定为:①整数用两个字节存储,并负数只考虑原码;②实数用4个字节存储,其中阶码部分占一个字节。
实验报告表2-2 其他进制数据与二进制转化实验记录表
实验报告表2-3 数据的原码、补码和反码表示实验记录表
实验报告表2-4 二进制算术运算实验记录表
实验报告表2-5溢出实验记录表
实验报告表2-6浮点数的小数点浮动实验记录表
实验报考表2-7 表示浮点数的二进制串中阶码位数改变实验记录表。
数据类型实验报告(3篇)

第1篇一、实验目的1. 理解和掌握基本数据类型的概念及特点。
2. 掌握不同数据类型的存储方式和表示方法。
3. 能够根据实际需求选择合适的数据类型。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.8.53. 开发工具:PyCharm三、实验内容1. 基本数据类型实验2. 复杂数据类型实验3. 数据类型转换实验四、实验步骤及结果1. 基本数据类型实验(1)实验目的:了解基本数据类型的概念及特点。
(2)实验步骤:① 定义变量并赋值:a = 10,b = 'hello',c = 3.14② 输出变量的类型:print(type(a)),print(type(b)),print(type(c))(3)实验结果:变量a的类型为int,变量b的类型为str,变量c的类型为float。
2. 复杂数据类型实验(1)实验目的:了解复杂数据类型的概念及特点。
(2)实验步骤:① 定义列表:list1 = [1, 2, 3, 'a', 'b', 'c']② 定义元组:tuple1 = (1, 2, 3, 'a', 'b', 'c')③ 定义字典:dict1 = {'name': 'Tom', 'age': 18, 'gender': 'male'}④ 定义集合:set1 = {1, 2, 3, 'a', 'b', 'c'}(3)实验结果:列表list1的类型为list,元组tuple1的类型为tuple,字典dict1的类型为dict,集合set1的类型为set。
3. 数据类型转换实验(1)实验目的:掌握不同数据类型之间的转换方法。
(2)实验步骤:① 将字符串转换为整数:str1 = '123',int1 = int(str1)②将整数转换为浮点数:int2 = 10,float1 = float(int2)③ 将浮点数转换为字符串:float2 = 3.14,str2 = str(float2)(3)实验结果:字符串str1转换为整数int1的结果为123,整数int2转换为浮点数float1的结果为10.0,浮点数float2转换为字符串str2的结果为'3.14'。
实验二-决策树实验-实验报告
决策树实验一、实验原理决策树是一个类似于流程图的树结构,其中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输入,而每个树叶结点代表类或类分布。
数的最顶层结点是根结点。
一棵典型的决策树如图1所示。
它表示概念buys_computer,它预测顾客是否可能购买计算机。
内部结点用矩形表示,而树叶结点用椭圆表示。
为了对未知的样本分类,样本的属性值在决策树上测试。
决策树从根到叶结点的一条路径就对应着一条合取规则,因此决策树容易转化成分类规则。
图1ID3算法:■决策树中每一个非叶结点对应着一个非类别属性,树枝代表这个属性的值。
一个叶结点代表从树根到叶结点之间的路径对应的记录所属的类别属性值。
■每一个非叶结点都将与属性中具有最大信息量的非类别属性相关联。
■采用信息增益来选择能够最好地将样本分类的属性。
信息增益基于信息论中熵的概念。
ID3总是选择具有最高信息增益(或最大熵压缩)的属性作为当前结点的测试属性。
该属性使得对结果划分中的样本分类所需的信息量最小,并反映划分的最小随机性或“不纯性”。
二、算法伪代码算法Decision_Tree(data,AttributeName)输入由离散值属性描述的训练样本集data;候选属性集合AttributeName。
输出一棵决策树。
(1)创建节点N;(2)If samples 都在同一类C中then(3)返回N作为叶节点,以类C标记;(4)If attribute_list为空then(5)返回N作为叶节点,以samples 中最普遍的类标记;//多数表决(6)选择attribute_list 中具有最高信息增益的属性test_attribute;(7)以test_attribute 标记节点N;(8)For each test_attribute 的已知值v //划分samples(9)由节点N分出一个对应test_attribute=v的分支;(10令S v为samples中test_attribute=v 的样本集合;//一个划分块(11)If S v为空then(12)加上一个叶节点,以samples中最普遍的类标记;(13)Else 加入一个由Decision_Tree(Sv,attribute_list-test_attribute)返回节点值。
C语言程序设计实验报告(二)
输入:40,50,60↙
5.运行下述程序,分析输出结果。 main(int b=10; float x=10.0; double y=10.0; printf("a=%d, b=%ld,x=%f, y= %lf\n",a,b,x,y); printf("a=%ld,b=%d, x=%lf,y=%f\n",a,b,x,y); printf("x=%f, x=%e, x=%g\n",x,x,x); } 从此题的输出结果认识各种数据类型在内存的存储方式。
4.了解数据类型在程序设计语言中的意义。
三、实验内容及要求:
内容: 1.编程序,输出如下图形: ** ** ** *** *** **** ****
原程序图
运行结果图
2.编写程序,实现下面的输出格式和结果( 表示空格):
a= 5,b= 7,a-b=-2,a/b= 71%
x=31.19,y= -31.2,z=31.1900
3.编写程序,输入变量 x 值,输出变量 y 的值,并分析输出结果。 (1) y =2.4 * x-1/2 (2) y=x%2/5-x (3) y=x>10&&x<100 (4) y=x>=10||x<=1 (5) y=(x-=x*10,x/=10)
要求变量 x、y 是 float 型。 原程序图
运行结果图
C 语言程序设计实验报告
姓名
学号
系别
班级
09 信息
主讲教师
指导教师
实验日期
专业 信息与计算科学
课程名称
C 语言程序设计
一、实验名称:
同组实验者
实验二、 数据类型及顺序结构
数值分析实验报告2
实验报告一、实验名称复合梯形求积公式、复合辛普森求积公式、龙贝格求积公式及自适应辛普森积分。
二、实验目的及要求1. 掌握复合梯形求积计算积分、复合辛普森求积计算积分、龙贝格求积计算积分和自适应辛普森积分的基本思路和步骤.2. 培养Matlab 编程与上机调试能力. 三、实验环境计算机,MATLAB 软件 四、实验内容1.用不同数值方法计算积分94ln 10-=⎰xdx x 。
(1)取不同的步长h 。
分别用复合梯形及复合辛普森求积计算积分,给出误差中关于h 的函数,并与积分精确指比较两个公式的精度,是否存在一个最小的h ,使得精度不能再被改善。
(2)用龙贝格求积计算完成问题(1)。
(3)用自适应辛普森积分,使其精度达到10-4。
五、算法描述及实验步骤1.复合梯形公式将区间[a,b]划分为n 等份,分点x k =a+ah,h=(b-a)/h,k=0,1,...,n ,在每个子区间[x k ,x k +1](k=0,1,...,n-1)上采用梯形公式(1.1),得)]()([2)(b f a f ab dx x f b a+-≈⎰ (1.1) )]()(2)([2)]()([211110b f x f b f hx f x f h T n k k k n k k n ++=+=∑∑-=+-= (1.2)),(),(12)(''2b a f h a b f R n ∈--=ηη(1.3) 其中Tn 称为复合梯形公式,Rn 为复合梯形公式的余项。
2.复合辛普森求积公式将区间[a,b]划分为n 等份,在每个子区间[x k ,x k +1](k=0,1,...,n-1)上采用辛普森公式(1.4),得)]()2(4)([6b f ba f a f ab S +++-=(1.4) )]()(2)(4)([6)]()()([611102/112/11b f x f x f b f hx f x f x f h S n k k n k k k k n k k n +++=++=∑∑∑-=-=+++-= (1.5) ),(),()2(180)()4(4b a f h a b f R n ∈-=ηη (1.6)其中Sn 称为复合辛普森求积公式,Rn 为复合辛普森求积公式的余项。
实验报告内容说明
实验报告内容说明
自查报告。
在本次实验中,我负责对实验数据的收集和分析。
在进行数据收集的过程中,我发现了一些错误和不足之处,现在进行自查报告如下:
1. 数据采集过程中,我发现有一些数据采集不准确,可能是由于仪器故障或操作不当导致的。
我已经进行了数据再次采集,并且对比了两次数据,确保了数据的准确性。
2. 在数据分析过程中,我发现了一些计算错误,导致了部分数据的分析结果不准确。
我已经对这些数据进行了重新计算,并且对比了两次数据,确保了数据分析的准确性。
3. 在实验报告撰写过程中,我发现了一些表述不清晰和错误的地方,我已经对报告进行了修改和完善,确保了报告的准确性和完整性。
通过以上自查报告,我对本次实验的数据采集和分析过程进行
了全面的检查和整改,确保了实验结果的准确性和可靠性。
同时,我也意识到了自身在实验过程中存在的不足之处,将会在以后的实验中加以改进和提高。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计算机系统基础实验报告
学院信电学院专业计算机科学与技术班级计算机1401 学号140210110 姓名段登赢实验时间:
一、实验名称:数据的表示1
二、实验目的和要求:
(1)实验目的:熟悉数值数据在计算机内部的表示方式,掌握相关的处理语句。
(2)实验要求:说明你做实验的过程(重要步骤用屏幕截图表示);提交源程序;分析并回答问题。
三、实验环境(软、硬件):
软件环境:
操作系统:Ubuntu ,版本:15.04
编译器软件:GCC,版本:5.4.0
硬件环境:
处理器:i386处理器
处理器个数:双处理器
总核心数:四核
处理器位数:32位
四、实验内容:
(1)下述两个结构所占存储空间多大?结构中各分量所在位置相对于结构起始位置的偏移量是多少?请编写程序以验证你的答案。
struct test1
{
char x2[3];
short x3[2];
int x1;
long long x4;
};
struct test2
{
char x2[3];
short x3[2];
int x1;
long long x4;
}__attribute__((aligned(8)));
(2)“-2 < 2”和“-2 < 2u”的结果一样吗?为什么?
(3)运行下图中的程序代码,并对程序输出结果进行分析。
(4)运行下列代码,并对输出结果进行分析。
#include <stdio.h>
void main()
{
union NUM
{
int a;
char b[4];
} num;
num.a = 0x12345678;
printf("0x%X\n", num.b[2]);
}
五、实验结果及分析:
(1)
补]4[ (2)
实验分析:
正数的源码,反码,补码都相同,负数在计算机存储时按补码存储和运算,源码除符号位外将每一位按位取反最后加一而来。
在32位计算机中int 占4个字节共32位。
所以-2在内存中的存储方式:1,111 1111 1111 1111 1111 1111 1111 1110B 即fffffffeH ,此时最高位为符号位,2在内存中的存储方式:0,000 0000 0000 0000 0000 0000 0000 0010B 即2H ,此时最高位为符号位。
2u 在内存中的存储方式:0000 0000 0000 0000 0000 0000 0000 0010B 即2H ,但此时最高位不再是符号位。
由上述可知:-2<2是有符号数的比较,即-2+(-2)=fffffffeH+fffffffeH=1FFFFFFFCH= ,最高位符号位溢出,所以证明被减数的符号是负号,即-2<2是正确的。
-2<2u 是有符号数和无符号数之间的比较,此时编译器会把有符号数自动转换成无符号数,所以就是:fffffffeH=4294967294D<2D=2H ,显然这是错误的。
(3)
实验分析:
因为所有比int 型小的数据类型(包括char,signed char,unsigned char,short,signed short,unsigned short )转换为int 型。
如果转换后的数据会超出int 型所能表示的范围的话,则转换为unsigned int 型;所以题中的c 在和a 比较时应该先转换成int 型,再转换成unsigned int 型,所以此时的c 为1111 1111 1111 1111 1111 1111 1111 1111B (有符号数按最高位符号位进行扩位)即FFFFFFFFH ,此时的a 为1H ,显然c 大于a ,所以第一次输出的是unsigned int is 0;同理当b 和c 比较时,c 应该转换成int 型,所以此时的c 为1111 1111 1111 1111 1111 1111 1111 1111B 即FFFFH=-2147483647D ,b 也应该转换成int 型,所以此时的b 为0000 0000 0000 0000 0000 0000 0000 0001B=1D ,显然b>c ,所以输出unsigned short is 1
(4)
实验分析:
由于在union 共用体当中,int a 和char b[4]数据公用同一段内存地址,而此时a 和b 同
时占用四个字节,所以当执行num.a = 0x12345678;同时b也会被赋值,b的内存示意图如下:
由上图可知执行printf("0x%X\n", num.b[2]);会输出0x34。
现在解释为什么会出现表中的情况对于数组来说,下标越小地址越小,下标越大地址越大,而a=0x12345678这个值中,1和2分别在最高位和次高位,它就会存储在下标大的b[3]中,以此类推,便可以得到表中的数据。
这也证明了我的32位Ubuntu是小端存储(字数据的高字节存储在高地址中,而字数据的低字节则存储在低地址中)。
六、实验心得
通过这次实验让我对结构体和公共体有了更为深入的理解,首先我明白了结构体中成员的对齐理论,知道了在结构体中数据成员初始化顺序的不同也会影响到该结构体所占的内存空间的大小。
其次我也学到了公共体的成员的内存地址是相同的,并且自己通过实验也亲自验证了这一结论。
并且再一次巩固了C语言中数据类型之间的自动转换,无符号数与有符号数之间的转换规则。