统计学--典型相关分析
统计学案例——相关回归分析报告
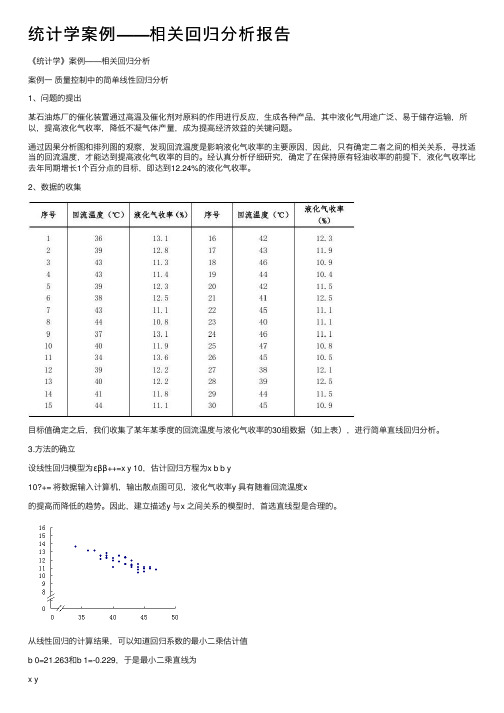
统计学案例——相关回归分析报告《统计学》案例——相关回归分析案例⼀质量控制中的简单线性回归分析1、问题的提出某⽯油炼⼚的催化装置通过⾼温及催化剂对原料的作⽤进⾏反应,⽣成各种产品,其中液化⽓⽤途⼴泛、易于储存运输,所以,提⾼液化⽓收率,降低不凝⽓体产量,成为提⾼经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化⽓收率的主要原因,因此,只有确定⼆者之间的相关关系,寻找适当的回流温度,才能达到提⾼液化⽓收率的⽬的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化⽓收率⽐去年同期增长1个百分点的⽬标,即达到12.24%的液化⽓收率。
2、数据的收集⽬标值确定之后,我们收集了某年某季度的回流温度与液化⽓收率的30组数据(如上表),进⾏简单直线回归分析。
3.⽅法的确⽴设线性回归模型为εββ++=x y 10,估计回归⽅程为x b b y10?+= 将数据输⼊计算机,输出散点图可见,液化⽓收率y 具有随着回流温度x的提⾼⽽降低的趋势。
因此,建⽴描述y 与x 之间关系的模型时,⾸选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最⼩⼆乘估计值b 0=21.263和b 1=-0.229,于是最⼩⼆乘直线为x y229.0263.21?-= 这就表明,回流温度每增加1℃,估计液化⽓收率将减少0.229%。
(3)残差分析为了判别简单线性模型的假定是否有效,作出残差图,进⾏残差分析。
从图中可以看到,残差基本在-0.5—+0.5左右,说明建⽴回归模型所依赖的假定是恰当的。
误差项的估计值s=0.388。
(4)回归模型检验 a.显著性检验在90%的显著⽔平下,进⾏t 检验,拒绝域为︱t ︱=︱b 1/ s b1︱>t α/2=1.7011。
由输出数据可以找到b 1和s b1,t=b 1/ s b1=-0.229/0.022=-10.313,于是拒绝原假设,说明液化⽓收率与回流温度之间存在线性关系。
统计学中常用的数据分析方法10典型相关分析与ROC分析

统计学中常用的数据分析方法
典型相关分析
相关分析一般分析两个变量之间的关系,而典型相关分析是分析两组变量(如3个学术能力指标与5个在校成绩表现指标)之间相关性的一种统计分析方法。
典型相关分析的基本思想和主成分分析的基本思想相似,它将一组变量与另一组变量之间单变量的多重线性相关性研究转化为对少数几对综合变量之间的简单线性相关性的研究,并且这少数几对变量所包含的线性相关性的信息几乎覆盖了原变量组所包含的全部相应信息。
R0C分析
R0C曲线是根据一系列不同的二分类方式(分界值或决定阈).以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线
用途:
1、R0C曲线能很容易地査出任意界限值时的对疾病的识别能力用途;
2、选择最佳的诊断界限值。
R0C曲线越靠近左上角,试验的准确性就越高;
3、两种或两种以上不同诊断试验对疾病识别能力的比较,一股用R0C曲线下面积反映诊断系统的准确性。
统计学专业基础课与专业课之间的典型相关分析

统计学专业基础课与专业课之间的典型相关分析摘要本文基于统计学系0301-0302两个班的66名学生17门课程(包括专业基础课和专业课)的考试成绩,运用典型相关分析法研究了统计学系基础课和专业课的相关程度。
通过运用统计分析软件SAS运行得到变量间的相关系数以及标准化后的典型相关系数,进而求出典型相关变量。
最后结合分析结果和实际情况对教学提了一点小小的建议。
关键词:基础课;专业课;典型相关分析;典型相关系数Canonical Correlation Analysis Between The Major and BasicSubjects of The Statistics MajorAbstractWith the method of canonical correlation analysis,I study about the correlation between the major and basic subjects of the statistics major.The research is based on the examination scores of66students of classes0301and0302who are in the major of statistics,including only17 subjects,the major and basic subjects.The article then gives the standard canonical correlations between the variables from which we can know the canonical correlative variables.In the end,I give some suggestions about education,according to the output of the analysis and the matter of fact.Key word:basic subject,major,canonical correlation,canonical coefficients1引言对于统计学系的学生来说,对数学理论的理解和掌握要求比较高,而且更重要的是要做到融会贯通,举一反三,学会理论联系实际,并利用统计分析的方法来解决日常生产生活中的问题,因而专业基础课程(如数学分析和高等代数等)的学习无疑是相当重要的,因为它直接关系到后续专业课的学习效果。
统计学中的相关分析方法

统计学中的相关分析方法统计学是一门研究数据收集、整理、分析和解释的学科,是现代科学研究中不可或缺的一部分。
在统计学中,相关分析是一种重要的方法,用于研究变量之间的关系。
本文将介绍相关分析的基本概念、方法和应用。
一、相关分析的基本概念相关分析是一种用来研究两个或多个变量之间关系的统计方法。
它通过计算相关系数来衡量变量之间的相关性。
相关系数是一个介于-1和1之间的数值,表示变量之间的相关程度。
当相关系数接近1时,表示变量之间存在强正相关;当相关系数接近-1时,表示变量之间存在强负相关;当相关系数接近0时,表示变量之间不存在线性相关。
二、相关分析的方法相关分析有多种方法,其中最常用的是皮尔逊相关系数。
皮尔逊相关系数是一种度量变量之间线性相关程度的方法。
它可以用来研究两个变量之间的关系,也可以用来研究多个变量之间的关系。
皮尔逊相关系数的计算公式如下:r = (Σ(Xi - X)(Yi - Ȳ)) / √(Σ(Xi - X)²Σ(Yi - Ȳ)²)其中,r表示相关系数,Xi和Yi分别表示第i个观测值的两个变量的取值,X和Ȳ分别表示两个变量的平均值。
除了皮尔逊相关系数,还有一些其他的相关分析方法,例如斯皮尔曼相关系数、切比雪夫距离等。
这些方法适用于不同类型的数据和不同的研究问题,研究者可以根据具体情况选择合适的方法进行分析。
三、相关分析的应用相关分析在各个领域都有广泛的应用。
在经济学中,相关分析可以用来研究经济变量之间的关系,例如GDP和失业率之间的关系、股票价格和利润之间的关系等。
在医学研究中,相关分析可以用来研究疾病和生活方式之间的关系,例如吸烟和肺癌之间的关系、饮食和心脏病之间的关系等。
在市场营销中,相关分析可以用来研究产品销量和广告投放之间的关系,帮助企业制定营销策略。
除了上述应用,相关分析还可以用来研究教育、环境、社会等领域的问题。
例如,在教育研究中,可以用相关分析来研究学生的学习成绩和学习时间之间的关系;在环境研究中,可以用相关分析来研究气候变化和自然灾害之间的关系;在社会研究中,可以用相关分析来研究收入和幸福感之间的关系。
统计学相关案例解析

解: H0: 480000, H1: 480000。
统计检验量z x 0 450000 480000 1.581
S
120000
n
40
由 0.05,查表得临界值z z0.05 1.645
n
10
置信上限:x t0.025
S 791.1 2.262 17.136 803.3(6 克)
n
10
∴ 有95%的把握这批食品的平均每袋重 量在778.84克到803.36克之间。
例4.某制造厂质量管理部门的负责人希望估计移交给
接收部门的5500包原材料的平均重量。一个由250包
原材料组成的随机样本所给出的平均值 x 65千克 。
35
50
环比发展速 — 110 度(%)
105 95
要求:(1)利用指标间的关系将表中所缺数字补齐; (结果保留1位小数)
(2)按水平法计算该地区第八个五年计划期间 化肥产量年平均增长速度。
解:(1)、
时间 1990年
化肥产量 (万吨)
300
定基增长 量(万吨)
—
环比发展 速度(%)
—
第八个五年计划期间 1991年 1992年 1993年 1994年 1995年
总体标准差 15千克。试构造总体平均值 的置
信区间,已知置信概率为95%,总体为正态分布。
已知Z0.05 1.645,Z0.025 1.96,t0.05 (249) 1.645, t0.025 (249) 1.96。
解:已知总体服从正态分布,所以样本均值也服从
统计学中的相关性分析

统计学中的相关性分析相关性分析是统计学中一种重要的数据分析方法,用于研究两个或多个变量之间的关系。
通过相关性分析,我们可以了解变量之间的相关程度,并从中推断可能存在的因果关系或者预测未来的趋势。
本文将介绍相关性分析的基本概念、常用方法和实际应用场景。
一、相关性分析的基本概念相关性是指两个或多个变量之间存在的关联程度。
通过相关性分析,我们可以测量这种关联程度,并判断其强度和方向。
常用的相关系数有皮尔逊相关系数、斯皮尔曼等级相关系数和判定系数等。
1. 皮尔逊相关系数皮尔逊相关系数是一种衡量线性相关性的指标,通常用r表示。
其取值范围在-1到1之间,0表示没有线性相关性,正数表示正相关性,负数表示负相关性。
绝对值越接近1,相关性越强。
2. 斯皮尔曼等级相关系数斯皮尔曼等级相关系数是一种非参数的相关性指标,适用于不满足线性假设的数据。
它通过将原始数据转化为等级或顺序,然后计算等级的相关性来衡量两个变量之间的关联程度。
3. 判定系数判定系数是衡量相关性的一个指标,也是回归分析中的常用指标。
判定系数的取值范围在0到1之间,表示因变量的变异程度中有多少可以被自变量解释。
越接近1,代表自变量对因变量的解释程度越高。
二、常用的相关性分析方法在统计学中,常用的相关性分析方法有:1. 直接计算相关系数最直接的方法是直接计算相关系数,即根据数据计算皮尔逊相关系数、斯皮尔曼等级相关系数等。
这种方法适用于数据量较小、手动计算较为简便的情况。
2. 统计软件分析对于大规模数据或者需要进行更加深入的相关性分析,可以使用统计软件。
常用的软件包括SPSS、R、Python等,通过简单的代码或者拖拽操作,即可得到相关性分析的结果和可视化图表。
3. 相关性图表和散点图相关性图表和散点图可以直观地展示变量之间的关系,有助于理解和解释数据。
通过绘制散点图,我们可以观察到数据点的分布情况,进而判断变量之间的相关性。
三、相关性分析的实际应用场景相关性分析在各个领域中都有广泛的应用,以下列举几个常见的应用场景:1. 经济学领域在经济学中,相关性分析可用于研究经济指标之间的关联程度。
统计学中的相关分析

统计学中的相关分析统计学是一门研究数据收集、分析和解释的学科,而相关分析是其中一个重要的分析方法。
相关分析是用来量化两个或更多变量之间关系强度的技术,它可以帮助我们理解和预测现象之间的相关性。
本文将介绍相关分析的基本概念、应用以及在实际问题中的运用。
一、相关分析的概念相关分析是统计学中用来确定两个或多个变量之间关系强度的方法。
关系强度通过相关系数来度量,相关系数的取值范围为-1到1。
相关系数为正值表示两个变量是正相关的,即随着一个变量的增加,另一个变量也会增加;相关系数为负值表示两个变量是负相关的,即随着一个变量的增加,另一个变量会减少;相关系数为零表示两个变量之间没有线性关系。
相关分析可以帮助我们了解变量之间的关系,并进行进一步的预测和分析。
二、相关分析的应用相关分析在实际问题中有着广泛的应用。
以下是几个常见领域的相关分析应用示例:1. 经济学领域:相关分析可以帮助经济学家确定不同经济指标之间的关系,如通货膨胀率与失业率之间的相关性,利率与投资之间的相关性等。
这些关系可以用来预测经济发展趋势,为经济政策制定提供参考依据。
2. 医学研究:相关分析在医学研究中的应用非常广泛。
例如,研究人员可以使用相关分析来确定吸烟与肺癌之间的关系,体重与心血管疾病之间的关系等。
这些关系可以帮助医生们更好地了解疾病的发展机制,并提供有效的预防和治疗方案。
3. 市场调查:相关分析可以用来确定市场调查数据中不同变量之间的关系。
例如,一家公司可以使用相关分析来确定广告投资与销售额之间的关系,从而确定最佳的广告投放策略。
相关分析还可以帮助市场调查人员找到潜在的目标客户群体,以提升市场营销效果。
三、相关分析的实际案例为了更好地理解相关分析的应用,我们将通过一个实际案例来说明其具体操作。
假设一个电商公司想要研究用户购买行为与广告点击率之间的关系。
他们分析了一段时间内的用户购买记录和广告点击数据,并进行了相关分析。
他们计算了购买金额和广告点击率之间的相关系数,并得到了一个正值0.75。
统计学相关分析

统计学相关分析统计学是一门研究数据收集、分析与解释的学科。
它的目标是通过系统和科学的方法研究数据,以便能够对各种现象进行描述、理解和预测。
统计学的应用非常广泛,涵盖了自然科学、社会科学、医学、工程、经济学等各个领域。
其中,相关分析是统计学的一个重要工具,可以用来研究两个或多个变量之间的关系。
相关分析是指研究两个或多个变量之间的关系的统计方法。
它可以用来确定这些变量之间是否存在其中一种关联性,并且可以量化这种关联性的强度和方向。
相关分析中常用的指标是相关系数,它可以衡量两个变量之间的线性关系。
相关系数是一个介于-1到+1之间的数值,它表示着两个变量之间的关联程度。
如果相关系数为-1,表示两个变量呈现完全负相关,即一个变量的增加导致另一个变量的减少;如果相关系数为+1,表示两个变量呈现完全正相关,即一个变量的增加导致另一个变量的增加;如果相关系数为0,表示两个变量之间没有线性关系。
相关分析有很多应用,尤其在社会科学和市场研究领域。
例如,在经济学中,相关分析可以用来研究不同经济指标之间的关系,进而预测经济发展的趋势。
在市场研究中,相关分析可以用来研究产品销售量与广告投入之间的关系,从而为企业制定营销策略提供支持。
在医学研究中,相关分析可以用来研究药物治疗效果与患者病情之间的关系,以便优化治疗方案。
进行相关分析的步骤通常包括以下几个方面:1.收集数据:首先需要收集两个或多个变量的相关数据。
这些数据可以通过实验、调查或观察来获取。
2.计算相关系数:根据收集到的数据,可以使用相关系数来度量变量之间的关系。
最常用的是皮尔逊相关系数,它适用于连续性变量。
如果变量是分类变量,可以使用斯皮尔曼相关系数。
3.判断关联性:计算出相关系数之后,就可以判断变量之间的关联性。
一般来说,绝对值大于0.7的相关系数被视为强相关,绝对值在0.3到0.7之间的相关系数被视为中等相关,而绝对值小于0.3的相关系数被视为弱相关。
4.分析结果:根据相关系数的大小和方向,可以对变量之间的关系进行解释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
l l l 0; l ,l
2 1 2 2 2 p1 (1)
( p1 )
; m ,m
(1)
( p1 )
可得到p1对线性组合Ui=l(i)’X(1), Vi=m(i)’X(2),称 每一对变量为典型变量. 其极大值 rU1V1 l1 称为第一典型相关系数. 一般只取前几个影响 大的典型变量和典型相关系数来分析.
SPSS的实现
对例tv.sav,首先打开例14.1的SPSS数据tv.sav, 通过File-New-Syntax打开一个空白文件(默认 文件名为Syntax1.sps),再在其中键入下面命令 行:
MANOVA led hed net WITH arti com man /DISCRIM ALL ALPHA(1) /PRINT=SIG(EIGEN DIM).
1
1 ˆ 其中 li2为 A R111R12 R22 R21 的特征根.
i 1
under H 0 , Q0 m ln ( p1 p2 ) ( when n 1)
2
1 m n 1 ( p1 p2 1). 2
如果H0为检验第r(r<k)个典型相关系数的显著性
计算结果
第一个表为判断这两组变量相关性的若干检验, 包括Pillai迹检验,Hotelling-Lawley迹检验, Wilks l检验和Roy的最大根检验;它们都是有 两个自由度的F检验。该表给出了每个检验的F 值,两个自由度和p值(均为0.000)。
计算结果
下面一个表给出了特征根(Eigenvalue),特征根所占的 百分比(Pct)和累积百分比(Cum. Pct)和典型相关系数 (Canon Cor)及其平方(Sq. Cor)。看来,头两对典型变 量(V, W)的累积特征根已经占了总量的99.427%。它们 的典型相关系数也都在0.95之上。
附录
两个变量时,用线性相关系数研究两 个变量之间的线性相关性:
Cov( X , Y ) Corr ( X , Y ) Var ( X )Var (Y ) rxy
( x x )( y y )
i i
(x x ) ( y y)
2 i i i i
i
2
返回
典型相关分析
典型相关系数 而且V1, V2, V3,…之间及而且W1, W2, W3,…之间互不相关。这样又出现了选 择多少组典型变量(V, W)的问题了。实 际上,只要选择特征值累积总贡献占主 要部分的那些即可。 软件还会输出一些检验结果;于是只要 选择显著的那些(V, W)。 对实际问题,还要看选取的(V, W)是否 有意义,是否能够说明问题才行。至于 得到(V, W)的计算,则很简单,下面就 tv.txt数据进行分析。数学原理?
典型相关分析
13.1两组变量的相关问题
我们知道如何衡量两个变量之间是
否相关的问题;这是一个简单的公 式就可以解决的问题(Pearson相关 系数、 Kendall’s t、 Spearman 秩相关系数)。公式 如果我们有两组变量,如何能够表 明它们之间的关系呢?
例子(数据tv.txt)
可以看出,头一个典型变量V1相应于前 面第一个(也是最重要的)特征值,主 要代表高学历变量hed;而相应于前面 第二个(次要的)特征值的第二个典型 变量V2主要代表低学历变量led和部分的 网民变量net,但高学历变量在这里起负 面作用。
计算结果
类似地,也可以得到被称为协变量(covariate)的 标准化的第二组变量的相应于头三个特征值得三 个典型变量W1、W2和W2的系数: 。
因此l2既是A又是B的特征值, 而相应的特征 向量为l,m
1 11 12
1 22
1 22
1 21 11 12
A和B的特征根有如下性质: (1)A和B有相同 的非零特征根, (2)其数目为p1. A和B的特征 根非负. (3) A和B的特征根均在0和1之间. 我们表示这些称为典型相关系数的非零特 征值和相应的特征向量为
ˆ 检验统计量为 r 1 (1 li2 )
i r p1
under H 0 , Q0 m ln 2 ( f ) ( when n 1) 1 m n r ( p1 p2 1); f ( p1 r 1)( p2 r 1) 2
再点击一个向右的三角形图标(运行目前程序,Run current),就可以得到所需结果了。 还可以把Syntax1.sps另以其他名字(比如tv.sps) 存入一个文件夹。下次使用时就可以通过File- Open-Syntax来打开这个文唯 一不能用SPSS的点击鼠标的“傻瓜” 方式,而必须用写入程序行来运行的模 型。读者不必要再去研究语法的细节, 只要能够举一反三,套用这个例子的程 序即可。 当然,如果读者愿意学习SPSS的语法, 则在处理数据时,肯定会更方便。
计算结果
对于众多的计算机输出挑出一些来介绍。下面表格 给出的是第一组变量相应于上面三个特征根的三个 典 型 变 量 V 1 、 V2 和 V3 的 系 数 , 即 典 型 系 数 (canonical coefficient)。注意,SPSS把第一组变 量称为因变量(dependent variables),而把第二组 称为协变量(covariates);显然,这两组变量是完 全对称的。这种命名仅仅是为了叙述方便。 这些系数以两种方式给出;一种是没有标准化的原 始 变 量 的 线 性 组 合 的 典 型 系 数 (raw canonical coefficient) , 一 种 是 标 准 化 之 后 的 典 型 系 数 (standardized canonical coefficient)。标准化的 典型系数直观上对典型变量的构成给人以更加清楚 的印象。
当然在实际例子中一般并不知道S。因 此在只有样本数据的情况下, 只要把S用 样本协差阵或样本相关阵代替就行了。 但是这时的特征根可能不在0和1的范围, 因此会出现软件输出中的特征根(比如 大于1)不等于相关系数的平方的情况, 这时,各种软件会给出调整后的相关系 数。
典型相关和回归分析的关系 把X(1)和X(2)换成回归中的X和Y, 这就是因 变量和自变量之间的相关问题. 而Y在X上 的投影,就是回归了.
例子结论
从这两个表中可以看出,V1主要和变量hed相关, 而V2主要和led及net相关;W1主要和变量arti及 man相关,而W2 主要和com相关;这和它们的 典型系数是一致的。 由于V1 和W1 最相关,这说明V1 所代表的高学历 观众和W1 所主要代表的艺术家(arti)及各部门经 理(man)观点相关;而由于V2和W2也相关,这说 明V2 所代表的低学历(led)及以年轻人为主的网 民(net)观众和W2 所主要代表的看重经济效益的 发行人(com)观点相关,但远远不如V1和W1的相 关那么显著(根据特征值的贡献率)。
和X(2)是否相关,如不相关, 就不必讨论.如果
X ( X (1) , X (2) ) ' N p1 p2 ( m , S). H 0 : Cov( X (1) , X (2) ) S12 0
这是为检验第1个典型相关系数的显著性 p ˆ 检验统计量为 (1 li2 )
SPSS的实现
注意2:一些SPSS的输出很长,这时输出窗 口截去了一些内容没有显示(这有些随意 性)。这时输出窗口(SPSS Viewer)中结果的 左下角有一个红色的三角型。 如果想要看全部内容,可以先点击鼠标左键, 选中输出结果,然后从点右键得到的菜单中 选择Export,就可以把全部结果(包括截去 的部分)存入一个htm形式的文件了供研究和 打印之用。
典型变量
假定两组变量为X1,X2…,Xp 和Y1,Y2,…,Yq ,那么, 问题就在于要寻找系数a1,a2…,ap 和b1,b2,…,bq , 和使得新的综合变量(亦称为典型变量 (canonical variable))
V a1 X 1 a2 X 2 a p X p W b1Y1 b2Y2 bqYq
这是Lagrange乘数法求下面f的极大值
f l ' S12 m (l ' S11l 1) (m ' S 22 m 1)
2 2
经过求偏导数和解方程, 得到ln=l’S12m=Cov(U,V), 及
l
n
Al l l , Bm l m,
2 2
( A S S S S21 , B S S S S )
而 X (1) 的协方差阵S>0,均值向量m=0, S X (2) 的剖分为: S11 S12 S X S 21 S 22
对于前面的新变量U=l’X(1)和V=m’X(2) Var(U)=Var(l’X(1) )=l’S11l Var(V)=Var(m’X(2) )=m’S22m Cov(U,V)=l’S12m, rUV=l’S12m/[(l’S11l)(m’S22m)] ½ 我们试图在约束条件Var(U)=1, Var(V)=1下寻求 l和m使rUV= Cov(U,V)=l’S12m达到最大.
典型变量的性质:
(1)X(1)和X(2)中的一切典型变量都不相关. (2) X(1)和X(2)的同一对典型变量Ui和Vi之间的 相关系数为li, 不同对的Ui和Vj(i≠j)之间不 相关.
样本情况, 只要把S用样本协差阵或样本相关阵R代替. 下面回到我们的例子。
典型相关系数的显著性检验: 首先看X(1)
由于一组变量可以有无数种线性组合 (线性组合由相应的系数确定),因此 必须找到既有意义又可以确定的线性组 合。 典型相关分析(canonical correlation analysis)就是要找到这两组变量线性组 合的系数使得这两个由线性组合生成的 变量(和其他线性组合相比)之间的相 关系数最大。