第三章 实验设计
第三章_心理学实验设计

O1:
O2:
Ob1
Xb2
O3:
O21 O22 …. O2k
O4:
O41 O42 …. O4k
R R R R R R
Xa1Xb1 Xa1Xb2 Xa2Xb1 Xa2Xb2 Xa3Xb1 Xa3Xb2
O1 O2 O3 O4 O5 O6
Xb1
O11 O31 O12 O32 O1: …. O3: …. O1k O3k
X
表示事后回溯设计中的自变量,是研究者不能操纵或改变的
五、实验设计的基本术语
1、因素与水平
因素:自变量
可以是刺激变量,也可以是被试变量
水平:因素的特定值称为“水平”或称为“处理”
2、水平结合
或者一个处理结合
一个因素的某一水平与另一因素的某一水平的结合,成为一个水平结合,
例如:噪声强度两个水平:40分贝(A1)、60分贝(A2);
可考察各个自变量对同一因变量的主要影响效应主效应可考察各个自变量交互作用对因变量的主要影响效应交互作用可考察一个自变量的各个水平在另一个因素的某个水平上的效应简单效应2完全随机化多因素设计模式a基本模式b数据的统计分析独立样本的多因素方差分析4随机化区组多因素实验设计a什么是随机化区组多因素实验设计在析因设计中还可以用一个组的被试去接受设计中每一种因素各个水平组合成的全部处理观测得到每个被试的全部反应分数就是一个区组至于哪个被试先接受哪一种实验处理则须用随机分配的方法来决定b基本模式c数据的统计分析随机化区组多因素方差分析重复测量的方差分析d优点a所需的被试人数少是完全随机化多因素设计中的一组b减少了个体差异5分区重复测量的多因素实验设计在析因实验设计中对被试的分配有时采用随机分配与重复测量相结合的方法即对一种或几种自变量用随机分配法而对其它自变量则用重复测量法这种综合分配的多因素实验设计被称为分区重复测量多因素实验设计多因素混合设计a基本模式a3b数据的统计分析采用重复测量的方差分析年龄组第一测试年第二测试年第三测试年交叉聚合实验设计p146148交叉聚合设计包括横断设计纵向设计和时间延迟设计推断年龄是发展的一个原因二准实验设计quasiexperimentaldesigns1单组准实验设计2多组准实验设计单组准实验设计1时间系列设计a设计模式
实验心理学,第三章 实验设计

喜好饮料问题
有效的实验设计应该是这样的:两个杯子一模一样, 既没有字母,也没有任何其他不同的标记可以让被试 看见或摸得到。
将可口可乐或百事可乐分别倒进两只杯里,一半被试 先饮可口可乐,然后饮百事可乐;另一半被试先饮百 事可乐,然后饮可口可乐。
这样的实验安排就不存在喜欢字母的问题了,而且, 实验顺序的效应也抵消了。
举例:在某项研究中要将30 个被试分配到三个自变量 水平A、B、C 中。
研究者需要先将被试按前测作业分数的高低排列,然后 将前三个被试随机分配到A、B、C 三组,接着将接下 来的三个被试如法分配,直到分配完毕。
1、匹配(matching)设 计
对动物进行被试间设计的实验研究时,一项重要的匹 配技术是拆窝技术(split-litter technique)。
同处理之前是相等的,即使有差异也是在统计允许的 限度以内的随机误差。
随机化设计的优缺点
优点: (1)控制两组被试变量的差异,分组方法简单可行。 (2)由于对每一被试者只作一次观测,可消除某些实
验误差。 缺点: (1)分成等组的方法仍欠精密。 (2)若两组在不同时期观测,就有可能插入实验以外
编制之测量工具的“信度”(可靠性)较低时。
研究进行中有较多变量无法控制时。
统计分析时,受试者须再细分为较小的各群组来分析比较 时。
实验设计时,预期会有较多受试者中途推出时。
怎样确定实验研究中被试样本人数
确定样本人数时要考虑以下因素 1、实验研究所要求的精确度 精确度是指样本平均数与总体平均数的一致性程度。精确度
定时系列设计模式
说明:Y1a、Y1b、Y1c分别表示实验处理前之观测值 Y2a、Y2b、Y2c分别表示实验处理后之观测值 X表示实验条件处理
预习第三章实验设计的基本类型详解演示文稿

现在是20页\一共有78页\编辑于星期三
配对组设计的步骤
现在是21页\一共有78页\编辑于星期三
配对组设计的优缺点
现在是22页\一共有78页\编辑于星期三
三、数据处理方法(SPSS软件)
➢ 包含的统计变量:实验的自变量A,实验的因变量Y。 ➢ 预期的统计结果:自变量A的主效应是否显著,即 F((P-1), P(n-1))
1
Y1a、Y1b、Y1c
X
说明:Y1 a、Y1b、Y1c 表示实验处理前的观测值
Y2a、Y2B、Y2C 表示实验处理后的观测值
X 表示实验条件处理
Y2a、Y2B、Y2C
➢ 举例:代币制对儿童问题行为的矫正作用
现在是34页\一共有78页\编辑于星期三
定时系列设计的优缺点
现在是35页\一共有78页\编辑于星期三
现在是30页\一共有78页\编辑于星期三
第一次参加射击运动的人在接受打靶训练前后打靶成绩的变化。
组数 1
表3 实验前与实验后设计模式
前观测
处理
Y1
X
说明:Y1 表示实验处理前对被试观测所得的值
Y2 表示实验处理后对被试观测所得的值
X 表示实验条件处理
后观测 Y2
现在是31页\一共有78页\编辑于星期三
在第一节课接近下课时,要求全班同学完成一项“克列别 林加算测验”。然后将同学随机分成第1组和第2组两组。让第 1组同学到操场跑步(实验组),第2组同学像往常一样开展正 常的课间休息(控制组)。经过10分钟的跑步,第1组同学又 被老师带回教室,稍作休息后,要求全班同学再完成一次“克 列别林加算测验”(一个自变量两种处理)
是把被试随机分配到自变量不同水平界定的实验条件下,接受不同的实 验处理。也就是说,要把被试随机分成几组,每一组被试只参加一种条 件下的实验,组与组之间的反应结果不产生相互影响,因此是独立的, 故称独立组实验设计。
第三章 准实验设计与单被试研究设计

或撤销一个处理,是否使被试的行为产生了显著改变。具体来说,就
是单元转换前后被试的行为模式是否有显著性差异。
2. 单元转换的时机
是否开始一个新的单元,主要取决于先前单元是否有清晰、明确
的模式。当然,其他因素也能影响何时和是否转换单元,比如:如果
基线单元的数据趋势已经表明病人的行为正在改善时,研究者不宜采 用新的处理单元对之进行干预;当基线数据显示出行为方面的严重危
方法学习50个生字,同时检测第四周学习的效果,依此类推,第五到第 八周都采用新的识字教学法。则八周识字教学的效果记录如下:
时间序列设计是对一组被试或个体进行一系列周期性测 量,在测量的时间序列中引进实验处理(X),然后观测引 进实验处理前后测量结果的变化趋势,从而推断实验处理是 否产生效果。
它的设计模式如下:
中位数检验的具体做法是:首先将两组数据合并成一个容量为N=n1+n2的样本,
再找出这个样本的中位数m。然后统计出X样本中大于m的数据个数a,小于或等于 m的数据个数b;Y样本中大于m的数据个数c,小于或等于m的数据个数d,再进行 χ 2检验。现在我们就以上述数据为例说明这一检验过程。
第一步:计算实验组X的后测与前测的差异量、控制组Y的后测与前测的差异量:
第三章
准实验设计与单被试研究设计
生态化运动不只是发生在心理学中,而是几乎所有的人文学 科中。许多人文学科过分追随自然科学的研究取向,采用分解还 原的方法,导致了对整体人研究的忽视,更忽视了社会文化及生 活情境对人的精神的影响。这种研究取向受到人本主义和后现代 哲学思潮的严厉批评,引发人文科学研究中两种文化的分裂及尖
三单被试研究设计17研究结果不能提供一系列被试组分方差和进行统计显著性检验单被试实验结果的呈现与解释常常依靠图示比如右图所显示的资料是来自于一项考察班级不团结行为矫治效果的研究这是其中一个学生的行为表现用直线将各个数据点连接起来有助于对比处理前后行为模式的改研究结果不能提供一系列被试组分数无法计算平均数方差和进行统计显著性检验
实验心理学基础讲义 第三章 实验的设计
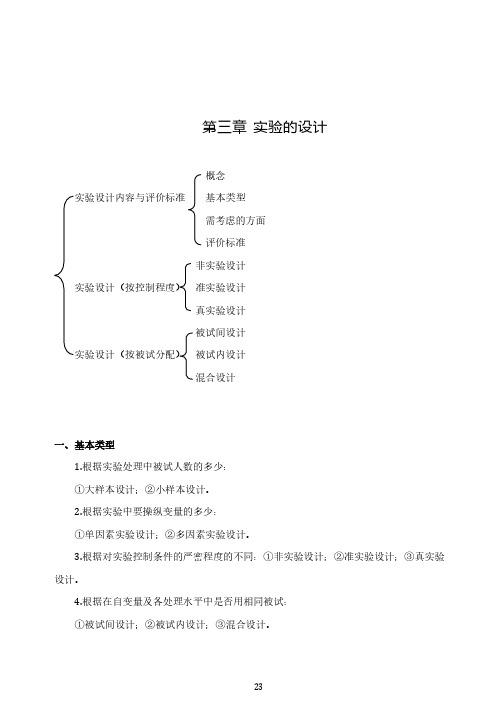
第三章实验的设计概念实验设计内容与评价标准基本类型需考虑的方面评价标准非实验设计实验设计(按控制程度)准实验设计真实验设计被试间设计实验设计(按被试分配)被试内设计混合设计一、基本类型1.根据实验处理中被试人数的多少:①大样本设计;②小样本设计。
2.根据实验中要操纵变量的多少:①单因素实验设计;②多因素实验设计。
3.根据对实验控制条件的严密程度的不同:①非实验设计;②准实验设计;③真实验设计。
4.根据在自变量及各处理水平中是否用相同被试:①被试间设计;②被试内设计;③混合设计。
二、被试间/内和混和设计一、被试间设计1.含义2.优缺点3.解决缺点的方法二、被试内设计1.含义2.优缺点3.克服缺点的方法三、混合设计1.含义2.如何计算实验处理数3.优缺点及克服方法两个技能:1.区分被试间设计、被试内设计、混合设计2.在混合设计中,区分被试内因素和被试间因素(一)被试间设计1.含义:每个被试只接受一个的处理,各自独立地在不同的处理条件下接受因变量的测量。
也被称为组间设计、独立组实验设计。
每个被试一个处理内和混和设计2.优缺点(1)优点12岁小学生40岁大叔80岁青光眼老爷爷一个处理方式不会污染另一种处理方式,避免了顺序效应(练习、疲劳)(2)缺点1)被试差异对实验造成的影响难以控制;2)需要的被试数量比较大。
3.克服缺点的方法缺点是由于不同的被试有差异造成的!因此,解决方法就是减小被试间的差异如何减少不同被试组之间的差异?(1)匹配法:将被试按某一个或几个特征上水平的相同或相似加以配对,然后把每对中的被试随机分配到各组,使各组之间的被试同质。
步骤:第一步前测,第二步分数配对,第三步随机分组2)匹配法的问题:第一,特征太多,无法完全匹配第二,工作量大第三,在多个特征之间有交互作用时,可能混淆实验结果第四,可能出现回归假象(2)随机化法:把被试随机分配到不同的组,接受不同的自变量处理。
随机化法的统计学前提:各随机被试组在未经过不同处理之前时相等的(差异在统计允许的限度内)(二)被试内设计1.含义:每个被试都会受到所有水平自变量的影响每个被试所有水平2.优缺点(1)优点1)节约被试人数2)排除了个体差异(2)缺点1)接受不同处理时的时间间隔,可能会有偶然事件发生影响实验结果。
试验设计和统计分析 第三章 田间试验技术

九、设置保护行
指在试验地的周围设置保护行。小区与小区之间一般不设保护行,重复区之间一般也不设保护行。保护行的树种一般逸捧以不影响甙硷地树木生 长为壹。例如:杉木成發,用柳衫作保护行。
5. 进行区组及小区的区划;6. 试验材料的准备、编号;7. 根据设计图将各个处理对号安排到试验地里;8. 绘制田间栽植图,并且与设计图对照,查看是
否有错误,如果发现错误,要及时纠正;9.栽植保护行,并作地标。
试验布置中要注意以下几点:
1)设计一定要根据试验的要求和试验地的实际
进行选择;2) 试验材料一定要编号(处理号和区组号), 并且要反复校对,不要出现错误;3) 对试验地的面积计算要根据小区的面积和重
十、设置地标
田间试验在野外较长时间,为了观察管理方便,
便于查找,设置地标是必要的。特别是造林试验,一般在试验范围的四周的每 个角埋上水泥桩。并要钉一个牌子,写明试验用地, 以示警示。
十一、田间试验的步骤
1. 拟定试验计划2. 确定试验因素、处理数、重复数、小区面 积,计算区组面积。3. 选择一个适宜的设计方案(设计方案在下 一章介绍)4. 选择试验用地
试验因素和处理(水平)数的确定1、试验因素的确定:试验因素是根据试验目的来提出的,那么根据试验目的来确定试验因素的类型及多少。同时也要考虑试验的条件、人力、财力、技术水平。
2、试验处理(水平)数的确定1) 处理数的多少依据试验的实际和别人的经验确定。2) 各处理间的效应要有明显的差异3) 各处理间的间距尽量相等
8、试验孑旨标(experiment indicator):指试验中用来判断试验处理效果的性状或标准。
第三章 正交试验设计
因素水平表
第三步选择正交表 可选择正交表L9(34)安排正交试验,将
A、B、C三个因素安排在前3列,见下表。
正交表L9(34)
第四步安排试验及试验结果
第五步试验结果分析
直观分析 极差分析 方差分析
直观分析
直观分析就是找正交表中安排的9次试验中 好的试验条件。本例试验目的是降低启动 压力,所以压力越小越好,即第3号试验的 试验条件在9次试验中是最好的。试验条件 是A1B3C3,压缩量为6%,粗糙度为0.8, 内径大小28。
二战后实验设计法在工业中得到推广和应用; 日本学者田口玄一首先将实验设计成功得应用于
新产品的开发。对于一些复杂的过程和产品,利 用实验设计法合理的选择适当的参数,可以大大 改善产品功能目标值的稳定性,即所谓稳健性设 计; 20世纪70年代初期,我国着名数学家华罗庚带 头在我国推广实验设计法。
三、实验设计法
设计质量管理——试验设计
质量管理中,经常会遇到多因素、有误差、 周期长之类试验,希望解决以下问题:
1. 对质量指标的影响,哪些因素较重要? 2. 每个因素取什么水平为好? 3. 各个因素按什么水平搭配较好? 试验设计是处理这类试验问题的一种简便易
行、行之有效的方法。
产品开发的三个阶段
顾客 要求
系统设计 容差设计
第二节单指标正交试验设计
正交表 正交试验设计
一、正交表
正交表为试验设计表的一类,具有较强的 代表性。
正交表的符号表示为:L a(b c) 其中:L----正交试验表的代号 a----正交表的试验次数 b----正交试验的水平数 c---- 正交试验的因素数 N=bc--- 全因子试验次数(即全部的因素和
参数设计
稳定性好 的产品
医学统计学第3章实验设计
设计类型、估算样本含量、选定统计分析指标和方法等。
根据研究者是否人为地设置处理因素,即是否给予干预
措施,可将医学研究分为调查研究和实验研究两大类。
1. 调查研究
又称观察性研究或非实验性研究,确切地说应是非随机
化对比研究。它对研究对象不施加任何干预措施,是在 完全“自然状态”下对研究对象的特征进行观察、记录, 并对观察结果进行描述和对比分析。
依照因素与水平的不同,可产生四类实验:
单因素单水平实验,如研究教育干预法预防小儿单纯性
肥胖的效果; 单因素多水平实验,如研究不同含氟制剂的防龋效果; 多因素单水平实验,如比较不同治疗方案对椎间盘突出 的治疗效果; 多因素多水平实验,如研究多种药物不同剂量的联合治 疗对消化溃疡的疗效。
与处理因素相对应并同时存在的是非处理因素。某些非
性。
三、实验效应
实验效应是处理因素作用下,受试对象的反应或结局,
它通过观察指标来体现。 选择观察指标时,应当注意以下几点:
1. 客观性
观察指标有主观指标和客观指标之分,主观指标是指被
观察者的主观感受、记忆、陈述或观察者的主观判断结 果;而客观指标则是借助测量仪器或实验室检查等手段 获得的结果。 在临床试验中,主观指标易受观察者和被观察者心理因
组的研究对象数量出现较大差异。应用随机化排列可避 免这种现象。(中医药统计学与软件应用:附表17)
1. 完全随机化 完全随机化就是直接对受试对象进行随机化 分组,分组后各组受试对象的例数不一定相 等。其具体步骤如下: (1) 编号 将n个受试对象按一定顺序编号,如动物可
对照形式有多种,常有以下几种: 1. 安慰剂对照 安慰剂或称伪药物,是一种无药理作用的制剂,不含试 验药物的有效成分,但其外观如剂型、大小、颜色、重
第三章正交试验设计中的方差分析2例题分析
第三章_正交试验设计中的方差分析2-例题分析第三章中的例题分析是关于正交试验设计中的方差分析的。
本例题分析主要涉及到两个因素和一个响应变量,通过正交试验设计的方法,对这两个因素的影响进行分析。
首先,我们需要了解正交试验设计的基本原理。
正交试验设计是一种实验设计方法,通过选择合适的试验因素和水平,使得每个试验条件都能够得到充分的信息,从而降低试验误差,提高试验效率。
在正交试验设计中,试验因素之间是相互独立的,这样可以更好地分析每个因素对响应变量的影响。
在本例题中,我们有两个因素,分别记作因素A和因素B,每个因素有两个水平。
我们还有一个响应变量Y,需要确定因素A、因素B和Y之间的关系。
接下来,我们需要进行方差分析。
方差分析是一种用于比较不同因素对响应变量的影响的统计方法。
在本例题中,我们可以使用两因素方差分析来分析因素A和因素B对响应变量Y的影响。
首先,我们需要计算总平方和(SST),表示响应变量的总变异。
然后,我们需要计算因素A的平方和(SSA),表示因素A对响应变量的影响,以及因素B的平方和(SSB),表示因素B对响应变量的影响。
同时,我们还需要计算交互作用的平方和(SSAB),表示因素A和因素B之间的交互作用对响应变量的影响。
接下来,我们可以计算各个平方和的自由度和均方差,从而得到F值。
F值可以用来判断因素对响应变量的影响是否显著。
如果F值大于临界值,则说明该因素对响应变量的影响是显著的。
最后,我们可以进行多重比较,比较每个因素水平之间的差异。
多重比较可以帮助我们确定哪些因素水平之间的差异是显著的。
通过以上的分析,我们可以得出因素A、因素B和响应变量Y之间的关系。
同时,我们还可以根据多重比较的结果,确定哪些因素水平之间的差异是显著的。
总结起来,本例题分析主要涉及到正交试验设计中的方差分析。
通过对两个因素和一个响应变量进行分析,我们可以确定因素对响应变量的影响是否显著,并确定哪些因素水平之间的差异是显著的。
第3章-实验研究设计
全国成人高等医学教育系列教材
第二节 实验研究设计基本要素和基本原则
实验研究(experimental study)是指研究者根据研究目的人为地对受 试对象(包括人或动物)施加处理因素,控制非处理因素,分析比较 处理因素效应的一种研究方法。
全国成人高等医学教育系列教材
一、实验研究设计的基本要素 受试对象 受试对象又称研究对象,是处理因素作用的客体。根据研究目的不同, 受试对象可以是人、动物和植物,也可以是某个器官、细胞或者是机 体的生物材料。
Z Z n
2
n
表示所需的样本含量
Z 单侧或双侧的界值
Z 单侧界值 容许误差 总体标准差
全国成人高等医学教育系列教材
两样本均数比较的样本含量估计
Z Z n 2
2
n
表示所需的样本含量
Z 单侧或双侧的界值
全国成人高等医学教育系列教材
二、实验研究设计的基本原则 对照原则 对照是比较的基础,有比较才有鉴别,对照的设立是控制混杂因素不可 缺少的重要原则。对照是指除试验组外,再设置一个或多个对照组进 行同步试验,其目的在于使处理因素和非处理因素的差异有一个科学 对比,消除或减少实验误差。
全国成人高等医学教育系列教材
实验研究设计中,受试对象被分到试验组还是对照组、是接受处理因素 或者非处理因素不是由研究者主观决定,而是通过随机化的方法来确 定的,此方法的目的是控制或消除非处理因素对研究结果的影响。
全国成人高等医学教育系列教材
二、实验研究设计类型 动物实验(animal experiment) 动物实验即以动物作为研究对象。在 动物实验设计中,可以严格地控制实验条件,包括实验的环境、温度、 湿度等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
A.极差B.方差C.标准差D.变异系数E.无正确选项
答案:A
20.均数是表示观察值的什么指标
A.变化范围B.离散程度C.个体差异D.平均水平E.无正确选项
答案:D
21.有关离散度指标意义中,描述不正确的是
A.数值越大,说明个体差异越大B.数值越大,说明观察值的变异程度越大
答案:假设检验
5.统计工作必须持严肃认真、实事求是的科学态度,不可_____________________统计数据。
答案:伪造和篡改
三、判断题
1.同一实验因素在数量上或强度上的不同程度,称为水平。()
答案:√
2.实验中根据研究目的确定的由实验者人为施加给实验对象的因素,称为区组因素。()
答案:×
3.凡是靠客观衡器的度量得到的指标称为定性指标。()
A.均数不变,标准差改变B.均数改变,标准差不变C.两者均不变D.两者均改变E.无正确选项
答案:B
32.关于标准差,以下哪些项是错误的()
A.反应样本观察值的离散程度B.度量了数据偏离样本均数的大小C.反映了平均数代表性的好坏D.不会小于样本平均数E.无正确选项
答案:D
33.调查某单位人员糖尿病患病情况,以空腹血糖值大于等于7.5的标准定为患糖尿病,结果在1000人中有23名糖尿病患者,977名非患者,整理后的资料是()
A.统计设计B.搜集资料
C.整理资料D.分析资料
答案:A
5.通过专题调查或专项实验获取相关数据属于统计工作中的()
A.统计设计B.搜集资料
C.整理资料D.分析资料
答案:B
6.通过科学的分组和归纳,使原始资料系统化、条理化.属于统计工作中的()
A.统计设计B.搜集资料
C.整理资料D.分析资料
答案:C
7.对数据进行统计描述与统计推断属于统计工作中的()
A.抽样误差的大小B.总体参数的波动大小C.重复试验准确度的高低D.数据的离散程度E.无正确选项
答案:A
27.比较身高与体重两组数据的变异程度,宜采用
A.四分位数间距B.变异系数C.标准差D.方差E.无正确选项
答案:B
28.某医学资料数据大的一段没有确定数值,描述其集中趋势使用的统计指标是()
A.中位数B.算术平均数C.几何均数D.百分位数E.无正确选项
A.数值数据B.定性数据C.定类数据D.定序数据E.以上都不是
答案:C
34.为反应300名老年人的舒张压数据的血压值分布状况,宜采用()
A.条形图B.直方图C.圆形图D.折线图E.散点图
答案:B
35.将一组数值数据资料整理成频数直方图(表)的主要目的是()
A.化成定类资料B.便于计算C.直观描述其数据的分布特征D.描述数值的变化E.以上都不是
答案:B
29.变异系数主要用于()
A.衡量正态分布的变异程度B.比较不同计量指标的变异程度C.衡量测量的准确程度D.衡量样本抽样误差的大小E.无正确选项
答案:B
30.对于近似正态分布资料,描述其变异程度常选用的指标是()
A.变异系数B.极差C.标准差D.四分位数间距E.无正确选项
答案:C
31.各观察值均加同一常数c后()
A.统计设计B.搜集资料
C.整理资料D.分析资料
答案:D
8.将由同一总体抽取的实验对象随机地分成两组或多组,然后接受不同处理,观察处理效应是否不同的实验设计称为()
A.完全随机设计B.配对设计
C.随机区组设计D.析因设计
答案:A
9.将实验对象按配对条件配成对子,再按随机化原则把每对中的两个体分别分配到实验组或对照组的实验设计称为()
6
3
1
A.成组资料B.配对资料C.等级资料D.个体资料E.无正确选项
答案:C
17.标准差越大说明
A.平均数值小B.观察值之间变异小C.平均数值大D.观察值之间变异大E.无正确选项
答案:D
18.10名新生儿出生体重均为3kg,则其体重的标准差为(kg)
A.3 B.1 C.0 D.2 E.无正确选项
答案:C
答案:√
四、计算题
答案:搜集资料
2.统计设计包括调查设计和_____________________。
答案:实验设计
3.整理资料要按照“_____________________,非同质者分开”的原则对资料进行质量分组并根据数后归纳汇总。
答案:同质者合并
4.分析工作包括两部分内容:一是参数估计,二是_____________________。
答案:×
4.靠人的感觉器官评定的指标称为定量指标。()
答案:×
5.当想按析因设计进行实验,但实验次数过多而不能承受时,部不同水平间有无差异,还可检验两个或多个因素间是否存在交互作用。()
答案:√
7.配对的条件一般以主要的非实验因素作为配比条件。()
C.随机区组设计D.析因设计
答案:D
12.只考虑实验点在实验范围内均匀分散的实验设计称为()
A.均匀设计B.配对设计
C.随机区组设计D.析因设计
答案:A
13.各观察值均加上或减去同一个常数后
A.均数不变,标准差改变B.均数改变,标准差不变C.两者都不变D.两者都变
E.无法确定
答案:B
14.欲比较7岁男童与20岁男青年的身高的变异程度,宜选用
C.数值越小,说明平均数的代表性越差D.数值越小,说明平均数的代表性越好
E.无正确选项
答案:C
22.一般来讲,表示个体变量值变异程度时,宜选用
A.算数平均数B.几何平均数C.标准误D.标准差E.无正确选项
答案:D
23.下列指标中不属于数值变量的是
A.身高B.体重C.血压D.职业E.无正确选项
答案:D
A.极差B.方差C.标准差D.变异系数E.无正确选项
答案:D
15.调查某人群的血型分布,清点各血型人数所得的资料属于
A.定性资料B.技术资料C.定量资料D.等级资料E.无正确选项
答案:C
16.用某冲新疗法治疗某病患者41人,治疗结果如下:该资料的类型是治疗人数
治疗结果
治愈
显效
好转
恶化
死亡
治疗人数
8
23
24.统计表内不应当出现的项目为
A.备注B.横标目、纵标目C.线条D.数字E.无正确选项
答案:A
25.关于统计表的制作,不正确的叙述是
A.统计表不用竖线和斜线分隔表、标目和数据
B.统计表的标题放在表的上方C.统计表包含的内容越多越好
D.统计表中的数字一般应按小数点位次对齐E.无正确选项
答案:C
26.标准误反映
A.完全随机设计B.配对设计
C.随机区组设计D.析因设计
答案:B
10.将几个实验对象按一定条件配成区组,再将每一区组的实验对象随机分配到各个处理组中的实验设计称为()
A.完全随机设计B.配对设计
C.随机区组设计D.析因设计
答案:C
11.将两个或多个因素的各水平交叉分组的实验设计称为()
A.完全随机设计B.配对设计
E.以上都不是
答案:C
38.比较腰围和体重两组数据变异度大小宜采用()
A.变异系数B.方差C.极差D.标准差E.众数
答案:A
39.各观察值同乘以一个不等于0的常数后,( )不变。
A.算术均值B.标准差C.中位数D.变异系数E.以上都不是
答案:D
二、填空题
1.统计工作分为统计设计、_____________________、整理资料、分析资料和运用资料五个基本步骤。
第三章实验设计
一、选择题
1.下列属于统计工作的基本步骤是()
A.学习资料B.整理资料
C.复习资料D.检查资料
答案:B
2.下列属于实验设计的基本要数是()
A.实验原理B.实验目的
C.实验因素D.实验方法
答案:C
3.下列不属于实验设计的基本原则的是()
A.重现B.重复
C.随机D.对照
答案:A
4.明确研究目的和研究检验假设,确定观察对象、样本含量和抽样方法,拟定研究设计方案、预期分析指标、误差控制措施、进度与费用等属于统计工作中的()
答案:C
36.比较某地10年间肝炎发病率的统计图宜用()
A.条形图B.直方图C.圆形图D.线图E.箱式图
答案:D
37.根据一组样本观测值计算得标注差其数值越小,则表明()
A.均值代表性越强,总体离散程度越大B.均值代表性越弱,总体离散程度越小C.均值代表性越强,总体离散程度越小D.均值代表性越弱,总体离散程度越大