曲线拟合
曲线拟合 归一化

曲线拟合归一化
目录
1.曲线拟合的定义和作用
2.归一化的定义和作用
3.曲线拟合和归一化在数据处理中的应用
4.曲线拟合和归一化的优缺点
5.结论
正文
曲线拟合是一种数学方法,用于在给定数据集上找到最佳匹配的曲线。
它可以帮助我们在数据中发现模式和趋势,从而更好地理解数据。
拟合的曲线可以是线性的,也可以是非线性的,具体取决于数据的特性。
曲线拟合在许多领域都有应用,包括经济学、物理学、生物学等。
归一化是一种数据处理的技术,它的主要目的是将数据转换到一个标准范围内,使得不同的特征之间的值可以进行直接的比较。
归一化的方法包括最大值和最小值归一化,以及标准差归一化等。
归一化可以提高模型的性能,特别是在数据量纲不同的情况下。
曲线拟合和归一化在数据处理中都有重要的应用。
曲线拟合可以用于拟合出数据集的函数关系,而归一化则可以将数据转换到同一量纲,方便后续的处理。
例如,在机器学习中,我们常常需要对输入数据进行归一化,以保证模型的稳定性和准确性。
曲线拟合和归一化都有其优缺点。
曲线拟合的优点是可以找出数据中的模式和趋势,但在数据量较少或者噪声较大的情况下,拟合的曲线可能会不准确。
归一化的优点是可以将数据转换到同一量纲,方便后续处理,但也可能会损失数据的原始信息。
总的来说,曲线拟合和归一化都是数据处理中常用的方法,它们可以帮助我们更好地理解和处理数据。
计算机 曲线 拟合公式

计算机曲线拟合公式
拟合曲线是指在已知一组数据的前提下,通过一定的数学方法,找出一个代表这组数据的曲线方程。
这个曲线方程可以用于对数据进行预测、分析和优化等操作。
常见的曲线拟合公式包括线性拟合、多项式拟合、指数拟合等。
1. 线性拟合
线性拟合是指拟合一个一次函数y=kx+b,其中k和b分别为
拟合曲线的斜率和截距。
通常使用最小二乘法来求解k和b。
最小二乘法是指通过最小化误差平方值的方法来确定k和b的值,误差平方值=∑(yi-(kxi+b))^2,其中yi为实际的数据值,
xi为自变量的取值。
通过求解误差平方值的导数,可以得到k
和b的值。
2. 多项式拟合
多项式拟合是指将一个多项式函数拟合到一组数据上。
多项式函数的一般形式为y=a0+a1*x+a2*x^2+…+an*x^n。
多项式拟
合的主要目的是通过多项式来描述数据中的非线性趋势。
常见的拟合方法包括最小二乘法、牛顿法、拉格朗日法等。
3. 指数拟合
指数拟合是指将一个指数函数y=a*exp(b*x)拟合到数据上。
这
种拟合常用于数据呈现出指数增长或衰减趋势的情况。
指数拟合的关键是通过对数变换将指数函数转化为线性函数,然后再进行线性拟合。
具体方法是对数据进行对数变换,然后用线性拟合的方法求解出a和b的值,再通过指数函数进行反推,得
到拟合曲线的方程。
以上是常见的曲线拟合公式及方法,拟合的具体选择要根据不同的数据趋势和实际需求进行决定。
曲线拟合方法

曲线拟合方法曲线拟合方法是在数据分析中应用广泛的一种数学模型,它能够有效地拟合一组数据,从而推断出它背后的现象,同时推断出现象的规律。
曲线拟合方法是最常用的无比可以满足实际应用要求的符号方法之一,在实际应用中可以清楚地看到它的优越性。
一、曲线拟合方法的定义曲线拟合方法是一种用来拟合数据的数学方法,即将一组数据拟合到一条曲线上,从而求解出拟合曲线的方程。
一般来说,曲线拟合方法是根据给定的数据集,通过最小二乘法来拟合出曲线的方程,以表述和描述该数据的特征。
曲线拟合方法给我们提供了一种比较直观和有效的数据分析工具,可以有效地发现数据中不同特征之间的关系,从而推断出它们背后的现象及其规律。
二、曲线拟合方法的基本思想曲线拟合方法的基本思想是将一组数据以曲线的形式,以拟合精度最高的方式拟合出曲线的方程。
有多种拟合方法,比如线性拟合、参数拟合、二次拟合、多项式拟合等,可以根据实际的数据特点,选择合适的拟合方法。
拟合方法的最终目的是使拟合曲线越接近原始数据,越接近实际情况,以此来求解出拟合曲线的方程,并且能够有效地反映出数据的规律特征。
三、曲线拟合方法的应用曲线拟合方法在实际工程中被广泛应用,它的应用非常广泛,可以用于各种数据的拟合,其中包括统计学中的数据拟合、物理学中拟合各种非线性函数曲线,以及优化、控制理论中根据给定数据拟合控制参数等。
曲线拟合方法可以有效地发现数据中不同特征之间的关系,从而推断出它们背后的现象,以及它们背后的规律,因此,曲线拟合方法在预测及数据分析中具有重要的作用。
四、曲线拟合方法的优缺点曲线拟合方法的优点在于它的拟合效果好,能够有效地发现数据中不同特征之间的关系,从而推断出它们背后的现象,以及它们背后的规律,因此它可以提供丰富、有价值的数据分析以及预测服务。
但是,曲线拟合方法也有一些缺点,比如它拟合的曲线不一定能够代表实际情况,有可能导致拟合出错误的结果,因此在使用时要注意控制拟合精度。
ai曲线拟合

ai曲线拟合
AI曲线拟合是指利用人工智能算法对给定的数据进行拟合,找到一个最佳的函数或曲线来描述数据的趋势和规律。
这个过程可以用于预测未来的数据点、揭示数据之间的关系、寻找最优解等。
在进行AI曲线拟合时,通常会使用一些常见的机器学习算法,如线性回归、多项式回归、支持向量回归、神经网络等。
具体的选择取决于数据的特点和需求。
在进行曲线拟合之前,需要先对原始数据进行预处理,包括数据清洗、归一化、特征选择等。
然后将数据分为训练集和测试集,用训练集来训练模型,再用测试集来评估模型的拟合效果。
在训练模型时,算法会尝试不同的拟合函数或曲线,通过调整函数的参数来使得模型与实际数据的差距最小化。
这个过程称为参数优化或模型训练。
最后,通过评估指标(如均方根误差、决定系数等)来判断模型的拟合效果,并根据需要对模型进行调整和改进。
需要注意的是,AI曲线拟合并不是万能的,它只能根据已有的数据找到一个最佳的拟合函数或曲线。
在使用时需要合理选择算法和模型,并结合领域知识和实际情况进行判断和解释。
第5章-1 曲线拟合(线性最小二乘法)讲解
求所需系数,得到方程: 29.139a+17.9b=29.7076 17.9a+11b=18.25
通过全选主元高斯消去求得:
a=0.912605
b=0.174034
所以线性拟合曲线函数为: y=0.912605x+0.174034
练习2
根据下列数据求拟合曲线函数: y=ax2+b
x 19 25 31 38 44 y 19.0 32.3 49.0 73.3 97.8
∑xi4 a + ∑xi2 b = ∑xi 2yi
∑xi2 a + n b = ∑yi
7277699a+5327b=369321.5 5327a+5b=271.4
曲线拟合的最小二乘法
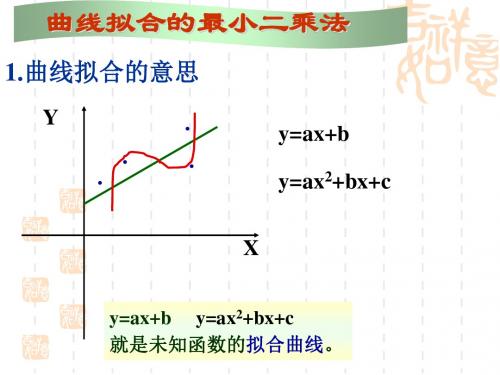
1.曲线拟合的意思
Y
.
.
.
.
y=ax+b y=ax2+bx+c
X
y=ax+b y=ax2+bx+c 就是未知函数的拟合曲线。
2最小二乘法原理
观测值与拟合曲线值误差的平方和为最小。
yi y0 y1 y2 y3 y4…… 观测值 y^i y^0 y^1 y^2 y^3 y^4…… 拟合曲线值
拟合曲线为: y=(-11x2-117x+56)/84
x
yHale Waihona Puke 1.61 1.641.63 1.66
1.6 1.63
1.67 1.7
1.64 1.67
1.63 1.66
1.61 1.64
1.66 1.69
1.59 1.62
curvefitting拟合三元函数

curvefitting拟合三元函数曲线拟合是一种数学处理方法,旨在通过选择最佳拟合曲线来描述数据集的趋势和关系。
对于三元函数的曲线拟合,我们需要考虑三个变量之间的关系,并找到最适合数据的曲线模型。
一般而言,三元函数可以表示为f(x,y)=z,其中x、y和z分别是自变量和因变量。
我们的目标是找到合适的函数形式来描述x、y和z之间的关系。
根据数据集的分布情况,我们可以选择适当的函数模型进行拟合。
以下是一些常见的三元函数模型:1. 线性函数:f(x, y) = ax + by + c,其中a、b和c是拟合曲线的系数。
这个模型适合于变量之间的简单线性关系。
2. 多项式函数:f(x, y) = ax² + bxy + cy² + dx + ey + f。
这个模型适合于拟合包含二次或更高次项的数据。
3. 指数函数:f(x, y) = ab^(cx) + dy。
这个模型适用于自变量和因变量之间存在指数增长或衰减的情况。
4. 对数函数:f(x, y) = a + bln(x) + cln(y)。
这个模型适用于数据集呈现出对数增长或衰减的情况。
5.样条函数:样条函数是一种灵活的曲线拟合方法,适用于数据集呈现出复杂的曲线形状。
它通过在数据集中插入节点来逼近拟合曲线。
选择合适的函数模型后,我们需要使用数值优化方法来估计模型的参数。
最常用的方法之一是最小二乘法,它通过最小化观测值和拟合值之间的差异来确定最佳拟合曲线。
一旦拟合曲线的参数确定,我们可以使用这个曲线模型来预测和分析其他数据。
最后,我们需要评估拟合结果的质量。
可以使用统计指标如均方根误差(RMSE)或确定系数(R²)来衡量拟合曲线对原始数据的拟合程度。
总结起来,曲线拟合是一种重要的数学处理方法,用于找到最佳拟合曲线来描述三元函数数据集的关系。
它可以帮助我们理解和预测变量之间的关联性,并为进一步的分析和预测提供基础。
选择合适的函数模型、使用数值优化方法进行参数估计以及评估拟合结果的质量是进行曲线拟合的关键步骤。
曲线拟合
数模俱乐部
曲线拟合
现在我们使用上面求得的系数产生 y: y = (0.1032)x - 28.4909 图像为如图:
如何改善这种状况呢?我 们可以尝试拟合更高阶的多项式。让我们使用一个二次多项式看看。
数模俱乐部
曲线拟合
使用下面的步骤来做: >> p = polyfit(sqft,price,2); 这次有三个系数产生。次数设为 2的 polyfit 函数使用下面的形式给我们返 回系数: y = p1x + p2x + p3 我们把它们提取出来放进变量中并绘图: >> a = p(1); >> b = p(2); >> c = p(3); >> x = [1200:10:4000]; >> y = a*x^2+ b*x + c; >> plot(x,y,sqft,price,'o'), xlabel('房子平方英尺数'),ylabel('平均售价'), ... title('欢乐谷的房子平均售价与平方英尺数的关系'), axis([1200 4000 135 450])
数模俱乐部
曲线拟合
图象如图 所示。 虽然 4000 平方英尺的 房子的价格看起来有点 偏离正常,其它的数据 还是基本上一个直线的 周围的,让我们找出这 条最拟合这些数据的直线。 在我们尝试求出 y = mx + b 的过程中, 房子的 SQFT(平方英尺数)充当 x的角色而平均售价充当 y 的角色。使用 polyfit 找出我们需要的系数,我们只需把数据传递给它并告知它我们在求一 次的多项式。
曲线拟合
曲线拟合法

曲线拟合法
曲线拟合法是一种用于根据离散数据拟合出函数模型的方法,可以用来估计未知数据.是统计分析中经常使用的一种数学方法,它可以用来实现从数据中获取信息的目的。
曲线拟合的最常用的方法是最小二乘法,它的主要思想是将最小的均方误差捆绑到拟合的曲线上,使得它可以更好地描述数据曲线。
曲线拟合是一个复杂的过程。
它的目的是将一系列离散点拟合成一个曲线,该曲线可以刻画数据点之间的关系。
它可以帮助研究者更好地理解数据,并对数据进行进一步研究。
首先,研究者需要确定拟合曲线的函数形式,例如多项式,指数或对数函数,接着将参数估计出来,这一步通常使用标准的最小二乘估计方法。
有时候,参数的估计可能会受到多种因素的影响,但对于拟合曲线的准确性来说,参数的估计是非常重要的。
此外,在最小二乘估计方法中,也需要考虑多元变量之间的关系,这要求研究者针对每一种可能的关系预估参数。
另外,有许多类型的拟合方法,不同的拟合方法适用于不同的数据集,比如,动态拟合法、矩阵法和多元拟合法,这些方法可以帮助研究者在拟合表达式中找到更准确的参数值。
总的来说,曲线拟合法是一种有效的数据模型,它可以根据离散数据拟合出函数模型,这有助于研究者更全面地理解数据,并能够预测出未知点的值,有效地估计出参数。
它在统计学中有着广泛的应用,这种方法对于提高数据分析的精度,预测未知变量,并更加准确地描
述数据曲线都有着重要意义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
32
30
28
26
24
22
20
18 16
18
20
22
24
26
28
30
数据拟合函数表
cfit
fit
产生拟合的目标
用库模型、自定义模型、平滑样条或 内插方法来拟合数据 产生或修改拟合选项 产生目标的拟合形式 显示一些信息,包括库模型、三次样 条和内插方法等。 显示曲线拟合工具的信息 返回拟合曲线的属性 对于拟合曲线显示属性值
•输出结果为: •p = • Columns 1 through 5 • 0.0193 -0.0110 -0.0430 0.0073 0.2449 • Column 6 • 0.2961 •说明拟合的多项式为:
0.0193x 5 0.0110x 4 0.043x 3 0.0073x 2 0.2449x 0.2961
• 算例: >> years=1950:10:1990; >> service=10:10:30; >> wage = [150.697 199.592 187.625 179.323 195.072 250.287 203.212 179.092 322.767 226.505 153.706 426.730 249.633 120.281 598.243]; >> w = interp2(service,years,wage,15,1975) w= 190.6288
Method:用于指定插值的方法,linear:线性插值(默认方 法)。Cubic三次多项插值。Spline:三次样条插值。Nearst: 最近邻插值。
• 例
>> year=1900:10:2010; >> product=[75.995,91.972,105.711,123.203,131.669,... 150.697,179.323,203.212,226.505,249.633,256.344,267.893]; >> p1995 = interp1(year,product,1995) p1995 = 252.9885 >> x = 1900:10:2010; >> y = interp1(year,product,x,'cubic'); >> plot(year,product,'o',x,y)
• 最简单的插值方法是先根据基准数据,调用 MATLAB的绘图命令获得数据的图形表现,然 后估计所需点处的值。
6.8.1分段插值
• 算法分析:所谓分段插值就是通过插值点用折 线或低次曲线连接起来逼近原曲线。 • MATLAB实现 可调用内部函数。
– 命令1 interp1 格式1 yi = interp1(x,y,xi,’method’) 功能 :输入参数为原始数据点(x,y),xi为指定插 值点的横坐标,yi是在xi指定位置计算出的插值结果。
对于拟合结果求积分
对于新的观察量计算预测区间的边界
返回数据的描述统计量
估计一个拟合结果结果或拟合类型
画出数据点、拟合线、预测区间、异 常值点和残差
6.8 插值和样条(非参数拟合)
有时我们对拟合参数的提取或解释不感兴趣,只想得到一个平滑的 通过各数据点的曲线,这种拟合曲线的形式称之为非参数拟合。 • 非参数拟合的方法包括 • (1)插值法Interpolants • (2)平滑样条内插法Smoothing spline • 在多项式曲线拟合并不要求拟合曲线通过这些测量数据点。 而插值是在原始数据点之间按照一定的关系插入新的数据点,以 便更准确的分析数据的变化规律。他是在假定所给的基准数据完 全正确的情况下,研究如何“平滑”的估算出“基准数据”之间 其它函数值。
– 命令2 interp2
• 功能 二维数据内插值(表格查找) :是对两个变量的函数 z=f(x,y)进行插值。 • 格式 ZI = interp2(x,y,z,xi,yi,’method’) • 功能:输入参数为原始数据点(x,y,z);x,y为两个独 立向量,z为矩阵,是由x,y确定的点上的值。 • Z(i,:)=f(x,y(i))和Z(:,i)=f(x(i),y) • method计算二维插值: ’linear’:双线性插值算法(缺省算法); ’nearest’:最临近插值; ’spline’:三次样条插值; ’cubic’:双三次插值。
• • • • • • • • • •
>> y=polyval(a,T) %计算多项式在某一点处的值 y= 1.0e+003 * 0.7718 0.8132 0.8754 0.9502 1.0274 >> plot(T,R,'k+',T,y,'r*') >> hold on >> plot(T,y,'b') >> polyval(a,60) ans = 906.0212
x=[1 3 4 5 6 7 8 9 10]; y=[10 5 4 2 1 1 2 3 4]; [p,s]=polyfit(x,y,4); y1=polyval(p,x); plot(x,y,'go',x,y1,'b--')
10 9 8 7 6 5 4 3 2 1
1
2
3
4
5
6
7
8
9
10
>> poly2str(p,'t') ans = -0.0049945 t^4 + 0.11461 t^3 0.61143 t^2 - 1.1005 t + 11.5499
s=
R: [6x6 double] df: 0 normr: 2.3684e-016 mu = 0.1669 0.1499
自由度为 0 标准偏差为 2.3684e-016
例:根据表中数据进行4阶多项式拟合
X 1 3 4 4 5 2 6 1 7 1 8 2 9 3 10 4 F(x) 10 5
>> >> >> >> >>
1050
1000
950
900
850
800
750 20
30
40
50
60
70
80
90
100
• 例:已知年龄和运动能力的一组数据,试确定 二者的关系(根据图形指定次数)
• 年龄 17 19 21 23 25 27 29 • 第一人20.48 25.13 26.15 30.0 26.1 20.3 19.35 • 第二人24.35 28.11 26.3 31.4 26.92 25.7 21.3
fitoptions fittype cflibhelp
disp
get set
数据拟合函数表
excludedata
smooth confint differentiate
指定不参与拟合的数据
平滑响应数据
计算拟合系数估计值的置信区间边界
对于拟合结果求微分
integrate
predint datastates feval plot
•[p,s,mu]=polyfit(x,y,n) •返回多项式的系数,mu是一个二维向量 [u1,u2],u1=mean(x),u2=std(x),对数据进行预处理 x=(x-u1)/u2 例: x=1:20; y=sqrt(x)+sin(x); p=polyfit(x,y,5) [p,S]=polyfit(x,y,5) Plot(x,y,’o’,x,polyval(p,x),’-’)
• 例:已知的数据点来自函数
根据生成的数据进行插值处理,得出较平滑的曲线 直接生成数据。 >> x=0:.12:1; >> y=(x.^2-3*x+5).*exp(-5*x).*sin(x); >> plot(x,y,x,y,'o')
>> temp=[300,400,500,600]'; >> beta=1000*[3.33,2.50,2.00,1.67]'; >> alpha=10000*[0.2128,0.3605,0.5324,0.7190]'; >> ti=[321,400,571]'; >> propty=interp1(temp,[beta,alpha],ti); %propty=interp1(temp,*beta,alpha+,ti ,’linear’); >> [ti,propty] 例 对于temp,beta 、 ans = alpha分别有两组数据与 1.0e+003 * 之对应,用分段线性插值 0.3210 3.1557 2.4382 法计算当t=321, 440, 571 0.4000 2.5000 3.6050 时beta 、alpha的值。 0.5710 1.7657 6.6489
• • • •
[y,delta]=polyval(p,x,s) 产生置信区间y±delta。如果误差结果服从 标准正态分布,则实测数据落在y±delta区 间内的概率至少为50%。
• • • •
例 >> x=[0 0.0385 0.0963 0.1925 0.2888 0.385]; >> y=[0.042 0.104 0.186 0.338 0.479 0.612]; >> [p,s,mu]=polyfit(x,y,5)
y 0.2015x3 1.4385x2 2.7477x 5.4370
(2)Polyval函数
• • • • • 利用该函数进行多项式曲线拟合评价 y=polyval(p,x) 返回n阶多项式在x处的值,x可以是一个矩 阵或者是一个向量,向量p是n+1个以降序 排列的多项式的系数。