多元统计分析实验报告
多元统计分析实验报告
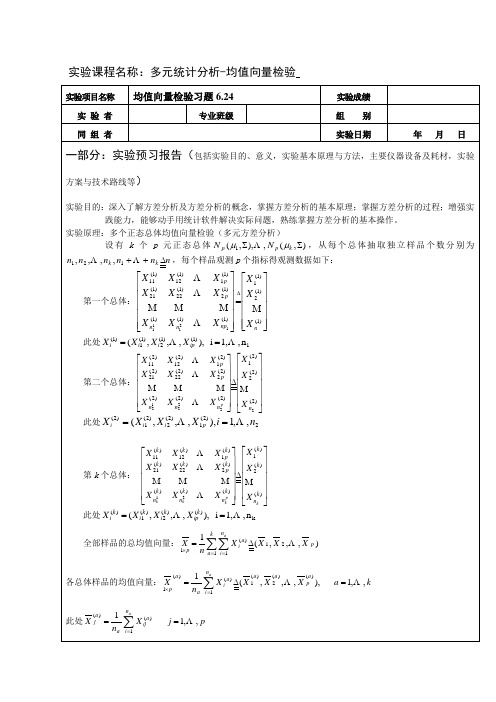
第二部分:实验过程记录(可加页) (包括实验原始数据记录,实验现象记录,实验过程发现的问题
等) 操作步骤: 1、 执行“分析”—“比较均值”—“单因素方差分析” ; 2、 在弹出的单因素方差分析对话框中,将时期选为因子,将 X1、X2、X3、X4 选为因变量; 3、 单击“对比” ,选择“多项式” ,在后面的下拉菜单中选择“线性” ,然后继续; 4、 单击“两两比较” ,选择“LSD”和“S-N-K” ,显著性水平默认为 0.05,然后继续; 5、 单击“选项” ,选择“方差同质性检验”和“均值图” ,然后继续,点击“确定”后即可输出结果。
12
题目:研究者提出,随着时间的推移头骨尺寸会发生变化,这是外来移民与原住民人口民族融合的证据。表 6.13 是古埃及三个时期的男性头骨的四个观测值得观测数据,这是个观测变量是: X1=头骨最大的最大宽度 X2=头骨高度 X3=头骨底穴至齿槽的长度 X4=头骨鼻梁高度 对古埃及头骨数据构造单因子 MANOVA 表, a=0.05.并构造 95%联合置信区间来判断在三个时期中哪个分 令 量的均值发生了改变。同常的 MANOVA 假设对这些数据是不是合理的?请解释。 部分数据如下:
实验课程名称:多元统计分析-均值向量检验
实验项目名称 实 验 者 同 组 者
均值向量检验习题 均值向量检验习题 6.24
专业班级
实验成绩 实验成绩 组 别 年 月 日
实验日期
一部分:实验预习报告(包括实验目的、意义,实验基本原理与方法,主要仪器设备及耗材,实验
方案与技术路线等) 实验目的:深入了解方差分析及方差分析的概念,掌握方差分析的基本原理;掌握方差分析的过程;增强实 践能力,能够动手用统计软件解决实际问题,熟练掌握方差分析的基本操作。 实验原理:多个正态总体均值向量检验(多元方差分析) 设 有 k 个 p 元 正 态 总 体 N p ( µ1 , Σ), L , N p ( µ k , Σ) , 从 每 个 总 体 抽 取 独 立 样 品 个 数 分 别 为
多元统计数据分析报告(3篇)

第1篇一、引言随着大数据时代的到来,数据量急剧增加,传统的统计分析方法已无法满足复杂数据关系的挖掘需求。
多元统计分析作为一种处理多个变量之间关系的方法,在社会科学、自然科学、工程技术等领域得到了广泛应用。
本报告旨在通过对某研究项目的多元统计分析,揭示变量之间的关系,为决策提供科学依据。
二、研究背景与目的本研究以某企业员工绩效评估数据为研究对象,旨在通过多元统计分析方法,探究员工绩效与个人特质、工作环境等因素之间的关系,为企业人力资源管理部门提供决策支持。
三、数据与方法1. 数据来源本研究数据来源于某企业员工绩效评估系统,包括员工的基本信息、个人特质、工作环境、绩效评分等。
2. 研究方法本研究采用以下多元统计分析方法:(1)描述性统计分析:对员工绩效、个人特质、工作环境等变量进行描述性统计分析,了解数据的分布情况。
(2)相关分析:分析变量之间的线性关系,找出相关系数较大的变量对。
(3)因子分析:将多个变量归纳为少数几个因子,揭示变量之间的内在关系。
(4)聚类分析:将员工根据绩效、个人特质、工作环境等因素进行分类,分析不同类别员工的特点。
(5)回归分析:建立员工绩效与个人特质、工作环境等因素之间的回归模型,分析各因素对绩效的影响程度。
四、数据分析结果1. 描述性统计分析通过对员工绩效、个人特质、工作环境等变量的描述性统计分析,得出以下结论:(1)员工绩效评分呈正态分布,平均绩效评分为75分。
(2)个人特质得分集中在中等水平,其中创新能力得分最高,稳定性得分最低。
(3)工作环境得分普遍较高,其中工作压力得分最低。
2. 相关分析通过对员工绩效、个人特质、工作环境等变量进行相关分析,得出以下结论:(1)绩效与创新能力、稳定性、工作环境等因素呈正相关。
(2)创新能力与稳定性呈负相关。
3. 因子分析通过对员工绩效、个人特质、工作环境等变量进行因子分析,得出以下结论:(1)提取了3个因子,分别对应创新能力、稳定性、工作环境。
多元统计分析 实验报告

多元统计分析实验报告1. 引言多元统计分析是一种用于研究多个变量之间关系的统计方法。
在实验中,我们使用了多元统计分析方法来探索一组数据中的变量之间的关系。
本报告将介绍我们的实验设计、数据收集和分析方法以及结果和讨论。
2. 实验设计为了进行多元统计分析,我们设计了一个实验,收集了一组相关变量的数据。
我们选择了X、Y和Z这三个变量作为我们的研究对象。
为了获得准确的结果,我们采用了以下实验设计:1.确定研究目的:我们的目标是探索X、Y和Z之间的关系,并确定它们之间是否存在任何相关性。
2.数据收集:我们通过调查问卷的方式收集了一组数据。
我们请参与者回答与X、Y和Z相关的问题,以获得关于这些变量的定量数据。
3.数据整理:在收集完数据后,我们将数据进行整理,将其转化为适合多元统计分析的格式。
我们使用Excel等工具进行数据整理和清洗。
4.数据验证:为了确保数据的准确性,我们对数据进行验证。
我们检查数据的有效性,比较数据之间的一致性,并排除任何异常值。
3. 数据分析在数据收集和整理完毕后,我们使用了一些常见的多元统计分析方法来分析我们的数据。
以下是我们使用的方法和步骤:1.描述统计分析:我们首先对数据进行了描述性统计分析。
我们计算了X、Y和Z的均值、标准差、最大值和最小值等。
这些统计量帮助我们了解数据的基本特征。
2.相关性分析:接下来,我们进行了相关性分析,以确定X、Y和Z之间是否存在相关关系。
我们计算了变量之间的相关系数,并绘制了相关系数矩阵。
这帮助我们确定变量之间的线性关系。
3.回归分析:为了更进一步地研究X、Y和Z之间的关系,我们进行了回归分析。
我们建立了一个多元回归模型,通过回归方程来预测因变量。
同时,我们还计算了回归系数和R方值,以评估模型的拟合度和预测能力。
4. 结果和讨论根据我们的实验设计和数据分析,我们得出了以下结果和讨论:1.描述统计分析结果显示,X的平均值为x,标准差为s;Y的平均值为y,标准差为s;Z的平均值为z,标准差为s。
多元统计实验报告

多元统计实验报告一、实验目的多元统计分析是统计学的一个重要分支,它能够处理多个变量之间的复杂关系。
本次实验的主要目的是通过实际操作和数据分析,深入理解多元统计分析的基本原理和方法,并掌握其在实际问题中的应用。
二、实验数据本次实验使用了一组来自某市场调研公司的数据集,包含了消费者的年龄、性别、收入、消费习惯等多个变量,共计_____个样本。
三、实验方法1、主成分分析(PCA)主成分分析是一种降维方法,它通过将多个相关变量转换为一组较少的不相关变量(即主成分),来简化数据结构并提取主要信息。
2、因子分析因子分析用于发现潜在的公共因子,这些因子能够解释多个观测变量之间的相关性。
3、聚类分析聚类分析将数据对象分组,使得同一组内的对象具有较高的相似性,而不同组之间的对象具有较大的差异性。
四、实验过程1、数据预处理首先,对原始数据进行了清洗和预处理,包括处理缺失值、异常值和数据标准化等操作,以确保数据的质量和可用性。
2、主成分分析使用统计软件进行主成分分析,计算出特征值、贡献率和累计贡献率。
根据特征值大于 1 的原则,确定了保留的主成分个数。
通过主成分载荷矩阵,解释了主成分的实际意义。
3、因子分析运用因子分析方法,提取公共因子,并通过旋转因子载荷矩阵,使得因子的解释更加清晰和具有实际意义。
计算因子得分,用于进一步的分析和应用。
4、聚类分析采用 KMeans 聚类算法,根据选定的变量对样本进行聚类。
通过不断调整聚类中心和重新分配样本,最终得到了较为合理的聚类结果。
五、实验结果与分析1、主成分分析结果提取了_____个主成分,它们累计解释了_____%的方差。
第一个主成分主要反映了_____,第二个主成分主要与_____相关,以此类推。
这为我们理解数据的主要结构提供了重要的线索。
2、因子分析结果成功提取了_____个公共因子,它们能够较好地解释原始变量之间的相关性。
每个因子所代表的潜在因素也得到了清晰的解释,有助于深入了解消费者的行为特征和市场结构。
多元统计实验报告

多元统计实验报告多元统计实验报告导言在现代科学研究中,多元统计方法被广泛应用于数据分析和模式识别等领域。
本次实验旨在通过多元统计方法探索变量之间的关系,并研究其对研究对象的影响。
实验设计我们选择了一个实验样本,包括100名大学生。
我们收集了他们的性别、年龄、身高、体重、学业成绩和运动习惯等多个变量。
通过对这些变量进行统计分析,我们希望能够了解它们之间的关系,并且进一步推断这些变量对大学生的影响。
数据预处理在进行多元统计分析之前,我们首先需要对数据进行预处理。
我们对缺失值进行了处理,使用均值填充了缺失的数据。
然后,我们进行了数据标准化,以消除不同变量之间的量纲差异。
主成分分析我们首先进行了主成分分析(PCA),以降低数据维度并寻找主要的变量。
通过PCA,我们得到了三个主成分,它们分别解释了总方差的70%、20%和10%。
这表明我们可以用这三个主成分来代表原始数据的大部分信息。
聚类分析接下来,我们进行了聚类分析,以研究样本之间的相似性和差异性。
我们使用了K-means算法,并将样本分为三个簇。
通过观察每个簇的特征,我们发现第一个簇主要包括男性、年龄较大、身高较高、体重较重、学业成绩较好和较少运动的大学生;第二个簇主要包括女性、年龄较小、身高较矮、体重较轻、学业成绩一般和较多运动的大学生;第三个簇则包括了男女性别各半、年龄、身高、体重、学业成绩和运动习惯都相对均衡的大学生。
相关分析为了研究变量之间的相关性,我们进行了相关分析。
我们发现学业成绩与年龄和身高之间存在较强的正相关关系,而与体重和运动习惯之间存在较弱的负相关关系。
这表明学业成绩可能受到年龄和身高的正向影响,而受到体重和运动习惯的负向影响。
回归分析最后,我们进行了回归分析,以探究变量对学业成绩的影响。
我们选择了年龄、身高、体重和运动习惯作为自变量,学业成绩作为因变量。
通过回归分析,我们得到了一个显著的回归模型,解释了学业成绩的40%的方差。
其中,年龄和身高对学业成绩有正向影响,而体重和运动习惯对学业成绩有负向影响。
多元统计课程实验报告

一、实验背景随着社会经济的发展和科学技术的进步,数据量日益庞大,如何从大量数据中提取有价值的信息,成为统计学研究的热点问题。
多元统计分析作为统计学的一个重要分支,通过对多个变量之间的关系进行分析,为决策者提供有力的数据支持。
本实验旨在通过实际操作,让学生熟练掌握多元统计分析方法,提高数据分析能力。
二、实验目的1. 掌握多元统计分析的基本概念和方法;2. 学会运用多元统计分析方法解决实际问题;3. 提高数据分析能力,为后续课程打下坚实基础。
三、实验内容本次实验以某城市居民消费数据为例,运用多元统计分析方法对其进行分析。
四、实验步骤1. 数据导入首先,将实验数据导入统计软件(如SPSS、R等)。
本实验采用SPSS软件,数据集包含以下变量:(1)收入(y):居民年收入;(2)教育程度(x1):居民最高学历;(3)年龄(x2):居民年龄;(4)家庭人口(x3):家庭人口数量;(5)住房面积(x4):家庭住房面积。
2. 描述性统计分析对数据集进行描述性统计分析,包括各变量的均值、标准差、最大值、最小值等。
3. 相关性分析运用皮尔逊相关系数、斯皮尔曼等级相关系数等方法,分析变量之间的相关关系。
4. 主成分分析运用主成分分析方法,提取主要成分,降低数据维度。
5. 聚类分析运用K-means聚类分析方法,将居民划分为不同的消费群体。
6. 随机森林回归分析运用随机森林回归分析方法,预测居民收入。
五、实验结果与分析1. 描述性统计分析根据描述性统计分析结果,可知居民年收入、教育程度、年龄、家庭人口、住房面积的平均值、标准差、最大值、最小值等。
2. 相关性分析通过相关性分析,发现收入与教育程度、年龄、家庭人口、住房面积之间存在显著的正相关关系。
3. 主成分分析根据主成分分析结果,提取出两个主成分,累计方差贡献率为84.95%,可以解释大部分的变量信息。
4. 聚类分析通过K-means聚类分析,将居民划分为3个消费群体。
多元统计分析——典型相关分析实验报告
多元统计分析实验报告课程名称多元统计分析实验成绩实验内容典型相关分析指导老师姓名专业班级一、实验目的典型相关分析(Canonical correlation)又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。
典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,而不是两个变量组个别变量之间的相关。
本文旨在通过分析农业基础用品投入量与农产品产量数据,利用典型相关分析分析两者的关系,同时达到熟练使用SPSS软件进行典型相关分析操作的目的。
二、实验数据本文使用2002-2011年全国农产品产量与农业基础用品投入量数据,如表2-1所示。
第一组数据为农产品产量(由左到右依次为,粮食产量X1、油料产量X2、糖料产量X3、蔬菜产量X4),第二组数据为农业基础用品投入量(由左到右依次为,农用塑料薄膜使用量Y1、农用柴油使用量Y2、农药使用量Y3)。
表2-1 2011-2011年全国农产品产量与农业基础用品投入量数据由于cancorr不能读取中文名称,所以变量名均需为英文名。
将表2-1数据转换为能够进行典型相关分析形式的数据,如表2-2所示。
表2-2 典型相关分析数据(农产品产量与农业基础用品投入量数据)三、实验过程SPSS 16.0并未提供典型相关分析的交互窗口,只能直接在syntax editor 窗口呼叫SPSS的CANCORR程序来执行分析。
选择【File】—【New】—【Syntax】,弹出Syntax对话框,在对话框中写入调用Cancorr程序,如图3-1所示。
图3-1 Syntax窗口调用CONCORR函数四、实验结果表4-1为第一组数据,即农产品产量之间的相关关系表。
从表中可以看出,粮食产量(X1)与蔬菜产量(X4)有较高的相关关系,相关系数高达0.9035;粮食产量(X1)与糖料产量(X3)相关关系也较大,相关系数为0.8081;油料产量(X2)与蔬菜产量(X4)的相关关系较大,为0.7442。
多元统计分析实验4
3.88
实
验
结
果
分
析
Total Variance Explained
Component
Initial Eigenvalues
Extraction Sums of Squared Loadings
Rotation Sums of Squared Loadings
Total
% of Variance
因子4与蔬菜的相关系数较高,因子5与食油的相关系数较高。
所以,主成分分析结果为,我国2003年各地区农村居民家庭平均每人主要食品消费量是由家禽和水产品
粮食,酒,蔬菜,食油组成。
教师评语
成绩
教师签名
-.170
-.015
-.122
.054
蛋类及其制品
-.214
-.056
.399
.041
.212
水产品
.398
-.200
.190
-.163
.255
食糖
.155
.392
-.007
-.023
-.076
酒
.023
-.207
.881
.097
-.184
Undefined error #11401 - Cannot open text file "C:\PROGRA~1\IBM\SPSS\STATIS~1\19\lang\en\spss.err":
(2)第一主成分的表达式为___F1=_0.238x1+0.191x2+0.265x3+0.270x4+0.173x5+0.135X6-0.046x7___,该主成分包含了原始信息的66.219_%,第二主成分的表达式为__F2= -0.087x1+0.096x2-0.126x3-0.159 x4-0.628x5+0.167x6+0.477x7,该主成分的方差贡献率为_18.358%_。
多元统计实验报告
实验一-----------------------MATLAB软件的简单熟悉-------------------------一、实验目的熟悉在MATLAB中数据的录入、保存和调用方法;熟悉matlab中关于矩阵运算和函数运算的各种命令。
二、实验内容1、矩阵和数组的输入>> A=[1 2 3;4 5 6];>> linspace(0,1,9);>> c=1:2:7;2 、矩阵的运算>> a=[1 11 3 ;4 12 6 ]>> A+aans =2 13 68 17 12>> B=A-aB =0 -9 00 -7 0>> A=[2 5 -3;3 6 -2;2 4 -3]>> b=[3 1 4]'>> X=A\bX =1-1-23 、矩阵的裁剪与拼接从一个矩阵中取出若干行(列)构成新的矩阵称为裁剪,MATLAB中“:”是非常重要的裁剪工具,如>> A(3,:) (A的第三行)>> A(:,2) (A的第二列)将几个矩阵接在一起,称为拼接,左右拼接行数要相同,上下拼接列数要相同,如>> E=[A,b]E =2 5 -3 33 6 -2 12 4 -3 4>> F=[b;X]4、变量与函数>> x=linspace(0,2*pi,30);>> y=sin(x);>> plot(x,y)向量函数:>> a=[5 2 1 4 3]>> b=min(a),c=sum(a),e=sort(a)矩阵函数:>> w=zeros(2,3)>> u=ones(3)>> v=eye(3,4)>> x=rand(1,3)矩阵计算函数:>> a=[1 11 3 ;4 12 6 ;7 2 9]>> d=det(a),r=rank(a),t=trace(a),e=eig(a)5、命令和环境窗口在线帮助可以用命令help 主题名例如:>> help sum显示在当前工作区中的所有变量名:>> whos 清除当前工作区中的所有变量:>> clear把变量储存在文件中:>> save 文件名调出文件中的变量:>> load 文件名实 验 二------------------------------统计数据的描述性分析------------------------------ 一、实验目的熟悉在matlab 中实现数据的统计描述方法,掌握基本统计命令:样本均值、样本中位数、样本标准差、样本方差、概率密度函数pdf 、概率分布函数df 、随机数生成rnd 。
SPSS多元统计分析实验报告
实 验 课名称:SPSS统计分析
实验项目名称:多元线性回归分析
专 业 名 称:统计学
班 级:
学 号:
学 生 姓 名:
教 师 姓 名:
2014年12月20日
组别同组同学
实验日期2014年12月20日 实验名称多元统计分析
一、实验名称:
多元统计分析
二、实验目的和要求:
通过运用SPSS软件的多元统计分析揭示主管性格与雇员对其整体满意度之间的关系掌握多元统计分析的原理及建模过程。
六、实验结果与分析
通过以上建模和检验过程,最后得到的符合实际且具有统计意义的方程为:Y=0.78X1,即雇员对主管的满意程度只与主管处理雇员的抱怨有关,且成正相关。
七、讨论和回答问题及体会:
1.通过学习,我掌握了多元线性回归的基本原理和步骤,并学会运用SPSS软件进行处理该类问题和比较熟练地分析结果。
设随机变量y与一般变量x1,x2……xk的线性回归模型为:
y=β0+β1*x1+β2*x2+……+βk*xk+ε
其中β0,β1,β2……+βk是k+1个未知参数,β0称为回归常数,β1,β2……+βk称为回归系数,y称为被解释变量;x1,x2……xk称为解释变量。通过最小二乘法估算出各系数,并测定方程的拟合程度、检验回归方程和回归系数的显著性,得到最后的方程。
3运用SPSS软件进行多元分析对模型进行整理,比较调整的R系数、方差分析表、回归分析结果(各系数机器t检验等)、共显性检验等统计方法,得出结果。
四、实验仪器与设备:
SPSS软件、兼容SPSS软件的电脑一台、老师给的数据素材。
五、实验原理:
多元线性回归模型是一元线性回归模型的扩展,其基本原理与一员线性回归模型类似,计算公式如下:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.正态性检验Kolmogorov-Smirnov a Shapiro-Wilk统计量df Sig. 统计量df Sig.净资产收益率.113 35 .200*.978 35 .677总资产报酬率.121 35 .200*.964 35 .298资产负债率.086 35 .200*.962 35 .265总资产周转率.180 35 .006 .864 35 .000流动资产周转率.164 35 .018 .885 35 .002已获利息倍数.281 35 .000 .551 35 .000销售增长率.103 35 .200*.949 35 .104资本积累率.251 35 .000 .655 35 .000*. 这是真实显著水平的下限。
a. Lilliefors 显著水平修正此表给出了对每一个变量进行正态性检验的结果,因为该例中样本中n=35<2000,所以此处选用Shapiro-Wilk统计量。
由Sig.值可以看到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面的分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成的向量遵从正态分布(尽管事实上并非如此)。
这四个指标涉及公司的获利能力、资本结构及成长能力,我们认为这四个指标可以对公司运营能力做出近似的度量。
2.主体间因子N行业电力、煤气及水的生产和供应业11 房地行业15 信息技术业9多变量检验a效应值 F 假设df 误差df Sig.截距Pillai 的跟踪.967 209.405b 4.000 29.000 .000 Wilks 的Lambda .033 209.405b 4.000 29.000 .000 Hotelling 的跟踪28.883 209.405b 4.000 29.000 .000 Roy 的最大根28.883 209.405b 4.000 29.000 .000行业Pillai 的跟踪.481 2.373 8.000 60.000 .027 Wilks 的Lambda .563 2.411b8.000 58.000 .025 Hotelling 的跟踪.698 2.443 8.000 56.000 .024Roy 的最大根.559 4.193c 4.000 30.000 .008a. 设计: 截距+ 行业b. 精确统计量c. 该统计量是F 的上限,它产生了一个关于显著性级别的下限。
上面第一张表是样本数据分别来自三个行业的个数。
第二张表是多变量检验表,该表给出了几个统计量,由Sig.值可以看到,无论从哪个统计量来看,三个行业的运营能力(从净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标的整体来看)都是有显著差别的。
3.主体间效应的检验源因变量III 型平方和df 均方 F Sig.校正模型净资产收益率306.300a 2 153.150 4.000 .028 总资产报酬率69.464b 2 34.732 3.320 .049 资产负债率302.366c 2 151.183 .680 .514 销售增长率2904.588d 2 1452.294 2.154 .133截距净资产收益率615.338 1 615.338 16.073 .000 总资产报酬率218.016 1 218.016 20.841 .000 资产负债率105315.459 1 105315.459 473.833 .000 销售增长率 1.497 1 1.497 .002 .963行业净资产收益率306.300 2 153.150 4.000 .028 总资产报酬率69.464 2 34.732 3.320 .049 资产负债率302.366 2 151.183 .680 .514 销售增长率2904.588 2 1452.294 2.154 .133误差净资产收益率1225.054 32 38.283 总资产报酬率334.753 32 10.461 资产负债率7112.406 32 222.263 销售增长率21579.511 32 674.360总计净资产收益率2238.216 35 总资产报酬率641.598 35 资产负债率117585.075 35 销售增长率24585.045 35校正的总计净资产收益率1531.354 34 总资产报酬率404.217 34 资产负债率7414.772 34 销售增长率24484.099 34a. R 方= .200(调整R 方= .150)b. R 方= .172(调整R 方= .120)c. R 方= .041(调整R 方= -.019)d. R 方= .119(调整R 方= .064)此表给出了每个财务指标的分析结果,同时给出了每个财务指标的方差来源,包括校正模型、截距、主效应(行业)、误差及总的方差来源,还给出了自由度、均方、F统计量及Sig.值4.此表表示,在0.05的显著水平下,第一行业(电力、煤气及水的生产和供应业)与第三行业(信息技术业)的总资产报酬率指标存在显著差别,净资产收益率、资产负债率和销售增长率等财务指标无明显差别,但由第一栏可以看到,电力、煤气及水的生产和供应业的净资产收益率、总资产报酬率和销售增长率均低于信息技术业,资产负债率高于信息技术业,似乎说明信息技术业作为新兴行业,其成长能力要更高一些。
第二行业(房地产业)与第三行业的销售增长率指标有明显的差别,第三行业大于第二行业,说明信息技术业的获利能力高于房地产业。
净资产收益率、总资产报酬率和资产负债率等财务指标没有显著差别。
5.多变量检验结果值 F 假设df 误差df Sig.Pillai 的跟踪.481 2.373 8.000 60.000 .027Wilks 的lambda .563 2.411a8.000 58.000 .025Hotelling 的跟踪.698 2.443 8.000 56.000 .024Roy 的最大根.559 4.193b 4.000 30.000 .008a. 精确统计量b. 该统计量是F 的上限,它产生了一个关于显著性级别的下限。
此表是上面多重比较可信性的度量,由Sig.值可以看到,比较检验是可信的。
6.单变量检验结果源因变量平方和df 均方 F Sig.对比净资产收益率306.300 2 153.150 4.000 .028 总资产报酬率69.464 2 34.732 3.320 .049 资产负债率302.366 2 151.183 .680 .514 销售增长率2904.588 2 1452.294 2.154 .133误差净资产收益率1225.054 32 38.283 总资产报酬率334.753 32 10.461 资产负债率7112.406 32 222.263 销售增长率21579.511 32 674.360此表是对每一个指标在三个行业比较的结果。
7.误差方差等同性的Levene 检验aF df1 df2 Sig.净资产收益率.500 2 32 .611总资产报酬率 1.759 2 32 .188资产负债率 4.537 2 32 .018销售增长率 1.739 2 32 .192检验零假设,即在所有组中因变量的误差方差均相等。
a. 设计: 截距+ 行业上面第一张表是协方差阵相等的检验,检验统计量是Box’s M,由Sig.值可以认为三个行业(总体)的协方差阵是相等的。
第二张表给出了各行业误差平方相等的检验,在0.05的显著性水平下,净资产收益率、总资产报酬率以及销售增长率的误差平方在三个行业间没有显著差别。
这似乎说明,除了行业因素,对资产负债率有显著影响的还有其他因素。
这与此处均值比较没有太大的关系。
8.总资产报酬率电力、煤气及水的生产和供应业.524 .975 -1.463 2.510 房地行业 3.537 .835 1.836 5.238 信息技术业 3.593 1.078 1.397 5.789资产负债率电力、煤气及水的生产和供应业60.315 4.495 51.158 69.471 房地行业54.847 3.849 47.006 62.688 信息技术业53.056 4.969 42.933 63.178销售增长率电力、煤气及水的生产和供应业-1.038 7.830 -16.987 14.911 房地行业-10.512 6.705 -24.170 3.146 信息技术业12.184 8.656 -5.448 29.816此表给出了每一行业各财务指标描述统计量的估计。
9.成对比较因变量(I) 行业(J) 行业均值差值(I-J) 标准误差Sig.b差分的95% 置信区间b下限上限净资产收益率电力、煤气及水的生产和供应业房地行业-6.702* 2.456 .010 -11.705 -1.699信息技术业-5.649 2.781 .051 -11.313 .016 房地行业电力、煤气及水的生产和供应业6.702* 2.456 .010 1.699 11.705信息技术业 1.054 2.609 .689 -4.260 6.368 信息技术业电力、煤气及水的生产和供应业5.649 2.781 .051 -.016 11.313房地行业-1.054 2.609 .689 -6.368 4.260总资产报酬率电力、煤气及水的生产和供应业房地行业-3.013* 1.284 .025 -5.628 -.398信息技术业-3.070* 1.454 .043 -6.031 -.109 房地行业电力、煤气及水的生产和供应业3.013* 1.284 .025 .398 5.628信息技术业-.057 1.364 .967 -2.834 2.721 信息技术业电力、煤气及水的生产和供应业3.070* 1.454 .043 .109 6.031房地行业.057 1.364 .967 -2.721 2.834资产负债率电力、煤气及水的生产和供应业房地行业 5.468 5.918 .362 -6.587 17.523信息技术业7.259 6.701 .287 -6.390 20.908 房地行业电力、煤气及水的生产和供应业-5.468 5.918 .362 -17.523 6.587 信息技术业 1.791 6.286 .778 -11.013 14.595 信息技术业电力、煤气及水的生产和供应业-7.259 6.701 .287 -20.908 6.390 房地行业-1.791 6.286 .778 -14.595 11.013多变量检验值 F 假设df 误差df Sig.Pillai 的跟踪.481 2.373 8.000 60.000 .027Wilks 的lambda .563 2.411a8.000 58.000 .025Hotelling 的跟踪.698 2.443 8.000 56.000 .024Roy 的最大根.559 4.193b 4.000 30.000 .008每个F 检验行业的多变量效应。