计量经济学案例作业
计量经济学作业

模型的检验 2.统计检验 统计检验 模型回归结果如下
模型的检验 ⑴.拟合优度检验 拟合优度检验 从图中可知 可决系数R 可决系数 2=0.955702>0.9通过检验 通过检验 ⑵.F检验 检验 原假设与备择假设为 H0:β1=0,β2=0,β3=0 , , H1:βj(j=1,2,3)不全为零 , , ) 的条件下F=330.8073(从图知) 在原假设成立 的条件下 (从图知) 给定显著性水平α=0.05 给定显著性水平 Fα(k,n-k-1)=F0.05(3,46)≈2.8<330.8073 , ) , ) 表明模型线性关系在95%的置信水平下显著成立 表明模型线性关系在 的置信水平下显著成立
模型的检验
⑵.参数大小的检验 参数大小的检验
y=232.4143+0.052569x1-5.91*10-5x2+0.348625x3
由于所收集的解释变量数据的数字较大,尤其 由于所收集的解释变量数据的数字较大,尤其x2是的数 字相比其它两个解释变量大很多, 字相比其它两个解释变量大很多,因此三个解释变量的系数 绝对值都小于1是合理的。而功率对车速影响作用最大,所 绝对值都小于 是合理的。而功率对车速影响作用最大, 是合理的 以它的系数最大是合理的。 以它的系数最大是合理的。
模型的检验 ⑵.预测值检验 预测值检验
从图中可知y回归的标准误差为 从图中可知 回归的标准误差为 8.783411
模型的检验
选取2009年一个样本 年一个样本 选取 09款三菱 款三菱-Eclipse跑车,车重 跑车, 款三菱 跑车 车重1505,最大 , 截面面积2491930,最大功率121,最快车 截面面积 ,最大功率 , 速210 将数据代入模型中求得y=208.532425 将数据代入模型中求得 |208.532425-210|=1.467575<8.783411 | 在标准误差以内, 在标准误差以内,通过检验
计量经济学-第五章案例分析

计量经济学期中教学案例分析作业第五章案例分析班级:电子商务15-2 班姓名:郑瑞璇学号:2015213720一、问题的提出与模型的建立根据本章引子提出的问题,为了给制定医疗机构的规划提供依据,分析比较医疗机构与人口数量的关系,建立卫生医疗机构数与人口数的回归模型。
假定医疗机构数与人口数之间满足线性约束,则理论模型设定为Yi= 31+ 化Xi+uiYi表示医疗机构数;Xi表示人口数。
由2001年《四川统计年鉴》得到如表1所示数据。
表1 四川省2000年各地医疗机构数与人口数地区人口数(万人)X医疗机构数(个)Y地区人口数(万人)X医疗机构数(个)Y成都1013.36304眉山339.9827自贡315911宜宾508.51530攀枝花103934广安438.61589泸州463.71297达州620.12403德阳379.31085雅安149.8866绵阳518.41616巴中346.71223广元302.61021资阳488.41361遂宁3711375阿坝82.9536内江419.91212甘孜88.9594乐山345.91132凉山402.41471南充709.24064二、参数估计进入EViews软件包,确定样本范围,编辑输入数据,选择估计方程菜单,得到图一的估计结果。
[=]Equatron: UNTITLED Workfile: UNTITLED::Untitled\ ■巴翁Dependent Variable: YMethod: Least SquaresDate: 12/19/16 Time: 21:39Sample: 1 21 induced observations: 21Variable Coefficient Std. Error t-Statistic ProbC -562.9074 291.5642 -1.930646 0.06B5X5372028 0.644239 8339811 00Q00R-squared 0.78543& Mean dependentvar 1508143Adjusted R-squared 0.774145 S.D. dependent var 1310.975S.E. of regression 5230301 Akaike info criterion 15 79746Sum squared resid 7375164 Schwarz criterion 15.89694Log likelihood -16X8733 Hann自n-Ouinn criter 15.31905F-statistic 69.55245 Durbin-Watson stat 1 947198ProbfF-stati stic) 0000000图一回归结果估计结果Yi = -562.9074 + 5.3728Xit= (-1.9306)(8.3398)2R =0.7854 F=69.55三、检验模型的异方差本例用的是四川省2000年各州市的医疗机构数和人口数,由于各地区人口数不同,对医疗机构设置数量有不同的需求,这种差异使得模型很容易产生异方差,从而影响模型的估计与使用。
计量经济学实际案例

二、均值分析1、分性别对身高进行的比较假设男女身高相等,否定假设可认为男生身高明显高于女生。
2、分南北地区进行比较(1)身高假设两者均值相等,检验结果不能否定原假设,因而不能认为南北方身高有显著差异。
(2)体重通过假设两者均值相等,检验结果无法否定原假设,因而认为南北方体重没有明显差异。
3、分出生年份月份进行比较年份性别身高体重84 男均值172.00 56.00N 1 1总计均值172.00 56.00N 1 185 男均值180.33 70.67N 3 3女均值161.00 51.00N 2 2总计均值172.60 62.80N 5 586 男均值174.20 65.40N 20 20女均值162.11 52.28N 18 18总计均值168.47 59.1887 男均值178.50 66.58N 6 6女均值164.83 52.83N 18 18总计均值168.25 56.27N 24 2488 男均值170.50 65.00N 2 2女均值167.00 53.50N 2 2总计均值168.75 59.25N 4 489 女均值165.00 50.00N 1 1总计均值165.00 50.00N 1 1总计男均值175.28 65.80N 32 32女均值163.56 52.46N 41 41总计均值168.70 58.31N 73 73ANOVA 表由表可看出,各年份出生的人身高体重无显著性差异。
总计均值171.00 64.00N 6 6 3 男均值174.50 69.50N 4 4 女均值160.25 50.75N 4 4 总计均值167.38 60.13N 8 8 4 男均值181.25 68.50N 4 4 女均值162.25 52.00N 4 4 总计均值171.75 60.25N 8 8 5 男均值169.50 65.25N 2 2 女均值156.00 43.00N 1 1 总计均值165.00 57.83N 3 3 6 男均值175.00 63.00N 1 1 女均值171.50 57.50N 4 4 总计均值172.20 58.60N 5 5 7 男均值171.00 64.33N 3 3 女均值167.00 50.50N 2 2 总计均值169.40 58.80N 5 5 8 男均值179.20 64.90N 5 5 女均值161.50 52.50N 2 2 总计均值174.14 61.36N 7 7 9 男均值171.67 58.00N 3 3 女均值163.33 54.33N 3 3 总计均值167.50 56.1710 男均值174.67 61.83N 3 3总计均值174.67 61.83N 3 311 女均值162.50 51.67N 12 12总计均值162.50 51.67N 12 1212 男均值171.00 66.50N 2 2女均值167.00 57.00N 1 1总计均值169.67 63.33N 3 3总计男均值175.28 65.80N 32 32女均值163.56 52.46N 41 41总计均值168.70 58.31N 73 73ANOVA 表由表同样可得出,各月出生的人身高体重无显著性差异。
计量经济学实证练习作业.docx
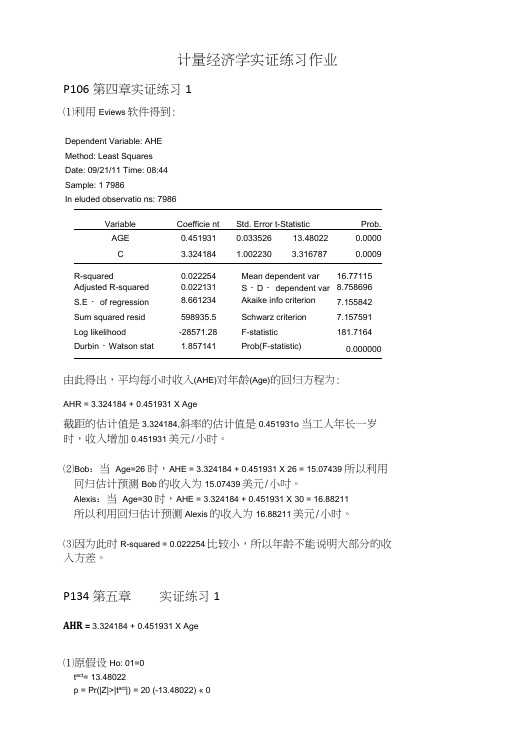
计量经济学实证练习作业P106第四章实证练习1⑴利用Eviews软件得到:Dependent Variable: AHEMethod: Least SquaresDate: 09/21/11 Time: 08:44Sample: 1 7986In eluded observatio ns: 7986Variable Coefficie nt Std. Error t-Statistic Prob.AGE 0.451931 0.033526 13.48022 0.0000C 3.324184 1.002230 3.316787 0.0009R-squared 0.022254 Mean dependent var 16.77115 Adjusted R-squared 0.022131 S・D・ dependent var 8.758696 S.E・ of regression 8.661234 Akaike info criterion 7.155842 Sum squared resid 598935.5 Schwarz criterion 7.157591 Log likelihood -28571.28 F-statistic 181.7164 Durbin・Watson stat 1.857141 Prob(F-statistic) 0.000000由此得出,平均每小时收入(AHE)对年龄(Age)的回归方程为:AHR = 3.324184 + 0.451931 X Age截距的估计值是3.324184,斜率的估计值是0.451931o 当工人年长一岁时,收入增加0.451931美元/小时。
⑵Bob:当Age=26 时,AHE = 3.324184 + 0.451931 X 26 = 15.07439 所以利用冋归估计预测Bob的收入为15.07439美元/小吋。
Alexis:当Age=30 时,AHE = 3.324184 + 0.451931 X 30 = 16.88211所以利用回归估计预测Alexis的收入为16.88211美元/小时。
计量经济学案例分析作业.doc

计量案例分析学院:国际贸易学院班级:贸易经济2班姓名:___________学号:_______2013年12月16日□ Equati on: UNTITLED Workfile: UNTITLED::Untitled、View | Proc | Object | Print〔Name〔Freeze] Estimate | Forecast | Stats | Resids |Dependent Variable: YMethod: Least SquaresDate: 12/21/13 Time: 19:06Sample: 1994 2007Included observations: 14VariableCoefficientStd.Errort-Statistic Prob.C•1471.9561137.046-1.294544 0.2316X2 0.042510.0046139.216082 0.0000X3 4.4324781.0633414.168445 0.0031X4 2.9222731.0936652.6720010.0283X5 1.4267861.4175551.006512 0.3436X6 -354.9821244.8486-1.449802 0.1852R-squared0.997311Mean dependent var3527.783Adjusted R-squared 0.995630 S.D. dependent var 1927.495S.E. of regression 127.4135 Akaike info criterion 12.83028Sum squared resid 129873.5 Schwarz criterion 13.10416Log likelihood -83.81195 Hannan-Quinn criter. 12.80493F-statistic 593.4168 Durbin-Watson stat 1.558415Prob(F-statistic) 0.0000019941997年中国旅游收入及相关数据¥=-1471.96+0.0425X2+4.432X3+2.922X4+1.427X5-354.98X6R2 =0.997 -R=0.996经济意义:说明假定其他变量不变的情况下,各每增加1万人次的国内旅游人数、1元的城镇居民人均旅游花费、1元的农村居民人均旅游花费、1万公里的公路里程和1万公里的铁路里程,国内旅游收入就会相应的增加0. 0425亿元、4. 432亿元、2.922亿元、1.427亿元和减少354. 98亿元。
计量经济学建模案例

计量经济学建模案例计量经济学是一种运用数学和统计方法对经济现象进行定量分析的方法,可以帮助经济学家解释和预测经济现象,并制定相应的政策。
下面是一种计量经济学建模案例:假设我们要研究某个城市的房价与房屋面积之间的关系。
我们可以使用多元线性回归模型来建模,其中自变量是房屋面积,因变量是房价。
为了使模型更加准确,我们还可以引入其他可能影响房价的变量,如地理位置、房屋年龄、房屋类型等。
首先,我们需要收集相关的数据。
我们可以通过调查和市场价格来获得房屋面积、房价以及其他相关变量的数据。
假设我们收集了100个样本数据来建立模型。
接下来,我们需要进行数据的预处理。
这包括数据清洗、缺失值处理、异常值处理等。
我们可以使用统计软件进行数据处理和分析。
然后,我们可以使用多元线性回归模型来建立房价与房屋面积以及其他相关变量之间的关系。
模型的形式可以表示为:房价= β0 + β1 × 房屋面积+ β2 × 地理位置+ β3 × 房屋年龄 +β4 × 房屋类型+ ε其中,β0、β1、β2、β3、β4是模型的回归系数,表示不同变量对房价的影响程度。
ε是误差项,表示模型无法解释的部分。
接着,我们可以使用最小二乘法估计回归系数,并进行统计显著性检验和模型拟合度检验。
这可以帮助我们判断模型的准确性和可解释性。
最后,我们可以使用估计的回归模型来进行预测和分析。
通过对模型的解释和系数的分析,我们可以得出不同变量对房价的影响程度,并制定相应的政策措施。
总之,计量经济学建模能够帮助我们理解和预测经济现象,对于研究者和政策制定者具有重要意义。
以上是一个简单的计量经济学建模案例,实际的建模过程可能更加复杂,需要根据具体问题进行相应的分析和处理。
计量经济学作业,DOC

计量经济学作业第二章为了初步分析城镇居民家庭平均每百户计算机用户有量(Y)与城镇居民平均每人全年家庭总收入(X)的关系,可以作以X为横坐所估计的参数,总收入每增加1元,平均说来城镇居民每百户计算机拥有量将增加0.002873台,这与预期的经济意义相符。
拟合优度和统计检验拟合优度的度量:本例中可决系数为0.8320,说明所建模型整体上对样本数据拟合较好,即解释变量“各地区城镇居民家庭人均总收入”对被解释变量“各地区城镇居民每百户计算机拥有量”的绝大部分差异做出了解释。
对回归系数的t检验:针对和,估计的回归系数的标准误差和t值分别为:,;的标准误差和t值分别为:,。
因为,绝;因,所以应拒绝。
城镇居民人均总收入对城镇居民每百取,平均置信度已经得到、、、n=31,可计算出。
当时,将相关数据代入计算得到83.7846 3.1627,即是说当地区城镇居民人均总收入达到25000元时,城镇居民每百户计算机拥有量平均值置信度95%的预测区间为(80.6219,86.9473)台。
个别置信度95%的预测区间为当时,将相关数据代入计算得到83.784616.7190是说,当地区城镇居民人均总收入达到元时,城镇居民每百户计算机拥有量化,选择“教育支出在地方财政支出中的比重”作为其代表。
探索将模型设定为线性回归模型形式:根据图中的数据,模型估计的结果写为(935.8816)(0.0018)(0.0080)(0.0517)(9.0867)(470.3214)t=(-2.5820)(6.3167)(4.9643)(2.8267)(2.5109)(1.8422)=0.9732F=181.7539n=31模型检验1.经济意义检验模型估计结果说明,在嘉定齐天然变量不变的情况下,地区生产12中数据可以得到:=0.9732可决系数为=0.9679:,性水平,在分布表中查出自由度为k-1=5何n-k=25界值.由表3.4得到F=181.7539,由于F=181.7539>,应拒绝原假设:,说明回归方程显著,即“地区生产总值”,“年末人口数”,“居民平均每人教育现金消费”,“居民教育消费价格指数”,“教育支出在地方财政支出中的比重”等变量联合起来确实对“地方财政教育支出”有显著影响。
计量经济学第五,六章作业

计量经济学第五,六章作业(总13页) -本页仅作为预览文档封面,使用时请删除本页-各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据(单位:元)(1)试根据上述数据建立2007年我国农村居民家庭人均消费支出对人均纯收入的线性回归模型。
(2)选用适当方法检验模型是否在异方差,并说明存在异方差的理由。
(3)如果存在异方差,用适当方法加以修正。
答:散点图线性回归分析图由图建立样本回归函数=+= F=由图形法可看出残差平方随的变动呈增大趋势,但还需进一步检验.White检验由上述结果可知,该模型存在异方差,理由是从数据可看出一是截面数据,看出各省市经济发展不平衡3)用加权最小二乘法修正,选用权数w1=,w2=,w3=.则散点图回归结果Goldfield-quanadt检验F==所以模型存在异方差t检验,F检验显著=+t=()()=,DW= ,F=剔除价格变动因素后的回归结果如下下表是北京市连续19年城镇居民家庭人均收入与人均支出的数据。
表略(1)建立居民收入—消费函数;残差图2ˆ79.9300.690(6.38)(12.399)(0.013)(6.446)(53.621)0.9940.575t t Y X Se t R DW =+====(2)检验模型中存在的问题,并采取适当的补救措施预以处理;(2)DW =,取%5=α,查DW 上下界18.1,40.1,18.1<==DW d d U L ,说明误差项存在正自相关(3)对模型结果进行经济解释。
采用科克伦奥科特迭代法广义差分因此,原回归模型应为t t X Y 669.0985.104+=其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加元。
.为了探讨股票市场繁荣程度与宏观经济运行情况之间的关系,取股票价格指数与GDP 开展探讨,表为美国1981-2006年股票价格指数(y )和国内生产总值GDP (x )的数据。
估计回归模型y_t=β_1+β_2 X_t+µ_t检验(1)中模型是否存在自相关,若存在,用广义差分法消除自相关最小二乘法估计回归模型为=3002527+ Se=t== F= DW=(2)LM=T=26*= P值为 t检验和F检验不可信。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2013级统计学专业《计量经济学》案例作业学号: 130702060 姓名:叶豪特1.下表是消费Y 与收入X 的数据,试根据所给数据资料完成以下问题:(1)估计回归模型u X Y ++=21ββ中的未知参数1β和2β,并写出样本回归模型的书写格式;(2)试用Goldfeld-Quandt 法和White 法检验模型的异方差性; (3)选用合适的方法修正异方差。
(1)eview 结果Method: Least SquaresDate: 06/08/15 Time: 10:20Sample: 1 60Included observations: 60Variable Coefficient Std. Error t-Statistic Prob. C 9.347522 3.638437 2.569104 0.0128 X 0.637069 0.019903 32.00881 0.0000 R-squared 0.946423 Mean dependent var 119.6667 Adjusted R-squared 0.945500 S.D. dependent var 38.68984 S.E. of regression 9.032255 Akaike info criterion 7.272246 Sum squared resid 4731.735 Schwarz criterion 7.342058 Log likelihood -216.1674 Hannan-Quinn criter. 7.299553 F-statistic 1024.564 Durbin-Watson stat 1.790431 Prob(F-statistic) 0.0000001β=9.35,2=0.64β,样本回归模型书写格式:01e=9.35+0.64XY X ββ=++(2)首先,用Goldfeld-Quandt 法进行检验。
a.将样本按递增顺序排序,去掉1/4,再分为两个部分的样本,即1222n n ==。
b.分别对两个部分的样本求最小二乘估计,得到两个部分的残差平方和,即2122603.01482495.840e e==∑∑求F 统计量为22212495.844.1390603.0148e F e===∑∑给定0.05α=,查F 分布表,得临界值为0.05(20,20) 2.12F =。
c.比较临界值与F 统计量值,有F =4.1390>0.05(20,20) 2.12F =,说明该模型的随机误差项存在异方差。
用White 法进行检验F-statistic6.301373 Probability 0.003370Test Equation:Dependent Variable: RESID^2 Method: Least SquaresDate: 06/08/15 Time: 12:25 Sample: 1 60C -10.03614 131.1424 -0.076529 0.9393 X 0.165977 1.619856 0.102464 0.9187 R-squared0.181067 Mean dependent var 78.86225 Adjusted R-squared 0.152332 S.D. dependent var 111.1375 S.E. of regression 102.3231 Akaike info criterion 12.14285 Sum squared resid 596790.5 Schwarz criterion 12.24757 Log likelihood -361.2856 F-statistic6.3013730.05α=,在自由度为2下查卡方分布表,得25.9915χ=。
比较临界值与卡方统计量值,即2210.8640 5.9915nR χ=>=,说明模型中的随机误差项存在异方差。
(2)用加权最小二乘估计,得如下结果Dependent Variable: Y Method: Least SquaresDate: 06/08/15 Time: 13:10 Sample: 1 60Included observations: 60 C 10.37051 2.629716 3.943587 0.0002 R-squared0.211441 Mean dependent var 106.2101 Adjusted R-squared 0.197845 S.D. dependent var 8.685376 S.E. of regression 7.778892 Akaike info criterion 6.973470 Sum squared resid 3509.647 Schwarz criterion 7.043282 Log likelihood -207.2041 F-statistic1159.176 R-squared0.946335 Mean dependent var 119.6667 Adjusted R-squared 0.945410 S.D. dependent var 38.68984 S.E. of regression 9.039689 Sum squared resid 4739.526其估计的书写形式为2ˆ10.37050.63100.2114,..7.7789,1159.18YX R s e F =+===2. 下表给出了日本工薪家庭实际消费支出与可支配收入数据日本工薪家庭实际消费支出与实际可支配收入单位:1000日元要求:(1)建立日本工薪家庭的收入—消费函数; (2)检验模型中存在的问题,并采取适当的补救措施预以处理;(3)对模型结果进行经济解释。
要求:(1)检测进口需求模型t t t u X Y ++=21ββ的自相关性;(2)采用科克伦-奥克特迭代法处理模型中的自相关问题。
(1)由eviews 一元线性回归结果可得:Dependent Variable: Y Method: Least Squares Date: 06/09/15 Time: 20:20 Sample: 1970 1994 Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.C -68.16026 15.26513 -4.465096 0.0002 X1.5297120.05097630.008460.0000R-squared0.975095 Mean dependent var 388.0000 Adjusted R-squared 0.974012 S.D. dependent var 43.33397 S.E. of regression 6.985763 Akaike info criterion 6.802244 Sum squared resid 1122.420 Schwarz criterion 6.899754 Log likelihood -83.02805 Hannan-Quinn criter. 6.829289 F-statistic 900.5078 Durbin-Watson stat 0.348288Prob(F-statistic)0.000000Y=-68.16+1.53X(1)220.975,0.974,900.5078,..0.348R R F DW ====(2)Dependent Variable: Y Method: Least Squares Date: 06/09/15 Time: 20:58 Sample: 1970 1994 Included observations: 25VariableCoefficientStd. Errort-StatisticProb.C 18.33144 29.51518 0.621085 0.5409 X 1.202239 0.109382 10.99121 0.0000 TIME^20.0505020.0155223.2536110.0036R-squared 0.983186 Mean dependent var 388.0000 Adjusted R-squared 0.981657 S.D. dependent var 43.33397 S.E. of regression 5.868976 Akaike info criterion 6.489404 Sum squared resid 757.7875 Schwarz criterion 6.635669 Log likelihood -78.11755 Hannan-Quinn criter. 6.529972 F-statistic 643.2046 Durbin-Watson stat 0.403640 Prob(F-statistic)0.000000D.W.检验结果表明,在5%显著性水平下,n=25,k=2(包含常数项),查表得1.29, 1.45,L U d d ==,由于D.W.=0.35<L d ,故(1)存在正自相关。
引入时间变量T (T=1,2,……,25)以平方的形式出现,回归函数变化为:2ˆY=18.33+1.20X+0.05T (2)22R 0.983,R 0.982,643.205,..0.404F DW ====,这里,D.W.值仍然比较低,没有通过5%显著性水平下的D.W.检验,因此判断(2)式仍然存在正自相关性。
再对(2)式进行序列相关性的拉格朗日乘数检验。
含一阶滞后残差项的辅助回归为:2t t-12e =50.81-0.19X+0.03T 0.75e 0.75R +=%%于是,LM=240.75⨯=18,该值大于显著性水平为5%,自由度为1的2χ分布的临界值20.05=3.84χ(1),由此判断原模型存在1阶序列相关性。
含2阶滞后残差项的辅助回归为: Dependent Variable: A Method: Least Squares Date: 06/09/15 Time: 22:00 Sample: 1970 1994Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.C -0.620166 19.49328 -0.031814 0.9749 X 0.001895 0.072225 0.026239 0.9793 TIME^2 0.001447 0.010240 0.141311 0.8890 RE 0.9176810.2108534.352228 0.0003 RE2-0.197403 0.213975-0.9225500.3672R-squared 0.604654 Mean dependent var 1.98E-14 Adjusted R-squared 0.525585 S.D. dependent var 5.619117 S.E. of regression 3.870322 Akaike info criterion 5.721409 Sum squared resid 299.5879Schwarz criterion5.965184 Log likelihood -66.51761 Hannan-Quinn criter. 5.789022 F-statistic7.647165 Durbin-Watson stat 1.826752 Prob(F-statistic)0.000657(RE2为2e t -%)2t t-1t-22e -0.620.00190.001440.924e -0.197e 0.605X time R =+++=%%%采用科克伦-奥克特两步法处理模型中的自相关问题 根据01111t t t Y X ββρμε-=+++,eviews 运行结果如下:112167.00 1.130.980.99t t Y X R μ-=++=最终的消费模型为 Y t = 93.7518+0.5351 X t(3)模型说明日本工薪居民的边际消费倾向为0.5351,即收入每增加1元,平均说来消费增加0.54元。