实验一SPSS报告
spss实验报告,心得体会

spss实验报告,心得体会篇一:SPSS实验报告SPSS应用——实验报告班级:统计0801班学号:1304080116 姓名: 宋磊指导老师:胡朝明2010.9.8一、实验目的:1、熟悉SPSS操作系统,掌握数据管理界面的简单的操作;2、熟悉SPSS结果窗口的常用操作方法,掌握输出结果在文字处理软件中的使用方法。
掌握常用统计图(线图、条图、饼图、散点、直方图等)的绘制方法;3、熟悉描述性统计图的绘制方法;4、熟悉描述性统计图的一般编辑方法。
掌握相关分析的操作,对显著性水平的基本简单判断。
二、实验要求:1、数据的录入,保存,读取,转化,增加,删除;数据集的合并,拆分,排序。
2、了解描述性统计的作用,并1掌握其SPSS的实现(频数,均值,标准差,中位数,众数,极差)。
3、应用SPSS生成表格和图形,并对表格和图形进行简单的编辑和分析。
4、应用SPSS做一些探索性分析(如方差分析,相关分析)。
三、实验内容:1、使用SPSS进行数据的录入,并保存: 职工基本情况数据:操作步骤如下:打开SPSS软件,然后在数据编辑窗口(Data View)中录入数据,此时变量名默认为var00001,var00002,…,var00007,然后在Variable View窗口中将变量名称更改即可。
具体结果如下图所示:输入后的数据为:将上述的数据进行保存:单击保存即可。
2、读取上述保存文件:选择菜单File--Open—Data;选择数据文件的类型,并输入文件名进行读取,出现如下窗口:选定职工基本情况.sav文件单击打开即可读取数据。
3、对上述数据新增一个变量工龄,其操作步骤为将当前数据单元确定在某变量上,选择菜单Data—Insert Variable,SPSS自动在当前数据单元所在列的前一列插入一2个空列,该列的变量名默认为var00016,数据类型为标准数值型,变量值均是系统缺失值,然后将数据填入修改。
结果如下图所示:篇二:SPSS相关分析实验报告本科教学实验报告(实验)课程名称:数据分析技术系列实验实验报告学生姓名:一、实验室名称:二、实验项目名称:相关分析三、实验原理相关关系是不完全确定的随机关系。
SPSS上机实验报告一
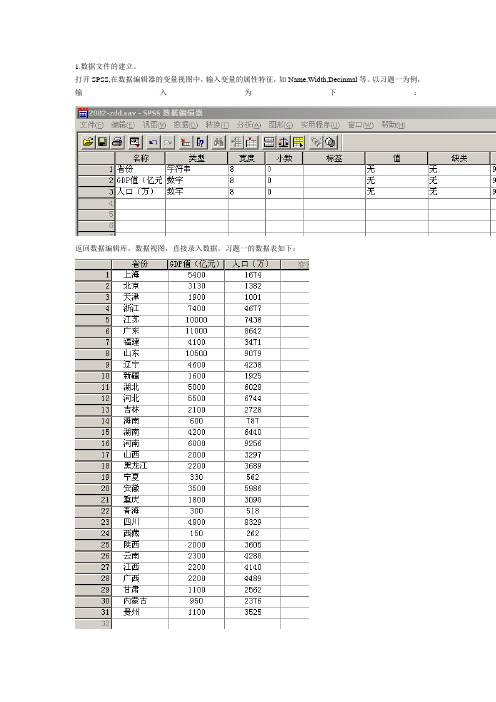
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。
统计学原理SPSS实验报告
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为mydata并保存在桌面。
如图1-4所示。
图1-4 数据的输入步骤4:调用Graphs菜单的Bar过程,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
选择的数据源见表1。
步骤5:数据准备。
激活数据管理窗口,定义变量名:年龄标化发生率为RATE,冠心病临床型为DISEASE,血压状态为BP。
RATE按原数据输入,DISEASE按冠状动脉机能不全=1、猝死=2、心绞痛=3、心肌梗塞=4输入,BP按正常=1、临界=2、异常=3输入。
步骤6:选Graphs菜单的Bar...过程,弹出Bar Chart定义选项框(图1-5)。
SPSS实验

《统计实验》实验报告姓名:方兆运专业:经济学学号:2012127131日期:2015年 3 月20 日地点:实验中心508实验一统计数据整理一、实验类型二、实验目的熟悉SPSS的菜单和窗口界面及SPSS的数据管理和预处理功能。
三、实验内容(1)定义变量,建立数据文件(2)输入数据(直接输入)(3)数据的增删(4)变量重新赋值(5)数据的运算与新变量的生成(6)数据排序(7)数据的行列互换。
四、实验数据某航空公司38名职员性别和工资情况的调查数据,如下表所示,试在SPSS中进行如下操作:(1)将表1数据输入到SPSS的数据编辑窗口中,将gender定义为字符型变量,保存数据文件,命名为“gender.sav”。
(2)将表2数据输入到SPSS的数据编辑窗口中,将salary定义为数值型变量,保存数据文件,命名为“salary.sav”。
(3)将两个数据文件合成一个数据文件,命名为“Employee Data.sav”。
(4)要求将数据文件“Employee Data.sav”按照变量salary(收入)进行升序排序,并建立一个新数据文件“Employee Data(sorted).sav”放置排序以后的结果。
(5)要求将数据文件“Employee Data.sav”按照变量gender(性别)进行分组,对每一组的变量salary计算其算术平均数,并计算其最大观察值,并建立一个新数据文件“Employee Data(aggregate).sav”放置分类汇总以后的结果。
(6)要求以gender(性别)对数据文件“Employee Data.sav”进行拆分,并要求在以后的统计分析中可以将各拆分文件的统计分析结果放在同一表格中显示。
(看不出操作结果,熟悉该操作过程即可)。
(7)要求在“Employee Data.sav”文件中,标识工资在30000元以上的员工。
标识变量名设为s_ed变量标签为工资学历标识。
SPSS期末综合实验报告

SPSS期末综合实验报告姓名:学号:成绩:(附:本实验报告基于SPSS 20.0)一、用“SUMMARIZE CASES”作一个分组比较【1】点击【分析】——【报告】——【个案汇总】菜单项,弹出“摘要个案”对话框,设置如下:【2】点击【确定】,输出结果,整理后得三线表,如下:个案汇总N性别城市学历男北京188 上海221 广州228 Total 637女北京190 上海166 广州154 Total 510从上表可以看出,上海市和广州市的男性比例要高于女性,而在北京市方面,男女之间则差别不大,但同时也要考虑到抽样调查数据中男性和女性的绝对数的大小不同。
二、对某一个变量“选择个案(select)”进行频数分析【1】点击【分析】——【描述统计】——【频率】菜单项,弹出“频率”对话框,设置如下:【2】点击【确定】,输出结果,整理后得三线表,如下:城市频数百分比(%)北京上海广州Total 378 33.0 387 33.7 382 33.3 1147 100.0从上表可以看出,在抽样调查的数据当中,样本中北京市的被调查者有378人,占总数的33.0%,样本中上海市的被调查者有387人,占总数的33.7%,样本中广州市的被调查者有382人,占总数的33.3%,因此,在误差允许的范围内,可以认为抽样是相对均匀的。
三、对某一个变量进行重新分组(recode)【1】点击【转换】——【重新编码为不同变量】,弹出“重新编码为不同变量”对话框,设置如下:【2】点击【更改】后,如上图,点击【旧值和新值】,弹出如下对话框,依次设置如下:【3】点击【继续】——【确定】可得如下效果,变量视图:四、对某两个定类变量进行卡方检验【1】点击【分析】——【描述统计】——【交叉表】菜单项,弹出“交叉表”对话框,如图所示:【2】在“行”列表框中选入“家庭收入2级Ts9”;在“列”列表框中选入“是否拥有家用轿车O1”,如图所示:【3】单击【单元格】,弹出“单元显示”对话框,选中“行百分比”复选框;如图:【4】单击【继续】,再单击【统计量】,弹出“统计量”对话框,选中“卡方”复选框,如图:【5】单击【继续】——【确定】,得到输出结果,整理后得三线表,如下:Ⅰ交叉表:家庭收入2级 * 是否拥有家用轿车Crosstabulation是否拥有家用轿车有没有家庭收入2级Below 48,000Count% within 家庭收入2级32 3039.6% 90.4%Over 48,000Count 225 429% within 家庭收入2级34.4% 65.6% TotalCount 257 732% within 家庭收入2级26.0% 74.0%Ⅰ由交叉表可知低收入家庭中只有9.6%拥有轿车,而中高收入家庭中有34.4%拥有轿车,样本数据差异明显,但该差异是否具有统计学意义尚需检验,卡方检验结果如下表。
spss统计实验报告

spss统计实验报告SPSS统计实验报告引言:SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学、经济学、医学和教育等领域。
本文将以一项关于学生学习成绩的统计实验为例,展示如何使用SPSS进行数据处理和分析。
一、实验目的本次实验的目的是探究学生的学习时间和学习成绩之间的关系。
通过对一组学生进行调查,收集他们的学习时间和成绩数据,然后使用SPSS进行统计分析,以揭示学习时间与学习成绩之间的相关性。
二、实验设计与数据收集我们选择了100名高中生作为实验对象,通过问卷调查的方式收集他们的学习时间和成绩数据。
学习时间以每周学习小时数为单位,成绩以百分制表示。
通过这种方式,我们可以得到一个包含学习时间和成绩两个变量的数据集。
三、数据处理与清洗在进行统计分析之前,我们需要对数据进行处理和清洗,以确保数据的准确性和一致性。
首先,我们检查数据是否存在缺失值或异常值。
如果发现有缺失值或异常值,我们可以选择删除这些数据或进行适当的填充和修正。
其次,我们对数据进行变量命名和编码,以便后续的分析和解释。
最后,我们对数据进行了简单的描述性统计,包括计算平均值、标准差和分布情况等。
四、数据分析与结果在进行数据分析时,我们首先进行了相关性分析,以确定学习时间和成绩之间的关系。
通过SPSS的相关性分析功能,我们计算了学习时间和成绩之间的皮尔逊相关系数。
结果显示,学习时间和成绩之间存在显著的正相关关系(r=0.75,p<0.01),即学习时间越长,成绩越好。
接下来,我们进行了回归分析,以进一步探究学习时间对成绩的影响程度。
通过SPSS的线性回归功能,我们建立了一个学习时间与成绩之间的回归模型。
回归分析的结果显示,学习时间对成绩的解释程度为56%,即学习时间可以解释学生成绩的变异程度的56%。
此外,回归模型的显著性检验结果也显示,该模型的回归系数是显著的(p<0.01)。
SPSS实验报告

SPSS实验报告描述性统计分析⼀、实验⽬的1.进⼀步了解掌握SPSS专业统计分析软件,能更好地使⽤其进⾏数据统计分析。
2.学习描述性统计分析及其在SPSS中的实现,内容具体包括基本描述性统计量的定义及计算﹑频率分析﹑描述性分析﹑探索性分析﹑交叉表分析等。
3.复习权重等前章的知识。
⼆﹑实验内容题⽬⼀打开数据⽂件“data4-5.sav”,完成以下统计分析:(1)计算各科成绩的描述统计量:平均成绩、中位数、众数、标准差、⽅差、极差、最⼤值和最⼩值;(2)使⽤“Recode”命令⽣成⼀个新变量“成绩段”,其值为各科成绩的分段:90~100为1,80~89为2,70~79为3,60~69为4,60分以下为5,其值标签设为:1-优,2-良,3-中,4-及格,5-不及格。
分段以后进⾏频数分析,统计各分数段的⼈数,最后⽣成条形图和饼图。
1.解决问题的原理因为问题涉及各科成绩,⽤描述性分析,第⼆问要先进⾏数据分段,其后利⽤频数分析描述统计量并可以⽣成条形图等。
2.实验步骤针对第⼀问第1步打开数据菜单选择:“⽂件→打开→数据”,将“data4-8.sav”导⼊。
第2步⽂件拆分菜单选择:“数据→拆分⽂件”,打开“分割⽂件”对话框,点击⽐较组按钮,将“科⽬”加⼊到“分组⽅式”列表框中,并确定。
第3步描述分析设置:(1)选择菜单:“分析→描述统计→描述”,打开“描述性”对话框,将“成绩””加⼊到“变量”列表框中。
打开“选项”对话框,选中如下图中的各项。
点击“继续”按钮。
(4)回到“描述性”对话框,点击确定。
针对第⼆问第1步频率分析设置:(1)选择菜单:“分析→描述统计→频率”,(2)打开“频率(F)”对话框,点击“合计”。
再点击“继续”按钮.(3)打开“图表”对话框,选中“条形”复选框,点击“继续”按钮。
(4)回到“频率(F)”对话框,点击确定。
(5)重复步骤(1)(2)把步骤(3)改成打开“图表”对话框,选中“饼图”复选框,点击“继续”按钮。
spss实训报告1

实训报告实验课程名称SPSS软件实训系(部)年级专业班学生姓名学号开课时间至学年第学期实验一均值比较与T检验一实验目的1、掌握均值比较,用于计算指定变量的综合描述统计量,2、掌握单样本T检验(One—Sample T Test),检验单个变量的均值与假设之间是否存在差异;3、掌握独立样本T检验(Independent Samples Test),用于检验两组来自独立总体的样本,企图理综题的均值或中心位置是否一样4、掌握配对样本T检验(Paired Samples Test),用于检验两个相关的样本是否来自具有相同均值的总体。
二实验内容1 (1) 解决问题的原理:分析该班的数学成绩与全国的平均成绩70分之间是否有显著性差异,其中全班平均成绩为单个变量的均值,全国平均成绩70分之间为假设检验值,此问题满足单样本T检验(One—Sample T Test)的条件,因此用单样本T检验来解决此问题。
(2) 实验步骤;第1步数据组织;首先建立SPSS数据文件,只需建立一个变量“成绩”,录入相应的数据即可。
第2步打开主对话框;选择Analyze→ Compare Means → One-Sample T Test ,打开同下图样的单样本T检验主对话框。
第3步确定要进行T检验的变量;在上图所示的对话框中,选择“成绩”变量作为检验变量,移入“Test Variable(s)”框中。
第4步输入要检验的值;在上图的对话框中的“Test value”中输入要检验的值,本例应输入70。
(3)结果分析(1)单样本统计量单样本统计量(One-Sample Statistics)(2)单样本T检验结果:当置信水平为95%时,显著性水平为0.05,从单样本T检验(One—Sample T Test)结果表可以看出,双尾检验率P值为0.002,小于0.05,故拒绝原假设,也就是说该班的数学成绩与全国的平均成绩70分之间有显著性差异。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一SPSS报告实验一一元线性回归分析一、实验目标与要求本实验的目的是学习并使用SPSS软件进行相关分析和回归分析,具体包括:(1) 皮尔逊pearson简单相关系数的计算与分析(2) 学会在SPSS上实现一元及多元回归模型的计算与检验。
(3) 学会回归模型的散点图与样本方程图形。
(4) 学会对所计算结果进行统计分析说明。
(5) 要求试验前,了解回归分析的如下内容。
, 参数α、β的估计, 回归模型的检验方法:回归系数β的显著性检验(t,检验);回归方程显著性检验(F,检验)。
二、实验原理1(相关分析的统计学原理相关分析使用某个指标来表明现象之间相互依存关系的密切程度。
用来测度简单线性相关关系的系数是Pearson简单相关系数。
2(回归分析的统计学原理相关关系不等于因果关系,要明确因果关系必须借助于回归分析。
回归分析是研究两个变量或多个变量之间因果关系的统计方法。
其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。
回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进行检验和判断,并进行预测等。
线性回归数学模型如下:y,,,,x,,x,?,,x,, i01i12i2kiki在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数:ˆˆˆˆy,,,,x,,x,?,,x,e i01i12i2kiki回归模型中的参数估计出来之后,还必须对其进行检验。
如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量和解释变量及其函数形式,或者对数据进行加工整理之后再次估计参数。
回归模型的检验包括一级检验和二级检验。
一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟和优度评价和显著性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差检验等。
三、实验演示内容与步骤1、一元线性回归分析实例分析:饮料销售量与气温的回归模型在这个例子里,考虑气温对饮料销售量的影响,建立的模型如下:y,,,,xi,,ii其中,y是饮料销售量,x是气温线性回归分析的基本步骤及结果分析:(1)绘制散点图打开数据文件,选择【图形】-【旧对话框】-【散点/点状】,如图1所示。
图1 散点图对话框选择简单分布,单击定义,打开子对话框,选择X变量和Y变量,如图2所示。
单击ok提交系统运行,结果见图3所示。
图2 Simple Scatterplot 子对话框从图上可直观地看出住房支出与年收入之间存在线性相关关系。
图3 散点图(2)简单相关分析, 打开数据文件“实验一.sav”,依次选择“【分析】?【相关】?【双变量】”打开对话框如图,将待分析的两个个指标移入右边的变量列表框内。
其他均可选择默认项,单击ok提交系统运行。
图4 Bivariate Correlations对话框结果分析:表1 均值与标准差Descriptive StatisticsMean Std. Deviation N气温 27.0000 10.60398 10销售量 380.0000 120.16193 10表1给出了气温与饮料销售量的均值和标准差。
表2 Pearson简单相关分析Correlations气温销售量**气温 Pearson Correlation 1 .859Sig. (2-tailed) .001N 10 10**销售量 Pearson Correlation .859 1Sig. (2-tailed) .001N 10 10**. Correlation is significant at the 0.01 level (2-tailed).表2给出了Pearson简单相关系数,相关检验t统计量对应的p值。
相关系数右上角有两个星号表示相关系数在0.01的显著性水平下显著。
从表中可以看出,气温和饮料销售量2个指标之间的相关系数都在0.859以上,对应的p值都接近0.001,表示2个指标具有较强的正相关关系。
根据饮料销售量与气温之间的散点图与相关分析显示,饮料销售量与气温之间存在显著的正相关关系。
在此前提下进一步进行回归分析,建立一元线性回归方程。
(3) 线性回归分析步骤1:选择菜单“【分析】—>【回归】—>【线性】”,打开Linear Regression对话框。
将变量销售量y移入Dependent列表框中,将气温x移入Independents列表框中。
在Method 框中选择Enter 选项,表示所选自变量全部进入回归模型。
图5 Linear Regresssion对话框步骤2:单击Statistics按钮,如图在Statistics子对话框。
该对话框中设置要输出的统计量。
这里选中估计、模型拟合度复选框。
图6 Statistics子对话框, 估计:输出有关回归系数的统计量,包括回归系数、回归系数的标准差、标准化的回归系数、t统计量及其对应的p值等。
, 置信区间:输出每个回归系数的95,的置信度估计区间。
, 协方差矩阵:输出解释变量的相关系数矩阵和协差阵。
, 模型拟合度:输出可决系数、调整的可决系数、回归方程的标准误差、回归方程F检验的方差分析。
步骤3:单击绘制按钮,在Plots子对话框中的标准化残差图选项栏中选中正态概率图复选框,以便对残差的正态性进行分析。
图7 plots子对话框步骤4:单击保存按钮,在Save子对话框中残差选项栏中选中未标准化复选框,这样可以在数据文件中生成一个变量名尾res_1 的残差变量,以便对残差进行进一步分析。
图8 Save子对话框其余保持Spss默认选项。
在主对话框中单击ok按钮,执行线性回归命令,其结果如下:表3 回归模型拟和优度评价及Durbin,Watson检验结果bModel SummaryAdjusted R Std. Error of Model R R Square Square the Estimate Durbin-Watsona1 .859 .739 .706 65.17343 1.938 a. Predictors: (Constant), 气温b. Dependent Variable: 销售量表3给出了回归模型的拟和优度(R Square)、调整的拟和优度(Adjusted R Square)、估计标准差(Std. Error of the Estimate)以及Durbin,Watson统计量。
从结果来看,回归的可决系数和调整的可决系数分别为0.739和0.706,即饮料销售量的74,以上的变动都可以被该模型所解释,拟和优度较高。
表4 方差分析表bANOVAModel Sum of Squares df Mean Square F Sig.a1 Regression 95969.392 1 95969.392 22.594 .001Residual 33980.608 8 4247.576Total 129950.000 9a. Predictors: (Constant), 气温b. Dependent Variable: 销售量表4给出了回归模型的方差分析表,可以看到,F统计量为22.594,对应的p 值为0.001,所以,拒绝模型整体不显著的原假设,即该模型的整体是显著的。
表5 回归系数估计及其显著性检验aCoefficientsUnstandardized Standardized 95.0% Confidence IntervalCoefficients Coefficients for BStd. LowerB Error Beta t Sig. Bound Upper Bound117.070 59.030 1.983 .083 -19.053 253.1939.738 2.049 .859 4.753 .001 5.014 14.462 a. Dependent Variable: 销售量表5给出了回归系数、回归系数的标准差、标准化的回归系数值以及各个回归系数的显著性t检验。
从表中可以看到无论是常数项还是解释变量x,其t统计量对应的p值都小于显著性水平0.05,因此,在0.05的显著性水平下都通过了t检验。
变量x的回归系数为9.738,即气温每增加1度,饮料销售量就增加9.738箱。
表6 残差统计表aResiduals StatisticsMinimum Maximum Mean Std. Deviation N Predicted Value 194.9753 526.0721 380.0000 103.26309 10 Residual -101.83300 119.47629 .00000 61.44610 10 Std. Predicted Value -1.792 1.415 .000 1.000 10 Std. Residual -1.562 1.833 .000 .943 10 a. Dependent Variable: 销售量表6显示了回归模型的残差、标准化残差的最大值、最小值、均值,标准差及样本容量。
为了判断随机扰动项是否服从正态分布,观察图9所示的标准化残差的P,P 图,可以发现,各观测的散点基本上都分布在对角线上,据此可以初步判断残差服从正态分布。
图9 标准化残差的P,P图。