应用多元统计分析SAS作业第三章
应用多元统计分析SAS作业审批稿

应用多元统计分析S A S作业YKK standardization office【 YKK5AB- YKK08- YKK2C- YKK18】5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。
对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。
表1 岩石化学成分的含量数据(1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等);(2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为2.95,2.15和1.54,试判断该标本是含矿还是不含矿?问题求解1 使用广义平方距离判别法对样本进行判别归类用SAS软件中的DISCRIM过程进行判别归类。
SAS程序及结果如下。
data d59;input group x1-x3@@;cards;1 2.58 0.9 0.951 2.9 1.23 11 3.55 1.15 11 2.35 1.15 0.791 3.54 1.85 0.791 2.7 2.23 1.31 2.7 1.7 0.482 2.25 1.98 1.062 2.16 1.8 1.062 2.33 1.74 1.12 1.96 1.48 1.042 1.94 1.4 1 23 1.3 1 2 2.78 1.7 1.48 ;proc print data =d59; run ;proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ;由输出结果可知,两总体间的广义平方距离为D 2=3.19774。
还可知两个三元总体均值相等的检验结果:D =3.19774,F =3.10891,p =0.0756<0.10,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。
多元统计分析第三章假设检验与方差分析

多元统计分析第三章假设检验与⽅差分析第3章多元正态总体的假设检验与⽅差分析从本章开始,我们开始转⼊多元统计⽅法和统计模型的学习。
统计学分析处理的对象是带有随机性的数据。
按照随机排列、重复、局部控制、正交等原则设计⼀个试验,通过试验结果形成样本信息(通常以数据的形式),再根据样本进⾏统计推断,是⾃然科学和⼯程技术领域常⽤的⼀种研究⽅法。
由于试验指标常为多个数量指标,故常设试验结果所形成的总体为多元正态总体,这是本章理论⽅法研究的出发点。
所谓统计推断就是根据从总体中观测到的部分数据对总体中我们感兴趣的未知部分作出推测,这种推测必然伴有某种程度的不确定性,需要⽤概率来表明其可靠程度。
统计推断的任务是“观察现象,提取信息,建⽴模型,作出推断”。
统计推断有参数估计和假设检验两⼤类问题,其统计推断⽬的不同。
参数估计问题回答诸如“未知参数θ的值有多⼤?”之类的问题,⽽假设检验回答诸如“未知参数θ的值是0θ吗?”之类的问题。
本章主要讨论多元正态总体的假设检验⽅法及其实际应⽤,我们将对⼀元正态总体情形作⼀简单回顾,然后将介绍单个总体均值的推断,两个总体均值的⽐较推断,多个总体均值的⽐较检验和协⽅差阵的推断等。
3.1⼀元正态总体情形的回顾⼀、假设检验在假设检验问题中通常有两个统计假设(简称假设),⼀个作为原假设(或称零假设),另⼀个作为备择假设(或称对⽴假设),分别记为0H 和1H 。
1、显著性检验为便于表述,假定考虑假设检验问题:设1X ,2X ,…,n X 来⾃总体),(2σµN 的样本,我们要检验假设100:,:µµµµ≠=H H (3.1)原假设0H 与备择假设1H 应相互排斥,两者有且只有⼀个正确。
备择假设的意思是,⼀旦否定原假设0H ,我们就选择已准备的假设1H 。
当2σ已知时,⽤统计量nX z σµ-=在原假设0H 成⽴下,统计量z 服从正态分布z )1,0(~N ,通过查表,查得)1,0(N 的上分位点2αz 。
《应用多元分析》(第三版)各章附录中SAS程序的说明等(DOC)

《应用多元分析》(第三版)各章附录中SAS程序的说明等(王学民编)附录1-1 SAS的应用例1—1.1的SAS程序:proc iml;x={1 2 3 4 5,2 4 7 8 9,3 7 10 15 20,4 8 15 30 20,5 9 20 20 40};g=inv(x);e=eigval(x);d=eigvec(x);h=det(x);t=trace(x);print g e d h t;程序说明:“proc iml"是一个矩阵运算的过程步;“x={1 2 3 4 5,2 4 7 8 9,3 7 10 15 20,4 815 30 20,5 9 20 20 40}”是输入矩阵1234524789371015204815302059202040⎛⎫⎪⎪⎪⎪⎪⎪⎝⎭,并赋值给变量x;inv(x)是x的逆矩阵函数,eigval(x)是x的特征值函数,eigvec(x)是x的特征向量函数,det(x) 是x的行列式函数,trace(x)是x的迹函数,这些函数分别赋值给我们取的变量g,e,d,h,t;“print g e d h t”是打印语句,指定将g e d h t的值输出。
附录2—1 SAS的应用例2.3。
3和例2。
3.6的SAS程序:proc iml;a={2 -1 4,0 1 —1,1 3 -2};b={5,-2,7};c={4 1 2,1 9 —3,2 —3 25};d=block(2,3,5);e=a*b;v=a*c*t(a);r=inv(d)*c*inv(d);print e v r;程序说明:“proc iml”是一个矩阵运算的过程步;“a={2 —1 4,0 1 —1,1 3 -2}”是输入矩阵214011132-⎛⎫⎪-⎪⎪-⎝⎭,并赋值给变量a;“b={5,—2,7}"是输入向量527⎛⎫⎪- ⎪⎪⎝⎭,并赋值给变量b;“c={4 1 2,1 9 -3,2 -3 25}”是输入矩阵4121932325⎛⎫⎪-⎪⎪-⎝⎭,并赋值给变量c;“d=block(2,3,5)”是输入对角阵diag(2,3,5),并赋值给变量d;“e=a*b”是将a与b相乘,并赋值给变量e;“v=a*c*t(a)”是将a,c,a’三个矩阵相乘,并赋值给变量v,其中t(a)是a的转置函数;“r=inv(d)*c*inv(d)”是将d-1,c,d-1相乘,并赋值给变量r,其中inv(d)是d的逆矩阵函数;”print e v r”是打印语句,指定将e v r的值输出.附录3-1 SAS的应用例3-1.1的SAS程序:proc corr data=sasuser.examp3a1 cov;var x1—x7;run;proc corr data=sasuser.examp3a1 nosimple cov;var x5 x6 x7;with x3 x4;partial x1 x2;run;程序说明:Proc步是以proc开头的一组或几组语句,它以另一个proc步、data步或run语句结束。
多元统计分析第三章课件

( X 0 ) t n S
2 n ( X ) 2 1 t2 n ( X ) ( S ) ( X ) 2 S 对于多元变量而言,可以将 t 分布推广为下面将要介绍的 2 Hotelling T 分布。
定义
设 X ~ N p (μ , Σ , ) S ~ Wp ( n, Σ 且 ) X 与S
2 -1
相互独立,n p , 则称统计量 T nX S X 的分布 为非中心 HotellingT2 分布,记为 T 2 ~ T 2 ( p, n, μ) 。 当 μ 0 时,称 T 服从(中心) Hotelling T 分布。
2 2
记为 T 2 ( p, n) 。 由于这一统计量的分布首先由 Harold Hotelling 提出 来的,故称为 Hotelling T 分布,值得指出的是,我 国著名统计学家许宝禄先生在 1938 年用不同方法也
n ai μ ai X T aiSai
n 1
当k很小时,联合T2置信区间 aix T aiSai n ai μ ai X T aiSai
n , i 1, 2,, k
的置信度一般会明显地大于1−α,因而上述区间会显得过宽, 即精确度明显偏低。这时,考虑采用庞弗伦尼(Bonferroni) 联合置信区间(p177):
第三章 多元正态总体的统计推断
§3.1 引言 §3.2 单个总体均值的推断
§3.3 单个总体均值分量间结构关系的检验
§3.4 两个总体均值的比较推断 §3.5 两个总体均值分量间结构关系的检验 §3.6 多个总体均值的比较检验(多元方差分析) §3.7 协方差阵的检验
§3.1 引言
在单一变量的统计分析中,已经给出了正态总体N ( , 2) 的均值和方差2的各种检验。对于多变量
多元统计分析 第三章 习题

因子分析作业
一家公司正试图对其销售员工的质量做评估,并且正寻找一种考察或一系列测试,以期可以解释是否有创造良好销售额的潜能。
该公司已挑选了50个销售人员的随机样本,还已对每一个人就3项表现作了评估,销售增长、销售利润和新客户销售额。
这些测度量已被变为同一尺度,其中100表示“平均业绩”。
50个人中的每一个接受4项测试,分别测量创造力、机械推理、抽象推理和数学能力。
(数据见练习9.19)
a、假设对标准化变量有正交因子模型,求m=2和m=3个公因子的主成分解或极大似然解。
b、由a的解,求m=2和m=3的旋转载荷,解释m=2和m=3的因子解。
c、列出m=2和m=3的共同度和特殊方差,比较这些结果,此时你更愿意选择m 等于什么值,为什么?
d、设随机选取一个新的销售人员,得到测验分数)
,
,
110
98
'
x,用
105
(
,
20
35
,
18
15
,
,
加权最小二乘法和回归方法,计算这个销售人员的因子得分。
多元统计分析案例实验-使用SAS软件对我国各地区城镇居民消费性支出的主成分分析和聚类分析

实验三我国各地区城镇居民消费性支出的主成分分析和聚类分析一、实验目的1.掌握如何使用SAS软件来进行主成分分析和聚类分析;2.看懂和理解SAS输出的结果,并学会以此来作出分析;3.掌握对实际数据如何来进行主成分分析;4.对同一组数据使用五种系统聚类方法及k均值法,学会对各种聚类效果的比较,获取重要经验;5.掌握使用主成分进行聚类二、实验内容数据集sasuser.examp633中含有1999年全国31个省、直辖市和自治区的城镇居民家庭平均每人全年消费性支出的八个主要变量数据。
对这些数据进行主成分分析,可将这31个地区的前两个主成分得分标示于平面坐标系内,对各地区作直观的比较分析。
对同样的数据使用五种系统聚类方法及k均值法聚类,并对聚类效果作比较。
最后,对主成分的图形聚类和正规聚类的效果进行比较。
实验1进行主成分分析,根据前两个主成分得分所作的散点图对31个地区进行比较分析。
实验2分别使用最长距离法、中间距离法、两种类平均法、离差平方和法和k均值法进行聚类分析,并比较其聚类效果。
实验3主成分聚类,并与上述正规的聚类方法进行比较三、实验要求1.用SAS软件的交互式数据分析菜单系统完成主成分分析;2.完成五种系统聚类方法及k均值法,比较其聚类效果;3.根据前两个主成分得分的散点图作直观的聚类,并与上述正规的聚类方法进行比较。
四、实验指导1.进行主成分分析在inshigt中打开数据集sasuser.examp633,见图1。
选菜单过程如下:在图1中选分析⇒多元(Y X)⇒在变量框中选x1,x2,x3,x4,x5,x6,x7,x8(见图2)⇒Y⇒选输出⇒选主分量分析,主分量选项(见图3)⇒在图4中作图中的选择(主成分个数缺省时为“自动”选项,此时只输出特征值大于1的主成分)⇒确定⇒确定⇒确定图1图2图3图4 得到如图5、图6所示的结果:图5图6 从图5可以看出,前两个和前三个主成分的累计贡献率分别达到80.6%和87.8%,第一主成分1ˆy 在所有变量(除在*2x 上的载荷稍偏小外)上都有近似相等的正载荷,反映了综合消费性支出的水平,因此第一主成分可称为综合消费性支出成分。
应用多元统计分析_课后答案

图 2.1
Descriptives 对话框
2.
单击 Options 按钮,打开 Options 子对话框。在对话框中选择 Mean 复选框,即计 算样本均值向量,如图 2.2 所示。单击 Continue 按钮返回主对话框。
图 2.2 Options 子对话框 3. 单击 OK 按钮,执行操作。则在结果输出窗口中给出样本均值向量,如表 2.1,即 样本均值向量为(35.3333,12.3333,17.1667,1.5250E2) 。
2.5 解: 依据题意,X= 57000 40200 21450 21900 45000 28350
′
15 16 12 8 15 8
27000 18750 12000 13200 21000 12000
144 36 381 190 138 26
′ E(X)= ∑6 α=1 x(α) = (35650,12.33,17325,152.5) n σ1 σ2 ρ2 (x1 −μ1 )2 σ2 1
+
σ2 1
(x2 −μ2 )2 σ2 2 )2
= = [
(x1 −μ1 )2 σ2 1 ρ(x1 −μ1 ) σ1
− −
2ρ(x1 −μ1 )(x2 −μ2 ) σ1 σ2 (x2 −μ2 ) 2 ] σ2
+
E( X ) μ
n→∞
lim E(
1 1 ������) = lim E( ������) = Σ n→∞ ������ n−1
2.7 试证多元正态总体 的样本均值向量 ̅) = E ( ΣX 证明: E(������ (α) ) = E (ΣX (α) ) =
n n 1 1 nμ n 1 n2
exp[−
医学统计学第四版各章例题SAS与STATA实现第三章
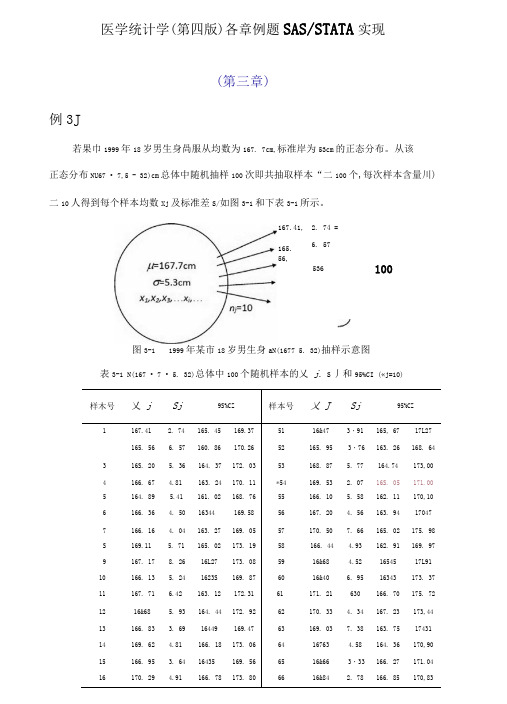
医学统计学(第四版)各章例题SAS/STATA 实现(第三章)例3J若果巾1999年18岁男生身咼服从均数为167. 7cm,标准岸为53cm 的正态分布。
从该 正态分布NU67 • 7,5 - 32)cm 总体中随机抽样100次即共抽取样本“二100个,每次样本含量川) 二10人得到每个样本均数Xj 及标准差S/如图3-1和下表3-1所示。
图3-1 1999年某市18岁男生身aN(1677 5. 32)抽样示意图表3-1 N(167 • 7 • 5. 32)总体中100个随机样本的乂 j. S 丿和95%CI («j=10)样木号乂 jSj9S%CZ样本号乂 JSj95%CZ1167.41 2. 74 165. 45 169.37 51 16&47 3・91 165, 67 17L27165. 566. 57 160. 86 170.26 52 165. 95 3・76 163. 26 168. 64 3 16S. 20 5. 36 164. 37 172. 03 53 168. 87 5. 77 164.74 173,00 4 166. 67 4.81 163. 24 170. 11 *54 169. 53 2. 07 16S. 05 171.00 5 164. 89 5.41 161. 02 168. 76 55 166. 10 5. 58 162. 11 170,10 6 166. 36 4. 50 16344 169.58 56 167. 20 4. 56 163. 94 17047 7 166. 16 4. 04 163. 27 169. 05 57 170. 50 7. 66 165. 02 175. 98 S 169.11 5. 71 165. 02 173. 19 58 166. 44 4.93 162. 91 169. 97 9 167. 178. 26 16L27 173. 08 59 16&68 4.52 16545 17L91 10 166. 13 5. 24 1623S 169. 87 60 16&40 6. 95 16343 173. 37 11 167. 71 6.42 163. 12 172.31 61 171. 21 630 166. 70 175. 72 12 16&68 5. 93 164. 44 172. 92 62 170. 33 4. 34 167. 23 173,44 13 166. 83 3. 69 16449 169.47 63 169. 03 7. 38 163. 75 17431 14 169. 62 4.81 166. 18 173. 06 64 16763 4.58 164. 36 170,90 15 166. 95 3. 64 16435 169. 56 65 16&66 3・33 166. 27 171.04 16170. 294.91166. 78173. 806616&842. 78166. 85170,83167.41, 165. 56,2. 74 = 6. 57 53610017 169. 20 5. 72 165. 11 173. 30 67 169. 31 5.31 165. 51 173. 11 1S 167. 65 2. 79 165. 65 169. 65 68 168. 46 4.81 16302 171.90 19 166. 51 5. 39 162. 65 170. 36 69 168. 60 5. 4S 164,68 172.52 •20163. 28 3. 19 16L00165. 5770 168.47 5. 05 164. 86 172,09 21 166. 29 4. 95 162.75 169. 84 71 165. 6S 5. 19 161.97 169. 40167. 65 5. 27 163S8 171.42 72 165. 68 8. 22 159. 80 171.5623 167. 64 4.61 16435 170. 94 73 168. 03 4.89 164. 53 171.5324 172.61 7. 74 167. 07 178.15 74 169. 37 5. 00 16579 172. 9425 166. 65 4. 12 163. 70 169. 59 75 169. 16 8. 36 163, 18 175,1426 165. 19 4.41 162. 04 168. 34 *76 171.27 4. 99 167.71174,8427 168. 80 7. 68 16331 174.30 77 16&36 4. 50 165, 14 171.5828 167如 2. 58 166.14 169. 83 78 168.50 3. 55 165, 96 171,0429 168.41 3.43 165. 95 170. 86 79 168. 08 5. 33 164. 27 171.9030 167. 75 7. 53 162.36 173. 13 80 165. 51 4.71 162.14 168. 88 ♦31 164. 25 4. 30 161. 17167. 33S1 167. 59 3. 73 164. 93 1702632 166. 42 5. 19 16271 170.13 *82 171. 12 4. 40 167. 98174, 2733 166. 90 4.41 163. 74 170. 05 83 165. 92 5. 11 162. 26 169.5834 166. 77 4. 34 163& 169& 84 16786 4. 44 164.69 171,0435 165. 77 5. 34 161.95 169.59 85 167. 43 6. 15 163. 03 171.8336 16442 6. 63 15938 168. 86 86 16790 6. 13 163. 51 172. 2837 169. 83 4. 20 166. 82 172. 84 87 167. 59 633 163. 06 172.1238 165. 16 4. 01 162. 29 168. 02 88 167. 744・60 16445 17L0339 166. 59 6. 20 1623 171.03 89 167. 408. 27 161. 49 173. 3240 165. 65 3. 56 163. 10 168. 20 90 167. 1S 6. 00 162. 89 171.4841 165. 72 4. 17 162.74 168.71 91 16643 3.87 163. 66 169,2142 166. 22 7. 44 1603 171.54 92 166. 62 4. 08 163. 70 169.5443 167.71 6. 12 163. 33 172. 09 93 166. 30 4.84 162. 83 169.7644 16725 5. 24 163. 50 170. 99 94 169. 70 5. 26 165. 94 1734545 165. 69 5.91 161.46 169. 92 95 169. 17 632 164. 65 173. 6946 169. 06 5. 65 165. 03 173. 10 96 167. 89 6. 07 163. 54 172. 2347 16&76 6. 14 16436 173. 15 97 167. 48 6. 03 163. 16 171.79 4S 16&64 4. 54 16539 171.89 98 169. 93 4.80 166. 50 173. 3749 167. 72 3. 82 164. 99 170. 45 99 16940 5. 57 16342 1733950 170. 39 4. 15 16742 173. 35 100 165. 69 5. 09 162, 06 16933*:表该样本资料算得的可信区间未包含已知总体均数167. 7cm例3 • 5某医生测量了36洛从事铅作业男性工人的血红蛋白含量,算得加均数为130. 83或L,标准差为25 - 74g/L.问从事铅作业工人的血红蛋白是否不同于正常成年男性平均值140gzL?⑴建立检验假设,确定检验水准Ho :严3=140g/L,即从事铅作业的男性工人平均血红蛋白含量与正常成年男性平均值H1: /岸MF140弓L 即从事铅作业的男性工人平均血红蛋白含量与正常成年男性平均值 不0=0. 05⑵讣算检验统il 嗤本例 «=36> 乂 =130 - 83g/L, 425 - 74g/L,“o=140g/L 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3-8假定人体尺寸有这样的一般规律,身高(X 1),胸围(X 2)和上半臂围(X 3)的平均尺寸比例是6:4:1,假设()()1,,X n αα=L 为来自总体()123=,,X X X X '的随机样本,并设()~,X N μ∑。
试利用表3.4中男婴这一数据来检验其身高、胸围和上半臂围这三个尺寸变量是否符合这一规律(写出假设H 0,并导出检验统计量)。
解:设32,~(,),~(,)Y CX X N Y N C C C μμ'=∑∑。
121231233106,,,,,014C X X X μμμμμμμ⎛⎫-⎛⎫ ⎪== ⎪⎪-⎝⎭ ⎪⎝⎭其中,分别为 的样本均值。
则检验三个变量是否符合规律的假设为0212:,:H C O H C O μμ=≠。
检验统计量为21(1)1~(1,1)(3,6)(1)(1)n p F T F p n p p n n p ---+=--+==--,由样本值计算得:=(82,60.2,14.5)X ',及15840.2 2.5=40.215.86 6.552.5 6.559.5A ⎛⎫ ⎪ ⎪ ⎪⎝⎭, 2-1(1)()()()=47.1434T n n CX CAC CX ''=-,221(1)12=18.8574(1)(1)5n p F T T n p ---+=⨯=--,对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值: p =P {F ≥18.8574}=0.0091948。
因为p 值=0.0091948<0.05,故否定0H ,即认为这组男婴数据与人类的一般规律不一致。
在这种情况下,可能犯第一类错误·且犯第一类错误的概率为0.05。
SAS 程序及结果如下:prociml ; n=6;p=3; x={7860.616.5, 7658.112.5, 9263.214.5, 815914, 8160.815.5, 8459.514 };m0={00,00}; c={10 -6,01 -4}; ln={[6]1}; x0=(ln*x)`/n; print x0;mm=i(6)-j(6,6,1)/n; a=x`*mm*x; a1=inv(c*a*c`); a2=c*x0; dd=a2`*a1*a2; d2=dd*(n-1); t2=n*d2;f=(n+1-p)*t2/((n-1)*(p-1)); print x0 a d2 t2 f; p0=1-probf(f,p-1,n-p+1); fa=finv(0.95,2,4); print p0; run ;3-11表3.4给出15名两周岁婴儿的身高(X 1),胸围(X 2)和上半臂围(X 3)的测量数据。
假设男婴的测量数据()()1,,6X αα=L 为来自总体()13,N μ∑()的随机样本;女婴的测量数据()()1,,9Y αα=L 为来自总体()3,N μ∑(2)的随机样本,试利用表3.4中的数据检验(1)(2)0:(0.05)H μμα==。
解:检验假设(1)(2)(1)(2)01::H H μμμμ=≠,。
取检验统计量为2+1(3,6,9)(2)n m p F Tp n m n m --====+-,由样本值计算得:=(82,60.2,14.5)=(7658.47613.5)X Y '',,,,1215840.2 2.5=40.215.86 6.552.5 6.559.519645.134.5=45.115.7611.6534.511.6514.5A A ⎛⎫ ⎪ ⎪ ⎪⎝⎭⎛⎫ ⎪ ⎪ ⎪⎝⎭,,进一步计算得:2112(2)()'()()=1.4754793D n m X Y A A X Y -=+--+-,225.3117256,nm T D n m==+ 21 1.498179(2)n m p F T n m p+--==+-。
对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值:p =P {F ≥1.498179}=0.2692616。
因为p 值=0.2692616>0.05,故接收0H ,即认为男婴和女婴的测量数据无显著性差异。
在这种情况下,可能犯第二类错误,且犯第二类错误的概率为=0.0268093β。
SAS 程序及结果如下:prociml ; n=6;m=9; p=3; x={ 7860.616.5 , 7658.112.5 , 9263.214.5 , 815914 , 8160.815.5 , 8459.514 } ; print x; ln={[6] 1} ;x0=(ln*x)/n; print x0; mx=i(n)-j(n,n,1)/n; a1=x`*mx*x; print a1; y={ 8058.414 , 7559.215 , 7860.315 , 7557.413 , 7959.514 , 7858.114.5 , 755812.5 , 6455.511 , 8059.212.5 } ;print y; lm={[9] 1} ; y0=(lm*y)/m; print y0; my=i(m)-j(m,m,1)/m; a2=y`*my*y; print a2; a=a1+a2; xy=x0-y0; ai=inv(a); print a ai; dd=xy*ai*xy`; d2=(m+n-2)*dd;t2=n*m*d2/(n+m) ;f=(n+m-1-p)*t2/((n+m-2)*p); fa=finv(0.95,p,m+n-p-1); beta=probf(f,p,m+n-p-1,t2); print d2 t2 f beta; pp=1-probf(f,p,m+n-p-1); print pp; quit ;3-12地质勘探中,在A,B,C 三个地区采集了一些岩石,测量其部分化学成分,其数据见表3.5。
假定这三个地区掩饰的成分遵从()3,(1,2,3)(0.05)i i N i μα∑==()。
(1)检验不全01231123:=:,,H H ∑=∑∑∑∑∑;不全等; (2)检验(1)(2)(1)(2)01::H H μμμμ=≠;;(3)检验(1)(2)(3)()()01::,i j H H i j μμμμμ==≠≠;存在使; (4)检验三种化学成分相互独立。
(1)检验假设01231123:=:,,H H ∑=∑∑∑∑∑;不全等,在H 0成立时,取近似检验统计量为2()f χ统计量:()()*4=121ln d M d ξλ-=--。
由样本值计算三个总体的样本协方差阵:1(1)(1)(1)(1)11()()11111110.243081=0.642649.2855240.014060.020520.00452n S A X X X X n n ααα='==----⎛⎫ ⎪- ⎪ ⎪⎝⎭∑()(), 1(2)(2)(2)(2)23()()12211116.30461= 4.756710.672230.05570.23880.006675n S A X X X X n n ααα='==----⎛⎫ ⎪- ⎪ ⎪-⎝⎭∑()(),1(3)(3)(3)(3)33()()13311112.97141=0.63370.342140.00010.002950.001875n S A X X X Xn n ααα='==----⎛⎫ ⎪ ⎪ ⎪-⎝⎭∑()()。
进一步计算可得12310.0018318,0.0000942,0.0011851,0.0000417,10S A S S S ===== 24.52397,0.433333,12,M d f ===(1)=13.896916d M ξ=-。
对给定显著性水平=0.05α,利用软件SAS9.3进行检验时,首先计算p 值:p =P {ξ≥13.896916}=0.3073394。
因为p 值=0.3073394>0.05,故接收0H ,即认为方差阵之间无显著性差异。
prociml ; n1=5;n2=4;n3=4; n=n1+n2+n3;k=3;p=3; x1={47.225.060.1, 47.454.350.15, 47.526.850.12, 47.864.19 0.17, 47.317.57 0.18};x2={54.336.220.12, 56.173.31 0.15, 54.42.43 0.22,52.625.92 0.12};x3={43.1210.330.05, 42.059.67 0.08, 42.59.620.02,40.779.68 0.04};xx=x1//x2//x3;/*三组样本纵向拼接*/ mm1=i(5)-j(5,5,1)/n1; mm2=i(4)-j(4,4,1)/n2; mm=i(n)-j(n,n,1)/n; a1=x1`*mm1*x1;print a1; a2=x2`*mm2*x2;print a2; a3=x3`*mm2*x3;print a3;tt=xx`*mm*xx;print tt;/*总离差阵*/ a=a1+a2+a3;print a;/*组离差阵*/ da=det(a/(n-k));/*合并样本协差阵*/da1=det(a1/(n1-1));/*每个总体的样本协差阵阵*/ da2=det(a2/(n2-1)); da3=det(a3/(n3-1));m=(n-k)*log(da)-(4*log(da1)+3*log(da2)+3*log(da3)); dd=(2*p*p+3*p-1)*(k+1)/(6*(p+1)*(n-k)); df=p*(p+1)*(k-1)/2;/*卡方分布自由度*/ kc=(1-dd)*m;/*统计量值*/ print da da1 da2 da3 m dd df; p0=1-probchi(kc,df);/*显著性概率*/ print kc p0; quit ;(2)提出假设(1)(2)(1)(2)01::H H μμμμ=≠,。
取检验统计量为2+1(3,6,9)(2)n m p F Tp n m n m --====+-,由样本值计算得:1=(47.472.5.604,0.144)=(54.38,4.47,0.1525)X X ''()(2),,120.24308=0.642649.285520.014060.020520.004526.3046= 4.756710.67220.05570.23880.006675A A ⎛⎫⎪- ⎪ ⎪⎝⎭⎛⎫⎪- ⎪ ⎪-⎝⎭,,进一步计算得:211112(2)()'()()=60.666995D n m X X A A X X -=+--+-()(2)()(2),22134.81554,nm T D n m==+ 2132.098939(2)n m p F T n m p+--==+-。