出行分布预测(第五章)
4 四步骤交通需求预测模型(2.1)出行分布预测

步 3:设 f(Fgi,Faj) 为增长函数,计算第(k+1)次预测值: qij
k 1
k 1 步 4:检验预测结果:计算新的产生量和吸引量 Pi k 1 qij ,
F
k 1 pi
P ki1 , Pi
F
k 1 aj
Aj
j
1 Ak j
2 出行分布预测
3 增长函数法 (3)平均增长率法 A. 方法原理:该方法认为qij的增长与i区产生量 的增长及j分区吸引量的增长同时相关,而且相关 的程度也相同,增长函数为 1 1 Fpi Fai f 平 F pi,Faj f 平 F Fai Fpi pi, aj 2 2 B. 特点评价:
该法比常增长率法合理,是一种最常用的方法
在实际运用时,因迭代步数较多,计算速度稍慢
2 出行分布预测
3 增长函数法
(4)底特律法(Detroit) A. 方法原理:此法认为,qij的增长与i分区产生 量增长率成正比,而且还与j分区吸引量增长率与 整个区域吸引量增长率的相对比率成正比
B. 特点评价:
A j A0 Pi j f D Fpi,Faj Fpi Q Q 0 Pi 0 A j A0 j Faj
2 出行分布预测
1 基本概念 (1)出行分布量 [例题]:分析两个交通小区i,j之间的出行分布 量
home factory home 小区i 5 6 小区j 1 2 3 4 factory home factory
qij=4 qji=2
2 出行分布预测
1 基本概念 (2)出行分布矩阵(PA矩阵)
0 0 0 q1 q (F F 13 13 p1 a3 ) / 2 4.0 (1.3786 1.3667) / 2 5.490
chapter5 Trip Generation
7.67%
12.99% 23.32% 21.64% 6.67% 14.84% 100.00%
2.52
2.9 2.96 3.05 2.97 2.6 2.81
18
比较两个年份的调查结果,可以看出,
2000年北京市居民出行率较1986年有了较 大程度的提高,不同性别的出行率也是如 此,并且具有明显的向高龄化发展的趋势
10
1、土地利用
①住宅用地是交通的主要发生源和居民出行的主
要起讫点。该用地的发生与吸引交通量通常用居 住面积、住户数、人口、住户平均人数等指标表 示。与住宅用地相关的出行有:上班、上学、自 由(购物、娱乐)、回家。 ②公共设施用地包括行政办公用地、商业金融业 用地、文化娱乐用地、体育用地、医疗卫生用地、 教育科研设计用地、文物古迹用地等。当然,也 是交通的主要发生源之一。该用地的发生与吸引 交通量通常用办公、营业面积、从业人口等指标 表示。与公共设施用地相关的出行有:上班、上 学、自由(娱乐)、业务、回家。
情况。可以看出,60岁以后的人群由于大多已经退休, 自由时间比较多,从而仍保持着较高的出行率。
24
司机、推销、市场开拓人员出行多,教师、
学生出行少
职业 工人 科技人员
六、职业和工种
人数
数量 28774 6106
出行量
% 数量 83261 18005 % 17.59% 3.80%
出行次数/日 2.89 2.95
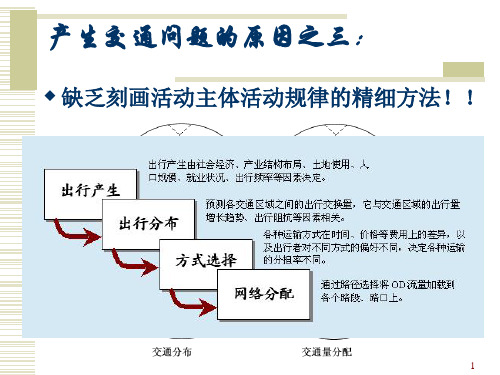
出行的发生与吸引是指研究对象区域内各交通小区的 交通发生与吸引量,它们与土地利用和设施有着密切 的关系。 发生与吸引交通量预测精度的高低将直接影响以后阶 段乃至整个预测过程的精度,因此精确地预测出行的 发生与吸引交通量,对交通规划工作是非常必要和重 要的。
出行分布预测

第五章出行分布预测§5.1 概念从出行发生预测可以得知对象区域各个分区出行产生量和出行吸引量。
下面的问题是:就某个分区而言,它所产生的这些出行量究竟到那个分区去了?它所吸引的这些出行量又究竟来自哪里?也就是要预测未来规划年各个分区之间出行的交换量。
我们把分区之间的出行的交换量叫做“出行分布量”,本章就来研究出行分布量的预测问题。
5.1.1 出行分布量出行分布量是指:分区i 与分区j 之间平均单位时间内的出行量,单位时间可以是一天、一周、一月等,也可以是专指高峰小时。
就一对分区i 和j 而言,它由两部分q ij 、q ji 组成:q ij ——以分区i 为产生点(注:不一定是出行的起点),以分区j 为吸引点(不一定是出行的终点)的出行量。
q ji ——以分区j 为产生点,分区i 为吸引点的出行量。
如同一个分区的产生量不一定等于吸引量一样,q ij 不一定等于q ji 。
从下面的例子可以看出这一点。
例5-1 如图5-1所示的两分区之间的六次出行中;q ij =4(出行1、2、5、6)q ji =2(出行3、4)但以i 为起点的出行数=3(出行1、4、5);以j 为起点的出行数=3(出行2、3、6)。
5.1.2 出行分布矩阵(PA 矩阵)出行分布矩阵是一个二维表(矩阵),行坐标为吸引分区号(Absorbing zone ),列坐标为产生分区号(Producing zone ),元素为出行分区量。
如表5-1所示,表5-1中的行数和列数相等。
从理论的严格意义上讲,产生区和吸引区不一定相同,甚至某些分区只是产生区,但不吸引任何出行,因而不是吸引区,如纯住宅区,也可能有某些分区只是吸图例:h —家庭;s —学校;f —工厂图5-1 (例5-1)两个分区间的六次出行引区,但不是产生区。
但是,实际中,绝大多数分区既是产生区又是吸引区,为了叙述简便起见,我们一般假定产生区和吸引区数相同,用n 表示。
但在后面也给出两者不相同的实例(例5-5)。
5-重力模型法

束,则可得到双约束重力模型(过程略):
( ) qij = ai ⋅ bj ⋅ Oi ⋅ Dj ⋅ f cij
∑ ( )
−1
ai
=
j
bj ⋅ Dj ⋅ f
cij
∑ ( )
−1
bj = i ai ⋅ Oi ⋅ f cij
双约束重力模型可以同时满足行列约束条件,是目前使
用较多的一种重力模型。
表1 现状OD矩阵及未来发生、吸引量
1 2 3 Oi` Oi 1 4 2 2 8 16
2 2 8 4 14 28
3 2 4 4 10 40
Dj` 8 14 10 32
Dj 16 28 40
84
表2 各区之间的行程时间
123 1244 2412 3422
美国联邦公路局重力模型
模型形式为:
∑ ( ( ) ) qij = Oi ⋅
5.5 重力模型的优缺点
优点:
模型形式直观,可解释性强,易被规划人员理解和 接 受; 能比较敏感地反映交通设施变化对出行的影响,适 用于中长期需求预测; 不需要完整的基年OD矩阵,如果有可信赖的模型参 数,甚至不需要基年OD矩阵; 特定交通小区(如新开发区)之间的分布量为零时, 也能进行预测。 能比较敏感地反映交通小区之间行驶时间变化的情况。
双约束重力模型的标定
双约束重力模型中的ai与bj是在计算过程中产生的,不是固 定的参数,因而对于双约束重力模型只有阻抗函数中的参数需 要标定。在取指数型阻抗函数时,需要标定的就是参数β。
如果参数β的取值能使得由重力模型计算结果中得到的出行
长度分布,与实际调查得到的出行长度分布最大程度地吻合, 则该值就作为模型参数标定的最优值。因此重力模型的标定问 题就转化为一个方程求根的问题。可以用牛顿法等数值方法求
第5章 交通分布模型——【吉林大学 运输系统规划与设计】

利用已有的出行矩阵,估计未来的出行情况。
一.统一增长系数法
已知总体增长率: Tij tij
Tt
对于 i, j 对
例题:已知4×4基 年出行矩阵,三年 后交通增长20%, 将t i j乘以1.2,得未 来出行矩阵。
第二节 增长系数法
一.统一增长系数法
特点:预测不真实,适合于很短时间的预测。
t
t ij
在车站的等候时间;
t nij 换车时间;
Fij 从i —> j 的旅行费用;
ij 从i —> j 的有关终点费用(停车);
所有与出行费用有关但没包含在内的属性参数(安全、舒适性、便利性等)
1,2 6 权重系数。以合适的量纲将所有属性转变为一个共同的
单位。(时间、金钱)
第二节 增长系数法
二. 注释
Tij D j每一列的和是该列出行节点的出行吸引总数
i
广义费用:可以用时间、距离、金钱表示。
某种交通方式的费用表示为:
Cij
1tivj
tw
2 ij
3titj
4tnij
5Fij
6 ij
Cij 从i —> j 的总费用(时间);
t
v ij
从i
—>
j
在车内的旅行时间;
t
w ij
到站点的步行时间;
1.弗尼斯法(Furness)
第二节 增长系数法
三.双约束增长系数法
迭 代 过 程 如 左
第二节 增长系数法
三.双约束增长系数法
例题:用Furness法求解表中出行矩阵,经过行、 列的三次迭代(共6次计算)得结果。
用佛尼斯法求解双约束出行矩阵过程如下:
第5讲 出行生成预测(30分钟)吴

X Zx
式中
Zx
X ——平均出行生成率;
——样本平均值的标准差; ——随要求可行度水平而变的系数。
第五讲 出行生成预测
标准差 公式为:
为以少数样本推算总体时产生的误差值,起计算
x
x
n
N n N
——住户出行生成率的样本标准差; n ——抽样数; N ——全体住户数。 在可靠区间 X Z 中 Zx 称为误差边界(d),则:
(1)有关各种家庭横向分类。澳大利亚根据其中西部的交通调查,规定 家庭大小与结构分为六类;家庭收入分六类及家庭拥有小车数分为三 类。我国的情况与其差别较大,应根据我国的实际情况进行分类。我 国可以考虑以住宅类型、家庭人口及家庭拥有自行车数作为分类项目 的出行产生模型。 (2)把每个家庭定位到相应的横向类别。就是对家庭房为调查资料进行 分类,把每个家庭都归入其可能类别的某一相应位置中。如澳大利亚 中西部地区可归入108(6*6*3)种的相应类别中。
第五讲 出行生成预测
西方国家的经验证明:有三个土地使用变量(小汽车
拥有量、家庭大小和家庭收入)影响家庭出行生成。根据 这些变量把家庭横向分类,并且由家庭访问调查资料计算 每一类的平均出行生成率。然后按下列步骤用此种模型计 算分区出行量: (1)用位于该区的各种类别的家庭数乘以相应类别的 平均出行率; (2)总计每种家庭类别的出行量。
无
1辆 ≥2辆
5.8a
7.2b
8.1a
11.8b
10.0a
12.9b
第五讲 出行生成预测
则我们可以从18个横向分类中找到这四类家庭相应的出行
产生率数字。所以此分区每日产生的出行数为:
(100×3.4)+(200 × 4.9)+(300 × 8.3)+(50 × 12.9)=4455次出行。
交通规划 第五章 交通分布
j
i
三、交通分布预测方法
根据各交通小区未来年份产生量、吸引量以及现 状OD矩阵求解未来OD矩阵; (增长系数法)
用未来年份产生量、吸引量以及交通区之间的交 通阻抗矩阵求解未来OD矩阵; (重力模型法)
根据出行产生、吸引量、交通区间阻抗、各小区 吸引概率,求解未来OD矩阵; (介入机会法)
根据交通小区划分和路段交通流量,反推交通小
作用 解决:预测每个交通小区的产生量去向 何方?吸引量来自哪里?政策依据。
tij
i
j
二、出行分布矩阵特性
出行分布矩阵的行数与列数一般相同,如 果行数与列数不相同,即m*n形式,属于 Hitchcock问题。
矩阵单元格:tij为以i小区为产生点以j小区 为吸引点的出行量。
矩阵的行表示产生,列表示吸引。矩阵的 行和表示产生量,列和表示吸引量。
差 大
FO13 U 3 / O3 36 / 33.074 1.0885
于
FD11 V1 / D1 39.3 / 36.8 1.0676
FD12 V2 / D2 90.3 / 96.9 0.9323
FD13 V3 / D3 36.9 / 34.4 1.074
T/X=1.01
3%
结
3
4.9 7.9 20.3 33.1 36.0
果
总计 36.8 96.9 34.4 168.1
未来 V 39.3 90.3 36.9
166 .5
(2)重新计算FO和FD、T/X
FO11 U1 / O1 38.6 / 36.5 1.0579
误
FO12 U 2 / O2 91.9 / 98.5 0.9333
2
7.0 38.0 6.0 51.0 91.9
完整word版,交通出行分布预测
交通出行分布预测作业二零一五年六月九号1. 分别采用平均增长率法、Fratar法对5月20日的OD调查表进行交通出行分布预测。
解:(1)现状OD表的绘制及未来出行发生/吸引量的预测1)考虑到实际调查中可能出现的偏差,现对5月20日和6月1日调查的原始数据进行如下规则的处理:1. 若不同站点统计人数有所偏差,以韵苑、喻园以及南大门询问统计的人数为准;2. 在不违背现有站点已统计总数的前提下,各个站点现有交通产生量/吸引量即为各站点统计的下车人数/上车人数;3. 各站点之间的交通量按照上/下行车站点顺序,对其上/下车人数进行推算(如:从喻园到集贸的交通量因其之间只隔1段,故为喻园车的下车人数);4. 其他未统计站点按照实际情况合理补充和调整;5. 由于第一次未安排喻园站的统计,故两次统计结果偏差较大;6. 因统计结果不全,且实际该时段东九的交通量可忽略不计,故不考虑该站的上/下车人数。
2)在测算设定未来发生量和吸引量时,参照如下依据:1. 根据近几年华科招生人数变化以及工科专业人数比例(考虑到工科专业的实验及大学物理等要搭乘校车的课程)。
网上显示,2015年预计招生7180人,虽比2014年的7300人少,但考虑到有3个新增的工科专业以及未来校区总人数的增长,故对各个站点下午上课时段的交通量影响不大,且预计会有少量增加;2. 对于现状站点交通量为0的站点,为方便计算,可将其增长忽略不计,即仍视为0;3. 由于集贸以及绝望坡的餐饮业发展,预计人流量会有相对较大的增长;4. 考虑到人们出行需求的增长,南大门站作为从学校到光谷的出口,交通量增长相对较大。
最终结果整理如下表(答案不唯一):(2)根据第一次的OD 表,用平均增长率法进行交通出行分布预测。
1) 数学原理平均增长率法属于增长率法,其原理可表示为:未来分布=现状分布*增长系数。
假设站点i 和j 之间的现状交通量为t ij (0),i 站点现状的产生交通量为G i (0),未来的产生交通量为G i ,站点j 现状的产生交通量为A i (0),未来的产生交通量为A i ,增长率计算过程:1. 计算未来交通量第一次近似值:t ij (1)=t ij (0)f2. 得到第1次预测各小区的发生交通量和吸引交通量:G i(0)=∑t ij (1)jA i(0)=∑t ij (1)i3. 计算调整系数:αi =G i (0)G i(1)βi =A j(0)A j(1)4. 若两个调整系数均收敛到1左右,则停止计算,相应的t ij (1)即为所求的分布;否则迭代。
四步骤交通需求预测模型出行分布预测优秀课件
rm
ij m
m
2 出行分布预测
2.4 简单引力模型法 (4)模型讨论
B. 交通阻抗
阻抗函数的选用: 实际选用哪种类型的阻抗函数要视具体情况决定 可以先用一些调查数据在坐标系上标出散点图, 看其与哪类函数的曲线吻合程度较好,然后决定 选用哪类阻抗函数
2 出行分布预测 2.4 简单引力模型法 (5)[例题]:已知3个交通小区的现状PA表、规划年 各小区的产生量和吸引量以及现状和规划年的各 小区间的出行时间,试用无约束引力模型法求解 规划年PA矩阵。
88.862
q 21
0.124
(91.9 39.3)1.173 9.01.445
75.542
q12
0.124
(38.6 90.3)1.173 9.01.445
72.458
q 22
0.124
(91.9 90.3)1.173 8.01.445
237.912
q13
0.124
(38.6 36.9)1.173 11.01.445
现状PA
2 出行分布预测
2.4 简单引力模型法
(5)[例题]:已知3个交通小区的现状PA表、规划年 各小区的产生量和吸引量以及现状和规划年的各
小区间的出行时间,试用无约束引力模型法求解
规划年PA矩阵。
现
将
状
来
行
行
驶
驶
时
时
间
间
2 出行分布预测
2.4 简单引力模型法
(5)[例题]:
1)用以下无约束引力模型进行求解
Y=lnqij, X=(1, X1, X2, X3)=(1, lnPi, lnAj, lnRij)
b0=lnK, b1=α, b2=β, b3= -γ
第五章交通发生与吸引
1.00 0.50 0.00
à ° à ° § Ñ · Å § Ñ Ò ¼ î » Ì ³ Ø » Ï É Â Ï Ï É Ø » ú É Ö À ö ³ Ó é ¯ » ¤ ¹ Ä Î ÷ × â Í ä Æ ü Ë
1. 原单位法
预测不同出行目的的生成交通量 :
T ( a N s )
m s m s
• 工厂、机关、商业中心等也是重要的交通 生成源。衡量其对交通产生的影响的最一 般的指标有单位面积的工作人员人数、占 用的土地面积等。
• 与交通生成相关的其它的土地利用用途还 有很多,可根据具体的规划的要求进行分 析。
家庭规模和人口构成
• 家庭是构成人们出行的基础,上班、自由 多以家庭为出发点。
平 均 出 行 次 数 男 ( )
2.50 2.00 1.50
1.12 1.87 1.94 1.75 1.66 2.07 2.04 1.95 1.78 1.72 1.60 1.37 1.09 0.70
1.00 0.50 0.00
2.00
平 均 出 行 次 数 女
1.80 1.60 1.40 1.20 1.00 0.80 0.60 0.40 0.20 0.00
平均出行次数
不同职业人员日平均出行次数(长春市97年居民调查结果)
单位公房
• 与工作单位同在一处或相距很近的单位宿 舍或住宅,其居住者的出行次数明显 减少
其它
• 劳动时间、商店销售额、工厂总产量、城 市的特点等许多因素也被考虑作为影响交 通产生的因素。 • 天气、工作日、休息日和季节等的不同也 影响人们的出行。
第五章 出行的发生与吸引
第一节 概述
第二节
第三节
发生与吸引交通量的影响因素
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
21
二、预测方法
[例题5] D.第1次迭代计算结果
A P
1 20.744 11.165 4.902 36.811
2 10.991 77.987 7.885 96.862
3 4.753 9.318 20.287 34.358
合计 36.478 98.470 33.074 168.031
1 2 3 合计
1 0 q32 q32 Fp03 Fa02 /(Q / Q 0 ) 5.0 1.3846 1.8060 / 1.5857 7.885
1 0 q33 q33 Fp03 Fa03 /(Q / Q 0 ) 17.0 1.3846 1.3667 / 1.5857 20.287
0 0 0 q1 q ( F F 23 23 p2 a 3 ) / 2 6.0 (1.8020 1.3667 ) / 2 9.506
1 0 q31 q31 ( Fp03 Fa0 1 ) / 2 4.0 (1.3846 1.4036 ) / 2 5.576
0 0 0 0 q1 q F F /( Q / Q ) 6.0 1.8020 1.3667 / 1.5857 9.318 23 23 p2 a3
1 0 0 q31 q31 Fp03 Fa0 /( Q / Q ) 4.0 1.3846 1.4036 / 1.5857 4.902 1
j j
B.特点评价:该方法是在底特律市1956年规划首次被开发 利用,收敛速度较快;等效于使用现状出行分布表的同时 概率最大化方法理论求解结果。
17
二、预测方法
[例题5]:已知3个交通小区的现状PA表和规划年各小区的产生 量和吸引量,试用底特律法求解规划年PA矩阵。设定收敛标 准为3% 。
现状PA
20
二、预测方法
[例题5]
0 0 0 0 q1 q F F /( Q / Q ) 7.0 1.8020 1.4036 / 1.5857 11.165 21 21 p2 a1
0 0 0 0 q1 22 q 22 Fp 2 Fa 2 /(Q / Q ) 38 .0 1.8020 1.8060 / 1.5857 77 .987
9
二、预测方法
2、增长率法 2.1增长函数法 (3)平均增长率法 A.方法原理:该方法认为qij的增长与i区产生量的增长及j分 区吸引量的增长同时相关,而且相关的程度也相同,增长函 数为:
1 f ( Fpi , Faj ) ( Fpi Faj ) 2
B.特点评价:该法比常增长率法合理,是一种最常用的方 法。在实际运用时,因迭代步数较多,计算速度稍慢。
2、增长率法 2.1增长函数法 (1)总体思路:
8
二、预测方法
2、增长率法 2.1增长函数法 (2)常增长率法 A.方法原理:该方法认为qij的增长仅与i区的产生量增长率 有关,增长函数为.特点评价:只单方面考虑产生量增长率对增长函数的影响, 忽视了吸引量增长率的影响。由于产生量与吸引量的不对称性, 该方法的预测精度不高,是一种最粗糙的方法。
1 0 q12 q12 Fp01 Fa02 /(Q / Q 0 ) 7.0 1.3786 1.8060 / 1.5857 10.991
1 0 q13 q13 Fp01 Fa03 /(Q / Q 0 ) 4.0 1.3786 1.3667 / 1.5857 4.753
《交通规划》
四阶段模型——出行分布预测
蒋阳升 教授
2011~2012年第二学期
西南交通大学交通运输与物流学院 交通工程专业
1
一、基本概念
1、出行分布量 出行分布量是指分区i与分区j之间平均单位时间内的出行量。 单位时间可以是一天、一周、一月等,也可以是专指高峰小时 。 qij——以分区i为产生点(不一定是出行的起点),以分区j为吸引点 (不一定是出行的终点)的出行量。 qji——以分区j为产生点,分区i为吸引点的出行量。
0 a1
A1 0 A1
39.3 1.4036 28.0
,
F
0 p2
P2 P20
91.9 1.8020 51.0
36.0 1.3846 26.0
Fa02
F
0 a3
A2 0 A2
90.3 1.8060 50.0
F
0 p3
P 3 0 P 3
A3 0 A3
36.9 1.3667 27.0
15
二、预测方法
, 。
[例题4] D.重新计算增长系数,k=0,
k 1 Fpi Pi Pi k 1
k 1 Faj Aj
1 Ak j
,
1 Fp 1
P 1 1 P 1
38.6 0.9582 40.285
Fa11
A1 1 A1
39.3 0.9717 40.444
,
F
2
一、基本概念
[例题3]:分析两个交通小区i,j之间的出行分布量
则:qij=4,qji=2。
3
一、基本概念
2、出行分布矩阵(PA矩阵) 出行分布矩阵是一个二维表(矩阵),行坐标为吸引分区号 ,列坐标为产生分区号,元素为出行分布量。(如下表所示)。 需要注意的是,早期的分布矩阵用的是OD矩阵,这与PA矩阵是不 同的,而准确的分布矩阵应该简记为PA矩阵。
1 0 q12 q12 ( Fp01 Fa02 ) / 2 7.0 (1.3786 1.8060 ) / 2 11.146 1 0 q13 q13 ( Fp01 Fa03 ) / 2 4.0 (1.3786 1.3667 ) / 2 5.490
[例题5] 求解过程:
,
A j / A0 Pi j f D ( Fpi , Faj ) Fpi Q / Q 0 Pi 0 A j / A0 j Faj
j j
A.求各小区产生量和吸引量的增长率,k=0。
,
Fp01
P 1 0 P 1
38.6 1.3786 28.0
F
Pi qij
,
j
A j qij
i
j i j j i
Q Pi A j qij qij
i
式中,(i,j=1, … ,n)
5
二、预测方法
1、预测方法种类
我们通过交通调查资料的分析和预测,可以找到和利用的数
据有:现状PA表,两个分区之间的交通阻抗矩阵。至今开发的出 行分布预测方法有:增长率法、引力模型法、机会模型法等。我 们详细介绍前面两种,第三种因为理论依据不足且难以实用,不 做详细介绍。预测方法的大体结构如下所示:
A P
1 17.0 7.0 4.0 28.0
1
2
3
合计 38.6 91.9 36.0
1 2 3 合计
1 2 3 合计 39.3 90.3 36.9
166.5
11
二、预测方法
[例题4]
,
求解过程: A.求各小区产生量和吸引量的增长率,k=0
Fp01
,
P 1 0 P 1
38.6 1.3786 28.0
14
二、预测方法
[例题4]
C.第1次迭代计算结果
A P
1 23.648 11.219 5.576 40.444
2 11.146 68.551 7.977 87.674
3 5.490 9.506 23.386 38.382
合计 40.285 89.277 36.939 166.500
1 2 3 合计
22
二、预测方法
,
[例题5]
。
E.重新计算增长系数,k=0 ,
F
,
k 1 pi
Pi Pi k 1
F
k 1 aj
A1 1 A1
Aj
1 Ak j
1 Fp 1
P 1 1 P 1
38.6 1.0579 Fa11 36.487
Fa12 Fa13
39.3 1.0676 36.811
1 0 q32 q32 ( Fp03 Fa02 ) / 2 5.0 (1.3846 1.8060 ) / 2 7.977
1 0 q33 q33 ( Fp03 Fa03 ) / 2 17.0 (1.3846 1.3667 ) / 2 23.386
A
P
1 q11 q21 …
2 q12 q22 …
… … … …
n q1n q2n …
小计 P1 P2 …
1 2 …
n
小计
qn1
A1
qn2
A2
…
…
qnn
An
Pn
Q
4
一、基本概念
2、出行分布矩阵(PA矩阵)
假定第一标号i为产生小区,第二标号j为吸引小区,产生量Pi 、吸引量Aj 、分布量qij、出行总量Q关系为:
6
二、预测方法
1、预测方法种类
(1)增长率法 增长函数法 法 Fueness
常增长率法 平均增长率法 底特律法 Frator法
(2)引力模型法
简单引力模型法 单约束引力模型法 双约束引力模型法
(3)机会模型法
7
二、预测方法
16
二、预测方法
2、增长率法 2.1增长函数法 (4)底特律法 A.方法原理:此法认为交通分布量的增长与i分区产生量增 长率成正比,而且还与j分区吸引量增长率与整个区域吸引量 增长率的相对比率成正比:
f D ( Fpi , Faj ) Fpi Faj Q / Q0 A j / A0 Pi j 0 Pi A j A0 j