Hadoop集群部署有几种模式?Hadoop集群部署方法介绍
分布式集群HA模式部署
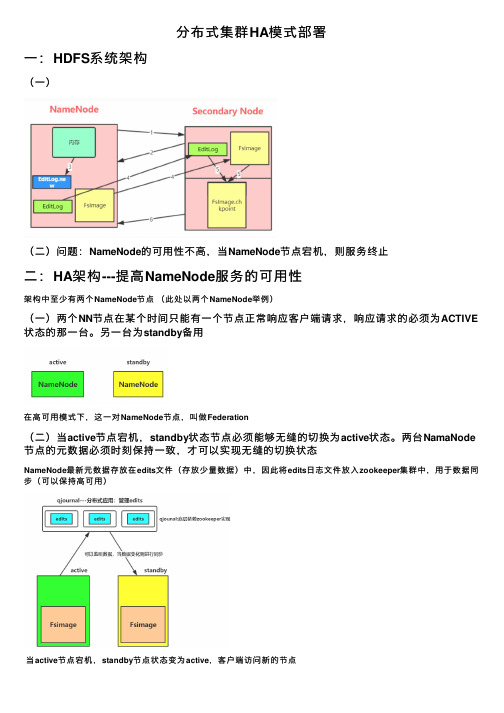
分布式集群HA模式部署⼀:HDFS系统架构(⼀)(⼆)问题:NameNode的可⽤性不⾼,当NameNode节点宕机,则服务终⽌⼆:HA架构---提⾼NameNode服务的可⽤性架构中⾄少有两个NameNode节点(此处以两个NameNode举例)(⼀)两个NN节点在某个时间只能有⼀个节点正常响应客户端请求,响应请求的必须为ACTIVE 状态的那⼀台。
另⼀台为standby备⽤在⾼可⽤模式下,这⼀对NameNode节点,叫做Federation(⼆)当active节点宕机,standby状态节点必须能够⽆缝的切换为active状态。
两台NamaNode 节点的元数据必须时刻保持⼀致,才可以实现⽆缝的切换状态NameNode最新元数据存放在edits⽂件(存放少量数据)中,因此将edits⽇志⽂件放⼊zookeeper集群中,⽤于数据同步(可以保持⾼可⽤)当active节点宕机,standby节点状态变为active,客户端访问新的节点(三)两个NameNode节点之间如何检测状态变化⽅法1:NameNode在zookeeper中注册各⾃状态(可以使⽤短暂连接,若某节点宕机,则数据销毁)⽅法2:将1中NameNode节点功能独⽴出来,在节点所在机器中启动监控进程,⽤于监控NameNode状态,并写⼊和监控zookeeper数据(四)避免状态切换出现brain split现象---fencing机制当active节点出现故障,则standby会切换状态为active。
但是如果原始节点出现的是短暂故障,在⼀段时间后恢复,则出现两台active机器(出现写edits⽂件不⼀致)解决⽅法:使ZKFC进程功能增加,当standby NameNode中ZKFC检测检测到原active NameNode节点⼯作不正常,会先进⾏下⾯的⼯作:⽅法1:standby使⽤ssh 原始active节点 kill -9 namenode进程 即使⽤ssh远程杀死对⽅active节点(会返回⼀个结果信息),⽅法1中需要使⽤⽹络通信,可能在通信中出现故障。
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
Hadoop - 介绍

Clint
NameNode
Second NameNode
Namespace backup
Heartbeats,balancing,replication etc
DataNode
Data serving
DataNode
DataNode
DataNode
DataNode
Google 云计算
MapReduce BigTable Chubby
GFS
Hadoop可以做什么?
案例1:我想知道过去100年中每年的最高温 度分别是多少?
这是一个非常典型的代表,该问题里边包含了大量的信息数据。
针对于气象数据来说,全球会有非常多的数据采集点,每个采 集点在24小时中会以不同的频率进行采样,并且以每年持续365 天这样的过程,一直要收集 100年的数据信息。然后在这 100年 的所有数据中,抽取出每年最高的温度值,最终生成结果。该 过程会伴随着大量的数据分析工作,并且会有大量的半结构化 数据作为基础研究对象。如果使用高配大型主机( Unix环境) 计算,完成时间是以几十分钟或小时为单位的数量级,而通过 Hadoop完成,在合理的节点和架构下,只需要“秒”级。
HIVE
ODBC Command Line JDBC Thrift Server Metastore Driver (Compiler,Optimizer,Executor ) Hive 包括
元数据存储(Metastore) 驱动(Driver)
查询编译器(Query Compiler)
1. HDFS(Hadoop分布式文件系统)
HDFS:源自于Google的GFS论文,发表于2003年10月, HDFS是GFS克隆版。是Hadoop体系中数据存储管理的 基础。它是一个高度容错的系统,能检测和应对硬件 故障,用于在低成本的通用硬件上运行。HDFS简化 了文件的一致性模型,通过流式数据访问,提供高吞 吐量应用程序数据访问功能,适合带有大型数据集的 应用程序。 Client:切分文件;访问HDFS;与NameNode交互, 获取文件位置信息;与DataNode交互,读取和写入数 据。 NameNode:Master节点,在hadoop1.X中只有一个, 管理HDFS的名称空间和数据块映射信息,配置副本 策略,处理客户端请求。 DataNode:Slave节点,存储实际的数据,汇报存储信 息给NameNode。 Secondary NameNode:辅助NameNode,分担其工作 量;定期合并fsimage和fsedits,推送给NameNode;紧 急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
Hadoop集群的三种方式

Hadoop集群的三种⽅式1,Local(Standalone) Mode 单机模式$ mkdir input$ cp etc/hadoop/*.xml input$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'$ cat output/*解析$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'input 夹下⾯的⽂件:capacity-scheduler.xml core-site.xml hadoop-policy.xml hdfs-site.xml httpfs-site.xml yarn-site.xml bin/hadoop hadoop 命令jar 这个命令在jar包⾥⾯share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar 具体位置grep grep 函数input grep 函数的⽬标⽂件夹output grep 函数结果的输出⽂件夹'dfs[a-z.]+' grep 函数的匹配正则条件直译:将input⽂件下⾯的⽂件中包含 'dfs[a-z.]+' 的字符串给输出到output ⽂件夹中输出结果:part-r-00000 _SUCCESScat part-r-00000:1 dfsadmin在hadoop-policy.xml 存在此字符串2,Pseudo-Distributed Operation 伪分布式在 etc/hadoop/core.site.xml 添加以下属性<configuration><property><name>fs.defaultFS</name><value>hdfs://:8020</value> 是主机名,已经和ip相互映射</property>还需要覆盖默认的设定,mkdir -p data/tmp<property><name>hadoop.tmp.dir</name><value>/opt/modules/hadoop-2.5.0/data/tmp</value> 是主机名,已经和ip相互映射</property>垃圾箱设置删除⽂件保留时间(分钟)<property><name>fs.trash.interval</name><value>10080</value></property></configuration>etc/hadoop/hdfs-site.xml: 伪分布式1个备份<configuration><property><name>dfs.replication</name><value>1</value></property>配置从节点<property><name>node.secondary.http-address</name><value>主机名:50090</value></property></configuration>格式化元数据,进⼊到安装⽬录下bin/hdfs namenode -format启动namenode,所有的命令都在sbin下,通过ls sbin/ 可以查看sbin/hadoop-daemon.sh start namenode hadoop 的守护线程启动(主数据)sbin/hadoop-daemon.sh start datanode 启动datanode(从数据)nameNode都有个web⽹页,端⼝50070创建hdfs ⽂件夹,创建在⽤户名下⾯bin/hdfs dfs -mkdir -p /user/chris查看⽂件夹bin/hdfs dfs -ls -R / 回调查询本地新建⽂件夹mkdir wcinput mkdir wcoutput vi wc.input创建wc.input⽂件,并写⼊内容hdfs⽂件系统新建⽂件夹bin/hdfs dfs -mkdir -p /user/chris/mapreduce/wordcount/input本地⽂件上传hdfs⽂件系统bin/hdfs dfs -put wcinput/wc.input /user/chris/mapreduce/wordcount/input/在hdfs⽂件系统上使⽤mapreduce$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/chris/mapreduce/wordcount/input /user/chris/mapreduce/wordcount/output红⾊代表:读取路径蓝⾊代表:输出路径所以mapreduce的结果已经写到了hdfs的输出⽂件⾥⾯去了Yarn on a Single Node/opt/modules/hadoop-2.5.0/etc/hadoop/yarn-site.xml 在hadoop的安装路径下<configuration><property><name>yarn.resourcemanager.hostname</name><value></value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>yarn 的配置已经完成在同⼀⽬录下slave⽂件上添加主机名或者主机ip,默认是localhostyarn-env.sh 和 mapred-env.sh把JAVA_HOME 更改下,防⽌出错export JAVA_HOME=/home/chris/software/jdk1.8.0_201将mapred-site.xml.template 重命名为mapred-site.xml,同时添加以下配置<configuration><property><name></name><value>yarn</name></property></configuration>先将/user/chris/mapreduce/wordcount/output/删除再次执⾏$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jarwordcount /user/chris/mapreduce/wordcount/input /user/chris/mapreduce/wordcount/output伪分布式执⾏完毕,mapreduce 执⾏在了yarn 上3,完全分布式基于伪分布式,配置好⼀台机器后,分发⾄其它机器step1: 配置ip 和 hostname 映射vi /etc/hosts192.168.178.110 hella-hadoop192.168.178.111 hella-hadoop02192.168.178.112 hella-hadoop03同时在window以下路径也得设置C:\Windows\System32\drivers\etc\hosts192.168.178.110 hella-hadoop192.168.178.111 hella-hadoop02192.168.178.112 hella-hadoop03具体可参考linux ip hostname 映射step2:部署(假设三台机器)不同机器配置不同的节点部署:hella-hadoop hella-hadoop02 hella-hadoop03HDFS:NameNodeDataNode DataNode DataNodeSecondaryNameNodeYARN:ResourceManagerNodeManager NodeManager NodeManager MapReduce:JobHistoryServer配置:* hdfshadoop-env.shcore.site.xmlhdfs-site.xmlslaves*yarnyarn-env.shyarn-site.xmlslaves*mapreducemapred-env.shmapred-site.xmlstep3:修改配置⽂件core.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://:8020</value></property><property><name>hadoop.tmp.dir</name><value>/opt/app/hadoop-2.5.0/data/tmp</value></property><property><name>fs.trash.interval</name><value>10080</value></property></configuration>hdfs-site.xml<configuration><property><name>node.secondary.http-address</name><value>:50090</value></property></configuration>slavesyarn-site.xml<configuration><property><name>yarn.resourcemanager.hostname</name><value></value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--NodeManager Resouce --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation-retain-seconds</name><value>640800</value></property></configuration>mapred-site.xml<configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>:19888</value></property></configurationstep4:集群的配置路径在各个机器上要⼀样,⽤户名⼀样step5: 分发hadoop 安装包⾄各个机器节点scp -p 源节点⽬标节点使⽤scp 命令需要配置ssh ⽆密钥登陆,博⽂如下:step6:启动并且test mapreduce可能会有问题No route to Host 的Error,查看hostname 以及 ip 配置,或者是防⽕墙有没有关闭防⽕墙关闭,打开,状态查询,请参考以下博⽂:4,完全分布式+ HAHA全称:HDFS High Availability Using the Quorum Journal Manager 即 HDFS⾼可⽤性通过配置分布式⽇志管理HDFS集群中存在单点故障(SPOF),对于只有⼀个NameNode 的集群,若是NameNode 出现故障,则整个集群⽆法使⽤,知道NameNode 重新启动。
hadoop核心组件概述及hadoop集群的搭建

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。
(完整版)hadoop常见笔试题答案

Hadoop测试题一.填空题,1分(41空),2分(42空)共125分1.(每空1分) datanode 负责HDFS数据存储。
2.(每空1分)HDFS中的block默认保存 3 份。
3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。
4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。
5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml、mapred-site.xml 、yarn-site.xml 。
6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。
7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。
一般来说,一个集群中会有一个namenode 和多个datanode 共同工作。
8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。
9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。
文件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。
10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。
11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。
Hadoop最全面试题整理(附目录)

Hadoop面试题目及答案(附目录)选择题1.下面哪个程序负责HDFS 数据存储。
a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker答案C datanode2. HDfS 中的block 默认保存几份?a)3 份b)2 份c)1 份d)不确定答案A 默认3 份3.下列哪个程序通常与NameNode 在一个节点启动?a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker答案D分析:hadoop 的集群是基于master/slave 模式,namenode 和jobtracker 属于master,datanode 和tasktracker 属于slave,master 只有一个,而slave 有多个SecondaryNameNode 内存需求和NameNode 在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode 运行在不同的机器上。
JobTracker 和TaskTrackerJobTracker 对应于NameNode,TaskTracker 对应于DataNode,DataNode 和NameNode 是针对数据存放来而言的,JobTracker 和TaskTracker 是对于MapReduce 执行而言的。
mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:jobclient,JobTracker 与TaskTracker。
1、JobClient 会在用户端通过JobClient 类将应用已经配置参数打包成jar 文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker 创建每一个Task(即MapTask 和ReduceTask)并将它们分发到各个TaskTracker 服务中去执行。
精品课件-云计算与大数据-第8章 Hadoop和Spark平台

8.2 Hadoop组成、体系结构和部署
8.2.3 Hadoop部署 3、完全分布式模式 • 完全分布式模式将构建一个Hadoop集群,实现真正的分布式。
其体系结构由两层网络拓扑组成,形成多个机架(Rack), 每个机架会有30~40台的机器,这些机器共享具有GB级别带 宽的网络交换机。 • 在配置Hadoop时,配置文件分为两类: (1) 只 读 类 型 的 默 认 文 件 : core-default.xml 、 hdfsdefault.xml、mapred-default.xml、mapred-queues.xml (2) 定 位 ( site-specific ) 设 置 : core-site.xml 、 hdfssite.xml、mapred-site.xml、mapred-queues.xml
8.2 Hadoop组成、体系结构和部署
8.2.1 Hadoop的组成 3、Flume数据收集工具 • Flume
的海量日志采集、聚合和传输的系统,Flume支持在日志系 统中定制各类数据发送方,用于收集数据;同时,Flume提 供对数据进行简单处理,并写到各种数据接受方(可定制) 的能力。
8.2 Hadoop组成、体系结构和部署 8.2.1 Hadoop的组成
8.2 Hadoop组成、体系结构和部署
8.2.1 Hadoop的组成 1、Sqoop数据库同步工具 • Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方
模块存在,后来为了让使用者能够快速部署,也为了让开发 人员能够更快速的迭代开发,Sqoop独立成为一个Apache项 目。它主要用于在Hadoop与传统的数据库等之间进行数据的 传递,可以将一个关系型数据库(例如:MySQL、Oracle、 Postgres等)中的数据导入到Hadoop的HDFS中,也可以将 HDFS的数据导入到关系型数据库中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop集群的部署分为三种,分别独立模式(Standalonemode)、伪分布式模式(Pseudo-Distributedmode)、完全分布式模式(Clustermode),具体介绍如下。
(1)独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的
程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常
方便,所以一般情况下,该模式在学习或者发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台节上,通常使用伪分布
式模式用来调试Hadoop分布式程序的代码,以及程序执行否正确,伪分布式模式完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节担任不同的角色,在实际工作应用发中,通常使用该模式构建级Hadoop系统。
在Hadoop环境中,所有器节仅划分为两种角色,分别master(主节,1个)和slave(从节,多个)。
因此,伪分布模式集群模式的特例,只将主节和从节合二
为一罢了。
接下来,本书将以前面的三台虚拟机为例,阐述完全分布模式Hadoop集群的与配置方法,具体集群规划如图1所示。
图1Hadoop集群规划
从图1可以看出,当前规划的Hadoop集群包含一台master节和两台slave节。
这里,将前面的Hadoop01作为Master节,Hadoop02和Hadoop03作为Slave
节。
1。