哈夫曼编码.ppt
合集下载
霍夫曼编码PPT课件

Your company slogan
对于各值(码值)的代码(码字)就是从根节点出发到底层节点所经历 的分支序列。如a4的代码(码字)为00,a6的码字为111... ...通常a4和 a6等称为码值,00和111等称为码字。所有码值和码字对应关系如下表 所示:
Your company slogan
(三)霍夫曼表
将所有码值和码字的关系整理成一张表,为了整字 节输出码字,表中还含有各码字的长度。这种表就称 为霍夫曼表。本例霍夫曼表如表所示:
Your company slogan
进行压缩编码时,只要将码值用码字代替即可。所 以源符a1 a1 a2 a2 a3 a3 a3 a4 a4 a4 a4 a5 a5 a5 a6 a6 a6 a7 a7 a8编码为: 01001001101110110110100000000110110 11010000100001001。
Your company slogan
四、霍夫曼编码
(一)霍夫曼编码过程
设信息源空间为[A*P]:{A:a1 a2 ……an}{P(A):P(a1) P(a2)P(a3)……P(an)}其中∑ P(ak)=1,先用r个码的号码符 号集X:{x1,x2,……xr}对信源A中的每一个符号ak进行编码。 编码过程如下: 把信源符号ai按其出现的概率的大小顺序排列起来; 把最末两个具有最小概率的元素之概率加起来; 把该概率之和同其余概率由大到小排队,然后再把两个最 小概率加起来,再排队; 重复步骤 (2) 、 (3), 直到概率和达到 1 为止 ; 在每次合并消息时,将被合并的消息赋以1和0或0和1; 寻找从每个信源符号到概率为1处的路径,记录下路径上 的1和0; 对每个符号写出"1"、"0"序列(从码数的根到终节点)。 创建霍夫曼表。 压缩编码时,将码值用码字代替。
对于各值(码值)的代码(码字)就是从根节点出发到底层节点所经历 的分支序列。如a4的代码(码字)为00,a6的码字为111... ...通常a4和 a6等称为码值,00和111等称为码字。所有码值和码字对应关系如下表 所示:
Your company slogan
(三)霍夫曼表
将所有码值和码字的关系整理成一张表,为了整字 节输出码字,表中还含有各码字的长度。这种表就称 为霍夫曼表。本例霍夫曼表如表所示:
Your company slogan
进行压缩编码时,只要将码值用码字代替即可。所 以源符a1 a1 a2 a2 a3 a3 a3 a4 a4 a4 a4 a5 a5 a5 a6 a6 a6 a7 a7 a8编码为: 01001001101110110110100000000110110 11010000100001001。
Your company slogan
四、霍夫曼编码
(一)霍夫曼编码过程
设信息源空间为[A*P]:{A:a1 a2 ……an}{P(A):P(a1) P(a2)P(a3)……P(an)}其中∑ P(ak)=1,先用r个码的号码符 号集X:{x1,x2,……xr}对信源A中的每一个符号ak进行编码。 编码过程如下: 把信源符号ai按其出现的概率的大小顺序排列起来; 把最末两个具有最小概率的元素之概率加起来; 把该概率之和同其余概率由大到小排队,然后再把两个最 小概率加起来,再排队; 重复步骤 (2) 、 (3), 直到概率和达到 1 为止 ; 在每次合并消息时,将被合并的消息赋以1和0或0和1; 寻找从每个信源符号到概率为1处的路径,记录下路径上 的1和0; 对每个符号写出"1"、"0"序列(从码数的根到终节点)。 创建霍夫曼表。 压缩编码时,将码值用码字代替。
哈夫曼编码PPT课件
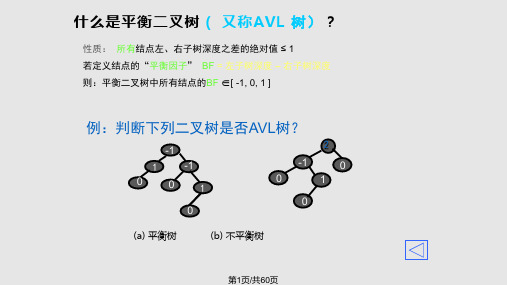
第19页/共60页
Huffman编码举例
例1【严题集6.26③】:假设用于通信的电文仅由8个字母 {a, b, c, d, e, f, g, h} 构成, 它们在电文中出现的概率分别为{ 0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10 },试 为这8个字母设计哈夫曼编码。如果用0~7的二进制编码方案又如何? 【类同P148 例2】
建议2: Huffman树的存储结构可采用顺序存储结构: 将整个Huffman树的结点存储在一个数组HT[1..n..m]中;
各叶子结点的编码存储在另一“复合”数组HC[1..n]中。
第16页/共60页
Huffman树和Huffman树编码的存储表示:
typedef struct{ unsigned int weight;//权值分量(可放大取整) unsigned int parent,lchild,rchild; //双亲和孩子分量 }HTNode,*HuffmanTree;//用动态数组存储Huffman树 typedef char**HuffmanCode; //动态数组存储Huffman编码表
HT[s1].parent=i; HT[s2].parent=i; HT[i].lchild=s1; HT[i].rchild=s2; HT[i].weight=HT[s1].weight+ HT[s2].weight;}
第18页/共60页
(续前)再求出n个字符的Huffman编码HC
HC=(HuffmanCode)malloc((n+1)*sizeof(char*)); //分配n个字符编码的头指针 向量(一维数组) cd=(char*) malloc(n*sizeof(char)); //分配求编码的工作空间(n)
Huffman编码举例
例1【严题集6.26③】:假设用于通信的电文仅由8个字母 {a, b, c, d, e, f, g, h} 构成, 它们在电文中出现的概率分别为{ 0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10 },试 为这8个字母设计哈夫曼编码。如果用0~7的二进制编码方案又如何? 【类同P148 例2】
建议2: Huffman树的存储结构可采用顺序存储结构: 将整个Huffman树的结点存储在一个数组HT[1..n..m]中;
各叶子结点的编码存储在另一“复合”数组HC[1..n]中。
第16页/共60页
Huffman树和Huffman树编码的存储表示:
typedef struct{ unsigned int weight;//权值分量(可放大取整) unsigned int parent,lchild,rchild; //双亲和孩子分量 }HTNode,*HuffmanTree;//用动态数组存储Huffman树 typedef char**HuffmanCode; //动态数组存储Huffman编码表
HT[s1].parent=i; HT[s2].parent=i; HT[i].lchild=s1; HT[i].rchild=s2; HT[i].weight=HT[s1].weight+ HT[s2].weight;}
第18页/共60页
(续前)再求出n个字符的Huffman编码HC
HC=(HuffmanCode)malloc((n+1)*sizeof(char*)); //分配n个字符编码的头指针 向量(一维数组) cd=(char*) malloc(n*sizeof(char)); //分配求编码的工作空间(n)
哈夫曼编码

单个字母编码时编码效率不高
信源字母集大时不易实现(香农-费诺码可解决)
硬件实现时需要缓冲寄存器(变长码固有的缺陷) 差错扩散(可增加信道校验码) 必须知道信源的统计特性(通用信源编码不需要)
School of Information and Mathematics
谢谢各位老师!
结论
结论:在哈夫曼编码过程中,对缩减信源符号按概率 由大到小的顺序重新排列时,应使合并后的新符号尽 可能排在靠前的位置,这样可使合并后的新符号重复
编码次数减少,使短码得到充分利用。
School of Information and Mathematics
结论
定理:在变长编码中,若各码字长度严格按照所对应符号
引例—色子游戏
点数出现 的频率
School of Information and Mathematics
引例—色子游戏
按概率编码
School of Information and Mathematics
引例—莫尔斯电报码
莫尔斯电报码:按照英文字母出现的概率编码,
在英文中,e的出现概率很高,而z的出现概率则最低。
例题
可见:第二种编码方法的码长方差要小许多。意味着第 二种编码方法的码长变化较小,比较接近于平均码长。
第一种方法编出的5个码字有4种不同的码长;
第二种方法编出的码长只有两种不同的码长;
显然,第二种编码方法更简单、更容易实现,所以
更好。
School of Information and Mathematics
哈夫曼编码
哈夫曼编码算法: (1) 信源符号按概率分布大小,以递减次序排列; (2) 取两个最小的概率,分别赋以“0”,“1”; 然后把这两个概率值相加,作为新概率值与其他概率重新排序 (3) 按重排概率值,重复(2)…,
第7章图像编码.ppt

像素冗余
由于任何给定的像素值,原理上都可以 通过它的相邻像素预测到,单个像素携 带的信息相对是小的。对于一个图像, 很多单个像素对视觉的贡献是冗余的。 这是建立在对邻居值预测的基础上。
例:原图像数据:234 223 231 238 235 压缩后数据:234 11 -8 -7 3,我们可以
对一些接近于零的像素不进行存储,从而 减小了数据量
7.1.5 图像传输中的压缩模型
源数据编码:完成原数据的压缩。
通道编码:为了抗干扰,增加一些容错、 校验位、版权保护,实际上是增加冗余。
通道:如Internet、广播、通讯、可移动介 质。
源数据 编码
通道 编码
通道
通道 解码
源数据 解码
7.2 哈夫曼编码
1.
根据信息论中信源编码理论,当平均码长R大于等于图像熵H时,总可设 计出一种无失真编码。当平均码长远大于图像熵时,表明该编码方法效率很低; 当平均码长等于或很接近于(但不大于)图像熵时,称此编码方法为最佳编码, 此时不会引起图像失真; 当平均码长大于图像熵时,压缩比较高,但会引起图 像失真。
第七章 图像编码
7.1 图像编码概述 7.2 哈夫曼编码 7.3 香农-范诺编码 7.4 行程编码 7.5 LZW编码 7.6 算术编码 7.7 预测编码 7.8 正交变换编码 7.9 JPEG编码 7.10 编程实例
7.1 图像编码概述
7.1.1 图像编码基本原理
虽然表示图像需要大量的数据,但图像数据是高度相关的, 或者说存在冗余(Redundancy)信息,去掉这些冗余信息后可以 有效压缩图像, 同时又不会损害图像的有效信息。数字图像的 冗余主要表现为以下几种形式:空间冗余、时间冗余、视觉冗余、 信息熵冗余、结构冗余和知识冗余。
哈夫曼编码

称这种预先规定的方法为编码方法
编码方法有多种 本问题采用哈夫曼编码方法
什么是哈夫曼编码方法
1952年由美国计算机科学家戴维· 哈夫曼先生提出 是一种数据压缩技术 该方法依据字符出现的概率进行编码 ,其基本思想为:
出现概率高的字符使用较短的编码 出现概率低的则使用较长的编码 使编码之后的码字的平均长 度最短
字母d的编码为0
18 0
可见:
1
11 0 5
பைடு நூலகம்
字母i的编码为10
7 d 0 i 10
1
6 0 2 a 110
在电文中出现频率高的字 母其对应叶子结点离根结 点近;出现频率低的字母 其对应叶子结点离根结点 远
字母a的编码为110 字母n的编码为111
1
4 n
因此,在电文中出现频率 高的字母的编码相对短, 而出现频率低的字母的编 码相对长
哈夫曼算法
返回开头
构建哈夫曼树例一
4个字母{ a,d,i,n } 在电文中出现的概率分别为{ 2,7,5,4}
a d i n
2
7
5
4
2
6
4 5
11
6 2 d 7 4 i
18
11 5 6
2
返回构建哈夫曼树
4
n
a
哈夫曼算法
根据给定的 n 个权值{ w1, w2,…, wn},构成 n 棵 二叉树的集合 F={ T1,T2 ,…,Tn },其中每棵二叉 树Ti中只有一个带权为 wi的根结点,其左右子树 均为空 在 F 中选取两棵根结点的权值最小的树作为左右 子树,构造一棵新的二叉树,且置新的二叉树的 根结点的权值为其左、右子树上根结点的权值之 和 在 F 中删除这两棵树,同时将新得到的二叉树加 入F中 重复(2)和(3),直到 F 只含一棵树为止
哈夫曼编码演示

//创建并输出编码表 generate_code(root, 0); fout = fopen(“code.txt”, "w"); dump_code(fout); //压缩 fout = fopen(decoded.txt, "w"); encode(fout);
return 0; } 这是我的main函数,为了方便观看做了些 许简省,去掉了关闭文件,清理资源的等 代码行。但仍可以运行。
2
程序介绍
压缩程序
思路: 1.读入文件,统计频率,为出现的每一个字符建立节点,并排成一列 2.将节点转化成哈夫曼树 3.利用哈夫曼树产生编码表文件 4.利用编码将源文件转换成二进制编码表示的文本文件 5.将转码后的文本文件压缩成bin文件
0 1 0 a 0.1 1 b 0.2 c 0.7
产生代码 a: 00 b: 01 c: 1
4
结束感想
本次编写还算成功,虽然调试途中出现了一些大大小小的bug,但是都没有造成很 严重的困扰,可能是因为我采用了老师的框架,绕过了很多陷阱的原因,同时也向 那些自己编写整个程序或是自己不断创新的同学表以敬意。 同时非常高兴的是这是第一次我们能学以致用,编写出能在在生活中得到应用的程 序,这充分体现了一点:科技改善生活。
for(j=0; j<wordnum/8; j++) { character=0; for(i=0; i<8; i++) character += (c = getc(fin)-48) * (int)pow(2,i); fwrite(&character,sizeof(char),1,fout); }
C语言中1个char类型占8bit,在计算机中,也就是8位二进制数,相当 于可以存储0-255大小的十进制数。 所以我们要想把字符串存储转化为二进制存储,只需要将每8位字符串 对应的十进制数计算出来,存入每个char类型。 若最后不足8位,补0至8位即可。
数据结构哈夫曼树课件
总结词
优化、提升
详细描述
基于哈夫曼树的网络流量分类算法的优化策 略主要从以下几个方面进行优化和提升:一 是优化哈夫曼树的构造算法,提高树的构造 效率和准确性;二是利用多级哈夫曼编码技 术,降低编码和解码的时间复杂度;三是引 入机器学习算法,对网络流量特征进行自动
提取和分类,进一步提升分类准确率。
THANKS
基于堆排序的构造算法
总结词:堆排序是一 种基于比较的排序算 法,它利用了堆这种 数据结构的特点,能 够在O(nlogn)的时间 内完成排序。在哈夫 曼树的构造中,堆排 序可以用来找到每个 节点的父节点,从而 构建出哈夫曼树。
详细描述:基于堆排 序的构造算法步骤如 下
1. 定义一个最大堆, 并将每个节点作为一 个独立的元素插入到 堆中。每个元素包含 了一个节点及其权值 。
哈夫曼编码的基本概念
哈夫曼编码是一种用于无损数据压缩的熵编码算法,具有较高的编码效率和较低的 编码复杂度。
它利用了数据本身存在的冗余和相关性,通过构建最优的前缀编码来实现高效的数 据压缩。
哈夫曼编码是一种可变长编码,其中每个符号的编码长度取决于它在输入序列中出 现的频率。
哈夫曼编码的实现方法
构建哈夫曼树
节ቤተ መጻሕፍቲ ባይዱ。
优化编码长度
在分配码字时,通过一些策略优化 编码长度,例如给高频符号更短的 码字。
可变长度编码
为了提高压缩比,可以使用可变长 度编码,即对于高频符号赋予更短 的码字,对于低频符号赋予更长的 码字。
04
哈夫曼树在数据压 缩中的应用
基于哈夫曼编码的数据压缩算法
哈夫曼编码是一种可变长度的 编码方式,通过统计数据的出 现频率来构建哈夫曼树,实现 数据压缩。
数据结构哈夫曼树和哈夫曼编码PPT课件
C
AB
AC
BC
ABC
第27页/共55页
回朔策略—求幂集
000
000
100
000
010
100
110
000
001
010
011 100 101 110
111
第28页/共55页
回朔策略—求幂集
void powerSet(int num){ if (num<=len-1) { for (int i=0; i<2; i++){ if (i = = 0) mask[num]=1; else mask[num]=0; powerSet(num+1);} } else{ for (int j=0; j<len; j++){ if (mask[j]==1) printf("%c",set[j]);} printf("\n");}
}
第29页/共55页
回朔策略—求幂集
int len=3; int mask[]={0,0,0}; char set[]={'A','B','C'}; int main(int argc, char* argv[]) {
powerSet(0); return 0; }
第30页/共55页
章末复习
1. 熟练掌握二叉树的结构特性,了解相应的证 明方法。 2. 熟悉二叉树的各种存储结构的特点及适用范 围。 3. 遍历二叉树是二叉树各种操作的基础。实现 二叉树遍历的具体算法与所采用的存储结构有 关。掌握各种遍历策略的递归算法,灵活运用 遍历算法实现二叉树的其它操作。层次遍历是 按另一种搜索策略进行的遍历。
哈夫曼编码---PPT
12
结果:
结果:
谢 谢
15
哈夫曼编码实现文件压缩与解压
小组成员:刘 勇 吴风松 张艳芬
1
信源编码的基本途径有两个:
使序列中的各个符号尽可能地互相独立, 即解除相关性;使编码中各个符号源自现的概率尽可能地相 等,即概率均匀化。
2
哈夫曼码为最佳无失真码 哈夫曼编码原理: 哈夫曼编码使用变长编码表对源符号(如文 件中的一个字母)进行编码,可以使编码 之后的字符串的平均长度、期望值降低, 从而达到无损压缩数据的目的。 特点:1.出现机率高的字母使用较短的编 码,反之出现机率低的则使用较长的编码 2.一个短的元素的编码不会成为其他长 3 编码的前缀
5
哈夫曼编码的建模:
为什么要用二叉树的结构来实 现哈夫曼编码?
6
例子说明:
0.4 0.2 0.2 0.1 0.1 0.4 0.2 0.2 0.2 0.4 0.4 0.2
0 1
0.6 0 0.4 1
1.0
0 1
0 1
7
对英文文本文件:
8
霍夫曼树的构造:
9
压缩:
10
解压:
11
程序实现框架:
哈夫曼编码方法
(1)将信源消息符号按其出现的概率大小依次 排列, p1 p2 pn (2)取两个概率最小的字母分别配以0和1两个 码元,并将这两个概率相加作为一个新字 母的概率,与未分配的二进符号的字母重 新排队。
4
(3)对重排后的两个概率最小符号重复步骤 (2) 的过程。
(4) 不断继续上述过程,直到最后两个符号配 以0和1为止。 (5) 从最后一级开始,向前返回得到各个信源 符号所对应的码元序列,即相应的码字。
信息论 第4章(哈夫曼编码和游程编码).ppt
- log2 p(xi)
2.34 2.41 2.48 2.56 2.74 3.34 6.66
码长 3 3 3 3 3 4 7
香农编码分析
可求得该信源的信源熵:
H ( X ) pxi log pxi 2.61(比特/符号) xi X
以及平均码长:
N ni p(xi ) 3.14 (码元/符号) i1
下面是对例1进行哈夫曼编码:
X1:0.20 X2:0.19 X3:0.18 X4:0.17
0.39 0.35
0.61
1.00
X6:0.10 X5:0.15
0.26
X7:0.01 0.11
对应的编码如下:
信源 x1
编码 10
码长 2
x2
x3
x4
x5
x6
x7
11 000 001 010 0110 0111
消息码 标识码 游程长度
该编码方式就称为游程编码(RLC).
例如:有一个信源: BBBBBBBBBBXXXXXXXXJJJJJJJJJAAAAAAAAAAAAA AAAAUUUUUUUUUUUUUUUUUUUU
经过游程编码,得到: B#10X#8J#9A#17U#20
其中#为标识码.
游程编码用于二值图像的压缩
游程编码的基本原理
很多信源产生的消息有一定相关性,往往 连续多次输出同样的消息,同一个消息连续输 出的个数称为游程(Run-Length).我们只需要 输出一个消息的样本和对应重复次数,就完全 可以恢复原来的消息系列.原始消息系列经过 这种方式编码后,就成为一个个编码单元(如下 图),其中标识码是一个能够和消息码区分的特 殊符号.
2.61 2.74
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4
构造Huffman树的步骤:
操作要点1:对权值的合并、删除与替换
——在权值集合{7,5,2,4}中,总是合并当前值最小的两个权
注:方框表示外结点(叶子,字符对应的权值), 圆框表示内结点(合并后的权值)。
5
操作要点2:按左0右1对Huffman树的所有分支编
号! ——将 Huffman树 与 Huffman编码 挂钩
(2) 重复以下步骤, 直到 F 中仅剩下一棵树为止:
① 在 F 中选取两棵根结点的权值最小的扩充二叉树, 做为左、 右子树构造一棵新的二叉树。置新的二叉树的根结点的权值为 其左、右子树上根结点的权值之和。
② 在 F 中删去这两棵二叉树。 ③ 把新的二叉树加入 F。
先举例!
3
例1:设有4个字符d,i,a,n,出现的频度分别为7,5,2, 4,
少。这种编码已广泛应用于网络通信中。
例2(严题集6.26③):假设用于通信的电文仅由8个字母 {a,
b, c, d, e, f, g, h} 构成,它们在电文中出现的概率分别为 { 0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10},试为这8 个字母设计哈夫曼编码。如果用0~7的二进制编码方案又如何?
=1.44+0.92+0.25=2.61
二进制码 WPL=3(0.19+0.32+0.21+0.07+0.06+0.10+0.02+0.03)=3
9
另一种结果表示:
10
例3(实验二方案3):设字符集为26个英文字母,其出 现频度如下表所示。要求编程实现:
先建哈夫曼树,再利用此树对报文“This program is my favorite”进行编码和译码。
注:若圆满实现了此方案,平时成绩将以满分计。
字符 空格 a
b
c
d
e
f
g
h
i
频度 186 64 13 22 32 103 21 15 47 57
字符 j 频度 1
k l mn o p q r s 5 32 20 57 63 15 1 48 51
字符 t u v w x y z
频度 80 23 8 18 1 16 1
解:先将概率放大100倍,以方便构造哈夫曼树。 权值集合 w={7, 19, 2, 6, 32, 3, 21, 10}, 按哈夫曼树构造规则(合并、删除、替换),可得到哈夫曼树。
7
为清晰起见,重新排序为:
w=×{2,×3, 6, 7, 10, 19, 21, 32}
w1=×{5×, 6, 7, 10, 19, 21, 32}
11
提示1:霍夫曼树中各结点的结构可以定义为如下 5个分量: char weight parent lchild Rchild
提示2:霍夫曼树的存储结构可采用顺序存储结构: 将整个霍夫曼树的结点存储在一个数组中:HT[1..n]; 将结点的编码存储在HC[1..n]中。
怎样编码才能使它们组成的报文在网络中传得最快? 法1:等长编码。例如用二进制编码来实现。
取 d=00,i=01,a=10,n=11 法2:不等长编码,例如用哈夫曼编码来实现。
取 d=0; i=10, a=110, n=111
最快的编码是哪个?是非等长的Huffman码! 怎样实现Huffman编码先?要构造Huffman树!
17
11
e 10 0.32 e 100 0.32
01 0 1
f 11111 0.03 f 101 0.03 g 01 0.21 g 110 0.21
7 10 6 5 a h d0 1
h 1101 0.10 h 111 0.10
2 3f c
Huffman码的WPL=2(0.19+0.32+0.21) + 4(0.07+0.06+0.10) +5(0.02+0.03)
01 d
01
i 01
a
n
Huffman编码结果:d=0, i=10, a=110, n=111 特点W:PL每=一1b码it都×不7+是2另bi一t×码5的+3前b缀it(,2+绝4不)=会35错译! 称为前缀码
6
霍夫曼编码的基本思想是:概率大的字符用短码,概率小的用
长码。由于霍夫曼树的WPL最小,说明编码所需要的比特数最
霍 夫 曼 树: 带权路径长度最小的树。
1
Huffman树简介:
Weighted Path Lengthn
树的带权路径长度如何计算? WPL 哈夫曼树则是:WPL 最小的树。
=k=1 wklk经典之例:752 4 a bc d(a)
WPL=36
2 c 4 d 75 ab (b)
WPL=46
Huffman树 7 a
100
w2=×{7, ×10, 11, 19, 21, 32}
w3=×{11,×17, 19, 21, 32}
40
60
w4=×{19,×21, 28, 32}
w5=×{28×,32,40}
19 21 32 28 b ge
w6=×{40×,60}
17
11
w7={100}
哈夫曼树
7 10 6 5 a hd
6.5 Huffman树及其应用 a
一、最优二叉树(霍夫曼树)
b
c
预备知识:若干术语
d
路 径: 由一结点到另一结点间的分支所构成
ef g
路径长度: 路径上的分支数目 a→e的路径长度= 2
树的路径长度:从树根到每一结点的路径长度之和。树长度=10
带权路径长度:结点到根的路径长度与结点上权的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和
2 3f c
8
对应的哈夫曼编码(左0右1): 100
符 编码 频率 符 编码 频率
0 40
1 60
a 1100 0.07 a 000 0.07 0 1
01
b 00 0.19 b 001 0.19 19 21 32 28
c 11110 0.02 c 010 0.02 b
g e0
1
d 1110 0.06 d 011 0.06
5 b
24 cd
(c)
WPL= 35
2
构造霍夫曼树的基本思想:
权值大的结点用短路径,权值小的结点用长路径。
构造Huffman树的步骤(即Huffman算法):
(1) 由给定的 n 个权值{w0, w1, w2, …, wn-1},构造具有 n 棵扩充 二叉树的森林F = { T0, T1, T2, …, Tn-1 },其中每一棵扩充二叉树 Ti 只有一个带有权值 wi 的根结点,其左、右子树均为空。
构造Huffman树的步骤:
操作要点1:对权值的合并、删除与替换
——在权值集合{7,5,2,4}中,总是合并当前值最小的两个权
注:方框表示外结点(叶子,字符对应的权值), 圆框表示内结点(合并后的权值)。
5
操作要点2:按左0右1对Huffman树的所有分支编
号! ——将 Huffman树 与 Huffman编码 挂钩
(2) 重复以下步骤, 直到 F 中仅剩下一棵树为止:
① 在 F 中选取两棵根结点的权值最小的扩充二叉树, 做为左、 右子树构造一棵新的二叉树。置新的二叉树的根结点的权值为 其左、右子树上根结点的权值之和。
② 在 F 中删去这两棵二叉树。 ③ 把新的二叉树加入 F。
先举例!
3
例1:设有4个字符d,i,a,n,出现的频度分别为7,5,2, 4,
少。这种编码已广泛应用于网络通信中。
例2(严题集6.26③):假设用于通信的电文仅由8个字母 {a,
b, c, d, e, f, g, h} 构成,它们在电文中出现的概率分别为 { 0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10},试为这8 个字母设计哈夫曼编码。如果用0~7的二进制编码方案又如何?
=1.44+0.92+0.25=2.61
二进制码 WPL=3(0.19+0.32+0.21+0.07+0.06+0.10+0.02+0.03)=3
9
另一种结果表示:
10
例3(实验二方案3):设字符集为26个英文字母,其出 现频度如下表所示。要求编程实现:
先建哈夫曼树,再利用此树对报文“This program is my favorite”进行编码和译码。
注:若圆满实现了此方案,平时成绩将以满分计。
字符 空格 a
b
c
d
e
f
g
h
i
频度 186 64 13 22 32 103 21 15 47 57
字符 j 频度 1
k l mn o p q r s 5 32 20 57 63 15 1 48 51
字符 t u v w x y z
频度 80 23 8 18 1 16 1
解:先将概率放大100倍,以方便构造哈夫曼树。 权值集合 w={7, 19, 2, 6, 32, 3, 21, 10}, 按哈夫曼树构造规则(合并、删除、替换),可得到哈夫曼树。
7
为清晰起见,重新排序为:
w=×{2,×3, 6, 7, 10, 19, 21, 32}
w1=×{5×, 6, 7, 10, 19, 21, 32}
11
提示1:霍夫曼树中各结点的结构可以定义为如下 5个分量: char weight parent lchild Rchild
提示2:霍夫曼树的存储结构可采用顺序存储结构: 将整个霍夫曼树的结点存储在一个数组中:HT[1..n]; 将结点的编码存储在HC[1..n]中。
怎样编码才能使它们组成的报文在网络中传得最快? 法1:等长编码。例如用二进制编码来实现。
取 d=00,i=01,a=10,n=11 法2:不等长编码,例如用哈夫曼编码来实现。
取 d=0; i=10, a=110, n=111
最快的编码是哪个?是非等长的Huffman码! 怎样实现Huffman编码先?要构造Huffman树!
17
11
e 10 0.32 e 100 0.32
01 0 1
f 11111 0.03 f 101 0.03 g 01 0.21 g 110 0.21
7 10 6 5 a h d0 1
h 1101 0.10 h 111 0.10
2 3f c
Huffman码的WPL=2(0.19+0.32+0.21) + 4(0.07+0.06+0.10) +5(0.02+0.03)
01 d
01
i 01
a
n
Huffman编码结果:d=0, i=10, a=110, n=111 特点W:PL每=一1b码it都×不7+是2另bi一t×码5的+3前b缀it(,2+绝4不)=会35错译! 称为前缀码
6
霍夫曼编码的基本思想是:概率大的字符用短码,概率小的用
长码。由于霍夫曼树的WPL最小,说明编码所需要的比特数最
霍 夫 曼 树: 带权路径长度最小的树。
1
Huffman树简介:
Weighted Path Lengthn
树的带权路径长度如何计算? WPL 哈夫曼树则是:WPL 最小的树。
=k=1 wklk经典之例:752 4 a bc d(a)
WPL=36
2 c 4 d 75 ab (b)
WPL=46
Huffman树 7 a
100
w2=×{7, ×10, 11, 19, 21, 32}
w3=×{11,×17, 19, 21, 32}
40
60
w4=×{19,×21, 28, 32}
w5=×{28×,32,40}
19 21 32 28 b ge
w6=×{40×,60}
17
11
w7={100}
哈夫曼树
7 10 6 5 a hd
6.5 Huffman树及其应用 a
一、最优二叉树(霍夫曼树)
b
c
预备知识:若干术语
d
路 径: 由一结点到另一结点间的分支所构成
ef g
路径长度: 路径上的分支数目 a→e的路径长度= 2
树的路径长度:从树根到每一结点的路径长度之和。树长度=10
带权路径长度:结点到根的路径长度与结点上权的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和
2 3f c
8
对应的哈夫曼编码(左0右1): 100
符 编码 频率 符 编码 频率
0 40
1 60
a 1100 0.07 a 000 0.07 0 1
01
b 00 0.19 b 001 0.19 19 21 32 28
c 11110 0.02 c 010 0.02 b
g e0
1
d 1110 0.06 d 011 0.06
5 b
24 cd
(c)
WPL= 35
2
构造霍夫曼树的基本思想:
权值大的结点用短路径,权值小的结点用长路径。
构造Huffman树的步骤(即Huffman算法):
(1) 由给定的 n 个权值{w0, w1, w2, …, wn-1},构造具有 n 棵扩充 二叉树的森林F = { T0, T1, T2, …, Tn-1 },其中每一棵扩充二叉树 Ti 只有一个带有权值 wi 的根结点,其左、右子树均为空。