应用回归分析-实用回归分析
实用回归分析(应用回归分析 )

一、普通最小二乘估计
(Ordinary Least Square Estimation,简记为OLSE)
最小二乘法就是寻找参数β0、β1的估计值使离差平方和达极小 n Q(ˆ0,ˆ1) (yi ˆ0 ˆ1xi )2 i1
n
min 0,1 i1
(yi
0
1xi )2
yˆi ˆ0ˆ1xi 称为yi的回归拟合值,简称回归值或拟合值
1 .3 回归分析的主要内容及其
一般模型
一元线性回归
线性回归
多元线性回归
多个因变量与多个自变
量的回归
讨论如何从数据推断回
归模型基本假设的合理
性
回归诊断
当基本假设不成立时如
判定回归方程拟合的效
选择回归函数的形式
何对数据进行修正 果
回归分析
回归变量的选择
自变量选择的准则
人均消费金 额(元) 234.75 259.26 280.58 305.97 347.15 433.53 481.36 545.40 687.51 756.27
ቤተ መጻሕፍቲ ባይዱ年份
1990 1991 1992 1993 1994 1995 1996 1997 1998
人均国民 人均消费
收入(元) 金额(元)
1634
表2.1
火灾损失表
距消防站离 x(km) 3 . 4 1 . 8 4 . 6 2 . 3 3 . 1 5 . 5 0 . 7 3 . 0 火灾损失 y(千元) 26.2 17.8 31.3 23.1 27.5 36.0 14.1 22.3 距消防站离 x(km) 2 . 6 4 . 3 2 . 1 1 . 1 6 . 1 4 . 8 3 . 8 火灾损失 y(千元) 19.6 31.3 24.0 17.3 43.2 36.4 26.1
数据分析方法:回归分析实用指南

数据分析方法:回归分析实用指南引言数据分析在当今社会中扮演着至关重要的角色。
通过收集、整理和分析数据,我们可以获得有关特定问题或现象的深入洞察。
回归分析是一种常用的统计分析方法,可以帮助我们理解变量之间的关系,并预测未来的趋势。
本文将为您介绍回归分析的概念、应用和常见方法,希望能够为您在实际应用中提供一些有用的指导。
什么是回归分析?回归分析是一种用于研究变量之间关系的统计方法。
它通过建立一个数学模型来描述自变量(独立变量)与因变量(依赖变量)之间的关系。
回归分析可以帮助我们理解变量之间的关联性,从而探索隐藏在数据背后的规律。
回归分析的应用领域回归分析在各个领域都有广泛的应用,以下是一些常见的应用领域:1. 经济学在经济学中,回归分析被用来研究各种经济变量之间的关系,如GDP与投资、通货膨胀与失业率等。
通过回归分析,经济学家可以预测未来的经济趋势,为政府和企业提供决策支持。
2. 市场营销在市场营销领域,回归分析被广泛应用于市场调研和销售预测。
通过分析市场数据和消费者行为,市场营销人员可以确定哪些因素对产品销售额产生积极影响,并相应地调整营销策略。
3. 医学研究医学研究中也常用回归分析来探索疾病与生活方式、遗传因素等之间的关系。
通过回归分析,医生和研究人员可以找到影响疾病发生和发展的风险因素,从而提供更有效的预防和治疗方法。
4. 社会科学回归分析在社会科学研究中也是一个重要的工具。
通过回归分析,社会科学家可以研究教育、犯罪、就业等不同社会现象之间的关系,从而为社会政策制定提供依据。
简单线性回归分析在回归分析中,最简单的一种形式是简单线性回归分析。
在简单线性回归中,我们只考虑一个自变量和一个因变量之间的关系。
1. 模型表达式简单线性回归模型的表达式为:Y=β0+β1X+ɛ其中,Y是因变量,X是自变量,β0和β1是回归系数,ɛ是误差项。
2. 回归系数解释回归系数β0和β1分别表示截距和斜率。
截距β0表示当自变量X为0时,因变量Y 的预测值。
回归分析法原理及应用

回归分析法原理及应用回归分析法是一种常用的统计方法,旨在探究自变量和因变量之间的关系。
在回归分析中,自变量是可以用于预测或解释因变量的变量,而因变量是被预测或被解释的变量。
利用回归分析,我们可以确定这些变量之间的关系,从而预测未来的趋势和结果。
回归分析法的原理非常简单,通过一系列统计方法来评估自变量和因变量之间的关系。
最常用的回归分析是线性回归分析,它建立在一条直线上,通过最小二乘法来寻找自变量和因变量之间的线性关系。
其它类型的回归分析包括多元回归分析、二元分类回归分析等。
回归分析法的应用非常广泛,它可以应用于医学、社会科学、金融、自然科学等领域。
举个例子,在医学领域,回归分析可用于预测疾病的发病率或死亡率。
在金融领域,回归分析可用于预测股票价格趋势或汇率变化。
在社会科学领域,回归分析可用于解释人类行为、心理和社会变化。
要使用回归分析法,需要完成以下步骤:1. 收集数据。
这包括自变量和因变量的数据,例如市场规模和销售额。
2. 进行数据预处理。
这包括检查数据是否有缺失、异常值或离群值。
必要时,可对数据进行清理并进行适当的转换或标准化。
3. 选择合适的回归模型。
这需要考虑自变量和因变量之间的关系类型,例如线性、非线性和分类。
根据实际情况和目标,选择最适合的回归模型。
4. 训练模型。
这需要将数据分为训练数据集和测试数据集,并利用训练数据集来建立回归模型。
模型的性能可以通过测试数据集的预测能力来评估。
5. 评估模型性能。
测试数据集可以用来评估模型的性能如何,例如模型的准确度、召回率或F1分数。
这些指标可以用来比较不同的回归模型。
回归分析法的优点包括:1. 提供对自变量与因变量之间的关系的量化估计。
2. 可以帮助我们理解变量之间的相互作用。
3. 可以预测未来的行为或趋势。
4. 可以作为一种基本的统计工具,应用于各种具体应用领域。
回归分析法的缺点包括:1. 回归模型只能处理自变量和因变量之间的线性关系,而不能处理非线性关系。
回归分析方法及其应用中的例子

3.1.2 虚拟变量的应用例3.1.2.1:为研究美国住房面积的需求,选用3120户家庭为建模样本,回归模型为:123log log P Y βββ++logQ=其中:Q ——3120个样本家庭的年住房面积(平方英尺) 横截面数据P ——家庭所在地的住房单位价格 Y ——家庭收入经计算:0.247log 0.96log P Y -+logy=4.17 20.371R =()() ()上式中2β=0.247-的价格弹性系数,3β=0.96的收入弹性系数,均符合经济学的常识,即价格上升,住房需求下降,收入上升,住房需求也上升。
但白人家庭与黑人家庭对住房的需求量是不一样的,引进虚拟变量D :01i D ⎧=⎨⎩黑人家庭白人家庭或其他家庭模型为:112233log log log log D P D P Y D Y βαβαβα+++++logQ=例3.1.2.2:某省农业生产资料购买力和农民货币收入数据如下:(单位:十亿元)①根据上述数据建立一元线性回归方程:ˆ 1.01610.09357yx =+ 20.8821R = 0.2531y S = 67.3266F = ②带虚拟变量的回归模型,因1979年中国农村政策发生重大变化,引入虚拟变量来反映农村政策的变化。
01i D ⎧=⎨⎩19791979i i <≥年年 建立回归方程为: ˆ0.98550.06920.4945yx D =++ ()() ()20.9498R = 0.1751y S = 75.6895F =虽然上述两个模型都可通过显着性水平检验,但可明显看出带虚拟变量的回归模型其方差解释系数更高,回归的估计误差(y S )更小,说明模型的拟合程度更高,代表性更好。
3.5.4 岭回归的举例说明企业为用户提供的服务多种多样,那么在这些服务中哪些因素更为重要,各因素之间的重要性差异到底有多大,这些都是满意度研究需要首先解决的问题。
国际上比较流行并被实践所验证,比较科学的方法就是利用回归分析确定客户对不同服务因素的需求程度,具体方法如下:假设某电信运营商的服务界面包括了A1……Am 共M 个界面,那么各界面对总体服务满意度A 的影响可以通过以A 为因变量,以A1……Am 为自变量的回归分析,得出不同界面服务对总体A 的影响系数,从而确定各服务界面对A 的影响大小。
回归分析方法及其应用实例

回归分析方法及其应用实例环境与规划学院2012级地理科学2014年11月回归分析方法及其应用实例摘要:回归分析方法,就是研究要素之间具体数量关系的一种强有力的工具,运用这种方法能够建立反应地理要素之间具体数量关系的数学模型,即回归模型。
本文首先给出回归分析方法的主要内容及解决问题的一般步骤,简单的介绍了回归分析建模的一般过程,进而引出了基本的一元线性回归分析方法的数学模型。
其次,叙述了多元线性回归理论模型,列举了多元线性回归模型应遵从的假定条件,探讨了多元线性回归模型中未知参数的估计方法及其参数的检验问题。
最后通过具体的案例来总结了多元回归分析的应用。
关键词:多元线性回归模型;模型检验;SPSS;实例应用。
引言:用回归分析建模的一般过程:(1)画散点图(2)设定模型(3)最小二乘估计模型中的参数并写出回归方程(4)拟合优度的测量(5)回归参数的显著性检验及其置信区间(6)残差分析(回归分析的前提假定)(7)预测(点、区间)在利用回归分析解决问题时,首先要建立模型,即函数关系式,其自变量称为回归变量,因变量称为应变量或响应变量。
如果模型中只含有一个回归变量,称为一元回归模型,否则称为多元回归模型(实际中所见到的大都是线性回归模型,非线性的一般可以化为线性的来处理)。
一、一元线性回归模型有一元线性回归模型(统计模型)如下:Y t =β0+β1 x t + u t上式表示变量y t和x t之间的真实关系。
其中yt称被解释变量(因变量),xt称解释变量(自变量),ut称随机误差项,β0称常数项,β1称回归系数(通常未知)。
上模型可以分为两部分。
(1)回归函数部分,E(y t) =β0+ β1 x t,(2)随机部分,u t(包含了所有没有考虑在内的影响因素对因变量的影响,越小越好)二、多元线性回归模型2.1 当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元线性回归。
设可预测的随机变量为y,它受到k个非随机因素X1,X2,X3``````X k 和不可预测的随机因素ε的影响。
(整理)回归分析应用实例讲解
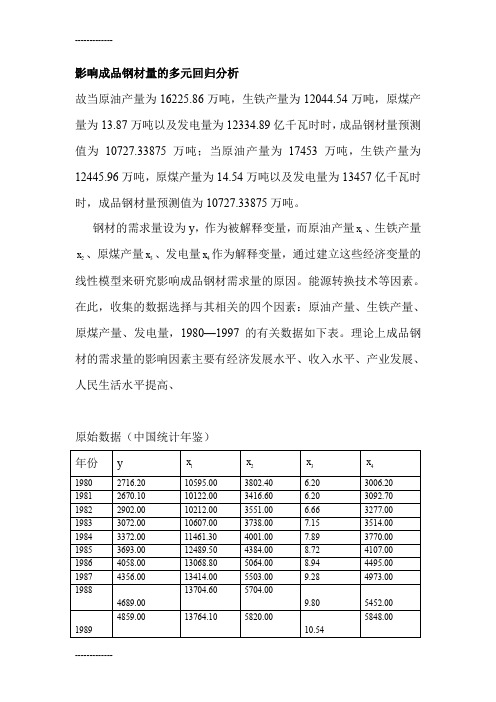
影响成品钢材量的多元回归分析故当原油产量为16225.86万吨,生铁产量为12044.54万吨,原煤产量为13.87万吨以及发电量为12334.89亿千瓦时时,成品钢材量预测值为10727.33875万吨;当原油产量为17453万吨,生铁产量为12445.96万吨,原煤产量为14.54万吨以及发电量为13457亿千瓦时时,成品钢材量预测值为10727.33875万吨。
钢材的需求量设为y,作为被解释变量,而原油产量x、生铁产量1x、原煤产量3x、发电量4x作为解释变量,通过建立这些经济变量的2线性模型来研究影响成品钢材需求量的原因。
能源转换技术等因素。
在此,收集的数据选择与其相关的四个因素:原油产量、生铁产量、原煤产量、发电量,1980—1997的有关数据如下表。
理论上成品钢材的需求量的影响因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、原始数据(中国统计年鉴)将中国成品一、 模型的设定设因变量y 与自变量1x 、2x 、3x 、4x 的一般线性回归模型为:y = 0β+11223344x x x x ββββε++++ε是随机变量,通常满足()0εE =;Var(ε)=2σ二 参数估计再用spss 做回归线性,根据系数表得出回归方程为:1234170.2870.0410.55417.8180.389y x x x x =-+-+ 再做回归预测,得出如下截图:故当原油产量为16225.86万吨,生铁产量为12044.54万吨,原煤产量为13.87万吨以及发电量为12334.89亿千瓦时时,成品钢材量预测值为10727.33875万吨;当原油产量为17453万吨,生铁产量为12445.96万吨,原煤产量为14.54万吨以及发电量为13457亿千瓦时时,成品钢材量预测值为10727.33875万吨。
三 回归方程检验由相关系数表看出,因变量与各个自变量的相关系数都很高,都在0.9 以上,说明变量间的线性相关程度很高,适合做多元线性回归模型。
《应用回归分析》课件

欢迎来到《应用回归分析》PPT课件,本课程将带领您深入了解回归分析的 原理、应用场景和进阶技巧。准备好开始你的数据之旅了吗?
回归分析基础
简单线性回归
学习如何通过一条直线来拟合数据集,预测因变量 与自变量之间的关系。
多元线性回归
掌握多个自变量对因变量的影响,解释多元线性回 归模型中的回归系数。
参考资料
• 学习资源:《回归分析实战》、Coursera 数据分析专项课程 • 推荐书目:《应用回归分析》、《统计学基础》 • 网上工具资源推荐:RStudio、Python Scikit-learn
Q&A
1 感兴趣问题答疑
回答学员在课程学习中提出的问题,解惑排难。
2 课程疑问解答
回答学员对课程内容、实操操作等方面的疑问。
回归分析进阶
1
非线性回归
探索非线性关系,学会拟合非线性函数,
泊松回归
2
以更准确地预测因变量。
了解如何处理计数型或二项分布的响应
变量,利用泊松回归进行相关研究。
3
广义线性回归
学习如何应用广义线性模型,处理非正 态响应变量以及多项式回归问题。
回归分析的实际应用
小案例:预测房价
利用回归分析来预测房价,了解房价与各种因素之 间的关系,并为购房者提供参考。
大案例:客户购买行为预测
通过回归模型预测客户的购买行为,为企业决策提 供数据支持和市场策略规划。
总结与展望
Hale Waihona Puke 1 回归分析的局限了解回归分析的限制和应 用场景,探讨其他统计方 法的补充。
2 未来应用趋势
展望回归分析在大数据和
3 怎样提高回归预测精
度?
回归分析课后习题-实用回归分析

第一章习题1.1变量间统计关系和函数关系的区别是什么?1.2回归分析与相关分析的区别和联系是什么?1.3回归模型中随机误差项的意义是什么?1.4线性回归模型中的基本假设是什么?1.5回归变量设置的理论依据是什么?在设置回归变量时应注意哪些问题?1.6收集、整理数据包括哪些基本内容?1.7构造回归理论模型的基本依据是什么?1.8为什么要对回归模型进行检验?1.9回归模型有哪几个方面的应用?1.10为什么强调运用回归分析研究经济问题要定性分析和定量分析相结合?第二章 习题2.1一元线性回归模型有哪些基本假定? 2.2 考虑过原点的线性回归模型1,1,,i i i y x i n βε=+=误差1,,n εε仍满足基本假定。
求1β的最小二乘估计。
2.3证明(2.27)式,10nii e==∑,10ni i i x e ==∑。
2.4回归方程01Ey x ββ=+的参数01,ββ的最小二乘估计与极大似然估计在什么条件下等价?给出证明。
2.5 证明0ˆβ是0β的无偏估计。
2.6 证明(2.42)式 ()()222021,i x Var n x x βσ⎡⎤=+⎢⎥-⎢⎥⎣⎦∑成立 2.7 证明平方和分解式SST SSR SSE =+2.8 验证三种检验的关系,即验证:(1)t ==(2)2212ˆ1ˆ2xx L SSR F t SSE n βσ===-2.9 验证(2..63)式:()()221var 1i i xx x x e n L σ⎡⎤-=--⎢⎥⎢⎥⎣⎦2.10 用第9题证明()2211ˆˆ2n i ii y y n σ==--∑是2σ的无偏估计。
2.11* 验证决定系数2r 与F 值之间的关系式 22Fr F n =+-以上表达式说明2r 与F 值是等价的,那么我们为什么要分别引入这两个统计量,而不是只使用其中的一个。
2.12* 如果把自变量观测值都乘以2,回归参数的最小二乘估计0ˆβ和1ˆβ会发生什么变化?如果把自变量观测值都加上2,回归参数的最小二乘估计0ˆβ和1ˆβ会发生什么变化? 2.13 如果回归方程01ˆˆˆy x ββ=+相应的相关系数r 很大,则用它预测时,预测误差一定较小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 .4 建立实际问题回归模型的过程
二. 收集整理统计数据
1.数据类型
时间序列—按时间顺序排列的数据 横截面数据—同一时间截面上的统计数据. 面板数据—是截面数据与时间序列数据综合起来的一种数据类型。例如2000、 2001、2002、2003、2004各年中国所有直辖市的GDP分别为(单位亿元):
即区分因变量(被解释变量)和自变量(解释 变量):前者是随机变量,后者不是。
1 .1 变量间的统计关系
• 回归分析构成计量经济学的方法论基础, 其主要内容包括:
– (1)根据样本观察值对经济计量模型的参 数进行估计,求得回归方程;
– (2)对回归方程、参数估计值进行显著性 检验;
– (3)利用回归方程进行分析、评价及预测。
应用回归分析
Applied Regression Analysis
教材 何晓群,刘文卿: 《应用回归分析》第二版, 中国人民大学出版社,2007年
统计软件
SPSS 17.0 最新版本
Statistical Package for the Social Science
章节 目录
第1章 回归分析概述 第2章 一元线性回归 第3章 多元线性回归 第4章 违背基本假定的情况 第5章 自变量选择与逐步回归 第6章 多重共线性的情形及其处理 第7章 岭回归 第8章 非线性回归 第9章 含定性变量的回归模型
自变量含定性变量的情 因变量是定性变量的情
况 况
1 .3 回归分析的主要内容及其一般模型
回归分析的一般形式
y f (x1, x2 , , xp )
随机误差项主要包括下列因素: (1)在解释变量中被忽略的因素的影 (2)变量观测值的观测误差的影响; (3)理论模型设定误差的影响; (3)其他随机因素的影响。
yˆ 33.73 0.516x
1 .3 回归分析的主要内容及其一般模型
一元线性回归
回 归
线性回归 多元线性回归
多个因变量与多个自变 量的回归
讨论如何从数据推断回 归模型基本假设的合理 性
分 析 的 主
回归诊断
当基本假设不成立时如 判定回归方程拟合的效
y
x 图1. 2 y 与x 非确定性关系图
1 .1 变量间的统计关系
• 对变量间统计依赖关系的考察主要是通过相关 分析(correlation analysis)或回归分析 (regression analysis)来完成的
统计依赖关系
正相关 线性相关 不相关 相关系数:
负相关 1 XY 1
第1章 回归分析概述
1 .1 变量间的统计关系 1 .2 回归方程与回归名称的由来 1 .3 回归分析的主要内容及其一般模型 1 .4 建立实际问题回归模型的过程 1 .5 回归分析应用与发展述评
思考与练习
1 .1 变量间的统计关系
函数关系
商品的销售额与销售量之间的关系 y = px 圆的面积与半径之间的关系
北京市 8、9、10、11、12; 上海市 9、10、11、12、13; 天津市 5、6、7、8、9; 重庆市 7、8、9、10、11
2. 注意的问题
( 1) 数据的可比性: 按可比价格计算,扣除价格变动因素,确切反映实物量的变化.
当(2)年统价一格计(报算告口期径n实.如际1G0价Dp格P()按用国价土格原指则数计换算算)成GN可P比(按价国格民. 原则计算).两者包含内
何对数据进行修正 果
选择回归函数的形式回归分析 回归变量的选择
自变量选择的准则 逐步回归分析方法
要 内 容
参数估计方法的改进
岭回归 主成分回归
偏最小二乘法
一元非线性回归
非线性回归
分段回归
多元非线性回归
含有定性变量的回归
1 .2 回归方程与回归名称的由来
1. 回归方程
2. 回归方程的由来
英国著名统计学家F.Galton(1822-1911年)和他的学生、 现代统计学的奠基者之一K.Pearson(1856—1936年)在研究 父母身高与其子女身高的遗传问题时,观察了1 078对夫妇, 他们以成年儿子身高作为纵坐标,夫妇平均身高为横坐标做 散点图,结果发现两者的关系近似于一条直线,经计算得到 如下方程:
相关关系的例子
子女身高 (y)与父亲身高(x)之间的关系 收入水平(y)与受教育程度(x)之间的关系 粮食亩产量(y)与施肥量(x1) 、降雨量(x2) 、温度(x3)之 间的关系 商品的消费量(y)与居民收入(x)之间的关系 商品销售额(y)与广告费支出(x)之间的关系
1 .1 变量间的统计关系
S=R2
、原原材材料料消价耗格额(x与3)之产间量的(x关1) 系、单位产量消耗(x2) y = x1 x2 x3
1 .1 变量间的统计关系
y(万元)
6000 5000 4000 3000 2000 1000
0 0
y = 1000x
123456 x(万辆)
图1.1 函数关系图
1 .1 变量间的统计关系
1 .4 建立实际问题回归模型的过程
实际问题
设置指标变量 收集整理数据 构造理论模型 估计模型参数
模型 N
检验
修改
Y
模型运用
经济因素分析 经济变量控制 经济决策预测
1 .4 建立实际问题回归模型的过程
一、设置指标变量
根据研究目的,利用经济学理论,从定性角度来确定经济问题中各因 素之间的因果关系。 指标变量不容易确定: 1. 认识的局限性; 2. 为了模型参数估计的有效性,设置的解释变量应该是不相关的,可是 在经济问题中很难找到. 3. 从经济学角度考虑应该引进非常重要的经济变量,但是在实际中没有 这样的数据,或数据很难拿到,可以考虑用相近的变量代替,或由其他几 个指标符合成一个新的指标. 4. 并不是模型中所涉及的解释变量越多越好 (1) 可能会引进与问题无关的变量; (2) 容易产生共线性—信息重叠 (3) 计算量大,误差累计大,估计模型参数精度不高.
正相关 非线性相关 不相关
负相关
有因果关系 回归分析 无因果关系 相关分析
1 .1 变量间的统计关系
• 注意 (1)不线性相关并不意味着不相关。 (2)有相关关系并不意味着一定有因果关系。 (3)相关分析对称地对待任何(两个)变量,
两个变量都被看作是随机变量。 (4)回归分析对变量的处理方法存在不对称性,