数据分析实验报告+++内附SAS程序
sas数值分析实验一

广东金融学院实验报告课程名称:图1:四个因素之间Pearson相关系数的结果图2:四个因素之间Spearman相关系数的结果图3:数据的方差分析图图5:数据的单因素方差分析结果图检验假设H0(即是否高企对于企业营业收入没有显著性影响)的p值为0.1931,该值较大,不能拒,认为是否高企对于企业营业收入没有显著性影响。
附录/*导入数据*/PROC IMPORT OUT= MyDatawo.TEST1DATAFILE= "C:\Users\hasee\Desktop\2012年高新区企业数据(修改了变量名).xls"DBMS=EXCEL REPLACE;RANGE="kfq_1$";GETNAMES=YES;MIXED=NO;SCANTEXT=YES;USEDATE=YES;SCANTIME=YES;RUN;/* 整理数据*/data MyDatawo.TestData;set MyDatawo.Test1;if companyProductNum=0then companyProductNum=.;/*如果工业总产值为0的话,将其数据记为缺省值*/if employee=0then employee=.;/*如果从业人数为0的话,将其数据记为缺省值*/run;/*计算数据两两间的Pearson相关系数和Spearman相关系数*/data MyDatawo.TestData1;set MyDatawo.TestData;keep activityPerson money apply authority;/*仅仅保留1、科技活动人员、科技经费、当年申请专利、当年授权专利四个变量进行分析*/run;proc corr data=MyDatawo.TestData1 Spearman pearson cov;run;/*计算回归方程和回归系数分析*/data MyDatawo.TestData2;set MyDatawo.TestData;run;proc reg data=MyDatawo.Testdata2;model companyProductNum = employee activityPerson money apply authority/r cli clm;run;/*单因素方差分析*/data MyDatawo.TestData3;set MyDatawo.TestData;run;proc anova data=MyDatawo.TestData3;class ifHigh;model income=ifHigh;run;。
数据分析SAS报告

90-08年人民消费能力分析一、问题提出改革开放以来中国经济飞速发展,GDP连续超过德国、日本,现以成为世界上第二大经济体,人民生活水平不断提高,但受金融危机的影响,近几年来物价持续上涨,本月CPI创历史新高,人民的消费能力是否随着GDP的增加而增加呢?本文以中国经济年鉴中的“人民消费支出构成”的数据为依据利用统计软件SAS 进行了相关分析。
数据如下食品衣着居住家庭设备用品及服务交通通讯文教娱乐用品及服务医疗保健其他商品及服务1990 58.8000 7.7700 17.3400 5.2900 1.4400 5.3700 3.2500 0.7400 1995 58.6200 6.8500 13.9100 5.2300 2.5800 7.8100 3.2400 1.7600 2000 49.1300 5.7500 15.4700 4.5200 5.5800 11.1800 5.2400 3.1400 2005 45.4800 5.8100 14.4900 4.3600 9.5900 11.5600 6.5800 2.1300 2007 43.0800 6.0000 17.8000 4.6300 10.1900 9.4800 6.5200 2.3000 2008 43.6700 5.7900 18.5400 4.7500 9.8400 8.5900 6.7200 2.0900二、问题分析1、通过对消费种类进行主成分分析判断人民的消费情况。
2、对主成分标准化后在分析各年的消费能力排名。
三、解决问题3.1 SAS程序:data examp4_4;input id x1-x8;cards;1990 58.8000 7.7700 17.3400 5.2900 1.4400 5.3700 3.2500 0.74001995 58.6200 6.8500 13.9100 5.2300 2.5800 7.8100 3.2400 1.76002000 49.1300 5.7500 15.4700 4.5200 5.5800 11.1800 5.2400 3.14002005 45.4800 5.8100 14.4900 4.3600 9.5900 11.5600 6.5800 2.13002007 43.0800 6.0000 17.8000 4.6300 10.1900 9.4800 6.5200 2.30002008 43.6700 5.7900 18.5400 4.7500 9.8400 8.5900 6.7200 2.0900;run;proc corr cov nosimple data=examp4_4;var x1-x8;run;proc princomp data=examp4_4 out=bb;var x1-x8;run;data score1; /*以下程序是对各年按第一主成分得分进行排名并打印结果*/set bb;keep id prin1;proc sort data=score1;by descending prin1;run;proc print data=score1;run;3.2程序结果:SAS 系统 2011年06月14日星期二下午09时09分56秒 1 CORR PROCEDURE8 变量: x1 x2 x3 x4 x5 x6 x7 x8协方差矩阵,自由度 = 5x1 x2 x3 x4 x5 x6 x7 x8x1 52.12778667 5.14183333 -5.43130667 2.34796667 -27.62341333 -11.27958667 -11.80248667 -3.46987333x2 5.14183333 0.67025667 -0.00552333 0.28069333 -2.68378667 -1.67572333 -1.16476333 -0.56306667x3 -5.43130667 -0.00552333 3.60317667 0.02857333 2.46057333 -1.51458333 1.10495667 -0.25200667x4 2.34796667 0.28069333 0.02857333 0.14566667 -1.21211333 -0.81766667 -0.54318667 -0.23039333x5 -27.62341333 -2.68378667 2.46057333 -1.21211333 15.22562667 5.86791333 6.34247333 1.61420667x6 -11.27958667 -1.67572333 -1.51458333 -0.81766667 5.86791333 5.25949667 2.60837667 1.55695333x7 -11.80248667 -1.16476333 1.10495667 -0.54318667 6.34247333 2.60837667 2.71649667 0.73517333x8 -3.46987333 -0.56306667 -0.25200667 -0.23039333 1.61420667 1.55695333 0.73517333 0.61110667Pearson 相关系数, N = 6当 H0: Rho=0 时,Prob > |r|x1 x2 x3 x4 x5 x6 x7 x8x1 1.00000 0.86989 -0.39630 0.85207 -0.98052 -0.68122 -0.99182 -0.614780.0243 0.4367 0.0312 0.0006 0.1362 0.0001 0.1940x2 0.86989 1.00000 -0.00355 0.89832 -0.84012 -0.89250 -0.86320 -0.879790.0243 0.9947 0.0150 0.0363 0.0167 0.0268 0.0208x3 -0.39630 -0.00355 1.00000 0.03944 0.33220 -0.34792 0.35318 -0.169830.4367 0.9947 0.9409 0.5200 0.4992 0.4923 0.7477x4 0.85207 0.89832 0.03944 1.00000 -0.81391 -0.93417 -0.86350 -0.772200.0312 0.0150 0.9409 0.0487 0.0064 0.0267 0.0719x5 -0.98052 -0.84012 0.33220 -0.81391 1.00000 0.65573 0.98620 0.529190.0006 0.0363 0.5200 0.0487 0.1574 0.0003 0.2803x6 -0.68122 -0.89250 -0.34792 -0.93417 0.65573 1.00000 0.69007 0.868450.1362 0.0167 0.4992 0.0064 0.1574 0.1292 0.0248x7 -0.99182 -0.86320 0.35318 -0.86350 0.98620 0.69007 1.00000 0.570590.0001 0.0268 0.4923 0.0267 0.0003 0.1292 0.2370x8 -0.61478 -0.87979 -0.16983 -0.77220 0.52919 0.86845 0.57059 1.000000.1940 0.0208 0.7477 0.0719 0.2803 0.0248 0.2370SAS 系统 2011年06月14日星期二下午09时09分56秒 2 The PRINCOMP ProcedureObservations 6Variables 8Simple Statisticsx1 x2 x3 x4 x5 x6 x7 x8Mean 49.79666667 6.328333333 16.25833333 4.796666667 6.536666667 8.998333333 5.258333333 2.026666667StD 7.21995753 0.818692046 1.89820354 0.381663028 3.902002904 2.293359254 1.648179804 0.781733117Correlation Matrixx1 x2 x3 x4 x5 x6 x7 x8x1 1.0000 0.8699 -.3963 0.8521 -.9805 -.6812 -.9918 -.6148x2 0.8699 1.0000 -.0036 0.8983 -.8401 -.8925 -.8632 -.8798x3 -.3963 -.0036 1.0000 0.0394 0.3322 -.3479 0.3532 -.1698x4 0.8521 0.8983 0.0394 1.0000 -.8139 -.9342 -.8635 -.7722x5 -.9805 -.8401 0.3322 -.8139 1.0000 0.6557 0.9862 0.5292x6 -.6812 -.8925 -.3479 -.9342 0.6557 1.0000 0.6901 0.8685x7 -.9918 -.8632 0.3532 -.8635 0.9862 0.6901 1.0000 0.5706x8 -.6148 -.8798 -.1698 -.7722 0.5292 0.8685 0.5706 1.0000Eigenvalues of the Correlation MatrixEigenvalue Difference Proportion Cumulative1 5.89746633 4.28709253 0.7372 0.73722 1.61037380 1.25296800 0.2013 0.93853 0.35740580 0.23990054 0.0447 0.98324 0.11750526 0.10025645 0.0147 0.99785 0.01724881 0.01724881 0.0022 1.00006 0.00000000 0.00000000 0.0000 1.00007 0.00000000 0.00000000 0.0000 1.00008 0.00000000 0.0000 1.0000EigenvectorsPrin1 Prin2 Prin3 Prin4 Prin5 Prin6 Prin7 Prin8x1 -.388779 -.255521 0.065754 -.053972 -.301799 0.827792 0.000000 0.000000x2 -.399550 0.099491 -.188366 -.430585 0.686086 0.080082 -.009088 0.363823x3 0.044856 0.746089 0.474521 -.307596 -.085587 0.162417 0.260725 -.140969x4 -.392797 0.115755 0.175040 0.698509 0.113186 -.075845 0.471865 0.269326x5 0.376954 0.252020 -.327681 0.389201 0.453421 0.471547 -.050611 -.324084x6 0.362360 -.365307 -.083990 -.262653 0.077957 0.075391 0.804639 0.000000x7 0.387184 0.242582 -.233722 0.041098 -.286309 0.173586 -.063738 0.786613x8 0.331056 -.314568 0.731663 0.083664 0.352742 0.134323 -.234979 0.226790SAS 系统 2011年06月14日星期二下午09时09分56秒 3Obs id Prin11 2005 1.946992 2007 1.571053 2008 1.319374 2000 1.303735 1995 -2.388246 1990 -3.752893.3结果分析利用SAS得到样本的协方差矩阵为S=[52.12779 5.141833 -5.43131 2.347967 -27.6234 -11.2796 -11.8025 -3.46987 5.141833 0.670257 -0.00552 0.280693 -2.68379 -1.67572 -1.16476 -0.56307 -5.43131 -0.00552 3.603177 0.028573 2.460573 -1.51458 1.104957 -0.252012.347967 0.280693 0.028573 0.145667 -1.21211 -0.81767 -0.54319 -0.23039 -27.6234 -2.68379 2.460573 -1.21211 15.22563 5.867913 6.342473 1.614207 -11.2796 -1.67572 -1.51458 -0.81767 5.867913 5.259497 2.608377 1.556953 -11.8025 -1.16476 1.104957 -0.54319 6.342473 2.608377 2.716497 0.735173 -3.46987 -0.56307 -0.25201 -0.23039 1.614207 1.556953 0.735173 0.611107 ]由此看出,各个指标的样本方差差异很大,因此从样本相关系数矩阵出发做主成分分析,得到下面的相关系数矩阵R=[1 0.86989 -0.3963 0.85207 -0.98052 -0.68122 -0.99182 -0.61478 0.86989 1 -0.00355 0.89832 -0.84012 -0.8925 -0.8632 -0.87979 -0.3963 -0.00355 1 0.03944 0.3322 -0.34792 0.35318 -0.16983 0.85207 0.89832 0.03944 1 -0.81391 -0.93417 -0.8635 -0.7722 -0.98052 -0.84012 0.3322 -0.81391 1 0.65573 0.9862 0.52919 -0.68122 -0.8925 -0.34792 -0.93417 0.65573 1 0.69007 0.86845 -0.99182 -0.8632 0.35318 -0.8635 0.9862 0.69007 1 0.57059 -0.61478 -0.87979 -0.16983 -0.7722 0.52919 0.86845 0.57059 1 ]要集中在衣食住行上面,下面我们只取这两个样本做进一步分析,利用SAS得到对应于λ̂1∗和λ̂2∗的正交单位化特征向量ê1∗和ê2∗,如下表*********1123456780.388780.399550.0448560.39280.3769540.362360.3871840.331056y x x x x x x x x =--+-++++*********2123456780.255520.0994910.7460890.1157550.252020.365310.2425820.31457y x x x x x x x x =-++++-+- *1y 和*2y 中关于各项消费水平的指标系数有正有负,说明了消费种类的差异性较大。
SAS与统计分析实验报告

SAS与统计分析实验报告⼀、实习⽬的:1、了解SAS系统的基本知识及操作⽅法。
2、学会运⽤SAS系统进⾏数据的处理与分析。
⼆、实习⼯具:SAS软件三、实习内容:1、T测验①单组样本均数的T测验例:已知某⼩麦品种的平均株⾼为65cm,施肥后,随机抽取10株⼩麦进⾏测量,得到10株⼩麦株⾼分别为64 cm、66 cm、63 cm、68 cm、70 cm、65 cm、67 cm、68 cm、66 cm、69 cm.试验施肥后平均株⾼与已知的平均株⾼65 cm间的差异显著性。
●假如株⾼变量名为G,SAS程序如下:data whq1;input G@@;cards;64 66 63 68 70 65 67 68 66 69;run;proc ttest data=whq1 ci=none h0=65alpha=0.05;var G;run;●程序说明:过程选项h0=65 指定零假设 ho:u=65,检验抽样总体的均值是否为65,alpha=0.05⽤来指定结果中各统计量可信区间的置信⽔平。
语句var G指定要检验的变量。
●程序运⾏结果:The TTEST ProcedureStatisticsLower CL Upper CLVariable N Mean Mean Mean Std Dev Std Err Minimum Maximum G 10 65.011 66.6 68.189 2.2211 0.7024 63 70T-TestsVariable DF t Value Pr > |t|G 9 2.28 0.0487●结果说明:结果中⾸先给出了输⼊数据集中分析变量的有关统计量,其中包括均数及其可信区间、标准差及其可信区间。
然后给出均数的标准误、观测值最⼤值和最⼩值。
最后,给出单组样本均数⽐较的T检验结果。
本例中t=2.28,对应的P值为0.0487。
根据分析结果可作出结论:施肥后平均株⾼与已知的平均株⾼65 cm有显著差异。
SAS数据分析实验报告
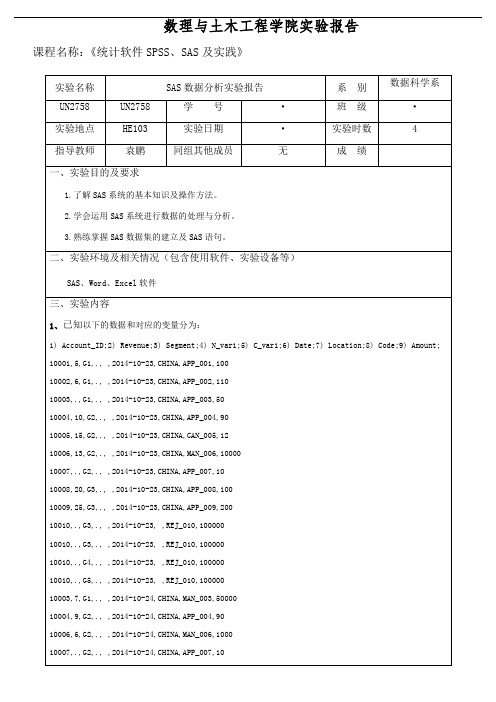
数理与土木工程学院实验报告课程名称:《统计软件SPSS、SAS及实践》实验结果(包括程序代码、程序结果分析)第一题:①读取数据,并创建一个SAS数据集,命名为transaction;data transaction;infile cards dlm=",";input Account_ID Revenue Segment N_var1 C_var1 Date Location Code Amount;cards;10001,5,G1,., ,2014-10-23,CHINA,APP_001,10010002,6,G1,., ,2014-10-23,CHINA,APP_002,11010003,.,G1,., ,2014-10-23,CHINA,APP_003,5010004,10,G2,., ,2014-10-23,CHINA,APP_004,9010005,15,G2,., ,2014-10-23,CHINA,CAN_005,1210006,13,G2,., ,2014-10-23,CHINA,MAN_006,1000010007,.,G2,., ,2014-10-23,CHINA,APP_007,1010008,20,G3,., ,2014-10-23,CHINA,APP_008,10010009,25,G3,., ,2014-10-23,CHINA,APP_009,20010010,.,G3,., ,2014-10-23, ,REJ_010,10000010010,.,G3,., ,2014-10-23, ,REJ_010,10000010010,.,G4,., ,2014-10-23, ,REJ_010,10000010010,.,G5,., ,2014-10-23, ,REJ_010,10000010003,7,G1,., ,2014-10-24,CHINA,MAN_003,5000010004,9,G2,., ,2014-10-24,CHINA,APP_004,9010006,6,G2,., ,2014-10-24,CHINA,MAN_006,100010007,.,G2,., ,2014-10-24,CHINA,APP_007,1010008,8,G3,., ,2014-10-24,CHINA,APP_008,10010009,9,G3,., ,2014-10-24,CHINA,APP_009,20010010,.,G3,., ,2014-10-24,CHINA,APP_010,10010010,10,G4,., ,2014-10-24,CHINA,APP_011,10110010,20,G5,., ,2014-10-24,CHINA,APP_012,102;run;proc transpose data=transaction out=a;var _all_;run;②基于数据集transaction,将变量“Revenue”中的缺失数据用其均值代替;data a;set a;array s(*) aa1-aa2;n=n(of s(*));mean=mean(of s(*));sum=sum( of s(*));do i=1to dim(s);if s(i)=.then s(i)=mean;end;run;proc print;run;③基于②,将取值全部缺失的变量删除。
多元统计分析实验报告计算协方差矩阵相关矩阵SAS

多元统计分析实验报告计算协方差矩阵相关矩阵SAS实验目的:通过对多元统计分析中的协方差矩阵和相关矩阵的计算,探究变量之间的相关性,并使用SAS进行实际操作。
实验步骤:1.数据准备:选择一个数据集,例如学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
2.数据整理:将数据转化为矩阵形式,每一行代表一个学生,每一列代表一个变量(即成绩),记为X。
3. 计算协方差矩阵:根据公式计算协方差矩阵C,其中元素Cij表示变量Xi和Xj之间的协方差。
计算公式为Cij = cov(Xi, Xj) = E((Xi - u_i)(Xj - u_j)),其中E为期望值,u_i和u_j分别是变量Xi和Xj的均值。
4. 计算相关矩阵:根据协方差矩阵计算相关矩阵R,其中元素Rij表示变量Xi和Xj之间的相关性。
计算公式为Rij = cov(Xi, Xj) / (sigma_i * sigma_j),其中sigma_i和sigma_j分别是变量Xi和Xj的标准差。
5.使用SAS进行实际操作:使用SAS软件导入数据集,并使用PROCCORR和PROCPRINT命令进行协方差矩阵和相关矩阵的计算和输出。
实验结果:通过计算协方差矩阵和相关矩阵,可以得到变量之间的相关性信息。
协方差矩阵的对角线上的元素表示每个变量的方差,非对角线上的元素表示不同变量之间的协方差。
相关矩阵的对角线上的元素都是1,表示每个变量与自身的相关性为1,非对角线上的元素表示不同变量之间的相关性。
使用SAS进行实际操作后,我们可以得到一个包含协方差矩阵和相关矩阵的输出表格。
该表格可以帮助我们更直观地理解变量之间的相关性情况,从而为后续的统计分析提供参考。
实验总结:通过本次多元统计分析实验,我们了解了协方差矩阵和相关矩阵的计算方法,并使用SAS软件进行实际操作。
这些矩阵可以帮助我们评估变量之间的相关性,为后续的统计分析提供重要的基础信息。
在实际应用中,我们可以根据协方差矩阵和相关矩阵的结果,选择合适的统计方法和模型,并做出恰当的推断和决策。
数据分析实验报告

实验一SAS系统的使用【实验类型】(验证性)【实验学时】2学时【实验目的】使学生了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。
【实验内容】1. 启动SAS系统,熟悉各个菜单的内容;在编辑窗口、日志窗口、输出窗口之间切换。
2. 建立数据集表1Name Sex Math Chinese EnglishAlice f908591Tom m958784Jenny f939083Mike m808580Fred m848589Kate f978382Alex m929091Cook m757876Bennie f827984Hellen f857484Wincelet f908287Butt m778179Geoge m868582Tod m898484Chris f898487Janet f8665871)通过编辑程序将表1读入数据集sasuser.score;2)将下面记事本中的数据读入SAS数据集,变量名为code name scale shareprice:000096 广聚能源8500 0.059 1000 13.27000099 中信海直6000 0.028 2000 14.2000150 ST麦科特12600 -0.003 1500 7.12000151 中成股份10500 0.026 1300 10.08000153 新力药业2500 0.056 2000 22.753)将下面Excel表格中的数据导入SAS数据集work.gnp;name x1 x2 x3 x4 x5 x6 北京190.33 43.77 7.93 60.54 49.01 90.4 天津135.2 36.4 10.47 44.16 36.49 3.94 河北95.21 22.83 9.3 22.44 22.81 2.8 山西104.78 25.11 6.46 9.89 18.17 3.25 内蒙古128.41 27.63 8.94 12.58 23.99 3.27 辽宁145.68 32.83 17.79 27.29 39.09 3.47 吉林159.37 33.38 18.37 11.81 25.29 5.22 黑龙江116.22 29.57 13.24 13.76 21.75 6.04 上海221.11 38.64 12.53 115.65 50.82 5.89 江苏144.98 29.12 11.67 42.6 27.3 5.74 浙江169.92 32.75 21.72 47.12 34.35 5 安徽153.11 23.09 15.62 23.54 18.18 6.39 福建144.92 21.26 16.96 19.52 21.75 6.73 江西140.54 21.59 17.64 19.19 15.97 4.94 山东115.84 30.76 12.2 33.1 33.77 3.85 河南101.18 23.26 8.46 20.2 20.5 4.3 湖北140.64 28.26 12.35 18.53 20.95 6.23 湖南164.02 24.74 13.63 22.2 18.06 6.04 广东182.55 20.52 18.32 42.4 36.97 11.68 广西139.08 18.47 14.68 13.41 20.66 3.85 四川137.8 20.74 11.07 17.74 16.49 4.39 贵州121.67 21.53 12.58 14.49 12.18 4.57 云南124.27 19.81 8.89 14.22 15.53 3.03 陕西106.02 20.56 10.94 10.11 18 3.29 甘肃95.65 16.82 5.7 6.03 12.36 4.49 青海107.12 16.45 8.98 5.4 8.78 5.93 宁夏113.74 24.11 6.46 9.61 22.92 2.53新疆123.24 38 13.72 4.64 17.77 5.753. 将sasuser.score数据集的内容复制到一个临时数据集test,要求只包含变量name, sex, math。
SAS数据分析实验报告
SAS数据分析实验报告摘要:本文使用SAS软件对一组数据集进行了分析。
通过数据清洗、数据变换、数据建模和数据评估等步骤,得出了相关的结论。
实验结果表明,使用SAS软件进行数据分析可以有效地处理和分析大型数据集,得出可靠的结论。
1.引言数据分析在各个领域中都扮演着重要的角色,可以帮助人们从大量的数据中提取有用信息。
SAS是一种常用的数据分析软件,被广泛应用于统计分析、商业决策、运营管理等领域。
本实验旨在探究如何使用SAS软件进行数据分析。
2.数据集描述本实验使用了一个包含1000个样本的数据集。
数据集包括了各个样本的性别、年龄、身高、体重等多种变量。
3.数据清洗在进行数据分析之前,首先需要对数据进行清洗。
数据清洗包括缺失值处理、异常值处理和重复值处理等步骤。
通过使用SAS软件中的相应函数和命令,我们对数据集进行了清洗,确保数据的质量和准确性。
4.数据变换在进行数据分析之前,还需要对数据进行变换。
数据变换包括数据标准化、数据离散化和数据归一化等操作。
通过使用SAS软件中的变换函数和操作符,我们对数据集进行了变换,使其符合分析的需要。
5.数据建模数据建模是数据分析的核心过程,包括回归分析、聚类分析和分类分析等。
在本实验中,我们使用SAS软件的回归、聚类和分类函数,对数据集进行了建模分析。
首先,我们进行了回归分析,通过拟合回归模型,找到了自变量对因变量的影响。
通过回归模型,我们可以预测因变量的值,并分析自变量的影响因素。
其次,我们进行了聚类分析,根据样本的特征将其分类到不同的群组中。
通过聚类分析,我们可以发现样本之间的相似性和差异性,从而做出针对性的决策。
最后,我们进行了分类分析,根据样本的特征判断其所属的类别。
通过分类分析,我们可以根据样本的特征预测其所属的类别,并进行相关的决策。
6.数据评估在进行数据分析之后,还需要对结果进行评估。
评估包括模型的拟合程度、变量的显著性和模型的稳定性等。
通过使用SAS软件的评估函数和指标,我们对数据分析的结果进行了评估。
sas实验报告
sas实验报告SAS实验报告。
一、实验目的。
本实验旨在通过使用SAS软件对实验数据进行分析,掌握SAS软件的基本操作和数据处理技能,进一步提高数据分析能力。
二、实验内容。
1. 数据导入,将实验数据导入SAS软件中,建立数据集。
2. 数据清洗,对数据进行缺失值处理、异常值处理等清洗工作,保证数据的准确性和完整性。
3. 描述统计分析,对数据进行描述性统计分析,包括均值、标准差、频数分布等。
4. 数据可视化,利用SAS软件绘制数据的直方图、箱线图等可视化图表,直观展现数据分布情况。
5. 假设检验,对数据进行假设检验,验证数据之间的关系和差异性。
三、实验步骤。
1. 数据导入,首先打开SAS软件,利用导入数据功能将实验数据导入SAS环境中,创建数据集。
2. 数据清洗,对导入的数据进行缺失值处理和异常值处理,保证数据的完整性和准确性。
3. 描述统计分析,利用SAS软件进行描述统计分析,得出数据的均值、标准差、频数分布等统计指标。
4. 数据可视化,利用SAS软件绘制数据的直方图、箱线图等可视化图表,直观展现数据的分布情况。
5. 假设检验,利用SAS软件进行假设检验,验证数据之间的关系和差异性。
四、实验结果分析。
通过SAS软件的操作,我们成功完成了对实验数据的导入、清洗、描述统计分析、数据可视化和假设检验等工作。
通过分析结果,我们得出了实验数据的基本特征和规律,验证了数据之间的关系和差异性,为进一步的数据分析工作奠定了基础。
五、实验总结与体会。
通过本次实验,我们深刻体会到了SAS软件在数据分析领域的强大功能和广泛应用。
掌握了SAS软件的基本操作和数据处理技能,提高了数据分析能力。
同时,也加深了对数据分析方法和技巧的理解和应用,为今后的科研工作打下了坚实的基础。
六、参考文献。
[1] 《SAS统计分析实战指南》。
[2] 《SAS数据分析与挖掘实战》。
七、附录。
实验数据集,xxx.xlsx。
以上为本次SAS实验报告的全部内容。
数据分析实验报告分析解析
word格式文档实验课程:数据分析专业:信息与计算科学班级:学号:姓名:中北大学理学院实验一 SAS系统的使用【实验目的】了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。
【实验内容】1. 将SCORE数据集的内容复制到一个临时数据集test。
SCORE数据集Name Sex Math Chinese EnglishAlice f 90 85 91Tom m 95 87 84Jenny f 93 90 83Mike m 80 85 80Fred m 84 85 89Kate f 97 83 82Alex m 92 90 91Cook m 75 78 76Bennie f 82 79 84Hellen f 85 74 84Wincelet f 90 82 87Butt m 77 81 79Geoge m 86 85 82Tod m 89 84 84Chris f 89 84 87Janet f 86 65 872.将SCORE数据集中的记录按照math的高低拆分到3个不同的数据集:math 大于等于90的到good数据集,math在80到89之间的到normal数据集,math 在80以下的到bad数据集。
3.将3题中得到的good,normal,bad数据集合并。
【实验所使用的仪器设备与软件平台】SAS【实验方法与步骤】1:DATA SCORE;INPUT NAME $ Sex $ Math Chinese English;CARDS;Alice f 90 85 91Tom m 95 87 84Jenny f 93 90 83Mike m 80 85 80Fred m 84 85 89Kate f 97 83 82Alex m 92 90 91Cook m 75 78 76Bennie f 82 79 84Hellen f 85 74 84Wincelet f 90 82 87Butt m 77 81 79Geoge m 86 85 82Tod m 89 84 84Chris f 89 84 87Janet f 86 65 87;Run;PROC PRINT DATA=SCORE;DATA test;SET SCORE;2:DATA good normal bad;SET SCORE;SELECT;when(math>=90) output good;when(math>=80&math<90) output normal; when(math<80) output bad;end;Run;PROC PRINT DATA=good;PROC PRINT DATA=normal;PROC PRINT DATA=bad;3:DATA All;SET good normal bad;PROC PRINT DATA=All;Run;【实验结果】结果一:结果二:结果三:实验二上市公司的数据分析【实验目的】通过使用SAS软件对实验数据进行描述性分析和回归分析,熟悉数据分析方法,培养学生分析处理实际数据的综合能力。
实验报告5——SAS编程基础
实验报告实验项目名称SAS编程基础所属课程名称现代统计软件实验类型验证性实验实验日期2014-10-11班级学号姓名成绩(2)相关系数计算其中第二张表给出回归方程:ˆ从图中看出,数据点随机地散布在零线附近,表明模型中残差等方差、题。
在上图右下中指出在0.05的检验水平下,不能再有其它变量进入模型。
比较R2和从标准化后的残差图看出,数据点随机地散布在零线附近,表明模型中误差等方差、的假设没有问题。
残差的QQ图近似一条直线,可以初步判定残差来自正态分布总体,20 26.1025 20.2830 19.9635 14.9940 14.3045 14.7050 13.90;run;title'数据集zy3';proc print;run;(2)对x和y作相关分析/*画x和y的散点图*/goptions ftext='宋体';proc gplot data = zy3;plot y*x;title'x和y的散点图';symbol v=dot i=none cv=orange ; run;/*求x和y的相关系数*/proc corr data = zy3;var x y;run;bay 1+ =by=回归ax(4)幂函数(5)指数函数bx ae y 回归data new3; set zy3;得回归方程:v = 4.25934 – 0.03876u(7) 结论实验报告说明1.实验项目名称:要用最简练的语言反映实验的内容。
要求与实验指导书中相一致。
2.实验类型:一般需说明是验证型实验还是设计型实验,是创新型实验还是综合型实验。
3.实验目的与要求:目的要明确,要抓住重点,符合实验指导书中的要求。
4.实验原理:简要说明本实验项目所涉及的理论知识。
5.实验环境:实验用的软硬件环境(配置)。
6.实验方案设计(思路、步骤和方法等):这是实验报告极其重要的内容。
概括整个实验过程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据分析实验报告三
课程名称:数据分析之典型性相关分析学院:
专业班:
姓名:
学号:
指导教师:
2008年 12月 8日
1. 实验名称直线回归分析(可直线化的曲线拟合)
2. 实验日期08年12月8日得分
3. 实验仪器:计算机及SAS软件。
4. 实验目的和要求:通过上机编程练习,学会SAS中proc reg,proc plot等过程的使用,学会如何使用SAS获取结果并分析结果。
5. 实验内容和原理:
问题:农药的生测实验:农夫菊酯原药对甜菜夜蛾的生测,用的是点滴法。
X指功夫原药的浓度(ppm),y是四龄甜菜夜蛾的死亡率。
研究并拟合甜菜夜蛾死亡率y与功夫原药浓度x 之间的曲线方程。
6.实验结果与分析:
程序
data reg6_8;
input x y @@;
y1=log(y);
x1=log(x);
cards;
25 20 50 30.5 100 47 200 52.0 400 67 800 87
;
ods html body = ‘reg6_8.htm’;
proc plot;
plot y*x y1*x y*x1 y1*x1;
run;
proc reg;
model y=x;
model y=x1;
model y1=x;
model y1=x1;
run;
quit;
程序说明:DATA步中的y1=log(y);x1=log(x);语句分别表示取y和x的自然对数,即
y1=ln(y),x1==ln(x)(如果取以10为底的对数数据,则需写成:y1=log10(y),x1=log10(x))。
假如还需要对原始数据y作倒数或平方根变换,则可在DATA步中的CARDS语句行之前插入语句:y2=1/y;y3=sqrt(y);。
注意:数据中有零值时不能进行对数和倒数变换,有负数时不能进行对数和平方根变换。
程序中原变量为x,y,则REG过程中的第1个MODEL语句是拟合直线方程:y=a+bx。
第2个MODEL语句是拟合对数曲线方程:y=a+bln(x),令x1=ln(x),
就使曲线直线化了。
第3个MODEL语句是拟合指数曲线方程:
bx
Ae
y=,即bx
a
e
y+
=,这
里,
a
e
A=,对此方程的两边同时去自然对数,就使曲线直线化了:y1=a+bx,这里y1=ln(y)。
第4个MODEL语句是为了拟合幂函数曲线:
b
Ax
y=,对此方程的两边同时取自然对数,
就使曲线直线化了:y1=a+bx1,这里y1=ln(y),x1=ln(x),a=ln(A)。
输出结果:
x1
这是:y=a+bln(x)的散点图。
这是:y1=a+bx1的散点图。
这里y1=ln(y),x1=ln(x),a=ln(A)。
这是第1个MODEL语句拟合的直线方程:y=30.37065+0.077x 。
从统计学角度看,模型的Pr>F=0.0053,小于0.01,是极显著的:截矩项和自变量x的p值均小于0.01,都是极显著的。
模型R-Square=0.8840,F=30.47。
这是第2个MODEL语句拟合的直线化的曲线方y^=-41.16419+18.52833x1, x1=ln(x)。
从统计学角度看,模型的Pr>F=0.0002,截矩项和自变量ln(x)的p值均小于0.01,
R-Square=0.9787,F=183.92,比第1个模型有很大的改善。
对数曲线方程为:y^=-41.16419+18.52833ln(x)
从专业知识角度看来说,根据此方程可以解释为:甜菜夜蛾死亡率y与功夫原药浓度x 的对数呈线性关系。
这是第3个MODEL语句拟合的直线化的曲线方程,模型的F值和R-Square值都没有前两个好,不选择它。
这是第4个MODEL语句拟合的直线化的曲线方程:ln(y^)=1.81133+0.40449ln(x)。
从统计学角度看,模型的Pr>F=0.0004,截矩项和自变量x1(即ln(x))的p值均小于0.01,R-Square=0.9658,F=112.86,比第2个模型的效果稍差一点。
第4个模型可以表示为:
)
*ln(
40449
.0
1081133*
)]
ln(
40449
.0
81133
.1
exp[
^x
e
e
x
y=
+
=
写成幂函数曲线方程为:
4985
.1
*
11858
.6
^x
y=
从专业知识角度来说,此方程可以理解为:甜菜夜蛾死亡率y与功夫原药浓度x有幂函数关系。
值得注意的是:除了第3个模型统计效果不如其他3个模型外,1,2,4这三个模型及其截矩、斜率系数的检验结果都呈显著性,各项的自由度也分别相等。
如果分析目的在于比较这3个曲线方程拟合同一批数据是否有显著差别,则需作曲线拟合优度的相互比较,吃用F检验,即:
F=较大剩余方差/较小剩余方差,然后,查方差齐性检验用的F临界值表得到p值。
使
曲线方程的剩余平方和等于∑-2^)
(y
y。
上述4个简单的曲线方程中都只有2个待估参数
(截矩与斜率),故剩余自由度都是n-2。
若是k次多项式曲线,当k=1时(即直线),剩余自由度df=n-2;当k=2时,剩余自由度df=n-3……..本题的目的是从3条看似较好的曲线中选择1条较优的模型进行实际应用,故只需看F值即可。
模型2的F值为183.92,模型4的F值为112.86,模型1的F 值仅为30.47。
由于模型2的F值最大,相对来说稍好些,即此试验数据用对数曲线方程拟合效果较好。