第08章 相关与回归分析
统计学简答题整理

统计学简答题整理第一章P111.获取直接统计数据的渠道主要有哪些?及区别在于?普查、抽样调查普查是为某一特定目的,专门组织的一次性全面调查。
这是一种摸清国情、国力的重要调查方法。
花费的时间、人力、财力和物力都较大,间隔的时间较长。
而两次普查之间的年份以抽样调查方法获得连续的统计数据。
抽样调查是统计调查中应用最广、最为重要的调查方法,它是通过随机样本对总体数量规律性进行推断的调查研究方法。
存在着由样本推断总体产生的抽样误差,但统计方法可以估计出误差的大小进一步控制误差;节省人力、财力、物力,又能保证实效性2.简要说明抽样误差和非抽样误差。
非抽样误差是由于调查过程中各有关环节工作失误造成的。
(它包括调查方案中有关规定或解释不明确所导致的填报错误、抄录错误、汇总错误,不完整的抽样框导致的误差,调查中由于被调查者不回答产生的误差,还有一种人为干扰造成的误差即有意瞒报或低报数据等)。
非抽样误差在普查、抽样调查中都有可能发生,但可以避免。
抽样误差是利用样本推断总体时产生的误差。
(由于样本只是总体的一部分,用样本的信息去推断总体,或多或少总会存在误差,因而抽样误差对任何一个随机样本来讲都是不可避免的。
但可计量、可控制)。
抽样误差与样本量的平方根成反比关系。
第二章P511.统计的计量尺度①列名尺度(定类尺度):是按照某一品质标志将总体分组之后,对属性相同的单位进行计量的方法。
各组之间的关系是并列的,没有大小、高低、先后之别。
②顺序尺度(定序尺度):是按照某一品质标志将总体分组,对等级相同的单位进行计量的方法。
各组之间的关系是有顺序的,可以进行排序。
③间隔尺度(也称定距尺度):是按某一数量标志将总体分组,对相同数量或相同数量范围的单位或其标志值进行计量的方法。
其特点是不仅可以进行排序,还可以计算不同数值之间的绝对差距。
④比例尺度(也称定比尺度):是类似于间隔尺度,又高于间隔尺度的计量方法。
其特点是不仅可计算数值的绝对差异,还可以计算数值的相对差异。
回归分析与相关分析

回归分析与相关分析回归分析是通过建立一个数学模型来研究自变量对因变量的影响程度。
回归分析的基本思想是假设自变量和因变量之间存在一种函数关系,通过拟合数据来确定函数的参数。
回归分析可以分为线性回归和非线性回归两种。
线性回归是指自变量和因变量之间存在线性关系,非线性回归是指自变量和因变量之间存在非线性关系。
回归分析可用于预测、解释和控制因变量。
回归分析的应用非常广泛。
例如,在经济学中,回归分析可以用于研究收入与消费之间的关系;在医学研究中,回归分析可以用于研究生活方式与健康之间的关系。
回归分析的步骤包括确定自变量和因变量、选择合适的回归模型、拟合数据、检验模型的显著性和解释模型。
相关分析是一种用来衡量变量之间相关性的方法。
相关分析通过计算相关系数来度量变量之间的关系的强度和方向。
常用的相关系数有Pearson相关系数、Spearman相关系数和判定系数。
Pearson相关系数适用于连续变量,Spearman相关系数适用于顺序变量,判定系数用于解释变量之间的关系。
相关分析通常用于确定两个变量之间是否相关,以及它们之间的相关性强度和方向。
相关分析的应用也非常广泛。
例如,在市场研究中,相关分析可以用于研究产品价格与销量之间的关系;在心理学研究中,相关分析可以用于研究学习成绩与学习时间之间的关系。
相关分析的步骤包括确定变量、计算相关系数、检验相关系数的显著性和解释相关系数。
回归分析与相关分析的主要区别在于它们研究的对象不同。
回归分析研究自变量与因变量之间的关系,关注的是因变量的预测和解释;相关分析研究变量之间的关系,关注的是变量之间的相关性。
此外,回归分析通常是为了解释因变量的变化,而相关分析通常是为了量化变量之间的相关性。
综上所述,回归分析和相关分析是统计学中常用的两种数据分析方法。
回归分析用于确定自变量与因变量之间的关系,相关分析用于测量变量之间的相关性。
回归分析和相关分析在实践中有广泛的应用,并且它们的步骤和原理较为相似。
第八讲非线性回归分析

线性对数回归函数
因为该模型中Y是对数形式而X不是, 所以有时称它为对数线性模型。
如何理解β1的含义
在线性对数模型中, β1 表示X变化1个 单位引起Y的变化为(100*β1)%。
推导:我们考察自变量X变化∆X的过程。
此时: f ( X X ) f ( X ) ln(Y Y ) ln(Y ) ( Y ) Y
对数形式
对数形式经常用于表示变量的百分率变 化。例如:
在消费者需求的经济分析中,通常假定 价格上涨1%导致需求量下降一定的 百 分率。称价格上涨1%引起的需求下降 百分率为价格弹性(elasticity)。
对数形式是经济学中最常用的形式,广泛地应用在 各个领域中:
例如:在宏观经济学中,我们如果想研究投资的增
但当回归函数为非线性时,由于Y的预期 变化依赖于自变量的取值,因此其计算 较复杂。
我们假定非线性总体回归的一般公式为
书中的两个例子
1。地区收入从10----11(单位是千美 元)
2。地区收入从40----41
Yˆ (607.3 3.8511 0.0423112 ) (607.3 3.8510 0.0423102 ) 2.96 Yˆ (607.3 3.85 41 0.0423 412 ) (607.3 3.85 40 0.0423 402 ) 0.42
可以看出,income对testscore的弹性 逐渐变小。
效应估计的标准误差
在上例中
利用多元回归建立非线性模型的 一般方法
(1)确定一种可能的非线性关系。最佳做法 是利用经济理论和你对实际应用的了解提出 一种可能的非线性关系。在看数据之前,问 自己联系Y和X的回归函数斜率是否依赖于X 或其他自变量的取值。
当d1=0(男性) 对Y的效应为β2 当d1=1(女性) 对Y的效应为β2+β3
《基础统计》教学资源2014.07.08 第七章 相关与回归思考

第七章 相关与回归分析参考答案一、填空题1.单 复 2.正 负 3. 线性 相关密切程度 4.两个变量 多个变量5.相关系数 6.微弱相关 低度相关 显著相关 高度相关7.最小二乘法 8、直线的截距 直线的斜率 正 向上倾斜的直线 负 向下倾斜的直线 二、选择题1.B 2.C 3.B 4.B 5.ABDE 6.C 7.C 8.ABC 9、ABE 10、 AD 11. ABD 12. AD 13. C 14. A 二、判断题1.X 2. √ 3. X 4.√ 5.X 6.X 7.√ 8.√ 9、 X 10、√ 三、计算题1. 解:(1)、0.94n xy x y r -==(2)、1226.92()n xy x y b n x x -==-∑∑∑∑∑,0139.09b y b x =-=,ˆ39.09 6.92yx ∴=+ (3)、0ˆ39.09 6.9213129.05y ∴=+⨯=,查表0.0252(2)(8) 2.306t n t α-==∴y 的95%的置信区间为()4.解:(1)、1222()n xy x y b n x x -==--∑∑∑∑∑,0121b y b x =-=ˆ212yx ∴=- 产量每增加10000件,单位成本会下降2元。
(2)、ˆ212y x ∴=-,0 6.5x =,0ˆ212 6.58y ∴=-⨯=由于x 和y 之间是1对1的函数关系,所以y 的实际值就是8,无区间预测。
5.解:(1)、0.977n xy x y r -==(2)、1220.68()n xy x y b n x x -==--∑∑∑∑∑,01138.92b y b x =-=ˆ138.920.68yx ∴=- 回归系数表示:价格每上升1个单位,需求量就相应地降低个单位。
6.解:(1)(2)通过散点图可以看出,x 和y 之间大致呈现出线性关系。
(3)、1223.87()n xy x y b n x x -==-∑∑∑∑∑,01 5.71b y b x =-=ˆ 5.71 3.87yx ∴=+ (4)、1b 的置信区间为(,)0b 的置信区间为(,)7. 解:这样的问题可以建立结果和影响因素之间的相关方程来解决。
概率论课件_高教版_第八章_方差分析与回归分析

MS A 168.00 F 20.56 MS e 8.17
查附表在f1=3,f2=12时, F0.05=3.49,F0.01=5.95 实得 F> F0.01或 P<0.01,说明药剂处理有统计意义。
四、单因素方差分析模型参数的估计 当方差分析结果为否定原假设时,就需要估计模型的有 关参数 ,下面就讨论方差分析模型参数的估计。 单因素方差分析的模型 为 xij i ij i 1,2, , r 2 ~ N ( 0 , ), 且相互独立 j 1,2, , m ij 其中为总以平均效应, i为因素A的第i个水平Ai 对试验指标 的作用; ij为随机因素对试验指标 值的影响。需要估计的 参数 有 , i , 2。不难证明这些参数的 极大似然估计量为: 1 r m 1 m 1 r m ˆ i xij ˆ xij xij rm i 1 j 1 m j rm i 1 j 1 1 r m 1 2 2 ˆ ˆ) ( xij SSe rm i 1 j 1 rm
Tr
T
xr
x
其中xij是因素A第i水平下第j次重复试验结果 , m r m r T T Ti xij xi T xij Ti x . m rm j 1 i 1 j 1 i 1
单因素方差分析的统计模型
试验数据xij满足 xij i ij i 1,2,, r 2 ~ N ( 0 , ),且相互独立 j 1,2,, m ij 其中为总以平均效应, i为因素A的第i个水平Ai 对试验指 标的作用 ; ij为随机因素对试验指标 值的影响。
鸡重/g-1000
60 80 1 2 12 9 28
Ti
08一元线性回归模型
第2章 一元线性回归模型2.0 通过案例学习回归分析案例1 中国宏观消费分析(file:china )摘自经济蓝皮书《2004年:中国经济形势分析与预测》和《经济计量分析》第1章案例。
按照我国现行国民经济核算体系,国内生产总值(按支出法计算)是由最终消费、资本形成总额和货物与服务的净出口之和三部分组成。
前两部分占绝大多数。
其中最终消费又分为居民消费和政府消费两类。
而居民消费又可分为农村居民消费和城镇居民消费。
在这种核算体系下,居民消费包括居民个人日常生活中衣、食、住、用等物质消费以及在文化生活服务性支出中属于物质产品的消费。
政府消费包括国家机关、国防、治安、文教、卫生、科研事业单位,经济建设部门的事业单位,人民团体等非生产机构使用的燃料、电力、办公用品、图书、设备等物质消费。
国内生产总值中最终消费与资本形成总额的比例关系,即旧核算体系下国民收入中消费与积累的比例关系是国民经济正常运行的最基本的比例关系。
如果这一比例关系发生严重失调,最终会成为制约经济正常运行的严重障碍。
下面分析中国的消费问题。
为消除物价变动因素以及异方差的影响,以下分析所用的数据均为不变价格数据(1952 = 1)以及分别取自然对数后的数据。
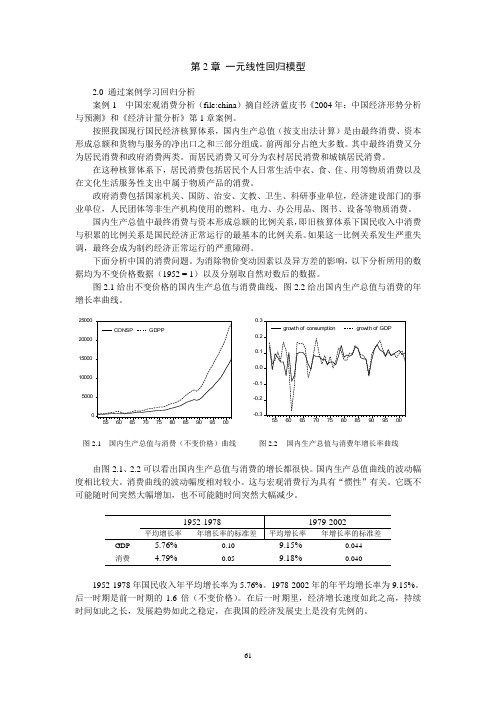
图2.1给出不变价格的国内生产总值与消费曲线,图2.2给出国内生产总值与消费的年增长率曲线。
50001000015000200002500055606570758085909500CONSPGDPP-0.3-0.2-0.10.00.10.20.355606570758085909500growth of consumptiongrowth of GDP图2.1 国内生产总值与消费(不变价格)曲线 图2.2 国内生产总值与消费年增长率曲线由图2.1、2.2可以看出国内生产总值与消费的增长都很快。
国内生产总值曲线的波动幅度相比较大。
消费曲线的波动幅度相对较小。
这与宏观消费行为具有“惯性”有关。
它既不可能随时间突然大幅增加,也不可能随时间突然大幅减少。
第八章相关与回归分析Correlation and Regression Analysis
象的相关关系必须借助于统计学中的相关与回归分析方法。
Chap 08-4
相关关系的类型
从相关关系涉及的变量数量看:单相关和复相关 一个变量对另一变量的相关关系,称为单相关; 一个变量对两个以上变量的相关关系时,称为复相关; 从变量相关关系的表现形式看:线性相关和非线性相关 从变量相关关系变化的方向看:正相关和负相关 从变量相关的程度看:完全相关〔函数关系〕、不完全相
或:
r
n xtyt xt yt
[n ( xt2)( xt)2]n [( yt2)( yt)2]
Chap 08-7
2 简单线性相关与回归分析
2.1 简单线性相关系数及检验 2.2 总体回归函数与样本回归函数 2.3 回归系数的估计 2.4 简单线性回归模型的检验 2.5 简单线性回归模型预测
Chap 08-8
相关系数
总体相关系数〔 population correlation coefficient〕 ρ 是反映两变量之间线性相关程度的 一种特征值,表现为一个常数。
关、不相关
Chap 08-5
相关分析与回归分析
而样本回归函数中 的和 是随机变量,其具体数值随所抽取的样本观测值不同而变动。
是当 x 等于 0 时 y 的平均估计值 S越小说明实际观测点与所拟合的样本回归线的离差程度越小,即样本回归线具有较强的代表性,反之,S越大说明实际观测点与所拟 合的样本回归线的离差程度越大,即回归线的代表性越差。
Chap 08-1
本节学习目标
通过本节的学习,你应该能够:
理解和掌握相关分析和回归分析的原理 估计一元线性回归模型,并对模型进行检验 利用计算机软件估计多元线性回归模型,并对模型进行
注册环保工程师基础考试经验分享
本人今年参加了注册环保工程师基础考试,因为复习的比较充分,考的还可以,估计有上午90,下午90,总分180左右。
在论坛里收获了很多,因此把自己的复习经验和心得写出来,作为回报吧。
首先强调一点:注册环保是从07年开始报考,每年9月份举行一次,全国统一,至今举办了07、08,、09、10共4次。
上午的公共基础是和注册结构,注册土木,注册电气等等是一样的。
基础考试考1天,上午4个小时,为公共基础,120道题,每题1分;下午也是4个小时,为专业基础,60道题,每题2分。
基础考试的合格线是上下午的总分划定,不单独设合格标准。
07年-09年基础考试的合格线一直是满分240分,132分合格。
通过率全国在10%上下浮动。
一、上午公共基础复习用书选择和复习建议。
(1)用书选择上午绝大部分人用的是天津大学出的《注册环保工程师执业资格考试基础考试(上)复习教程》(简称天大版),这本书是目前市面上最好的一本辅导教材,特点是知识点很细,贴近考试,每门科目后面有和考试完全一样的选择题来巩固,题目难度和考试相当,缺点是内容很杂,上午共11门课,全书816页,题目2000多道,要想全部看完并做完课后习题大概要300个小时。
(注:这本书10年出了新版,加了法律,其他部分没有任何变化。
)具体购买方式可以去网上书店,新华书店等。
另外机械工业出版社出版了考试中心的一套共4册,全名是《全国勘察设计注册工程师公共基础考试辅导丛书》,4册分别为《数理化基础》,《力学基础》,《电气与信息技术基础》,《工程经济与法律法规》。
这套书大家不要被考试中心的名头迷惑,个人觉得不适合做复习用,因为例题很少,相当于大纲的扩展,不建议全部买,建议买《电气与信息技术基础》,《工程经济与法律法规》这2本即可。
完全没有必要都买,因为精力有限,建议只要把天津大学出版社的这本从头到尾认真看即可,不要贪多。
(2)复习时间1、复习时间比较多上午的书得看3遍,第一遍看知识点、做例题,不用翻对应的大学教材,没有这个必要。
徐建华计量地理学期课后习题
计量地理学期末第二章1. 地理数据有哪几种类型,各种类型地理数据之间的区别和联系是什么?答:地理数据就是用一定的测度方式描述和衡量地理对象的有关量化指标。
按类型可分为:1)空间数据:点数据,线数据,面数据;2)属性数据:数量标志数据,品质标志数据地理数据之间的区别与联系:数据包括空间数据和属性数据,空间数据的表达可以采用栅格和矢量两种形式。
空间数据表现了地理空间实体的位置、大小、形状、方向以及几何拓扑关系。
属性数据表现了空间实体的空间属性以外的其他属性特征,属性数据主要是对空间数据的说明。
如一个城市点,它的属性数据有人口,GDP,绿化率等等描述指标。
它们有密切的关系,两者互相结合才能将一个地理试题表达清楚。
2. 各种类型的地理数据的测度方法分别是什么?地理数据主要包括空间数据和属性数据:空间数据——对于空间数据的表达,可以将其归纳为点、线、面三种几何实体以及描述它们之间空间联系的拓扑关系;属性数据——对于属性数据的表达,需要从数量标志数据和品质标志数据两方面进行描述。
其测度方法主要有:(1) 数量标志数据①间隔尺度(Interval Scale)数据: 以有量纲的数据形式表示测度对象在某种单位(量纲)下的绝对量。
②比例尺度(Ratio Scale)数据: 以无量纲的数据形式表示测度对象的相对量。
这种数据要求事先规定一个基点,然后将其它同类数据与基点数据相比较,换算为基点数据的比例。
(2) 品质标志数据①有序(Ordinal)数据。
当测度标准不是连续的量,而是只表示其顺序关系的数据,这种数据并不表示量的多少,而只是给出一个等级或次序。
②二元数据。
即用0、1 两个数据表示地理事物、地理现象或地理事件的是非判断问题。
③名义尺度(Nominal Scale)数据。
即用数字表示地理实体、地理要素、地理现象或地理事件的状态类型。
3. 地理数据的基本特征有哪些?1)数量化、形式化与逻辑化2 )不确定性3 )多种时空尺度4 ) 多维性4. 地理数据采集的来源渠道有哪些?1)来自于观测、测量部门的有关专业数据。
第08章--对数极大似然估计
( yt
1
2 xt 2 2
3wt
)2
T t 1
log
( yt
1
2 xt
3wt
1 2
log(
2
)
这里, 是原则正态分布旳密度函数。
16
lt
( ,
)
log
yt
1
2 xt
3wt
1 2
log(
2)
将这一例子旳对数极大似然函数过程写成下面旳赋值语
句:
Series res=y-c(1)-c(2)*x-c(3)*w
15
下面考虑2个变量旳例子:
yt 1 2 xt 3wt ut ut ~ N (0, 2 )
这里,y, x, w 是观察序列,而 ={1, 2, 3, 2}是模型旳参数。
有T个观察值旳样本旳对数似然函数能够写成:
log
L(
,
2)
T 2
log(2
)
1 2
T t 1( y ; ψ) 0 , i =1, 2, …, n (8.1.2)
i
由上式可解得 n1 向量 旳极大似然估计值 ψˆ,而式(8.1.2)
也被称为似然函数。
6
因为 L(y ; ) 与 ln[L(y ; ))] 在同一点处取极值,所
以也能够由
ln L( y ; ψ) 0 , i =1, 2, …, n (8.1.3)
而对数极大似然措施使得寻找这些极大似然估计变 得轻易了。只需创建一种对数似然对象,把上面旳赋值 语句输入到logL旳阐明窗口,然后让EViews来估计这个 模型。
20
在输入赋值语句时,只需对上面旳文本做两处微小旳 改动就能够了。首先,把每行开头旳关键字series删掉(因 为似然阐明暗含了假定序列是目前旳)。第二,必须在阐 明中加入额外旳一行(关键字@logL为包括似然贡献旳序 列命名)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计算样本相关系数,并能对相关系数进行显著性检验
Chap 08-2
第8章 相关与回归分析
8.1 8.2 8.3 8.4 相关与回归的基本概念 简单线性相关与回归分析 多元线性相关与回归分析 非线性相关分析与非线性回归分析
Chap 08-3
8.1 相关与回归的基本概念
观测值不同而变动。 总体回归模型中的ut是yt与未知的总体回归线之间的纵向距离,
它是不可直接观测的。而样本回归函数中的et是yt与样本回归
线之间的纵向距离,当根据样本观测值拟合出样本回归线之后, 可以计算出et的具体数值。
Chap 08-25
误差项的标准假定
假定1:误差项的期望值等于0,即对所有的t总有E(ut)=0
其中,ut是随机误差项,又称随机干扰项,它是一个特殊的随机 变量,反映未列入方程式的其他各种因素对Y的影响。
总体回归线与随机误差项
y
xi对应的因变量 的实际观测值yi
Eyt β1 β2 x t
ut
斜率 = β2 随机误差项
yi的拟合值
截距 = β1
xi
x
Chap 08-23
样本回归线和样本回归模型
相关分析是用一个指标(相关系数r)来表明现象间依存 关系的密切程度。 回归分析是用数学模型近似表达变量间的平均变化关系。
Chap 08-7
相关分析与回归分析
相关分析可以不必确定变量中哪个是自变量,哪个是因
变量,其所涉及的变量都是随机变量。
回归分析必须事先确定具有相关关系的变量中哪个为自 变量,哪个为因变量。一般地说,回归分析中因变量是 随机的,而把自变量作为研究时给定的非随机变量。
2
正规方程组
(标准方程组)
整理得:
ˆ n1 2 xt yt ˆ ˆ x x 2 x y ˆ 1 t 2 t t t
Chap 08-28
最小二乘估计量
求解正规方程组,可得:
ˆ n xt yt xt yt ( xt x )( yt y ) 2 2 2 2 ( xt x ) n xt xt
ˆ ˆ 1 y 2 x
以上就是总体回归系数的最小二乘估计量。
Chap 08-29
最小二乘估计量的性质
最小二乘估计量是随着样本的不同而不同的随机变量;
在满足标准假定的情况下,回归参数的最小二乘估计 量是无偏的,即
ˆ ˆ E 1 1,E 2 2
最小二乘估计量是因变量 Y 的线性组合; 数学上还可以证明,在所有的线性无偏估计中,回归 系数的最小二乘估计量的方差最小,同时随着样本容 量的增大,其方差会不断缩小; 综上所述,在标准的假定条件下,最小二乘估计量是 最佳线性无偏估计量和一致估计量。
2401
729 1089 3600 441 2025 2601 y2=14111
81
49 36 169 49 121 144 x2=713
Chap 08-12
样本相关系数计算的例子
树的高度, y
70 60
r
[n( x t ) ( x t ) 2 ][n( y t ) ( y t ) 2 ]
2 2
n x t y t xt y t
8 3142 73 321 [8 713 (73)2 ][814111 (321)2 ]
50
40
30
0.886
20
10
0 0 2 4 6 8 10 12 14
树干的直径, x
r = 0.886 → 表明 x 和 y 具有高度线 性相关关系。
0.886 1 0.8862 82
4.68
Chap 08-18
单相关系数的显著性检验
t r 1 r2 n2 0.886 1 0.8862 82 4.68
决策: 拒绝 H0
结论: 足以证明树的高 度与树干的直径 之间存在一定程 度的线性相关关 系。
d.f. = 8-2 = 6 /2=0.025 /2=0.025
相关分析和回归分析有共同的研究对象,常常必须互相
补充。相关分析需要依靠回归分析来表明现象数量相关 的具体形式,而回归分析则需要依靠相关分析来表明现 象数量变化的密切程度。只有当变量之间存在着高度相 关时,进行回归分析才有意义。
Chap 08-8
8.2 简单线性相关与回归分析
8.2.1 8.2.2 8.2.3 8.2.4 8.2.4 简单线性相关系数及检验 总体回归函数与样本回归函数 回归系数的估计 简单线性回归模型的检验 简单线性回归模型预测
Chap 08-13
Excel 输出结果
Excel 相关分析的输出结果 工具 / 数据分析 / 相关系数
树的高度 树的高度 树干的直径 1 0.886231 树干的直径 1
树的高度与树干的直径 的相关系数
Chap 08-14
相关系数的特点
r的取值在-1与1之间; 当r=0时,X与Y的样本观测值之间没有线性关系; 在大多数情况下,0<|r|<1,即X与Y的样本 观测值之间存在着一定的线性关系,当r>0时,X 与Y为正相关,当r<0时,X与Y为负相关。 如果|r|=1,则表明X与Y完全线性相关,当r =1时,称为完全正相关,而r=-1时,称为完全 负相关。 r是对变量之间线性相关关系的度量。r=0只是表 明两个变量之间不存在线性关系,但它并不意味着X 与Y之间不存在其他类型的关系。
(自由度为 n – 2 )
Chap 08-17
单相关系数的显著性检验
是否可以根据5%的显著性水平认为树的高 度与树干的直径之间存在一定程度的线性相 关关系?
H0: ρ = 0 H1: ρ ≠ 0 (无线性相关关系) (确实存在线性相关关系)
=0.05 , df = 8 - 2 = 6
t
r 1 r2 n2
8.1.1 8.1.2 8.1.3 变量间的相互关系 相关关系的类型 相关分析与回归分析
Chap 08-4
变量间的相互关系
确定性的函数关系:当一个或者几个变量取一定的值时, 另一个变量有确定值与之相对应;例如销售收入与销售量 之间的关系、路程与速度之间的关系; 不确定性的相关关系:当一个或几个相互联系的变量取一 定数值时,与之相对应的另一个变量的值虽然不确定,但 它仍按照某种规律在一定的范围内变化;
假定2:误差项的方差为常数,即对所有的t总有 Var(ut)=E(ut2)=
2
假定3:误差项之间不存在序列相关关系,其协方差为零; 假定4:自变量是给定的变量,与随机误差项线性无关;
假定5:随机误差项服从正态分布;
Chap 08-26
最小二乘估计
在根据样本数据确定样本回归方程时,总是希望 y 的 估计值 尽可能地接近其实际观测值,即残差 et 的总 量越小越好。由于 et 有正有负,简单的代数和会相互 抵消,因此为了数学上便于处理,我们采用残差平方 和作为衡量总偏差的尺度。 所谓最小二乘法,就是根据这一思路,通过使残差平 方和最小来估计回归系数的方法。
变量之间的函数关系和相关关系在一定条件下可以相互转化。 客观现象的函数关系可以用数学分析的方法去研究,而研究客观现 象的相关关系必须借助于统计学中的相关与回归分析方法。
Chap 08-5
相关关系的类型
从相关关系涉及的变量数量看:单相关和复相关
一个变量对另一变量的相关关系,称为单相关; 一个变量对两个以上变量的相关关系时,称为复相关;
r = 样本相关系数 n = 样本容量
Chap 08-11
样本相关系数计算的例子
树的 高度 y 35 树干的 直径 x 8 xy 280 y2 1225 x2 64
49
27 33 60 21 45 51 y=321
9
7 6 13 7 11 12 x=73
441
189 198 780 147 495 612 xy=3142
应用统计学
第八章 相关与回归分析 Correlation and Regression Analysis
Chap 08-1
本章学习目标
通过本章的学习,你应该能够:
理解和掌握相关分析和回归分析的原理 估计一元线性回归模型,并对模型进行检验
利用计算机软件估计多元线性回归模型,并对模型进行 检验
X 和 Y 的关系用线性函数来描述 Y 的变化被认为是由于 X 的变化引起的
Chap 08-21
总体回归函数(模型)
总体回归函数(模型): 截距项 因变量 Y的第t 个观测 值 斜率
自变量X的 第t个观测值
随机误差项 (随机干扰项)
yt β1 β2 x t u t
线性部分 随机误差项
Chap 08-22
被解释变量、因变量(Dependent variable):被视为 随着自变量而变化的变量,是我们想要加以解释的变 量。 解释变量、自变量(Independent variable):被视为主 动变化的变量 ,用于解释被解释变量。
Chap 08-20
一元(简单)线性回归模型
只有一个自变量, X
ˆ Q e t (yt y t )
2
2
ˆ x ))2 (yt ( 1 ˆ2 t
Chap 08-27
最小二乘估计
欲使Q达到最小, ˆ ˆ Q对 和 的偏导数必须等于 。 0
1
ˆ ˆ 2 yt 1 2 xt 0 即 ˆ ˆ 2 xt yt 1 2 xt 0