数据库分类
wto数据库的商品分类标准

wto数据库的商品分类标准世界贸易组织(WTO)的商品分类标准採用《关税与贸易(国际贸易)编码分类》(HS),分支部门是关税与贸易司(CTA)。
它由世贸组织的152个成员国编制,用于对出口和进口产品统一归类,也是海关收费的重要依据,以及统计和分析世界贸易数据的唯一标准。
HS分类标准根据商品名称,结构,材料,用途,外观和其他相关特征,将其细分为21个类别,98个大类,分别由第一位至第六位的数字或字母组成,共计12,000多个商品代码,形成了世界商品归类标准。
首先,世界贸易组织的商品分类标准首先以“品类”为单位,将商品划分为21个“类”,包括动物产品(第01类),植物产品(第02类),食品(第03类),纺织品(第04类),石油(第05类),工业原料(第06类),药品(第30类),文化用品(第36类),机电产品(第85类)等。
其次,在每个“类”基础上,由浅到深,逐步划分为较高层次的98个“大类”。
其次,由4位,6位或8位数字组成的HS编码,将每个大类再细分为更小的商品分类,涵盖了所有更具体的商品。
例如,HS的第10类是“矿物燃料”,大类2611中的煤就属于它。
而具体到煤类分类,第6位的编码2611.10则记录了颗粒状的烟煤,2611.20则是点火煤,2611.30则是粉煤,2611.40则表示煤炭泥,以此类推。
最后,除了HS编码,WTO还派出专门的研究人员,为每个HS编码指定一个术语来精确描述商品,即编码名称。
例如,烟煤的HS编码为2611.10,它的编码名称是“焦煤,颗粒状”,点火煤的HS编码为2611.20,它的编码名称是“焦炭,颗粒状,点火炭”等。
总之,WTO的商品分类标准,全面而精准地按HS编码分类所有商品,并为每个HS编码指定一个术语以描述该商品,从而为全球贸易提供统一的、一致的、精确的商品归类标准,维护全球贸易秩序。
为什么需要图数据库?图数据库的类别与分类

图数据库
02.图数据库技术分析
数易轩图数据库技术小组
1、“高成长”的图数据库
第下二 图个 是叫 一属 个性评图估,是给为所了有解类决型高数连 据接 库的 做数 了据 一怎 张样 图高 :效查询、 使用、存储。属性图的节点和边是它构成的重点,或者我们 可以称为是顶点不变。属性图最大的特点它的边和节点都是 可以定义属性的,这样相对RDF有一个很大的突破,因为 RDF本身是不能有属性的。
图数据库
01.图的概念
数易轩图数据库技术小组
1. 现实世界的图
关于图,我们说的图肯定不是图片,我们指的是高连接的结 构数据。其实图本身这种结构的使用,跟IT技术的发展可以 分开来看。很多人接触图可能都是了解我们看的小说或者剧 里面有什么样错综复杂的关系。 在实际生活中,其实在很多方面大家都会用到:社交网络或 者交通网络、通讯、资金,甚至我们去看地铁图等都会用到。 以图的形式来组织和表达,会让我们更容易的接受和理解它。
图
数
据
库
THANK YOU
数易轩图数据库技术小组
更具体来看一个更完整的结构,其实有三类在工业界中使用 的图的形式:
3、工业界的图
常见的或者说会比较多被传播的就是RDF、属性图和超图, 超图使用比较少,我们侧重讲前两个: 第一个RDF已经有挺长的时间了,大家如果搜RDF相关的东 西,可以搜出来。但是它有一个特点,因为它的来源实际上 更多是学术界的研究,过程中服务的主要对象就是语义万维 网,这是一个将互联网上所有知识来做连接使用的这样一个 有宏大目标的事情。
像银行的业务我们碰到了一个挑战,就是这种业务场景下我 们面临的数据是高连接的数据。对于银行来讲,资金流是一 个很重要的场景,人之间的关系也是很重要的一个场景。当 我们在一些典型的业务环节里面,比如发放贷款环节或是审 计环节里,就会关注到人之间有什么样的关系、企业之间有 什么样的关系、账户之间的资金是怎么流转的,后面就会有 具体业务的展开。
数据分类的方法

数据分类的方法数据分类是指将一组数据按照一定的规则或特征进行划分,以便于更好地管理和利用这些数据。
在实际应用中,数据分类的方法有很多种,本文将介绍几种常用的数据分类方法。
一、按照数据类型分类。
数据类型是指数据的性质和特征,常见的数据类型包括数值型、字符型、日期型等。
按照数据类型进行分类可以帮助我们更好地理解和处理数据。
例如,对于数值型数据,可以进行统计分析和数学运算;对于字符型数据,可以进行文本处理和字符串操作;对于日期型数据,可以进行时间序列分析和日期计算等。
二、按照数据来源分类。
数据来源是指数据的获取途径和渠道,常见的数据来源包括数据库、文件、传感器、网络等。
按照数据来源进行分类可以帮助我们更好地管理和维护数据。
例如,对于数据库中的数据,可以进行数据库管理和查询操作;对于文件中的数据,可以进行文件读写和格式转换;对于传感器采集的数据,可以进行实时监测和数据采集等。
三、按照数据内容分类。
数据内容是指数据的具体信息和含义,常见的数据内容包括客户信息、产品信息、销售信息等。
按照数据内容进行分类可以帮助我们更好地分析和利用数据。
例如,对于客户信息,可以进行客户分群和行为分析;对于产品信息,可以进行产品推荐和库存管理;对于销售信息,可以进行销售预测和市场营销等。
四、按照数据特征分类。
数据特征是指数据的属性和特点,常见的数据特征包括连续型、离散型、定性型、定量型等。
按照数据特征进行分类可以帮助我们更好地理解和描述数据。
例如,对于连续型数据,可以进行概率分布和回归分析;对于离散型数据,可以进行频数统计和卡方检验;对于定性型数据,可以进行因子分析和聚类分析;对于定量型数据,可以进行相关分析和回归分析等。
五、按照数据应用分类。
数据应用是指数据的具体用途和目标,常见的数据应用包括数据挖掘、机器学习、商业智能等。
按照数据应用进行分类可以帮助我们更好地选择合适的数据处理方法和工具。
例如,对于数据挖掘应用,可以选择关联规则挖掘和聚类分析;对于机器学习应用,可以选择分类算法和回归算法;对于商业智能应用,可以选择报表分析和数据可视化等。
汽车行业数据库分类导航
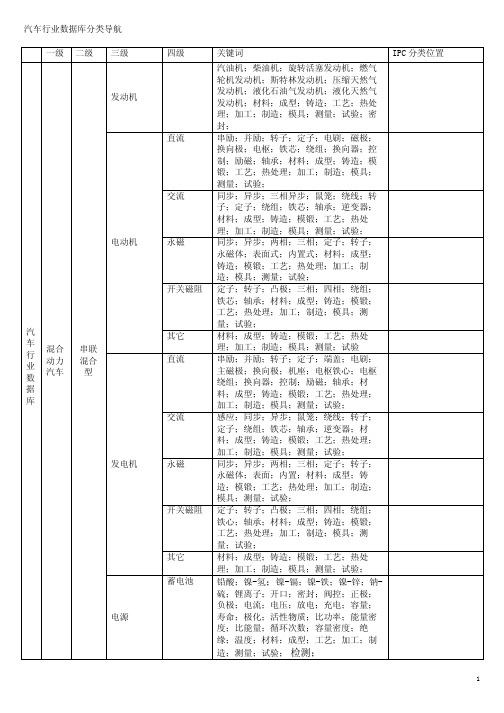
5
其它 氢气
直接 燃 料 甲醇 电池
燃料 电池 电动 汽车
其它 汽油
重整 燃 料 天然气 电池
甲醇
材料;成型;铸造;锻造;焊接;冲压; 工艺;热处理;加工;制造;模具;测 量;试验;检验;运输; 储能;蓄能;燃料;燃料箱;蓄电池;超 级电容器;飞轮;控制单元;电动机;发 电机;DC/DC;DC/AC;AC/DC;转换器;逆 变器;空气供给;驱动;齿轮;排放;成 份;性能;密度;热值;温度;压力;设 备;成本;储存;材料;成型;加工;工 艺;制造;模具;测量;试验;检验;运 输;检测;监测; 燃料;成分;性能;燃料箱;储能;装 置;蓄电池;超级电容;飞轮;动力控 制;单元;电动机;发电机;燃料电池 组;DC/DC;DC/AC;AC/DC;逆变器;转换 器;空气供给;驱动;齿轮;原料;设 备;压缩机;脱硫;转化炉;催化剂;工 艺;成本;储存;材料;成型;加工;制 造;测量;试验;检验;运输;检测;监 测; 燃料;成分;性能;燃料箱;蓄电池;超 级电容;飞轮;动力控制;单元;电动 机;发电机;燃料电池组;DC/DC; DC/AC;AC/DC;逆变器;转换器;空气供 给;驱动;齿轮;原料;设备;催化剂; 工艺;成本;储存;材料;成型;加工; 制造;测量;试验;检验;运输;检测; 监测; 燃料;成分;性能;燃料箱;储能;装 置;蓄电池;超级电容;飞轮;动力控 制;单元;电动机;发电机;燃料电池 组;DC/DC;DC/AC;AC/DC;逆变器;转换 器;空气供给;驱动;齿轮;原料;设 备;压缩机;脱硫;转化炉;催化剂;工 艺;成本;储存;材料;成型;加工;制 造;测量;试验;检验;运输;检测;监 测; 燃料;成分;性能;燃料箱;储能;装 置;蓄电池;超级电容;飞轮;动力控 制;单元;电动机;发电机;燃料电池 组;DC/DC;DC/AC;AC/DC;逆变器;转换 器;空气供给;驱动;齿轮;原料;设 备;压缩机;脱硫;转化炉;催化剂;工 艺;成本;储存;材料;成型;加工;制 造;测量;试验;检验;运输;检测;监 测; 燃料;成分;性能;燃料箱;储能;装 置;蓄电池;超级电容;飞轮;动力控 制;单元;电动机;发电机;燃料电池 组;DC/DC;DC/AC;AC/DC;逆变器;转换 器;空气供给;驱动;齿轮;原料;设 备;压缩机;脱硫;转化炉;催化剂;工 艺;成本;储存;材料;成型;加工;制 造;测量;试验;检验;运输;检测;监 测;
数据库的种类

本文由502980446贡献 doc1。
一 . 数据库的种类 IBM 的 DB2 作为关系数据库领域的开拓者和领航人,IBM 在 1977 年完成了 System R 系统的原型,1980 年开始提供集成的数据库服务器—— System/38,随 后是 SQL/DSforVSE 和 VM,其初始版本与 SystemR 研究原型密切相关。
DB2 forMVSV1 在 1983 年推出。
该版本的目标是提供这一新方案所承诺的简单 性,数据不相关性和用户生产率。
1988 年 DB2 for MVS 提供了强大的在线 事务处理(OLTP)支持,1989 年和 1993 年分别以远程工作单元和分布式 工作单元实现了分布式数据库支持。
最近推出的 DB2 Universal Database 6.1 则是通用数据库的典范, 是第一个具备网上功能的多媒体关系数据库管 理系统,支持包括 Linux 在内的一系列平台。
Oracle Oracle 前身叫 SDL,由 Larry Ellison 和另两个编程人员在 1977 创 办,他们开发了自己的拳头产品,在市场上大量销售,1979 年,Oracle 公 司引入了第一个商用 SQL 关系数据库管理系统。
Oracle 公司是最早开发关 系数据库的厂商之一,其产品支持最广泛的操作系统平台。
目前 Oracle 关 系数据库产品的市场占有率名列前茅。
Informix Informix 在 1980 年成立,目的是为 Unix 等开放操作系统提供专业的 关系型数据库产品。
公司的名称 Informix 便是取自 Information 和 Unix 的结合。
Informix 第一个真正支持 SQL 语言的关系数据库产品是 Informix SE(StandardEngine)。
InformixSE 是在当时的微机 Unix 环境下主要的数 据库产品。
它也是第一个被移植到 Linux 上的商业数据库产品。
简述数据库语言的分类

简述数据库语言的分类
数据库语言主要分为三类:数据定义语言(DDL)、数据操作语言(DML)和数据控制语言(DCL)。
1. 数据定义语言(DDL)是用于定义和管理数据库结构的语言,包括创建、修改、删除表格、视图、索引、函数、存储过程等结构。
常见的DDL命令包括CREATE、ALTER和DROP等。
2. 数据操作语言(DML)是用于对数据库中的数据进行操作的语言,包括插入、查询、更新和删除数据等操作。
常见的DML命令包括SELECT、INSERT、UPDATE和DELETE等。
3. 数据控制语言(DCL)是用于授权和权限管理的语言,可以对用户和角色进行授权和管理。
常见的DCL命令包括GRANT和REVOKE 等。
企业安全生产基础数据库行业分类表
企业安全生产基础数据库行业分类表
(根据 GBT4754-2011 确定并统一编码规则)
系统大类 编码
危险化学品
121
二级分类
危化生产(石油加工、炼焦和核燃料制造) 危化生产(化学原料和化学制品制造) 危化生产(医药制造) 危险化学品经营 危险化品使用
编码
C25 C26 C27 Z01 Z02
C311 C312 C313 C314 C315
有色金属
AJ05
常用有色金属冶炼 贵金属冶炼 稀有金属冶炼
有色金属合金制造 有色金属铸造
有色金属压延加工
C321 C322 C323 C324 C325 C326
建材行业
AJ06
非金属矿物制品 金属制品
C30 C33
1
机械制造
AJ07
轻工业
AJ08
纺织行业
AJ09
烟草行业
AJ10
商贸行业
AJ11
其它行业AJ12通 Nhomakorabea设备制造 专用设备制造
汽车制造 铁路、船舶、航空航天和其他运输设备制造
电气机械和器材制造 计算机、通信和其他电子设备制造
仪器仪表制造 其他制造业 废弃资源综合利用 金属制品、机械和设备修理
农副食品加工 食品制造
酒、饮料和精制茶制造 皮革、毛皮、羽毛及其制品和制鞋 木材加工和木、竹、藤、棕、草制品
金融业 房地产业
2
C34 C35 C36 C37 C38 C39 C40 C41 C42 C43
C13 C14 C15 C19 C20 C21 C22 C23 C24 C29
C17 C18 C28
C1610 C1620 C1690
F51 F52 F59 H61 H62
GO数据库的分类层级说明
GO数据库的分类层级说明每次⽤GO分析宝宝就凌乱了,分类关系有传递性吗?怎么推导它们之间的调控关系?语义之间的关系怎么定义?嗯,躺枪的同学默默流泪好了……我们也是操碎了⼼,今天为⼤家科普⼀下GO数据库的规则。
知识拿⾛,不谢~我们都知道GO数据的各个分类间(GO term)是呈现树状层级分类的(图1),那么层级间到底有什么样的关系呢,请看下⾯的图⽂解释:图1 GO term间的有向⽆环图⼀. GO term之间的关系分类之间关系的基本理解分类之间的关系有三种:is a、part of 和 regulates,接下来我们逐⼀来讲解每种情况。
1.Is a · is a → is aIs a具有传递性,即如果A is a B,B is a C,那么A is a C。
形式化表⽰为is a·is a→is a。
例如下图:线粒体(mitochondrion)是⼀种胞内细胞器(intracellular organelle),⽽胞内细胞器是⼀种细胞器官(organelle),从⽽可以推出:线粒体是⼀种细胞器官。
图中的实线表⽰结点之间的关系,虚线表⽰推理⽽并未证明的关系。
2.Part of · part of→part ofPart of具有传递性,如果A is part of B,B is part of C,那么A is part of C。
形式化表⽰为part of·part of→part of。
同样如下图所⽰:线粒体(mitochondrion)是细胞质(cytoplasm)的⼀部分,细胞质⼜是细胞(cell)的⼀部分,从⽽可得出:线粒体是细胞的⼀部分。
3.part of · is a /is a · part of → part of如果关系is a与part of组合,则其关系均为part of 。
分别如下图所⽰:调节控制关系及其推导GO term中,如果某⼀过程直接影响另⼀过程或参数值(quality)的表现形式,我们称前者调节控制(regulates)后者。
数据库中如何分类、分组并总计SQL数据
数据库中如何分类、分组并总计SQL数据您需要了解如何使用某些SQL子句和运算符来安排SQL数据,从而对它进行高效分析。
下面这些建议告诉您如何建立语句,获得您希望的结果。
以有意义的方式安排数据可能是一种挑战。
有时您只需进行简单分类。
通常您必须进行更多处理——进行分组以利于分析与总计。
可喜的是,SQL提供了大量用于分类、分组和总计的子句及运算符。
下面的建议将有助于您了解何时进行分类、何时分组、何时及如何进行总计。
1、分类排序通常,我们确实需要对所有数据进行排序。
SQL的ORDER BY子句将数据按字母或数字顺序进行排列。
因此,同类数据明显分类到各个组中。
然而,这些组只是分类的结果,它们并不是真正的组。
ORDER BY显示每一个记录,而一个组可能代表多个记录。
2、减少组中的相似数据分类与分组的不同在于:分类数据显示(任何限定标准内的)所有记录,而分组数据不显示这些记录。
GROUP BY子句减少一个记录中的相似数据。
例如,GROUP BY能够从重复那些值的源文件中返回一个的邮政编码列表:SELECT ZIPFROM CustomersGROUP BY ZIP仅包括那些在GROUP BY和SELECT列列表中字义组的列。
换句话说,SELECT列表必须与GROUP列表相匹配。
只有一种情况例外:SELECT列表能够包含聚合函数。
(而GROUP BY不支持聚合函数。
)记住,GROUP BY不会对作为结果产生的组分类。
要对组按字母或数字顺序排序,增加一个ORDER BY子句(#1)。
另外,在GROUP BY子句中您不能引用一个有别名的域。
组列必须在根本数据中,但它们不必出现在结果中。
3、分组前限定数据您可以增加一个WHERE子句限定由GROUP BY分组的数据。
例如,下面的语句仅返回肯塔基地区顾客的邮政编码列表。
SELECT ZIPFROM CustomersWHERE State = 'KY'GROUP BY ZIP在GROUP BY子句求数据的值之前,WHERE对数据进行过滤,记住这一点很重要。
多级分类的数据库表设计
在设计多级分类的数据库表时,通常有几种常见的方法:
1. 邻接列表(Adjacency List Model):
这种方法中,每个类别记录都会包含一个引用其父类别的字段。
例如,在一个商品分类系统中,可以创建一个categories表,结构如下:
sql代码:
在这个模型中,parent_id为NULL的记录代表顶级分类,其他记录通过parent_id关联到其父分类。
2. 路径枚举(Path Enumeration):
每个分类记录存储其完整的分类路径,例如。
这种方式的一个示例是:
sql代码:
3. nested set模型(Nested Set Model):
使用左右边界值表示树状结构,便于快速查询子节点和兄弟节点,但插入、删除操作相对复杂,需要更新所有相关节点的边界值。
4. 闭包表(Closure Table):
这是一种现代且高效的设计方式,它使用一个单独的表来存储类别之间的层级关系:
sql代码:
在闭包表中,每条记录表示ancestor_id是descendant_id的一个祖先,并通过depth字段指示它们之间的层级距离。
根据实际需求(如查询效率、更新频率、数据量大小等),可以选择适合的模型进行设计。
对于大多数场景来说,闭包表模型提供了较好的性能和扩展性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库通用分类方法
1、参考数据库
参考数据库(Reference databases)是能指引用户
到另一信息源获取原文或其他细节的数据库,包括书
目数据库(Bibliographic databases)如题录库、文摘索
引库、图书馆机读目录库,和指南数据库(Referral
databases或Directory databases),如企业名录库、产
品数据库等;
2、源数据库
源数据库(Source databases),指能直接提供所需原始资料或具体数据的数据库。包括数
值数据库(Numeric databases)、全文数据库(Full text databases)、术语数据库(Terminological
databases)和图像数据库(Graphic databases)。具体的如新闻消息全文库、法律法规全文库、
商情全文库、期刊论文数据库、财务数据库、科技报告数据库、各种统计数据库、含有图片
或照片的产品目录库、资料库等;
3、混合型数据库
混合型数据库(Mixed databases),能同时存贮多种类型数据的数据库。近几年兴起的超
文本技术将文献与文献之间得关系连接起来。各种形式的信息不是以一整篇文献为单元存储
在系统中,而是通过关系链路将同一文本或不同文本中的信息单元组织起来。这样,用户从
任一信息点出发可以遍历与其相关的各个信息单元,可以不必事先周密地考虑所有的检索语
词和检索规则也能准确、迅速地获得所需信息。