基于平衡二叉树的排序算法分析与设计
数据结构平衡二叉树的操作演示

平衡二叉树操作的演示1.需求分析本程序是利用平衡二叉树,实现动态查找表的基本功能:创建表,查找、插入、删除。
具体功能:(1)初始,平衡二叉树为空树,操作界面给出创建、查找、插入、删除、合并、分裂六种操作供选择。
每种操作均提示输入关键字。
每次插入或删除一个结点后,更新平衡二叉树的显示。
(2)平衡二叉树的显示采用凹入表现形式。
(3)合并两棵平衡二叉树。
(4)把一棵二叉树分裂为两棵平衡二叉树,使得在一棵树中的所有关键字都小于或等于x,另一棵树中的任一关键字都大于x。
如下图:2.概要设计平衡二叉树是在构造二叉排序树的过程中,每当插入一个新结点时,首先检查是否因插入新结点而破坏了二叉排序树的平衡性,若是则找出其中的最小不平衡子树,在保持二叉排序树特性的前提下,调整最小不平衡子树中各结点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
具体步骤:(1)每当插入一个新结点,从该结点开始向上计算各结点的平衡因子,即计算该结点的祖先结点的平衡因子,若该结点的祖先结点的平衡因子的绝对值不超过1,则平衡二叉树没有失去平衡,继续插入结点;(2)若插入结点的某祖先结点的平衡因子的绝对值大于1,则找出其中最小不平衡子树的根结点;(3)判断新插入的结点与最小不平衡子树的根结点个关系,确定是那种类型的调整;(4)如果是LL型或RR型,只需应用扁担原理旋转一次,在旋转过程中,如果出现冲突,应用旋转优先原则调整冲突;如果是LR型或RL型,则需应用扁担原理旋转两次,第一次最小不平衡子树的根结点先不动,调整插入结点所在子树,第二次再调整最小不平衡子树,在旋转过程中,如果出现冲突,应用旋转优先原则调整冲突;(5)计算调整后的平衡二叉树中各结点的平衡因子,检验是否因为旋转而破坏其他结点的平衡因子,以及调整后平衡二叉树中是否存在平衡因子大于1的结点。
流程图3.详细设计二叉树类型定义:typedef int Status;typedef int ElemType;typedef struct BSTNode{ElemType data;int bf;struct BSTNode *lchild ,*rchild;} BSTNode,* BSTree;Status SearchBST(BSTree T,ElemType e)//查找void R_Rotate(BSTree &p)//右旋void L_Rotate(BSTree &p)//左旋void LeftBalance(BSTree &T)//插入平衡调整void RightBalance(BSTree &T)//插入平衡调整Status InsertAVL(BSTree &T,ElemType e,int &taller)//插入void DELeftBalance(BSTree &T)//删除平衡调整void DERightBalance(BSTree &T)//删除平衡调整Status Delete(BSTree &T,int &shorter)//删除操作Status DeleteAVL(BSTree &T,ElemType e,int &shorter)//删除操作void merge(BSTree &T1,BSTree &T2)//合并操作void splitBSTree(BSTree T,ElemType e,BSTree &T1,BSTree &T2)//分裂操作void PrintBSTree(BSTree &T,int lev)//凹入表显示附录源代码:#include<stdio.h>#include<stdlib.h>//#define TRUE 1//#define FALSE 0//#define OK 1//#define ERROR 0#define LH +1#define EH 0#define RH -1//二叉类型树的类型定义typedef int Status;typedef int ElemType;typedef struct BSTNode{ElemType data;int bf;//结点的平衡因子struct BSTNode *lchild ,*rchild;//左、右孩子指针} BSTNode,* BSTree;/*查找算法*/Status SearchBST(BSTree T,ElemType e){if(!T){return 0; //查找失败}else if(e == T->data ){return 1; //查找成功}else if (e < T->data){return SearchBST(T->lchild,e);}else{return SearchBST(T->rchild,e);}}//右旋void R_Rotate(BSTree &p){BSTree lc; //处理之前的左子树根结点lc = p->lchild; //lc指向的*p的左子树根结点p->lchild = lc->rchild; //lc的右子树挂接为*P的左子树lc->rchild = p;p = lc; //p指向新的根结点}//左旋void L_Rotate(BSTree &p){BSTree rc;rc = p->rchild; //rc指向的*p的右子树根结点p->rchild = rc->lchild; //rc的左子树挂接为*p的右子树rc->lchild = p;p = rc; //p指向新的根结点}//对以指针T所指结点为根结点的二叉树作左平衡旋转处理,//本算法结束时指针T指向新的根结点void LeftBalance(BSTree &T){BSTree lc,rd;lc=T->lchild;//lc指向*T的左子树根结点switch(lc->bf){ //检查*T的左子树的平衡度,并做相应的平衡处理case LH: //新结点插入在*T的左孩子的左子树,要做单右旋处理T->bf = lc->bf=EH;R_Rotate(T);break;case RH: //新结点插入在*T的左孩子的右子树上,做双旋处理rd=lc->rchild; //rd指向*T的左孩子的右子树根switch(rd->bf){ //修改*T及其左孩子的平衡因子case LH: T->bf=RH; lc->bf=EH;break;case EH: T->bf=lc->bf=EH;break;case RH: T->bf=EH; lc->bf=LH;break;}rd->bf=EH;L_Rotate(T->lchild); //对*T的左子树作左旋平衡处理R_Rotate(T); //对*T作右旋平衡处理}}//右平衡旋转处理void RightBalance(BSTree &T){BSTree rc,ld;rc=T->rchild;switch(rc->bf){case RH:T->bf= rc->bf=EH;L_Rotate(T);break;case LH:ld=rc->lchild;switch(ld->bf){case LH: T->bf=RH; rc->bf=EH;break;case EH: T->bf=rc->bf=EH;break;case RH: T->bf = EH; rc->bf=LH;break;}ld->bf=EH;R_Rotate(T->rchild);L_Rotate(T);}}//插入结点Status InsertAVL(BSTree &T,ElemType e,int &taller){//taller反应T长高与否if(!T){//插入新结点,树长高,置taller为trueT= (BSTree) malloc (sizeof(BSTNode));T->data = e;T->lchild = T->rchild = NULL;T->bf = EH;taller = 1;}else{if(e == T->data){taller = 0;return 0;}if(e < T->data){if(!InsertAVL(T->lchild,e,taller))//未插入return 0;if(taller)//已插入到*T的左子树中且左子树长高switch(T->bf){//检查*T的平衡度,作相应的平衡处理case LH:LeftBalance(T);taller = 0;break;case EH:T->bf = LH;taller = 1;break;case RH:T->bf = EH;taller = 0;break;}}else{if (!InsertAVL(T->rchild,e,taller)){return 0;}if(taller)//插入到*T的右子树且右子树增高switch(T->bf){//检查*T的平衡度case LH:T->bf = EH;taller = 0;break;case EH:T->bf = RH;taller = 1;break;case RH:RightBalance(T);taller = 0;break;}}}return 1;}void DELeftBalance(BSTree &T){//删除平衡调整BSTree lc,rd;lc=T->lchild;switch(lc->bf){case LH:T->bf = EH;//lc->bf= EH;R_Rotate(T);break;case EH:T->bf = EH;lc->bf= EH;R_Rotate(T);break;case RH:rd=lc->rchild;switch(rd->bf){case LH: T->bf=RH; lc->bf=EH;break;case EH: T->bf=lc->bf=EH;break;case RH: T->bf=EH; lc->bf=LH;break;}rd->bf=EH;L_Rotate(T->lchild);R_Rotate(T);}}void DERightBalance(BSTree &T) //删除平衡调整{BSTree rc,ld;rc=T->rchild;switch(rc->bf){case RH:T->bf= EH;//rc->bf= EH;L_Rotate(T);break;case EH:T->bf= EH;//rc->bf= EH;L_Rotate(T);break;case LH:ld=rc->lchild;switch(ld->bf){case LH: T->bf=RH; rc->bf=EH;break;case EH: T->bf=rc->bf=EH;break;case RH: T->bf = EH; rc->bf=LH;break;}ld->bf=EH;R_Rotate(T->rchild);L_Rotate(T);}}void SDelete(BSTree &T,BSTree &q,BSTree &s,int &shorter){if(s->rchild){SDelete(T,s,s->rchild,shorter);if(shorter)switch(s->bf){case EH:s->bf = LH;shorter = 0;break;case RH:s->bf = EH;shorter = 1;break;case LH:DELeftBalance(s);shorter = 0;break;}return;}T->data = s->data;if(q != T)q->rchild = s->lchild;elseq->lchild = s->lchild;shorter = 1;}//删除结点Status Delete(BSTree &T,int &shorter){ BSTree q;if(!T->rchild){q = T;T = T->lchild;free(q);shorter = 1;}else if(!T->lchild){q = T;T= T->rchild;free(q);shorter = 1;}else{SDelete(T,T,T->lchild,shorter);if(shorter)switch(T->bf){case EH:T->bf = RH;shorter = 0;break;case LH:T->bf = EH;shorter = 1;break;case RH:DERightBalance(T);shorter = 0;break;}}return 1;}Status DeleteAVL(BSTree &T,ElemType e,int &shorter){ int sign = 0;if (!T){return sign;}else{if(e == T->data){sign = Delete(T,shorter);return sign;}else if(e < T->data){sign = DeleteAVL(T->lchild,e,shorter);if(shorter)switch(T->bf){case EH:T->bf = RH;shorter = 0;break;case LH:T->bf = EH;shorter = 1;break;case RH:DERightBalance(T);shorter = 0;break;}return sign;}else{sign = DeleteAVL(T->rchild,e,shorter);if(shorter)switch(T->bf){case EH:T->bf = LH;shorter = 0;break;case RH:T->bf = EH;break;case LH:DELeftBalance(T);shorter = 0;break;}return sign;}}}//合并void merge(BSTree &T1,BSTree &T2){int taller = 0;if(!T2)return;merge(T1,T2->lchild);InsertAVL(T1,T2->data,taller);merge(T1,T2->rchild);}//分裂void split(BSTree T,ElemType e,BSTree &T1,BSTree &T2){ int taller = 0;if(!T)return;split(T->lchild,e,T1,T2);if(T->data > e)InsertAVL(T2,T->data,taller);elseInsertAVL(T1,T->data,taller);split(T->rchild,e,T1,T2);}//分裂void splitBSTree(BSTree T,ElemType e,BSTree &T1,BSTree &T2){ BSTree t1 = NULL,t2 = NULL;split(T,e,t1,t2);T1 = t1;T2 = t2;return;}//构建void CreatBSTree(BSTree &T){int num,i,e,taller = 0;printf("输入结点个数:");scanf("%d",&num);printf("请顺序输入结点值\n");for(i = 0 ;i < num;i++){printf("第%d个结点的值",i+1);scanf("%d",&e);InsertAVL(T,e,taller) ;}printf("构建成功,输入任意字符返回\n");getchar();getchar();}//凹入表形式显示方法void PrintBSTree(BSTree &T,int lev){int i;if(T->rchild)PrintBSTree(T->rchild,lev+1);for(i = 0;i < lev;i++)printf(" ");printf("%d\n",T->data);if(T->lchild)PrintBSTree(T->lchild,lev+1);void Start(BSTree &T1,BSTree &T2){int cho,taller,e,k;taller = 0;k = 0;while(1){system("cls");printf(" 平衡二叉树操作的演示 \n\n");printf("********************************\n");printf(" 平衡二叉树显示区 \n");printf("T1树\n");if(!T1 )printf("\n 当前为空树\n");else{PrintBSTree(T1,1);}printf("T2树\n");if(!T2 )printf("\n 当前为空树\n");elsePrintBSTree(T2,1);printf("\n********************************************************************* *********\n");printf("T1操作:1.创建 2.插入 3.查找 4.删除 10.分裂\n");printf("T2操作:5.创建 6.插入 7.查找 8.删除 11.分裂\n");printf(" 9.合并 T1,T2 0.退出\n");printf("*********************************************************************** *******\n");printf("输入你要进行的操作:");scanf("%d",&cho);switch(cho){case 1:CreatBSTree(T1);break;case 2:printf("请输入要插入关键字的值");scanf("%d",&e);InsertAVL(T1,e,taller) ;break;case 3:printf("请输入要查找关键字的值");scanf("%d",&e);if(SearchBST(T1,e))printf("查找成功!\n");elseprintf("查找失败!\n");printf("按任意键返回87"); getchar();getchar();break;case 4:printf("请输入要删除关键字的值"); scanf("%d",&e);if(DeleteAVL(T1,e,k))printf("删除成功!\n");elseprintf("删除失败!\n");printf("按任意键返回");getchar();getchar();break;case 5:CreatBSTree(T2);break;case 6:printf("请输入要插入关键字的值"); scanf("%d",&e);InsertAVL(T2,e,taller) ;break;case 7:printf("请输入要查找关键字的值"); scanf("%d",&e);if(SearchBST(T2,e))printf("查找成功!\n");elseprintf("查找失败!\n");printf("按任意键返回");getchar();getchar();break;case 8:printf("请输入要删除关键字的值"); scanf("%d",&e);if(DeleteAVL(T2,e,k))printf("删除成功!\n");elseprintf("删除失败!\n");printf("按任意键返回");getchar();getchar();break;case 9:merge(T1,T2);T2 = NULL;printf("合并成功,按任意键返回"); getchar();getchar();break;case 10:printf("请输入要中间值字的值"); scanf("%d",&e);splitBSTree(T1,e,T1,T2) ;printf("分裂成功,按任意键返回"); getchar();getchar();break;case 11:printf("请输入要中间值字的值"); scanf("%d",&e);splitBSTree(T2,e,T1,T2) ;printf("分裂成功,按任意键返回"); getchar();getchar();break;case 0:system("cls");exit(0);}}}main(){BSTree T1 = NULL;BSTree T2 = NULL;Start(T1,T2);}。
平衡二叉树用途

平衡二叉树用途
平衡二叉树是一种常用的数据结构,在计算机科学中有广泛的应用。
以下是平衡二叉树的几个主要用途:
1. 查找和排序:
平衡二叉树可以用于快速查找和排序数据。
由于平衡二叉树的特殊结构,它可以在O(log n)的时间内完成查找和排序操作。
这使得它成为一种比线性搜索更有效的方法。
2. 实现字典:
平衡二叉树可以用来实现字典,其中键是树中的节点,值是与该键相关联的数据。
在这种情况下,平衡二叉树的节点将按照键的顺序排列,因此查找特定键的值是非常快速的。
3. 数据库:
平衡二叉树可以用于实现数据库中的索引。
索引可以帮助加速数据库的查询操作。
平衡二叉树可以在不需要扫描整个数据库的情况下快速定位特定的记录。
4. 线性数据结构的实现:
平衡二叉树可以用于实现一些常见的线性数据结构,如栈、队列和优先队列。
这是通过在树的一侧添加新节点并在另一侧移除节点来实现的,从而保持平衡性。
5. 模拟:
平衡二叉树可以用于模拟一些实际情况下的问题。
例如,可以使用平衡二叉树来模拟航班预定系统中的座位分配。
总之,平衡二叉树是一种非常有用的数据结构,它可以在许多应用中提供高效的解决方案。
哈夫曼编码PPT课件
Huffman编码举例
例1【严题集6.26③】:假设用于通信的电文仅由8个字母 {a, b, c, d, e, f, g, h} 构成, 它们在电文中出现的概率分别为{ 0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10 },试 为这8个字母设计哈夫曼编码。如果用0~7的二进制编码方案又如何? 【类同P148 例2】
建议2: Huffman树的存储结构可采用顺序存储结构: 将整个Huffman树的结点存储在一个数组HT[1..n..m]中;
各叶子结点的编码存储在另一“复合”数组HC[1..n]中。
第16页/共60页
Huffman树和Huffman树编码的存储表示:
typedef struct{ unsigned int weight;//权值分量(可放大取整) unsigned int parent,lchild,rchild; //双亲和孩子分量 }HTNode,*HuffmanTree;//用动态数组存储Huffman树 typedef char**HuffmanCode; //动态数组存储Huffman编码表
HT[s1].parent=i; HT[s2].parent=i; HT[i].lchild=s1; HT[i].rchild=s2; HT[i].weight=HT[s1].weight+ HT[s2].weight;}
第18页/共60页
(续前)再求出n个字符的Huffman编码HC
HC=(HuffmanCode)malloc((n+1)*sizeof(char*)); //分配n个字符编码的头指针 向量(一维数组) cd=(char*) malloc(n*sizeof(char)); //分配求编码的工作空间(n)
第九章-数据结构与算法基础

解题思路多代入法二叉树度叶子结点就是没有孩子的结点,其度为0,度为二的结点是指有两个子数的结点。
注意树的度和图的度区别叶子结点二叉排序树完全二叉树若设二叉树的深度为h,除第h 层外,其它各层(1~h-1) 的结点数都达到最大个数,第h 层所有的结点都连续集中在最左边,这就是完全二叉树。
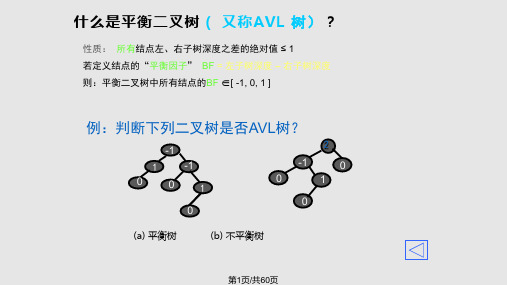
完全二叉树——只有最下面的两层结点度小于2,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树;最优二叉树(就是哈弗曼树)平衡二叉树平衡二叉树,又称AVL树。
它或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的高度之差之差的绝对值不超过1.。
满二叉树满二叉树——除了叶结点外每一个结点都有左右子叶且叶结点都处在最底层的二叉树,。
除最后一层无任何子节点外,每一层上的所有结点都有两个子结点(最后一层上的无子结点的结点为叶子结点)。
也可以这样理解,除叶子结点外的所有结点均有两个子结点。
节点数达到最大值。
所有叶子结点必须在同一层上.本题主要考查一些特殊二叉树的性质。
若二叉树中最多只有最下面两层的结点度数可以小于2,并且最下面一层的叶子结点都依次排列在该层最左边的位置上,则这样的二叉树称为完全二叉树,因此在完全二叉树中,任意一个结点的左、右子树的高度之差的绝对值不超过1。
二叉排序树的递归定义如下:二叉排序树或者是一棵空树;或者是具有下列性质的二叉树:(1)若左子树不空,则左子树上所有结点的值均小于根结点的值;(2)若右子树不空,则右子树上所有结点的值均大于根结点的值;(3)左右子树也都是二叉排序树。
在n个结点的二叉树链式存储中存在n+1个空指针,造成了巨大的空间浪费,为了充分利用存储资源,可以将这些空链域存放指向结点在遍历过程中的直接前驱或直接后继的指针,这种空链域就称为线索,含有线索的二叉树就是线索二叉树。
最优二叉树即哈夫曼树。
排序各种排序的大致思路?各种排序适用于什么情况?各种排序的时间,空间复杂度?快速排序1.快速排序(Quicksort)是对冒泡排序法的一种改进,它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列;在对一个基本有序的数组进行排序时适合采用快速排序法。
数据结构_查找原理及典型的查找算法

3.对非线性(树)结构如何进行折半查找? 可借助二叉排序树来查找(属动态查找表形式)。
9.1.2 有序表的查找
折半查找过程可以描述为一棵二叉树
折半查找的判定树 如:(a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11)
总之:
二叉排序树既有类似于折半查找的特性,又采用了链 表存储,它是动态查找表的一种适宜表示。
一、二叉排序树
(3)构造过程: 例:输入序列{45,12,37,3,53,100,24}
45
12
53
3
37
100
24
一、二叉排序树
(2)非递归查找过程 BiTree SearchBST(BiTree T,KeyType key){
CH9 查找
查找的基本概念 9.1 静态查找表
9.1.1 顺序查找 9.1.2 有序表的查找 9.1.3 索引顺序表的查找
9.2 动态查找表
9.2.1 二叉排序树和平衡二叉树 9.2.2 B-和B+树
9.3 哈希表
查找的基本概念
1.查找表 2.查找
关键字 主关键字 次关键字
}
9.2.1 二叉排序树和平衡二叉树
一、二叉排序树 二、平衡二叉树
一、二叉排序树
1.定义、特点、构造过程
(1)定义 二叉排序树或者是一棵空树,或是具有下列性质的二叉树:
若左子树非空,则左子树上所有结点的值均小于它的 根结点的值。
若右子树非空,则右子树上所有结点的值均大于它的 根结点的值。
有序/无序表 有序表
顺序/链式存 储
顺序存储
分块查找 介于二者之间 表中元素逐段有序 顺序/链式存储
置换-选择排序 总结

Prim 算法和Kruskal算法的执行过程以及时间复杂度等。 Dijkstra算法和Floyd算法在执行过程中,辅助数据结构的变化 (即迭代过程)。拓扑排序的过程和结果。AOE网求关键路径的 过程中各参量的变化,包括事件的最早发生事件和最迟发生时 间、活动的最早开始时间和最晚开始时间。有关图的算法设计 都可以通过修改图的遍历算法实现。 静态和动态查找的具体方法、平均查找长度的定义等。折 半查找重点。二叉排序树的算法设计。平衡二叉树的定义和平 衡调整的过程,判断平衡旋转的类型、进行平衡旋转等。 B—树与B+树的定义、特点、深度与关键码个数之间的关 系、B—树的插入和删除的操作过程等。 散列的基本思想、处理冲突的方法、平均查找长度的计算 等。主要考查应用各种散列函数以及各种处理冲突的方法构造 散列表的过程,以及计算查找成功情况下的平均比较次数。
[示例]利用败者树
FO 空 WA(4个记录) 空 FI 36,21,33,87,23,7,62,16, 54,43,29,… 空 21 21,23 21,23,33 21,23,33,36 21,23,33,36,62 21,23,33,36,62,87 21,23,33,36,62,87||7 … 36,21,33,87 36,23,33,87 36,7,33,87 36,7,62,87 16,7,62,87 1,62,16,54, 43,29,… 7,62,16,54, 43,29,… 62,16,54,43,29,… 16,54,43,29,… 54,43,29,… 43,29,… 29,… …
k阶哈夫曼树示例
长度分别为2,3,6,9,12,17,18,24的8 个初始归并段进行3路归并,求最佳归并树。 91 24 9
5 0 2 3
20 6
算法分析与设计及案例习题解析
习题解析第1章1. 解析:算法主要是指求解问题的方法。
计算机中的算法是求解问题的方法在计算机上的实现。
2. 解析:算法的五大特征是确定性、有穷性、输入、输出和可行性。
3. 解析:计算的算法,其中n是正整数。
可以取循环变量i的值从1开始,算i的平方,取平方值最接近且小于或者等于n的i即可。
4. 解析:可以使用反证法,设i=gcd(m, n)=gcd(n, m mod n),则设m=a*i,n=b*i,且a与b互质,这时m mod n=(a-x*b)*i,只需要证明b和a-x*b互质,假设二者不互质,可以推出a与b 不互质,因此可以得到证明。
5. 解析:自然语言描述:十进制整数转换为二进制整数采用“除2取余,逆序排列”法。
具体做法是:用2整除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为0时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。
流程图:如图*.1图*.1 十进制整数转换成二进制整数流程图6. 解析:a.如果线性表是数组,则可以进行随机查找。
由于有序,因此可以进行折半查找,这样可以在最少的比较次数下完成查找。
b.如果线性表是链表,虽然有序,则只能进行顺序查找,从链表头部开始进行比较,当发现当前节点的值大于待查找元素值,则查找失败。
7. 解析:本题主要是举例让大家了解算法的精确性。
过程中不能有含糊不清或者二义性的步骤。
大家根据可行的方式总结一下阅读一本书的过程即可。
8. 解析:数据结构中介绍的字典是一种抽象数据结构,由一组键值对组成,各个键值对的键各不相同,程序可以将新的键值对添加到字典中,或者基于键进行查找、更新或删除等操作。
由于本题已知元素唯一,因此大家可以据此建立一个自己的字典结构。
实现字典的方法有很多种:•最简单的就是使用链表或数组,但是这种方式只适用于元素个数不多的情况下;•要兼顾高效和简单性,可以使用哈希表;•如果追求更为稳定的性能特征,并且希望高效地实现排序操作的话,则可以使用更为复杂的平衡树。
数构复习提纲
期末考试题型2014年6月6日星期五22:46一.单选题(含20个小题,每小题2分,计40分)二.简答题(含6个小题,每小题6分,计36分)21.综合比较顺序表和链表的主要特点。
22.将中缀表达式 16 – 9 * ( 4 + 3 ) 转换成对应的后缀表达式(要求按人工操作的步骤分步书写或描述)。
23.设const int N=3,int x[N]={0};void Backtrack(int t) {if(t+1>N) {printf("\n");for(int i=0; i<N; i++) printf("%d",x[i]);}else for(int i=0; i<2; i++) {x[t]=i;Backtrack(t+1);}}试按格式写出调用Backtrack(0) 的运行结果。
24.设二叉树T按照二叉链表存储,试分析下列递归算法的主要功能。
int Leafnode(BiTree T){if(!T) return 0;if(!T->Lchild && !T->Rchild) return 1;return Leafnode(T->Lchild)+Leafnode(T->Rchild);}25.用依次插入关键字的方法,为序列{ 5,4,2,8,6,9 }构造一棵平衡二叉树(要求保留构造过程中的各棵不平衡二叉树)。
26.对关键字序列503,87,512,61,908,170,897,275,653,426分别执行下列排序算法,写出第1趟排序后的关键字序列:(1)冒泡排序;(2)链式基数排序。
三.设计题(含2个小题,每小题12分,计24分)27.给定两个带头结点的链表La和Lb,试设计一个高效的算法,将La中自第i个结点起的m个结点,移到Lb中的第j个结点之前。
返回链表La和Lb。
28.设计一种二进制编码,使传送数据 a,act,case,cat,ease,sea,seat,state,tea的二进制编码长度最短。
头歌二叉排序表的基本操作
头歌二叉排序表的基本操作一、概述二叉排序树,也称为二叉搜索树(Binary Search Tree, BST),是一种特殊的二叉树,其中每个节点都满足以下性质:对于任意节点,其左子树中所有节点的值都小于该节点的值,而其右子树中所有节点的值都大于该节点的值。
这种特性使得二叉排序树成为一种非常有效的数据结构,用于在各种算法中实现快速查找、插入和删除操作。
二、基本操作1. 插入操作插入操作是二叉排序树中最常用的操作之一。
其基本步骤如下:(1)创建一个新节点,并将要插入的值赋给该节点。
(2)如果二叉排序树为空,则将新节点作为根节点。
(3)否则,从根节点开始比较新节点的值与当前节点的值。
如果新节点的值小于当前节点的值,则将新节点插入到当前节点的左子树中;否则,将新节点插入到当前节点的右子树中。
(4)重复步骤3,直到找到一个空位置来插入新节点。
2. 删除操作删除操作是二叉排序树中比较复杂的操作之一。
其基本步骤如下:(1)找到要删除的节点。
如果找不到要删除的节点,则无法进行删除操作。
(2)如果找到要删除的节点,则将其从树中删除。
如果该节点只有一个子节点,则直接删除该节点;如果该节点有两个子节点,则可以选择将其中的一个子节点“提升”到该节点的位置,然后删除该子节点。
在提升子节点时,需要考虑子节点的值与要删除的节点的值之间的关系,以确保二叉排序树的性质不变。
(3)如果被提升的子节点仍然包含要删除的节点,则需要重复步骤2,直到找到要删除的节点并将其删除。
3. 查找操作查找操作用于在二叉排序树中查找指定的值。
其基本步骤如下:(1)从根节点开始,比较当前节点的值与要查找的值。
如果它们相等,则查找成功,返回当前节点的位置。
(2)如果当前节点的值大于要查找的值,则进入当前节点的左子树中进行查找;否则进入当前节点的右子树中进行查找。
(3)重复步骤2,直到找到要查找的值或者搜索路径上的所有节点都已访问过。
如果最终没有找到要查找的值,则返回空指针。
horn二原则
horn二原则霍尔恩二原则,全名霍尔恩基本二叉树旋转操作,又称为霍尔恩旋转,是一种计算机科学中的基础算法,主要用于平衡二叉树的调整。
霍尔恩二原则的核心思想是通过旋转二叉树的结点来维持平衡性,并保持搜索树的数据结构特点。
一般来说,霍尔恩旋转算法被用于解决在二叉查找树中执行插入或删除操作时可能导致树不平衡的问题。
霍尔恩二原则的实现方法有两种:1.做法一在这种情况下,算法使用四个结点x、y、z和t来实现。
其中,y代表根节点,x代表y的左子结点,z代表y的右子结点,而t是z的左子结点。
在此做法中,当前节点y的平衡因子bf应该等于2。
在执行算法时,结点x被认为是当前y的左子结点,而当前的z被认为是y的右子结点。
要保证旋转后新的子树仍然是平衡的,我们必须交替执行三个步骤:(1)从z到x的方向旋转(z,y);(2)从y到t的方向旋转(y,x);(3)从z到t的方向旋转(z,t)。
这个算法主要针对y的bf为2的情况。
当y的bf为-2时,该做法同样可用,只需要把左右子树的方向交换即可。
2.做法二在第二种情况下,我们只使用三个结点来执行旋转:y、z和t。
与第一种情况不同的是,这个算法会用到旋转中点之外的子树。
在第二种算法中,我们认为y的bf是2,而z的bf可以是0、-1或-2。
如果z的bf是0或-1,那么y的左子树是更深的子树,只需要向右旋转即可。
如果z的bf是-2,新的当前节点是t,我们需要先向左旋转z和t,再向右旋转z和y,最后将z的孩子与y连接。
两个做法的效果是相同的,它们都可以达到维护平衡的目的。
霍尔恩二原则是平衡二叉树算法中的核心思想,得到了广泛的应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于平衡二叉树的排序算法分析与设计
本文根据平衡二叉树的构造原理,提出了利用平衡二叉树进行内
部排序的思想,据此完成了对应的算法设计,并通过典型实例进行
验证和效率分析。
关键词:平衡二叉树 内部排序
analysis and design for internal sort algorithm
based on avl tree
zou yong-lin tang xiao-yang
(school of computer science and engineering,
changshu institute of technology, 215500)
abstract
according to the principle of avl tree constructing, the
ideal of sorting by using the avl tree was developed and the
algorithm was designed and implemented in this paper.
finally, the correctness and the efficiency for this
algorithm were validated and analysed through the example.
keywords
avl tree, internal sort
【中图分类号】g642
1.引言
在数据结构课程教学的理论和实践中,有关内部排序的常用方
法,一般将它们分为五大类[1][2][3]:插入、交换、选择、归并
和基数排序;并且,大多采用顺序表或链表(队)结构讨论各种算
法的具体实现过程。
实际上,并不是所有的内部排序算法都必须使用线性表对应的存
储结构来描述。不妨换一种思路,二叉排序树(bst树)和平衡二
叉树(avl树)作为动态查找表结构,它们具有一个基本特点,就
是进行中序遍历可以得到一个按结点关键字值递增有序的序列;并
且对于平衡二叉树而言,进行一次中序遍历的过程,其时间复杂度
为o(log2n)。因此,利用构造平衡二叉树的方法,同样可以实现
对一个无序序列进行排序的目的。
2.构造平衡二叉树的基本过程
由平衡二叉树的原理可知,将一个无序序列构造成一棵平衡二叉
树时,为了确保其平均查找长度与树的深度相当,在每次插入一个
新结点时,需要判断是否失去平衡,从而决定是否需要进行平衡处
理以及如何进行平衡处理。
如果一棵平衡二叉树,由于插入一个新结点导致失去平衡,则重
新恢复平衡的调整方法有4种,分别是:单向右旋、单向左旋、先
左后右和先右后左。具体过程是:首先找到最小不平衡子树,根据
其根的平衡因子的值和对应的形态,选择采用不同的方法来恢复其
平衡性。
3. 算法设计
根据上述原理,可选择二叉链表存储结构,设计构造平衡二叉树
的算法。为了实现待排序关键字中可能存在重复关键字的情形,可
对平衡二叉树的定义稍作修改,允许在平衡二叉树中存在值相同的
结点;同时,为了确保其稳定性,约定将后续的值相同的关键字以
其右子树中的新结点插入。
算法主要代码如下:
#define lh 1 //左高
#define eh 0 //等高
#define rh -1 //右高
#define num 20
#define true 1
#define false 0
int taller;
typedef struct bstnode //平衡二叉树的结点结构
{
int data; //关键字
int bf; //平衡因子
struct bstnode *lc,*rc; //左右指针
}bstnode;
int insrtavl(bstnode *t,bstnode *newnode,bstnode **tr,
int taller)
{ //在平衡二叉树中插入一个新元素
if (newnode->datadata) //在t的左子树中搜索插入
{
if (t->lc==null) //t的左子树为空树,直接插入
{
taller=true; t->lc=newnode;
}
else //非空,找到插入点再插入
insrtavl(t->lc,newnode,&(t->lc),taller);
if (taller) //判断平衡性
switch (t->bf)
{
case lh: //进行左平衡处理
leftbalance(t,tr); taller=false; break;
case eh:
t->bf=lh; taller=true; break;
case rh:
t->bf=eh; taller=false; break;
}
}
else //在t的右子树中搜索插入
{
if (t->rc==null) //t的右子树为空树,直接插入
{
taller=true; t->rc=newnode;