基于有向通链表格检测算法
一种表格框线检测和字线分离算法

一
种表 格 框 线检 测 和 字线 分 离算 法
刘 长 松 潘 世 言 郑 冶 枫 丁 晓 青
( 清华大学电 子工程系智能技术与系统国 家重点实验室 北京 1 0 8 ) 0 0 4
摘 要 该 文提 出了一 种基于 有 向单连通 链 的表格框 线检测 算法 ,能够 合理地 利 用单连通 链边 沿的 全局统 计特性 和单连 通链 之间 的局部 位置关 系,精确地 提取 表格框线 ,具 有抗倾 斜,抗断 裂,抗 字线交 叠等优 点 . 在此基础 上 。提 出 了一种能 够分 离交叠 字线 的表格 框线去 除算法 。并 成功应 用 于实际 的表格识 别 系统 中. 关键词 表 格识别 ,图像分 析 ,直 线检测 ,字符 识别 中图号 TP3 1 9
法 在 满 足 各 自 的 约 束 条 件 下 能 够 取 得 好 的 效 果 , 但 对 表 格 线 断 裂 、倾 斜 等 情 况 难 以 适 应 。 我 们构造 了一种 称为 有 向单 连通链 ( CC, rcin l igeC n e tdC an DS Di t a Sn l o n ce h i)的图像 结 e o —
利 因素 的限制 : ( ) 1 运算 量大 ; ( ) 2 只适 合于 检测 直线 而得 不 到端 点; ( ) 3 判决 门限 难 以确 定。
不 可 能 找 到 一 个 适 用 于 所 有 图 像 的 统 一 门 限 , 而 对 不 同 的 应 用 选 取 各 自合 理 的 门 限 又 是 一 个 相 当 棘 手 的 自适 应 问题 。 如 果 假 设 表 格 线 都 在 水 平 或 垂 直 方 向 附 近 , 可 以 通 过 缩 小 角 度 搜 索 范 围 来 减 少 运 算 量 , 但
l引 言
拉链表并链算法

拉链表并链算法链:古代软兵器的中介之物,故名思意,有着连接、衔接的意思,拉链算法是目前数据仓库领域比较xX的算法之一通用非常广,记录数据量很大且为全量实体记录历史的操作。
例如,某某移动通信公司客户资料,以河北为例,河北有客户2800W,客户资料每个一条就是2800W条记录算上历史客户,全量大概有5000W 条左右。
作为数据仓库来存储这些信息几千万条记录不算什么。
可是要是记录历史全量所用到的存储就非常的庞大。
问题实例为:一般正常情况下,从河北移动的BOSS系统上每天采集全量的日数据大概为2500W条,历史存储每天存储一个2500W条的日表,存储三个月,就需要3*30*2500W条的数据存储空间,数据量为20E。
这只是存储三个月的历史如果存储更长时间则无法估计需要的存储。
而用拉链算法存储。
每日只是向历史表(HIS)中添加新增和变化的数据量。
每日不过数十W条。
存储一年也就是需要5000W条记录的存储空间即两个日全量的空间。
下面详细介绍下拉链算法:1.采集当日全量存储到ND(NewDay)表中。
(比正常的全量表多两个字段(START_DATE&END_DATE)2.可从历史表中取出昨日全量数据存储到OD(oldDay)表中。
(比正常的全量表多两个字段(START_DATE&END_DATE)3.用ND-OD为当日新增和变化的数据(即每日增量)4.用OD-ND为状态到此结束需要封链的数据。
5.历史表(HIS)比ND表和OD表多两个字段(START_DATE&END_DATE)6.针对第三部来讲,ND和OD表的(START_DATE&END_DATE)分别记录当前日期和最大日期,取意为开始日期为当前天的数据和结束日期为最大日期。
注意0D和ND的START_DATEND 0D两个表进行全字段比较但是(START_DATE&END_DATE)除外。
将结果记录到w_l表中0D ND两个表进行全字段比较同样(START_DATE&END_DATE)除外。
CBTC算法

CBTC 算法本文有针对性地介绍了两种拓扑控制算法以及他们的实现和性能分析,分别是CBTC 和CLTC 。
CBTC (Cone-Based Distributed Topology Control )算法,提出的前提条件是通信节点没有GPS (全球定位系统)的帮助,拓扑控制只要方向信息。
严格意义上说就是,节点u 以最小功率α,u p 发射信号,这个功率必须确保u 周围的任一个α扇形区域内,有一个可以和其通信的节点存在。
CBTC 算法提出,α= 5π/6是确保网络连通的必须和充分的条件。
若α> 5π/6则不能保证网络连通性。
1.介绍:多跳无线网络,例如分组无线网络,ad hoc 网络,和传感器网络,都具有这种特点:两节点间的通信可能会跨越多条连续的无线链路。
不像有线网络,其典型的特征是,有一个固定的网络拓扑(除了故障发生),而无线网络中的节点会通过调整自己的发射功率以控制自己的邻接点个数,从而潜在的会改变网络拓扑。
拓扑控制的目的是设计功率高效算法,既保持网络连通性有优化性能指标,如生存时间和吞吐率。
正如Chandrakasan et al.所指出的,最小化能量消耗的网络协议对于成功利用传感器网络是至关重要的。
为了在出现故障和移动时,简化配置和再配置,分布式的拓扑控制算法只需要本地的拓扑信息并且容许异步运行,这两点很有吸引力。
拓扑控制算法可以描述如下:给定节点集合V ,有可能是平面上的移动节点。
对于每个节点u ∈V ,用它任一个给定的时间的坐标(x (u ), y (u ))来表示。
每个节点有功率函数p ,这里p (d )给出了,为了和离u 有d 距离远的节点v 建立通信链路所需的最小功率。
这里假定,每个节点的最大发射功率max p 都是相同的,并且任两个节点直接通信的距离为R ,例如p (R ) = max p 。
如果每个节点均以最大功率max p 发射,就可以得到一个图R G = (V, E ), E = {(u, v)|d (u, v ) ≤ R }(d (u, v )是u 和v 之间的欧几里德距离)。
供应链网络优化的数学模型分析

供应链网络优化的数学模型分析随着全球化的发展和市场竞争的加剧,供应链网络优化成为了企业提高效益和降低成本的重要手段。
供应链网络优化的目标是通过最优的资源配置和流程设计,实现供应链的高效运作和协同发展。
数学模型在供应链网络优化中起到了关键作用,能够帮助企业在复杂的供应链网络中做出合理的决策,提高供应链的效率和灵活性。
一、供应链网络的数学建模供应链网络是一个复杂的系统,涉及到多个环节和参与方。
为了对供应链网络进行优化,需要将其抽象为数学模型,并对模型进行分析和求解。
供应链网络的数学建模主要包括以下几个方面:1. 节点和边的建模:供应链网络可以看作是一个有向图,其中节点表示供应链的各个环节,边表示物流和信息流的流动。
通过对节点和边的建模,可以清晰地描述供应链网络的结构和关系。
2. 资源和需求的建模:供应链网络中的资源包括原材料、设备和人力资源等,需求包括市场需求和内部需求。
通过对资源和需求的建模,可以对供应链网络中的资源分配和需求满足进行量化和优化。
3. 运输和库存的建模:供应链网络中的运输和库存是影响供应链效率和成本的重要因素。
通过对运输和库存的建模,可以确定最优的运输路径和库存策略,实现供应链的快速响应和成本控制。
4. 成本和效益的建模:供应链网络优化的目标是降低成本和提高效益。
通过对成本和效益的建模,可以量化供应链网络的运作成本和效益,为决策提供依据。
二、供应链网络优化的数学方法供应链网络优化的数学方法主要包括线性规划、整数规划、动态规划和模拟等。
这些方法可以根据具体问题的特点选择合适的模型和算法,对供应链网络进行优化。
1. 线性规划:线性规划是一种常用的优化方法,适用于供应链网络中的资源分配和生产计划等问题。
通过建立线性规划模型,可以确定最优的资源配置方案,实现供应链网络的高效运作。
2. 整数规划:整数规划是一种在线性规划基础上增加整数限制的优化方法,适用于供应链网络中的库存和运输等问题。
通过建立整数规划模型,可以确定最优的库存水平和运输路径,提高供应链网络的响应速度和成本效益。
链路损耗及菲涅尔半径
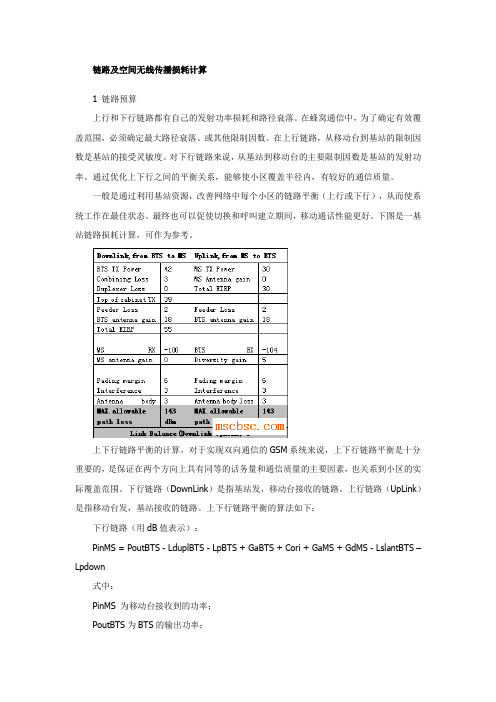
链路及空间无线传播损耗计算1 链路预算上行和下行链路都有自己的发射功率损耗和路径衰落。
在蜂窝通信中,为了确定有效覆盖范围,必须确定最大路径衰落、或其他限制因数。
在上行链路,从移动台到基站的限制因数是基站的接受灵敏度。
对下行链路来说,从基站到移动台的主要限制因数是基站的发射功率。
通过优化上下行之间的平衡关系,能够使小区覆盖半径内,有较好的通信质量。
一般是通过利用基站资源,改善网络中每个小区的链路平衡(上行或下行),从而使系统工作在最佳状态。
最终也可以促使切换和呼叫建立期间,移动通话性能更好。
下图是一基站链路损耗计算,可作为参考。
上下行链路平衡的计算。
对于实现双向通信的GSM系统来说,上下行链路平衡是十分重要的,是保证在两个方向上具有同等的话务量和通信质量的主要因素,也关系到小区的实际覆盖范围。
下行链路(DownLink)是指基站发,移动台接收的链路。
上行链路(UpLink)是指移动台发,基站接收的链路。
上下行链路平衡的算法如下:下行链路(用dB值表示):PinMS = PoutBTS - LduplBTS - LpBTS + GaBTS + Cori + GaMS + GdMS - LslantBTS –Lpdown式中:PinMS 为移动台接收到的功率;PoutBTS为BTS的输出功率;LduplBTS为合路器、双工器等的损耗;LpBTS为BTS的天线的馈缆、跳线、接头等损耗;GaBTS为基站发射天线的增益;Cori为基站天线的方向系数;GaMS为移动台接收天线的增益;GdMS为移动台接收天线的分集增益;LslantBTS为双极化天线的极化损耗;LPdown为下行路径损耗;上行链路(用dB值表示):PinBTS = PoutMS - LduplBTS - LpBTS + GaBTS + Cori + GaMS + GdBTS -LPup +[Gta] 式中:PinBTS为基站接收到的功率;PoutMS为移动台的输出功率;LduplBTS为合路器、双工器等的损耗;LpBTS为BTS的天线的馈缆、跳线、接头等损耗;GaBTS为基站接收天线的增益;Cori 为基站天线的方向系数;GaMS为移动台发射天线的增益;GdBTS为基站接收天线的分集增益;Gta为使用塔放的情况下,由此带来的增益;LPup为上行路径损耗。
表格检测的启发式算法

表格检测的启发式算法表格检测是计算机视觉领域中的一个重要任务,它涉及到从图像或文档中准确地检测和定位表格区域。
表格在许多领域中都是信息的重要载体,因此准确地识别和提取表格可以帮助我们更好地理解和利用这些数据。
启发式算法是一种基于经验和直觉的方法,它不依赖于严格的数学模型,而是通过启发式规则和策略来解决问题。
在表格检测中,启发式算法可以应用于识别表格的常见特征和模式,帮助我们快速、准确地检测表格区域。
以下是一个基于启发式算法的表格检测的步骤:1.图像预处理:对于输入的图像,首先需要进行预处理操作,以消除干扰和噪声,提高后续处理的准确性。
预处理操作可以包括图像平滑、二值化、边缘检测等,根据具体情况选择合适的方法。
2.表格候选区域生成:启发式算法可以利用表格的常见特征和几何属性来生成表格候选区域。
例如,表格通常是由连续的直线和交叉点组成的,因此可以使用霍夫变换或类似的方法来检测图像中的直线和交叉点,并根据它们的几何关系生成候选区域。
3.候选区域筛选:生成的候选区域可能包括一些非表格的区域,因此接下来需要进行筛选操作,将非表格区域排除。
启发式算法可以利用表格区域的其他特征,如文字、颜色、纹理等来进一步筛选候选区域。
4.表格区域的精确定位:通过上述步骤,我们得到了可能的表格候选区域,接下来需要进一步精确定位表格的边界框。
启发式算法可以利用表格的几何属性,如长宽比、边缘分布等来帮助准确地定位表格的边界。
5.结果优化:在得到表格区域的边界框后,可以对结果进行优化操作,进一步提高检测的准确性和稳定性。
例如,可以使用形态学操作对边界框进行腐蚀和膨胀,消除可能存在的边界误差。
启发式算法在表格检测中有许多优势,比如速度快、实现简单等。
然而,启发式算法也存在一些挑战,如对复杂的表格结构可能无法准确检测、对不同类型的表格需要调整参数等。
为了克服启发式算法的局限性,现代的表格检测方法通常会结合其他的计算机视觉技术,如深度学习、卷积神经网络等。
基于通勤出行链的公共交通使用行为辨识研究

第23卷第5期2023年10月交 通 工 程Vol.23No.5Oct.2023DOI:10.13986/ki.jote.2023.05.012基于通勤出行链的公共交通使用行为辨识研究胡 松1,杨 贝2,翁剑成3,王海鹏1,常 征1(1.交通运输部公路科学研究所,北京 100088;2.中路公科(北京)咨询有限公司,北京 100088;3.北京工业大学北京市交通工程重点实验室,北京 100124)摘 要:基于出行行为视角深入分析公共交通出行者的行为模式及特征对靶向改善公共交通服务水平具有重要意义.研究通过RP 调查获取出行者个体特征信息,并在分析海量智能卡交易数据的基础上,结合关联匹配方法提取公共交通通勤出行链;基于探索性因子分析筛选出行天数㊁日均出行频次和出行完整度以及个体社会经济属性等9个指标刻画乘客公共交通使用行为;在对连续性变量离散化的基础上,利用DBSCAN 算法构建乘客公共交通使用行为辨识模型.结果表明:构建的聚类算法可有效识别公共交通使用行为类别;调查群体被划分为公共交通高㊁中㊁低3类使用度群组,占比分别为54.2%㊁33.7%和12.1%,并将第3类人群视为公共交通使用行为改善潜力最大群体,未来应结合交通限制政策与服务水平2个维度改善此类公共交通乘客的使用行为.关键词:公共交通;使用行为;通勤出行链;探索性因子分析;DBSCAN 算法中图分类号:U 491文献标志码:A文章编号:2096⁃3432(2023)05⁃071⁃06收稿日期:2022⁃09⁃20.基金项目:交通运输部公路科学研究所(院)交通强国试点项目(QG2022⁃2⁃8⁃4);国家自然科学基金(52072011).作者简介:胡松(1992 ),男,博士,助理研究员,研究方向为智能交通㊁交通行为建模.E⁃mail:598529387@.Public Transport Usage Behaviour Identification Based onCommuting Travel ChainHU Song 1,YANG Bei 2,WENG Jiancheng 3,WANG Haipeng 1,CHANG Zheng 1(1.Research Institute of Highway Ministry of Transport,Beijing 100088,China;2.Zhonglu Gongke (Beijing)Consulting Co.,Ltd.,Beijing 100088,China;3.Faculty of Urban Construction,Beijing University of Technology,Beijing 100124,China)Abstract :Specifically analysis of the behavior patterns and characteristics of public transport travelers from the perspective of travel behavior is of great significance for targeted improvement of public transport service level.The individual characteristics of travelers were obtained by the RP survey,and the commuting travel chain of public transportation is extracted by the association matching method based on the analysis of massive smart card transaction data.The 9indicators,including travel days,daily travel frequency,travel integrity and individual socio⁃economic attributes,are selected to describe passenger public transport usage behaviour based on exploratory factor analysis.On the basis of discretization ofcontinuous variables,DBSCAN algorithm is used to construct the identification model of passenger public transportation usage behaviour.The results show that the constructed clustering algorithm can effectively identify the categories of public transport usage behaviour.The respondents are divided into three categories:high,medium and low usage groups of public transport,accounting for 54.2%,33.7%and 12.1%respectively,and the third group is regarded as the group with the greatest potential to improvepublic transport behavior.It is necessary to improve the usage bahaviour of such public transport交 通 工 程2023年passengers from two dimensions of traffic restriction policy and service level.Key words:public transport;usage behaviour;commuting travel chains;exploratory factor analysis;DBSCAN algorithm0 引言随着国家及各地政府对于城市公共交通系统建设的大力支持及推动,尤其是2018年国家公交都市建设示范城市的评估验收,各大城市居民的交通出行模式与结构也逐渐发生了变化.如何探究出行者的公共交通出行行为机理与特征,有利于为未来提高公共交通服务及出行率.并且,随着智能交通技术等的广泛应用,交通领域的数据资源得到了极大的丰富,结合交通智能海量数据开展公共交通出行行为研究具有重大意义.近些年,国内外许多专家学者在多源交通大数据的环境下对公共交通使用行为方面进行了大量研究.孙世超等[1]利用上海市通勤人群公交使用情况问卷调查数据,结合营销学领域中的RFM模型对乘客的态度和行为忠诚度进行划分,并得出约1/3高频率出行者有向其他方式转移的风险.Ma等[2]基于北京市IC和AFC卡的刷卡数据汇集个体出行链,并应用基于DBSCAN算法对出行链进行分析,并结合Kmeans++聚类算法和粗糙集理论对个体的出行特征进行聚类和分类.梁泉等[3]利用北京市公共交通刷卡和线站数据,结合个体出行知识图谱构建了BP神经元网络乘客分类模型,并利用案例验证了算法的准确性.Zhang等[4]利用人际距离学提出了基于规则的群体出行行为划分规方法,并利用北京市交通刷卡大数据开展案例分析,验证了规则算法的有效性与局限性.Cui等[5]利用深圳1个月的智能卡交易数据,提出了1种基于周登机频率的用户分类方法,并利用案例对模型的有效性进行了验证.通过以上分析可知,现有研究多是采用客观的智能卡交易数据开展研究,缺乏对个体社会经济属性的关联剖析.或者对于公共交通使用情况的分析不够聚焦.因此,本文以大型城市北京为研究背景,结合主观调查问卷数据和客观智能卡刷卡数据提取通勤者的出行链信息,并从公共交通使用行为角度构建人群聚类模型,进而揭示通勤者的公共交通使用行为特征,为未来有针对性地改善公共交通服务水平及提高其分担率奠定基础.1 数据获取与分析1.1 主观出行调查数据RP(revealed preference)调查可获取出行者主观的历史出行行为信息,为进一步研究大型都市公共交通通勤个体及群体的出行行为,本研究以具有 国家公交都市建设示范城市”之称的北京市作为调查城市.2018年9月于北京实施个体出行调查,并采用线上线下相结合的调查方式.其中,线下调查的日维度时间覆盖早晚高峰与平峰时段,周维度时间覆盖工作日与非工作日,空间维度覆盖主城区内的居住区㊁商业区与休闲区.详细的问卷调查设计及实施过程可参考2016年Fu和Juan的文献[6].调查共收回问卷317份,通过在公共交通刷卡大数据中检验主观问卷调查获取的卡号有效性,最终得到249份信息可匹配的问卷.部分问卷信息无法与刷卡数据匹配的主要原因为卡号信息填写有误与数据库信息缺失等.为了针对研究公共交通通勤者的使用行为机理,问卷设置了出行目的题项,选取 通勤/通学”者的问卷作为研究基础.本次调查在研究相关文献的基础上,旨在搜集北京市公共交通乘客的出行行为特征信息与经济社会属性信息,并进行匿名处理.其中,部分出行行为特征信息如出行时间㊁地点和天数仅作信息验证与辅助参考作用,实际研究则采用个体刷卡的动态交易数据,以体现乘客每次出行的差异性,故本节不做具体展示;而个体经济社会属性信息主要包括年龄㊁职业㊁收入㊁教育程度㊁汽车拥有量等,具体内容如表1所示. 在进行数据研究前,为了检验调查问卷结构设计的合理性与问卷信息的可靠性与有效性,需要对问卷数据进行信度与效度的检验.本文利用SPSS软件中的 可靠性分析”功能进行测度,选用Alpha模型在95%置信水平下计算信度系数Cronbach’sα值.经系统可靠性分析,可得有效个案数为249,即所有问卷数据均为有效;而Cronbach’sα值为0.883,大于可接受的最小值0.7,说明问卷数据具有良好的质量.27 第5期胡 松,等:基于通勤出行链的公共交通使用行为辨识研究表1 出行者经济社会属性信息统计题目题项占比/%题目题项占比/%教育水平1㊁高中以下2㊁高中3㊁大学专科4㊁大学本科5㊁研究生及以上0.03.612.648.235.6收入/元1㊁1500以下2㊁1500~30003㊁3000~50004㊁5000~80005㊁8000~150006㊁15000以上2.41.88.430.146.410.9年龄/岁1㊁0~182㊁19~243㊁25~344㊁35~445㊁45~546㊁55以上0.09.047.628.710.83.9工作1㊁公务员2㊁企事业单位职员3㊁私营企业4㊁服务业5㊁工人6㊁自由工作者7㊁学生8㊁待业/下岗/其他6.672.98.43.03.60.63.01.9性别1㊁男2㊁女51.248.8是否接送小孩1㊁是2㊁否19.980.1车辆拥有/辆1㊁无2㊁13㊁24㊁2辆以上41.650.06.61.81.2 客观出行刷卡数据本文主要依托北京市公交都市平台获取多源公共交通客观数据,提取2018年9月3日至7日5个工作日的刷卡数据开展研究,数据内容主要包括地面公交IC卡交易数据㊁地面公交GPS数据和轨道AFC系统交易数据等.地面公交初始数据共包含19个字段,从中筛选并保留用户卡号㊁上/下车线路编号㊁上/下车站点编号和上/下车时间等关键字段;轨道交通初始数据共包含37个字段,从中筛选并保留用户卡号㊁进/出站线路号㊁进/出站车站编码和进/出站时间等关键字段.选取公交GPS数据中的线路编号㊁数据回传时间㊁数据回传经纬度以及静态线站表中公交㊁轨道的站点编号㊁站点经纬度和站间距等字段,从而对原始公共交通刷卡交易数据进行数据校准与缺失数据弥补,提高数据的密集性与数据质量.1.3 基于主客观数据的通勤出行链提取基于处理后的主观调查数据与客观刷卡数据,以时间和用户卡号为关键字对数据进行关联匹配.为链接同1个持卡者1d中的公交与地铁多段出行数据,需要确定出行换乘刷卡交易时间阈值与站点空间距离阈值,具体阈值可参照文献[7].为了将获取的主客观数据进行有效的关联,形成信息全面㊁完备的个体出行链数据,本文提出了基于主客观数据的个体出行链提取方法,具体流程见图1.图1 个体出行链数据提取流程图按照图1的流程步骤,可获得包含个体社会经济属性与出行行为信息的多源数据的出行链信息,出行链结构及部分内容如表2所示.其中,出行模式表示1次出行所采用的交通方式,B为公交,R为轨道, -”为换乘.37交 通 工 程2023年表2 通勤公共交通出行链示例类别卡号31210229个体社会经济属性性别年龄职业教育程度收入车辆拥有量男25~34岁公务员大学本科5000~8000元1辆出行行为信息出行日期20180901 20180926出行模式R R-B 上车时间21:26 08:35上车站点五道口 西小口︙︙︙︙出行距离17997m 15065m2 公共交通使用行为模型构建2.1 公共交通使用行为刻画指标提取在主客观数据融合的通勤链数据基础上,本研究经过对相关文献的分析与北京市公共交通出行情况的调研,拟选取换乘次数㊁出行天数和日均出行频次[8⁃9]㊁出行完整度[3]4个连续型变量与性别㊁年龄㊁职业㊁教育水平㊁收入和车辆拥有量6个离散型变量[6]为初始特征指标,以期对北京市公共交通的使用行为提供综合全面的特征刻画.具体指标内容见表3所示.表3 公共交通使用行为评估指标指标描述C1换乘次数乘坐公交与地铁之间的换乘总次数C2出行天数乘坐公共交通出行的天数C3日均出行频次乘坐公共交通出行的总次数与天数的比值C4出行完整度1d出行中,采用公共交通往返出行的完整程度,取值[0,1]D1性别D2年龄D3职业个体社会经济属性D4教育水平D5收入D6车辆拥有量2.2 探索性因子分析为了进一步研究本文所取连续型指标的共线性与相关性关系,利用SPSS软件对其开展探索性因子分析.本文采用基于特征值提取(特征值>1)的最大方差旋转主成分分析法来评估指标内部的一致性,具体结果见表4所示.表4 指标相关性与显著性矩阵关系C1C2C3C4C11.000相关性C20.2581.000C30.3100.7381.000C40.1840.3940.5291.000C1显著性C20.000C30.0000.000C40.1410.0000.000 通常相关系数不小于0.3便认为变量之间存在较好的线性相关性,否则关联性较弱,即表明该变量与其他变量测量的内容不同,在主成分提取中应该剔除.从表4可得知,多数因素之间的相关系数均大于0.3,仅C1与C2㊁C4之间的相关系数不满足条件;并且,从关系显著性角度可得知,除C1与C4之外的因素间显著相关,均为0.而因素的成分得分可衡量各成分在整个目标描述过程所占的解释程度,成分得分矩阵如表5所示.表5 成分得分矩阵成分得分C10.201C20.381C30.407C40.307 从表5看出,在主成分分析中C1指标的得分最低,表明对于数据变异的解释性较差.综合考虑,本文将换乘次数从指标集中移除,即采用出行天数㊁日均出行频次㊁出行完整度及个体社会经济属性等9个因素综合刻画通勤者使用公共交通出行的行为特征.此外,由于个体社会经济属性所表征的内容各不相同,故没有对此类指标因素进行因子分析.2.3 基于DBSACN算法的公共交通使用行为聚类模型为了深入挖掘不同通勤者工作日期间使用公共交通的情况,需要基于通勤出行链数据和选取因素集对调查人群进行分类.由于指标数据集中存在连47 第5期胡 松,等:基于通勤出行链的公共交通使用行为辨识研究续型变量与离散型变量,较难使用1种有效㊁准确的算法同时进行处理;并且,离散型变量更有利于分类模型进行数据划分,消除边缘数据分类的混沌性,克服数据中隐藏的缺陷,使模型结果更加稳定.因此,本文首先需要将3个连续型变量转化为离散型变量,再利用聚类模型对人群进行分类分析.基于对出行天数㊁日均出行频次㊁出行完整度数据内容的分析,本文采用等宽法[10]进行数据的离散化.其中,出行频次以间距1将数据分割成i个区间,即[0,1)㊁[1,2)㊁[2,3)㊁[3,4)㊁[4,∞),各区间的数值类别标号分别为i=1,2,3,4,5.同理,出行天数和出行完整度的数值分割间距分别设置为1和0.2,其区间类别标号均为i=1,2,3,4,5.具有噪声的基于密度的聚类方法(DBSCAN)模型是1种基于空间密度的聚类算法,该算法视为1种被低密度区域分隔的高密度区域划分方法,可在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合.本文模型中测度样本间的最近邻距离度量参数时,选用普适性较强的欧式距离,见式(1):d=∑n i=1(x i-y i)2(1)该模型涉及的参数主要为最小样本量(min_ samples)㊁邻域的距离阈值(eps)和叶子节点数量,具体参数取值需要结合数据情况进行标定. DBSCAN模型的构建步骤如表6所示.表6 DBSCAN模型构建步骤标记所有样本对象为unvisited;随机选择1个unvisited对象p;标记p为visited;If p的邻域至少有min_samples个对象 创建1个新簇C,并把p添加到C; 令N为p的领域中的对象集合; For N中的每个点p If p是unvisited; 标记P为visited; If p的邻域至少有min_samples个对象,把这些对象添加到N; If p不属于任何簇,把p添加到C; End for; 输出C;Else标记p为噪声;直到没有标记为unvisited对象停止.3 案例分析为深入量化分析通勤者的公共交通使用行为特征,本文基于2018年9月3日至7日的公共交通刷卡客观数据,匹配调查获取的249个受访者的主观问卷数据,提取案例研究的通勤出行链信息.3.1 模型构建与参数选取基于表6的模型构建流程,利用python软件实现DBSCAN模型的构建与数据聚类实施.其中,模型的最近邻搜索算法参数选择 auto”机制,该算法机制可从蛮力模型㊁KD树模型和球树模型3种方法中基于数据内容自动选取最优的最近邻搜索算法去拟合数据.此外,将249个样本所对应的9个因素指标数据输入到初始DBSCAN模型中,并利用聚类结果的轮廓系数s(i)对模型结果进行评价,从而对min_ samples㊁eps和树的叶子节点数(leaf_size)等参数进行调整.其中,s(i)的计算式见式(2):s(i)=1-a(i)b(i)a(i)<b(i)0a(i)=b(i)b(i)a(i)-1a(i)>b(iìîíïïïïïï)(2)式中,a(i)为样本i到同簇其他样本的平均欧式距离;b(i)为样本i到其他某簇C j的所有样本的平均距离最小值,即样本i的簇间不相似度.经过多次模型拟合的调整过程,确定各参数值为: min_samples=2,eps=1.5,leaf_size=30,此时聚类结果的轮廓系数为0.76,表明聚类结果较为合理.3.2 群体公共交通使用行为聚类分析将前述249位受访者的指标数据输入到调整好的模型,最终聚类算法将调查人群划分为3类,具体内容如表7所示. 从表7看出,3个出行行为指标中,第2类通勤人群的出行天数㊁日均出行频次和出行完整度均要远高于其他2类人群,表明此类人群在工作日会频繁使用公共交通出行,属于公共交通高使用度乘客,为公共交通系统需要持续维护的顾客群体,而且此类人群在通勤者中的占比也最多.并且,此类通勤者的性别的类别标号为1.49,非常接近1.5,表明该类人群的男女比例十分均衡;同理可知,公共交通高使用度乘客多为25~34岁之间的年轻群体,主要为本科及研究生以上高学历的企事业单位的职员,收57交 通 工 程2023年表7 聚类结果统计聚类1聚类2聚类3统计情况84人(33.7%)135人(54.2%)30人(12.1%)指标均值C23.794.591.75C32.112.431.20C42.453.371.95D11.461.491.55D23.483.323.50D33.112.012.00D43.954.674.50D53.884.784.90D61.891.541.75 注释:括号中为各类人数占比.入为中高水平,并且拥有0或1辆车的出行者人数较为均衡.第1类人群为占据通勤者1/3公共交通中使用度乘客,其出行天数㊁日均出行频次和出行完整度均3个指标值均稍低于第1类通勤者.此类人群的男性稍多于女性,年龄主要在25~44岁,在私企工作者居多,以专科和本科毕业生为主,收入为3000~ 8000的中等水平,大部分人群家庭拥有1辆小汽车.同时也反映了教育水平与工作单位质量㊁收入整体成正比的关系.此外,第3类人群的出行天数㊁日均出行频次和出行完整度3个指标值处于通勤者中最低的水平,即为公共交通低使用度乘客.该类乘客通常采用小汽车㊁合乘或打车等方式出行,主要由于车辆限行㊁交通管制㊁身体不适及天气不良等内外影响因素被迫选择公共交通出行的群体,也正是未来提高公共交通出行率的潜在人群.此部分用户的女性稍多于男性,年龄和是车辆拥有量与第2类人群相似,而其他社会经济属性指标多与第1类人群一致.总体来看,此类人群具有一定的经济基础与稳定的工作,拥有小汽车且追求较为舒适的出行环境,故未来公共交通管理者可从交通限制政策与服务水平2个角度去提高此类通勤者的公共交通使用程度.4 结论研究设计并实施了公共交通出行行为调查方 案,基于客观公共交通大数据利用关联匹配算法提取公共交通通勤出行链信息.从个体出行行为与社会经济属性角度选取了公共交通使用行为影响指标,利用因子分析法筛选9个刻画指标,结合DBSCAN算法构建了乘客公共交通使用行为聚类模型.结果表明,调查的通勤人群被划分为公共交通高㊁中㊁低使用度3类,占比分别为54.2%㊁33.7%和12.1%,其中第3类为未来提高公共交通出行率的主要争取人群,并且可从公共交通限制政策与服务水平2个角度去促进该类人群的公共交通使用度.研究为深入理解公共交通出行行为,改善公共交通服务水平和吸引力提供技术支持.参考文献:[1]孙世超,杨东援.基于RFM模型的通勤人群公交忠诚度研究[J].交通运输系统工程与信息,2015,15(4): 216⁃221.[2]Ma X,Wu Y J,Wang Y,et al.Mining smart card data for transit riders’travel patterns[J].Transportation Research Part C:Emerging Technologies,2013,36:1⁃12. [3]梁泉,翁剑成,林鹏飞,等.基于个体出行图谱的公共交通通勤行为辨别方法研究[J].交通运输系统工程与信息,2018,18(2):100⁃107.[4]Zhang Y,Martens K,Long Y.Revealing group travel behaviour patterns with public transit smart card data[J]. Travel Behaviour and Society,2018,10:42⁃52. [5]Cui C L,Zhao Y L,Duan Z Y.Research on the Stability of Public Transit Passenger Travel Behaviour Based on Smart Card Data[C]//Cota International Conference of Transportation Professionals.2014. [6]Fu X,Juan Z.Empirical analysis and comparisons about time⁃allocation patterns across segments based on mode⁃specific preferences[J].Transportation,2016,43(1): 37⁃51.[7]王月玥.基于多源数据的公共交通通勤出行特征提取方法研究[D].北京:北京工业大学,2014. [8]潘福全,王健,亓荣杰,等.基于公交限时免费换乘的居民出行方式选择建模与分析[J].科学技术与工程, 2018,454(21):134⁃138.[9]胡松,翁剑成,周伟,等.基于关联分析的乘客公共交通依赖度识别方法[J].交通运输系统工程与信息, 2020,20(4):136⁃142.[10]刘晓明,李盼池,刘显德,等.贝叶斯网络参数学习中的连续变量离散化方法研究[J].计算机与数字工程,2018,46(5):992⁃996.67。
基于区域通信链接图分析五防与自动化通信中的问题

3 2
徐 海 斌 : 于 区域 通 信 链 接 图分 析 五 防 与 自动 化 通 信 中 的 问题 基
2 )值 班人 员单 独操 控界 面 的功 能 目前 , 除 了极 个别 站外 , 班 人 员 没有 一 个 可 以 操控 的界 值 面用 以监 控 当前 的五 防和 自动化 通信状 态 。建议 采 用 O NE信号或 者通 信灯 ( NI I 软界 面 ) 的方 式 , 增设 一个 值班 人员 可 以监控 的信 号来 表示 目前 的 串 口通 信状态 。
3 实现 五 防 闭 锁 的 功 能 要 实 现 五 防 闭 锁 )
视 图 1中的交界 区域 , 即如 果 各 站 的五 防系 统 与 自动化 系统 间通 信 中断 时 , 影 响 到该 站 的遥 控 会 操作 , 而大 五防 系统影 响 面更广 , 带有 遥控 许可 的 五 防系统影 响后 果更 为严 重 。而单独 的 串 口通 信
Ke r s u s a i n;fv r t c in s s e ;a t ma i n s s e ;c mm u ia i n y wo d :s b t t o i e p o e to y t m uo t y tm o o nc t o
1 两种 接 线 方 式
目 前,
第 3 3卷 第 1 期
21 年 2 O2 月
电 力 与 能 源
3 1
基 于 区域 通信 链 接 图分 析 五 防 与 自动 化 通 信 中 的 问题
徐 海 斌
( 海 市 电力 工 程 建 设 监 理 有 限公 司 , 海 上 上 203 ) 0 2 3
摘 要 : 过 区 域 通 信 链 接 图示 分 析 方 法 , 析 了 目前 变 电 站 各 区域 间 , 防 系 统 与 自动 化 通 信 方 式 中 存 在 的 通 分 五 隐 患 及 通 信 中 的 一些 问 题 , 出 了需 要 改 进 和 完 善 的补 充 功 能 、 全 措 施 和 管理 制度 , 来 规 范通 信 故 障 时 的 提 安 用 各类操作 。 关 键 词 : 电 站 ; 防 系统 ; 变 五 自动 化 系 统 ; 信 通
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
郑冶枫 等:基于有向单连通链的表格框线检测算法 2.2 字符尺寸的估计
793
在直线检测算法中需要设定最短直线长度门限 , 大于该门限的直线保留 , 小于该门限的直线被认为是字符 笔划而滤除 . 最短直线长度门限实际代表了字符的尺寸 . 由于表格的不同 , 扫描分辨率的不同 , 字符尺寸变化很 大 , 从十几个像素到上百个像素 . 很多文献中该门限或者设定为一个固定值 [2] , 或者作为一个参数需要用户输 入 [3,5]. 若能自动估计字符的尺寸 , 则可以提高直线检测算法的自适应能力 . 我们提出一种基于连通域分析的自 动估计方法 .利用在生成单连通链时提取的黑像素游程 ,对这些游程作连通域分析 ,就可以统计得到连通域宽度 和高度的直方图,如图 3 所示.对于单一字号汉字占多数的表格,直方图只出现一个明显的峰,该峰即对应字符的 尺寸.而在实际表格中,汉字、数字、英文常常同时出现,不同的字号也同时出现.直方图中出现多个峰,此时我们 取高度大于一定门限的最大峰作为字符尺寸的估计.图 3 是两个表格样张的连通域宽度和高度直方图.表格样 张 1 只有单一字号的汉字,在直方图中形成一个非常明显的峰,如图 3(a)和图 3(b)所示,我们取最高的峰作为字 符尺寸的估计.表格样张 2 中同时存在汉字和数字,数字的宽度是汉字的一半左右,其连通域宽度的直方图比较 分散 , 形成多个明显的峰 ,如图 3(c) 所示 .我们取最右边的峰作为字符尺寸的估计 .对于左右和上下结构的汉字 , 理论上必须将各个连通域合并后才能估计出字符的尺寸 .这种相邻连通域的合并一方面计算量大 ,另一方面比 较困难 . 它相当于作字符切分 , 而中英文混排的字符切分是比较困难的 , 在图像粘连严重时就更难了 . 幸好 , 实验 结果表明 ,这种连通域合并是不需要的 .以左右结构的汉字为例 ,其各个连通域在高度直方图中有助于形成正确 的峰 , 而在宽度直方图中 , 会造成一些干扰 , 但在统计足够多的字符后 , 这种干扰不会引起字符尺寸估计错误 . 我 们的连通域分析利用了已经提取的黑像素游程 ,比从像素级上开始作连通域分析快很多 (实验结果表明可以快 5~10 倍).通过实验,我们发现,统计 100 个连通域就可以得到相当精确的结果,所以我们统计完 100 个连通域后 就不再作连通域分析了,这样可以大大减少计算开销.
792
Journal of Software 软件学报 2002,13(4)
Abnormal run-length①
C
ˆ ( xi′ ) y'i − y
C′
{•
dx
⋅
ˆ y
① “毛刺 ”游程 .
Fig.2
Co-Linear distance of two horizontal DSCCs 图2 两横向单连通链的同线距离
表格是一种很常见的文档形式 .它作为一种高度精炼、集中的信息表达手段 , 以其简明、规范、便于填写 和处理等特点 ,被广泛地应用在国民经济和日常生活的各个方面 . 表格的自动输入、存储、管理已经成为文档 智能处理领域的一个重要组成部分. 表格由一些有一定约束关系的横线、竖线和少量的斜线组成 . 为了构成表格单元 ,直线之间存在相互约束 关系 .我们称表格中这种相互之间存在约束关系的直线为表格框线 ,以区别一般的直线 .直线检测是图像分析领 域中最基本的、不断研究探讨的问题之一 . 其中较为成熟的算法是 Hough 变换以及繁多的快速算法 [1]. 虽然 Hough 变换作为一种全局的检测方法,对线段的连通性没有要求,有利于检测虚线和断裂的直线.但由于难以确 定直线的起点和终点 ,运算量过大 , 它在具体的工程实践中的应用却受到了限制 .表格中的框线绝大多数集中在 水平和垂直两个方向,这提示我们可以将 Hough 变换中(ρ,θ)空间的 θ分量的搜索范围大大地减小,从而大幅度地 减少运算量.这种特殊的 Hough 变换等效于实际中经常使用的投影算法[2].但投影法不能提取斜线,而且抗图像 倾斜的能力有限,当图像出现较大角度(大于 5°)的倾斜时,算法就会失效. 矢量化算法 (vectorization)是另一类应用较广的直线检测算法[3~5].直接对光栅图像的各个像素进行处理 ,存 储量大 , 而且因为不能利用像素间的位置关系 , 很不方便 . 而矢量化过程作为目标识别的预处理过程 , 将输入的 光栅图像转化成矢量基元(比如直线段、圆弧段等等).它一方面使处理对象由像素变成矢量基元,数目下降一个 数量级 , 另一方面选择合适的矢量基元可以使后续的目标识别过程转化成较简单的矢量基元的生长、合并过 程 , 难度大大降低 . 因为矢量基元的选择决定了目标检测算法的性能 , 所以它必须容易提取 , 大小合适 , 反映待检 测目标的最本质的特性 . 我们构造了一种称为 “有向单连通链 ” 的图像结构作为直线检测的矢量化基元 ,它具有 定义简单,物理意义明确,易于检测、存储和处理等优点.在一定约束条件下合并有向单连通链,可以快速、准确
1
有向单连通链的定义
分别对应于横线和竖线 ,有向单连通链也分为横向单连通链和纵向单连通链两种 .横向单连通链用于检测
横线和倾斜角度小于 45º的斜线;纵向单连通链用于检测竖线和倾斜角度大于 45º的斜线 .以横向单连通链为例: 横向单连通链 C h 为图像游程序列 R1R2 ...Rm .序列中每一个游程项 Ri 都是横向宽度为一个像素、纵向由连续的 黑像素段形成的游程(如图 1 所示),记为 Ri ( xi , ys i , yei ) = {( x, y ) | p ( x, y ) = 1 , x = xi , y ∈ [ ys i , yei ], p ( xi , ys − 1) = p ( xi , ye + 1) = 0}. 其中 p(x,y)代表坐标(x,y)处的像素值,1 代表黑像素点,0 代表白像素点;xi,ysi 和 yei 分别表示游程 Ri 的 x 坐 标、 起始 y 坐标和终止 y 坐标;Ch 中的各个 Ri 在 x 方向(横向 )上排列成一个序列,且序列中任意相邻的两个游程 Ri 和 Ri+1 横向单连通,即:除了 Ch 两端的游程 R1 和 Rm 以外,任何 Ri 的两侧都有且仅有一个游程与其连通.对 R1 的右侧和 Rm 的左侧也是如此.但对于 R1 左侧和 Rm 的右侧,要么不存在任何连通游程(如 R13 的右侧),要么存在 1 个以上的连通游程(如 R1 的左侧有 R15 和 R14 同时与之连通),要么虽然只有一个连通游程,但这个连通游程同 时还与处于 R1 或 R m 同一列的其他游程连通(如 R9 ).
R8
ห้องสมุดไป่ตู้
( x6 , ys6 )
R7
R9
R10
R3 R15 R1 R14 R2 R4 R5
R6
R11
R12 R
13
( x6 , ye6 )
R1R2 ⋅ ⋅ ⋅ R7 in the box
forms a horizontal DSCC
①
①框内的 R1R2 ⋅ ⋅ ⋅ R7 形成一个横向单连通链 .
Fig.1 图1
791
地提取直线 . 单连通链的合并结果还有少量的错误 . 一类是字符笔划的误合并 , 即存在 “ 伪 ” 直线 ; 一类是直线断 裂 .表格框线约束信息的引入可以帮助去除伪直线 , 补全断裂的直线 .我们称这种引入表格框线约束信息的直线 检测算法为表格框线检测算法. 本文第 1 节给出有向单连通链的定义.第 2 节讨论基于有向单连通链的框线检测算法.第 3 节讨论算法的 加速问题 , 加速后我们的算法的速度与投影法的速度相当 . 最后 , 我们将通过实验 , 验证本算法的有效性 . 实验表 明,我们提出的基于有向单连通链的表格框线检测算法具有速度较快、抗任意角度的倾斜、抗断裂等特点.
领域为图像处理 , 模式识别 ,智能信息处理 ;丁晓青 (1939−),女 ,江苏雎宁人 ,教授 ,博士生导师 ,主要研究领域为图像处理 , 模式识别 ,智能 图文信息处理 ;潘世言 (1973−),男 ,安徽桐城人 ,博士生 ,主要研究领域为图像处理 ,模式识别 .
郑冶枫 等:基于有向单连通链的表格框线检测算法
直线,所以设定其距离为无穷大.若 dx>0,则表示 C 和 C′在纵向没有交叠,dx 的数值代表 C 和 C′内侧两个端点游 程的横向距离.此时 dCC 和式中的第 2 项代表 C′各中心点到 C 延长线的均方误差.这一项越小,表明 C′越贴近 C 的延伸部分,即 C 和 C′越有可能处在同一条直线上.我们采用最小二乘拟合法延伸 C.只有长度小于两倍游程平 均长度的游程才作为“有效游程”,参与拟合,这样可以排除“毛刺游程”的干扰.式中 B 表示有效游程集合. 若 C′可以合并入 C,它必须同时满足以下两个合并准则: 1. 线性延伸条件: d C ′C − d x < W ,W 为单连通链 C 的平均宽度; 2. 间隙条件:考察位于 C 和 C′内侧两个端点之间,长度为 dx,宽度为 W 的图像区域,可能出现 3 类情况: (1) 空白.设定门限 T1(实验中 T1=15),若 dx≤T1,我们认为空白是表格线的正常断裂,C 和 C′仍属于同一直线, 应合并;若 dx>T1,则说明 C 和 C′相距过远,不应再视为一条直线,所以不合并. (2) 存在其他单连通链,其宽度小于两倍 C 的宽度.处理方法同情况 1. (3) 存在其他单连通链,其宽度大于两倍 C 的宽度.此时 C 和 C′之间存在直线或字符笔划.设定一个较小的 门限 T2(实验中 T2=8),若 dx≤T2,合并 C 和 C′,否则不合并. 合并算法的第 1 步是选定一条合适的单连通链 Cs 作为 “种子链”(我们选择有效游程最多的作为 “种子链”). 首先在 Cs 的某个单侧寻找距离 Cs 最近的一系列 Ci′,然后按同线距离从小到大的顺序依次判定是否满足上述合 并条件.若找到可以合并的 Ck′,则将 Cs 和 Ck′中的所有有效游程 Ri(i=1,2,...,n)和 Rj′(j=1,2,...,m)放在一起,做最小 二乘拟合,继续进行搜索和合并.处理完一侧,再处理另一侧,直到 Cs 的两侧都找不到可以合并的 C′为止.从剩余 的所有未经合并的单连通链中选取新的初始 “种子链 ”,用同样的方法可以检测出其他直线 . 重复上述过程 ,直到 再也无法找到合适的初始 “种子 ”链为止 .由于合并前单连通链比较短 , 其统计特性不够稳定 ,为了防止发生不可 弥补的误合并,我们在第 1 次合并时,门限设得比较小.经过初始合并后,连续性比较好的直线就可以完整地提取 出来 , 而断裂比较严重的直线被识别成若干条线段 . 接着 , 我们加入字符尺寸的信息 , 将门限放宽到等于字符尺 寸,进行第 2 次合并.经过第 2 次合并后,我们滤除小于字符宽度的横线和小于字符高度的竖线,排除单个字符笔 划产生的直线.