匈牙利算法
最大化指派问题匈牙利算法

最大化指派问题匈牙利算法匈牙利算法,也称为Kuhn-Munkres算法,是用于解决最大化指派问题(Maximum Bipartite Matching Problem)的经典算法。
最大化指派问题是在一个二分图中,找到一个匹配(即边的集合),使得匹配的边权重之和最大。
下面我将从多个角度全面地介绍匈牙利算法。
1. 算法原理:匈牙利算法基于增广路径的思想,通过不断寻找增广路径来逐步扩展匹配集合,直到无法找到增广路径为止。
算法的基本步骤如下:初始化,将所有顶点的标记值设为0,将匹配集合初始化为空。
寻找增广路径,从未匹配的顶点开始,依次尝试匹配与其相邻的未匹配顶点。
如果找到增广路径,则更新匹配集合;如果无法找到增广路径,则进行下一步。
修改标记值,如果无法找到增广路径,则通过修改标记值的方式,使得下次寻找增广路径时能够扩大匹配集合。
重复步骤2和步骤3,直到无法找到增广路径为止。
2. 算法优势:匈牙利算法具有以下优势:时间复杂度较低,匈牙利算法的时间复杂度为O(V^3),其中V是顶点的数量。
相比于其他解决最大化指派问题的算法,如线性规划算法,匈牙利算法具有更低的时间复杂度。
可以处理大规模问题,由于时间复杂度较低,匈牙利算法可以处理大规模的最大化指派问题,而不会因为问题规模的增加而导致计算时间大幅增加。
3. 算法应用:匈牙利算法在实际中有广泛的应用,例如:任务分配,在人力资源管理中,可以使用匈牙利算法将任务分配给员工,使得任务与员工之间的匹配最优。
项目分配,在项目管理中,可以使用匈牙利算法将项目分配给团队成员,以最大程度地提高团队成员与项目之间的匹配度。
资源调度,在物流调度中,可以使用匈牙利算法将货物分配给合适的运输车辆,使得货物与运输车辆之间的匹配最优。
4. 算法扩展:匈牙利算法也可以扩展到解决带权的最大化指派问题,即在二分图的边上赋予权重。
在这种情况下,匈牙利算法会寻找一个最优的匹配,使得匹配边的权重之和最大。
运筹学匈牙利法

运筹学匈牙利法运筹学匈牙利法(Hungarian Algorithm),也叫匈牙利算法,是解决二部图最大(小)权完美匹配(也称作二分图最大权匹配、二分图最小点覆盖)问题的经典算法,是由匈牙利数学家Kuhn和Harold W. Kuhn发明的,属于贪心算法的一种。
问题描述在一个二分图中,每个节点分别属于两个特定集合。
找到一种匹配,使得所有内部的节点对都有连边,并且找到一种匹配方案,使得该方案的边权和最大。
应用场景匈牙利算法的应用场景较为广泛,比如在生产调度、货车调度、学生对导师的指定、电影的推荐等领域内,都有广泛的应用。
算法流程匈牙利算法的伪代码描述如下:进行循环ɑ、选择一点未匹配的点a作为起点,它在二分图的左边β、找出a所有未匹配的点作为下一层节点ɣ、对下一层的每个节点,如果它在右边未匹配,直接匹配ɛ、如果遇到一个已经匹配的节点,进入下一圈,考虑和它匹配的情况δ、对已经匹配的点,将它已经匹配的点拿出来,作为下一层节点,标记这个点作为已被搜索过ε、将这个点作为当前层的虚拟点,没人配它,看能否为它找到和它匹配的点ζ、如果能匹配到它的伴侣,令它们成对被匹配最后输出最大权匹配。
算法优缺点优点:相比于暴力求解二分图最大权匹配来说,匈牙利算法具有优秀的解决效率和高效的时间复杂度,可以在多项式时间(O(n^3))内解决二分图最大权匹配问题。
缺点:当二分图较大时,匈牙利算法还是有很大的计算复杂度,复杂度不佳,算法有效性差。
此时就需要改进算法或者使用其他算法。
总结匈牙利算法是一个常见的解决二分图最大权匹配问题的算法,由于其简洁、易用、效率优秀等特性,广泛应用于学术和实际问题中。
匈牙利算法虽然在处理较大规模问题时效率不佳,但仍然是一种值得掌握的经典算法。
匈牙利算法

匈牙利算法本文讲述的是匈牙利算法,即图论中寻找最大匹配的算法,暂不考虑加权的最大匹配(用KM 算法实现),文章整体结构如下:1.基础概念介绍2.算法的实现一. 部分基础概念的介绍概念点1. 图G的一个匹配是由一组没有公共端点的不是圈的边构成的集合。
这里,我们用一个图来表示下匹配的概念:如图所示,其中的三条边即该图的一个匹配;所以,匹配的两个重点:1. 匹配是边的集合;2. 在该集合中,任意两条边不能有共同的顶点。
那么,我们自然而然就会有一个想法,一个图会有多少匹配?有没有最大的匹配(即边最多的匹配呢)?我们顺着这个思路,继续往下走。
概念点2. 完美匹配:考虑部集为X={x1 ,x2, ...}和Y={y1, y2, ...}的二部图,一个完美匹配就是定义从X-Y的一个双射,依次为x1, x2, ... xn找到配对的顶点,最后能够得到 n!个完美匹配。
这里有一个概念,有点陌生,即什么是二部图,这个其实很好理解,给定两组顶点,但是组内的任意两个顶点间没有边相连,只有两个集合之间存在边,即组1内的点可以和组2内的点相连,这样构建出来的图就叫做二部图(更好理解就是n个男人,n个女人,在不考虑同性恋的情况下,组成配偶)。
这样是不是简单多了?既然说到了双双组成配偶,那我们干的就是月老做的活了,古话说得好,宁拆一座庙,不毁一桩婚,如果真的给出n个帅气的男孩,n个漂亮的女孩,他们之间互相有好感,但一个男孩可以对多个女孩有感觉,一个女孩也可能觉得多个男孩看起来都不错,在这种情况下,我们怎么让他们都能成双成对呢?将这个问题抽象出来,互有好感就是一条条无向边(单相思我们先不考虑),而男孩和女孩就是一个个节点,我们构建出这么一个图,而完美匹配就是让所有看对眼的男孩和女孩都能够在一起。
完美匹配是最好的情况,也是我们想要的情况。
当然,有些情况下我们做不到完美匹配,只能尽可能实现最多的配对,这个就叫做最大匹配。
可以看出来,完美匹配一定是最大匹配,而最大匹配不一定是完美匹配。
匈牙利算法
匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,并推动了后来的原始对偶方法。
美国数学家哈罗德·库恩于1955年提出该算法。
此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig和Jenő Egerváry的工作之上创建起来的。
匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。
匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
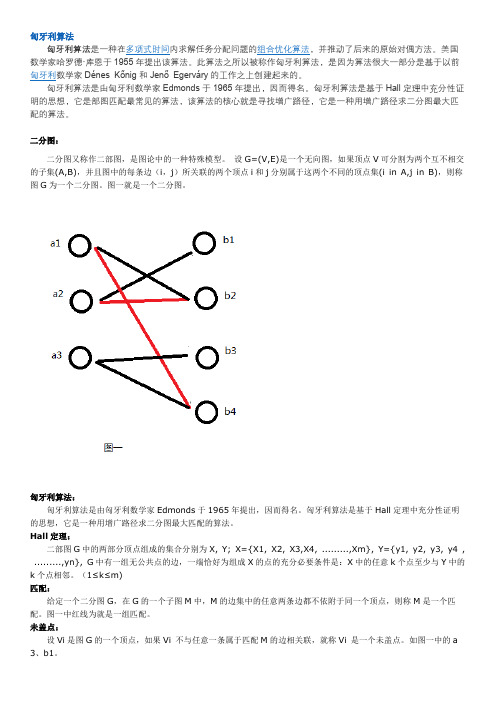
二分图:二分图又称作二部图,是图论中的一种特殊模型。
设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
图一就是一个二分图。
匈牙利算法:匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。
匈牙利算法是基于Hall定理中充分性证明的思想,它是一种用增广路径求二分图最大匹配的算法。
Hall定理:二部图G中的两部分顶点组成的集合分别为X, Y; X={X1, X2, X3,X4, .........,Xm}, Y={y1, y2, y3, y4 , .........,yn}, G中有一组无公共点的边,一端恰好为组成X的点的充分必要条件是:X中的任意k个点至少与Y中的k个点相邻。
(1≤k≤m)匹配:给定一个二分图G,在G的一个子图M中,M的边集中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
图一中红线为就是一组匹配。
未盖点:设Vi是图G的一个顶点,如果Vi 不与任意一条属于匹配M的边相关联,就称Vi 是一个未盖点。
如图一中的a 3、b1。
设P是图G的一条路,如果P的任意两条相邻的边一定是一条属于M而另一条不属于M,就称P是一条交错路。
匈牙利算法

匈牙利算法是一种组合优化算法,用于解决多项式时间内的任务分配问题,并推广了后来的原始对偶方法。
美国数学家Harold Kuhn在1955年提出了该算法。
之所以将该算法称为匈牙利算法,是因为该算法的很大一部分是基于匈牙利数学家DénesKőnig和JenőEgerv áry的先前工作。
匈牙利算法是一种组合优化算法,用于解决多项式时间内的任务分配问题,并推广了后来的原始对偶方法。
美国数学家Harold Kuhn在1955年提出了该算法。
之所以将该算法称为匈牙利算法,是因为该算法的很大一部分是基于匈牙利数学家DénesKőnig和JenőEgerv áry的先前工作。
众所周知,匈牙利是一个国家的名称,与算法的发明者有关。
匈牙利算法的发明者埃德蒙兹(Edmonds)于1965年提出了匈牙利算法。
我不知道为什么匈牙利算法的发明者是匈牙利算法,而且我从未见过其他以国家命名的算法。
是因为匈牙利人提出的算法太少了吗?
匈牙利算法的核心原理非常简单,即找到增强路径以实现最大匹配。
我们将匈牙利算法与Gale-Shapley算法的原理进行了比较,您发现了什么?实际上,这两种算法的核心原理是相同的。
在GS算法中,我们首先开始追求男孩,并尽可能地进行匹配。
然后,单身男孩一次又一次地认罪,如果有更好的比赛,以前的比赛将被打破。
在稳定婚
姻的问题中,我们定义了匹配的质量,而在本地二分匹配的问题中,匹配既不是好事也不是坏事。
如果我们抛开匹配的好坏,而把高品质男生抓住劣等男生的过程当作匹配调整的过程,那么这两种算法的核心几乎是相同的。
匈牙利算法——精选推荐

匈⽛利算法0 - 相关概念0.1 - 匈⽛利算法 匈⽛利算法是由匈⽛利数学家Edmonds于1965年提出,因⽽得名。
匈⽛利算法是基于Hall定理中充分性证明的思想,它是⼆部图匹配最常见的算法,该算法的核⼼就是寻找增⼴路径,它是⼀种⽤增⼴路径求⼆分图最⼤匹配的算法。
0.2 - ⼆分图 若图G的结点集合V(G)可以分成两个⾮空⼦集V1和V2,并且图G的任意边xy关联的两个结点x和y分别属于这两个⼦集,则G是⼆分图。
1 - 基本思想1. 找到当前结点a可以匹配的对象A,若该对象A已被匹配,则转⼊第3步,否则转⼊第2步2. 将该对象A的匹配对象记为当前对象a,转⼊第6步3. 寻找该对象A已经匹配的对象b,寻求其b是否可以匹配另外的对象B,如果可以,转⼊第4步,否则,转⼊第5步4. 将匹配对象b更新为另⼀个对象B,将对象A的匹配对象更新为a,转⼊第6步5. 结点a寻求下⼀个可以匹配的对象,如果存在,则转⼊第1步,否则说明当前结点a没有可以匹配的对象,转⼊第6步6. 转⼊下⼀结点再转⼊第1步2 - 样例解析 上⾯的基本思想看完肯定⼀头雾⽔(很⼤程度是受限于我的表达能⼒),下⾯通过来就匈⽛利算法做⼀个详细的样例解析。
2.1 - 题⽬⼤意 农场主John有N头奶⽜和M个畜栏,每⼀头奶⽜需要在特定的畜栏才能产奶。
第⼀⾏给出N和M,接下来N⾏每⾏代表对应编号的奶⽜,每⾏的第⼀个数值T表⽰该奶⽜可以在多少个畜栏产奶,⽽后的T个数值为对应畜栏的编号,最后输出⼀⾏,表⽰最多可以让多少头奶⽜产奶。
2.1 - 输⼊样例5522532342153125122.2 - 匈⽛利算法解题思路2.2.1 - 构造⼆分图 根据输⼊样例构造如下⼆分图,蓝⾊结点表⽰奶⽜,黄⾊结点表⽰畜栏,连线表⽰对应奶⽜能在对应畜栏产奶。
2.2.2 - 模拟算法流程为结点1(奶⽜)分配畜栏,分配畜栏2(如图(a)加粗红边所⽰)为结点2(奶⽜)分配畜栏,由于畜栏2已经被分配给结点1(奶⽜),所以寻求结点1(奶⽜)是否能够分配别的畜栏,以把畜栏2腾给结点2(奶⽜)。
匈牙利算法
匈牙利算法是一种组合优化算法,可以在多项式时间内解决任务分配问题,并在以后推广原始的对偶方法。
美国数学家哈罗德·库恩(Harold Kuhn)在1955年提出了该算法。
该算法之所以称为匈牙利算法,是因为它很大程度上是基于前匈牙利数学家Denes K nig和Jen Egervary的工作。
假设它是无向图。
如果顶点集V可以分为两个不相交的子集,则在该子集中选择具有最大边数的子集称为图的最大匹配问题。
如果存在匹配项和匹配项数,则该匹配项称为完美匹配项,也称为完全匹配项。
称为完美匹配时的特殊。
在介绍匈牙利算法之前,只有几个概念,M是G的匹配项。
如果,则边缘已经在匹配的M上。
M交错的路径:P是G的路径。
如果P中的边是属于M的边和不属于M而是属于G的边交替,则称P为M交错的路。
如:路径,。
M饱和点:例如,如果V与M中的边关联,则V为m饱和点;否则,V为非M饱和点。
例如,它们都属于M饱和点,而其他所有点都属于非M饱和点。
M扩展路径:P是M交错的路径。
如果P的起点和终点均为非M饱和点,则P称为m增强路径。
例如(不要与流网络中的增强路径混淆)。
寻找最多匹配项的一种明显算法是找到所有匹配项,然后保留最多匹配项。
但是该算法的时间复杂度是边数的指数函数。
因此,我们需要找到一种更有效的算法。
下面介绍使用增强路径查找最大匹配的方法(称为匈牙利算法,由匈牙利数学家爱德蒙兹(Edmonds)于1965年提出)。
增强轨道(也称为增强轨道或交错轨道)的定义:如果P是连接图G中两个不匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配)在P上交替,则称P为扩充路径相对于M从增强路径的定义可以得出以下三个结论:(1)到P的路径数必须是奇数,并且第一个边缘和最后一个边缘都不属于M。
(2)通过将M和P取反可以获得更大的匹配度。
(3)当且仅当没有M的增加路径时,M是G的最大匹配。
算法简介:(1)令M为空(2)通过异或运算找到增强路径P并获得更大的匹配项而不是M(3)重复(2),直到找不到扩展路径。
匈牙利算法
匈牙利算法匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。
匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
在介绍匈牙利算法之前还是先提一下几个概念,下面M是G的一个匹配。
M-交错路:p是G的一条通路,如果p中的边为属于M中的边与不属于M但属于G中的边交替出现,则称p是一条M-交错路。
如:路径(X3,Y2,X1,Y4),(Y1,X2,Y3)。
M-饱和点:对于v∈V(G),如果v与M中的某条边关联,则称v 是M-饱和点,否则称v是非M-饱和点。
如X1,X2,Y1,Y2都属于M-饱和点,而其它点都属于非M-饱和点。
M-可增广路:p是一条M-交错路,如果p的起点和终点都是非M-饱和点,则称p为M-可增广路。
如(X3,Y2,X1,Y4)。
(不要和流网络中的增广路径弄混了)求最大匹配的一种显而易见的算法是:先找出全部匹配,然后保留匹配数最多的。
但是这个算法的时间复杂度为边数的指数级函数。
因此,需要寻求一种更加高效的算法。
下面介绍用增广路求最大匹配的方法(称作匈牙利算法,匈牙利数学家Edmonds于1965年提出)。
增广路的定义(也称增广轨或交错轨):若P是图G中一条连通两个未匹配顶点的路径,并且属于M的边和不属于M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径。
由增广路的定义可以推出下述三个结论:1-P的路径个数必定为奇数,第一条边和最后一条边都不属于M。
2-将M和P进行取反操作可以得到一个更大的匹配M'。
3-M为G的最大匹配当且仅当不存在M的增广路径。
算法轮廓:⑴置M为空⑵找出一条增广路径P,通过异或操作获得更大的匹配M'代替M⑶重复⑵操作直到找不出增广路径为止折叠。
匈牙利算法详解
匈牙利算法详解
匈牙利算法是一种解决二分图最大匹配问题的经典算法,也叫做增广路算法。
它的基本思想是从左侧一端开始,依次匹配左侧点,直到无法添加匹配为止。
在匹配过程中,每次都通过BFS 寻找增广路径,即可以让已有的匹配变得更优或添加新的匹配。
增广路的长度必须为奇数,因为必须从未匹配的左侧点开始,交替经过已匹配的右侧点和未匹配的左侧点,最后再到达未匹配的右侧点。
当没有找到增广路径时,匹配结束。
匈牙利算法的具体实现可以使用DFS 或BFS,这里以BFS 为例。
算法步骤如下:
1. 从左侧一个未匹配的点开始,依次找增广路径。
如果找到,就将路径上的匹配状态翻转(即已匹配变未匹配,未匹配变已匹配),并继续找增广路径;如果找不到,就说明已经完成匹配。
2. 使用BFS 寻找增广路径。
从左侧的某个未匹配点开始,依次搜索路径中未匹配的右侧点。
如果找到右侧未匹配点,则说明找到了增广路径;否则,将已搜过的左侧点打上标记,以免重复搜索。
如果找到增广路径,就将路径的左侧和右侧点的匹配状态翻转。
3. 重复步骤1 和2,直到找不到增广路径为止。
匈牙利算法的时间复杂度为O(VE),其中V 和E 分别为二分图中的左侧点数和右侧点数。
实际运行效率很高,可以处理百万级别的数据。
匈牙利算法
匈牙利算法:匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,并推动了后来的原始对偶方法。
美国数学家哈罗德·库恩于1955年提出该算法。
此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家DénesKőnig和JenőEgerváry 的工作之上创建起来的。
设G=(V,E)是一个无向图。
如顶点集V可分割为两个互不相交的子集V1,V2,选择这样的子集中边数最大的子集称为图的最大匹配问题(maximalmatchingproblem)。
果一个匹配中,|V1|≤|V2|且匹配数|M|=|V1|,则称此匹配为完全匹配,也称作完备匹配。
特别的当|V1|=|V2|称为完美匹配。
作用:解决指派问题。
所谓的指派问题就比如:甲乙丙三个人去做ABC 三件事情。
每个人做每件事情所花的时间可能不一样。
每个人只能安排一件事情,问怎样安排才能使三个人所工作的时间之和最小?扩展成n个人n件事也可以,但要求是:事情数和人数一样多每人只能做一件事这样的问题就称作指派问题匈牙利算法就是解决这样的问题的。
步骤概括:每行减去此行最小数判断是否达到算法目标,如未达到算法目标,继续下一步。
否则结束。
横纵交替,从行开始。
找出所有还没有选中0的行(具体见步骤实例),在此行后面打钩;把此行中有0的列全打钩。
在打钩的列中,如果有零,又在有0的行打钩,如此交替,直到不能再打钩。
在没有打钩的行和打钩的列上划线,会得到发现所有的0已经被划去,如果没有划去,请检查前面的步骤。
此时剩下的所有元素中,找到最小值,就记为min吧。
在第4步画线的行减去min(此时原来的0变成-min),再在画线的列加上min(此时矩阵中没有了负数)。
回到第2步。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
C实现(作者BYVoid) CPP
#include <stdio.h> #include <string.h> #define MAX 102 long n,n1,match; long adjl[MAX][MAX]; long mat[MAX]; bool used[MAX]; FILE *fi,*fo; void readfile() { fi=fopen("flyer.in","r"); fo=fopen("flyer.out","w"); fscanf(fi,"%ld%ld",&n,&n1); long a,b; while (fscanf(fi,"%ld%ld",&a,&b)!=EOF) adjl[a][ ++adjl[a][0] ]=b; match=0; }
未盖点:设Vi是图G的一个顶点,如果Vi 不与任 未盖点 意一条属于匹配M的边相关联,就称Vi 是一个未 盖点。
交错路:设P是图G的一条路,如 交错路 果P的任意两条相邻的边一定是一 条属于M而另一条不属于M,就称 P是一条交错路。 可增广路:两个端点都是未盖点 可增广路 的交错路叫做可增广路。
---匈牙利算法(by_Beyond_the_Void)
procedure hungary; var i:longint; begin fillchar(b,sizeof(b),0); for i:=1 to m do begin fillchar(c,sizeof(c),0); if path(i) then inc(ans); end; end; begin fillchar(a,sizeof(a),0); readln(m,n,k); for i:=1 to k do begin readln(x,y); a[x,y]:=true; end; ans:=0; hungary; writeln(ans); end.
匈牙利算法 (by Be大匹配的算法。 它由匈牙利数学家 Edmonds于1965年提出, 因而得名。
Beyond the Void的博客:/blog/ 的博客: 的博客 例题:USACO 4.2.2 The Perfect Stall 完美的牛栏 stall4
void print() { fprintf(fo,"%ld",match); fclose(fi); fclose(fo); } int main() { readfile(); hungary(); print(); return 0; }
Pascal实现(作者魂牛)? PASCAL
var a:array[1..1000,1..1000] of boolean; b:array[1..1000] of longint; c:array[1..1000] of boolean; n,k,i,x,y,ans,m:longint; function path(x:longint):boolean; var i:longint; begin for i:=1 to n do if a[x,i] and not c[i] then begin c[i]:=true; if (b[i]=0) or path(b[i]) then begin b[i]:=x; exit(true); end; end; exit(false); end;
bool crosspath(long k) { for (long i=1;i<=adjl[k][0];i++) { long j=adjl[k][i]; if (!used[j]) { used[j]=true; if (mat[j]==0 || crosspath(mat[j])) { mat[j]=k; return true; } } } return false; } void hungary() { for (long i=1;i<=n1;i++) { if (crosspath(i)) match++; memset(used,0,sizeof(used)); } }
流程图
伪代码:CPP
bool 寻找从k出发的对应项出的可增广路 { while (从邻接表中列举k能关联到顶点j) { if (j不在增广路上) { 把j加入增广路; if (j是未盖点 或者 从j的对应项出发有可增广路) { 修改j的对应项为k; 则从k的对应项出有可增广路,返回true; } } } 则从k的对应项出没有可增广路,返回false; } void 匈牙利hungary() { for i->1 to n { if (则从i的对应项出有可增广路) 匹配数++; } 输出 匹配数; }