节分布拟合检验
第八章 分布检验和拟合优度 检验

2
其中 n ( x) S ( x) F0 ( x) 在零假设下, W 2 ,U 2 的分布和F0 ( x)的分布无关. 注: nD2 2 和 U 2 的渐近分布一样; 4nD2 2 和 两个独立的 W 2 统计量的和的渐近分布一样.
关于正态分布的一些其他检验和相应的R程序
S ( x)
i
n
针对上面三种检验,检验统计量分别为 :
D sup x ( F0 ( x) S ( x)) D sup x F0 ( x) S ( x) D sup x ( S ( x) F0 ( x))
在零假设下,统计量D的分布对于一切连续分布F0 ( x) 是一样的
min i ni
分 时,Q趋于 (k 1)
2
例题
例8.3 某饭店想知道他的顾客用电话是否服从 Possion分布,在他们计算机上(n=908)获得一 个小时内打电话得数据:
打电话次数 相应的人数 0 1 2 3 490 334 68 16
15.04 15.36 14.57 14.53 15.57 14.69 15.37 14.66 14.52 15.41 15.34 14.28 15.01 14.76 14.38 15.87 13.66 14.97 15.29 14.95
按照设计要求,内径应该为15±0.2mm。 问题:检验一下这个数据是否来自均值为15,方差为0.04 的正态分布?
8.1 Kolmogrov-Smirnov单样本检验及一些正态性检验
设真实分布为F(x),假设问题:
F ( x) F0 ( x) H 0 : F ( x) F0 ( x) H1 : F ( x) F0 ( x) F ( x) F ( x) 0
概率论课件分布拟合检验

基因表达分析
通过分布拟合检验,可以 对基因表达数据进行统计 分析,了解基因表达模式 和功能。
临床试验数据分析
在临床试验中,分布拟合 检验可用于分析药物疗效、 疾病发病率等数据。
其他应用场景
环境监测
在环境监测领域,分布拟合检验可用 于分析空气质量、水质等环境指标的 分布特征。
社会调查
在社会调查中,分布拟合检验可用于 分析人口普查、民意调查等数据,了 解社会现象和趋势。
本研究还发现,不同分布拟合检验方法在拟合效 果上存在差异,其中QQ图和概率图在判断分布拟 合优劣方面表现较好,而直方图在可视化展示方 面更具优势。
研究展望
在未来的研究中,可以进一步 探讨其他理论分布与实际数据 的拟合程度,以寻找更合适的
分布模型。
可以结合机器学习和人工智能 算法,对数据进行更深入的挖 掘和分析,以提高分布拟合检
分析结果表明,所选理论分布与实际数据存在一 定的拟合程度,但也存在一定的偏差。其中,正 态分布和指数分布与实际数据的拟合效果较好, 而泊松分布和威布尔分布的拟合效果相对较差。
在本研究中,我们采用了多种分布拟合检验方法 ,包括直方图、QQ图、概率图和统计检验等方法 ,对实际数据进行了深入的分析和比较。
通过绘制直方图和QQ图,可 以直观地观察数据分布与理论 分布的拟合程度。同时,计算 峰度系数和偏度系数等统计指 标,可以量化地评估分布拟合 程度。
案例二:人口普查数据分布拟合检验
• 总结词:人口普查数据分布拟合检验是评估人口数据质量和预测人口发 展趋势的重要手段。
• 详细描述:通过对人口普查数据进行分布拟合检验,可以判断人口数据 是否符合预期的分布形态,如年龄、性别、地区分布等,从而评估数据 质量和预测未来人口发展趋势。
5第五章 拟合优度检验

体色 F2观测尾数
鲤鱼遗传试验F2观测结果
青灰色 1503 红色 99 总数 1602
⒈ 提出无效假设与备择假设
H 0 : 鲤鱼体色F2 代分离符合3: 1 比率 H A : 鲤鱼体色F2 代分离不符合3: 1 比率
⒉计算理论次数 青灰色的理论数为: E1=1602 ×3/4=1201.5 红色的理论数: E2=1602×1/4=400.5 2 3.计算 c 因为该资料只有k=2组,所以此例的 自由度为2-1=1 ( O,需进行连续性矫正。 E 0.5) 2
9 9 p(0) , 9 3 3 1 16 3 p(1) p(2) , 16 1 p(3) 16
9 T0 179 100.6875 , 16 3 T1 T2 179 33.5625 16
1 T3 179 11.1875 16
按公式
行总数 列总数 Ei 总数
计算各格理论值,填于各格 括号中。再计算统计量:
2
( 254 236.5 0.5)
2
236.5 2 ( 246 263.5 0.5)
( 219 236.5 0.5)
2
236.5 2 ( 281 263.5 0.5)
263.5 263.5 1.222 1.222 1.097 1.097 4.638
尾区概率 P=P1+P0=0.122+0.010=0.132。 由于不知什么性别对药物反 应强烈;∴应进行双侧检验, 即与 =0.025 比较。 2 , ∴接受H0,男女对该药反应 无显著不同。
2 P
0.025
作业26/11
p102
第7章分布拟合
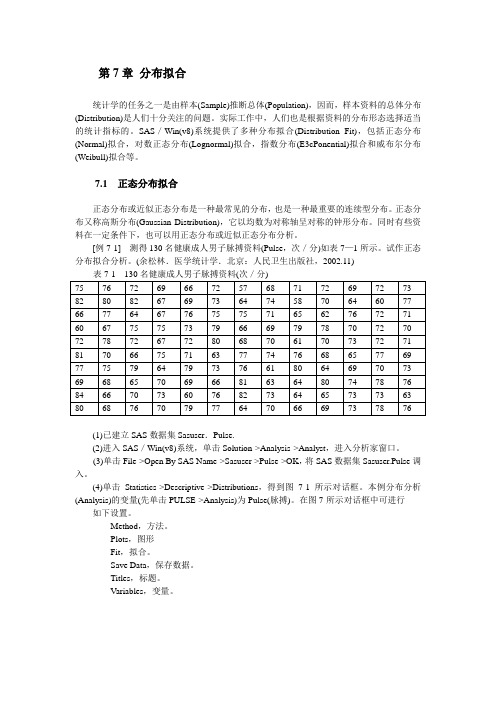
第7章分布拟合统计学的任务之一是由样本(Sample)推断总体(Population),因而,样本资料的总体分布(Distribution)是人们十分关注的问题。
实际工作中,人们也是根据资料的分布形态选择适当的统计指标的。
SAS/Win(v8)系统提供了多种分布拟合(Distribution Fit),包括正态分布(Normal)拟合,对数正态分布(Lognormal)拟合,指数分布(E3cPonential)拟合和威布尔分布(Weibull)拟合等。
7.1 正态分布拟合正态分布或近似正态分布是一种最常见的分布,也是一种最重要的连续型分布。
正态分布又称高斯分布(Gaussian Distribution),它以均数为对称轴呈对称的钟形分布。
同时有些资料在一定条件下,也可以用正态分布或近似正态分布分析。
[例7-1] 测得130名健康成人男子脉搏资料(Pulse,次/分)如表7—1所示。
试作正态分布拟合分析。
(余松林.医学统计学.北京:人民卫生出版社,2002.11)(1)已建立SAS数据集Sasuser.Pulse.(2)进入SAS/Win(v8)系统,单击Solution->Analysis->Analyst,进入分析家窗口。
(3)单击File->Open By SAS Name->Sasuser->Pulse->OK,将SAS数据集Sasuser.Pulse调入。
(4)单击Statistics->Descriptive->Distributions,得到图7-1所示对话框。
本例分布分析(Analysis)的变量(先单击PULSE->Analysis)为Pulse(脉搏)。
在图7-所示对话框中可进行如下设置。
Method,方法。
Plots,图形Fit,拟合。
Save Data,保存数据。
Titles,标题。
Variables,变量。
图7-1 Distributions:Pulse(分布)对话框(5)在图7-1所示对话框中,单击Method按钮,得到图7-2所示对话框。
列联分析与拟合优度检验

第三节 拟合优度检验
3. 几个拟合优度检验例题 • 其次,确定临界值:
0.05, k 2
2 0.05
2
1
3.84146
第三节 拟合优度检验
3. 几个拟合优度检验例题 • 最后,计算并做出结论:
2 38 302 62 702
30
70
3.0476 3.84146
2. 拟合优度检验的基本过程 • 提出假设:
H0 :总体服从于某种分布 H1 :总体不服从该种分布
第三节 拟合优度检验
2. 拟合优度检验的基本过程 • 计算检验统计量:
2
oi ei 2
ei
oi: 观 测 频 数 ;ei: 期 望 频 数
当 所 有 类 的 期 望 频 数 均大 于 等 于5时,
• 交叉列表分析的主要目的,在于分析两变量 间的相互关系,即是否相互关联(相互独立) 以及关联的强度。
第一节 列联表
2.列联表的基本形式 • 列联表所展示的是至少两个变量的交叉频数。
表中的每个频数 均由两个变量的 值交互决定
第一节 列联表
2.列联表的基本形式
观察表中的频数,
• 列联表所展示的是至少两个变可量以的大交致叉判频断数出。 两个变量是否相
• 描述等级相关强度的系数主要是斯皮尔曼相 关系数和肯达尔的一致性系数,它们均依据 数据的“秩”即排序来计算:
斯 皮 尔 曼 相 关 系 数 ( 或rs )
( Ri R )( Si S ) ( Ri R )2 ( Si S )2
式 中 :Ri :第 i 个 x 值 的 秩 ;
Si :第i 个 y 值的秩。
3. 几个拟合优度检验例题 • 最后,计算并得出结论:
分布拟合检验

随机变量 x 的偏度和峰度指的是 x 的标准化变 量[x-E(x)]/ D( x ) 的三阶中心矩和四阶中心矩: x - E(x) 3 E[( x E ( x )) 3 ] v1=E[( ) ]= , 3/ 2 ( D( x )) D(x) x - E(x) 4 E[( x E ( x )) 4 ] v2=E[( ) ]= . 2 ( D( x )) D(x) 当随机变量 x 服从正态分布时,v1=0 且 v2=3. 设 x1,x2,…,xn 是来自总体 x 的样本,则 v1,v2 的矩估 计分别是 g1=B3/B 3/2 , g2=B4/B 2 . 2 2 其中 Bk(k=2,3,4)是样本 k 阶中心矩,并分别称 g1, g2 为样本偏度和样本峰度.
例 1 在一实验中,每隔一定时间观察一次由某 种铀所放射的到达计数器上的 粒子数 x,共观察了 100 次,得结果如下表所示: 表 8.2 铀放射的 粒子数的实验记录 i 0 1 2 3 4 5 6 7 8 9 10 11 12 fi 1 5 16 17 26 11 9 9 2 1 2 1 0 Ai A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 其中 fi 是观察到有 i 个 粒子的次数。从理论上考虑 知 x 应服从泊松分布
155 149 141 142 141 147 149 140
158 158 140 137 149 146 138 142
解 为了粗略了解这些数据的分布情况,我们先根 据所给的数据画出直方图,下面就来介绍直方图。 上述数据的最小值、最大值分别为126、158,即所 有数据落在区间[126,158]上现取区间[124.5,159.5] ,它能覆盖区间[126,158]。将区间[124.5,159.5]等 分为7个小区间,小区间的长度记为 , (159.5 124.5) / 7 5. 称为组距。小区间的端点称为组限。数出落在每个 小区间内的数据频数 f i ,算出频率 f i / n / n( n 84, i 1,2,,7) 如下表
蒙特卡洛模拟算法在IBMSPSSModeler中的应用及分析,第1部分:模拟拟合及生成
蒙特卡洛模拟算法在IBMSPSSModeler中的应⽤及分析,第1部分:模拟拟合及⽣成IBM SPSS Modeler 中的蒙特卡洛模拟算法蒙特卡洛⽅法也称统计模拟⽅法,是⼀种以概率统计理论为指导的⼀类⾮常重要的数值计算⽅法。
蒙特卡洛⽅法通常可以分成两类:⼀类是所求解的问题本⾝具有内在的随机性,借助计算机的运算能⼒可以直接模拟这种随机的过程。
另⼀种类型是所求解问题可以转化为某种随机分布的特征数,⽐如随机事件出现的概率,或者随机变量的期望值。
通过随机抽样的⽅法,以随机事件出现的频率估计其概率,或者以抽样的数字特征估算随机变量的数字特征,并将其作为问题的解。
这种⽅法多⽤于求解复杂的多维积分问题。
在 IBM SPSS Modeler 中,蒙特卡洛模拟算法分为三个节点,其中“模拟⽣成”节点提供了⼀种使⽤⼤量统计分布从头开始⽣成综合数据的简便⽅法;“拟合”节点可以⾃动构建预配置的源节点,反映历史变量的分布和历史变量间的关系;“模拟评估”节点是设计⽤于评估由模拟分析流产⽣的字段的终端节点,并能提供有⽤的分布和相关图。
限于篇幅,本⽂将分为上下两篇进⾏阐述,上篇重点阐述模拟节点之拟合及⽣成节点,下篇则重点介绍模拟评估节点。
本⽂为上篇。
回页⾸模拟节点的属性及设置“模拟拟合”节点属性及设置1. 节点属性“模拟拟合”节点是将⼀组候选统计分布拟合到数据中的每个字段。
每个分布到字段的拟合可以通过拟合度标准进⾏评估。
执⾏“模拟拟合”节点时,它可以为每个字段分配其最佳拟合分布并⾃动构建⼀个“模拟⽣成”节点(或更新现有节点)。
使⽤“模拟⽣成”节点就可以为每个字段⽣成模拟数据。
虽然“模拟拟合”节点是⼀个终端节点,但它不能⽣成模型,也不能输出或图表或者导出数据。
如果历史数据较为稀疏(即缺失值⾮常多),那么拟合组件可能很难找到⾜够多的有效值将分布拟合到数据。
因此要将分布拟合到数据,拟合组件⾄少需要 2000 个有效值。
因此当数据较为稀疏时应先去除不需要的稀疏字段或插补缺失值,然后再进⾏拟合。
《拟合优度检验》课件
柯克伦科夫勒检验
总结词
柯克伦科夫勒检验是一种基于概率的拟合优度检验方法,用于检验观测频数与期望频数之间的差异是否显著。
详细描述
柯克伦科夫勒检验基于二项分布,通过计算观测频数与期望频数的离差平方和,得到柯克伦科夫勒统计量。在样 本量足够大的情况下,柯克伦科夫勒统计量近似服从正态分布。通过比较柯克伦科夫勒统计量与临界值,可以判 断观测频数与期望频数是否存在显著差异。
03
拟合优度检验的步骤
Chapter
确定检验假设
零假设(H0)
样本数据与理论分布无显著差异。
对立假设(H1)
样本数据与理论分布存在显著差异。
计算检验统计量
统计量计算
根据样本数据和理论分布的性质,计 算相应的统计量,如卡方统计量、熵 值统计量等。
统计量性质
了解统计量的分布特性,以便后续的 临界值判断。
斯皮尔曼秩检验
总结词
斯皮尔曼秩检验是一种非参数拟合优度检验方法,用于检验观测频数与期望频数之间的差异是否显著 。
详细描述
斯皮尔曼秩检验基于秩次,通过将观测频数与期望频数按照大小排序,并计算秩次之差得到秩次统计 量。在自由度等于分类数减一的情况下,秩次统计量服从F分布。通过比较秩次统计量与临界值,可 以判断观测频数与期望频数是否存在显著差异。
Chapter
皮尔逊卡方检验
总结词
皮尔逊卡方检验是最常用的拟合优度检验方法之一 ,用于检验观测频数与期望频数之间的差异是否显 著。
详细描述
皮尔逊卡方检验基于卡方分布,通过计算观测频数 与期望频数的离差平方和,得到卡方统计量。在自 由度等于分类数减一的情况下,卡方统计量服从卡 方分布。通过比较卡方统计量与临界值,可以判断 观测频数与期望频数是否存在显著差异。
复杂数据模型下瑞利及广义瑞利分布的拟合检验与统计推断
复杂数据模型下瑞利及广义瑞利分布的拟合检验与统计推断关键词:瑞利分布;广义瑞利分布;数据模型;拟合检验;统计推断1.引言随着科学技术的进步,数据的规模和复杂性不息增长。
在大数据时代,探究数据分布模型是分外重要的,并且对模型的拟合检验和统计推断也变得尤其关键。
瑞利分布及广义瑞利分布是常见的概率分布模型,其在信号处理、天文学、物理学等领域都有广泛的应用。
因此,对这两种概率分布模型的拟合检验和统计推断具有重要的探究价值。
2.瑞利分布及广义瑞利分布2.1瑞利分布瑞利分布是一种常见的概率分布模型,常用来描述射线、波和信号在随机震动的介质中传输的衰减状况,其概率密度函数为:$$f(x;\sigma)=\frac{x}{\sigma^2}\exp(-\frac{x^2}{2\sigma^2}),x\geq0$$其中,$\sigma$是瑞利分布的标准参数,它是随机过程振幅的方均值的平方根,也称为瑞利参数。
2.2广义瑞利分布广义瑞利分布是瑞利分布的推广形式,其概率密度函数为:$$f(x;k,\sigma)=\frac{2x}{\sigma^2}\left(\frac{x^2}{\sig ma^2}\right)^{\frac{k}{2}-1}\exp(-\frac{x^k}{\sigma^k}),x\geq0,k>0,$$其中,$\sigma$是广义瑞利分布的标准参数,$k$是广义瑞利分布的外形参数。
3.数据模型和预估方法在现实生活中,瑞利分布及广义瑞利分布往往作为复杂数据模型的子模型出现。
针对这种状况,本文介绍了最大似然预估法、贝叶斯预估法和矩预估法等统计方法,并详尽谈论了在复杂数据模型下的参数预估方法。
4.拟合检验为了验证瑞利分布及广义瑞利分布在复杂数据模型下的适用性,本文提出了适用于大样本的渐进理论检验方法和适用于小样本的Bootstrap检验方法。
通过这两种方法的试验结果,本文验证了瑞利分布及广义瑞利分布在复杂数据模型下的优越性。
K-S分布检验和拟合优度χ2检验
第八章 分布检验和拟合优度χ2检验
1
Kolmogorov-Smirnov 单样本检验及一些正态性检验
2
Kolmogorov-Smirnov 两样本分布检验
3
Pearson χ2 拟合优度检验 5
(1 0 0 0 , 0 .0 5 )
1000
因为D1ooo<0.043,故认为样本数据所提供的信息 因为D , 无法拒绝H 即接受H 认为可做正态分布的拟合。 无法拒绝 0,即接受 0,认为可做正态分布的拟合。 K-S检验法是一种精确分布的方法 检验法是一种精确分布的方法, K-S检验法是一种精确分布的方法,不受观察次 数多少的限制。 数多少的限制。这个方法可应用于分组或不分组的 情形。检验量D 情形。检验量 n也可用于检验随机样本是否抽自某 特定的总体的问题。 特定的总体的问题。
第二节
K-S双样本分布检验 双样本分布检验
一、适用范围 K-S双样本检验主要用来检验两个独立样本是否来自 双样本检验主要用来检验两个独立样本是否来自 同一总体(或两样本的总体分布是否相同)。 )。其单 同一总体(或两样本的总体分布是否相同)。其单 尾检验主要用来检验某一样本的总体值是否随机地 大于(或小于)另一样本的总体值。 大于(或小于)另一样本的总体值。 二、理论依据和方法 1、理论依据: 、理论依据: 单样本检验相似, 与K-S单样本检验相似,K-S双样本检验是通过两个 单样本检验相似 双样本检验是通过两个 样本的累计频数分布是否相当接近来判断H 样本的累计频数分布是否相当接近来判断 o是否为 真。如果两个样本间的累计概率分布的离差很大, 如果两个样本间的累计概率分布的离差很大, 同的总体,就应拒绝H 这就意味着两样本来自不同的总体,就应拒绝 o。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第五节 分布拟合检验本章前四节所介绍的各种检验法, 是在总体分布类型已知的情况下, 对其中的未知参数进行检验, 这类统计检验法统称为参数检验. 在实际问题中, 有时我们并不能确切预知总体服从何种分布, 这时就需要根据来自总体的样本对总体的分布进行推断, 以判断总体服从何种分布. 这类统计检验称为非参数检验. 解决这类问题的工具之一是英国统计学家K. 皮尔逊在1900年发表的一篇文章中引进的——2χ检验法,不少人把此项工作视为近代统计学的开端。
内容分布图示★ 引言 ★ 引例 ★ 2χ检验法的基本思想 ★ 2χ检验法的基本原理和步骤★ 2χ检验法-总体含未知参数的情形★ 例1 ★ 例2 ★ 例3 ★ 例4 ★ 例5★ 内容小结 ★ 课堂练习★ 习题7-5内容要点:一、引例例如, 从1500到1931年的432年间, 每年爆发战争的次数可以看作一个随即变量, 据统计, 这432根据所学知识和经验, 即可以假设每年爆发战争次数分布X 近似泊松分布. 于是问题归结为:如何利用上述数据检验X 服从泊松分布的假设.二、2χ检验法的基本思想2χ检验法是在总体X 的分布未知时, 根据来自总体的样本, 检验总体分布的假设的一种检验方法. 具体进行检验时,先提出原假设:0H : 总体X 的分布函数为)(x F然后根据样本的经验分布和所假设的理论分布之间的吻合程度来决定是否接受原假设. 这种检验通常称作拟合优度检验. 它是一种非参数检验. 一般地, 我们总是根据样本观察值用直方图和经验分布函数, 推断出总体可能服从的分布, 然后作检验. 三、2χ检验法的基本原理和步骤 1) 提出原假设:0H :总体X 的分布函数为)(x F如果总体分布为离散型, 则假设具体为0H :总体X 的分布律为 ,2,1,}{===i p x X P i i如果总体分布为连续型, 则假设具体为0H :总体X 的概率密度函数).(x f2) 将总体X 的取值范围分成k 个互不相交的小区间, 记为k A A A ,,2,1 ,如可取为);,(],(,],,(],,(11,22110k k k k a a a a a a a a ---其中0a 可取-∞,k a 可取+∞;区间的划分视具体情况而定,使每个小区间所含样本值个数不小于5,而区间个数k 不要太大也不要太小;3) 把落入第i 个小区间i A 的样本值的个数记作i f ,称为组频数,所有组频数之和k f f f +++ 21等于样本容量n ;4) 当0H 为真时,根据所假设的总体理论分布,可算出总体X 的值落入第i 个小区间i A 的概率i p , 于是i np 就是落入第i 个小区间i A 的样本值的理论频数.5) 当0H 为真时, n 次试验中样本值落入第i 个小区间i A 的频率n f i /与概率i p 应很接近, 当0H 不真时, 则n f i /与i p 相差较大. 基于这种思想, 皮尔逊引进如下检验统计量.)(122∑=-=ki ii i np np f χ 并证明了下列结论. 定理1 当n 充分大)50(≥n 时, 则统计量2χ近似服从)1(2-k χ分布. 根据该定理, 对给定的显著性水平α, 确定l 值, 使αχ=>}{2l P ,查2χ分布表得, ),1(2-=k l αχ 所以拒绝域为).1(22->k αχχ若由所给的样本值n x x x ,,,21 算得统计量2χ的实测值落入拒绝域, 则拒绝原假设0H , 否则就认为差异不显著而接受原假设0H .四、总体含未知参数的情形在对总体分布的假设检验中, 有时只知道总体X 的分布函数的形式, 但其中还含有未知参数, 即分布函数为),,,,,(21r x F θθθ 其中r θθθ,,,21 为未知参数. 设n X X X ,,,21 是取自总体X 的样本, 现要用此样本来检验假设:0H :总体X 的分布函数为),,,,,(21r x F θθθ此类情况可按如下步骤进行检验:1) 利用样本nX X X ,,,21,求出rθθθ,,,21的最大似然估计rθθθˆ,,ˆ,ˆ21 , 2) 在),,,,,(21r x F θθθ 中用i θˆ代替),,,2,1(r i i =θ则),,,,,(21r x F θθθ 就变成完全已知的分布函数).ˆ,,ˆ,ˆ,(21rx F θθθ3) 计算i p 时, 利用).ˆ,,ˆ,ˆ,(21r x F θθθ 计算i p 的估计值);,,2,1(ˆk i pi = 4) 计算要检验的统计量∑=-=ki i i ip n pn f122ˆ/)ˆ(χ, 当n 充分大时,统计量2χ近似服从)1(2--r k αχ分布;5) 对给定的显著性水平α, 得拒绝域).1(ˆ/)ˆ(2122-->-=∑=r k p n p n f ki i i i αχχ 注: 在使用皮尔逊2χ检验法时,要求50≥n ,以及每个理论频数),,1(5k i np i =≥,否则应适当地合并相邻的小区间,使i np 满足要求.例题选讲:例1(讲义例1) 将一颗骰子掷120次, 所得数据见表7-5-216152********54321i n i 出现次数点数问这颗骰子是否均匀、对称? (取05.0=α)解 若这颗骰子是均匀的、对称的, 则1~6点中每点出现的可能性相同, 都为1/6. 如果用i A 表示第i 点出现),6,,2,1( =i 则待检假设 6/1)(:0=i A P H .6,2,1 =i在0H 成立的条件下, 理论概率,6/1)(==i i A p p 由120=n 得频率.20=i np 计算结果如下表.因此分布不含未知参数, 又,6=k ,05.0=α 查表得.071.11)5()1(205.02==-χχαk由上表, 知,071.118.4)(6122<=-=∑=i ii i np np f χ 故接受,0H 认为这颗骰子是均匀对称的.例2(讲义例2)检验引例中对战争次数X 提出的假设X H :0服从参数为λ的泊松分布. 根据观察结果, 得参数λ的最大似然估计为.69.0ˆ==x λ按参数为0.69的泊松分布, 计算事件i X =的概率,i p i p 的估计是,!/69.0ˆ69.0i e pi i -=4,3,2,1,0=i将5ˆ<i pn 的组予以合并, 即将以生3次及4次战争的组归并为一组.因0H 所假设的理论分布中有一个未知参数, 故自由度为.2114=--按,05.0=α 自由度为2 查2χ分布表得 ,991.5)2(205.0=χ 因统计量2χ的观察值,991.5433.22<=χ 未落入拒绝域. 故认为每年发生战争的次数X 服从参数为0.69的泊松分布.例3 一农场10年前在一鱼塘 里按比例20:15:40:25投放了四种鱼:鲑鱼,鲈鱼,竹夹鱼,和试取α解 以X 记鱼种类的序号, 按题意需检验假设: X H :0的分布律为所需计算列在下表中. 现在 60041.1162-=χ,41.11=,4=k ,0=r 但)1(205.0--r k χ,14.11815.7)3(205.0<==χ 故拒绝,0H 认为各鱼类数量之比较10年前有显著改变.例4 在一次实验中, 每隔一定时间时观察一次由某种铀所放射的到达计数器上的a 粒子数X , 共观察了100次, 得结果如下表所示铀放射的到达计数器上的α粒子数的实验记录121110987654321012129911261716511211109876543210A A A A A A A A A A A A A A f i ii ≥应服从泊松分布从理论上考虑知粒子的次数个是观察到有其中X i f i .α.,2,1,0,!}{ ===-i i e i X P i λλ::05.00服从泊松分布总体下检验假设试在水平X H.,2,1,0,!}{ ===-i i e i X P i λλ解 因在0H 中参数λ未具体给出, 所以先估计.λ14.61116.18815025.016867.16624040.020011.1119015.010020.14512020.0132ˆ/ˆˆ43212=∑A A A A p n f pn pf A i i i i ii由最大似然估计法得.2.4ˆ==x λ在0H 假设下, 即在X 服从泊松分布的假设下, X 所有可能取的值为},,2,1,0{ 将其分成如表所示的两两不相交的子集将其分成如表所示的两两不相交的子集,,,,1210A A A 则}{i X P =有估计,!2.4ˆ2.4i e p i i -= ,1,0=i计算结果如表所示, 其中有些5ˆ<i pn 的组予以适当合并, 使得每组均有,5ˆ<i p n 如表中第四列花括号所示. 此处, 并组后,8=k 但因在计算概率时, 估计了一个参数,λ 故,1=r2χ的自由度为.6118=--查表得592.12)6()118(205.0205.0==--χχ现在,592.12281.6100281.1062<=-=χ 故在水平0.05下接受,0H 即认为样本来自泊松布总体.例5(讲义例3)为检验棉纱的拉力强度(单位: 公斤)X 服从正态分布, 从一批棉纱中随机抽取300条进行拉力试验, 结果列在表7-5-5中, 我们的问题是检验假设:0H )01.0(),(~2=ασμN X .表7-5-5 棉纱拉力数据5648.1~34.17138.2~18.2135334.1~20.16318.2~04.2123720.1~06.151604.2~90.1112506.1~92.041990.1~76.110992.0~78.032576.1~62.19278.0~64.025362.1~48.18164.0~5.01ii f xi f xi解 可按以下四步来检验:(1) 将观测值i x 分成13组: ,0∞-=a ,64.01=a ,78.02=a , ,81.212=a ,13∞=a 但是这样分组后, 前两组和最后两组的i np 比较小, 故把它们合并成为一个组(见分组数据表)(2) 计算每个区间上的理论频数. 这里)(x F 就是正态分布),(2σμN 的分布函数, 含有两个未知数μ和,2σ 分别用它们的最大似然估计X =μˆ和∑=-=ni in X X 122/)(ˆσ来代替. 关于X的计算作如下说明: 因拉力数据表中的每个区间都很狭窄, 我们可认为每个区间内i X 都取这个区间的中点, 然后将每个区间的中点值乘以该区间的样本数, 将这些值相加再除以总样本数就得具体样本均值,X 计算得到: ,41.1ˆ=μ.26.0ˆ22=σ 对于服从)26.0,41.1(2N 的随机变量Y , 计算它在上面第i 个区间上的概率.i p (3) 计算30021,,,x x x 中落在每个区间的实际频数,i f 如分组表中所列.(4) 计算统计量值: ,07.22ˆ)ˆ(10122=-=∑=k i i i p n pn f χ 因为,2,100==r k 故2χ的自由度为,71210=-- 查表得 ,07.2248.18)7(2201.0=<=χχ 故拒绝原假设, 即认为棉纱拉力强度不服从正态分布.棉纱拉力数据的分组表课堂练习1. 自1965年1月1日至1971年2月9日共2231天中,全世界记录到里氏震级4级和4级以上地震计162次,统计如下:相继两次地震记录表86681017263150403935343029252420191514109540出现的频率间隔天数--------x 试检验相继两次地震间隔的天数X 服从指数分布(=α0.05).31.969.60223.01604.2~90.11048.152.170584.01990.1~76.1915.1115.361205.02576.1~62.1838.238.551846.05362.1~48.1784.784.632128.05648.1~34.1638.238.551846.05334.1~20.1585.015.361205.03720.1~06.1448.752.170584.02506.1~92.0331.269.60223.0992.0~78.0232.268.40156.0704.278.01ˆˆˆ---->≤-或区间区间序号i i i i i p n f p n pf。