SPSS常用函数
spss函数大全解读资料

Spss 算术函数孙中友江苏ABS(numexpr 数值。
返回 numexpr (必须为数值的绝对值。
ARSIN(numexpr 数值。
返回 numexpr 的反正弦(以弧度为单位 ,求出的值必须为 -1 和 +1 之间的数字值。
ARTAN(numexpr 数值。
返回 numexpr 的反正切(以弧度为单位 , numexpr 必须为数字值。
COS(radians 数值。
返回 radians 的余弦(以弧度为单位 , radians 必须为数字值。
EXP(numexpr 数值。
返回 e 的 numexpr 次幂, 其中 e 是自然对数的底数, 而numexpr 是数值。
较大的 numexpr 值可能会产生超过机器性能的结果。
LN(numexpr 数值。
返回以 e 为底数的 numexpr 的对数, numexpr 必须为大于 0 的数值。
LNGAMMA(numexpr 数值。
返回 numexpr 的完全 Gamma 函数的对数, numexpr 必须为大于 0 的数值。
LG10(numexpr 数值。
返回以 10 为底数的 numexpr 的对数, numexpr 必须为大于 0 的数值。
MOD(numexpr,modulus 数值。
返回 numexpr 除以 modulus 所得到的余数。
两个参数都必须为数值,且 modulus 不得为 0。
RND(numexpr 数值。
返回对 numexpr 舍入后产生的整数, numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去 0 以后的数值。
SIN(radians 数值。
返回 radians 的正弦(以弧度为单位 , radians 必须为数字值。
SQRT(numexpr 数值。
返回 numexpr 的正平方根, numexpr 必须为非负数。
TRUNC(numexpr 数值。
返回 numexpr 被截断为整数(向 0 的方向的值。
统计函数后缀 .n 可在所有统计函数中使用以指定有效参数的数目。
SPSS学习系列28. 二元Logistic回归
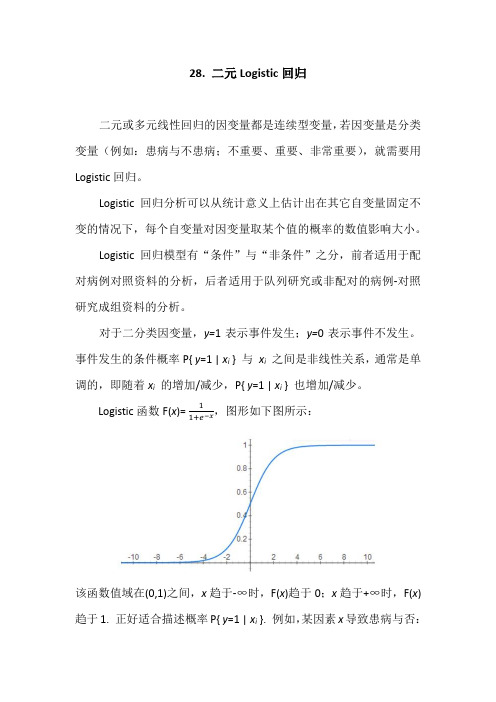
28. 二元Logistic回归二元或多元线性回归的因变量都是连续型变量,若因变量是分类变量(例如:患病与不患病;不重要、重要、非常重要),就需要用Logistic回归。
Logistic回归分析可以从统计意义上估计出在其它自变量固定不变的情况下,每个自变量对因变量取某个值的概率的数值影响大小。
Logistic回归模型有“条件”与“非条件”之分,前者适用于配对病例对照资料的分析,后者适用于队列研究或非配对的病例-对照研究成组资料的分析。
对于二分类因变量,y=1表示事件发生;y=0表示事件不发生。
事件发生的条件概率P{ y=1 | x i } 与x i之间是非线性关系,通常是单调的,即随着x i的增加/减少,P{ y=1 | x i } 也增加/减少。
,图形如下图所示:Logistic函数F(x)=11+e−x该函数值域在(0,1)之间,x趋于-∞时,F(x)趋于0;x趋于+∞时,F(x)趋于1. 正好适合描述概率P{ y=1 | x i }. 例如,某因素x导致患病与否:x 在某一水平段内变化时,对患病概率的影响较大;而在x 较低或较高时对患病概率影响都不大。
记事件发生的条件概率P{ y =1 | x i } = p i ,则p i =11+e −(α+βx i )=e α+βx i 1+e α+βx i记事件不发生的条件概率为1- p i =11+e α+βx i则在条件x i 下,事件发生概率与事件不发生概率之比为p i 1−p i= e α+βx i称为事件的发生比,简记为odds. 对odds 取自然对数得到ln (p i1−p i)= α+βx i 上式左边(对数发生比)记为Logit(y), 称为y 的Logit 变换。
可见变换之后的Logit(y)就可以用线性回归,计算出回归系数α和β值。
若分类因变量y 与多个自变量x i 有关,则变换后Logit(y)可由多元线性回归:11logit()ln()1k k pp x x p αββ==++-或 111()1(1|,,)1k k k x x p y x x e αββ-++==+一、简单的二元Logistic 回归出现某种结果的概率与不出现的概率之比,称为优势比OR. 问题1:研究“低体重出生儿”与“孕妇是否吸烟”之间的关系 有数据文件:因变量low:是否“低体重出生儿”(0=正常,1=低体重);自变量smoke:是否吸烟(0=不吸烟,1=吸烟)【分析】——【回归】——【二元Logistic】,打开“Logistic回归”窗口,将变量“low”选入【因变量】框,变量“smoke”选入【协变量】框;点【确定】,得到因变量编码初始值内部值正常0低出生体重 1块 0: 起始块若模型只含常数项,预测正确率为68.8%(=130/189);方程中的变量B S.E, Wals df Sig. Exp (B)步骤 0 常量-.790 .157 25.327 1 .000 .454 B=-0.79为模型常数项估计值,S.E为B的标准误;Wals为Wald卡方检验,原假设H0:回归系数=0;Exp(B)=0.454(表示患病率与未患病率之比:(1-68.8%)/68.8%);引入变量后的得分,以及该变量的回归系数是否为0的检验,原假设H0:回归系数=0;(主要针对逐步引进多个变量时的变量筛选)块 1: 方法 = 输入似然比卡方值,上一模型(常数项模型)与当前模型似然比值之差,检验两个模型有无差异,原假设H0:无差异。
SPSS05日期时间函数及其应用

返回目录
常量格式示例3
格 式 dd-mmm-yyyy hh:mm dd-mmm-yyyy hh:mm:ss dd-mmm-yyyy hh:mm:ss.ss hh:mm hh:mm:ss hh:mm:ss.ss ddd hh:mm ddd hh:mm:ss ddd hh:mm:ss.ss 说 明 日(2位)-月(英文月份缩写)-年(4位) 时 (2位):分(2位) 日(2位)-月(英文月份缩写)-年(4位) 时 (2位):分(2位):秒(2位) 日(2位)-月(英文月份缩写)-年(4位) 时 (2位):分(2位):秒(2位).百分秒 时(2位):分(2位) 时(2位):分(2位):秒(2位) 时(2位):分(2位):秒(2位).百分秒 日数 时(2位):分(2位) 日数 时(2位):分(2位):秒(2位) 日数 时(2位):分(2位):秒(2位).百分秒 示 例 11-AUG-1945 11:10 11-AUG-1945 11:10:35 11-AUG-1945 11:10:35.30 11:30,08:50 11:08:05,08:15:25 11:08:05.80,08:15:25.45 128 08:50 128 08:50:30 128 08:50:30.78
SDATEw
可排序的 日期*
8 10
4
8 10
6 8 6
40
yy/mm/dd yyyy/mm/dd
90/10/28 1990/10/28
4 Q 90 4 Q 1990 OCT 90
40
q Q yy q Q yyyy
QYRw
季度和年
6 6
40
mmm yy
MOYRw
月和年
8 6
WKYRw 星期和年 8
spss求一元多次函数

spss求一元多次函数
一元多次函数是在数学中最常见的函数形式之一,可以作为一种工具来分析和
处理各种实际问题。
使用SPSS(Statistical Package for the Social Sciences)求一元多次函数可以更好地掌握与之相关关系,从而得出有价值的结论和指导。
首先,使用SPSS进行一元多次函数求解时,首先需要输入原始数据。
通常来说,原始数据都是用于确定函数拟合的的结果的X,Y值的对应关系。
然后,输入
相关参数,SPSS将自动运行优化算法来拟合出最佳的函数形式。
此外,可以使用SPSS计算出一元多次函数表示或模型,根据计算出的参数,进一步计算出当前原
始数据集的拟合和预测值,从而比较当前的一元多次函数模型的准确性。
此外,SPSS还可用来验证多元多次函数模型的准确性,例如,对原始数据进
行多元实验分析,比较实验结果,以便了解数据的变化趋势,从而进一步验证多元多次函数模型的准确性。
总之,SPSS作为一种统计和分析工具,能很好地帮助用户更轻松地求一元多
次函数模型。
它能够根据用户输入的原始数据,计算最佳的拟合模型;能够计算拟合值与实际值的比较,验证模型准确性;还可以基于实验数据进行分析,以便获得更可靠的结果。
SPSS的常用的一些函数大全

算术函数ABS(numexpr) 数值。
返回numexpr(必须为数值)的绝对值。
ARSIN(numexpr) 数值。
返回numexpr 的反正弦(以弧度为单位),求出的值必须为-1 和+1 之间的数字值。
ARTAN(numexpr) 数值。
返回numexpr 的反正切(以弧度为单位),numexpr 必须为数字值。
COS(radians) 数值。
返回radians 的余弦(以弧度为单位),radians 必须为数字值。
EXP(numexpr) 数值。
返回e 的numexpr 次幂,其中e 是自然对数的底数,而numexpr 是数值。
较大的numexpr 值可能会产生超过机器性能的结果。
LN(numexpr) 数值。
返回以e 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
LNGAMMA(numexpr) 数值。
返回numexpr 的完全Gamma 函数的对数,numexpr 必须为大于0 的数值。
LG10(numexpr) 数值。
返回以10 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
MOD(numexpr,modulus) 数值。
返回numexpr 除以modulus 所得到的余数。
两个参数都必须为数值,且modulus 不得为0。
RND(numexpr) 数值。
返回对numexpr 舍入后产生的整数,numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去0 以后的数值。
SIN(radians) 数值。
返回radians 的正弦(以弧度为单位),radians 必须为数字值。
SQRT(numexpr) 数值。
返回numexpr 的正平方根,numexpr 必须为非负数。
TRUNC(numexpr) 数值。
返回numexpr 被截断为整数(向0 的方向)的值。
统计函数后缀.n 可在所有统计函数中使用以指定有效参数的数目。
例如,仅当至少两个变量含有效值时,MEAN.2(A,B,C,D) 对变量A、B、C 和D 返回其有效值的均值。
实战利用SPSS进行生存分析

实战利⽤SPSS进⾏⽣存分析⽤SPSS软件进⾏⽣存分析给⼤家介绍3种常⽤⽅法寿命表法、Kaplan-Meier分析法、Cox回归分析⼀、寿命表分析适⽤于⼤数据⽰例:若要研究性别对于肺病⽣存率有⽆区别,收集数据下列信息time:⽣存时间(单位天)status:0=存活,1=死亡sex:1=男,2=⼥操作步骤按步骤将数据导⼊(lung数据集来⾃于R 内置数据)选定寿命表分析⽅法对各选项进⾏设置(其中注意状态设置:选取表⽰事件已发⽣的值)设置完所有选项后确认得到结果(可进⾏导出)1.得到存活表:该表给出了男⼥对应时间内存活和死亡⼈数,并计算了存活率、风险⽐等统计量2.中位数⽣存时间:即⽣存率为50%时,⽣存时间的平均⽔平;可知:⽣存时间的平均⽔平⼥⼠⾼于男⼠3.⽣存函数:男⼠较⼥⼠累计⽣存率下降快⼆、Kaplan-Meier分析适⽤于⼩样本⽰例:若要研究药物治疗对卵巢癌⽣存率有⽆区别,收集数据下列信息futime:⽣存时间(单位天)fustat:0=存活,1=死亡rx:1=未治疗,2=治疗操作步骤:按步骤将数据导⼊(ovarian数据集来⾃于R内置数据)选定Kaplan-Meier分析法,并对选项进⾏设置设置结束后确认,得到结果(可进⾏导出)1.⽣存表的均值和中位数、百分位数:可以看出治疗与未治疗有均值、四分位数略有差异2.整体⽐较:检验结果p值>0.05,证明治疗组与⾮治疗组差异不显著3.存活函数:治疗组较⾮治疗组⽣存结果好,但从假设检验结果来看差异不明显三、Cox回归分析⽰例:若要研究结肠癌治疗⽅式对患者⽣存时间的影响,收集了下⾯所⽰的数据:time:⽣存时间(单位天)status:0=存活,1=死亡rx:治疗⽅式,Obs=观察,Lev=⽅式1,Lev+5FU=⽅式2obstruct:0=⽆阻塞的结肠肿瘤,1=有阻塞的结肠肿瘤perfor:0=⽆结肠穿孔,1=有结肠穿孔extent:传播程度:1 =黏膜下层,2 =肌⾁,3 =浆膜,4 =相邻结构操作步骤:导⼊结肠癌colon数据(R中内置数据)选定cox回归分析参数设置:协变量依次导⼊,⽅法按分析所需进⾏选择点击'分类',协变量依次选⼊分类协变量点击'绘图',勾选⽣存函数,主要变量为rx,将rx变量选⼊单线框中,绘制⽣存曲线点击'选项',设置输出RR的95%置信区间。
SPSS05日期时间函数及其应用(1)

返回
格利戈里历法很快在罗马天主教势力范围被 普遍接受,但是在英国却引起了一片喧嚣的反对 声,英国人仍然坚持朱利安历法,拒绝“抹掉10 天”。直到1752年,英国人才想通,理性终于占 了上风,不过从1582年到那时,历法又多出了1天, 所以英国议会在1752年作出决定,抹掉11天---1752年9月3日至13日,至此才接受了格利戈里的 改革。请注意,英国历史中,这11天什么也没有 发生。由此可以看到,一次历法改革是多么不容 易,对于一个聪明、合理的决定,仅仅因为看上 去有点怪就有人反对,竟然花了快二百年才接受!
常量格式示例2
格 式 q Q yyyy q Q yy mmm yyyy mmm yy ww WK yyyy ww WK yy Monday, Tuesday… Mon, Tue, Wed… January, February… Jan, Feb, Mar… 季度 Q 年(4位) 季度 Q 年(2位) 月份(英文)年(4位) 月份(英文)年(2位) 周数 “WK” 年(4位) 周数 “WK” 年(2位) 直接输入英文的星期几 直接输入星期几的英文缩写 直接输入英文月份 直接输入英文月份缩写 说 明 示 例 3Q1945,4Q1995 3Q45,4Q95 AUG1945 DEC1995 AUG45DEC95 33 WK 1945,52 WK 1995 33 WK 45,52 WK 95 Friday FRI August,December AUG,DEC 返回
常量格式示例3
格 式 dd-mmm-yyyy hh:mm dd-mmm-yyyy hh:mm:ss dd-mmm-yyyy hh:mm:ss.ss hh:mm hh:mm:ss hh:mm:ss.ss ddd hh:mm ddd hh:mm:ss ddd hh:mm:ss.ss 说 明 日(2位)-月(英文月份缩写)-年(4位) 时 (2位):分(2位) 日(2位)-月(英文月份缩写)-年(4位) 时 (2位):分(2位):秒(2位) 日(2位)-月(英文月份缩写)-年(4位) 时 (2位):分(2位):秒(2位).百分秒 时(2位):分(2位) 时(2位):分(2位):秒(2位) 时(2位):分(2位):秒(2位).百分秒 日数 时(2位):分(2位) 日数 时(2位):分(2位):秒(2位) 日数 时(2位):分(2位):秒(2位).百分秒 示 例 11-AUG-1945 11:10 11-AUG-1945 11:10:35 11-AUG-1945 11:10:35.30 11:30,08:50 11:08:05,08:15:25 11:08:05.80,08:15:25.45 128 08:50 128 08:50:30 128 08:50:30.78 返回
SPSS常用参数设置

同样包括"前缀"与"后缀"两个输入框,分别用于输入所有负值的前缀与后缀,系统 默认前缀为"-"。
"小数分隔符"
该选项组用于设置小数分隔符,有"句点"和"逗号"两种分隔符可选。
五、输出
"轮廓标签"
该选项组包括"项标签中的变量显示为(V)"和"项标签中的变量显示为(A) "两个下拉框,分别用于设置变量标签和变量值的显示方式。两个下拉框中 都有三个可选项:"标签",使用变量标签标示每个变量;"名称",使用变量 名称标示每个变量;"标签与名称",两者都使用。
十一、语法编辑器
"语法颜色编码"
在该选项组中,用户可以选择是否显示语法颜色编码并设置"命令"、"子命令"、"关 键字"、"值"、"注释"及"引号"的字体和颜色。
"错误颜色编码"
在该选项组中,用户可以选择是否显示验证颜色编码并设置在命令和子命令中语法 错误的字体和颜色。
"装订线"
该选项组包括"显示行号"和"显示命令跨度"两个复选项,用于设置在语法编辑器的 装订线内是否显示行号和命令跨度。
八、文件位置
"会话日志"
该选项组用户可以勾选"日志中的记录语法"复选框启用会话日志自动记录会话中 运行的命令,可以通过选择"附加"或"覆盖"设置日志文件的记录方式,此外用户 还可以选择日志文件的名称和位置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS常用函数SPSS函数是一个常用程序,并且利用一个或多个自变量(参数)来执行。
每个SPSS函数均有一个关键名称,且绝不能写错。
通常,函数的格式为:函数名称(自变量,自变量,……),某些函数可能只含有一个自变量,而有些函数则可能含有多个自变量,当一个函数含有多个自变量时,各自变量间用逗号(,)隔开,而函数的自变量通常又可分为以下三种:(1)常数,如SQRT(100);(2)变量名称,如MEAN(VAR1,VAR2,VAR3);(3)表达式,如MIN(30,SQRT(100))。
总之,SPSS函数和我们平时EXCEL里面函数格式规则并无差别。
SPSS提供了180多种函数,共可分为十多类(SPSS 17.0中大大小小分了18类)。
和EXCEL一样,我们也不可能记住所有函数,只要知道一些常用函数,至于其他函数要用的时候再去查找也不迟,下面将列举一些常用函数:1.ArithmeticFunctions算术函数算术函数是最常用的函数,可以满足对变量进行的一般运算,算术函数主要有:﹡算术表达式也包括单值与变量名的情况。
2.StatisticalFunctions统计函数统计函数也是统计分析中常用的函数之一,主要反映变量的数据特征,时间序列的滞后期变量等,具体函数有:3.LogicalFunctions逻辑函数l ANY(test,valu,value,…]) 逻辑型函数,自变量为(变量名,x1,x2,…),函数功能是判断变量值是否是x1、x2…中的一个,例如:Any(数学,80,90,70):分别对每条个案判断其数学成绩是否为80或90或70分。
l RANGE(test,lo,hi[,10,hi...] 逻辑型函数变量必须都为数值型或都为字符型,自变量为(变量名,x1,x2),其中:x1≤x2,函数功能是判断某变量值是否在x1至x2之间,例如:RANGE (数学,80,90):分别对每条个案判断其数学成绩是否在80至90分之间4.DateandTimeFunctions日期和时间函数l DATE.DMY (day,month,year)SPSS日期型格式的数值函数,返回与指定的日、月、年相应的日期值。
要正确显示这个值,必须将变量赋予DATE格式。
自变量必须为整数。
day的范围在1~31,month的范围在1~12,year的范围在4位数时要大于1582,2位数时应是该世纪的后两位年代数值。
l DATE.YRDAY(year,daynum)SPSS格式日期型数值函数,返回与指定的天数、年相应的日期值。
要正确显示这个值,必须赋予其DATE格式。
Daynum取值范围在1~366。
l XDATE.DATE(datevalue)SPSS日期格式的数值型函数,从具有SPSS的日期格式的自变量数值返回一个日期,自变量数值由DATE.xxx函数产生或按DATEs输入格式读取。
该函数用于将日期的数值格式转换为日期格式,因此要想按日期格式显示必须再在Variable View中定义一种日期格式,否则会按SPSS日期的数值格式显示。
此函数无2000年问题21世纪的日期也能正确显示。
l XDATE.HOUR(datevalue)数值型函数,从DATE.xxx函数产生或按一种DATE格式读入的SPSS日期格式的数值,返回一个小时数(0~23)。
l XDATE.JDAY(datevalue)数值型函数,通过DATE.xxx产生或由DATE输入格式读入SPSS日期格式的数值,返回一年的天数(1~366)。
l XDATE.MDAY(datevalue)数值型函数,从一个SPSS日期格式的数值通过DATE.xxx函数产生或由DATE输入格式读入,返回一个月的天数(1~31)。
l XDATE.MINUTE(datevalue)数值型函数,通过DATE.xxx产生或由DATE输入格式读入SPSS日期格式的数值,返回分钟数(0-59)。
l XDATE.MONTH(datevalue)数值型函数,通过DATE.xxx产生或由DATE输入格式读入SPSS日期格式的数值,返回一年中的月数(1~12)。
l XDATE.TDAY(timevalue)数值型函数,自变量是由TIME.XXX 函数产生或由TIME输入格式读取的SPSS时间间隔格式的数值,返回整天数(正整数)。
l XDATE.TIME(datevalue)SPSS时间间隔格式的数值型函数,把自变量的值看作从午夜开始的秒数,返回一天中的时间(小时、分、秒)。
自变量是SPSS日期格式的数值,可以是由DATE.xxx函数产生的或由DATE输入格式读入的。
由该函数建立的变量应该给定一个合适的显示格式。
在VariableView中,赋予它一个时间显示格式,将变量值显示成小时和分。
l XDATE.WEEK(datevalue)数值型函数。
由一个SPSS日期格式数值(由DATE.xxx函数产生或由一种DATE输入格式读入),返回周数(1~53整数)。
l XDATE.WKDAY(datevalue)数值型函数,由一种通过DATE.xxx 函数产生或用DATE格式读入的SPSS日期格式数值,返回的数值表示一周的星期几(星期1~星期日用1~7之间的整数表示)。
l XDATE.YEAR(datevalue)数值型函数,由DATE.xxx函数产生或用DATE格式读入的SPSS日期格式的数值,返回年数。
l YRMODA(year,month,day)数值型函数,返回一个由1582年10月15日到自变量给定的年月日(year,month,day)之间的天数。
总结:以上的日期函数分为三大类:date.SSS(); XDATE.SSS(datevalue);YRMODA(year,month,da y); 他们有各自不同的作用,其中的变量也不尽相同。
其中date函数中()主要是用来返回其中XDATE函数中的()主要是用来返回具体的日期数据的。
5.RandomVariableFunctions随机变量函数随机变量函数的一般形式为:RV.分布名(参数,…)。
其中圆点前是函数类名,圆点后是分布名称,圆点是半角的圆点,括号内是自变量。
自变量是分布参数。
如果在数据文件中建立新变量时使用这些函数,变量值的个数等于数据文件中有效观测量数。
函数值为产生服从指定统计分布的随机序列。
下面列出常用的分布函数的随机数。
l NORMAL(stddev)数值型函数,产生一个来自均值为0标准差为stddev的分布总体的随机数。
l RV.BERNOULLI(p)数值型函数,产生一个来自伯努利分布具有指定概率参数P的随机数。
l RV.BINOM(n,p)数值型函数,产生一个来自二项式分布具有指定试验次数n和概率参数p的随机数。
l RV.CHISQ(df)数值型函数,产生一个来自卡方分布具有指定自由度df的随机数。
l RV.EXP(shape)数值型函数,产生一个来自指数分布具有指定形状参数的随机数。
l RV.F(df1,df2)数值型函数,产生一个来自F分布具有指定自由度的随机数。
l RV.GEOM(p)数值型函数,产生一个来自几何分布具有指定概率参数P的随机数。
l RV.HYPER(totd,sample,hits) 数值型函数,产生一个来自超几何分布具有指定参数的随机数。
l RV.LOGISTIC(mean,scale)数值型函数,产生一个来自逻辑斯蒂分布具有指定的均数mean和标度scale参数的随机数。
l RV.LNORMAL(a,b)数值型函数,产生一个来自对数正态分布具有指定参数的随机数。
l RV.NORMAL(mean,stddev)数值型函数,产生一个来自正态分布具有指定均值mean和标准差stddev的随机数。
l RV.PARETO(threshold,shape)数值型函数,产生一个来自帕雷托分布具有指定临界值threshold和形状shape参数的随机数。
l RV.POISSON(mean)数值型函数,产生一个来自泊松分布具有指定均值或比率参数的随机数。
l RV.T(df)数值型函数,产生一个来自学生T分布具有指定自由度的随机数。
l RV.UNIFORM(min,max)数值型函数,产生一个来自具有指定最大值max和最小值mill的均匀一致分布的随机数.l RV.WEIBULL(a,b)数值型函数,产生一个来自威布尔分布具有指定参数的随机数。
l UNIFORM(max)数值型函数,产生一个来自一致分布的值在0和自变量给定的Max之间的伪随机数。
自变量Max必须是一个数值,但可以是负数。
6.InverseDistributionFunctions反分布函数反分布函数的一般形式为:IDF.分布名(p,参数,…)。
其中圆点前是函数类名,圆点后是分布名称,括号内是自变量。
第一个自变量p 是这个分布的累积概率,其后的自变量是指定分布的参数。
函数值是相应分布的累计概率值为p的临界值。
l IDF.CHISQ( (p,df)数值型函数,产生来自卡方分布的临界值,第一个自变量为概率值p,第二个自变量为自由度df。
例如:累积概率为0.95,自由度为5的卡方分布的临界值记作IDF.CHISQ(0.95,5),其函数值IDF.CHISQ(0.95,5)=1.145。
l IDF.EXP(p,scale)数值型函数。
产生一个来自指数分布的临界值,该分布具有给定行状参数shape,概率值p。
l IDF.F(p,dfl,df2)数值型函数,产生一个来自F分布的值,该分布自由度为dfl、df2,累计概率p的临界值。
例如显著性概率在0.05水平上,自由度分别为6、5的F值为IDF.F (0.95,6,5)=4.9503。
l DF.LOGISTIC(prob,mean,scale)数值型函数,产生一个均值为mean和标度参数为scale,累计概率为p的逻辑斯蒂分布的临界值。
l IDF.LNORMAL(p,a,b)数值型函数,产生具有指定参数和累计概率p的对数正态分布的临界值。
l IDF.NORMAL(p,mean,stddev)数值型函数,产生来自正态分布具有指定均值和标准差的累计概率。
例如,显著性水平为0.05,均值为0,标准差为1的标准正态分布的临界值IDF.NORMAL(0.95,0,1)=1.645。
l IDF.PARETO(prob,threshold,shape)数值型函数,产生一个来自帕累托分布,累计概率为p的值,该分布的临界值为threshold,尺度参数为scale。
l IDF.T(prob,df)数值型函数,产生一个自由度df,累计概率为p 的来自学生T分布的临界值。
l IDF.UNIFORM(p,min,max)数值型函数,产生一个累计概率p 的来自均匀分布的临界值,均匀分布的最大值max、最小值min。