专题2:线性判别分析、诊断的敏感度、特异度及ROC曲线的绘制
最新ROC分析方法概要资料

第二章ROC曲线分析概要本文先介绍了ROC理论的一些基础知识如特异度和灵敏度等,然后简要介绍了非参数ROC分析方法,并建立了ROC模型。
最后介绍了ROC曲线及在R软件中的绘制。
2.1 ROC分析的基本要素ROC分析的基本要素包括真阳性和假阳性也称灵敏度和特异度,以及“金标准”“金标准”划分被测试者的真实状态为对照组和病例组两类。
常见的金标准有跟踪随访、活组织检查、尸体解剖、手术探查等。
虽然“金标准”没有必要是十全十美的,但“金标准”应与评价的诊断系统无关,而且比要评价的诊断系统更可靠。
“金标准”不够完美时,可用采用Bayesian、模糊金标准、EM估计等方法解决。
对按照“金标准”确定的二分类总体,对照组和病例组分别用阴性和阳性表示诊断试验结果。
假定总体样本量是N,诊断试验的可能结果总共有四种:被测试者患病且被正确诊断为患病者,被测试者无病且被错误诊断为患病者,被测试者无病且被正确诊断为无病者,被测试者无病且被错误诊断为患病者。
我们可以用一个2×2的列联表来表示它们之间的关系。
在医学研究中,诊断试验准确度指标最常用的是灵敏度与特异度。
灵敏度(sensitivity),也叫真阳率(true positive rate,即TPR)是被测试者患病且被正确诊断为患病者的样本量在阳性总体中占的比例。
灵敏度值越大,假阴率越小。
据表2-1 其计算公式是:灵敏度(sensitivity) = 真阳率(TPR)= 1 −假阴率(FNR)=标准误为:特异度(specificity),也叫真阴率(true non-positive rate,即TNPR),是受试者无病且被正确诊断为无病者的样本量占阴性总体的比例。
假阳率(false positive rate,即FPR) = 1−特异度特异度值越大,假阳率越小。
据表2-1 其计算公式是:特异度(specificity) =真阴率(TNPR) = 1−假阳率(FPR) =标准误为:假设二分类总体均服从正态分布, TPR、FPR、TNPR 和FNPR之间的关系可以用图2-1来描述。
roc曲线特异度

roc曲线特异度ROC曲线全称为受试者工作特性曲线(Receiver Operating Characteristic curve),是一种用来评价二分类模型预测性能的工具。
特异度(specificity)是ROC曲线的一个重要组成部分,表示在所有实际为负例的样本中,模型预测为正例的比例。
一、特异度的定义特异度(specificity),也称为真负率(true negative rate),被定义为所有实际为负例的样本中,模型预测为负例的比例。
在二分类模型中,假设有两个类,类0和类1。
特异度定义为真正例率(TPR)和假正例率(FPR)的比值,即specificity = TPR / (TPR + FPR)。
其中,TPR表示真正例率,即实际为正例且被模型预测为正例的比例;FPR表示假正例率,即实际为负例但被模型预测为正例的比例。
二、特异度的计算特异度的计算需要基于模型的预测结果和实际样本标签。
假设有N个样本,其中N0个样本实际为类0,N1个样本实际为类1。
模型对每个样本进行预测,得到一个预测概率值,根据这个概率值将样本分为正例或负例。
然后可以计算出真正例数(TP,即实际为类1且被预测为类1的样本数)和假正例数(FP,即实际为类0但被预测为类1的样本数)。
特异度即可由以下公式计算:specificity = TP / (TP + FP)。
三、特异度的意义特异度是ROC曲线的一个重要组成部分,它表示模型对于负例的预测能力。
特异度高意味着模型对于负例的预测准确性较高,能够有效地将负例排除。
在许多实际应用场景中,我们往往更关注模型的特异度,因为避免将负例误判为正例往往更为重要。
四、特异度与ROC曲线ROC曲线是以假正例率(FPR)为横坐标,以真正例率(TPR)为纵坐标绘制的曲线。
特异度是ROC曲线的一个重要组成部分,表示在所有实际为负例的样本中,模型预测为正例的比例。
在绘制ROC曲线时,随着模型阈值的改变,特异度也会发生变化。
r语言绘制roc曲线的步骤

r语言绘制roc曲线的步骤引言:R语言是一种功能强大的统计分析工具,它提供了丰富的绘图功能,包括绘制ROC曲线。
ROC曲线是一种用于评估分类模型性能的图形工具,它可以帮助我们判断分类模型的准确性和可靠性。
本文将介绍使用R语言绘制ROC曲线的步骤。
正文:1. 数据准备1.1 导入数据在R语言中,我们可以使用read.csv()函数导入数据。
首先,我们需要将数据保存为csv格式,然后使用read.csv()函数将数据读入R环境中。
1.2 数据预处理在绘制ROC曲线之前,我们需要对数据进行预处理,以确保数据的准确性和一致性。
这包括处理缺失值、处理异常值、数据标准化等步骤。
2. 构建分类模型2.1 选择合适的分类模型在绘制ROC曲线之前,我们需要选择合适的分类模型。
常用的分类模型包括逻辑回归、决策树、支持向量机等。
选择合适的分类模型可以提高ROC曲线的准确性和可靠性。
2.2 拟合分类模型在R语言中,我们可以使用各种函数(如glm()函数、rpart()函数、svm()函数等)来拟合分类模型。
拟合分类模型的目的是根据已有的数据,建立一个能够准确分类的模型。
2.3 评估分类模型性能在拟合分类模型之后,我们需要评估分类模型的性能。
常用的评估指标包括准确率、召回率、F1值等。
这些指标可以帮助我们了解分类模型的准确性和可靠性。
3. 绘制ROC曲线3.1 计算真阳性率和假阳性率在绘制ROC曲线之前,我们需要计算真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)。
TPR表示被正确分类为正例的样本占所有真实正例样本的比例,而FPR表示被错误分类为正例的样本占所有真实负例样本的比例。
3.2 绘制ROC曲线在R语言中,我们可以使用plot()函数绘制ROC曲线。
将计算得到的TPR和FPR作为横纵坐标,即可得到ROC曲线。
3.3 计算AUC值AUC(Area Under Curve)是ROC曲线下的面积,它可以用来评估分类模型的性能。
单基因绘制roc曲线

单基因绘制ROC曲线引言在生物学和医学领域,基因是研究的重要对象之一。
单基因研究是一种常见的方法,通过分析单个基因的表达水平或突变情况,可以对疾病的发生机制和治疗方法进行深入研究。
在单基因研究中,绘制ROC(Receiver Operating Characteristic)曲线是一种常用的方法,用于评估基因的预测能力和区分能力。
本文将详细介绍单基因绘制ROC曲线的方法和应用。
什么是ROC曲线ROC曲线是一种用于评估分类模型性能的工具。
在生物学和医学领域中,我们常常需要将样本分为正类和负类,例如将癌症患者和非癌症患者进行区分。
ROC曲线通过绘制真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)之间的关系,来评估分类模型的准确性和可靠性。
绘制ROC曲线的步骤绘制ROC曲线的步骤如下:1.收集基因表达数据以及样本标签。
基因表达数据可以通过高通量测序或芯片技术获取,样本标签表示样本的分类(正类或负类)。
2.计算分类模型的预测概率。
常见的分类模型包括逻辑回归、支持向量机等。
这些模型可以通过训练数据得到,然后用于预测测试数据的标签。
3.根据预测概率对样本进行排序。
将预测概率从高到低排序,得到一个有序列表。
4.设置不同的分类阈值。
从最低的预测概率开始,逐渐增加分类阈值。
当预测概率大于等于分类阈值时,将样本划分为正类,否则划分为负类。
5.计算TPR和FPR。
根据分类结果,计算真阳性率(TPR)和假阳性率(FPR)。
TPR表示正类样本被正确分类的比例,FPR表示负类样本被错误分类为正类的比例。
6.绘制ROC曲线。
将不同分类阈值下的TPR和FPR绘制在坐标系中,得到ROC曲线。
ROC曲线的评估指标通过绘制ROC曲线,我们可以得到一条曲线,曲线下的面积被称为AUC(Area Under Curve)。
AUC是评估分类模型性能的重要指标,其取值范围为0.5到1,值越接近1表示模型的性能越好。
绘制ROC曲线、找截断值,教你两种软件操作方法!
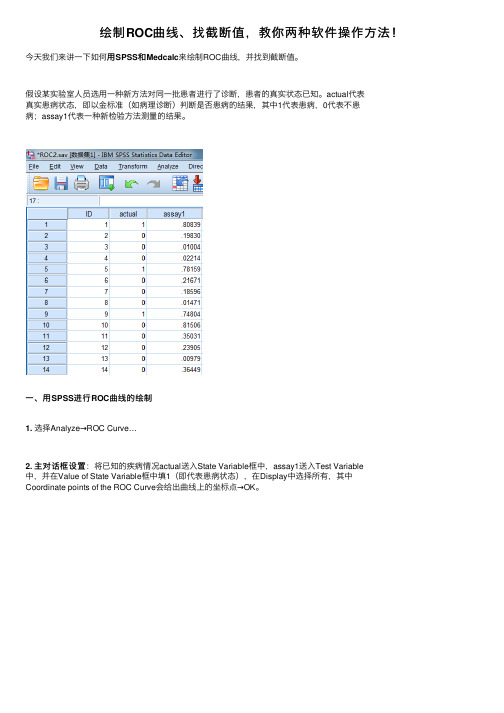
绘制ROC曲线、找截断值,教你两种软件操作⽅法!⽤SPSS和Medcalc来绘制ROC曲线,并找到截断值。
今天我们来讲⼀下如何⽤假设某实验室⼈员选⽤⼀种新⽅法对同⼀批患者进⾏了诊断,患者的真实状态已知。
actual代表真实患病状态,即以⾦标准(如病理诊断)判断是否患病的结果,其中1代表患病,0代表不患病;assay1代表⼀种新检验⽅法测量的结果。
⼀、⽤SPSS进⾏ROC曲线的绘制1. 选择Analyze→ROC Curve…主对话框设置:将已知的疾病情况actual送⼊State Variable框中,assay1送⼊Test Variable2. 主对话框设置中,并在Value of State Variable框中填1(即代表患病状态),在Display中选择所有,其中Coordinate points of the ROC Curve会给出曲线上的坐标点→OK。
3. 结果(1) ROC曲线(2) ROC曲线下⾯积:从Area Under the Curve的结果可知,assay1的ROC曲线下⾯积为0.856(95%置信区间:0.825-0.886,P<0.001)。
(3) ROC曲线上的坐标点:如下图所⽰,我们可以根据Coordinates of the Curve的结果可以得到⼀系列灵敏度和1-特异度的值。
要想获得截断值,就是最接近左上⾓(0,1.0)的点所对应的坐标点,我们可以将这两列值复制到Excel表中,根据正确指数最⼤选出最佳临界点。
正确指数⼜称约登指数(Youden’s index),表⽰检验⽅法发现真正病⼈与⾮病⼈的总能⼒,是灵敏度与特异度之和减去1,即约登指数=灵敏度+特异度-1,在Excel中,⽤灵敏度-(1-特异度)得到的就是约登指数,对相减的结果进⾏排序,可以得到正确指数的最⼤值,即最佳临界点。
操作:操作:将数据复制到excel中,计算灵敏度-(1-特异度),选中D列,进⾏降序排列,得到约登指数的最⼤值约为0.5631,对应的灵敏度≈90.2%,特异度≈(1-0.338)=66.2%。
诊断试验的ROC曲线

诊断试验的ROC 曲线一、ROC 曲线的概念在诊断试验中,对诊断指标每一个可能的诊断界值,都能得到一个四格表:诊断试验金标准诊断病人非病人合计+ ab 1m- cd0m合计1n 0nn计算出这些四格表的灵敏度e S 和特异度p S ,以假阳性率p S 1为横轴,以真阳性率e S 为纵轴,在算术坐标纸上作图,所得到的线图称为ROC 曲线(Receiver Operator Characteristic)。
例如:为了研究肌酸激酶(CK )诊断心肌梗塞的作用,对金标准诊断为心肌梗塞的230例病人和130名正常人分别测定了每个人的CK 值,有如下频数表:CK 值 病人组 正常人组合计 1~ 2 88 90 40~ 13 26 39 80~ 118 15 133 280~ 97 1 98 合计230130将这4种诊断方法的结果列成下表:诊断界值e Sp Sp S -11 1 0 1 40 0.9913 0.6769 0.3231 80 0.9348 0.8769 0.1231 2800.41270.99230.0077对上表的数据,以假阳性率p S -1为横轴,以真阳性率e S 为纵轴,在算术坐标纸上描点,将点连成曲线,就得到了ROC 曲线:二、ROC 曲线的用途 1.评价指标的诊断能力; 2.确定最佳诊断界值;3.比较两个诊断指标的诊断能力。
三、ROC 曲线评价指标的诊断能力 ROC 曲线下的面积计算(1)参数法如果诊断试验的指标在病人和非病人总体中均服从正态分布,可用参数法估计ROC 曲线下的面积。
设诊断指标x 在非病人总体中服从)(200σμN ,在病人总体中服从)(211σμN 。
如果01μμ>,101)(σμμ-=a ,10σσ=b 如果01μμ<,110)(σμμ-=a ,1σσ=bROC 曲线下的面积为:)1(2b a A +Φ=)(u Φ是标准正态分布曲线下(-∞,u )范围中的面积,可通过《医学统计学》中的附表1查到。
ROC曲线(受试者工作特征曲线)分析详解

ROC曲线(受试者工作特征曲线)分析详解ROC曲线(受试者工作特征曲线)分析详解最后更新:2011-5-9 阅读次数: 8788一、ROC曲线的概念受试者工作特征曲线(receiver operator characteristic curve, ROC曲线),最初用于评价雷达性能,又称为接收者操作特性曲线。
ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。
传统的诊断试验评价方法有一个共同的特点,必须将试验结果分为两类,再进行统计分析。
ROC曲线的评价方法与传统的评价方法不同,无须此限制,而是根据实际情况,允许有中间状态,可以把试验结果划分为多个有序分类,如正常、大致正常、可疑、大致异常和异常五个等级再进行统计分析。
因此,ROC曲线评价方法适用的范围更为广泛。
二、ROC曲线的主要作用1.ROC曲线能很容易地查出任意界限值时的对疾病的识别能力。
2.选择最佳的诊断界限值。
ROC曲线越靠近左上角,试验的准确性就越高。
最靠近左上角的ROC曲线的点是错误最少的最好阈值,其假阳性和假阴性的总数最少。
3.两种或两种以上不同诊断试验对疾病识别能力的比较。
在对同一种疾病的两种或两种以上诊断方法进行比较时,可将各试验的ROC 曲线绘制到同一坐标中,以直观地鉴别优劣,靠近左上角的ROC曲线所代表的受试者工作最准确。
亦可通过分别计算各个试验的ROC曲线下的面积(AUC)进行比较,哪一种试验的AUC最大,则哪一种试验的诊断价值最佳。
三、ROC曲线分析的主要步骤1.ROC曲线绘制。
依据专业知识,对疾病组和参照组测定结果进行分析,确定测定值的上下限、组距以及截断点(cut-off point),按选择的组距间隔列出累积频数分布表,分别计算出所有截断点的敏感性、特异性和假阳性率(1-特异性)。
以敏感性为纵坐标代表真阳性率,(1-特异性)为横坐标代表假阳性率,作图绘成ROC曲线。
roc曲线绘制原理

roc曲线绘制原理
ROC曲线(Receiver Operating Characteristic curve)是一
种用于评估分类模型性能的图表。
它是以真阳性率(true positive rate,又称敏感度)为纵轴,假阳性率(false positive rate)为
横轴,绘制出来的曲线。
真阳性率是指被正确分类为正例的样本占
所有正例样本的比例,假阳性率则是被错误分类为正例的负例样本
占所有负例样本的比例。
在绘制ROC曲线时,首先需要计算出分类模型在不同阈值下的
真阳性率和假阳性率。
然后,将这些真阳性率和假阳性率按照不同
的阈值点连接起来,就得到了ROC曲线。
ROC曲线的斜率代表了模
型的性能,曲线下面积(AUC)则代表了模型的整体性能。
一般来说,ROC曲线越靠近左上角,模型的性能就越好。
绘制ROC曲线的原理是通过对分类模型在不同阈值下的性能进
行评估,并将评估结果以图表的形式展现出来,以便直观地比较不
同模型的性能优劣。
ROC曲线的绘制原理相对简单,但对于评估分
类模型的性能具有重要意义。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
专题2:线性判别分析、诊断的敏感度、特异度及ROC曲线的绘制
一、判别分析
判别分析是利用已知类别的样本建立判别模型,对未知类别的样本判别的一种统计方法。
进行判别分析必须已知观测对象的分类和若干表明观测对象特征的变量值。
判别分析从中筛选出能提供较多信息的变量并建立判别函数,使得利用推导出的判别函数对观测量判别其所属类别时的错判率最小。
判别函数一般形式是:Y = a1X1+a2X2+a3X3...+a n X n
其中: Y 为判别分数(判别值);X1,X2,X3:⋯X n 为反映研究对象特征的变量,a1、a2、
a3⋯a n 为各变量的系数,也称判别系数。
SPSS 对于分为m类的研究对象,建立m-1个线性判别函数。
对于每个个体进行判别时,把测试的各变量值代入判别函数,得出判别分数,从而确定该个体属于哪一类。
或者计算属于各类的概率,从而判断该个体属于哪—类。
例如:脂肪肝与健康人的判别分析
SPSS中的操作:分析——分类——判别,在判别分析对话框中将是否患有脂肪肝选入“分类变量”点击定义范围最小值输入0,最大值输入1。
之后将所有质量数变量选入“自变量”,选择“使用步进方法进入”(根据自变量对判别贡献的大小进行逐步选择)点击“分类”按钮,在输出选择“不考虑该个案的分类”进行互交式检验。
点击“保存”按钮,选择“判别得分”,方可画出ROC曲线。
其他选项默认即可。
输出结果如下:
输入的/删除的变量a,b,c,d
步骤
输入的Wilks 的Lambda
统计量
精确 F
统计量df1 df2 Sig.
1 v55 .935 1 1 896.000 62.707 1 896.000 .000
2 v59 .898 2 1 896.000 51.005 2 895.000 .000
3 v42 .862 3 1 896.000 47.685 3 894.000 .000
4 v33 .844 4 1 896.000 41.144 4 893.000 .000
5 v89 .827 5 1 896.000 37.440 5 892.000 .000
6 v11
7 .819 6 1 896.000 32.81
8 6 891.000 .000
7 v86 .811 7 1 896.000 29.707 7 890.000 .000
8 v112 .806 8 1 896.000 26.819 8 889.000 .000
9 v23 .802 9 1 896.000 24.419 9 888.000 .000 在每个步骤中,输入了最小化整体Wilk 的Lambda 的变量。
a. 步骤的最大数目是200。
b. 要输入的最小偏F 是3.84。
c. 要删除的最大偏F 是2.71。
d. F 级、容差或VIN 不足以进行进一步计算。
标准化的典型判别式函数系数
函数
1
v23 .159
v33 -.359
v42 .439
v55 .601
v59 -.474
v86 .227
v89 .314
v112 -.185
v117 .230
分类结果b,c
是否患有脂肪肝预测组成员
0 1
合计
初始计数0 306 119 425
1 170 303 473
% 0 72.0 28.0 100.0
1 35.9 64.1 100.0 交叉验证a计数0 304 121 425
1 174 299 473
% 0 71.5 28.5 100.0
1 36.8 63.
2 100.0
a. 仅对分析中的案例进行交叉验证。
在交叉验证中,每个案例都是按照从该案例以外的所有其他案例派生的函数来分类的。
b. 已对初始分组案例中的 67.8% 个进行了正确分类。
c. 已对交叉验证分组案例中的 67.1% 个进行了正确分类。
二、敏感度与特异度
敏感度和特异度是用来说明诊断性试验准确性的两个常用指标。
诊断性试验的敏感度越高,漏诊率越低。
特异性高的诊断性试验的阳性结果对诊断更有意义。
特异度越高,误诊的比例越低。
敏感度(sensitivity)又称真阳性率,即实际有病而按该筛检实验的标准被正确判断为有病的百分比。
它反映筛检实验发现病人的能力。
特异度(specificity)又称真阴性率,即实际无病按该诊断标准被正确地判断为无病的百分比。
它反映筛检实验确定非病人的能力。
阳性预测值(Positive Predictive Value,PPV)指筛检实验阳性者不患目标疾病的可能性。
阴性预测值(Negative Predictive Value,NPV)指筛检实验阴性者患目标疾病的可能性。
预测
1 0 合计
实际 1 True Positive(TP) False Negative(FN) Actual Positive(TP+FN)
0 Fasle Positive(FP) True Negative(TN) Actual Negative(FP+TN) 合计Predicted Positive(TP+FP) Predicted Negative (FN+TN) TP+FP+FN+TN
呼气测试结果
脂肪肝健康合计
B超结果脂肪肝331 142 473 Sensitivity=TP/(TP+FN)
=70%
健康100 325 425 Specificity=TN/(FP+TN)
=76%
合计431 467 898
PPV=TP/(TP+FP)
=77%
NPV=TN/(FN+TN)
=70%
以上结果来自于线性判别分析
三、ROC曲线
ROC曲线指受试者工作特征曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。
在ROC 曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
Youden指数则为灵敏度与特异度两者之和减一。
AUC(Area under the curv)曲线下方的面积,AUC的值就是处于ROC curve下方的那部分面积的大小。
ROC曲线的做法
SPSS中:分析——ROC曲线图——将判别得分选入检验变量,后将“是否患有脂肪肝”作为状态变量,将状态值选为1.其他默认即可。
输出结果如下
曲线下的面积
检验结果变量:用于分析 1 的来自函数 1 的判别得分
面积
.762
检验结果变量:用于分析 1 的来自函数 1 的判别得分在正的和负的实际状态组之间至少有一个结。
统计量可能会出现偏差。