第三章判别函数分类器
模式识别(3-1)

§3.2 最大似然估计
最大似然估计量: -使似然函数达到最大值的参数向量。 -最符合已有的观测样本集的那一个参数向量。 ∵学习样本从总体样本集中独立抽取的
N ) p( X | ) p( X k | i ) k 1 N个学习样本出现概率的乘积
i
i
∴
p( X | i . i
i
§3.2 Bayes学习
假定: ①待估参数θ是随机的未知量 ②按类别把样本分成M类X1,X2,X3,… XM 其中第i类的样本共N个 Xi = {X1,X2,… XN} 并且是从总体中独立抽取的 ③ 类条件概率密度具有某种确定的函数形式,但其 参数向量未知。 ④ Xi 中的样本不包含待估计参数θj(i≠j)的信息,不 同类别的参数在函数上是独立的,所以可以对每一 类样本独立进行处理。
有时上式是多解的, 上图有5个解,只有一个解最大即 (对所有的可能解进行检查或计算二阶导数)
§3.2 最大似然估计
例:假设随机变量x服从均匀分布,但参数1, 2未知, 1 1 x 2 p ( x | ) 2 1 , 0 其他 求1, 2的最大似然估计量。 解:设从总体中独立抽取N个样本x1 , x2 , , xN , 则其似然函数为: 1 p ( x1 , x2 , , xN | 1, 2 ) ( 2 1 ) N l ( ) p ( X | ) 0
§3.2 Bayes学习
p ~ N 0 , 0
2
其中 0和 0 是已知的
2
已知的信息还包括一组抽取出来的样本X i x1 , x2 ,, xN ,从而 可以得到关于 的后验概率密度:
模式识别复习题分解

《模式识别》试题库一、基本概念题1.1 模式识别的三大核心问题是:、、。
1.2、模式分布为团状时,选用聚类算法较好。
1.3 欧式距离具有。
马式距离具有。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性1.4 描述模式相似的测度有:。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度1.5 利用两类方法处理多类问题的技术途径有:(1);(2);(3)。
其中最常用的是第个技术途径。
1.6 判别函数的正负和数值大小在分类中的意义是:,。
1.7 感知器算法。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。
1.8 积累位势函数法的判别界面一般为。
(1)线性界面;(2)非线性界面。
1.9 基于距离的类别可分性判据有:。
(1)1[]w BTr S S-(2)BWSS(3)BW BSS S+1.10 作为统计判别问题的模式分类,在()情况下,可使用聂曼-皮尔逊判决准则。
1.11 确定性模式非线形分类的势函数法中,位势函数K(x,x k)与积累位势函数K(x)的关系为()。
1.12 用作确定性模式非线形分类的势函数法,通常,两个n维向量x和x k的函数K(x,x k)若同时满足下列三个条件,都可作为势函数。
①();②( ); ③ K(x,x k )是光滑函数,且是x 和x k 之间距离的单调下降函数。
1.13 散度J ij 越大,说明ωi 类模式与ωj 类模式的分布( )。
当ωi 类模式与ωj 类模式的分布相同时,J ij =( )。
1.14 若用Parzen 窗法估计模式的类概率密度函数,窗口尺寸h1过小可能产生的问题是( ),h1过大可能产生的问题是( )。
1.15 信息熵可以作为一种可分性判据的原因是: 。
1.16作为统计判别问题的模式分类,在( )条件下,最小损失判决规则与最小错误判决规则是等价的。
1.17 随机变量l(x )=p( x |ω1)/p( x |ω2),l( x )又称似然比,则E {l( x )|ω2}=( )。
线性判别函数

一、线性判别函数
g(X)=0 就是相应的决策面方程,在线性判别函数条 件下它对应d维空间的一个超平面:
1x1 2 x2 … d xd 0 0
一、线性判别函数
3、多类问题判别
情况一
例:有一三类问题,分别建立了三个判决函数,判别规 则如下:
若样本x=(6,2)T,试判断该样本的类别。
1
M 2 N2 X2 X
Sw S1 S2 (X M1)(X M1)T (X M2 )(X M2 )T
X 1
X 2
2
阈值点 其中:
二、Fisher 线性判别函数
例题:
二、Fisher 线性判别函数
二、Fisher 线性判别函数
二、Fisher 线性判别函数
若d(ij X)>0,j i, i, j 1, 2,..., M ,则决策X i
情况2
例,设一个三类问题,建立了如下判决函数
情况2 特例
例,设一个三类问题,按最大值判决规则建立了三个判 决函数:
二、广义线性判别函数 欲设计这样一个一维样本的分类器,使其性能为:
令
➢ 通过非线性变换,非线性判决函数变成了线性判决函 数;
线性判别函数
3.1 线性判别函数的基本概念
贝叶斯决策理论设计分类器的步骤图
❖ 判别函数包含两类:
➢线性判别函数: ➢非线性判别函数,即广义线性判决函数
线性判别函数是统计模式识别方法中的一个重要的基
本方法。它是由训练样本集提供的信息直接确定决策域的
划分。
在训练过程中使用的样本集,该样 本集中的每个样本的类别已知。
个d维样本。Fisher准则就是找到一条直线,使得模式样本
在这条直线上的投影最有利于分类。设 W 为这条直线正
模式识别 线性分类器

3(3-1)/2=3个判决函数。即:每次从M类中取出两类的组合:
2
=
d 23 ( X ) 0
x2
-
3
-
1
O
2023/12/6
2!
d13 ( X ) 0
2
−
1
- d12 ( X ) 0
例3.4 已知dij(X)的位
region ,IR)。
d1 , d 2 0,
d3 0
d1 0,
d 2 , d3 0
2
1
d 2 0,
d1 , d 3 0
全部<0
不属任何类
IR,可能
属于1 或 3
3
IR,可能
属于3 或 2
x
d 3 0,
d1 , d 2 0
-
d3 ( X ) 0
1
d ( X ) w1 x1 w2 x2 w3 0
2
x1
O
图3.2 两类二维模式的分布
2023/12/6
式中: x1 , x2 为坐标变量,
w1 , w2 , w3 为方程参数。
5
x2
d(X) 0
+
-
将某一未知模式 X 代入:
1
d ( X ) w1 x1 w2 x2 w3
c) 找交集。
12
例3.2 已知di(X)的位置和正负侧,分析三类模式的分布区域 。
请同学们自己先分析一下。
d 3( X ) 0
+
—1ຫໍສະໝຸດ —d2 ( X) 0
+
3 第三章 参数估计与非参数估计
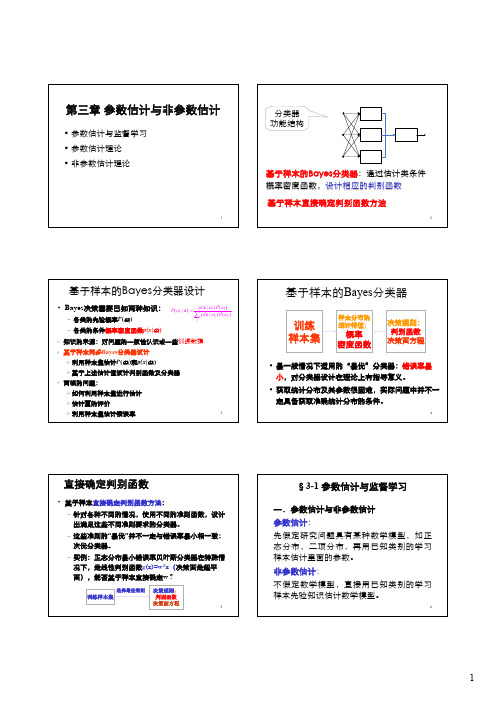
1第三章参数估计与非参数估计•参数估计与监督学习•参数估计理论•非参数估计理论2基于样本的Bayes分类器:通过估计类条件概率密度函数,设计相应的判别函数分类器功能结构基于样本直接确定判别函数方法3基于样本的Bayes 分类器设计•Bayes 决策需要已知两种知识:–各类的先验概率P (ωi )–各类的条件概率密度函数p(x |ωi )(|)()(|)(|)()i i i j j jp P P p P ωωωωω=∑x x x 知识的来源:对问题的一般性认识或一些训练数据基于样本两步Bayes 分类器设计¾利用样本集估计P (ωi )和p(x |ωi )¾基于上述估计值设计判别函数及分类器面临的问题:¾如何利用样本集进行估计¾估计量的评价¾利用样本集估计错误率4基于样本的Bayes 分类器训练样本集样本分布的统计特征:概率密度函数决策规则:判别函数决策面方程•最一般情况下适用的“最优”分类器:错误率最小,对分类器设计在理论上有指导意义。
•获取统计分布及其参数很困难,实际问题中并不一定具备获取准确统计分布的条件。
5直接确定判别函数•基于样本直接确定判别函数方法:–针对各种不同的情况,使用不同的准则函数,设计出满足这些不同准则要求的分类器。
–这些准则的“最优”并不一定与错误率最小相一致:次优分类器。
–实例:正态分布最小错误率贝叶斯分类器在特殊情况下,是线性判别函数g (x)=w T x (决策面是超平面),能否基于样本直接确定w ?训练样本集决策规则:判别函数决策面方程选择最佳准则6一.参数估计与非参数估计参数估计:先假定研究问题具有某种数学模型,如正态分布,二项分布,再用已知类别的学习样本估计里面的参数。
非参数估计:不假定数学模型,直接用已知类别的学习样本先验知识估计数学模型。
§3-1 参数估计与监督学习13¾估计量:样本集的某种函数f (X),X ={X 1, X 2 ,…, X N }¾参数空间:总体分布未知参数θ所有可能取值组成的集合(Θ)12ˆ(,,...,)N d θθ=x x x 的()是样本集的函数,它对样本集的一次实现估计称计量点估为估计值¾点估计的估计量和估计值§3-2 参数估计理论14¾估计量评价标准: 无偏性,有效性,一致性–无偏性:E ( )=θ–有效性:D ( )小,估计更有效–一致性:样本数趋于无穷时,依概率趋于θ:ˆθˆlim ()0N P θθε→∞−>=ˆθˆθ15最大似然估计计算方法•Maximum Likelihood (ML)估计–估计参数θ是确定而未知的,Bayes 估计方法则视θ为随机变量。
第3章-基本概念--机器学习与应用第二版

第3章基本概念本章介绍机器学习中的常用概念,包括算法的分类,算法的评价指标,以及模型选择问题。
按照样本数据是否带有标签值,可以将机器学习算法分为有监督学习与无监督学习。
按照标签值的类型,可以将有监督学习算法进一步细分为分类问题与回归问题。
按照求解的方法,可以将有监督学习算法分为生成模型与判别模型。
比较算法的优劣需要使用算法的评价指标。
对于分类问题,常用的评价指标是准确率;对于回归问题,是回归误差。
二分类问题由于其特殊性,我们为它定义了精度与召回率指标,在此基础上可以得到ROC曲线。
对于多分类问题,常用的评价指标是混淆矩阵。
泛化能力是衡量有监督学习算法的核心标准。
与模型泛化能力相关的概念有过拟合与欠拟合,对泛化误差进行分解可以得到方差与偏差的概念。
正则化技术是解决过拟合问题的一种常见方法,在本章中我们将会介绍它的实例-岭回归算法。
3.1算法分类按照样本数据的特点以及求解手段,机器学习算法有不同的分类标准。
这里介绍有监督学习和无监督学习,分类问题与回归问题,生成模型与判别模型的概念。
强化学习是一种特殊的机器学习算法,它的原理将在第20章详细介绍。
3.1.1监督信号根据样本数据是否带有标签值(label),可以将机器学习算法分成有监督学习和无监督学习两类。
要识别26个英文字母图像,我们需要将每张图像和它是哪个字符即其所属的类别对应起来,图像的类别就是标签值。
有监督学习(supervised learning)的样本数据带有标签值,它从训练样本中学习得到一个模型,然后用这个模型对新的样本进行预测推断。
样本由输入值与标签值组成:(),y x其中x为样本的特征向量,是模型的输入值;y为标签值,是模型的输出值。
标签值可以是整数也可以是实数,还可以是向量。
有监督学习的目标是给定训练样本集,根据它确定映射函数:()y f=x确定这个函数的依据是它能够很好的解释训练样本,让函数输出值与样本真实标签值之间的误差最小化,或者让训练样本集的似然函数最大化。
第3章 Bayes决策理论

第3章 Bayes决策理论
“概率论”有关概念复习
Bayes公式:设实验E的样本空间为S,A为E的事件,
第3章 Bayes决策理论
B1,B2,…,Bn为S的一个划分,且P(A)>0,P(Bi)>0,
(i=1,2,…,n),则:
P( Bi | A) P( A | Bi ) P( Bi )
n
P( A | B
返回本章首页
第3章 Bayes决策理论
平均错误概率
P(e)
P (e x ) p ( x ) d x
从式可知,如果对每次观察到的特征值 x , P(e x) 是 尽可能小的话,则上式的积分必定是尽可能小的。这就 证实了最小错误率的Bayes决策法则。下面从理论上给 予证明。以两类模式为例。
解法1:
利用Bayes公式
第3章 Bayes决策理论
p ( x 10 | 1 ) P(1 ) P(1 | x 10) p ( x 10) p ( x 10 | 1 ) P(1 ) p ( x 10 | 1 ) P(1 ) p( x 10 | 2 ) P(2 ) 0.05 1/ 3 0.048 0.05 1/ 3 0.50 2 / 3
解法2:
写成似然比形式
第3章 Bayes决策理论
p ( x 10 | 1 ) 0.05 l12 (x 10) 0.1 p ( x 10 | 2 ) 0.50 P (2 ) 2 / 3 判决阀值12 2 P (1 ) 1/ 3 l12 (x 10) 12 , x 2 , 即是鲑鱼。
若 P(i x) P( j x) , j i ,则判
若 P(i x) 若 若
第三章线性模型

其中 x = [1, x1 , · · · , xd ]T 和 w = [b, w1 , · · · , wd ]T 分别为 d + 1 维的增广特征向 量和增广权重向量。 在线性回归问题中,可以直接用 f (x, w) 来预测输出目标。但在分类问题 中,由于输出目标是一些离散的标签或者是这些标签的后验概率(在 (0, 1) 之 间) ,而 f (x, w) 的值域为实数,因此无法直接用 f (x, w) 来进行预测,需要引入
邱锡鹏:《神经网络与深度学习》 https://nndl.github.io/
44
2017 年 10 月 12 日
第三章
线性模型
x1
w
T
x
+
b
=
0
w
x2
b ∥ ∥w
图 3.2: 两类分类线性判别函数。样本特征向量 x = [x1 , x2 ],权重向量 w = [w1 , w2 ]。 对于分类问题,使用线性回归算法来求解是不合适的。一是线性函数的输 出值域和目标标签的值域不相同,二是损失函数很难定义。如果使用平方损失 会导致比较大的误差。图3.3a给出了使用线性回归算法来解决一维的两类分类 问题示例。 为了解决连续的线性函数不适合进行分类的问题, 我们引入非线性的 logistic 函数作为激活函数,来预测目标标签 y = 1 的后验概率。 p(y = 1|x) = σ (wT x)
第三章
线性模型
线性模型(Linear Model)是机器学习中应用最广泛的模型,指通过样本 特征的线性组合来进行预测的模型。上一章中介绍的线性回归就是典型的线性 模型。给定一个 d 维样本 [x1 , · · · , xd ]T ,其线性组合函数为 f (x, w) = w1 x1 + w2 x2 + · · · + wd xd + b = wT x , (3.1) (3.2)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
矢量
矢量X可以看作是N维欧氏空间中的一个 点,用一个列矢量表示:
x1
X
x2
xN
矩阵
矩阵可以看作是由若干个矢量构成的:
A
X1T XT2
XTM
矩阵的秩
矩阵所有行向量的最大无关组个数称为 行秩;
求向量W,使得d(X)=WTX,能够区分 Ω1类和Ω2类。
问题的表达
X1T W 0, XT2 W 0, , XTL W 0 XTL1W 0, XTL2W 0, , XTM W 0
daij (t) dt
M N
矩阵函数对矩阵的微分
矩阵X=(xij)M*N,M*N元函数f(X),定义 f(X)对矩阵X的导数:
f
df dX
f xij
M N
x11 f
xM1
f
x1N
f
i 1
wi ai 2
N
i 1
wi aiN
结果是一个N维列矢量。
正交
设W和X为N维列矢量,如果W与X的内 积等于零:
WT X 0
则称W与X正交,也称W垂直于X。
逆矩阵
A为一个N*N的方阵,A的逆阵用A-1表 示,满足:
AA1 A1A I
其中I为单位阵。 一个矩阵的逆阵存在条件:1)是一个方阵, 2)是一个满秩矩阵,矩阵的秩为N
判别准则:
di
X
max 1 jM
dj X
X i
3.2 两类别线性判别函数的学习
一、问题的表达 二、感知器算法 三、最小均方误差算法(LMSE)
问题的表达
已知两个类别的训练样本集合:
1 :X1, X2, , XL
2 : XL1, XL2, , XM
当d2(X)≥0,而d1(X)<0且d3(X)<0时,判 别X属于Ω2;
当d3(X)≥0,而d1(X)<0且d2(X)<0时,判 别X属于Ω3;
其它 每两类之间可以用一个超平面分开,但 是不能用来把其余类别分开;
需要将M个类别的多类问题转化为 M(M-1)/2个两类问题。
矩阵的迹、行列式值与特征值 之间的关系
矩阵A有N个特征值1,2,…, N, 则有如下关系:
N
tr A i i 1
N
det(A) i i 1
矩阵对数值变量微分
矩阵A(t)=[aij(t)]M*N,元素aij(t)是变量t 的函数,矩阵A(t)对t的微分:
dA(t) dt
+
d12(X)=0
-
类别一
类别二
d 13(X)=0 -
+
类别三
d
23
(X)=0
+
-
多类问题(情况三)
情况三是情况二的特例,不存在拒识区 域。
(X)=0
d 12
类别一
类别二
d 13(X)=0
类别三
d
23
(X)=0
多类问题(情况三)判别函数
M个类别需要M个线性函数:
di X WiT X wi1x1 wi2x2 wiN xN wi(N1)
xMN
常用矢量微分的性质
X和W为N维矢量,A为M*N的矩阵:
f X XT W f X WT X
df X
W dX
df X W
dX
f X XT AX
df X (A AT )X
dX
3.1 线性判别函数
一、两类问题 二、多类问题
两类问题的线性判别函数
矩阵的特征值和特征向量
A为一个N*N的方阵,如果有:
Aξ ξ
数称为A的特征值,矢量ξ 称为A的特 征矢量。
矩阵的迹和行列式值
A为一个N*N的方阵,A的迹为主对角线 元素之和:
N
tr A aij i 1
A为一个N*N的方阵,A的迹为主对角线 元素之和:
det A
多类问题(情况一)
d1 X x1 x2 d2 X x1 x2 5 d3 X x2 1
x2
d
2
(X)=0
IR
d
(X)=0
1
类别一 IR
IR 类别三
类别二
d3(X)=0 IR
x1
多类问题(情况一)判别规则
当d1(X)≥0,而d2(X)<0且d3(X)<0时,判 别X属于Ω1;
W=(w1, w2, …, wN , 1)T称为增广的权矢 量。
两类问题线性判别准则
0,
d X WT X 0,
0,
X 1 X 2 拒识
多类问题(情况一)
每一类模式可以用一个超平面与其它类 别分开;
这种情况可以把M个类别的多类问题分 解为M个两类问题解决;
第i类与第j类之间的判别函数的为:
dij X WiTj X i j
多类问题(情况二)判别准则
如果对任意j≠i ,有dij(X) )≥0 ,则决策X 属于Ωi。
其它情况,则拒识。
多类问题(情况二)
d12 X x1 x3 5 d13 X x1 3 d23 X x1 x2
d X0 w1x1 w2x2 wnxn wn1 W0T X0 wn1
X0=(x1, x2,…, xN)T为待识模式的特征矢 量;
W0=(w1, w2, …, wN)T称为权矢量。
线性判别函数的增广形式
d X WT X
X=(x1, x2,…, xN, 1) T称为增广的特征矢 量;
矩阵所有列向量的最大无关组个数称为 列秩;
一个矩阵的行秩等于列秩,称为矩阵的 秩。
转置
列矢量W的转置WT为一个行矢量;
N*M的矩阵A的转置AT为一个M*N的矩 阵。
矢量与矢量的乘法(1)
设W和X为N维列矢量
N
WT X wi xi i 1
结果是一个数。
矢量与矢量的乘法(2)
设W和X为N维列矢量
w1x1
WXT
w2
x1
wN
x1
w1x2 w2 x2
wN x2
w1xN
w2 xN
wN
xN
结果是一个N*N维的矩阵。
矢量与矩阵的乘法
设W为N维列矢量,A为一个N*M的矩
阵:
N
wi
ai1
i1
N
WT
A