非线性回归分析
《非线性回归分析》课件
封装式
• 基于模型的错误率和复 杂性进行特征选择。
• 常用的封装方法包括递 归特征消除法和遗传算 法等。
嵌入式
• 特征选择和模型训练同 时进行。
• 与算法结合在一起的特 征选择方法,例如正则 化(Lasso、Ridge)。
数据处理方法:缺失值填充、异常值 处理等
1
网格搜索
通过预定义的参数空间中的方格进行搜
随机搜索
2
索。
在预定义的参数空间中进行随机搜索。
3
贝叶斯调参
使用贝叶斯优化方法对超参数进行优化。
集成学习在非线性回归中的应用
集成学习是一种将若干个基学习器集成在一起以获得更好分类效果的方法,也可以用于非线性回归建模中。
1 堆叠
使用多层模型来组成一个 超级学习器,每个模型继 承前一模型的输出做为自 己的输入。
不可避免地存在数据缺失、异常值等问题,需要使用相应的方法对其进行处理。这是非线性回归 分析中至关重要的一环。
1 缺失值填充
常见的方法包括插值法、代入法和主成分分析等。
2 异常值处理
常见的方法包括删除、截尾、平滑等。
3 特征缩放和标准化
为了提高模型的计算速度和准确性,需要对特征进行缩放和标准化。
偏差-方差平衡与模型复杂度
一种广泛用于图像识别和计算机 视觉领域的神经网络。
循环神经网络
一种用于处理序列数据的神经网 络,如自然语言处理。
sklearn库在非线性回归中的应用
scikit-learn是Python中最受欢迎的机器学习库之一,可以用于非线性回归的建模、评估和调参。
1 模型建立
scikit-learn提供各种非线 性回归算法的实现,如 KNN回归、决策树回归和 支持向量机回归等。
非线性回归分析常见曲线及方程

非线性回归分析常见曲线及方程Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】非线性回归分析回归分析中,当研究的因果关系只涉及和一个时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。
此外,回归分析中,又依据描述自变量与因变量之间因果关系的表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。
通常线性回归分析法是最基本的分析方法,遇到非线性回归问题可以借助数学手段化为线性回归问题处理两个现象变量之间的相关关系并非线性关系,而呈现某种非线性的曲线关系,如:双曲线、二次曲线、三次曲线、幂函数曲线、指数函数曲线(Gompertz)、S型曲线(Logistic) 对数曲线、指数曲线等,以这些变量之间的曲线相关关系,拟合相应的回归曲线,建立非线性回归方程,进行回归分析称为非线性回归分析常见非线性规划曲线1.双曲线1bay x =+2.二次曲线3.三次曲线4.幂函数曲线5.指数函数曲线(Gompertz)6.倒指数曲线y=a/e b x其中a>0,7.S型曲线(Logistic)1e x ya b-=+8.对数曲线y=a+b log x,x>09.指数曲线y=a e bx其中参数a>01.回归:(1)确定回归系数的命令[beta,r,J]=nlinfit(x,y,’model’,beta0)(2)非线性回归命令:nlintool(x,y,’model’, beta0,alpha)2.预测和预测误差估计:[Y,DELTA]=nlpredci(’model’, x,beta,r,J)求nlinfit 或lintool所得的回归函数在x处的预测值Y及预测值的显着性水平为1-alpha的置信区间Y,DELTA.例2 观测物体降落的距离s与时间t的关系,得到数据如下表,求s关于t的回归方程2ˆct=.+btas+解:1. 对将要拟合的非线性模型y=a/e b x,建立M文件如下:function yhat=volum(beta,x)yhat=beta(1)*exp(beta(2)./x);2.输入数据:x=2:16;y=[ 10];beta0=[8 2]';3.求回归系数:[beta,r ,J]=nlinfit(x',y','volum',beta0); beta即得回归模型为:1.064111.6036e x y-=4.预测及作图:[YY,delta]=nlpredci('volum',x',beta,r ,J); plot(x,y,'k+',x,YY,'r')2.非线性函数的线性化曲线方程曲线图形变换公式变换后的线性函数by ax=ln ln ln c a v x u y=== u c bv +=bx y ae =ln ln c a u y==u c bv +=b xe y a=1ln ln x c a v u y===u c bv +=ln y a b x +=ln v x u y== u bv +=a。
非线性回归分析的入门知识

非线性回归分析的入门知识在统计学和机器学习领域,回归分析是一种重要的数据分析方法,用于研究自变量和因变量之间的关系。
在实际问题中,很多情况下自变量和因变量之间的关系并不是简单的线性关系,而是呈现出一种复杂的非线性关系。
因此,非线性回归分析就应运而生,用于描述和预测这种非线性关系。
本文将介绍非线性回归分析的入门知识,包括非线性回归模型的基本概念、常见的非线性回归模型以及参数估计方法等内容。
一、非线性回归模型的基本概念在回归分析中,线性回归模型是最简单和最常用的模型之一,其数学表达式为:$$Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_pX_p +\varepsilon$$其中,$Y$表示因变量,$X_1, X_2, ..., X_p$表示自变量,$\beta_0, \beta_1, \beta_2, ..., \beta_p$表示模型的参数,$\varepsilon$表示误差项。
线性回归模型的关键特点是因变量$Y$与自变量$X$之间呈线性关系。
而非线性回归模型则允许因变量$Y$与自变量$X$之间呈现非线性关系,其数学表达式可以是各种形式的非线性函数,例如指数函数、对数函数、多项式函数等。
一般来说,非线性回归模型可以表示为:$$Y = f(X, \beta) + \varepsilon$$其中,$f(X, \beta)$表示非线性函数,$\beta$表示模型的参数。
非线性回归模型的关键在于确定合适的非线性函数形式$f(X,\beta)$以及估计参数$\beta$。
二、常见的非线性回归模型1. 多项式回归模型多项式回归模型是一种简单且常见的非线性回归模型,其形式为: $$Y = \beta_0 + \beta_1X + \beta_2X^2 + ... + \beta_nX^n +\varepsilon$$其中,$X^2, X^3, ..., X^n$表示自变量$X$的高次项,$\beta_0, \beta_1, \beta_2, ..., \beta_n$表示模型的参数。
非线性回归分析常见模型

非线性回归常见模型一.基本内容模型一xc e c y 21=,其中21,c c 为常数.将xc ec y 21=两边取对数,得x c c e c y xc 211ln )ln(ln 2+==,令21,ln ,ln c b c a y z ===,从而得到z 与x 的线性经验回归方程a bx z +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型二221c x c y +=,其中21,c c 为常数.令a c b c x t ===212,,,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型三21c x c y +=,其中21,c c 为常数.a cbc x t ===21,,,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型四反比例函数模型:1y a b x=+令xt 1=,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.模型五三角函数模型:sin y a b x=+令x t sin =,则变换后得到y 与t 的线性经验回归方程a bt y +=,用公式求即可,这样就建立了y 与x 非线性经验回归方程.二.例题分析例1.用模型e kx y a =拟合一组数据组()(),1,2,,7i i x y i =⋅⋅⋅,其中1277x x x ++⋅⋅⋅+=;设ln z y =,得变换后的线性回归方程为ˆ4zx =+,则127y y y ⋅⋅⋅=()A.70e B.70C.35e D.35【解析】因为1277x x x ++⋅⋅⋅+=,所以1x =,45z x =+=,即()127127ln ...ln ln ...ln 577y y y y y y +++==,所以35127e y y y ⋅⋅⋅=.故选:C例2.一只红铃虫产卵数y 和温度x 有关,现测得一组数据()(),1,2,,10i i x y i =⋅⋅⋅,可用模型21e c x y c =拟合,设ln z y =,其变换后的线性回归方程为4zbx =- ,若1210300x x x ++⋅⋅⋅+=,501210e y y y ⋅⋅⋅=,e 为自然常数,则12c c =________.【解析】21e c x y c =经过ln z y =变换后,得到21ln ln z y c x c ==+,根据题意1ln 4c =-,故41e c -=,又1210300x x x ++⋅⋅⋅+=,故30x =,5012101210e ln ln ln 50y y y y y y ⋅⋅⋅=⇒++⋅⋅⋅+=,故5z =,于是回归方程为4zbx =- 一定经过(30,5),故ˆ3045b -=,解得ˆ0.3b =,即20.3c =,于是12c c =40.3e -.故答案为:40.3e -.该景点为了预测2023年的旅游人数,建立了模型①:由最小二乘法公式求得的数据如下表所示,并根据数据绘制了如图所示的散点图.。
第八讲非线性回归分析

线性对数回归函数
因为该模型中Y是对数形式而X不是, 所以有时称它为对数线性模型。
如何理解β1的含义
在线性对数模型中, β1 表示X变化1个 单位引起Y的变化为(100*β1)%。
推导:我们考察自变量X变化∆X的过程。
此时: f ( X X ) f ( X ) ln(Y Y ) ln(Y ) ( Y ) Y
对数形式
对数形式经常用于表示变量的百分率变 化。例如:
在消费者需求的经济分析中,通常假定 价格上涨1%导致需求量下降一定的 百 分率。称价格上涨1%引起的需求下降 百分率为价格弹性(elasticity)。
对数形式是经济学中最常用的形式,广泛地应用在 各个领域中:
例如:在宏观经济学中,我们如果想研究投资的增
但当回归函数为非线性时,由于Y的预期 变化依赖于自变量的取值,因此其计算 较复杂。
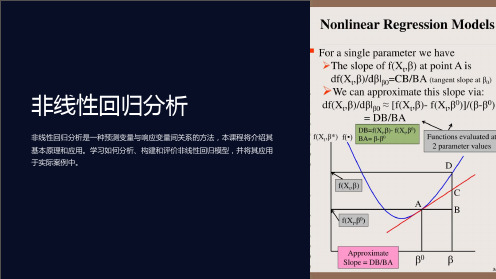
我们假定非线性总体回归的一般公式为
书中的两个例子
1。地区收入从10----11(单位是千美 元)
2。地区收入从40----41
Yˆ (607.3 3.8511 0.0423112 ) (607.3 3.8510 0.0423102 ) 2.96 Yˆ (607.3 3.85 41 0.0423 412 ) (607.3 3.85 40 0.0423 402 ) 0.42
可以看出,income对testscore的弹性 逐渐变小。
效应估计的标准误差
在上例中
利用多元回归建立非线性模型的 一般方法
(1)确定一种可能的非线性关系。最佳做法 是利用经济理论和你对实际应用的了解提出 一种可能的非线性关系。在看数据之前,问 自己联系Y和X的回归函数斜率是否依赖于X 或其他自变量的取值。
当d1=0(男性) 对Y的效应为β2 当d1=1(女性) 对Y的效应为β2+β3
应用MATLAB进行非线性回归分析

应用MATLAB进行非线性回归分析非线性回归分析是一种用于建立非线性函数与自变量之间的关系的统计方法。
与线性回归不同,非线性回归假设因变量与自变量之间的关系是一个非线性函数,通常是指数型、对数型、幂函数等。
MATLAB是一种强大的科学计算软件,提供了丰富的函数和工具箱,可以用于进行非线性回归分析。
下面将介绍如何在MATLAB中进行非线性回归分析的步骤。
1.数据准备首先,需要准备用于非线性回归分析的数据。
数据应包括自变量和因变量的观测值。
可以将数据保存在一个MATLAB数据文件中,或使用MATLAB中的数组或矩阵来表示。
2.建立模型根据实际情况,选择适当的非线性函数模型来描述自变量和因变量之间的关系。
例如,可以使用指数函数模型y = a * exp(b * x)、对数函数模型y = a * log(b * x)、幂函数模型y = a * x^b等。
3.拟合模型并求解参数使用MATLAB中的非线性最小二乘法函数(如lsqcurvefit)拟合模型,并求解模型中的参数。
这些函数需要提供待拟合的非线性模型、观测数据和初始参数值。
例如,可以使用以下代码进行非线性最小二乘拟合:```MATLABx=[1,2,3,4,5];%自变量观测值y=[2,3,5,7,9];%因变量观测值p0=[1,1];%初始参数值p = lsqcurvefit(model, p0, x, y); % 拟合模型和求解参数```4.分析结果通过拟合模型得到的参数,可以分析和解释自变量和因变量之间的关系。
可以通过计算拟合优度等指标评价模型的拟合效果。
5.可视化结果使用MATLAB的绘图函数,将观测数据和拟合函数的曲线绘制在同一张图上,以直观地展示非线性回归分析的结果。
例如,可以使用以下代码绘制拟合曲线:```MATLABxx = linspace(min(x), max(x), 100); % 生成等间距的自变量yy = model(p, xx); % 计算拟合函数的因变量plot(x, y, 'o', xx, yy); % 绘制观测数据和拟合曲线```通过以上步骤,就能够应用MATLAB进行非线性回归分析。
非线性回归方程公式详解
非线性回归方程公式详解一、非线性回归的定义和方程1、非线性回归非线性回归是回归函数关于未知回归系数具有非线性结构的回归。
常用的处理方法有回归函数的线性迭代法、分段回归法、迭代等。
非线性回归分析的主要内容与线性回归分析相似。
2、回归分析对具有相关关系的两个变量进行统计分析的方法叫回归分析。
其基本步骤是:(1)画散点图;(2)求回归直线方程;(3)用回归直线方程作预报。
3、回归直线如果具有相关关系的两个变量的一组数据(x1,y1)(x1,y1),(x2,y2)(x2,y2),⋯⋯,(xn,yn)(xn,yn)大致分布在一条直线附近,那么我们称这样的变量之间的关系为线性相关关系,这条直线就是回归直线,记为yˆ=bˆx+aˆy^=b^x+a^。
4、回归直线方程的求法——最小二乘法设具有线性相关关系的两个变量xx,yy的一组观察值为(xi,yi)(xi,yi)(i=1,2,⋯,n)(i=1,2,⋯,n),则回归直线方程yˆ=bˆx+aˆy^=b^x+a^的系数为bˆ=b^=∑ni=1(xi−x¯¯¯)(yi−y¯¯¯)∑ni=1(xi−x¯¯¯)2=∑ni=1(xi−x¯)(yi−y¯)∑ni=1(xi−x¯)2=∑ni=1xiyi−nx¯¯¯y¯¯¯∑ni=1x2i−nx¯¯¯2∑ni=1xiyi−nx¯ y¯∑ni=1xi2−nx¯2,aˆ=y¯¯¯−bˆx¯¯¯a^=y¯−b^x¯,其中(xi,yi)(xi,yi)为样本数据,x¯¯¯=x¯=1n∑ni=1xi1n∑ni=1xi,y¯¯¯=y¯=1n∑ni=1yi1n∑ni=1yi为样本平均数。
非线性回归分析的方法研究
非线性回归分析的方法研究在科学和工程领域,回归分析是一种广泛使用的数据分析方法,旨在探索变量之间的相互关系。
然而,许多实际问题是非线性的,传统的线性回归方法无法很好地解决这些问题。
因此,非线性回归分析的研究变得越来越重要。
本文将介绍非线性回归分析的基本概念、方法、应用领域以及所面临的挑战,并讨论未来的研究方向。
非线性回归分析方法可以解决许多复杂的问题,如生物医学、经济学、工程等领域中的非线性关系。
例如,在生物医学领域,药物浓度与治疗效果之间的关系往往是非线性的;在经济学领域,价格和需求之间的关系也往往是非线性的。
因此,研究非线性回归分析的方法对于解决这些实际问题具有重要的意义。
参数非线性回归是一种常用的非线性回归方法,它通过建立一个包含参数的数学模型来描述变量之间的非线性关系。
这种方法通常包括确定参数的初始值、使用最小二乘法等优化算法来拟合模型以及验证模型的可靠性等步骤。
基于核的非线性回归方法使用核函数来计算变量之间的相似性,并将这些相似性用于建立回归模型。
这种方法不需要明确的数学表达式,因此可以处理一些难以描述的复杂非线性关系。
支持向量回归是一种基于支持向量机(SVM)的非线性回归方法。
它通过建立一个SVM模型来描述变量之间的非线性关系,并使用优化算法来寻找最优的模型参数。
非线性回归分析方法在各个领域都有广泛的应用。
例如,在生物医学领域,非线性回归分析可以用于研究药物浓度与治疗效果之间的关系,为新药研发提供指导;在经济学领域,非线性回归分析可以用于研究价格和需求之间的关系,帮助企业制定更加合理的定价策略。
非线性回归分析还广泛应用于工程、环境科学、社会科学等领域。
数据处理:非线性回归分析需要处理的数据往往比较复杂,需要采取合适的数据预处理方法来提高分析的准确性。
模型选择:不同的非线性回归方法适用于不同的问题,如何根据实际问题选择合适的模型是一个重要的挑战。
模型优化:非线性回归模型需要通过优化算法来寻找最优的模型参数,如何选择合适的优化算法也是一个重要的挑战。
SPSS数据分析—非线性回归
SPSS数据分析—非线性回归
线性回归的关键条件是因变量与自变量之间呈线性关系。
如果存在非线性关系,就需要使用非线性回归进行分析。
在SPSS中,非线性回归有两个过程可供调用:回归曲线估计和
非线性回归。
这两种方法的思路不同,前者通过变量转换将曲线线性化,再使用线性回归进行拟合;后者则直接按照非线性模型进行拟合。
使用变量转换的方法简单易行,但只适用于拟合比较简单的非线性关系。
此外,变量转换可能会改变残差的分布和独立性等性质,导致拟合结果不一定是最优解。
当曲线关系复杂时,无法通过变量转换进行直线化。
因此,非线性回归模型可以很好地解决这些问题。
非线性回归模型提出了一个基本模型框架,期望函数可以为任意形式,甚至没有表达式。
在参数估计上,由于是曲线,无法直接使用最小二乘法进行估计,需要使用XXX-牛顿法进行估计,这一方法比较依赖于初始值的设定。
为了比较两种方法的效果,我们使用同一组数据来进行拟合。
使用回归曲线估计进行拟合时,需要进行变量转换,只能
拟合比较简单的非线性关系。
而使用非线性回归进行拟合时,直接按照非线性模型进行拟合,可以拟合更为复杂的非线性关系。
因此,非线性回归在处理复杂非线性关系时更为有效。
非线性回归分析
非线性回归分析随着数据科学和机器学习的发展,回归分析成为了数据分析领域中一种常用的统计分析方法。
线性回归和非线性回归是回归分析的两种主要方法,本文将重点探讨非线性回归分析的原理、应用以及实现方法。
一、非线性回归分析原理非线性回归是指因变量和自变量之间的关系不能用线性方程来描述的情况。
在非线性回归分析中,自变量可以是任意类型的变量,包括数值型变量和分类变量。
而因变量的关系通常通过非线性函数来建模,例如指数函数、对数函数、幂函数等。
非线性回归模型的一般形式如下:Y = f(X, β) + ε其中,Y表示因变量,X表示自变量,β表示回归系数,f表示非线性函数,ε表示误差。
二、非线性回归分析的应用非线性回归分析在实际应用中非常广泛,以下是几个常见的应用领域:1. 生物科学领域:非线性回归可用于研究生物学中的生长过程、药物剂量与效应之间的关系等。
2. 经济学领域:非线性回归可用于经济学中的生产函数、消费函数等的建模与分析。
3. 医学领域:非线性回归可用于医学中的病理学研究、药物研发等方面。
4. 金融领域:非线性回归可用于金融学中的股票价格预测、风险控制等问题。
三、非线性回归分析的实现方法非线性回归分析的实现通常涉及到模型选择、参数估计和模型诊断等步骤。
1. 模型选择:在进行非线性回归分析前,首先需选择适合的非线性模型来拟合数据。
可以根据领域知识或者采用试错法进行模型选择。
2. 参数估计:参数估计是非线性回归分析的核心步骤。
常用的参数估计方法有最小二乘法、最大似然估计法等。
3. 模型诊断:模型诊断主要用于评估拟合模型的质量。
通过分析残差、偏差、方差等指标来评估模型的拟合程度,进而判断模型是否适合。
四、总结非线性回归分析是一种常用的统计分析方法,可应用于各个领域的数据分析任务中。
通过选择适合的非线性模型,进行参数估计和模型诊断,可以有效地拟合和分析非线性关系。
在实际应用中,需要根据具体领域和问题的特点来选择合适的非线性回归方法,以提高分析结果的准确性和可解释性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS—非线性回归(模型表达式)案例解析
2011-11-16 10:56
由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二!
非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型
还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢?
答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究:
第一步:非线性模型那么多,我们应该选择“哪一个模型呢?”
1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型
点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高!
点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果:
通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度明显高于
“二次”模型的拟合度(0.912 >0.900)不过,几乎接近
接着,我们采用S 模型,得到如下所示的结果:
结果分析:
1:从ANOVA表中可以看出:总体误差= 回归平方和 + 残差平方和(共计:0.782)F统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等)
2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986)常数项为2.672
所以 S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用)
当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量) = e^(-0.957/广告费用)
下面,我们直接采用“非线性”模型来进行操作
第一步:确定“非线性模型”
从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。
从图形可以看出:它符合The asymptotic regression model (渐近回归模型)
表达式为:Y(销售量)= b1 + b2*e∧b3*(广告费用)
当b1>0, b2<0, and b3<0,时,它符合效益递减规律,我们称之为:Mistcherlich's model
第二步:确定各参数的初始值
1:b1参数值的确定,从表达式可以看出:随着”广告费用“的增加,销售量也会增加,最后达到一个峰值,由于:b2<0, b3<0 ,随着广告费用的增加:
b2*e∧b3*(广告费用)会逐渐趋向于“0” 而此时 Y(销售量)将接近于 b1值,从上图可以看出:Y(销售量)的最大值为12点多,接近13,所以,我们设定b1的初始值为13
2:b2参数值确定:当Y(销售量)最小时,此时应该广告费用最小,基本等于“0”,可以得出:b1+b2= Y(销售量)此时Y销售量最小,从图中可以看出:第一个值为6.7左右,接近7这个值,所以:b2=7-13=-6
3: b3参数值确定:可以用图中两个分离点的斜率来确定b3的值,例如取
(x1=2.29,y1=8.71) 和( x2=5.75, y2=12.74) 通过公式 y2-y1/x2-x1=1.16,(此处可以去整数估计值来算b3的值)
确定参数初始值和参数范围的方法如下所示:
1:通过图形确定参数的取值范围,然后在这个范围里选择初始值。
2:根据非线性方程的数学特性进行某些变换后,再通过图形帮助判断初始值的范围。
3:先使用固定的数代替某些参数,以此来确定其它参数的取值范围。
4:通过变量转换,使用线性回归模型来估计参数的初始值
第三步:建立模型表达式和选择损失函数
点击“分析”—回归——非线性,进入如下所示界面:
如上图中,点击参数,分别添加b1,b2,b3进入参数框内,在模型表达式中输入:b1 + b2*Exp(b3*广告费用)(步骤为:选择“函数组”—算术——Exp函数),将“销售量”变量拖入“因变量”框内
“损失函数”默认选项为“残差平方和” 如果有特需要求,可以自行定义
点击“约束”进入如下所示的界面:
点击“继续”按钮,此时会弹出警告信息,提示用户是否接受建议, 建议内容为:将采用序列二次编程进行参数估计,点击确定,接受建议即可
参数的取值范围指在迭代过程中,将参数限制在有意义的范围区间内,提供两种对参数范围约束的方法:
1:线性约束,在约束表达式里只有对参数的线性运算
2:非线性约束,在约束表达式里,至少有一个参数与其它参数进行了乘,除运算,或者自身的幂运算
在“保存”选项中,勾选“预测值”和“残差”即可,点击继续
点击“选项”得到如下所示的界面:
此处的“估计方法”选择“序列二次编程”的方法,此方法主要利用的是双重迭代法进行求解,每一步迭代都建立一个二次规划算法,以此确定优化的方向,把估计参数不断的带入损失函数进行求值运算,直到满足指定的收敛条件为止
点击继续,再点击“确定”得到如下所示的结果:
上图结果分析:
1:从“迭代历史记录”表中可以看出:迭代了17次后,迭代被终止,已经找到最优解
此方法是不断地将“参数估计值”代入”损失函数“求解,而损失函数采用的是”残差平方和“最小,在迭代17次后,残差平方和达到最小值,最小值为(6.778)此时找到最优解,迭代终止
2:从参数估计值”表中可以看出:
b1= 12.904 (标准误为0.610,比较小,说明此估计值的置信度较高) b2=-11.268 (标准误为:1.5881,有点大,说明此估计值的置信度不太高) b3=-0.496(标准误为:0.138,很小,说明此估计值的置信度很高)
非线性模型表达式为:Y(销售量)= 12.904-11.268*e^(-0.496*广告费用)
3:从“参数估计值的相关性”表中可以看出:b1 和 b3的相关性较强,b2和
b1或b3的相关性都相对弱一些,其中b1和b2的相关性最弱
4:从anova表中可以看出:R方 = 1- (残差平方和)/(已更正的平方和) = 0.909,拟合度为0.909,说明此模型能够解释90多的变异,拟合度已经很高了
前面已经提到过,S行曲线的拟合度更高,为(0.916)那到底哪个更合适呢?如果您的数据样本容量够大,我想应该是“非线性模型”的拟合度会更高!
其实想想,我们是否可以将“非线性”转换为“线性”后,再利用线性模型进行分析了?后期有时间的话,将还是以本例为说明,如何将“非线性”转换为“线性”后进行分析!!。