计量资料的统计推断
统计描述与统计推断

统计描述与统计推断统计的主要工作就是对统计数据进行统计描述和统计推断。
统计描述是统计分析的最基本内容,是指应用统计指标、统计表、统计图等方法,对资料的数量特征及其分布规律进行测定和描述;而统计推断是指通过抽样等方式进行样本估计总体特征的过程,包括参数估计和假设检验两项内容。
(一)统计描述1.计量资料的统计描述计量资料的统计描述主要通过编制频数分布表、计算集中趋势指标和离散趁势指标以及统计图表来进行。
(1)集中趋势。
指频数表中频数分布表现为频数向某一位置集中的趋势。
集中趋势的描述指标:1)算术平均数。
直接法:x为观察值,n为个数加权法又称频数表法,适用于频数表资料,当观察例数较多时用。
f为各组段的频数。
2)几何平均数(geometric mean)。
几何平均数用符号G表示。
用于反映一组经对数转换后呈对称分布的变量值在数学上的平均水平。
直接法:加权法又称频数表法,当观察例数n较大时,可先编制频数分布表,用此法算几何平均数:3)百分位数(percentile )与中位数(median )。
百分位数是一种位置坐标,用符号x P 表示常用的百分位数有 2.5P 、5P 、50P 、75P 、95P 、97.5P 等,其中25P 、50P 、75P 又称为四分位数。
百分位数常用于描述一组观察值在某百分位置上的水平,多个百分位结合使用,可更全面地描述资料的分布特征。
中位数是一个特定的百分位数即50P ,用符号M 表示。
把一组观察值按从小到大(或从大到小)的次序排列,位置居于最中央的那个数据就是中位数。
中位数也是反映频数分布集中位置的统计指标,但它只由所处中间位置的部分变量值计算所得,不能反映所有数值的变化,故中位数缺乏敏感性。
中位数理论上可以用于任何分布类型的资料,但实践中常用于偏态分布资料和分布两端无确定值的资料。
其计算方法有直接法和频数表法两种。
直接法:当观察例数n 不大时,此法常用,先将观察值按大小次序排列,选用下列公式求M 。
实习3 计量资料的统计推断.

分析
• 计算差值d d • 计算 d n
s
d
d d n
2
2
n 1
s
• 计算t值
d
Sd n
d 0 t Sd
4.已知某地120名正常成人脉搏均数为 73.2/min,标准差为8.1/min,试估计该地正常 成年人脉搏总体均数的95%可信区间。
分析 1.大样本 2.代入公式,计算t值
5.某地区1999年测定了30岁以上正常人与冠心病人 的血清总胆固醇含量(mmol/L),资料见实习表3-1。 试检验正常人与冠心病人血清总胆固醇含量的差异有 无显著性。
实习表3-1 某地区30岁以上正常人与冠心病人的血清总胆固醇含量(mmol/L)
组别 测定人数 56 正常人 142 冠心病人
均数 4.67 5.78
• • • •
利用公式估计医学正常值 估计总体均数的可信区间 两样本均数比较的u检验 样本均数与总体均数的比较
2.某校在体检中随机抽取了同年级男生12 人,女生15人,测定其体重指数(BMI), 结果如下,试分析男女生体重指数有无差异?
男生(12人): 20.7 22.4 19.6 20.1 20.8 23.1 18.2 19.6 19.9 21.7 22.5 22.0 女生(15人): 18.5 17.6 19.5 18.7 21.3 20.5 17.5 21.9 22.1 20.8 19.7 19.0 19.8 20.5 20.7
分析
• • • • 计算男生体重指数的样本均数,标准差 计算女生体重指数的样本均数,标准差 进行两样本均数比较的t检验 利用计算器统计功能键进行简化计算
3.某新药治疗贫血患者12名,治 疗前和治疗后的血红蛋白(g/L)含 量如下: 患者号 1 2 3 4 5 6 7 8 9 10 11 12 治疗前 123 110 130 142 133 129 100 110 125 128 117 107 治疗后 128 135 128 147 150 140 125 127 130 150 127 110
《计量资料的统计推断》的复习思考题

《计量资料的统计推断》的复习思考题1.什么是统计推断?统计推断包括哪两方面内容?2.什么样的分布是t分布?对称分布、正态分布、t分布和标准正态分布有何区别和联系?3.什么是标准误?标准差和标准误有什么区别和联系?4.什么是总体均数的可信区间?某指标的95%正常值范围和95%可信区间有何区别何联系?5.显著性检验的目的意义是什么?基本原理是什么?前提条件有哪些?6.什么情况下可认为具有可比性?举例说明日常生活中常犯的没有可比性时进行比较的错误。
7.显著性检验的一般步骤有哪些?8.显著性检验时,假设有几种?哪几种?如何假设?9.假设检验时,如何选择进行单侧或双侧检验?10.什么是检验水准/显著性水平?一般是多少?如何根据实际情况来确定检验水准?11.假设检验时的“P值”是什么?举例说明。
12.统计学结论和实际意义有何异同?13.什么情况下应该作u/z检验?什么情况下应该作t检验?14.举例说明成组设计和配对设计有何区别。
15.有人说,“只要是比较两个均数,都可以作t检验。
”你认为这种说法对吗?为什么?16.什么是I类错误?什么是II类错误?为什么显著性检验时会犯这两类错误?这两类错误各有什么特点?相互之间有什么关系?17.什么是把握度?科学研究时如何才能使把握度达到一定的水平?18.为什么说统计学结论是概率性的,既不绝对肯定,也不绝对否定?19.随机抽取某品种2月龄苗猪25头,测得其平均体重为20kg,标准差为3kg。
试估计该品种2月龄苗猪的体重。
20.随机测得100听某批某种罐头净重量平均为344.0g,标准差为4.43g。
试估计该批该种罐头的净重量和正常值范围。
21.某鱼场按常规方法所育鲢鱼苗一月龄的平均体长为7.25cm,标准差为1.58cm。
为提高鱼苗质量,现采用一新方法进行育苗,一月龄时随机抽取100尾进行测量,测得其平均体长为7.65cm。
试问新方法能否使一月龄鲢鱼苗体长更长?22.某名优绿茶含水量标准为不超过5.5%。
计量资料的统计学方法

计量资料的统计学方法
首先,计量资料的统计学方法包括描述统计和推断统计。
描述
统计用于总结和展示数据的特征,包括均值、中位数、标准差、频
数分布等。
这些统计量可以帮助我们了解数据的集中趋势、离散程
度和分布形态。
推断统计则用于从样本数据中推断总体的特征,包
括参数估计和假设检验。
参数估计可以帮助我们对总体参数(如均值、比例)进行估计,而假设检验则可以帮助我们对总体参数的假
设进行检验。
其次,计量资料的统计学方法还包括回归分析和方差分析。
回
归分析用于研究自变量和因变量之间的关系,可以帮助我们预测因
变量的取值。
常见的回归分析包括简单线性回归和多元线性回归。
方差分析则用于比较多个总体均值是否相等,可以帮助我们判断不
同组别之间的差异是否显著。
此外,计量资料的统计学方法还包括相关分析和时间序列分析。
相关分析用于研究两个变量之间的相关关系,可以帮助我们了解它
们之间的相关性强弱和方向。
时间序列分析则用于研究时间序列数
据的特征和规律,包括趋势、季节性和周期性等,可以帮助我们进
行未来的预测和规划。
综上所述,计量资料的统计学方法涵盖了描述统计、推断统计、回归分析、方差分析、相关分析和时间序列分析等多个方面,可以
帮助我们全面深入地理解和解释数据的特征和规律。
在实际应用中,研究者可以根据具体问题的特点和要求选择合适的统计方法进行分
析和解释。
医学统计学学习笔记

医学统计学笔记一、绪论及基本概念1. 资料类型①计量资料(定量资料、数值变量资料):连续型、离散型②计数资料(定性资料、无序分类变量、名义变量):二分类、多分类③等级资料(半定量资料、有序分类变量)信息量:计量资料>等级资料>计数资料2.误差类型①过失误差:可避免②系统误差:具有明确的方向性,可避免③随机误差:分为随机测量误差和随机抽样误差,没有固定的大小和方向,不可避免3.核心概念参数:u、σ;固定的常数,总体的统计指标,参数大小客观存在,但往往未知。
统计量:X̅,S,P;样本的统计指标,参数附近波动的随机变量。
概率为参数,频率为统计量。
4.医学统计工作的基本步骤:设计、收集资料、整理资料、分析资料二、计量资料的统计描述1.集中趋势的描述a.算术均数,简称均数(mean):主要适用于对称分布或偏度不大的资料,尤其适合正态分布资料。
不能用于开口型资料。
u(总体均数),X(样本均数)。
b.几何均数(geometric mean,G):适用于经对数转换后呈对称分布。
观察值不能为0 、不能同时有正有负。
同一资料算得的几何均数小于算术均数。
c.中位数(median, M)和百分位数(precentile, Px):适用于各种分布类型资料。
当计量资料适合计算均数或几何均数时,不宜用中位数表示其平均水平。
用频数表法计算百分位数时,组距不一定要相等。
P x=L x+i x(n∗x%−∑f L)f xL x:第x百分位数所在组段的下限i x:第x百分位数所在组段的组距f x:第x百分位数所在组段的频数∑f L:第x百分位数所在组段上一组段累计频数d.调和均数(harmonic mean,H):适用于表达呈极严重的正偏态分布资料的平均水平。
计算方法为求倒数的均值后再取其倒数。
SPSS:在Transform中输入公式。
2.离散(dispersion)趋势的描述a.极差(range,R):也称为全距。
b.四分位数间距(quartile range,Q):即统计图中箱子的高度,常用于偏态资料离散度的描述,多与M 合用。
计量资料和计数资料的统计方法

计量资料和计数资料的统计方法计量资料和计数资料是统计学中常见的两种数据类型,它们在统计分析中有着不同的处理方法和应用场景。
本文将分别介绍计量资料和计数资料的统计方法,并探讨其在实际问题中的应用。
一、计量资料的统计方法计量资料是指可以用数值表示的数据,例如身高、体重、温度等。
统计学中常用的计量资料分析方法有描述统计和推断统计。
1. 描述统计描述统计是对收集到的数据进行总结和描述的方法。
常用的描述统计量有平均值、中位数、众数、标准差、方差等。
平均值是计量资料最常用的描述统计量,它可以反映数据的集中趋势。
中位数和众数则可以反映数据的位置和分布情况。
标准差和方差则可以衡量数据的离散程度。
2. 推断统计推断统计是基于样本数据对总体进行推断的方法。
在推断统计中,常用的统计分析方法有假设检验和置信区间估计。
假设检验用于验证关于总体的某个参数的假设,例如总体均值是否等于某个特定值。
置信区间估计则可以给出总体参数的一个区间估计,例如总体均值的置信区间。
二、计数资料的统计方法计数资料是指不连续的、以计数形式出现的数据,例如人数、次数、事件发生次数等。
计数资料的统计方法主要包括频数分布、列联表分析和卡方检验。
1. 频数分布频数分布是计数资料最常用的分析方法之一,它将数据按照不同的取值进行分类,并统计每个类别的频数。
通过频数分布可以直观地了解数据的分布情况和特征。
2. 列联表分析列联表分析是用于分析两个或多个分类变量之间关系的方法。
通过构建列联表可以清晰地展示不同变量之间的交叉频数,并计算各个格子的期望频数和卡方值。
列联表分析可以帮助我们判断两个变量之间是否存在相关性。
3. 卡方检验卡方检验是用于检验两个或多个分类变量之间是否存在显著差异的统计方法。
卡方检验基于计数资料的频数分布和列联表,通过计算观察频数与期望频数的差异,并进行假设检验来判断变量之间是否独立。
三、计量资料和计数资料的应用计量资料和计数资料在实际问题中具有广泛的应用。
计量资料的统计推断-t检验

t分布 特征
f(t)
ν─>∞(标准正态曲线) ν =5 ν =1
-5
-4
-3
-2
-1
0
1
不同自由度下的t 分布图
2
3
4
5
• 自由度ν 不同,曲线形态不同,t分布是一簇曲线。 • 自由度ν 越大,t分布越接近于正态分布;当自由度 ν 逼近∞时,t分布趋向于标准正态分布。
t
概率、自由度与t值关系 ——t界值
140 138 140 135 135 120 147 114 138 120
治疗矽肺患者血红蛋白量(克%)
编号
1
治疗前
113
治疗后
140
治疗前后差数d
27
2
3 4 5 6
150
150 135 128 100
138
140 135 135 120
-12
-10 0 7 20
7
8 9 10
110
120 130 123
配对样本均数t检验——实例分析
• 例: 有12名接种卡介苗的儿童,8周后用 两批不同的结核菌素,一批是标准结核菌 素,一批是新制结核菌素,分别注射在儿 童的前臂,两种结核菌素的皮肤浸润反应 平均直径(mm)如表5-1所示,问两种结核菌 素的反应性有无差别?
表 5-1
12 名儿童分别用两种结核菌素的皮肤浸润反应结果(mm) 编号 1 2 3 4 5 6 7 8 9 10 11 12 合计 标准品 12.0 14.5 15.5 12.0 13.0 12.0 10.5 7.5 9.0 15.0 13.0 10.5 新制品 10.0 10.0 12.5 13.0 10.0 5.5 8.5 6.5 5.5 8.0 6.5 9.5 差值 d 2.0 4.5 3.0 -1.0 3.0 6.5 2.0 1.0 3.5 7.0 6.5 1.0 39(d) d2 4.00 20.25 9.00 1.00 9.00 42.25 4.00 1.00 12.25 49.20 42.25 1.00 195(d2)
量性研究资料的统计学分析方法--高等教育自学考试辅导《护理学研究》第八章第二节讲义1
正保远程教育旗下品牌网站 美国纽交所上市公司(NYSE:DL)
自考365 中国权威专业的自考辅导网站
官方网站: 高等教育自学考试辅导《护理学研究》第八章第二节讲义1
量性研究资料的统计学分析方法
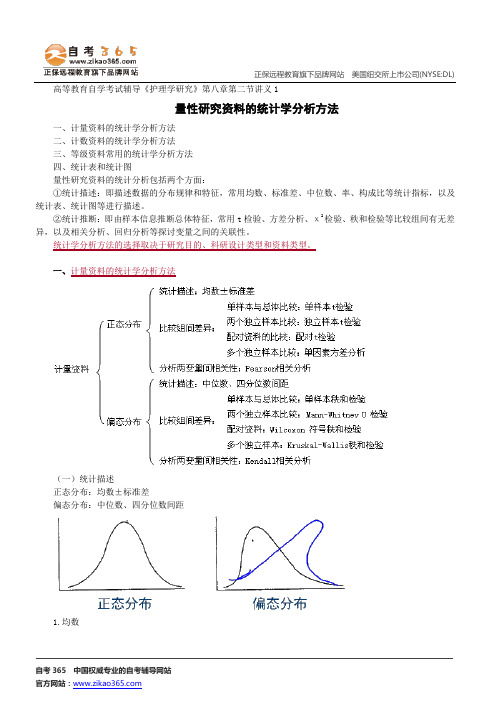
一、计量资料的统计学分析方法
二、计数资料的统计学分析方法
三、等级资料常用的统计学分析方法
四、统计表和统计图
量性研究资料的统计分析包括两个方面:
①统计描述:即描述数据的分布规律和特征,常用均数、标准差、中位数、率、构成比等统计指标,以及统计表、统计图等进行描述。
②统计推断:即由样本信息推断总体特征,常用t 检验、方差分析、χ2检验、秩和检验等比较组间有无差异,以及相关分析、回归分析等探讨变量之间的关联性。
统计学分析方法的选择取决于研究目的、科研设计类型和资料类型。
计量资料的统计学分析方法
(一)统计描述
正态分布:均数±标准差
偏态分布:中位数、四分位数间距
1.均数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
的代表程度。
用于估计总体均数的可信区间;
用于假设检验。
减少SE的途径
克服系统误差和减少随机误差;
增大样本含量。
2020/10/6
第四章与第五章 统计推断
9
一 标准误
下一页
7 标准差SD与标准误SE的区别
离散指标,用于说明变异程度的大小。
意义上:
S 描述变量 X 的变异程度,说明变量值分布; SX 描述 X 的变异程度,说明 X 分布情况。
作用上:
S 描述 X 对 X 的代表性,说明 X 对的代表程度; SX 描述 X 对的代表性,说明 X 代表的可靠性。
应用上:
S 用于参考值范围的估计。
当总体标准差未知时,用 S 估计,得样本均数
标准误的估计值 SE s s
X
n
例 4.1
SE SX
S n
0.38 0.032(估 计 值) 140
2020/10/6
第四章与第五章 统计推断
8
一 标准误
下一页
6 SE的应用及减少的途径
抽样误差的大小,样本均数变异度,说明样
本均数估计总体均数的可靠性;
样本均数标准误
越小,说明样本均数与总体均数的差异程度越小, 用该样本均数估计总体均数越可靠。
越大,样本均数的抽样误差就越大。
2020/10/6
第四章与第五章 统计推断
7
一 标准误
下一页
5 标准误SE
若 X~N(,2),则 X 也服从正态分布,即
X
~
N(, X 2)
N(, 2
n
)
/ n 为样本均数标准差(标准误)。
2 t分布的曲线与特征(P29)
以 0 为中心、左右对称的单峰曲线;
自由度为参数,高峰随 n 增大而增高;
以 N(0,1)为渐近分布;
当, S X X ,
t 分布u 分布
以横轴为渐近线;
曲线下面积为 1。
2020/10/6
第四章与第五章 统计推断
13
均数估计
下一页
3 附表2 t分布界值表 P195
第四章与第五章 统计推断
2
第四章第一节 均数的抽样误差与标准误
统计推断与抽样误差 均数的抽样误差—标准误 SE应用及减少的途径
2020/10/6
第四章与第五章 统计推断
3
一 标准误
下一页
1 总体与样本
总体
抽取部分观察单位
样本
参数:
总体均数
总体标准差 总体率
统计推断
统计量: 样本均数 X 样本标准差 S 样本率 P
SX 用于总体参数可信区间的估计。
2020/10/6
第四章与第五章 统计推断
10
第四章 第二节 总体均数的估计
t 分布 t-distribution 总体均数的估计
Estimation of Population Mean 参数估计 可信区间的涵义与要素 总体均数的可信区间
2020/10/6
第四章与第五章 统计推断
由样本统计量估计总体参数。
点(值)估计,point estimation。
求导总体参数的估计值。
区间估计,interval estimation。
把抽样误差考虑在内的总体指标的估计方法。
按预先给定的概率(可信度、confidence level)估计
横标目:
自由度; 纵标目:
自由 度
单侧 双侧
0.05 0.10
概率 P 0.025 0.01 0.02 0.02
0.005 0.01
概率P。 1
6.314 12.706 31.821 63.657
t界值是在 2
2.920 4.303 6.965 9.925
某一自由度下3,t分布曲2.3线53下3.182 4.541 5.841
11
均数估计
1 t分布的推导(P29)
X~N ( μ,σ 2 )
下一页
X~N( μ,σ2 ) X
X ~ N 0,1
Xμ
U
~N (0,1)
σ
X
X 未知,用 SX
S 估计之,产生新
n
的统计量t
X
SX
~t 分布(
n - 1)。
2020/10/6
第四章与第五章 统计推断
12
均数估计
下一页
2020/10/6
第四章与第五章 统计推断
4
一 标准误
下一页
2 统计推断
statistical inference 为了研究总体进行随机抽样获取样本,利用
样本信息推断总体特征的过程。
医学研究中大多数是无限总体, 即使是有限总体,但也经常受各种条件的限制,
不可能直接获得总体的信息。
内容:参数估计与假设检验。
2020/10/6
第四章与第五章 统计推断
5
一 标准误
下一页
3 抽样误差(参阅P6)
sampling error。 在抽样研究(sampling study)中,由于生物个
体的差异客观存在,造成的样本统计量与总 体参数之间的差异,或同一总体的样本统计 量之间的差异。
在抽样研究中,抽样误差是无法避免的,但具有 一定的规律性。
高侧:P(t>=1.725)=a=0.05
或P(t<1.725)=1-a=0.95
双侧:=20,a=0.05,ta2.086
P(|t|>= 2.086)=a=0.05,或P(|t|<2.086)=1-a =0.95
2020/10/6
第四章与第五章 统计推断
15
均数估计
下一页
5 参数估计 parametric estimation
两端(双侧)阴影部分为P。
反映t分布曲线下的面积。
从概率的角度看:阴影部分
是P=P( t>=| ta()|)。
2020/10/6
第四章与第五章 统计推断
14
均数估计
下一页
4 查 t界值表
单侧:=20, a =0.05,ta1.725
低侧:P(t<=-1.725)= a =0.05
或P(t>-1.725)=1-a =0.95
医学统计学
第四章与第五章 计量资料的统计推断
2020/10/6
第四章与第五章 统计推断
1
医学统计学
计量资料的统计推断
第四章 第五章
第一节 抽样误差与标准误差 第二节 总体均数的估计 第三节 假设检验意义和步骤 第一节~第五节 t检验 第六节 t检验中的注意事项 第七节 假设检验中两类错误
2020/10/6
产生抽样误差的原因:个体差异。
样本均数的抽样误差是指样本均数与总体均 数之间的差异,或样本均数之间的差异。
2020/10/6
第四章与第五章 统计推断
6
一 标准误
下一页
4 样本均数的标准差
统计学中把样本均数的标准差用于描述样本 均数的离散程度,称为标准误(standard error)。
用于衡量描述抽样误差的大小。