六步学会用MATLAB做空间计量回归详细步骤
使用Matlab技术进行回归分析的基本步骤

使用Matlab技术进行回归分析的基本步骤回归分析是统计学中一种用于研究变量间关系的方法,可以用来预测和解释变量之间的相关性。
在实际应用中,使用计算工具进行回归分析可以提高分析效率和准确性。
本文将介绍使用Matlab技术进行回归分析的基本步骤,并探讨其中的一些关键概念和技巧。
一、数据准备在进行回归分析之前,首先需要收集和整理相关的数据。
这些数据通常包括自变量和因变量。
自变量是用来解释或预测因变量的变量,而因变量是需要解释或预测的变量。
在Matlab中,可以将数据保存为数据矩阵,其中每一列代表一个变量。
二、模型建立在回归分析中,需要建立一个数学模型来描述自变量和因变量之间的关系。
最简单的线性回归模型可以表示为:Y = βX + ε,其中Y是因变量,X是自变量,β是回归系数,ε是误差项。
在Matlab中,可以使用regress函数来进行线性回归分析。
三、模型拟合模型拟合是回归分析的核心步骤,它的目标是找到最佳的回归系数,使得预测值与实际观测值之间的差异最小。
在Matlab中,可以使用OLS(Ordinary Least Squares)方法来进行最小二乘法回归分析。
该方法通过最小化残差平方和来估计回归系数。
四、模型诊断模型诊断是回归分析中非常重要的一步,它可以帮助我们评估模型的合理性和有效性。
在Matlab中,可以使用多种诊断方法来检验回归模型是否满足统计假设,例如残差分析、方差分析和假设检验等。
这些诊断方法可以帮助我们检测模型是否存在多重共线性、异方差性和离群值等问题。
五、模型应用完成模型拟合和诊断之后,我们可以使用回归模型进行一些实际应用。
例如,可以使用模型进行因变量的预测,或者对自变量的影响进行解释和分析。
在Matlab中,可以使用该模型计算新的观测值和预测值,并进行相关性分析。
六、模型改进回归分析并不是一次性的过程,我们经常需要不断改进模型以提高预测的准确性和解释的可靠性。
在Matlab中,可以使用变量选择算法和模型改进技术来优化回归模型。
MATLAB回归分析工具箱使用方法

MATLAB回归分析工具箱使用方法1.数据准备在使用回归分析工具箱进行分析之前,首先需要准备好要使用的数据集。
数据集通常包含自变量和因变量,自变量是预测因变量的变量。
将数据集导入MATLAB中,并确保数据格式正确,可以使用MATLAB内置的导入工具或手动输入数据。
2.回归模型的选择在进行回归分析之前,需要选择适当的回归模型。
回归模型决定了如何拟合数据和生成预测。
常见的回归模型包括线性回归、多项式回归、逻辑回归等。
根据数据的特征和目的选择合适的回归模型。
3.拟合数据选择适当的回归模型后,可以使用回归分析工具箱中的函数来拟合数据。
常用的函数包括“fitlm”(线性回归)、“fitpoly”(多项式回归)、“fitglm”(逻辑回归)等。
将自变量和因变量传入对应的函数中,并得到拟合的模型。
例如,对于线性回归可以使用以下代码进行拟合:```mdl = fitlm(X,Y,'linear');```其中,X为自变量数据,Y为因变量数据,'linear'表示选择线性回归模型。
4.模型评估在拟合数据后,需要对模型进行评估以确定其拟合程度和预测性能。
可以使用回归分析工具箱中的函数来评估模型,如“plotResiduals”(绘制残差图)、“predict”(预测值)、“coefTest”(参数显著性检验)等。
通过观察残差图、计算R²值、进行参数显著性检验等方法,评估模型的拟合效果。
5.预测拟合好模型后,可以使用该模型进行预测未来的趋势。
使用“predict”函数可以生成预测值,并与实际值进行比较以评估模型的预测能力。
例如```Ypred = predict(mdl,Xnew);```其中,Xnew为新的自变量数据,Ypred为预测的因变量值。
6.结果可视化最后,可以使用MATLAB中的绘图工具来可视化回归分析的结果。
可以绘制拟合曲线、残差图、预测结果等,以便更直观地理解数据和模型。
六步学会用MATLAB做空间计量回归详细步骤
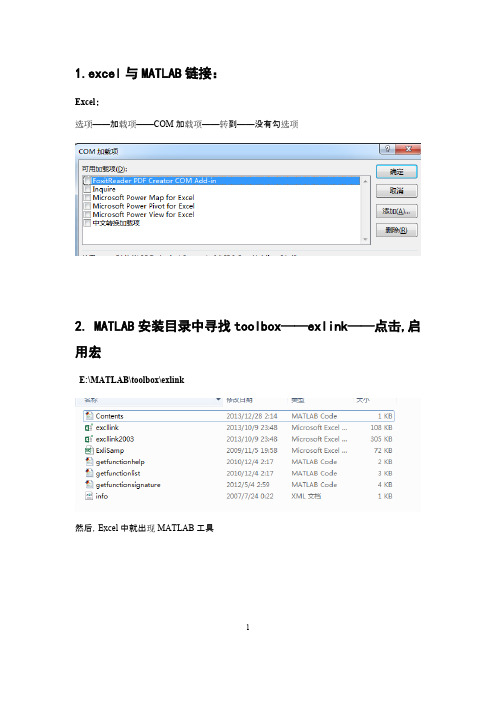
1.excel与MATLAB链接:Excel:选项选项——加载项——COM加载项——转到——没有勾2. MATLAB安装目录中寻找toolbox——exlink——点击,启用宏E:\MATLAB\toolbox\exlink12(注意Excel中的数据:)3.启动matlab(1(点击start MATLAB (2(senddata to matlab ,并对变量矩阵变量进行命名(注意:选取变量为数值,不包括各变量)3(data 表中数据进行命名)(空间权重进行命名)(3(导入MATLAB 中的两个矩阵变量就可以看见44.将elhorst 和jplv7两个程序文件夹复制到MATLAB 安装目录的toolbox 文件夹5.设置路径:56.输入程序,得出结果T=30;N=46;W=normw(W1);y=A(:,3);x=A(:,[4,6]);xconstant=ones(N*T,1);[nobs K]=size(x);results=ols(y,[xconstant x]);vnames=strvcat('logcit','intercept','logp','logy');prt_reg(results,vnames,1);sige=results.sige*((nobs-K)/nobs);loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'*results.resid % The (robust)LM tests developed by ElhorstLMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 解释每一行分别表示:该面板数据的时期数为30(T=30),该面板数据有30个地区(N=30),将空间权重矩阵标准化(W=normw(w1)),将名为A(以矩阵形式出现在MATLABA中)的变量的第3列数据定义为被解释变量y,将名为A的变量的第4、5、6列数据定义为解释变量矩阵x,定义一个有N*T行,1列的全1矩阵,该矩阵名为:xconstant,(ones即为全1矩阵)6说明解释变量矩阵x的大小:有nobs行,K列。
matlab回归建模过程

matlab回归建模过程摘要:一、引言二、MATLAB 回归建模的基本步骤1.数据的收集与整理2.建立回归模型3.模型参数估计4.模型检验5.模型预测与控制三、MATLAB 回归建模的实例分析1.一元线性回归2.多元线性回归3.逐步回归四、MATLAB 回归建模的优点与局限五、结论正文:一、引言MATLAB 是一种广泛应用于科学计算和工程设计的软件,其强大的数据处理和可视化功能为各种数学建模问题提供了便捷的解决方案。
在数学建模领域,回归分析是一种重要的方法,用于研究因变量和自变量之间的关系。
本文将详细介绍如何使用MATLAB 进行回归建模的过程。
二、MATLAB 回归建模的基本步骤1.数据的收集与整理在进行回归分析之前,首先需要收集相关的数据。
这些数据可以是实验测量值、历史统计数据等。
在收集到数据后,需要对其进行整理,将其转换为MATLAB 可以处理的格式。
2.建立回归模型在建立回归模型时,需要根据数据的特点和问题的实际背景选择合适的回归模型。
常见的回归模型有一元线性回归、多元线性回归、多项式回归、指数回归等。
3.模型参数估计在建立回归模型后,需要通过最小二乘法或其他方法对模型的参数进行估计。
MATLAB 提供了线性回归函数`regress`和多项式回归函数`polyfit`等工具用于模型参数的估计。
4.模型检验在模型参数估计完成后,需要对模型进行检验,以判断模型是否符合数据的实际情况。
常见的模型检验方法有残差分析、参数显著性检验等。
5.模型预测与控制在模型经过检验后,可以使用模型对未来的数据进行预测,或者利用模型对现有的数据进行控制。
MATLAB 提供了`predict`和`fit`等函数用于模型的预测和控制。
三、MATLAB 回归建模的实例分析1.一元线性回归以某市社会商品零售总额与职工工资总额的数据为例,可以使用一元线性回归模型进行建模。
首先输入数据,然后画出散点图,接着使用`regress`函数进行最小二乘回归,得到模型参数。
用MATLAB求解回归分析

(2)非线性回归命令:nlintool(x,y,’model’, beta0,alpha) ) 2、预测和预测误差估计: 、预测和预测误差估计: [Y,DELTA]=nlpredci(’model’, x,beta,r,J) 求nlinfit 或nlintool所得的回归函数在x处的预测值Y及预测值的显 著性为1-alpha的置信区间Y ± DELTA.
4、预测及作图: [;,x',beta,r ,J); plot(x,y,'k+',x,YY,'r')
例5 财政收入预测问题:财政收入与国民收入、工业总产值、 农业总产值、总人口、就业人口、固定资产投资等因素有关。 下表列出了1952-1981年的原始数据,试构造预测模型。
得结果:b = -16.0730 0.7194 stats = 0.9282 180.9531 0.0000 bint = -33.7071 0.6047 1.5612 0.8340
ˆ ˆ ˆ ˆ 即 β 0 = −16.073, β 1 = 0.7194 ; β 0 的置信区间为[-33.7017,1.5612], β 1 的置信区间为[0.6047,0.834];
回 归 系 数 的 区 间 估 计 F 检验回归模型的 计 数 : 系数r2、 、 F 的 p 差 区 间 时 为 水 0 平 05 ) . 性 残 信 省 著 置 (缺 显
系数 r2 F > F1F k 的 n-k-1
1
回归 H0 F H0 回归模型 回归 .
p< α
3、 、
区间: 区间:
rcoplot
r2=0.9282, F=180.9531, p=0.0000 p<0.05, 可知回归模型 y=-16.073+0.7194x 成立.
MATLAB回归分析工具箱使用方法

MATLAB回归分析工具箱使用方法下面将详细介绍如何使用MATLAB中的回归分析工具箱进行回归分析。
1.数据准备回归分析需要一组自变量和一个因变量。
首先,你需要将数据准备好,并确保自变量和因变量是数值型数据。
你可以将数据存储在MATLAB工作区中的变量中,也可以从外部文件中读取数据。
2.导入回归分析工具箱在MATLAB命令窗口中输入"regstats"命令来导入回归分析工具箱。
这将使得回归分析工具箱中的函数和工具可用于你的分析。
3.线性回归分析线性回归分析是回归分析的最基本形式。
你可以使用"regstats"函数进行线性回归分析。
以下是一个简单的例子:```matlabdata = load('data.mat'); % 从外部文件加载数据X = data.X; % 自变量y = data.y; % 因变量stats = regstats(y, X); % 执行线性回归分析beta = stats.beta; % 提取回归系数rsquare = stats.rsquare; % 提取判定系数R^2```在上面的例子中,"regstats"函数将自变量X和因变量y作为参数,并返回一个包含回归系数beta和判定系数R^2的结构体stats。
4.非线性回归分析如果你的数据不适合线性回归模型,你可以尝试非线性回归分析。
回归分析工具箱提供了用于非线性回归分析的函数,如"nonlinearmodel.fit"。
以下是一个非线性回归分析的例子:```matlabx=[0.10.20.5125]';%自变量y=[0.92.22.83.66.58.9]';%因变量f = fittype('a*exp(b*x)'); % 定义非线性模型model = fit(x, y, f); % 执行非线性回归分析coeffs = model.coefficients; % 提取模型系数```在上面的例子中,"fittype"函数定义了一个指数型的非线性模型,并且"fit"函数将自变量x和因变量y与该模型拟合,返回包含模型系数的结构体model。
MATLAB统计工具箱中回归分析命令
MATLAB统计工具箱中回归分析命令
相关关系的测度
(相关系数取值及其意义)
完全负相关
无线性相关
完全正相关
-1.0 -0.5 0 +0.5 +1.0
r
负相关程度增加 正相关程度增加
MATLAB统计工具箱中回归分析命令
统计工具箱中的回归分析命令
1.多元线性回归 2.多项式回归 3.非线性回归 4.逐步回归
回
残
置
归
差
信
系
区
显著性水平 (缺省时为0.05)
数
间 用于检验回归模型的统计量,
的
有三个数值:相关系数r 2、
区
F值、与F 对应的概率p
间
估
计
相关系数 r2 越接近 1,说明回归方程越显著;
F > F1-α(k,n-k-1)时拒绝 H0,F 越大,说明回归方程越显著;
与 F 对应的概率 p 时拒绝 H0,回归模型成立.
3. 当变量 x 取某个值时,变 量 y 的取值可能有几个
4. 各观测点分布在直线周围
x
MATLAB统计工具箱中回归分析命令
变量间的关系
(相关关系)
相关关系的例子
▪ 商品的消费量(y)与居民收入(x)之间的关系 ▪ 商品销售额(y)与广告费支出(x)之间的关系 ▪ 粮食亩产量(y)与施肥量(x1) 、降雨量(x2) 、
得回归模型为 :
s ˆ 4.8 29 t2 4 6.8 6 58 t 9 9 .16 329
To MATLAB(liti21)
MATLAB统计工具箱中回归分析命令
法二
化为多元线性回归:
t=1/30:1/30:14/30;
利用 Matlab作回归分析
利用 Matlab 作回归分析一元线性回归模型:2,(0,)y x N αβεεσ=++求得经验回归方程:ˆˆˆyx αβ=+ 统计量: 总偏差平方和:21()n i i SST y y ==-∑,其自由度为1T f n =-; 回归平方和:21ˆ()n i i SSR y y ==-∑,其自由度为1R f =; 残差平方和:21ˆ()n i i i SSE y y ==-∑,其自由度为2E f n =-;它们之间有关系:SST=SSR+SSE 。
一元回归分析的相关数学理论可以参见《概率论与数理统计教程》,下面仅以示例说明如何利用Matlab 作回归分析。
【例1】为了了解百货商店销售额x 与流通费率(反映商业活动的一个质量指标,指每元商品流转额所分摊的流通费用)y 之间的关系,收集了九个商店的有关数据,见下表1.试建立流通费率y 与销售额x 的回归方程。
表1 销售额与流通费率数据【分析】:首先绘制散点图以直观地选择拟合曲线,这项工作可结合相关专业领域的知识和经验进行,有时可能需要多种尝试。
选定目标函数后进行线性化变换,针对变换后的线性目标函数进行回归建模与评价,然后还原为非线性回归方程。
【Matlab数据处理】:【Step1】:绘制散点图以直观地选择拟合曲线x=[1.5 4.5 7.5 10.5 13.5 16.5 19.5 22.5 25.5];y=[7.0 4.8 3.6 3.1 2.7 2.5 2.4 2.3 2.2];plot(x,y,'-o')输出图形见图1。
510152025图1 销售额与流通费率数据散点图根据图1,初步判断应以幂函数曲线为拟合目标,即选择非线性回归模型,目标函数为:(0)b y ax b =< 其线性化变换公式为:ln ,ln v y u x == 线性函数为:ln v a bu =+【Step2】:线性化变换即线性回归建模(若选择为非线性模型)与模型评价% 线性化变换u=log(x)';v=log(y)';% 构造资本论观测值矩阵mu=[ones(length(u),1) u];alpha=0.05;% 线性回归计算[b,bint,r,rint,states]=regress(v,mu,alpha)输出结果:b =[ 2.1421; -0.4259]表示线性回归模型ln=+中:lna=2.1421,b=-0.4259;v a bu即拟合的线性回归模型为=-;y x2.14210.4259bint =[ 2.0614 2.2228; -0.4583 -0.3934]表示拟合系数lna和b的100(1-alpha)%的置信区间分别为:[2.0614 2.2228]和[-0.4583 -0.3934];r =[ -0.0235 0.0671 -0.0030 -0.0093 -0.0404 -0.0319 -0.0016 0.0168 0.0257]表示模型拟合残差向量;rint =[ -0.0700 0.02300.0202 0.1140-0.0873 0.0813-0.0939 0.0754-0.1154 0.0347-0.1095 0.0457-0.0837 0.0805-0.0621 0.0958-0.0493 0.1007]表示模型拟合残差的100(1-alpha)%的置信区间;states =[0.9928 963.5572 0.0000 0.0012] 表示包含20.9928SSR R SST==、 方差分析的F 统计量/963.5572//(2)R E SSR f SSR F SSE f SSE n ===-、 方差分析的显著性概率((1,2))0p P F n F =->≈; 模型方差的估计值2ˆ0.00122SSE n σ==-。
MATLAB回归分析工具箱使用方法
MATLAB回归分析工具箱使用方法回归分析是一种用于探索变量之间关系的统计方法。
它可以通过分析一个或多个自变量(也称为预测变量或解释变量)与一个因变量(也称为响应变量或预测变量)之间的关系来进行预测和解释。
在MATLAB中,进行回归分析需要使用统计和机器学习工具箱。
下面是使用MATLAB回归分析工具箱的一般步骤:1.准备数据:首先,你需要准备你要进行回归分析的数据。
数据应包括自变量和因变量。
你可以将数据存储在MATLAB的工作空间中。
2. 导入数据:如果你的数据存储在外部文件中,如Excel文件或CSV文件,你可以使用MATLAB的导入工具将数据导入到MATLAB中。
3.拟合模型:在回归分析中,你需要选择适当的模型来拟合你的数据。
MATLAB提供了多种回归模型,如线性回归、多项式回归、广义线性模型等。
你可以根据你的数据类型和需求选择适当的模型。
4. 拟合模型参数:一旦你选择了合适的模型,你需要拟合模型参数。
在MATLAB中,你可以使用"fitlm"函数来拟合线性模型,使用"fitrgp"函数来拟合高斯过程回归模型。
这些函数将返回一个拟合模型的对象。
5.模型评估:拟合模型后,你可以对模型进行评估。
MATLAB提供了一些工具来评估模型的好坏,如决定系数(R²)、均方根误差(RMSE)等。
你可以使用这些指标来判断你的模型是否满足你的需求。
6. 预测:一旦你拟合了你的模型并评估了模型的好坏,你可以使用模型来进行预测。
你可以使用"predict"函数来预测新的自变量对应的因变量。
除了上述步骤外,MATLAB还提供了一些其他的回归分析工具箱的功能,如特征选择、模型比较、交叉验证等。
你可以根据你的需求来选择适当的功能和方法。
总结起来,使用MATLAB回归分析工具箱进行回归分析的一般步骤包括数据准备、数据导入、选择模型、拟合模型参数、模型评估和预测。
用MATLAB求解回归分析
1. 对回归模型建立M文件model.m如下: function yy=model(beta0,X) a=beta0(1); b=beta0(2); c=beta0(3); d=beta0(4); e=beta0(5); f=beta0(6); x1=X(:,1); x2=X(:,2); x3=X(:,3); x4=X(:,4); x5=X(:,5); x6=X(:,6); yy=a*x1+b*x2+c*x3+d*x4+e*x5+f*x6;
例 2 观测物体降落的距离 s 与时间 t 的关系,得到数据如下表, 求 s 关于 t 的回归方程 sˆ a bt ct 2 .
t (s)
1/30
2/30
3/30
4/30
5/30
6/30
7/30
s (cm) 11.86
15.67
20.60
26.69
33.71
41.93
51.13
t (s) s (cm)
回归系数 的初值
(2)非线性回归命令:nlintool(x,y,’model’, beta0,alpha)
2、预测和预测误差估计: [Y,DELTA]=nlpredci(’model’, x,beta,r,J)
求nlinfit 或nlintool所得的回归函数在x处的预测值Y及预测值的显 著性为1-alpha的置信区间Y DELTA.
80
70
50
65
90
100 110 60
收入 1000 600 1200 500 300 400 1300 1100 1300 300
价格 5
7
6
6
8
7
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.excel与MATLAB链接:Excel:选项——加载项——COM加载项——转到——没有勾选项2. MATLAB安装目录中寻找toolbox——exlink——点击,启用宏E:\MATLAB\toolbox\exlink然后,Excel中就出现MATLAB工具(注意Excel中的数据:)3.启动matlab(1)点击start MATLAB(2)senddata to matlab ,并对变量矩阵变量进行命名(注意:选取变量为数值,不包括各变量)(data表中数据进行命名)(空间权重进行命名)(3)导入MATLAB中的两个矩阵变量就可以看见4.将elhorst和jplv7两个程序文件夹复制到MATLAB安装目录的toolbox文件夹5.设置路径:6.输入程序,得出结果T=30;N=46;W=normw(W1);y=A(:,3);x=A(:,[4,6]);xconstant=ones(N*T,1);[nobs K]=size(x);results=ols(y,[xconstant x]);vnames=strvcat('logcit','intercept','logp','logy');prt_reg(results,vnames,1);sige=results.sige*((nobs-K)/nobs);loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'*results.resid % The (robust)LM tests developed by ElhorstLMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 解释每一行分别表示:附录:静态面板空间计量经济学一、OLS静态面板编程1、普通面板编程T=30;N=46;W=normw(W1);y=A(:,3);x=A(:,[4,6]);xconstant=ones(N*T,1);[nobs K]=size(x);results=ols(y,[xconstant x]);vnames=strvcat('logcit','intercept','logp','logy');prt_reg(results,vnames,1);sige=results.sige*((nobs-K)/nobs);loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'*results.resi d% The (robust)LM tests developed by ElhorstLMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 2、空间固定OLS (spatial-fixed effects)T=30;N=46;W=normw(W1);y=A(:,3);x=A(:,[4,6]);xconstant=ones(N*T,1);[nobs K]=size(x);model=1;[ywith,xwith,meanny,meannx,meanty,meantx]=demean(y,x,N,T,mo del);results=ols(ywith,xwith);vnames=strvcat('logcit','logp','logy'); % should be changed if x is changedprt_reg(results,vnames);sfe=meanny-meannx*results.beta; % including the constant term yme = y - mean(y);et=ones(T,1);error=y-kron(et,sfe)-x*results.beta;rsqr1 = error'*error;rsqr2 = yme'*yme;FE_rsqr2 = 1.0 - rsqr1/rsqr2 % r-squared including fixed effects sige=results.sige*((nobs-K)/nobs);logliksfe=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'*results.res idLMsarsem_panel(results,W,ywith,xwith); % (Robust) LM tests3、时期固定OLS(time-period fixed effects)T=30;N=46;W=normw(W1);y=A(:,3);x=A(:,[4,6]);xconstant=ones(N*T,1);[nobs K]=size(x);model=2;[ywith,xwith,meanny,meannx,meanty,meantx]=demean(y,x,N,T,mo del);results=ols(ywith,xwith);vnames=strvcat('logcit','logp','logy'); % should be changed if x is changedprt_reg(results,vnames);tfe=meanty-meantx*results.beta; % including the constant term yme = y - mean(y);en=ones(N,1);error=y-kron(tfe,en)-x*results.beta;rsqr1 = error'*error;rsqr2 = yme'*yme;FE_rsqr2 = 1.0 - rsqr1/rsqr2 % r-squared including fixed effects sige=results.sige*((nobs-K)/nobs);logliktfe=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'*results.resi dLMsarsem_panel(results,W,ywith,xwith); % (Robust) LM tests4、空间与时间双固定模型T=30;N=46;W=normw(W1);y=A(:,3);x=A(:,[4,6]);xconstant=ones(N*T,1);[nobs K]=size(x);model=3;[ywith,xwith,meanny,meannx,meanty,meantx]=demean(y,x,N,T,mo del);results=ols(ywith,xwith);vnames=strvcat('logcit','logp','logy'); % should be changed if x is changedprt_reg(results,vnames)en=ones(N,1);et=ones(T,1);intercept=mean(y)-mean(x)*results.beta;sfe=meanny-meannx*results.beta-kron(en,intercept);tfe=meanty-meantx*results.beta-kron(et,intercept);yme = y - mean(y);ent=ones(N*T,1);error=y-kron(tfe,en)-kron(et,sfe)-x*results.beta-kron(ent,intercept); rsqr1 = error'*error;rsqr2 = yme'*yme;FE_rsqr2 = 1.0 - rsqr1/rsqr2 % r-squared including fixed effects sige=results.sige*((nobs-K)/nobs);loglikstfe=-nobs/2*log(2*pi*sige)-1/(2*sige)*results.resid'*results.re sidLMsarsem_panel(results,W,ywith,xwith); % (Robust) LM tests二、静态面板SAR模型1、无固定效应(No fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0;info.model=0;info.fe=0;results=sar_panel_FE(y,[xconstant x],W,T,info);vnames=strvcat('logcit','intercept','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model); panel_effects_sar(results,vnames,W);2、空间固定效应(Spatial fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0;info.model=1;info.fe=0;results=sar_panel_FE(y,x,W,T,info);vnames=strvcat('logcit','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sar(results,vnames,W);3、时点固定效应(Time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=2;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sar_panel_FE(y,x,W,T,info);vnames=strvcat('logcit','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sar(results,vnames,W);4、双固定效应(Spatial and time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=3;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sar_panel_FE(y,x,W,T,info);vnames=strvcat('logcit','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sar(results,vnames,W);三、静态面板SDM模型1、无固定效应(No fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0;info.model=0;info.fe=0;results=sar_panel_FE(y,[xconstant x wx],W,T,info);vnames=strvcat('logcit','intercept','logp','logy','W*logp','W*logy'); prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sdm(results,vnames,W);2、空间固定效应(Spatial fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=1;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sar_panel_FE(y,[x wx],W,T,info);vnames=strvcat('logcit','logp','logy','W*logp','W*logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);3、时点固定效应(Time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=2;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn on% New routines to calculate effects estimatesresults=sar_panel_FE(y,[x wx],W,T,info);vnames=strvcat('logcit','logp','logy','W*logp','W*logy');% Print out coefficient estimatesprt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);4、双固定效应(Spatial and time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.bc=0;info.lflag=0; % required for exact resultsinfo.model=3;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sar_panel_FE(y,[x wx],W,T,info);vnames=strvcat('logcit','logp','logy','W*logp','W*logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sdm(results,vnames,W)wald test spatial lag% Wald test for spatial Durbin model against spatial lag modelbtemp=results.parm;varcov=results.cov;Rafg=zeros(K,2*K+2);for k=1:KRafg(k,K+k)=1; % R(1,3)=0 and R(2,4)=0;endWald_spatial_lag=(Rafg*btemp)'*inv(Rafg*varcov*Rafg')*Rafg*btempprob_spatial_lag=1-chis_cdf (Wald_spatial_lag, K)wald test spatial error% Wald test spatial Durbin model against spatial error modelR=zeros(K,1);for k=1:KR(k)=btemp(2*K+1)*btemp(k)+btemp(K+k); % k changed in 1, 7/12/2010 % R(1)=btemp(5)*btemp(1)+btemp(3);% R(2)=btemp(5)*btemp(2)+btemp(4);endRafg=zeros(K,2*K+2);for k=1:KRafg(k,k) =btemp(2*K+1); % k changed in 1, 7/12/2010Rafg(k,K+k) =1;Rafg(k,2*K+1)=btemp(k);% Rafg(1,1)=btemp(5);Rafg(1,3)=1;Rafg(1,5)=btemp(1);% Rafg(2,2)=btemp(5);Rafg(2,4)=1;Rafg(2,5)=btemp(2); endWald_spatial_error=R'*inv(Rafg*varcov*Rafg')*Rprob_spatial_error=1-chis_cdf (Wald_spatial_error,K) LR test spatial lagresultssar=sar_panel_FE(y,x,W,T,info);LR_spatial_lag=-2*(resultssar.lik-results.lik)prob_spatial_lag=1-chis_cdf (LR_spatial_lag,K)LR test spatial errorresultssem=sem_panel_FE(y,x,W,T,info);LR_spatial_error=-2*(resultssem.lik-results.lik)prob_spatial_error=1-chis_cdf (LR_spatial_error,K) 5、空间随机效应与时点固定效应模型T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);[ywith,xwith,meanny,meannx,meanty,meantx]=demean(y,[x wx],N,T,2); % 2=time dummiesinfo.model=1;results=sar_panel_RE(ywith,xwith,W,T,info);prt_spnew(results,vnames,1)spat_model=1;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sdm(results,vnames,W)wald test spatial lagbtemp=results.parm(1:2*K+2);varcov=results.cov(1:2*K+2,1:2*K+2);Rafg=zeros(K,2*K+2);for k=1:KRafg(k,K+k)=1; % R(1,3)=0 and R(2,4)=0;endWald_spatial_lag=(Rafg*btemp)'*inv(Rafg*varcov*Rafg')*Rafg*btempprob_spatial_lag= 1-chis_cdf (Wald_spatial_lag, K)wald test spatial errorR=zeros(K,1);for k=1:KR(k)=btemp(2*K+1)*btemp(k)+btemp(K+k); % k changed in 1, 7/12/2010% R(1)=btemp(5)*btemp(1)+btemp(3);% R(2)=btemp(5)*btemp(2)+btemp(4);endRafg=zeros(K,2*K+2);for k=1:KRafg(k,k) =btemp(2*K+1); % k changed in 1, 7/12/2010 Rafg(k,K+k) =1;Rafg(k,2*K+1)=btemp(k);% Rafg(1,1)=btemp(5);Rafg(1,3)=1;Rafg(1,5)=btemp(1);% Rafg(2,2)=btemp(5);Rafg(2,4)=1;Rafg(2,5)=btemp(2);endWald_spatial_error=R'*inv(Rafg*varcov*Rafg')*Rprob_spatial_error= 1-chis_cdf (Wald_spatial_error,K) LR test spatial lagresultssar=sar_panel_RE(ywith,xwith(:,1:K),W,T,info);LR_spatial_lag=-2*(resultssar.lik-results.lik)prob_spatial_lag=1-chis_cdf (LR_spatial_lag,K)LR test spatial errorresultssem=sem_panel_RE(ywith,xwith(:,1:K),W,T,info);LR_spatial_error=-2*(resultssem.lik-results.lik)prob_spatial_error=1-chis_cdf (LR_spatial_error,K)四、静态面板SEM模型1、无固定效应(No fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0;info.model=0;info.fe=0;results=sem_panel_FE(y,[xconstant x],W,T,info);vnames=strvcat('logcit','intercept','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model); panel_effects_sar(results,vnames,W);2、空间固定效应(Spatial fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0;info.model=1;info.fe=0;results=sem_panel_FE(y,x,W,T,info);vnames=strvcat('logcit','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model); panel_effects_sar(results,vnames,W);3、时点固定效应(Time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=2;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sem_panel_FE(y,x,W,T,info);vnames=strvcat('logcit','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sar(results,vnames,W);4、双固定效应(Spatial and time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);xconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=3;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sem_panel_FE(y,x,W,T,info);vnames=strvcat('logcit','logp','logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=0;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sar(results,vnames,W);五、静态面板SDEM模型1、无固定效应(No fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);xconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0;info.model=0;info.fe=0;results=sem_panel_FE(y,[xconstant x wx],W,T,info);vnames=strvcat('logcit','intercept','logp','logy','W*logp','W*logy'); prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sdm(results,vnames,W);2、空间固定效应(Spatial fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=1;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sem_panel_FE(y,[x wx],W,T,info);vnames=strvcat('logcit','logp','logy','W*logp','W*logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sdm(results,vnames,W);3、时点固定效应(Time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.lflag=0; % required for exact resultsinfo.model=2;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn on% New routines to calculate effects estimatesresults=sem_panel_FE(y,[x wx],W,T,info);vnames=strvcat('logcit','logp','logy','W*logp','W*logy');% Print out coefficient estimatesprt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sdm(results,vnames,W)4、双固定效应(Spatial and time period fixed effects)T=30;N=46;W=normw(W1);y=A(:,[3]);x=A(:,[4,6]);for t=1:Tt1=(t-1)*N+1;t2=t*N;wx(t1:t2,:)=W*x(t1:t2,:);endxconstant=ones(N*T,1);[nobs K]=size(x);info.bc=0;info.lflag=0; % required for exact resultsinfo.model=3;info.fe=0; % Do not print intercept and fixed effects; use info.fe=1 to turn onresults=sem_panel_FE(y,[x wx],W,T,info);vnames=strvcat('logcit','logp','logy','W*logp','W*logy');prt_spnew(results,vnames,1)% Print out effects estimatesspat_model=1;direct_indirect_effects_estimates(results,W,spat_model);panel_effects_sdm(results,vnames,W)。