出版社资源优化配置模型
数学建模万能模型的推广

数学建模万能模型的推广Prepared on 21 November 2021十、模型的推广山于折旧费用相对总成本费用很少,折旧费用对公司经济利益的影响能力是很有限的,|11±面模型求解过程也有力地说明了这点。
因此,在实际问题中,公司在预定财务计划的时候,可以忽略掉折旧费用的计算来对计划进行估算。
同时,我们给出下面的理论证明:对于建造费用和房产的折旧费用给出如下相对保守的比较:由于房产公司它的月建造能力最少是22套,建材成本按i月份与i+2月份建房数H相同计算,即:二G+0. 5 x N: x (1 + )丿―二G+0. 5x /V; x(l + u^2)A J = (G+O. 5X 222*1. 1)-(G+O. 5X 222)=0. 1*0. 5*222△丿表示:这是△丿的最小可能值对于Z,=0. IX所有房子的损耗总月数比较△丿与乙,只有当所有房子的损耗总的月数$0.5*222,即2242时乙才相对占优。
可见△丿影响盈利的能力远大于乙。
所以这时应该适当地多考虑房地的早建设。
证明了上述论述的正确性。
即:公司在实际中可根据估算公式:L = S-G-K-X进行预算。
九、模型的推广通过对题LI的解读我们不难发现这是一类规划问题。
我们建立了一个双LI 标整数线性规划模型。
仔细分析我们建立的模型不难发现:这个模型不仅仅适用于出版社的资源配置问题,它对规划类问题的求解都可以起到指导作用。
规划问题是运筹学的一个重要分支。
它在解决工业生产组织、经济计划、组织管理人机系统中,都发挥着重要的作用。
本文模型的建立是为了解决一定量的资源分配给多部门的问题,若A部门分到的资源多,其余部门分的资源就会相对的减少。
通过资源配置最优化为杠杆平衡它们之间的分配关系。
决策者要通过概念抽象、关系分析可将各类影响因子放入规划模型中,可以通过相关的计算机软件得到兼顾全局的最优解。
本题的求解是一个典型的规划问题,我们模型的使用范圉非常广泛,涉及到投资时,有限的资金如何分配到各种投资方式上;工厂选址时,要兼顾距离原料区和服务区的路程……这一类问题均能得到较好的解决。
13068-数学建模-2006高教社杯全国大学生数学建模竞赛A题评阅要点

2006高教社杯全国大学生数学建模竞赛A题评阅要点[日期:2007-03-25] 来源:作者:[字体:大中小] 2006高教社杯全国大学生数学建模竞赛A题评阅要点[本要点仅供参考,各赛区应根据对题目的理解及学生的解答自主地进行评阅]本题考察的重点是:从决策问题的海量的、不完全的、甚至错漏(带有噪音、错误、异型)的数据中分析出决策的逻辑结构和提取有用的数据(附录中许多数据是没有用的!)以及依赖数据信息,进而构建数学模型的能力。
本题的资源优化配置模型是规划问题,其中也包括一些预测模型。
因此,理解并且实现优化问题的基础结构是取得基本分值的必要条件。
1、目标函数的构成成分主要包括销售额表达式(注意如果作者利用了附录数据说明中的假设,则赢利与销售额等价),可以以课程为单位,也可以以学科为单位;包括由市场信息产生的对于不同课程的调控因子(竞争力系数);由于数据说明中的提示,也应该包括每个课程的申报需求量的“计划准确性因子”(学生用词会不同)。
当然,前两点更重要些。
2、约束条件构成对于出版社来说,所谓产能主要是人力资源,即策划、编辑和版面设计人员的分布形成主要约束;此外,书号总量(500)也应该作为约束条件;同时,在数据说明中指出的“满足申请书号量的一半”也应该以约束方式表达。
3、规划变量可以以每个课程的书号数量,也可以以学科的书号数作为变量,但是得到的结果会有所不同。
实现以上三点,对于问题的理解是比较全面的,应该得到基本分值。
进一步提高的分值来源于实现上述三点的具体模型的考虑和建模水平。
1)如果注意到数据说明中提示的,同一课程的教材在价格和销售量的同一性,销售额表达式是比较容易表示的:构造每个课程的、用书号数表达的销售额,然后将所有书号的销售额的表达式累加,形成总社的销售额的基本表达式,这是目标函数的主体部分。
2)市场信息产生的对于不同课程的调控因子(也称竞争力系数)的表示,是一个信息不足情况下的决策模型。
配置模型

出版社的资源配置模型摘要本文讨论出版社的资源优化问题。
根据出版社的工作流程,我们将问题分为两个阶段。
第一阶段是总出版社如何将总数一定的书号分配给各分出版社;第二阶段是分出版社如何将分得的书号数分配到具体的课程上,以实现利润的最大化。
在建立模型确定第一阶段的书号分配方案时,本文侧重于体现长远发展战略和增加强势出版社支持力度的原则,为此我们引入强势的概念,并以此作为目标函数。
强势是反映各分出版社的市场占有率、满意度、市场排位等的一个综合指标。
我们首先对附件2所给数据提取市场占有率、满意度、市场排位等影响书号数分配的因素,统计出各因素历年的数据,并采用熵权法得到相应的指标权重,然后通过TOPSIS方法得到各分社在总社中的排名强势系数。
最后我们将所得到的强势系数带入目标函数,利用Lingo软件计算出各分社应分配的书号数。
为了取得更好更贴近实际的结果,我们对模型进行优化,通过引入稳定性的概念来约束分配方案中的奇异现象,最后得到更好的分配方案(表4.6)。
在第二阶段的书号分配过程中,我们以各分社利润最大化为目标又建立了一个优化模型。
这里需要解决的难点是预测当年各课程的单位书号的销售量。
通过对附件3,4的分析处理,得到各课程往年的单位书号的销售量,并以此为基础运用灰色预测的方法预测出2006年单位书号的销售量。
最后用Lingo软件包求解得到结果(表4.8与附录3)。
最后我们根据得出的结果,对出版社提出了相应的建议,给出了出版社在分配书号的过程中兼顾短期效益和长远利益时应该考虑的影响因素。
关键词:资源优化,熵权法,TOPSIS方法,灰色预测,强势值。
1 问题的重述出版社资源配置的好坏直接决定着出版社的经济效益和长远的发展战略,所以如何合理的分配出版社的资源,以达到出版社每年获得的利润最大,而且有利于出版社的长远发展,这就是本题所要解决的问题。
出版社最重要的资源就是书号,书号就包括了一个出版社的人力资源、生产资源、资金和管理资源等信息,所以对出版社资源的合理分配就是对出版社的书号进行合理的分配。
模糊数学方法在出版社资源优化配置中的应用

20 0 7年 2月
Fb O 7 e .2 o
文章 编号 :6 2— 5 X(07 0 — 0 2—0 17 0 8 20 ) 1 0 1 4
模 糊 数 学 方法 在 出版 社 资 源优 化 配置 中的应 用
金检华 , 李永 明 , 春泉 李
( 陕西师范大学 数 学与信息科学学 院, 安讯
第1 期
金检 华, :模糊数 学方 法在出版 社资源优化 配置 中的应用 等
1 3
版社 的教材估计该 出版社主要教材 的市场 占有率 、 场竞 争力等其他相关 因素。利润 与销售量 息息相 市 关, 而影响销售量的因素很多 , 主要有: 产品的市场 占有率 ( 反应市场的现有需求量) 产品单价 、 、 顾客 的满 意度 ( 反应市场对产品的潜在需求量) 。而作为决策依托 , 采集信息可靠性对其影响巨大。作为教材出版 社, 其消费群体主要是学校 , 根据数据可统计 出学校需求 占总需求 的9 %以上 。 5 然而 , 市场系统是一个动态的不稳定系统。考虑到市场信息 ( 主要是需求与竞 争力 ) 不完全 , 很难精 确地确立各因素与最终利益之间的量化关系 , 基于此类数据精确化程度低、 模糊性强的特点 , 建立模糊数 学模型 , 其基本思路为 :1 ( )提取影响书号数分类 因素的数据样本 ;2 ( )数据规范化 , 建立数据库 ;3 ( )选 择指标 因子和分类对象 ;4 ( )建立模糊相似矩阵进行聚类分析, 给出总社的一个分类 ;5 ( )对分得的各类 进行书号数分配 ;6 ( )根据算得的历年册数利用灰色预测方法预测下一年每 门课程的册数。 以下一 年 的最 大利润 为 目标 函数 , 立模 糊数 学优 化 模型 如下 : 建
=
Ⅳ
Y=I1 or s. I ∑Nc . 1 / 1  ̄ ; t
2017年全国数学建模论文

2017年全国数学建模论文数学建模是从现实问题中建立数学模型的过程.在对实际问题本质属性进行抽象提炼后,用简洁的数学符号、表达式或图形,形成便于研究的数学问题,并通过数学结论解释某些客观现象,预测发展规律,或者提供最优策略。
下文是店铺为大家搜集整理的关于2017年全国数学建模论文的内容,欢迎大家阅读参考!2017年全国数学建模论文篇1浅论数学建模中最优化方法的使用摘要:随着计算机等各项技术的发展,用数学思维解决实际问题显得越来越重要。
结合2006年全国大学生数学建模竞赛A题,本文给出了整数线性规划模型的建模过程,体现了最优化方法在数学建模中的重要作用。
并通过介绍几个简单的数学模型,加深了对最优化方法与数学建模的认识,阐述了数学建模与最优化方法之间的紧密关系,最优化方法是数学建模的本质,数学模型是最优化方法的实现方式。
关键词:最优化;数学建模;数学规划.1.引言数学建模是从实际课题中抽象、提炼出数学模型的过程。
人们常对实际事物建立种种数学模型以期通过对该模型的考察来描述、解释、预计或分析出实际事物相关的规律。
2.最优化模型典型的最优化模型可以描述成如下形式:Min{f(X)|X∈D}其中,X=(x1,x2,…xn)T表示一组决策变量,xi(i=1,…,n)通常在实数域R内取值,称决策变量的函数f(X)为该最优化模型的目标函数。
D为n维欧式空间Rn的某个子集,通常由一组关于决策变量的等式或不等式刻画,形如:Minf(X)s.t.Ci(X)≥0(i=1,2, (1)Ci(X)=0(I=m1+1,…m)这时,称模型中关于决策变量的等式或不等式Ci(X)≥0(i=1,2,…m1)、Ci(X)=0(I=m1+1,…m)为约束条件,而称满足全部约束条件的空间Rn中的点X为该模型的可行解,称即由所有可行解构成的集合为该模型的可行域。
称X*∈D为最优化模型Min{f(X)|X∈D}的(全局)最优解,若满足:对?X∈D均有f(X*)≤f(X),这时称X*∈D处的目标函数值f(X*)为最优化模型Min{f(X)|X∈D}的(全局)最优值;称X*∈D为最优化模型Min{f(X)|X∈D}的局部最优解,若存在δ>0,对?X∈D∩{X∈Rn| }均有f(X*)≤f(X)。
数学建模资源分配方案
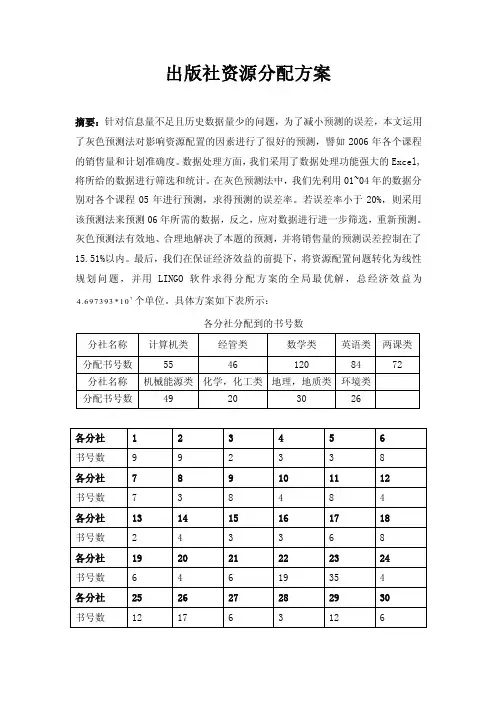
出版社资源分配方案摘要:针对信息量不足且历史数据量少的问题,为了减小预测的误差,本文运用了灰色预测法对影响资源配置的因素进行了很好的预测,譬如2006年各个课程的销售量和计划准确度。
数据处理方面,我们采用了数据处理功能强大的Excel,将所给的数据进行筛选和统计。
在灰色预测法中,我们先利用01~04年的数据分别对各个课程05年进行预测,求得预测的误差率。
若误差率小于20%,则采用该预测法来预测06年所需的数据,反之,应对数据进行进一步筛选,重新预测。
灰色预测法有效地、合理地解决了本题的预测,并将销售量的预测误差控制在了15.51%以内。
最后,我们在保证经济效益的前提下,将资源配置问题转化为线性规划问题,并用LINGO软件求得分配方案的全局最优解,总经济效益为74.697393*10个单位。
具体方案如下表所示:各分社分配到的书号数关键词:灰色预测线性规划市场竞争力计划准确度满意度一、问题的重述1.1背景知识随着党中央国务院“十一五”发展规划的提出,我国的文化产业也受到了前所未有的重视,同时,“十一五”也宣告了出版产业面临着前所未有的挑战。
“十一五”期间,出版发行业将面临因特网、手机短信、数字出版等科技发展引发的对出版环境的影响,不少出版社和发行单位已经或者正在开始着手对自身未来发展的思考和规划,这种现象本身也是出版业理性回归的一个重要标志。
对于出版发行单位而言,战略规划的最大价值在于它的过程,在于培养一种在市场经济环境中的系统思考与应变能力,而不仅仅是规划的结果。
根据加入WTO的承诺,2006年是我国出版分销行业全面放开的最后一年,深化体制改革以应对入世,正在成为出版发行行业的重中之重。
行业对竞争力的关注前所未有的重视,任何研究报告、市场调查、行业排名都会触动出版社敏感的神经。
教育出版对出版社的竞争力影响大,经营成为最主要的提高竞争力的手段,形成了相对稳定的竞争力优势。
因此,占据出版业优势地位的教材出版业更注重对市场的调查研究,对市场做出科学的评估和预测,需要的就是一种科学的调查、评估和预测方法。
基于中台理念的出版单位统一资源中心建设——以高等教育出版社为例
129传媒个案1.什么是中台中台是一种企业互联网架构,与前台、后台相对应,指系统中被共用的中间件的集合。
中台按照不同的功能和角色可分为两个重要方面:(1)业务中台,构建组件化、服务化、高内聚、低耦合、高复用的业务能力,赋能前台应用敏捷开发,实现全网业务能力共享与业务流程贯通。
(2)数据中台,聚焦于数据汇聚、数据治理、数据模型、数据服务。
2.中台在出版单位应用的背景与意义内容资源是出版单位最核心的资产,内容资源建设、管理和应用是出版单位的核心工作,是出版单位融合发展的基础。
出版单位经过多年数字化建设,积累了大量数字化资源,形成若干满足不同需求的网站、平台、应用程序等。
但出版单位数字化在取得成绩的同时,也面临一些问题,各平台独立建设,资源数据、运营数据、用户行为数据等无法有效整合和共享,功能重复建设,资产管理粗放,数据质量参差不齐,文件版本混乱,现有技术开发模式在快速响应用户需求系统迭代升级上不具竞争力。
对业务系统较多的出版单位或集团来说,利用中台整合、集聚内容资源,进行规范化、资产化、智能化管理,构建全面合理的数字资产管控及应用体系,建立起支撑各业务平台快速迭代的公共能力复用中台,是促进媒体深度融合[2]、实现高质量发展的必然要求。
3.基于中台理念的统一资源中心建设实施路径出版单位统一资源中心建设的总体目标是建设数据中台及业务中台,整合传统媒体与新兴媒体,构建数字出版、数字教育“新生态”。
系统总体设计如图1所示。
统一资源中心建设以“数据中台+业务中台”的双中台架构为基础,建设重点是“三统一五中心”。
3.1 统一什么?3.1.1统一数据标准统一资源中心的“统一”首先是统一数据标准,统一数据标准在实践中可从三个层面去落实——数据模型、元数据标准、分类标准。
3.1.1.1 数据模型对各类产品及其他数据建立数据模型,包括数据结构(必要组件、可选组件)、数据操作、人员角色、数据约束等。
教育出版领域数据模型可参考标准包括“中央文化企业数字化转型升级”项目标准《GCZX 14—2014 图书数字资源内容标引规则》、国家标准《GB∕T 36642-2018 信息技术学习、教育和培训在线课程》《GB∕T 29802-2013 信息技术学习、教育和培训测试试题信息模型》《GB∕T 36453-2018 信息技术学习、教育和培训电子课本信息模型》《GB∕T 36098-2018 信息技术学习、教育和培训虚拟实验构件封装》以及国际标准EPUB等,但这些标准还远远不够,出版单位需要在这些标准基础上修改完善并补充缺失的标准,建设企业数据标准体系。
全国数学建模大赛历年题目分析以及参赛成功方法
全国数学建模大赛历年题目分析以及参赛成功方法数学建模竞赛的赛题分析1. CUMCM历年赛题简析2. “彩票中的数学”问题3. 长江水质的评估、预测与控制问题4. 煤矿瓦斯和煤尘的监测与控制问题5. 其他几个数学建模的问题数学建模竞赛的规模越来越大,水平越来越高;竞赛的水平主要体现在赛题水平;赛题的水平主要体现:(1)综合性、实用性、创新性、即时性等;(2)多种解题方法的创造性、灵活性、开放性等;(3)海量数据的复杂性、数学模型的多样性、求解结果的不唯一性等。
纵览16年的本科组32个题目(专科组13个),从问题的实际意义、解决问题的方法和题型三个方面作一些简单的分析。
一、CUMCM历年赛题的简析1. CUMCM 的历年赛题浏览:1992年:(A)作物生长的施肥效果问题(北理工:叶其孝)(B)化学试验室的实验数据分解问题(复旦:谭永基)1993年:(A)通讯中非线性交调的频率设计问题(北大:谢衷洁)(B)足球甲级联赛排名问题(清华:蔡大用)1994年:(A)山区修建公路的设计造价问题(西电大:何大可)(B)锁具的制造、销售和装箱问题(复旦:谭永基等)1995年:(A)飞机的安全飞行管理调度问题(复旦:谭永基等)(B)天车与冶炼炉的作业调度问题(浙大:刘祥官等)一、CUMCM历年赛题的简析1. CUMCM 的历年赛题浏览:1996年:(A)最优捕鱼策略问题(北师大:刘来福)(B)节水洗衣机的程序设计问题(重大:付鹂)1997年:(A)零件参数优化设计问题(清华:姜启源)(B)金刚石截断切割问题(复旦:谭永基等)1998年:(A)投资的收益和风险问题(浙大:陈淑平)(B)灾情的巡视路线问题(上海海运学院:丁颂康)1999年:(A)自动化机床控制管理问题(北大:孙山泽)(B)地质堪探钻井布局问题(郑州大学:林诒勋)(C)煤矸石堆积问题(太原理工大学:贾晓峰)一、CUMCM历年赛题的简析1.CUMCM 的历年赛题浏览:2000年:(A)DNA序列的分类问题(北工大:孟大志)(B)钢管的订购和运输问题(武大:费甫生)(C)飞越北极问题(复旦:谭永基)(D)空洞探测问题(东北电力学院:关信)2001年:(A)三维血管的重建问题(浙大:汪国昭)(B)公交车的优化调度问题(清华:谭泽光)(C)基金使用计划问题(东南大学:陈恩水)2002年:(A)汽车车灯的优化设计问题(复旦:谭永基等)(B)彩票中的数学问题(信息工程大学:韩中庚)(D) 球队的赛程安排问题(清华大学:姜启源)一、CUMCM历年赛题的简析1.CUMCM 的历年赛题浏览2003年:(A)SARS的传播问题(集体)(B)露天矿生产的车辆安排问题(吉林大:方沛辰)(D)抢渡长江问题(华中农大:殷建肃)2004年:(A)奥运会临时超市网点设计问题(北工大:孟大志)(B)电力市场的输电阻塞管理问题(浙大:刘康生)(C)酒后开车问题(清华大学:姜启源)(D)公务员的招聘问题(信息工程大学:韩中庚)2005年:(A)长江水质的评价与预测问题(信息工大:韩中庚)(B)DVD在线租赁问题(清华大学:谢金星等)(C) 雨量预报方法的评价问题(复旦:谭永基)一、CUMCM历年赛题的简析1.CUMCM 的历年赛题浏览2006年:(A)出版社的资源管理问题(北工大:孟大志)(B)艾滋病疗法的评价及预测问题(天大:边馥萍)(C)易拉罐形状和尺寸的设计问题(北理工:叶其孝)(D)煤矿瓦斯和煤尘的监测与控制问题(信息工程大学:韩中庚)2007年:(A)中国人口增长预测问题(清华大学:唐云)(B)“乘公交,看奥运”问题(吉大:方沛辰,国防科大:吴孟达)(C)“手机套餐”优惠几何问题(信息工程大学:韩中庚)(D)体能测试时间的安排问题(首都师大:刘雨林)一、CUMCM历年赛题的简析一、CUMCM历年赛题的简析1.CUMCM 的历年赛题浏览2001年夏令营三个题:(A)三峡工程高坡开挖优化设计(三峡大学:李建林等)(B)城市交通拥阻的分析与治理(北京理工大学:叶其孝)(C)乳房癌的诊断问题(复旦大学:谭永基)2006年夏令营三个题:(A)教材出版业的市场调查、评估和预测方法问题(北工大:孟大志)(B)铁路大提速下的京沪线列车调度问题(信息工程大学:韩中庚)(C)旅游需求的预测预报问题(北京理工:叶其孝)2、从问题的实际意义分析32个问题从实际意义分析大体上可分为:工业、农业、工程设计、交通运输、经济管理、生物医学和社会事业等七个大类。
优化模型举例
一单位实物 行走时间(分钟) 捕获时间(分钟) 热量(焦耳)
X
2
2
25
Y
3
1
30
假设捕食者每天能得到 x 单位的食物 X 和
y 单位的食物 Y ,则每天获得的热量值为
max u 25x 30 y 2x 3y 120
s.t 2x y 80 x 0, y 0.
2020/7/1
2020/7/1
收点
发点
B1
B2
…. Bn
A1X11 X12….. X1na1
A2
X21 X22
…. X2n
a2
….. …..
Am
Xm1
Xm2 ….. Xmn
am
b1 b2
….
bn
2020/7/1
A1的总费用
A1 ~ B j
n
C11x11 C12 x12 ... C1n x1n C1 j x1 j j 1
2020/7/1
03年B题:“露天矿生产的车辆安排”,非线性 规划模型。 04年B题:“电力市场的输电阻塞管理”,双目
标线性规划模型。 05年B题:“DVD在现租赁”,0-1规划模型。 06年A题:“出版社的资源优化配置”,线性规 划模型。
2020/7/1
(一)优化模型的数学描述
将一个优化问题用数学式子来描述,即求函数
2.根据设计变量的性质 静态问题和动态问题。
3.根据目标函数和约束条件表达式的性质 线性规划,非线性规划,二次规划,多目标规划等。
2020/7/1
(1)非线性规划
目标函数和约束条件中,至少有一个非线性函数。
min u f (x) x
s. t. hi ( x) 0,i 1,2,..., m. gi ( x) 0(gi ( x) 0), i 1,2,..., p.
优化书号资源配置方案
摘要该问题属于多因素的决策问题,本文首先进行数据预处理,利用层次分析法得到每门课程出版社的满意度,出版社的排位指标,强势产品的指标,教材获得方式指标,课程类型指标。
利用统计方法得到销售量的增长率、计划申请书的平均准确度、每门课程市场占有率;其次用出版社的满意度、出版社的排位指标、销售量的增长率和市场占有率提炼出该课程的竞争力,用市场占有率推导出市场需求;再者以支持强势产品的原则,同时考虑市场长远发展规划,建立了增加经济效益为目的的单目标整数规划模型;最后,利用LINGO软件得到书号的分配方案(见表20),计算出出版社的总收益为7。
在模型推广中,在一2.019593310定的条件下给出了其它的分配方法。
本文的优点为充分利用数据,提出多种量化指标,提炼出竞争力指标和市场需求。
不足之处是长远发展战略考虑不够细致。
关键词: 单目标整数规划竞争力分配方案优化配置书号资源方案一、问题的重述:出版社的资源都捆绑在书号上,经过各个部门的运作,形成成本和利润。
某个以教材类出版物为主的出版社,总社领导每年需要针对分社提交的生产计划申请书、人力资源情况以及市场信息分析,将总量一定的书号数合理地分配给各个分社,使出版的教材产生最好的经济效益。
事实上,由于各个分社提交的需求书号总量远大于总社的书号总量,因此总社一般以增加强势产品支持力度的原则优化资源配置。
资源配置完成后,各个分社(分社以学科划分)根据分配到的书号数量,再重新对学科所属每个课程作出出版计划,付诸实施。
资源配置是总社每年进行的重要决策,直接关系到出版社的当年经济效益和长远发展战略。
我们要解决的问题就是根据该出版社掌握的一些数据资料,利用数学建模的方法,在信息不足的条件下,提出以量化分析为基础的资源(书号)配置方法,给出一个明确的分配方案,向出版社提供有益的建议。
二、问题的假设1.假设同一课程不同书目价格差别不大,同时销售量相近。
2.假设所有教材利润率同一。
3.假设市场上每年的书号数一定。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
出版社资源优化配置的数学模型摘要本文通过对出版社提供的调查问卷等数据进行分析,建立相应的数学模型,以增加强势产品支持力度等为原则对出版社的书号资源进行优化配置。
首先我们对所提供的问卷调查数据进行了分析,分别给出了该出版社各门学科所出版的书籍在所有书籍中所占的比率、调查数据中各学科书籍在所有书籍中的比例、该出版社在调查者心目中的排名情况、每年新书、旧书的比率、调查者获得教材的方式和被访者对该出版社与其他出版社主观评价平均得分的比较等,对该出版社目前在市场中的地位,市场状况等基本情况有一个基本的了解。
为了使出版社06年的效益最大化,本文主要考虑以下三个方面。
一、如何对效益进行量化二、强势产品的确定三、如何体现对强势产品的支持本文在确定效益的量化标准后,在书号总量,人力资源量,申请成功率,强势产品优先等约束条件下运用线性规划使效益达到最大。
效益的量化方面,我们利用历年各学科书籍销量与价格均值计算出该学科的收入,再除以其总的书号数得到各学科历年每个书号的平均价值,通过灰色预测模型GM(1,1)预测2006年各分社每个书号的平均价值。
这样以各分社书号分配量为变量,可以得到效益最大化的目标函数。
强势产品的确定方面,我们考虑了该社各学科在市场中的占有率,以及各学科书目在整个市场的比例两个因素。
通过累计重要度法,确定两个指标的权数,计算出各学科的重要度。
然后以重要度对个学科排序,确定重要度高者工作能力满足率(即分配书号数/最大工作能力)亦高的约束条件。
最后通过SPSS的聚类分析功能将学科进行分类,给出各学科强势水平的等级。
线性规划的约束条件有以下几项:书号总数一定;得到书号数不能大于最大工作能力;为保持工作连续性和对各分社计划一定程度上的认可,出版社在分配书号时至少保证分给各分社申请数量的一半;申请成功率变化不超过历年均值的 三倍标准差;重要度高者书号工作能力满足率亦高。
在上述约束下由线性规划得到出版社06年书号的最优分配。
分配方案为:计算机类68,经管类42,数学类120,英语类102,两课类55,机械能源类36,化学、化工类18,地理、地质类30,环境类29。
最优方案下的最大效益为0.2142579E+08。
数据分析发现历年各分社每一课程书号所占比例基本保持稳定,因此我们以此为依据再对各分社的书号进行分配。
关键字:灰色预测模型累计重要度法线性规划根据该出版社提供的数据,针对分社提交的生产计划申请书、人力资源情况以及市场调查数据分析,将总量一定的书号数以增加强势产品支持力度的原则优化资源配置。
资源配置完成后,各个分社根据分配到的书号数量,再重新对学科所属每个课程作出出版计划,付诸实施使出版的教材产生最好的经济效益和良好的长远发展。
二、基本假设1、假设抽样调查为随机抽样,即样本数据具有代表性2、假设“实际销售量”为当年实际销售的数量,即每年出版书籍全部卖完3、根据表4.7,各分社历年申请成功率基本保持稳定,不妨假设申请成功率变化不超过历年均值的±三倍标准差三、符号说明x1 计算机类的书号数x2 经管类的书号数x3 数学类的书号数x4 英语类的书号数x5 两课类的书号数x6 机械能源类的书号数x7 化学、化工类的书号数x8 地理、地质类的书号数x9 环境类的书号数α第i个指标的客观权重iε第i个指标序列与特征序列的关联度i0C 方差比P 误差概率Z重要度i数据分析4.1从调查数据中算出01-05年该出版社各门学科所出版的书籍在所有书籍中所占的比率(采用该出版社书籍的人数数/全部调查人数)图4.1从线型图我们可以看出地理、地质类,环境类这两门学科在市场中的占有率较高4.2调查数据中各学科书籍在所有书籍中的比例(该学科书籍数/书籍总数)从表中可看出各学科在所有书籍中的分额保持稳定4.3 该出版社在调查者心目中的排名从表中可看出该出版社在读者中地位较高,且比较稳定4.4 每年新书、旧书使用情况从表中可看出读者中使用新书者占了绝大多数,且新旧书所占比例稳定,没有出现旧书使用率提高等情况。
4.5 受访者获得教材的方式表4.5显示受访者获得教材方式稳定,决大多数受访者通过教材科发书获得教材4.6受访者对该出版社与其他出版社出版书籍主观评价平均得分的比较表4.6显示,受访者对该出版社各科书籍评价与其他出版社书籍相当,A出版社在教材质量上没有明显优势4.7各分社申请成功率(实际销售量/计划销售量)表4.7 各分社历年申请成功率表4.7显示各分社历年申请成功率基本保持稳定,为避免分配时出现部分分社申请成功率过高,部分过低的情况发生。
我们假设06年申请成功率不超过历年均值的 三倍标准差。
五、模型建立和求解5.1书号价值的计算根据各门课程每年的销售量及其均价可以算出该课程的价值,求和得到每年各学科的价值,再除以各学科当年书号个数,即得各学科当年每个书号的平均价值。
公式表示如下:⨯∑∑学科内各课程学科内各课程课程实际销售量课程均价书号个数 通过EXCEL 计算如下表5.2灰色预测的概念(1)灰色系统、白色系统和黑色系统白色系统是指一个系统的内部特征是完全已知的,即系统的信息是完全充分的。
黑色系统是指一个系统的内部信息对外界来说是一无所知的,只能通过它与外界的联系来加以观测研究。
灰色系统内的一部分信息是已知的,另一部分信息是未知 的,系统内各因素间有不确定的关系。
(2)灰色预测法灰色预测法是一种对含有不确定因素的系统进行预测的方法。
灰色预测是对既含有已知信息又含有不确定信息的系统进行预则,就是对在一定范围内变化的、与时间有关的灰色过程进行预测。
灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。
灰色预测法用等时距观测到的反映预测对象特征的一系列数量值构造灰色预测模型,预测未来某一时刻的特征量,或达到某一特征量的时间。
灰色预测模型GM(1,1)是进行定量预测的一种方法,其应用范围广,预测精度高。
我们用灰色模型GM(1,1)预测06年各分社每个书号平均价值。
5.3 灰色预测模型GM (1,1)的原理根据研究的要求,收集需要预测的变量在连续若干个时间内的观测值,按其出现时间的先后次序排列而成时间序列:(0)000[(1),(2),,()]x x x x n =。
对(0)x 作累加生成,得到新的数列(1)(0)1()(),1,2,,.im x i x m i n ===∑为参数估计对数列(1)x ,可建立预测模型的白化形式方程(1)(1)(1)dx x dt αμ+=式中,αμ为待估参数,分别为发展灰数和内生控制灰数.设待估参数向量u αμ⎡⎤=⎢⎥⎣⎦, 按最小二乘法求得1()T T n u B B B y -=,式中(1)(1)(1)(1)(1)(1)1((1)(2)121((2)(3)1(2)21((1)()12x x x x B x n x n ⎡⎤-+⎢⎥⎢⎥⎢⎥-+⎢⎥=⎢⎥⎢⎥⎢⎥--+⎢⎥⎣⎦(0)(0)(0)[(2),(3),,()](3)n y x x x n =将u 代入(1)式,并解微分方程,可确定GM(1,1)预测模型为(1)(0)(1)(1)(4)i x i x e μμμαα-⎛⎫+=-+ ⎪⎝⎭对结果的检验(1)残差检验:残差检验分绝对误差和相对误差.通过检验判断误差变动是否平稳或均匀.绝对误差ε的计算公式为:(0)(0)(0)()()()(1,2,,)i x i x i i n ε=-=相对误差M 的计算公式为:(0)(0)(0)()()()100%(1,2,,)()i Mi i n x i ε=⨯=(2)关联度检验:计算原始数列(0)x 与其模型计算值(0)x 绝对误差的最小差和最大差:(0)(0)(0)(0)min{|()()|},max{|()()|}x i x i x i x i -- 计算关联系数W(i)(第i 个数据的关联系数):(0)(0)(0)(0)(0)(0)(0)(0)min{|()()|}max{|()()|}()(1,2,,)|()()|max{|()()|}x i x i p x i x i W i i n x i x i p x i x i -+-==-+-式中p 为取定的最大差百分比,一般取50%,即p =0.5.(3)后验差检验:计算原始数列(0)x 的均方差(0)S :0(5)S = 式中,(0)2(0)201(())n i S x i x ==-∑,(0)x 为(0)x 数列的平均值,即(0)(0)11()n i x x i n ==∑ 计算残差ε的均方差1S :1(6)S =式中,(0)(0)2(0)211(()),n i S i εεε==-∑为残差ε的平均值,即(0)(0)11()(7)n i i n εε==∑计算方差比C : 10(8)S C S =计算小误差概率P :(0)(0)0{|()|0.6745(9)P i S εε=-<最后根据P 、C 值检验预测精度.表5.2 预测精度等级划分表5.4 06年各分社每个书号平均价值的预测将以上算法通过MATLAB 程序实现[附件grey.m],可得到06年各分社每个书号平均价值的预测值,见下表:对结果的检验这里以计算机类为例,对结果进行检验。
(1) 残差检验表(2) 关联度检验绝对误差的最小差为 min {Δ(i)}=0绝对误差的最大差为max {Δ(i)}=382.03最大差百分比p ,取50%,即p =0.5.可计算得如下关联系数表:关联度1()(10.7382+0.4308+0.3333+0.7130)0.8038151i i n ξξ===⨯+=--∑(3) 后验差检验实际价值的均值为5185.29,均方差01533.09S =残差的均值为24.09,均方差1233.06S =方差比10233.060.15201533.09S C S ===最小误差概率(0)(0)(0)(0)(0)(0)0{|()|0.6745}{|()|0.67451533.09}={|()|1034.07}=1P i S i i εεεεεε=-<⨯=-<⨯-<(因为(0)(0)max |()|357.941034.07i ε-=<即全部的(0)(0)|()|1034.07i ε-<,因此P=1。
)根据预测精度等级划分表,P>0.95,C<0.35,预测效果很好。
综合以上三类检验方法,可见用灰色模型GM(1,1)预测06年计算机类每个书号平均价值,效果很好,同样的方法对其他预测值进行检验,效果都很好。