学习显示高动态范围的图像
图像编码中的动态范围调整技术研究(三)

在图像编码技术中,动态范围调整是一项重要的研究领域。
它涉及到对图像的亮度和对比度进行调整,以便在不同的显示设备上达到最佳的显示效果。
一、图像动态范围的定义和作用动态范围是指图像中最亮和最暗部分之间的亮度差异。
在拍摄和显示图像的过程中,由于光照条件和摄像设备的限制,图像的动态范围常常会超出显示设备的范围,导致图像无法完整地显示出所有细节。
动态范围的调整可以提高图像的视觉效果,使得图像在各种显示设备上都能够准确传达出拍摄者的意图。
在摄影领域,摄影师经常使用HDR(High Dynamic Range)技术来拍摄高动态范围的照片,并通过后期处理将其转换为标准动态范围的图像。
二、动态范围调整的方法1. 色调映射色调映射是一种常用的动态范围调整方法。
它通过改变图像的亮度和对比度来调整图像的动态范围。
色调映射可以分为全局映射和局部映射两种。
全局映射是指将图像的整个动态范围按比例缩放,使得最亮部分变为最大亮度,最暗部分变为最小亮度。
这种方法简单直观,但往往无法处理复杂的光照条件和细节。
局部映射是指对图像的不同区域进行不同的亮度和对比度调整。
它可以根据图像的特征和需求,有选择性地调整图像的动态范围。
局部映射可以通过阈值分割、曲线调整等技术实现。
2. 色彩空间转换色彩空间转换是另一种常用的动态范围调整方法。
它通过将图像从RGB色彩空间转换到其他色彩空间,再进行调整后再转换回RGB色彩空间,以改变图像的亮度和对比度。
常用的色彩空间转换方法包括YUV、YCbCr、Lab等。
这些色彩空间通常将亮度分量和色度分量分开处理,可以更加灵活地调整图像的动态范围。
例如,可以通过调整亮度分量来改变图像的明暗程度,通过调整色度分量来改变图像的饱和度。
三、动态范围调整的应用领域动态范围调整技术在许多领域得到广泛应用。
1. 摄影领域在摄影领域,动态范围调整可以使得照片更加真实和生动。
通过HDR技术,摄影师可以拍摄到具有更高动态范围的照片,并通过后期处理将其转换为标准动态范围的图像。
图像编码中的高动态范围处理技巧(四)

图像编码中的高动态范围处理技巧随着数字摄影技术的不断发展,越来越多的摄影师和摄影爱好者开始使用高动态范围(High Dynamic Range,简称HDR)技术来捕捉图像。
HDR技术能够在一幅图像中同时保留高亮部分和暗部的细节,使得照片更加真实,更好地还原实景。
然而,在图像编码中,由于HDR图像的数据量巨大,如何高效地处理和编码HDR图像成为了一个值得探讨的问题。
本文将就图像编码中的高动态范围处理技巧进行深入论述。
1. 动态范围压缩技术为了更好地适应亮度范围广泛的HDR图像,我们需要将其动态范围压缩到合适的范围内。
传统的算法中,常使用的动态范围压缩方法有Tone Mapping和Gamma校正。
Tone Mapping是一种将高动态范围图像编码为低动态范围图像的技术。
它通过改变图像的亮度曲线和颜色映射方式,将亮度范围较宽的高动态范围图像映射到较窄的低动态范围图像。
这样做可以减小HDR 图像的数据量,并且保持照片的美感。
常用的Tone Mapping算法有Reinhard、Mantiuk等。
Gamma校正是一种将线性的输入图像映射为非线性的输出图像的技术。
人眼对亮度的感知是非线性的,而相机捕捉到的图像数据是线性变化的。
通过应用Gamma校正,可以使得图像在显示设备上显示出符合人眼感知的亮度。
常见的Gamma校正值有和。
2. 图像压缩算法在图像编码中,压缩是必不可少的环节。
对于HDR图像,由于其数据量巨大,传统的编码算法往往无法满足要求。
因此,我们需要将HDR图像进行压缩,以减小数据量,并且保持图像质量。
无损压缩算法在图像编码中得到了广泛的应用。
JPEG2000是一种常见的无损压缩算法,它在保持图像质量的前提下可将图像的数据量压缩到很小。
对于HDR图像的编码,可以使用基于JPEG2000的无损压缩算法来实现。
此外,还有一种常见的压缩算法是有损压缩算法。
有损压缩算法通过牺牲图像的一些细节来达到更小的数据量。
【计算机应用】_高动态范围图像_期刊发文热词逐年推荐_20140726
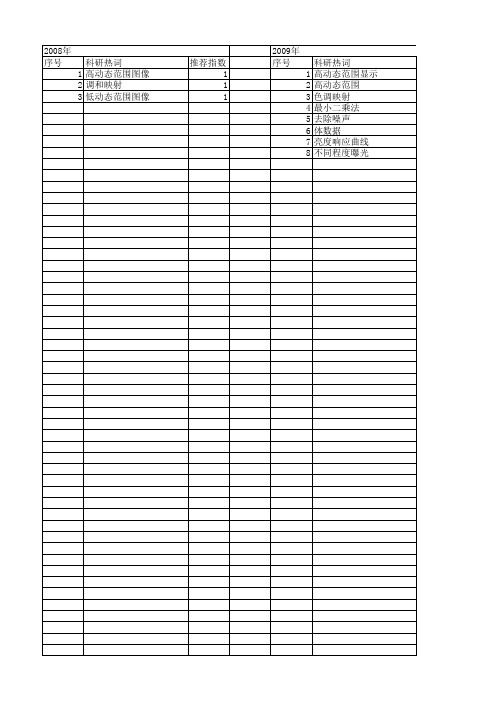
2013年 科研热词 高动态范围 图像处理 高动态范围图像 高低光 边缘保持滤波 视屏流 色阶映射 自适应retinex 算子 相机阵列 灰度范围 图像配准 图像增强 动态光照 光场合成孔径 二重曝光 推荐指数 3 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
科研热词 高动态范围图像 高斯混合模型 高动态范围 阶调映射 色阶映射 色调映射 自然度 细节调整 期望最大 映射函数 局部边缘保留滤波器 多尺度分解 双边滤波 动态系数 分层模型 retinex
推荐指数 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号
科研热词 1 高动态图像 2 色调映射算子 3 最新进展
推荐指数 1 1 1
2012年 序号 1 2 3 4 5
科研热词 高动态范围图像 非线性滤波器 局部极值 图像分解 保留边界
推荐指数 1 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
2008年 序号
科研热词 1 高动态范围图像 2 调和映射 3 低动态09年 序号 1 2 3 4 5 6 7 8
科研热词 高动态范围显示 高动态范围 色调映射 最小二乘法 去除噪声 体数据 亮度响应曲线 不同程度曝光
推荐指数 1 1 1 1 1 1 1 1
HDR(高动态范围图片)
HDR 是英⽂ High-Dynamic Range 的缩写,中⽂译名为⾼动态光照渲染。
HDR 可以令3D 画⾯更像真,就像⼈的眼睛在游戏现场中。
在HDR 的帮助下,我们可以使⽤超出普通范围的颜⾊值,因⽽能渲染出更加真实的3D 场景。
HDR (⾼动态范围图⽚)HDR百科名⽚⽬录数字图像处理中的HDR国内的HDR 软件HDR 特效展开编辑本段数字图像处理中的HDR简介 HDR 的全称是High Dynamic Range,即⾼动态范围,⽐如所谓的⾼动态范围图象(HDRI )或者⾼动态范围渲染(HDRR )。
动态范围是指信号最⾼和最低值的相对⽐值。
⽬前的16位整型格式使⽤从“0”(⿊)到“1”(⽩)的颜⾊值,但是不允许所谓的“过范围”值,⽐如说⾦属表⾯⽐⽩⾊还要⽩的⾼光处的颜⾊值。
在HDR 的帮助下,我们可以使⽤超出普通范围的颜⾊值,因⽽能渲染出更加真实的3D 场景。
也许我们都有过这样的体验:开车经过⼀条⿊暗的隧道,⽽出⼝是耀眼的阳光,由于亮度的巨⼤反差,我们可能会突然眼前⼀⽚⽩光看不清周围的东西了,HDR 在这样的场景就能⼤展⾝⼿了。
下⾯是由OpenEXR ⽹站提供的HDR 的⼀个简单例⼦。
OpenEXR 是由⼯业光魔(Industrial Light & Magic )开发的⼀种HDR 标准。
⼯业光魔则是⼀家世界闻名的加州⼯作室,该⼯作室创造过许多惊⼈的CG 和视觉效果,⽐如1977年版的电影《星球⼤战》中的很多特效。
最左边的是原始图⽚,树⽊⾮常暗因为整体曝光受到远处⾼亮光的影响;中间图⽚的亮度提⾼了3级;⽽右边图⽚的亮度提⾼了7级,树⽊的细节很容易辨别,⽽背景极度明亮。
总之简单来说,HDR 可以⽤3句话来概括: 1.亮的地⽅可以⾮常亮 2.暗的地⽅可以⾮常暗 3.亮暗部的细节都很明显 HDR 是⽬前追求画⾯逼真度最新最先进的⼿段。
Crytek 已经准备把它加⼊Far Cry 的1.3补丁中,以及EPIC Games 的史诗⼤作Unreal Tournament 3。
了解电脑显示器的高动态范围(HDR)技术

了解电脑显示器的高动态范围(HDR)技术在当今数字化时代,电脑显示器在人们的生活和工作中起到了至关重要的作用。
不仅作为我们与电脑交互的窗口,同时也是我们欣赏照片、观看电影和玩游戏的媒介。
然而,随着科技的不断发展,我们对显示器的要求也越来越高。
高动态范围(HDR)技术应运而生,为我们带来了更为逼真和令人陶醉的视觉体验。
一、什么是高动态范围(HDR)技术?高动态范围(HDR)技术是一种提高显示器图像的亮度、对比度和色彩饱和度的技术。
传统的显示器技术在展现图像时有限的动态范围会导致画面细节不够清晰,并且在亮度和暗度的表现上有局限性。
而有了HDR技术之后,显示器能够呈现更广泛的动态范围,让画面的亮度和色彩更加逼真、生动。
二、HDR技术的工作原理HDR技术的核心是对图像信号进行编码和解码,以展现更广阔的动态范围。
当一个支持HDR的显示器接收到一个HDR格式的图像信号时,它会将信号解码后再进行渲染,以确保色彩的准确再现和更高的亮度对比度。
HDR技术通常使用扩展的色彩空间和高位深度来存储和处理图像信息,从而提供更多细节和更真实的色彩。
三、HDR技术的优势和应用1. 提供更真实的色彩和亮度对比度:HDR技术通过提高亮度和对比度,能够呈现更真实的色彩和更丰富的细节,让画面更加逼真。
2. 改善暗部和亮部细节:HDR技术能够准确地展示照片或视频中的暗部和亮部细节,使得观看者能够更清晰地辨认出细微差别。
3. 提升观影和游戏体验:有了HDR技术,观看电影和玩电子游戏将更加震撼人心。
细节更加清晰,色彩更加鲜艳,让人仿佛身临其境。
4. 专业图像处理和设计应用:对于从事图像处理和设计的专业人士来说,HDR技术能够准确地显示和编辑图像,提供更好的工作环境。
四、如何享受HDR技术的乐趣?要享受HDR技术带来的视觉盛宴,首先需要准备一个支持HDR的显示器。
确保显示器与操作系统和软件的兼容性,以便正常使用HDR功能。
同时,可以通过调整显示器设置来优化HDR效果,以适应不同的观看环境和个人喜好。
一种高动态范围图像可视化算法

李 晓光 ,沈兰荪 ,林健文
(. 1 北京 工业 大学 信 号与信 息处理研 究室 , 北京 102 ;2 香 港理 工 大学 电子 工程 及 资讯 学 系 多媒 体 中心 , 00 2 .
香港 )
摘
要 :提 出的 自 应 H R图像 可视 化 算法 中, 入 图像被 分 解 为基 本层 和 细 节层 。该 算 法将 整 体 明暗 效 果 适 D 输
维普资讯
第2 4卷 第 1 1期
20 0 7年 1 1月
计 算 机 应 用 研 究
Ap l a i n Re e r h o mp t r p i to s a c fCo u e s c
Vo. 4 No 1 12 ." 1
No .2 o v o 7
vs aiain ag r h wa e e s r h n d s ly n i l z t oi m sn c sa y w e ipa i g HDR g so h tn a d o t u e ie . n v l lo t m a e n u o l t i e n t e sa d r u p td v c s A o e g r h b s d o ma a i s aila d s t t a no ma in w sp o o e rte d s ly o p t n t i il i fr t a rp s d f ip a f a a sc o o h HDR g s T ea g rtm o l e i ep o lmso ・ i ma e . h o h c u d d a w t t r be f l i l hh O v r l i r si n p e e v t n a d v s a e al r p o u t n h a e of ew e h s w s e o l e a h e e a- e a mp e so rs r ai i l d ti r d ci .T e t d . f b t e n t e e t o i u sc u d b c iv d ab l o n u se o r s l a c h o g h d p iee h n e n fd ti .E p r n a e u t s o h u e o e o a c f h p ra h i r s n e tr u h t e a a t n a c me to ea l v s x e me tl s ls h w t e s p r r r r n eo e a p o c nt m i r i pfm t e o iu u l y f sa q ai . v l t
如何处理高动态范围的场景

如何处理高动态范围的场景拍摄一副照片,如何从一幅静态的图像中传达出动态的感觉?如何捕捉到高动态范围的场景,让每一个细节都清晰可见?本文将为您详细介绍如何处理高动态范围(HighDynamicRange,简称HDR)的场景。
什么是高动态范围?高动态范围指的是相机或摄影所能捕捉到的光线范围之宽度。
在现实生活中,我们会经常遇到一些明暗对比很大的场景,比如夜晚的城市灯光与黑暗的天空,或者是室内明亮的光线与窗外的阳光。
这些场景的亮度差异很大,如果只使用普通的相机拍摄,很难同时捕捉到细节丰富的亮部和暗部。
如何处理高动态范围的场景?处理高动态范围的场景有多种方法,下面将为您介绍一些常用的技巧。
1.使用HDR模式拍摄现在的相机大多都内置了HDR模式,通过拍摄多张不同曝光度的照片,然后将它们合成成一张照片。
使用HDR模式可以更好地捕捉到高亮和低亮区域的细节,使得整个场景看起来更加平衡。
2.后期处理如果您使用的相机没有HDR模式,或者想要更好地控制照片的效果,那么后期处理是一个不错的选择。
现在市面上有很多专业的图像处理软件,比如AdobeLightroom和Photoshop等,它们提供了丰富的功能,可以帮助您调整照片的亮度、对比度和色彩等参数。
在后期处理中,可以使用曝光融合、色调映射和阴影/高光恢复等技术,将暗部和亮部的细节都呈现出来。
还可以通过调整饱和度和色彩平衡等参数,使得照片更加生动和自然。
3.使用滤镜除了HDR模式和后期处理,还可以使用滤镜来处理高动态范围的场景。
滤镜可以降低亮度,增加对比度,使得暗部和亮部都能够得到适当的展示。
常用的滤镜包括中灰滤镜和渐变灰滤镜等,它们可以帮助您在拍摄时就达到更好的动态范围。
处理高动态范围的场景需要一定的技巧和方法,无论是使用相机的HDR模式,还是通过后期处理或滤镜来调整照片,都可以让您的照片更加生动和细腻。
希望本文对您有所启发,让您在拍摄高动态范围的场景时能够做出更好的作品。
学习Photoshop中的高动态范围和HDR照片合成方法

学习Photoshop中的高动态范围和HDR照片合成方法高动态范围(High Dynamic Range,简称HDR)照片合成是一种将不同曝光度的多张照片合成为一张高质量照片的技术。
这种技术可以帮助摄影师捕捉到更大范围的亮度和色彩细节,从而创造出更加真实而丰富的图像效果。
在本篇教程中,我将向大家介绍使用PhotoShop软件进行HDR照片合成的方法和技巧。
首先,我们需要准备多张不同曝光度的照片。
这些照片应该覆盖到您想要呈现的整个亮度范围。
通常情况下,从一个过曝光的照片到一个欠曝光的照片应该有至少3-5个不同的曝光度级别。
您可以使用相机的曝光补偿功能来拍摄这些照片,或者使用不同快门速度拍摄同一场景。
确保在拍摄期间相机位置、对焦和白平衡等参数保持一致。
接下来,我们将打开PhotoShop软件并导入这些照片。
在PhotoShop主界面上,单击“文件”菜单,然后选择“脚本”和“图像处理器”选项。
在“图像处理器”对话框中,单击右上角的“浏览”按钮,选择您准备好的HDR照片。
确保选中“打开图像”复选框,这将帮助您在处理照片时自动打开它们。
然后单击“OK”按钮。
在接下来的对话框中,您可以选择处理照片的输出设置。
在“处理操作”下拉菜单中,选择“合并到HDR Pro”。
然后,您可以选择合适的色彩空间和位深度。
对于大多数普通照片,选择“ProPhoto RGB”色彩空间以及16位的位深度会给予您足够的灵活性。
单击“OK”按钮后,HDR Pro对话框将打开。
在此对话框中,您可以调整HDR照片的各种设置。
您可以尝试调整“曝光”、“恢复高光”、“恢复阴影”和“饱和度”等选项,以获得最佳的图像效果。
还可以使用“干扰消除”选项来减少图像中的噪点。
完成设置后,单击“OK”按钮,PhotoShop将会合成HDR照片,并将其显示在主界面上。
接下来,您可以对合成后的HDR照片进行进一步的调整和编辑。
例如,您可以使用曲线工具来调整图像的亮度和对比度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Pattern Recognition 40(2007)2641–2655/locate/prLearning to display high dynamic range imagesGuoping Qiu a ,∗,Jiang Duan a ,Graham D.Finlayson ba School of Computer Science,The University of Nottingham,Jubilee Campus,Nottingham NG81BB,UKb School of Computing Science,The University of East Anglia,UKReceived 27September 2005;received in revised form 10April 2006;accepted 14February 2007AbstractIn this paper,we present a learning-based image processing technique.We have developed a novel method to map high dynamic range scenes to low dynamic range images for display in standard (low dynamic range)reproduction media.We formulate the problem as a quantization process and employ an adaptive conscience learning strategy to ensure that the mapped low dynamic range displays not only faithfully reproduce the visual features of the original scenes,but also make full use of the available display levels.This is achieved by the use of a competitive learning neural network that employs a frequency sensitive competitive learning mechanism to adaptively design the quantizer.By optimizing an L 2distortion function,we ensure that the mapped low dynamic images preserve the visual characteristics of the original scenes.By incorporating a frequency sensitive competitive mechanism,we facilitate the full utilization of the limited displayable levels.We have developed a deterministic and practicable learning procedure which uses a single variable to control the display result.We give a detailed description of the implementation procedure of the new learning-based high dynamic range compression method and present experimental results to demonstrate the effectiveness of the method in displaying a variety of high dynamic range scenes.᭧2007Pattern Recognition Society.Published by Elsevier Ltd.All rights reserved.Keywords:Learning-based image processing;Quantization;High dynamic range imaging;Dynamic range compression;Neural network;Competitive learning1.IntroductionWith the rapid advancement in electronic imaging and com-puter graphics technologies,there have been increasing interests in high dynamic range (HDR)imaging,see e.g.,Ref.[1–17].Fig.1shows a scenario where HDR imaging technology will be useful to photograph the scene.This is an indoor scene of very HDR.In order to make features in the dark areas visible,longer exposure had to be used,but this rendered the bright area saturated.On the other hand,using shorter exposure made features in the bright areas visible,but this obscured features in the dark areas.In order to make all features,both in the dark and bright areas simultaneously visible in a single image,we can create a HDR radiance map [3,4]for the ing the technology of Ref.[3],it is relatively easy to create HDR maps for high dynamic scenes.All one needs is a sequence of low∗Corresponding author.Fax:+441159514254.E-mail address:qiu@ (G.Qiu).0031-3203/$30.00᭧2007Pattern Recognition Society.Published by Elsevier Ltd.All rights reserved.doi:10.1016/j.patcog.2007.02.012dynamic range (LDR)photos of the scene taken with different exposure intervals.Fig.2shows the LDR display of the scene in Fig.1mapped from its HDR radiance map,which has been created using the method of [3]from the photos in Fig.1.It is seen that all areas in this image are now clearly visible.HDR imaging technology has also been recently extended to video [13,14].Although we can create HDR numerical radiance maps for high dynamic scenes such as those like Fig.1,reproduction devices,such as video monitors or printers,normally have much lower dynamic range than the radiance map (or equivalently the real world scenes).One of the key technical issues in HDR imaging is how to map HDR scene data to LDR display values in such a way that the visual impressions and feature details of the original real physical scenes are faithfully reproduced.In the literature,e.g.,Refs.[5–17],there are two broad categories of dynamic range compression techniques for the dis-play of HDR images in LDR devices [12].The tone reproduc-tion operator (TRO)based methods involve (multi-resolution)spatial processing and mappings not only take into account the2642G.Qiu et al./Pattern Recognition 40(2007)2641–2655Fig.1.Low dynamic range photos of an indoor scene taken under different exposureintervals.Fig.2.Low dynamic display of high dynamic range map created from the photos in Fig.1.The dynamic range of the radiance map is 488,582:1.HDR radiance map synthesis using Paul Debevec’s HDRShop software (/HDRShop/).Note:the visual artifacts appear in those blinds of the glass doors were actually in the original image data and not caused by the algorithm.values of individual pixel but are also influenced by the pixel spatial contexts.Another type of approaches is tone reproduc-tion curve (TRC)based.These approaches mainly involve the adjustment of the histograms and spatial context of individual pixel is not used in the mapping.The advantages of TRO-based methods are that they generally produce sharper images when the scenes contain many detailed features.The problems with these approaches are that spatial processing can be computa-tionally expensive,and there are in general many parameters controlling the behaviors of the operators.Sometimes these techniques could introduce “halo”artifacts and sometimes they can introduce too much (artificial)detail.TRC-based methods are computationally simple.They preserve the correct bright-ness order and therefore are free from halo artifacts.These methods generally have fewer parameters and therefore are eas-ier to use.The drawbacks of this type of methods are that spa-tial sharpness could be lost.Perhaps one of the best known TRC-based methods is that of Ward and co-workers’[5].The complete operator of Ref.[5]also included sophisticated models that exploit the limita-tions of human visual system.According to Ref.[5],if one just wanted to produce a good and natural-looking display for an HDR scene without regard to how well a human ob-server would be able to see in a real environment,histogram adjustment may provide an “optimal”solution.Although the histogram adjustment technique of Ref.[5]is quite effective,it also has drawbacks.The method only caps the display contrast(mapped by histogram equalization)when it exceeds that of the original scene.This means that if a scene has too low contrast,the technique will do nothing.Moreover,in sparsely populated intensity intervals,dynamic range compression is achieved by a histogram equalization technique.This means that some sparse intensity intervals that span a wide intensity range will be com-pressed too aggressively.As a result,features that are visible in the original scenes would be lost in the display.This un-satisfactory aspect of this algorithm is clearly illustrated in Figs.9–11.In this paper,we also study TRC-based methods for the dis-play of HDR images.We present a learning-based method to map HDR scenes to low dynamic images to be displayed in LDR devices.We use an adaptive learning algorithm with a “conscience”mechanism to ensure that,the mapping not only takes into account the relative brightness of the HDR pixel val-ues,i.e.,to be faithful to the original data,but also favors the full utilization of all available display values,i.e.,to ensure the mapped low dynamic images to have good visual contrast.The organization of the paper is as follows.In the next section,we cast the HDR image dynamic range compression problem in an adaptive quantization framework.In Section 3,we present a solution to HDR image dynamic range compression based on adaptive learning.In Section 4,we present detailed imple-mentation procedures of our method.Section 4.1presents re-sults and Section 4.2concludes our presentation and briefly discusses future work.2.Quantization for dynamic range compressionThe process of displaying HDR image is in fact a quantiza-tion and mapping process as illustrated in Fig.3.Because there are too many (discrete)values in the high dynamic scene,we have to reduce the number of possible values,this is a quantiza-tion process.The difficulty faced in this stage is how to decide which values should be grouped together to take the same value in the low dynamic display.After quantization,all values that will be put into the same group can be annotated by the group’s index.Displaying the original scene in a LDR is simply to rep-resent each group’s index by an appropriate display intensity level.In this paper,we mainly concerned ourselves with the first stage,i.e.,to develop a method to best group HDR values.Quantization,also known as clustering,is a well-studied subject in signal processing and neural network literature.Well-known techniques such as k -means and various neural network-based methods have been extensively researched [18–21].Let x(k),k =1,2,...,be the intensities of the luminance compo-nent of the HDR image (like many other techniques,we only work on the luminance and in logarithm space,also,we treatG.Qiu et al./Pattern Recognition 40(2007)2641–26552643QuantizationInputHigh dynamic range data (real values)1x xMappingDisplaying Intensity LevelsFig.3.The process of display of high dynamic range scene (from purely anumerical processing’s point of view).each pixel individually and therefore are working on scalar quantization).A quantizer is described by an encoder Q ,which maps x(k)to an index n ∈N specifying which one of a small collection of reproduction values (codewords)in a codebook C ={c n ;n ∈N }is used for reconstruction,where N in our case,is the number of displayable levels in the LDR image.There is also a decoder Q −1,which maps indices into reproduction values.Formally,the encoding is performed as Q(x(k))=n if x(k)−c n x(k)−c i ∀i (1)and decoding is performed as Q −1(n)=c n .(2)That is (assuming that the codebook has already been de-signed),an HDR image pixel is assigned to the codeword that is the closest to it.All HDR pixels assigned to the same code-words then form a cluster of pixels.All HDR pixels in the same cluster are displayed at the same LDR level.If we order the codewords such that they are in increasing order,that is c 1<c 2<···<c N −1<c N ,and assign display values to pixels belonging to the clusters in the order of their codeword values,then the mapping is order preserving.Pixels belonging to a clus-ter having a larger codeword value will be displayed brighter than pixels belonging to a cluster with a codeword having a smaller value.Clearly,the codebook plays a crucial role in this dynamic range compression strategy.It not only determines which pix-els should be displayed at what level,it also determines which pixels will be displayed as the same intensity and how many pixels will be displayed with a particular intensity.Before we discuss how to design the codebook,lets find out what require-ments for the codebook are in our specific application.Recall that one of the objectives of mapping are that we wish to preserve all features (or as much as possible)of the HDR image and make them visible in the LDR reproduction.Because there are fewer levels in the LDR image than in the HDR image,the compression is lossy in the sense that there will be features in the HDR images that will be impossible to reproduce in the LDR images.The question is what should bepreserved (and how)in the mapping (quantization)in order to produce good LDR displays.For any given display device,the number of displayable lev-els,i.e.,the number of codewords is fixed.From a rate dis-tortion’s point of view,the rate of the quantizer is fixed,and the optimal quantizer is the one that minimizes the distortion.Given the encoding and decoding rules of Eqs.(1)and (2),the distortion of the quantizer is defined asE =i,ki (k) x(k)−c i where i (k)=1if x(k)−c i ≤ x(k)−c j ∀j,0otherwise .(3)A mapping by a quantizer that minimizes E (maximizes rate distortion ratio)will preserve maximum relevant information of the HDR image.One of the known problems in rate distortion optimal quan-tizer design is the uneven utilization of the codewords where,some clusters may have large number of pixels,some may have very few pixels and yet others may even be empty.There may be two reasons for this under utilization of codewords.Firstly,the original HDR pixel distribution may be concentrated in a very narrow range of intensity interval;this may cause large number of pixels in these densely populated intervals to be clustered into a single or very few clusters because they are so close together.In the HDR image,if an intensity interval has a large concentration of pixels,then these pixels could be very important in conveying fine details of the scene.Although such intervals may only occupy a relatively narrow dynamic range span because of the high-resolution representation,the pixels falling onto these intervals could contain important de-tails visible to human observers.Grouping these pixels together will loose too much detail information.In this case,we need to “plug”some codewords in these highly populated intensity intervals such that these pixels will be displayed into different levels to preserve the details.The second reason that can cause the under utilization of codewords could be due to the opti-mization process being trapped in a local minimum.In order to produce a good LDR display,the pixels have to be reasonably evenly distributed to the codewords.If we assign each code-word the same number of pixels,then the mapping is histogram equalization which has already been shown to be unsuitable for HDR image display [5].If we distribute the pixel popula-tion evenly without regarding to their relative intensity values,e.g.,grouping pixels with wide ranging intensity values just to ensure even population distribution into each codeword,then we will introduce too much objectionable artifacts because compression is too aggressive.In the next section,we intro-duce a learning-based approach suitable for designing dynamic range compression quantizers for the display of HDR images.3.Conscience learning for HDR compressionVector quantization (VQ)is a well-developed field [16](although we will only design a scalar quantizer (SQ),we will borrow techniques mainly designed for VQ.There are2644G.Qiu et al./Pattern Recognition40(2007)2641–2655 many methods developed for designing vector quantizers.Thek-means type algorithms,such as the LBG algorithm[18],and neural network-based algorithms,such as the Kohonenfeature map[19]are popular tools.As discussed in Section2,our quantizer should not only be based on the rate distortioncriterion,but also should ensure that there is an even spreadof pixel population.In other words,our quantizer should min-imize E in Eq.(3)and at the same time the pixels should beevenly distributed to the codewords.Therefore the design algo-rithm should be able to explicitly achieve these two objectives.In the neural network literature,there is a type of consciencecompetitive learning algorithm that will suit our application.Inthis paper,we use the frequency sensitive competitive learning(FSCL)algorithm[20]to design a quantizer for the mappingof HDR scenes to be displayed in low dynamic devices.Tounderstand why FSCL is ideally suited for such an application,wefirst briefly describe the FSCL algorithm.The philosophy behind the FSCL algorithm is that,when acodeword wins a competition,the chance of the same codewordwinning the next time round is reduced,or equivalently,thechance of other codewords winning is increased.The end effectis that the chances of each codeword winning will be equal.Putin the other way,each of the codewords will be fully utilized.In the context of using the FSCL for mapping HDR data tolow dynamic display,the limited number of low dynamic levels(codewords)will be fully utilized.The intuitive result of fullyutilized display level is that the displayed image will have goodcontrast,which is exactly what is desired in the display.How-ever,unlike histogram equalization,the contrast is constrainedby the distribution characteristics of the original scene’s inten-sity values.The overall effect of such a mapping is thereforethat,the original scenes are faithfully reproduced,while at thesame time,the LDR displays will have good contrast.FSCL algorithmStep1:Initialize the codewords,c i(0),i=1,2,...,N,to ran-dom numbers and set the counters associated with each code-word to1,i.e.f i(0)=1,i=1,2,...,NStep2:Present the training sample,x(k),where k is thesequence index,and calculate the distance between x(k)andthe codewords,and subsequently modify the distances usingthe counters valuesd i(k)= x(k)−c i(k) d∗i(k)=f i(k)d i(k)(4)Step3:Find the winner codeword c j(k),such thatd∗j(k) d∗i(k)∀iStep4:Update the codeword and counter of the winner asc j(k+1)=c j(k)+ (x(k)−c j(k))f j(k+1)=f j(k)+1where0< <1(5)Step5:If converged,then stop,else go to Step2.The FSCL process can be viewed as a constrained optimiza-tion problem of the following form:J=E+iki(k)−|x(k)|N2,(6)where is the Lagrange multiplier,|x(k)|represents the totalnumber of training samples(pixels),N is the number of code-words(display levels),E and are as defined in Eq.(3).Minimizing thefirst term ensures that pixel values close toeach other will be grouped together and will be displayed asthe same single brightness.Minimizing the second term facil-itates that each available displayable level in the mapped im-age will be allocated similar number of pixels thus creating awell contrast display.By sorting the codewords in an increasingorder,i.e.,c1<c2<···<c N−1<c N,the mapping also ensuresthat the brighter pixels in the original image are mapped to abrighter display level and darker pixels are mapped to a darkerdisplay level thus ensuring the correct brightness order to avoidvisual artifacts such as the“halo”phenomenon.Because the mapping not only favors an equally distributedpixel distribution but also is constrained by the distancesbetween pixel values and codeword values,the current methodis fundamentally different from both traditional histogramequalization and simple quantization-based methods.His-togram equalization only concerns that the mapped pixels haveto be evenly distributed regardless of their relative brightness,while simple quantization-based mapping(including many lin-ear and nonlinear data independent mapping techniques,e.g.,Ref.[2])only takes into account the pixel brightness valuewhile ignoring the pixel populations in each mapped level.As a result,histogram equalization mapping will create visu-ally annoying artifacts and simple quantization-based methodwill create mappings with under utilized display levels whichoften resulting in many features being squashed and becomeinvisible.With FSCL learning,we could achieve a balancedmapping.4.Implementation detailsBecause the objective of our use of the FSCL algorithm inthis work is different from that of its ordinary applications,e.g.,vector quantization,there are some special requirementsfor its implementation.Our objective is not purely to achieverate distortion optimality,but rather should optimize an ob-jective function of the form in Eq.(6)and the ultimate goalis,of course,to produce good LDR displays of the HDR im-ages.In this section,we will give a detailed account of itsimplementation.4.1.Codebook initializationWe work on the luminance component of the image only andin logarithm space,from thefloating point RGB pixel valuesof the HDR radiance map,we calculateL=log(0.299∗R+0.587∗G+0.114∗B),L max=MAX(L),L min=MIN(L).(7)In using the FSCL algorithm,we found that it is very importantto initialize the codewords to linearly scaled values.Let thecodebook be C={c i;i=1,2,...,N},N is the number ofcodewords.In our current work,N is set to256.The initialG.Qiu et al./Pattern Recognition 40(2007)2641–26552645020004000600080001000012000133659712916119322505000100001500020000250000326496128160192224petitive learning without conscience mechanism will produce a mapping close to linear scaling.Left column:competitive learning without conscience mechanism.Right column:linear scaling.Radiance map data courtesy of Fredo Durand.values of the codewords are chosen such that they are equally distributed in the full dynamic range of the luminance:c i (0)=L min +i256(L max −L min ).(8)Recall that our first requirement in the mapping is that the dis-play should reflect the pixel intensity distribution of the original image.This is achieved by the optimization of E in Eq.(3)with the initial codeword values chosen according to Eq.(8).Let us first consider competitive learning without the conscience mechanism.At the start of the training process,for pixels falling into the interval c i (0)±(L max −L min )/512,the same code-word c i will win the competitions regardless of the size of pixel population falling into the interval.The pixels in the intensity intervals that are far away from c i will never have the chance to access it.In this case,distance is the only criterion that de-termines how the pixels will be clustered and pixel populations distributed into the codewords are not taken into account.Af-ter training,the codewords will not change much from their initial values because each codeword will only be updated by pixels falling close to it within a small range.In the encodingor mapping stage,since the codewords are quite close to their corresponding original positions which are linearly scattered in the FDR,the minimum distortion measure will make the map-ping approximately linear and extensive simulations demon-strate that this is indeed the case.As a result,the final mapped image will exhibit the pixel intensity distribution characteris-tics of the original image.Fig.4(a)shows a result mapped by competitive learning without the conscience mechanism,com-pared with Fig.4(b),the linearly scaled mapping result,it is seen that both the images and their histograms are very similar which demonstrate that by initializing the codewords according Eq.(8),optimizing the distortion function E in Eq.(3)has the strong tendency to preserve the original data of the original im-age.However,like linear compression,although the resulting image reflects the data distribution of the scene,densely pop-ulated intensity intervals are always over-quantized (too much compression)which causes the mapped image lacking contrast.With the introduction of the conscience mechanism,in the training stage,competition is based on a modified distance measure,d ∗in Eq.(4).Note that if a codeword wins the competitions frequently,its count and consequently its modi-2646G.Qiu et al./Pattern Recognition 40(2007)2641–2655σ = 0.05, η(0) = 0.1 σ = 0.05, η(0) = 0.2 010002000300040005000600070008000900006412819210002000300040005000600070008000064128192100020003000400050006000700006412819210002000300040005000600070000641281921000200030004000500060007000064128192σ = 0.05, η(0) = 0.3σ = 0.05, η(0) = 0.4σ = 0.05, η(0) = 0.5Fig.5.Final mapped images and their histograms for fixed and various (0).Radiance map data courtesy of Fredo Durand.fied distance increases,thus reducing its chance of being the winner and increasing the likelihood of other codewords with relatively lower count values to win.This property is exactly what is desired.If a codeword wins frequently,this means that the intensity interval it lies in gathers large population of pixels.In order to ensure the mapped image having goodG.Qiu et al./Pattern Recognition 40(2007)2641–26552647η(0) = 0.2, σ= 0.05 020004000600080000641281922000400060008000064128192100020003000400050006000700006412819210002000300040005000600070000641281921000200030004000500060007000064128192η(0) = 0.2, σ = 0.04 η(0) = 0.2, σ = 0.02η(0) = 0.2, σ = 0.0087η(0) = 0.2, σ = 0.002Fig.6.Final mapped images and their histograms for fixed (0)and various .Radiance map data courtesy of Fredo Durand.contrast,these densely populated intensity intervals should be represented by more codewords,or equivalently,more dis-play levels.The incorporation of the conscience mechanism makes the algorithm conscience of this situation and passes the chances to codewords with lower count values to win the com-petitions so that they can be updated towards the population dense intensity intervals and finally join in the quantization of these intervals.2648G.Qiu et al./Pattern Recognition40(2007)2641–2655 The training starts from linearly scattered codewords,withthe introduction of the conscience mechanism,the code-words are moved according to both their values and the pixelpopulation distribution characteristics.At the beginning of thetraining phase,the mapping is linear,and the mapped image’shistogram is narrow,as training progresses,the mapped im-age’s histogram is gradually wider,and when it reaches anequilibrium,it achieves an optimal mapping that preserves theappearance of the original scene and also has good visibilityand contrast.Although initializing the codewords according to Eq.(8)may lead to largerfinal distortion E than other(random)meth-ods for codeword initialization,this does not matter.Unlike conventional use of FSCL,our objective is not to achieve rate distortion optimality,but rather,the aim is to cluster the HDR image pixels in such a way that the groupings not only reflect the pixel distribution of the original scene,the pixel populations are also evenly distributed to the codewords such that the im-age can be displayed in LDR devices with good visibility and contrast.Because of the special way in which the initial values of the codewords are set,some codewords may scatter far away from densely populated intensity intervals where more codewords are needed to represent the pixels.In order to achieve this,we let the fairness function,f i’s in Eq.(5)of the FSCL algorithm,accumulate the counts throughout the entire training process,thus increasing the chances to obtain more contrast.4.2.Setting the training rateThe training rate in Eq.(5)is an important parameter in the training of the quantizer.It not only determines the convergence speed but also affects the quality of thefinal quantizer.In the neural network literature,there are extensive studies on this subject.In our work,we use the following rule to set the training rate as a function training iterations(k)= (0)exp(− k)),(9) where (0)is the initial value set at the beginning of the training, is a parameter controlling how fast the training rate decadesas training progresses.In the experiments,we found that larger initial training rate values and slower decreasing speeds(smaller in Eq.(9)) led to higher contrast images when the algorithm achieved an equilibrium state.The result is rger initial val-ues and slower decreasing speed of the training rate make remain relatively large throughout.Once a codeword,which may be far away from densely populated intensity intervals, wins a competition,the larger training rate would drag it closer to the densely populated intensity intervals and thus increasing its chance to win again the next time round.Thefinal result is that densely populated intensity intervals are represented by more codewords or more display levels and the displayed im-ages will have more details.The effects for smaller training rates are almost the opposite,small training rate will result in1214161811011211411611810.20.30.40.50.6η(0)=EIterationsFig.7.Training curves forfixed =0.05and various (0)corresponding to those in Fig.5.the image having a narrower histogram(lower contrast)and more similar to the effect of linear compression.This is again expected.Because we initialize the codewords by linear scal-ing and small will make thefinal codewords closer to their initial values when the training achieves an equilibrium.Fig.5 shows examples of mapped images and their histograms with different (0)andfixed .Fig.6shows examples of mapped images and their histograms with different andfixed (0). By changing the training rate settings,the mapped image’s his-togram can be controlled to have narrower shapes(lower con-trast images)or broader shapes(higher contrast images).This property of the training rate provides the users with a good guidance to control thefinal appearance of the mapped HDR images.According to the above analysis,in order to control the final appearance of the mapped image,we canfix one param-eter and change the other.To achieve the same contrast for the final mapping,we can either use a smaller (0)and a smaller , or,a larger (0)and a larger .However in the experiments we found that,with a smaller (0)and a smaller ,the algorithm took longer to converge to an equilibrium state.Fig.7shows the training curves for the training rate settings corresponding to those in Figs.5and8shows the training curves for the train-ing rate settings corresponding to those in Fig.6.The image in Fig.5mapped with (0)=0.5and =0.05and the image in Fig.6mapped with (0)=0.2and =0.002have similar contrast.However,as can be seen from the training curves in Figs.7and8,for (0)=0.5and =0.05,the training con-verged within100iterations and for (0)=0.2and =0.002 the training took more than400iterations to converge.Thus as a guide for the use of the training algorithm,we recom-mend that the control of thefinal image appearance be achieved byfixing a relatively aggressive and adjusting (0)because of the fast convergence speed under such conditions.Setting (0)=0∼1and =0.05,and train the quantizer for100 iterations worked very well for all images we have tried.After 50iterations,E changed very little by further iterations,there-fore for most images,less than50iterations suffice.Through experiments,we also found that it was only necessary to use。