偏度和峰度概念的认识误区
偏度和峰度的标准误

偏度和峰度的标准误偏度和峰度是统计学中用于描述概率分布形状的重要指标。
它们可以帮助我们了解数据的分布特征,并帮助我们做出适当的统计分析和推断。
在本文中,我将详细介绍偏度和峰度的概念、计算方法以及它们的标准误。
一、偏度的概念和计算方法偏度是用来度量概率分布的不对称性的统计量。
它反映了数据分布的左偏还是右偏,以及偏斜程度的大小。
偏度的计算公式如下:偏度 = (3 * (平均值 - 中位数)) / 标准差其中,平均值是数据的算术平均数,中位数是数据的中间值,标准差是数据的离散程度的度量。
偏度的取值范围是从负无穷到正无穷。
当偏度为0时,表示数据分布是对称的,左右两侧的偏斜程度相同。
当偏度大于0时,表示数据分布是右偏的,也称为正偏,即数据分布的尾部偏向右侧。
当偏度小于0时,表示数据分布是左偏的,也称为负偏,即数据分布的尾部偏向左侧。
二、峰度的概念和计算方法峰度是用来度量概率分布的尖锐度或平坦度的统计量。
它反映了数据分布的峰态或波态的程度。
峰度的计算公式如下:峰度 = ((数据的四阶矩 / 标准差的四次方) - 3)其中,四阶矩是数据的四阶中心距,标准差是数据的离散程度的度量。
峰度的取值范围是从负无穷到正无穷。
当峰度为0时,表示数据分布的峰态与正态分布相同。
当峰度大于0时,表示数据分布的峰态比正态分布更尖锐,峰部更窄且尾部更重。
当峰度小于0时,表示数据分布的峰态比正态分布更平坦,峰部更宽且尾部更轻。
三、偏度和峰度的标准误偏度和峰度的标准误是用于估计偏度和峰度的标准差的度量。
它们可以帮助我们判断估计的偏度和峰度是否准确。
标准误的计算方法依赖于样本量的大小。
对于偏度的标准误,计算公式如下:偏度的标准误 = sqrt((6 * 样本量 * (样本量 - 1)) / ((样本量 - 2) * (样本量 + 1) * (样本量 + 3)))对于峰度的标准误,计算公式如下:峰度的标准误 = sqrt((24 * 样本量 * (样本量 - 1)^2 * (样本量 - 2)) / ((样本量 - 3) * (样本量 + 5) * (样本量 + 1) * (样本量 + 3)))其中,样本量是用于计算偏度和峰度的样本的数量。
偏度和峰度

你的位置:第四章| 第七节|五、偏度与峰度五、偏度与峰度(一)偏度偏度是指次数分布非对称的偏态方向程度。
为了精确测定次数分布的偏斜状况,统计上采用偏斜度指标。
计算偏斜度有不同的方法,现介绍其中比较简单的一种方法。
由前述介绍可知,在对称分布条件下,=M e=M0;在偏态分布条件下,三者存在数量(位置)差异。
其中,Me居于中间,与M0分居两边,因此,偏态可用与M0的绝对差额(距离)来表示,即与M0的绝对差额越大,表明偏斜程度越大;与M0的绝对差额越小,则表明偏斜程度越小。
当>M0,说明偏斜的方向为右(正)偏;当<M0,则说明偏斜的方向为左(负)偏。
由于偏态是以绝对数表示的,具有原数列的计量单位,因此不能直接比较不同数列的偏态程度。
为了使不同数列的偏态值可比,可计算偏态的相对值,即偏斜度(α)又称为偏态系数,就是将偏态的绝对数用其标准差除之。
公式为:(4-55)偏斜度是以标准差为单位的算术平均数与众数的离差,故其取值范围一般在0与±3之间。
α为0表示对称分布,α为+3与-3分别表示极右偏态和极左偏态。
(二)峰度峰度是指次数分布曲线顶峰的尖平程度,是次数分布的又一重要特征。
统计上,常以正态分布曲线为标准,来观察比较某一次数分布曲线的顶端正党风尖顶或平顶以及尖平程度的大小。
根据变量值的集中与分散程度,峰度一般可表现为三种形态:尖顶峰度、平顶峰度和标准峰度。
当变量值的次数在众数周围分布比较集中,使次数分布曲线比正态分布曲线顶峰更为隆起尖峭,称为尖顶峰度;当变量值的次数在众数周围分布较为分散,使次数分布曲线较正态分布曲线更为平缓,称为平顶峰度。
可见,尖顶峰度或平顶峰度都是相对正态分布曲线的标准峰度而言的。
峰度的测定,一般是采用统计动差方法,即以四阶中心动差V4为测定依据,将V4除以其标准差的四次方σ4,以消除单位量纲的影响,便于不同次数分布曲线的峰度比较,从而得到以无名数表示的相对数,即为峰度的测定值(β)。
用偏度和峰度检验正态分布的方法

用偏度和峰度检验正态分布的方法引言正态分布是统计学中最常见的分布之一,也是许多统计推断和假设检验的基础。
在实际应用中,我们常常需要检验数据是否符合正态分布。
偏度(skewness)和峰度(kurtosis)是常用的两个统计量,可以用来判断数据的分布形态。
本文将介绍偏度和峰度的概念,并详细说明如何使用这两个统计量来检验数据是否符合正态分布。
1. 偏度偏度是描述数据分布对称性的统计量。
它衡量了数据分布的左右偏斜程度,可以判断数据是左偏、右偏还是近似对称。
偏度的定义如下:Skewness=∑(X i−X‾)3ni=1/nσ3其中,X i是样本观测值,X‾是样本均值,σ是样本标准差,n是样本容量。
偏度的取值范围为负无穷到正无穷。
当偏度为0时,表示数据分布近似对称;当偏度大于0时,表示数据分布右偏;当偏度小于0时,表示数据分布左偏。
2. 峰度峰度是描述数据分布尖锐程度的统计量。
它衡量了数据分布的峰态,可以判断数据是平顶、尖峭还是扁平。
峰度的定义如下:Kurtosis=∑(X i−X‾)4ni=1/nσ4其中,X i是样本观测值,X‾是样本均值,σ是样本标准差,n是样本容量。
峰度的取值范围为负无穷到正无穷。
当峰度为0时,表示数据分布为正态分布;当峰度大于0时,表示数据分布比正态分布更尖峭;当峰度小于0时,表示数据分布比正态分布更平顶。
3. 检验方法3.1 偏度检验偏度检验的原假设(H0)是数据分布的偏度等于0,即数据分布近似对称。
备择假设(H1)是数据分布的偏度不等于0,即数据分布不对称。
常用的偏度检验方法有两种:Shapiro-Wilk检验和Jarque-Bera检验。
3.1.1 Shapiro-Wilk检验Shapiro-Wilk检验是一种基于排序的统计检验方法,适用于小样本和大样本。
它的原假设是数据来自正态分布。
在Python中,可以使用SciPy库的shapiro函数进行Shapiro-Wilk检验。
spss判断是否符合正态分布
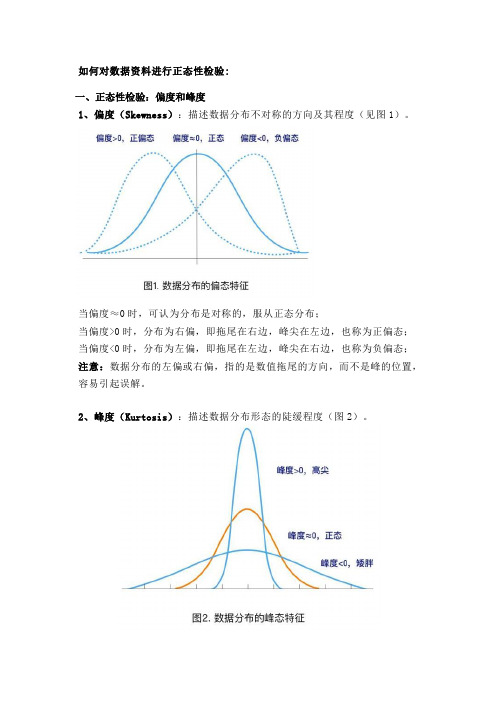
如何对数据资料进行正态性检验:一、正态性检验:偏度和峰度1、偏度(Skewness):描述数据分布不对称的方向及其程度(见图1)。
当偏度≈0时,可认为分布是对称的,服从正态分布;当偏度>0时,分布为右偏,即拖尾在右边,峰尖在左边,也称为正偏态;当偏度<0时,分布为左偏,即拖尾在左边,峰尖在右边,也称为负偏态;注意:数据分布的左偏或右偏,指的是数值拖尾的方向,而不是峰的位置,容易引起误解。
2、峰度(Kurtosis):描述数据分布形态的陡缓程度(图2)。
当峰度≈0时,可认为分布的峰态合适,服从正态分布(不胖不瘦);当峰度>0时,分布的峰态陡峭(高尖);当峰度<0时,分布的峰态平缓(矮胖);利用偏度和峰度进行正态性检验时,可以同时计算其相应的Z评分(Z-score),即:偏度Z-score=偏度值/标准误,峰度Z-score=峰度值/标准误。
在α=0.05的检验水平下,若Z-score在±1.96之间,则可认为资料服从正态分布。
了解偏度和峰度这两个统计量的含义很重要,在对数据进行正态转换时,需要将其作为参考,选择合适的转换方法。
3、SPSS操作方法以分析某人群BMI的分布特征为例。
(1) 方法一选择Analyze → Descriptive Statistics → Frequencies将BMI选入Variable(s)框中→点击Statistics →在Distribution框中勾选Skewness和Kurtosis(2) 方法二选择Analyze → Descriptive Statistics → Descriptives将BMI选入Variable(s)框中→点击Options →在Distribution框中勾选Skewness和Kurtosis4、结果解读在结果输出的Descriptives部分,对变量BMI进行了基本的统计描述,同时给出了其分布的偏度值0.194(标准误0.181),Z-score = 0.194/0.181 = 1.072,峰度值0.373(标准误0.360),Z-score = 0.373/0.360 = 1.036。
正态分布偏度和峰度标准误计算公式 知乎

正态分布偏度和峰度标准误计算公式1. 正态分布的基本概念在统计学中,正态分布也被称为高斯分布,它是一种非常重要且常见的概率分布。
正态分布的概率密度函数呈钟型曲线,左右对称,由两个参数μ和σ^2决定。
在正态分布中,均值为μ,方差为σ^2。
2. 偏度的概念及计算公式偏度是描述数据分布形态的统计量,用于衡量分布偏离正态分布的程度。
偏度为0表示数据分布形态与正态分布完全对称。
偏度大于0表示数据分布形态偏向于左侧,偏度小于0表示数据分布形态偏向于右侧。
计算偏度的公式为:\[ Skewness = \frac{n}{(n-1)(n-2)} \cdot \frac{\sum_{i=1}^n (x_i - \overline{x})^3}{s^3} \]其中,n为样本容量,\( x_i \)为第i个观测值,\( \overline{x} \)为样本均值,s为样本标准差。
3. 峰度的概念及计算公式峰度是描述数据分布尖峭程度的统计量,用于衡量数据分布的尖峭或平缓程度。
峰度为0表示数据分布相对于正态分布具有相同的尖峭程度。
峰度大于0表示数据分布相对于正态分布更尖峭,峰度小于0表示数据分布相对于正态分布更平缓。
计算峰度的公式为:\[ Kurtosis = \frac{n(n+1)}{(n-1)(n-2)(n-3)} \cdot \sum_{i=1}^n\frac{(x_i - \overline{x})^4}{s^4} - \frac{3(n-1)^2}{(n-2)(n-3)} \]4. 正态分布偏度和峰度标准误计算公式正态分布的偏度和峰度标准误计算公式可以帮助我们对样本偏度和峰度进行显著性检验,从而确定样本的偏度和峰度是否显著地不同于零,进而判断数据分布是否具有偏斜和尖峭特征。
偏度标准误的计算公式为:\[ SE(Skewness) = \sqrt{\frac{6n(n-1)}{(n-2)(n+1)(n+3)}} \]峰度标准误的计算公式为:\[ SE(Kurtosis) = \sqrt{\frac{24n(n-1)^2(n-2)(n-3)(n+5)(n+3)}{n(n-2)(n+3)(n+5)(n+7)(n+9)}} \]5. 个人观点和理解正态分布的偏度和峰度标准误计算公式为我们提供了在统计学研究中对数据分布形态进行检验的重要工具。
峰度,偏度

峰度(Kurtosis)和偏度(Skewness)是统计学中用于描述概率分布形状的两个重要概念。
1. **峰度(Kurtosis):** 峰度度量了概率分布曲线的尖峰程度,即它衡量了数据集中数据点分布在均值周围的程度。
峰度通常与正态分布进行比较。
- 正态分布的峰度为3,称为Mesokurtic。
如果数据的峰度大于3,表示它比正态分布更陡峭(尖峰),称为Leptokurtic。
- 如果数据的峰度小于3,表示它比正态分布更平坦(扁平),称为Platykurtic。
峰度计算方式:\[Kurtosis = \frac{1}{n}\sum_{i=1}^{n}\left(\frac{x_i-\bar{x}}{\sigma}\right)^4 - 3\] 其中,\(n\) 是数据点数量,\(\bar{x}\) 是均值,\(\sigma\) 是标准差。
2. **偏度(Skewness):** 偏度度量了概率分布曲线的不对称性,即它描述了数据集中数据点相对于均值的分布情况。
- 如果偏度为正数,表示数据分布向右偏斜,也称为正偏斜,意味着数据的尾部在均值的右侧,尾部较长。
- 如果偏度为负数,表示数据分布向左偏斜,也称为负偏斜,意味着数据的尾部在均值的左侧,尾部较长。
- 如果偏度接近0,表示数据相对对称,分布相对均匀。
偏度计算方式:\[Skewness = \frac{1}{n}\sum_{i=1}^{n}\left(\frac{x_i-\bar{x}}{\sigma}\right)^3\]其中,\(n\) 是数据点数量,\(\bar{x}\) 是均值,\(\sigma\) 是标准差。
峰度和偏度是用于了解数据分布形状的重要统计量,它们可以帮助分析数据是否符合正态分布,或者是否存在偏斜和尖峰。
这对于许多统计分析和数据建模任务都非常重要。
变异系数、偏度、峰度的认识及应用

变异系数、偏度、峰度的认识与应用一、变异系数1、名词解释:变异系数又称"标准差率",是衡量资料中各观测值变异程度的另一个统计量.当进行两个或多个资料变异程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较.如果单位和〔或〕平均数不同时,比较其变异程度就不能采用标准差,而需采用标准差与平均数的比值〔相对值〕来比较. 简单来说就是:在表示离散程度上,标准差并不是全能的,当度量单位或平均数不同时,只能用变异系数了,它也是表示离散程度,是标准差与平均数的比值称为变异系数,记为C·V.变异系数可以消除单位和〔或〕平均数不同对两个或多个资料变异程度比较的影响.2、计算公式变异系数C.V =〔标准偏差SD÷平均值MN 〕× 100%3、应用:例题:已知某良种猪场长白成年母猪平均体重为190kg,标准差为10.5kg,而大约克成年母猪平均体重为196kg,标准差为8.5kg,试问两个品种的成年母猪,那一个体重变异程度大.此例观测值虽然都是体重,单位相同,但它们的平均数不相同,只能用变异系数来比较其变异程度的大小.由于,长白成年母猪体重的变异系数:C.V = 10.5 / 190 * 100% =5.53%大约克成年母猪体重的变异系数:C.V = 8.5 / 196 * 100% = 4.34% 所以,长白成年母猪体重的变异程度大于大约克成年母猪. 二、偏度1、名词解释:偏度以bs 表示,xi 是样本测定值,是样本n 次测定值的平均值.表征概率分布密度曲线相对于平均值不对称程度的特征数.2、偏度与与正态分布的关系:正态分布的偏度为0,两侧尾部长度对称.bs<0称分布具有负偏离,也称左偏态,此时数据位于均值左边的比位于右边的少,直观表现为左边的尾部相对于与右边的尾部要长,因为有少数变量值很小,使曲线左侧尾部拖得很长;bs>0称分布具有正偏离,也称右偏态,此时数据位于均值右边的比位于左边的少,直观表现为右边的尾部相对于与左边的尾部要长,因为有少数变量值很大,使曲线右侧尾部拖得很长;而bs 接近0则可认为分布是对称的.若知道分布有可能在偏度上偏离正态分布时,可用偏离来检验分布的正态性.右偏时一般算术平均数>中位数>众数,左偏时相反,即众数>中位数>平均数.正态分布三者相等.3、计算方法:其中i X 是第i 个样本,sd 是样本标准差,1g 是总体偏度的有偏估计. 三、峰度1、名词解释:峰度,又称峰态系数.表征概率密度分布曲线在平均值处峰值高低的特征数.直观看来,峰度反映了尾部的厚度.2、特点:峰度以k b 表示,i Y 是样本测定值,bar Y 是样本n 次测定值的平均值,s 为样本标准差.正态分布的峰度为3.3k b <称分布具有不足的峰度,3k b >称分布具有过度的峰度.若知道分布有可能在峰度上偏离正态分布时,可用峰度来检验分布的正态性.3、计算方法:随机变量的峰度计算方法为:随机变量的四阶中心矩与方差平方的比值.某单位引体向上测试总体分布情况分析一、 测试成绩i X 〔单位:个〕:三月份测试成绩:8、8、10、7、11、14、6、5、7、7、9、10、12、4、6、8、7、11、8、9、10、12、9、8、6、5、8、9、5、8、8、10、8、11五月份测试成绩:4、10、9、4、11、6、8、9、7、11、12、7、9、6、10、8、9、7、8、14、12、9、8、7、8、9、5、7、8、10、8、5、6、8、14二、数据分析:三月份:样本容量:35n =样本方差:13.34602五月份:样本容量:35m =样本方差:14.14776三、图像:如上图所示,其中横轴为引体向上的个数,纵轴为达到相同个数的频数. 由上图可以发现,三月份我单位成员引体向上测试总体分布情况服从28.352941,13.34602σμ==的正态分布;五月份我单位成员引体向上测试总体分布情况服从28.371429,14.14776σμ==的正态分布.四、假设检验:现给定显著性水平0.05α=,进行假设检验.提出原假设:00:H μμ= ()0,1N 2113.34602s =,2214.14776s =.所以统计量的值。
偏度和峰度的定义

偏度和峰度的定义偏度和峰度这俩概念啊,就像是描述数据这个大家庭里成员特征的特殊标签。
咱先来说说偏度。
偏度就好比是在看一群人的身材是不是对称的。
如果数据的分布就像一个完美对称的人,左右两边完全一样,那这个偏度就是0。
你看,正态分布就是这样一个完美的例子,就像一个身材超级匀称的模特,各个部分都恰到好处地分布着。
要是偏度大于0呢,就像这个人左边瘦右边胖,大部分的数据都集中在右边,左边拖着一个长长的尾巴,这种分布就有点奇怪了,就像那些设计很奇特的不对称的衣服,只有少数人能欣赏得来。
而偏度小于0的时候,就反过来了,右边瘦左边胖,数据大多集中在左边,右边有个小尾巴。
这就像有些房子,左边盖得很大很满,右边就剩个小角落似的。
你说这偏度是不是很有趣,它就像一个数据的身材裁判,告诉我们数据分布是不是歪了。
再讲讲峰度。
峰度呢,就像是在评判一座山的尖峭程度。
正态分布的峰度是3,如果数据的峰度比3大,那就像是一座超级尖峭的山,山尖又高又窄,数据在中间集中得特别厉害,周围的坡度很陡。
这就好比那些专业登山运动员挑战的高峰,不是一般人能轻易攀登的。
要是峰度小于3呢,就像一座比较平缓的山,数据分布得比较散,没有那么集中在中间,就像我们平时散步能轻松走上去的小山坡。
咱举个实际的例子吧。
比如说学生的考试成绩。
如果成绩的分布偏度是0,那就是说高分和低分的人数差不多,就像一个班级里,学得好和学得不太好的同学数量比较均衡。
要是偏度大于0呢,可能就是低分的同学比较少,大部分同学成绩都比较高,就像一个学霸班,只有少数几个同学稍微落后一点。
那峰度呢,如果峰度比较大,说明成绩都集中在某个分数段附近,可能是这个考试比较简单,大家都考得差不多。
如果峰度小,那就是成绩分布得比较散,有考得特别高的,也有考得特别低的,中间分数段的人反而没那么多,就像这个考试题目特别难或者特别容易区分学生水平。
偏度和峰度这两个概念啊,虽然听起来有点复杂,但其实就是我们了解数据分布特征的两个小助手。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
人们经常用偏度、峰度来描述随机变量或一组数据的分 布形状, 但在教学和实践中对这两个概念的认识上常常存在 着较大的误区, 错误认识也常出现在统计学( 包括概率论与 数理统计) 方面的教科书中。
1 偏度概念的认识误区
随机变量 x 的偏度定义为
基金项目: 上海市重点学科建设资助项目( B803)
g1=
E[x- E(x)]3 [Var(x)]3/2
布。但由式( 4) 计算得到的峰度值却为g$ 2=- 0.1996, 小于正态 分布的峰度值 0。
参考文献: [1]王学民编著.应用概率统计[M].上 海 : 上 海 财 经 大 学 出 版 社 , 2005,
( 10) .
( 责任编辑/李友平)
146 统计与决策 2008 年第 12 期( 总第 264 期)
设 x1,…,xn 是 一 组 样 本 数 据 或 一 组 有 限 总 体 数 据 , 则 其
峰度的计算公式为
n
! g$ 2=
(n-
n(n+1) 1)(n- 2)(n-
3)s4
i
=
1
(xi-
x)4-
3
(n- 1)2 (n- 2)(n-
3)
( 4)
其中 x 和 s 的含义同前。
在统计学( 包括概率论与数理统计) 教科书中经常看到
表 3 中给出了通过不同评估方法得到的结果, 从数据对
比看出: 采用本文方法所估计的测量不确定度精度优于其它
三 种 方 法 。本 文 得 到 的 结 果 同 样 还 可 以 作 为 以 后 计 算 测 量 结
果的先验信息。
表3 评估方法 计算结果
不同评估方法的结果比较( mm)
A 类评估方法 最大熵方法 贝叶斯方法
33 35 27 13 16 53 61 11 33 70
46 45 53 20 35 33 10
6
24 80
75 77 70 44 60 12 72 53 77 54
49 11 11 20 18 21 21 35 28 84
例1 图1和
图 2 是容量均为
100 的 两 组 数 据 ( 数
据见 表 1) 的 频 数 直
( 责任编辑/浩 天)
统计与决策 2008 年第 12 期( 总第 264 期) 145
知识丛林
个方向上的尾部有拉长趋势的程度。因此,
正 ( 负) 偏度往往更多反映的是分布在右
( 左) 方向的尾部比在左( 右) 方向的尾部有
拉长的趋势。
设 x1, …,xn 是来自总体 x 的一个样本 , 则总体 x 的偏度可估计为
没有量纲的数值。峰度 g2 的取值范围是[ - 2,∞] 。正态分布的 峰度为零。人们以正态分布为标准, 若 g2>0, 则说明随机变量 X 分 布 的 尾 部 比 正 态 分 布 的 尾 部 粗 , 并 且 g2 值 越 大 , 倾 向 认 为 尾 部 越 粗 ; 若 g2<0, 则 说 明 X 分 布 的 尾 部 比 正 态 分 布 的 尾 部细, 且|g2|值越大, 倾向认为尾 部 越 细 。 峰 度 g2 可 用 来 比 较 已标准化了的各随机变量分布的尾部厚度。
尾, 图 1 分布的右尾较图 2 离均值更远) 。本例说明了将偏度
描述为反映分布在众 数两边的对称偏斜性 的一个量是欠妥当 的。
2 峰度概念的
认识误区
图3
峰度是另一个反映随机变量分布形状的量, 随机变量 x
的峰度定义为
g2=
E[x- E(x)]4 [Var(x)]2
-3
( 3)
它度量了分布尾部的厚度。同偏度一样, 峰度也是一个
[J]. 北京航空航天大学学报,2006, 32(11). [8]PK. Li and B. Liu. The entropy of fuzzy variables. In Proceed-
ings of the Fourth International Conference on In formation and Management Science ,Kunming, China, 2005. [9]Eulalia Szmidt, Janusz Kacprzyk. Entropy for intuitionistic fuzzy set[J]. Fuzzy Set and Systems,2001, 118(3).
y:
35 72 49 48
9
21 44 18 26 30
7
14
6
36 23 37 72 40 16 50
35 19 24 35 17 54 50 40 13 48
30
8
10 109 41 17 66 56 47 53
58 36 10 28 13 30 63 79 17 76
55 101 42 25 27 17 29 65 19 15
参考文献: [1]王中宇, 张海滨, 刘智敏. 测量不确定度最大残差系数的一种新算
法[J]. 计量学报, 2006, 27(3). [2]国家质量技术监督局. 测量不确定 度 评 定 与 表 示 指 南[M]. 北 京 :
中国计量出版社 2000. [3]吴乃龙, 袁素云. 最大熵方法. 长沙: 湖南科学技术出版社, 1991. [4]薄晓静, 陈晓怀. 基于贝叶斯理论的测量不确定度 A 类评定[J]. 工
将 峰 度 描 述 为 反 映 分 布 在 众 数 附 近 “峰 ”的 尖 峭 程 度 的 一 个
量。事实上, 这种说法是错误的, 我们可以通过下面的例 2 看
清这一点。
例 2 图 3 是将 150 个数据( 数据见表 2) 经标准化后画
出的密度直方图, 并拟合上了标准正态密度曲线。从图中可
以 看 出 , 分 布 在 众 数 附 近 “峰 ”的 尖 峭 程 度 要 远 高 于 正 态 分
测量结果可表示为:
70.24
x= ∫ x·f(x)·dx
(16)
69.84
将 已 知 数 据 代 入 式 (16)得 :
x=69.9887mm
测量结果的标准不确定度可表示为:
# u=
70.24
∫
(x-
x" )2·f(x)·dx
69.84
(17)
将 已 知 数 据 代 入 式 (17)得 :
u=0.1468mm
n
n
! # ! 其中
x= 1 n
i
xi 是样本均值,
=1
s=
1 n- 1
i=
(xi- x")2
1
是样
本标准差。若 n 个数据 x1,…,xn 组成一个有限总体, 则该总体
的偏度也按式( 2) 计算。本文后面的计算结果及图形都是使
用 SAS9 的 INSIGHT 菜单子系统得到的。
表1
x:
36.9 36.8 43.2 22.4 15.7 32.9 25.4 15.2 33.7 26.2
布在众数两边的对称偏斜性, 国内有许多统计教科书就是这
样写的。实际上, 分布在众数两边的对称偏斜性对偏度值的
影响是比较有限的, 对偏度值影响较大的倒是分布在其中一
4.2 测量不确定度的计算
由上所述, 求得被测量后验信息的概率密度函数以后,
即 可 利 用 式 (16)和 (17)求 出 测 量 结 果 的 估 计 值 及 其 不 确 定 度 。
知识丛林
偏度和峰度概念的认识误区
王学民
( 上海财经大学 统计系, 上海 200439)
摘 要: 偏度和峰度的概念常常引起误解, 甚至这种误解也常出现在概率统计的教科书中。文章 对这两个概念的理解做了准确的阐述, 并列举了两个例子来分别说明两个概念的认识误区。
关键词: 偏度; 峰度; 认识误区 中图分类号: O212.2 文献标识码: A 文章编号: 1002- 6487( 2008) 12- 0145- 02
34.3 43.5 32
7 36.9 32.3 25.4 27.4 19.3 21.3
32.1 45.2 15.2 34.4 39.5 32.7 9.7 40.6 32.4 33.2
37.5 47.9 22.7 13.5 29.7 32.4 35.9 38.6 26.6 42.7 3.7 36.1 33.2 47.3 33.3 38.7 38.8 32.1 41.8 27 38.4 35.1 24.8 22.1 37 37.8 40.4 26.4 38.8 42.8 45.3 33 43.9 35.2 24 7.9 17.1 22.5 39 60 29.6 40.6 17.9 34.8 34.6 30.7 45 24.7 16.7 70 34.2 37.2 28.2 14.2 51.5 33 43.7 11.2 54.9 90 41.3 24.9 45.4 9.3 32.4 36.1 39.5 40.8 35.1 130
0.1579
0.1562
0.1724
本文方法 0.1468
5 结论
本文提出了一种基于最大熵方法的测量不确定度贝叶 斯 评 估 模 型 。该 模 型 将 最 大 熵 和 贝 叶 斯 两 种 方 法 的 优 点 有 机
结合, 其中采用最大熵方法确定样本信息的概率密度函数含 有较少的主观假设, 贝叶斯评估充分利用了先验信息, 评估 方法合理。采用本文方法所计算的测量不确定度可靠性高, 精度优于其它方法。
( 1)
它度量了分布的偏斜程度及偏向, 是一个无量纲的数
值 。 若 g1>0, 则 称 x 的 分 布 是 正 偏 ( 或 右 偏 ) 的 ; 若 g1<0,则 称 x 的分布是负偏( 或左偏) 的。|g1|越大, 说明分布偏斜得越厉 害 。偏 度 常 常 习 惯 地 被 不 太 确 切 地 认 为 是 反 映 了 随 机 变 量 分