【原创】R语言通过ARIMA建模进行预测研究实例 报告(附代码数据)
r语言arimax代码实例

r语言arimax代码实例
在R语言中,你可以使用`forecast`包中的`auto.arima`函数来拟合ARIMA模型。
以下是一个简单的例子:
```r
# 安装和加载必要的包
install.packages("forecast")
library(forecast)
# 创建一个ARIMA模型
# 我们使用auto.arima函数,它会自动选择最佳的ARIMA模型参数
fit <- auto.arima(your_time_series_data)
# 显示模型的参数
summary(fit)
# 使用模型进行预测
forecasts <- forecast(fit, h = 10) # h是预测的步数
# 显示预测结果
print(forecasts)
```
在这个例子中,你需要将`your_time_series_data`替换为你实际的时间序列数据。
你可以使用`ts()`函数将数据转换为时间序列格式。
例如,如果你的数据在名为`data`的dataframe中,你可以这样写:```r
your_time_series_data <- ts(data$your_column)
```
然后,你可以使用`auto.arima`函数来拟合ARIMA模型,并使用`forecast`函数来生成预测。
【原创】R语言时间序列arima和随机森林模型预测分析报告(附代码数据)
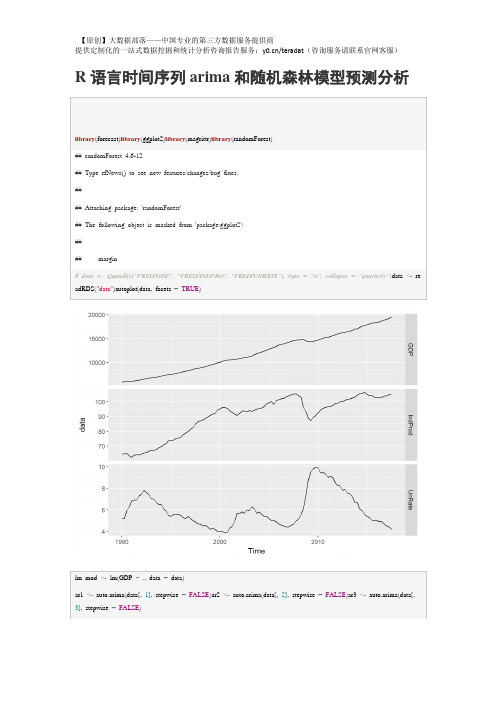
##
## Model df: 4. Total lags used: 8
checkresiduals(lm_mod)
##
## Breusch-Godfrey test for serial correlation of order up to 10
## Q* = 2.2891, df = 5, p-value = 0.8079
##
## Model df: 3. Total lags used: 8
checkresiduals(arireg)
##
## Ljung-Box test
##
## data: Residuals from Regression with ARIMA(2,2,1) errors
lm_mod<-lm(GDP~.,data=data)
ar1<-auto.arima(data[,1],stepwise=FALSE)ar2<-auto.arima(data[,2],stepwise=FALSE)ar3<-auto.arima(data[,3],stepwise=FALSE)
GDP<-forecast(ar1)$meanIndProd<-forecast(ar2)$meanUnRate<-forecast(ar3)$meanf3<-cbind(IndProd,UnRate)arireg<-auto.arima(data[,1],stepwise=FALSE,xreg=data[,-1])
summary(lm_mod)
##
## Call:
## lm(formula = GDபைடு நூலகம் ~ ., data = data)
R 语言环境下用ARIMA模型做时间序列预测
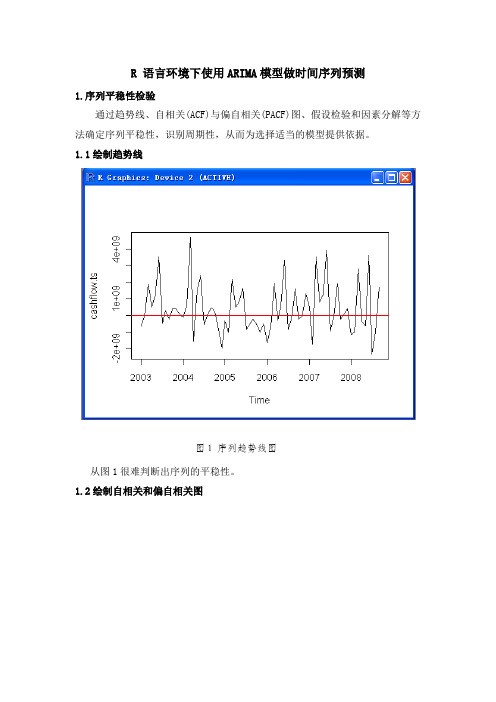
R 语言环境下使用ARIMA模型做时间序列预测1.序列平稳性检验通过趋势线、自相关(ACF)与偏自相关(PACF)图、假设检验和因素分解等方法确定序列平稳性,识别周期性,从而为选择适当的模型提供依据。
1.1绘制趋势线图1 序列趋势线图从图1很难判断出序列的平稳性。
1.2绘制自相关和偏自相关图图2 序列的自相关和偏自相关图从图2可以看出,ACF拖尾,PACF1步截尾(p=1),说明该现金流时间序列可能是平稳性时间序列。
1.3 ADF、PP和KPSS 检验平稳性图3 ADF、PP和KPSS检验结果通过ADF检验,说明该现金流时间序列是平稳性时间序列(p-value for ADF test <0.02,拒绝零假设).pp test和kpss test 结果中的警告信息说明这两种检验在这里不可用。
但是这些检验没有充分考虑趋势、周期和季节性等因素。
下面对该序列进行趋势、季节性和不确定性因素分解来进一步确认序列的平稳性。
1.4 趋势、季节性和不确定性因素分解R 提供了两种方法来分解时间序列中的趋势、季节性和不确定性因素。
第一种是使用简单的对称过滤法,把相应时期内经趋势调整后的观察值进行平均,通过decompose()函数实现,如图4。
第二种方法更为精确,它通过平滑增大规模后的观察值来寻找趋势、季节和不确定因素,利用stl()函数实现。
如图5。
图4 decompose()函数分解法图5 stl()函数分解法两种方法得到的结果非常相似。
从上图可以看出,该现金流时间序列没有很明显的长期趋势。
但是有明显的季节性或周期性趋势,经分解后的不确定因素明显减少。
综上平稳性分析检验,我们选用包含季节性因素的S-ARIMA模型来预测现金流时间序列。
2.S-ARIMA模型2.1 建立SARIMA模型在R 软件包中包含auto.arima()、expand.grid() 等函数,针对p,d,q 众多的可能取值,可以通过expand.grid()建立所有的可能参数组合,用for()条件函数代入相应的arima()模型,把结果储存在BIC当中。
基于R语言的我国甘蔗产量ARIMA模型建立与预测分析

基于R语言的我国甘蔗产量ARIMA模型建立与预测分析作者:郝小玲梁春庞新华朱鹏锦严霖黄强龙凌云来源:《绿色科技》2016年第12期摘要:采用时间序列预测法对我国甘蔗产量预测问题进行了研究。
以国家统计局1965~2012年间我国历年甘蔗产量统计数据为基础,依据自回归积分滑动平均(ARIMA)模型理论,运用R语言建立了ARIMA模型对我国未来甘蔗产量进行了预测。
数据检验显示:该模型拟合效果较好,预测精度较高,表明运用该模型对我国甘蔗产量的变化趋势进行了分析及预测是可行的,具有较高的实际应用价值。
分析了该模型所得预测结果,对我国甘蔗产业未来发展的可预见性趋势与风险提供了应对建议。
关键词:R语言;甘蔗产量;ARIMA模型;预测中图分类号:C32文献标识码:A文章编号:16749944(2016)120257041引言我国是世界第三大产糖国和第一大原糖进口国,据联合国粮农组织(FAO)2013年数据统计,我国产糖量约占全球食糖总产的8 %,原糖进口量约占贸易总量的12 %[1,2]。
其中,蔗糖是我国食糖来源的主体。
近年来由于我国甘蔗主产区生产技术水平较低,品种退化严重,综合利用不完善,政策扶持力度不够以及农民种蔗积极性降低等因素,我国甘蔗生产呈萎缩态势[3,4]。
因此,亟待对甘蔗生产未来发展趋势进行预测,从而制定有效的对策,把握市场供求关系,进而保护相关企业及种植户利益,这将对优化我国甘蔗产业的综合发展产生现实影响。
通过研究我国甘蔗生产发展的变动规律并对其产量预测,对甘蔗产业发展的变化趋势进行分析与归纳,为提前防范和应对产业风险提供更有针对性的依据,使甘蔗生产更适应市场经济发展要求,将进一步推动我国甘蔗产业的健康发展。
2我国甘蔗产业发展现状甘蔗(Saccharum officinarum)是禾本科甘蔗属植物,原产于南亚与东南亚地区,在33°N-33°S之间地区均有分布,22°N-22°S范围内面积较为集中[5]。
基于R语言的负荷预测ARIMA模型并行化研究

y
|
(4)
s2
= 1-|
y¢ - y y max - max(s1,s 2 )
(6)
式中:s1、s2、s表示预测的准确率;y 表示负荷的 真实值;y¢是预测值;ymax 和 ymin 分别是 y 的最大值 和最小值。s越大,表示预测结果越准确。
3218
麦鸿坤等:基于 R 语言的负荷预测 ARIMA 模型并行化研究
工程化和运行效率的要求,需要实现算法的并 行化[9]。由于在数据存储中已经使用到分布式技术, 因此可以将程序分别部署在不同的服务器上。而对
第 39 卷 第 11 期
电网技术
3217
于同一用户的不同时间的采集点数据,则使用基于 线程的 ARIMA 并行来处理。
区别于以往使用 ARIMA 模型对负荷进行具体 分析和预测[4,6],本文目的在于从工程化角度出发, 研究基于 R 语言的负荷预测 ARIMA 模型并行化的 具体实现。首先介绍 ARIMA 模型建模的一般过程, 通过 R 语言与 JAVA 之间的交互,完成了 ARIMA 模型的串行算法。然后,根据负荷数据特点,进行 数据划分,实现了算法的并行化。最后以安徽地区 随机获取的用户电力负荷进行了测试,结果表明所 提算法准确率好,代码执行效率高。
KEY WORDS: power load prediction; ARIMA; JAVA; R language; parallelization
摘要:自回归求和移动平均(autoregressive integrated moving average,ARIMA)模型常在 R 语言环境下被用于电力负荷数 据的分析和预测。然而,面对海量数据背景下的工程应用, R 环境下 ARIMA 模型的运行效率无法达到令人满意的程度。 针对此问题,通过 JAVA 与 R 的实时通信,充分利用 JAVA 丰富的开源资源与 R 强大的统计计算功能,在 JAVA 中进行 程序的逻辑判断,在 R 中进行数值计算,采用混合编程, 最后完成 ARIMA 模型接口的封装,实现了基于负荷数据预 测的 ARIMA 模型的串行化程序。在串行程序完成的基础上, 根据电力负荷特性,对数据进行划分,结合 JAVA 多线程技 术,实现了 ARIMA 模型的并行化。最后,结合文中提出的
使用R语言进行时间序列(arima,指数平滑)分析

使用R语言进行时间序列(arima,指数平滑)分析读时间序列数据您要分析时间序列数据的第一件事就是将其读入R,并绘制时间序列。
您可以使用scan()函数将数据读入R,该函数假定连续时间点的数据位于包含一列的简单文本文件中。
数据集如下所示:••••••••••••••••Age of Death of Successive Kings of England#starting with William the Conqueror#Source: McNeill, "Interactive Data Analysis"604367505642506568436534...仅显示了文件的前几行。
前三行包含对数据的一些注释,当我们将数据读入R时我们想要忽略它。
我们可以通过使用scan()函数的“skip”参数来使用它,它指定了多少行。
要忽略的文件顶部。
要将文件读入R,忽略前三行,我们键入:•••> kings[1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48[26] 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56在这种情况下,英国42位连续国王的死亡年龄已被读入变量“国王”。
一旦将时间序列数据读入R,下一步就是将数据存储在R中的时间序列对象中,这样就可以使用R的许多函数来分析时间序列数据。
要将数据存储在时间序列对象中,我们使用R中的ts()函数。
例如,要将数据存储在变量'kings'中作为R中的时间序列对象,我们键入:••••••Time Series:Start = 1End = 42Frequency = 1[1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48[26] 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56有时,您所拥有的时间序列数据集可能是以不到一年的固定间隔收集的,例如,每月或每季度。
r语言时间序列预测实例 -回复
r语言时间序列预测实例-回复R语言时间序列预测实例本文将以R语言为工具,介绍一个时间序列预测的实例。
我们将从数据收集、数据处理、建模和预测等几个步骤来进行讲解。
第一步:数据收集首先,我们需要收集一组时间序列数据。
本实例中,我们将使用一个公开可获得的数据集,即美国某地区的房价指数数据。
我们可以从美国统计局或房产相关网站上找到这些数据。
第二步:数据处理在开始时间序列预测之前,我们需要对数据进行处理和准备。
通常,时间序列数据在收集过程中会有一些缺失值、异常值或离群值。
因此,在进行模型训练之前,我们需要对数据进行清洗和处理。
首先,我们需要将数据导入到R中,并检查数据的完整性和一致性。
可以使用read.csv()或read.table()等函数将数据导入R。
导入数据后,我们需要对数据进行可视化,以了解数据的基本特征。
使用plot()函数可以绘制时间序列的图形,观察序列的趋势、季节性和周期性等。
如果存在缺失值或异常值,我们需要对其进行处理。
可以使用na.omit()、na.approx()或na.interp()等函数来填充缺失值,或者使用outliers()等函数来识别和处理异常值。
第三步:建模在数据处理完成后,我们可以开始进行时间序列预测建模。
进行时间序列预测的一种常用方法是使用自回归移动平均模型(ARIMA模型)。
在R中,可以使用forecast包中的auto.arima()函数来自动选择最佳ARIMA模型。
该函数会根据给定的时间序列数据和其他参数,选择出最优的ARIMA模型。
除此之外,我们还可以尝试其他的时间序列模型,如指数平滑法、季节性分解法、灰色预测法等等。
根据实际情况和数据特点,选择合适的模型进行预测。
第四步:预测构建好ARIMA模型后,我们可以使用模型对未来的数据进行预测。
在R 中,可以使用forecast包中的forecast()函数来进行预测。
使用forecast()函数可以得到模型的预测结果,包括预测值、置信区间和预测误差等。
R语言季节性arima模型案例附代码数据
R语言季节性arima模型案例代码数据文件sales.csv提供公司季度销售数据。
为这些数据构建时间序列图。
描述数据。
data=read.csv("sales.csv")head(data)## sales## 1 105715## 2 120136## 3 181669## 4 239813## 5 159980## 6 164760plot(as.numeric(data[,1]),type="l")# 分解为趋势和季节成分# 从数据来看,有明显得波动趋势,因此可能存在季节性趋势,需要进行季节性差分。
# 计算趋势(使用适当的移动平均线)和季节性成分。
将时间趋势,季节性因素和剩余序列与时间对应,并对您的地块进行评论。
kingstimeseries <-ts(as.numeric(data[,1]),frequency =12)kingstimeseries## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec## 1 3 8 19 25 14 15 24 29 21 23 28 33## 2 26 27 31 37 30 32 36 41 34 35 39 44## 3 38 40 47 50 42 43 51 55 45 46 54 4## 4 48 49 56 9 52 53 7 13 5 6 12 16## 5 10 11 18 22 17 20 2 1kingstimeseriescomponents <-decompose(kingstimeseries)kingstimeseriescomponents$seasonal # get the estimated values of the s easonal component## Jan Feb Mar Apr May Jun ## 1 -1.1649306 0.6059028 7.7934028 -4.4149306 5.3767361 7.1684028 ## 2 -1.1649306 0.6059028 7.7934028 -4.4149306 5.3767361 7.1684028 ## 3 -1.1649306 0.6059028 7.7934028 -4.4149306 5.3767361 7.1684028 ## 4 -1.1649306 0.6059028 7.7934028 -4.4149306 5.3767361 7.1684028 ## 5 -1.1649306 0.6059028 7.7934028 -4.4149306 5.3767361 7.1684028 ## Jul Aug Sep Oct Nov Dec ## 1 -2.1753472 2.7204861 -5.5503472 -4.2586806 1.4913194 -7.5920139 ## 2 -2.1753472 2.7204861 -5.5503472 -4.2586806 1.4913194 -7.5920139 ## 3 -2.1753472 2.7204861 -5.5503472 -4.2586806 1.4913194 -7.5920139 ## 4 -2.1753472 2.7204861 -5.5503472 -4.2586806 1.4913194 -7.5920139 ## 5 -2.1753472 2.7204861plot(kingstimeseriescomponents)# 从差分图来看,数据有明显得季节趋势,需要进行季节性差分。
【原创】R语言案例数据分析可视化报告 (附代码数据)
R语言案例数据分析可视化报告这个问题集的目标是让你参与到R中的一些活动中,并且在欣赏数据可视化的重要性的同时进行一个深思熟虑的练习。
对于每个问题,创建一个代码块或文本响应,完成/回答所请求的活动或问题。
Questions计算每列的均值,方差和每对之间的相关性library(ggplot2)library(GGally)library(fBasics)## Loading required package: timeDate## Loading required package: timeSeries#### Rmetrics Package fBasics## Analysing Markets and calculating Basic Statistics## Copyright (C) 2005-2014 Rmetrics Association Zurich## Educational Software for Financial Engineering and Computational Science## Rmetrics is free software and comes with ABSOLUTELY NO WARRANTY.basicStats(data, ci = 0.95)## x1 x2 x3 x4 y1 y2## nobs 11.000000 11.000000 11.000000 11.000000 11.000000 11.000000## NAs 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000## Minimum 4.000000 4.000000 4.000000 8.000000 4.260000 3.100000## Maximum 14.000000 14.000000 14.000000 19.000000 10.840000 9.260000## 1. Quartile 6.500000 6.500000 6.500000 8.000000 6.315000 6.695000## 3. Quartile 11.500000 11.500000 11.500000 8.000000 8.570000 8.950000## Mean 9.000000 9.000000 9.000000 9.000000 7.500909 7.500909## Median 9.000000 9.000000 9.000000 8.000000 7.580000 8.140000## Sum 99.000000 99.000000 99.000000 99.000000 82.510000 82.510000## SE Mean 1.000000 1.000000 1.000000 1.000000 0.612541 0.612568## LCL Mean 6.771861 6.771861 6.771861 6.771861 6.136083 6.136024## UCL Mean 11.228139 11.228139 11.228139 11.228139 8.865735 8.865795## Variance 11.000000 11.000000 11.000000 11.000000 4.127269 4.127629 ## Stdev 3.316625 3.316625 3.316625 3.316625 2.031568 2.031657## Skewness 0.000000 0.000000 0.000000 2.466911 -0.048374 -0.978693## Kurtosis -1.528926 -1.528926 -1.528926 4.520661 -1.199123 -0.514319 ## y3 y4## nobs 11.000000 11.000000## NAs 0.000000 0.000000## Minimum 5.390000 5.250000## Maximum 12.740000 12.500000## 1. Quartile 6.250000 6.170000## 3. Quartile 7.980000 8.190000## Mean 7.500000 7.500909## Median 7.110000 7.040000## Sum 82.500000 82.510000## SE Mean 0.612196 0.612242## LCL Mean 6.135943 6.136748## UCL Mean 8.864057 8.865070## Variance 4.122620 4.123249## Stdev 2.030424 2.030579## Skewness 1.380120 1.120774## Kurtosis 1.240044 0.628751cor(data, use="complete.obs", method="kendall")## x1 x2 x3 x4 y1 y2## x1 1.00000000 1.00000000 1.00000000 -0.4264014 0.6363636 0.56363636 ## x2 1.00000000 1.00000000 1.00000000 -0.4264014 0.6363636 0.56363636 ## x3 1.00000000 1.00000000 1.00000000 -0.4264014 0.6363636 0.56363636 ## x4 -0.42640143 -0.42640143 -0.42640143 1.0000000 -0.4264014 -0.42640143 ## y1 0.63636364 0.63636364 0.63636364 -0.4264014 1.0000000 0.56363636 ## y2 0.56363636 0.56363636 0.56363636 -0.4264014 0.5636364 1.00000000 ## y3 0.96363636 0.96363636 0.96363636 -0.4264014 0.6000000 0.60000000 ## y4 -0.09090909 -0.09090909 -0.09090909 0.4264014 -0.1636364 -0.01818182 ## y3 y4## x1 0.96363636 -0.09090909## x2 0.96363636 -0.09090909## x3 0.96363636 -0.09090909## x4 -0.42640143 0.42640143## y1 0.60000000 -0.16363636## y2 0.60000000 -0.01818182## y3 1.00000000 -0.05454545## y4 -0.05454545 1.00000000ggcorr(data, geom = "blank", nbreaks = 5, label = TRUE,palette = "RdYlBu", hjust = .75)+geom_point(size = 10, aes(color = coefficient > 0, alpha = abs(coefficient) > 0.4)) +scale_alpha_manual(values = c("TRUE" = 0.25, "FALSE" = 0)) +guides(color = FALSE, alpha = FALSE)3.为每个x,yx,y数据对创建散点图。
基于R语言ARIMA模型在慢阻肺急性加重患者发病预测中
回归积分滑动平均模型( a u t o r e g r e s s i v ei n t e g r a t e dm o v , 简称 A R I MA ) , 探讨慢阻肺急性加 i n ga v e r a g em o d e l 重入院人次的变化规律。 R语言是一种为统计计算和绘图而生的语言和环 境, 它是一套开源的数据分析解决方案, 由一个庞大且
统计功能 R语言的用户贡献了大量优秀的包( p a c k a g e ) 。本文采用 R语言作为统计分析的工具。 资料与方法 1 资料来源 从某 院 病 案 首 页 信 息 管 理 系 统 中 检 索 2 0 1 3- 2 0 1 5年出院第一诊断为慢阻肺急性加重( I C D- 1 0编
4 ] 码为 J 4 4 1 ) 的病人为研究对象 [ , 以每月的入院人次
·2 8 8 ·
中国卫生统计 2 0 1 7年 4月第 3 4卷第 2期
基于 R语言 A R I MA模型在慢阻肺急性加重患者 发病预测中的应用
成都市第三人民医院信息部( 6 1 0 0 3 1 ) ㊀郭慧敏㊀杜㊀军 ㊀黄路非
△
㊀㊀【 提㊀要】 ㊀目的㊀建立慢阻肺急性加重入院人次的自回归积分滑动平均模型( A R I MA ) , 科学预测慢阻肺急性加重 入院人次, 为该病的诊治以及合理利用医疗资源提供理论依据。方法㊀使用 R语言( v 3 2 3 ) 做模型的识别、 模型的参数 估计与检验, 建立 A R I MA模型, 对某院 2 0 1 3- 2 0 1 5年慢阻肺急性加重出院人次进行模型拟合, 用2 0 1 6年 1 3月的预测 值与实际值作比较, 检验模型的预测能力, 并且预测 2 0 1 6年 4- 6月慢阻肺急性加重入院人次。 结果 ㊀ 经过多次检验, 确 定A R I MA ( 2 , 2 , 1 ) ( 1 , 1 , 1 ) 模型预测能力最佳, 其残差序列是白噪声。用 2 0 1 6 年 1 3 月数据来检验模型, 其 MA P E 的 1 2 0 %, 说明模型的拟合优度相对较好, 预测能力可靠, 根据该模型预测 2 0 1 6年 4 6月该院慢阻肺急性加重 绝对值均小于 1 入院人次分别为 1 6 2 、 1 6 0 、 1 5 9 。结论㊀A R I MA模型能够很好的拟合慢阻肺急性加重的入院人次并进行短期预测, 模型显 示2 0 1 6年该院的急性支气管炎的入院人次将有所上升, 为医院合理利用医疗资源提供了有力依据。 【 关键词】 ㊀R语言㊀慢阻肺急性加重㊀预测㊀回归滑动平均混合模型
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
本文是我们通过时间序列和ARIMA模型预测拖拉机销售的制造案例研究示例的延续。
您可以在以下链接中找到以前的部分:
第1部分:时间序列建模和预测简介
第2部分:在预测之前将时间序列分解为解密模式和趋势
第3部分:ARIMA预测模型简介
在本部分中,我们将使用图表和图表通过ARIMA预测PowerHorse拖拉机的拖拉机销售情况。
我们将使用前一篇文章中学到的ARIMA建模概念作为我们的案例研究示例。
但在我们开始分析之前,让我们快速讨论一下预测:
诺查丹玛斯的麻烦
人类对未来和ARIMA的痴迷 - 由Roopam撰写
人类对自己的未来痴迷- 以至于他们更多地担心自己的未来而不是享受现在。
这正是为什么恐怖分子,占卜者和算命者总是高需求的原因。
Michel de Nostredame(又名Nostradamus)是一位生活在16世纪的法国占卜者。
在他的着作Les Propheties (The Prophecies)中,他对重要事件进行了预测,直到时间结束。
诺查丹玛斯的追随者认为,他的预测对于包括世界大战和世界末日在内的重大事件都是不可挽回的准确。
例如,在他的书中的一个预言中,他后来成为他最受争议和最受欢迎的预言之一,他写了以下内容:
“饥饿凶猛的野兽将越过河流
战场的大部分将对抗希斯特。
当一个德国的孩子什么都没有观察时,把
一个伟大的人画进一个铁笼子里
【原创】定制代写开发r/python/spss/matlab/WEKA/sas/sql/C++/stata/eviews数据挖掘和统计分析可视化调研报告/程序/PPT等/爬虫数据采集服务(附代码数据),咨询QQ:3025393450
有问题到百度搜索“大数据部落”就可以了
欢迎登陆官网:/teradat
他的追随者声称赫斯特暗指阿道夫希特勒诺查丹玛斯拼错了希特勒的名字。
诺查丹玛斯预言的一个显着特点是,他从未将这些事件标记到任何日期或时间段。
诺查丹玛斯的批评者认为他的书中充满了神秘的专业人士(如上所述),他的追随者试图强调适
合他的写作。
为了劝阻批评者,他的一个狂热的追随者(基于他的写作)预测了1999年7月世界末日的月份和年份 - 相当戏剧化,不是吗?好吧当然,1999年那个月没有发生任何惊天动地的事情,否则你就不会读这篇文章。
然而,诺查丹玛斯将继续成为讨论的话题,因为人类对预测未来充满了痴迷。
时间序列建模和ARIMA预测是预测未来的科学方法。
但是,你必须记住,这些科学技术也不能免受力量拟合和人类偏见。
在这个说明中,让我们回到我们的制造案例研究示例。
ARIMA模型 - 制造案例研究示例
回到我们的制造案例研究示例,您可以帮助PowerHorse拖拉机进行销售预测,以管理他们的库存和供应商。
本文的以下部分以图形指南的形式表示您的分析。
您可以在以下链接Tractor Sales中找到PowerHorse的MIS团队共享的数
据。
您可能希望分析此数据以重新验证将在以下部分中执行的分析。
现在,您已准备好开始分析,以预测未来3年的拖拉机销售情况。
步骤1:将拖拉机销售数据绘制为时间序列
首先,您已为数据准备了时间序列图。
以下是您用于读取R中的数据并绘制时间序列图表的R代码。
1 2 data = read.csv('/blogs/wp-content/uploads/2015/06/Tractor-Sales.csv')
3
data = ts(data[,2],start = c(2003,1),frequency = 12)
plot(data, xlab='Years', ylab = 'Tractor Sales')
显然,上面的图表有拖拉机销售的上升趋势,还有一个季节性组件,我们已经分析了早期关于时间序列分解的文章。
第2步:差异数据使数据在平均值上保持不变(删除趋势)
接下来要做的是使系列静止,如前一篇文章所述。
这是通过使用以下公式对序列进行一阶差分来消除上升趋势:
第一个差异(d = 1)
用于绘制差异系列的R代码和输出显示如下:
4
plot(diff(data),ylab='Differenced Tractor Sales')
好的,所以上面的系列在方差上不是固定的,即随着我们向图表右侧移动,图中的变化也在增加。
我们需要使系列在方差上保持稳定,以通过ARIMA模型产生可靠的预
测。
步骤3:记录变换数据以使数据在方差上保持不变
使系列在方差上保持静止的最佳方法之一是通过对数变换转换原始系列。
我们将回到我们原来的拖拉机销售系列并对其进行变换以使其在变化时保持静止。
以下等式以数学方式表示对数变换的过程:
销售日志
以下是与输出图相同的R代码。
请注意,由于我们在没有差分的情况下使用原始数据,因此该系列不是平均值。
五
plot(log10(data),ylab='Log (Tractor Sales)')。