汉字编码关系
第三章汉字编码原理

㈣标调拼音码
• 汉语是有声调的语言,汉语的声调是一 个重要的“音位”,具有重要的辨义功 能。有一种乐器叫做“雷琴”,可以只 用“音高”就能模拟汉语的句子。这个 例子足以说明汉语声调的重性。
• 拼音码为了降低重码率,采用标调的办法,这 样的拼音码,我们称之为“标调拼音码”。 • 汉语的音节是有数的:不加声调只有412个, 加声调则有1300个左右。 • 汉字共有6万个。收在《基本集》中的有67 63个。 • 不加声调平均每个音节约有15个重码,加上 重码分布的不平衡,个别的音节就有几十甚至 上百个; • 如果加上声调,平均每个音节只有不到4个重 码了。
拼音编码的瓶颈
• 同音字繁多,影响输入 • 《新华字典》中,读SHI音的字有72个, • 《汉语词典》中,读YI音的字有164个。
• • • • • • • •
同音词也影响编码输入 Shi-shi的词就有如下的24条: 失实、失时、诗史、失事、 失势、施事、实施、时时、 事事、时事、时势、时世、 时式、史诗、史实、试试、 誓师、事实、适时、事势、 逝世、世事、视事、实时
• 一般的编码方案多采用26个英文字母 作码元, • 也有的在这个基础上再增加10个数目 字,使码元数增加到36个的方案, • 还有的把字母键盘区的其它功能键也利 用上的。 • 这种需要增加码元数的方案多数是形码 方案。
3、确定编码规则
• 理想的规则是“字码意义对应” 、规则简单, 好学易记,没有复杂的条件限制或特例情况。 • 实际上最难做到。 • 比如按形排序,同笔画数的字很多,同笔画的 字当中,起笔相同的也不少,甚至笔顺相同的 也有。究竟谁先谁后,难以给出一个标准。 • 按音排序也有个同音字的先后问题。同音、同 调、同笔画数的汉字再按什么条件排先后,都 是难题。 • 人为地增加许多规定,势必增加用户的学习量。
汉字国标码 (gb2312-80) 规定的汉字编码,每个汉字用

汉字国标码 (gb2312-80) 规定的汉字编码,每个汉字用概念汉字国标码 (gb2312-80) 规定的汉字编码,每个汉字用 2为每个汉字编上唯一的代码,方便计算机识别与处理。
2. 国标码1980年,我国颁布了汉字编码的标准:GB2312-80《信息交换汉字编码字符集》,简称国标码。
国标码是4位十六进制数组成。
3. 区位码GB2312是一种汉字编码方式,具体由区位码实现,GB2312将所有汉字编入一个94*94的二维表中,行和列共同定位一个字,行就是“区”,列就是“位”,合并就为区内码。
区位码是一组4位十进制的数,前两位是区码,后两位是位码。
例如:譬如“万” 字在 45 区 82 位, 所以“万” 字的区位码是: 4582.00-09 区(682个): 是符号、数字、英文字符...制表符等;10-15 区: 空白, 留待扩展;16-55 区(3755个): 常用汉字(也有叫一级汉字), 按拼音排序;56-87 区(3008个): 非常用汉字(也有叫二级汉字), 这是按部首排序的;88-94 区: 空白, 留待扩展4. 机内码机内码是微软为了解决汉字编码与ASCLL编码冲突。
从而规定把每个字节的最高位都从 0 换成 1(这之前它们都是 0),或者说把每个字节(区和位)都再加上 80H(128的十六进制表示),从而得到“机内码”,简称"内码"。
关系与转换1.三者的关系国标码 = 区位码 + 2020H;机内码 = 国标码 +8080H;2020H解释因为ASCLL码中分为控制型编码和有形字符编码,前32位是控制码(如回车,退格等),沿用前32个,覆盖后面的。
故国标码规定在区位码的基础上每个字节分别加上20H(32的十六进制表示)。
8080H解释为避免与ASCLL编码冲突,从而规定把每个字节的最高位都从0 换成 1(这之前它们都是 0),或者说把每个字节(区和位)都再加上 80H(128的十六进制表示)。
汉字的编码方式以及相应的关系

汉字的编码方式以及相应的关系汉字的编码方式以及相应的关系在当今信息时代,汉字编码方式是一个备受关注的话题。
汉字作为中文的基本表达形式,其编码方式的选择和规范对于信息技术、文化传承以及国际交流都具有重要的意义。
我们有必要对汉字的编码方式进行全面评估,并根据深度和广度的要求来探讨其相关的问题。
我们来看一下汉字的编码方式。
汉字的编码方式有多种,其中最为常见的是Unicode、GBK、Big5等。
Unicode是一个国际标准,它主要用于整合和统一世界上所有的符号和文字。
而GBK是我国最常用的字符集,它包含了大部分常用汉字和少量的生僻字,是我国计算机领域的标准。
与此相对应的是Big5编码,它是台湾地区所使用的一种传统编码方式。
这些不同的编码方式在一定程度上反映了汉字的传统与现代、国际化与本土化的关系。
进一步来说,汉字的编码方式与其发展历史、文化底蕴以及实际运用之间存在着紧密的关系。
汉字作为中国文字的代表,承载着悠久的历史和深厚的文化内涵。
其编码方式不仅仅是一种技术手段,更是对于汉字所承载的文化价值和民族认同的体现。
我们在选择和规范汉字的编码方式时,需要全面考量文化传承、技术发展和国际交流的多重需求,确保汉字得到妥善的保护和传承。
我们还需要深入思考汉字的编码方式对于教育、出版、文化创意产业等方面的影响和作用。
随着信息化技术的发展,汉字的编码方式不仅仅是影响计算机输入、网页显示等技术领域,更是对于教育教学、文学创作、文化传播等领域产生着深远的影响。
我们需要在汉字的编码方式上进行深入的评估和探讨,更好地发挥其在各个领域中的作用和效果。
在总结和回顾上述内容时,我们可以清晰地看到汉字的编码方式是一个涵盖文化、技术、教育等多个领域的综合话题。
其深度和广度不仅需要我们全面理解其相关知识和背景,更需要我们具备跨学科、跨领域的能力来进行分析和思考。
个人而言,我认为汉字的编码方式是一个值得我们深入研究和关注的话题,它不仅关乎我国的文化传承和软实力的提升,更关乎我们对于技术发展和人文精神的综合理解。
汉字编码标准
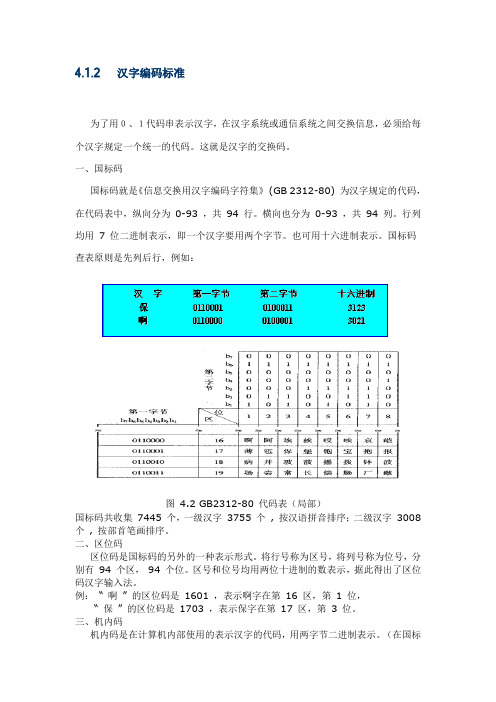
4.1.2 汉字编码标准为了用0、1代码串表示汉字,在汉字系统或通信系统之间交换信息,必须给每个汉字规定一个统一的代码。
这就是汉字的交换码。
一、国标码国标码就是《信息交换用汉字编码字符集》(GB 2312-80) 为汉字规定的代码,在代码表中,纵向分为0-93 ,共94 行。
横向也分为0-93 ,共94 列。
行列均用7 位二进制表示,即一个汉字要用两个字节。
也可用十六进制表示。
国标码查表原则是先列后行,例如:图 4.2 GB2312-80 代码表(局部)国标码共收集7445 个,一级汉字3755 个, 按汉语拼音排序;二级汉字3008 个, 按部首笔画排序。
二、区位码区位码是国标码的另外的一种表示形式。
将行号称为区号,将列号称为位号,分别有94 个区,94 个位。
区号和位号均用两位十进制的数表示,据此得出了区位码汉字输入法。
例:“ 啊” 的区位码是1601 ,表示啊字在第16 区,第 1 位,“ 保” 的区位码是1703 ,表示保字在第17 区,第 3 位。
三、机内码机内码是在计算机内部使用的表示汉字的代码,用两字节二进制表示。
(在国标码每个字节前添1 就是机内码,添1 是为了确保与英文字符区分开)。
输入汉字→国标码( 区位码) →机内码→存储转换关系:十六进制的区位码+ 2020H →国标码十六进制的国标码+ 8080H →机内码8080H 等于二进制的l000000010000000 ,国标码加上8080H ,可以保证机内码每个字节首位均为 1 。
例:“ 啊” 的区位码是:1601 转换成十六进制10011001 +2020=3021 (国标码)再转换成机内码:3021+8080=B0A1二进制表示为1011000010100001 (B0A1 )中山市港口理工学校计算机科温金辉。
简述汉字的4种编码

简述汉字的4种编码汉字作为世界上最古老的文字之一,有着悠久的历史。
为了方便计算机处理和传输汉字,人们设计了多种编码方式。
下面将简述汉字的主要四种编码。
1. ASCII编码(American Standard Code for Information Interchange,美国信息交换标准代码):ASCII是最早的一种字符编码,用于表示拉丁字母和一些常用符号。
由于最初是由美国发明的,所以只包含128个字符,包括大小写字母、数字、标点符号等。
ASCII编码对于汉字是不适用的,因此在中国不能完整地表示汉字。
2. GB2312编码:GB2312是中国国家标准局于1980年发布的汉字编码标准,它是一种双字节编码,用于表示汉字和少量非汉字字符。
GB2312编码共收录了7445个常用汉字和682个非汉字字符。
GB2312编码是汉字的首次正式编码,为后来的汉字编码奠定了基础。
3. GBK编码:GBK是GB2312编码的扩展,由中国国家标准局于1995年发布。
GBK编码兼容GB2312,并进一步扩展了汉字字符集,收录了21003个汉字和8829个非汉字字符。
GBK编码是目前广泛使用的汉字编码,支持绝大多数汉字字符。
4. Unicode编码:Unicode是国际标准化组织(ISO)制定的一种字符编码标准,用于表示全球范围内的所有字符。
Unicode编码采用了固定的编码格式,可以表示从汉字到其他任何文字的字符。
Unicode编码采用不同的实现方式,最常见的有UTF-8、UTF-16和UTF-32等。
其中,UTF-8编码是一种可变长度编码,用来表示Unicode字符集中的字符,它将每个字符映射为一个或多个字节,广泛应用于互联网和计算机系统。
总结起来,汉字的编码方式经历了从最早的ASCII编码到GB2312、GBK和Unicode编码的发展演变。
随着计算机和互联网的普及,Unicode编码成为了汉字编码的主流,尤其是UTF-8编码,在国际化和跨平台应用中被广泛使用。
传统汉字与 Unicode 编码的关系

传统汉字与 Unicode 编码的关系汉字是中华民族独有的文字系统,拥有悠久的历史和丰富的文化内涵。
然而,随着信息技术的发展,传统汉字面临着新的挑战。
Unicode 编码作为一种全球通用的字符编码标准,对于汉字的传承和发展起到了重要的作用。
本文将探讨传统汉字与 Unicode 编码的关系,并分析其对汉字文化的影响。
一、Unicode 编码的出现Unicode 编码是由国际组织 Unicode 联盟制定的一套字符编码标准。
它的目标是为全球所有字符提供唯一的编号,使得不同的计算机系统可以互相交换和处理文本。
Unicode 编码的出现,解决了传统汉字在计算机技术中的兼容性问题,为汉字的数字化和信息化提供了基础。
二、传统汉字的复杂性传统汉字的复杂性是汉字与 Unicode 编码关系的重要背景。
汉字作为一种象形文字,每个字形都有其独特的内涵和意义。
然而,传统汉字的数量庞大,字形复杂,无法直接映射到计算机的二进制系统中。
这就需要一种编码标准来对汉字进行数字化表示。
三、Unicode 编码与汉字的映射Unicode 编码通过将每个字符分配一个唯一的编号来实现字符的数字化表示。
对于汉字而言,Unicode 编码采用了统一的汉字区段,将每个汉字与一个唯一的编码值进行对应。
这种映射关系使得汉字可以在计算机系统中得以存储和处理。
四、Unicode 编码对汉字文化的影响Unicode 编码的出现对汉字文化产生了深远的影响。
首先,Unicode 编码的普及使得汉字得以在全球范围内传播和使用。
无论是中文搜索引擎、中文网站还是中文输入法,都离不开Unicode 编码的支持。
其次,Unicode 编码的标准化使得不同计算机系统之间的文本交换变得更加方便和可靠。
这为汉字的数字化和信息化提供了基础,推动了汉字文化的传承和发展。
五、Unicode 编码的挑战尽管Unicode 编码为汉字的数字化提供了基础,但仍面临一些挑战。
首先,Unicode 编码的汉字区段容量有限,无法覆盖所有传统汉字。
汉字编码方式以及相应的关系

汉字编码方式以及相应的关系
汉字编码方式是指对汉字进行编码的方法和规则。
根据编码方式和用途的不同,汉字编码可以分为以下几种:
1. 拼音码:以汉字的拼音为基础进行编码,输入速度快,但重码较多,不易记忆。
2. 五笔码:五笔码是一种形码,将汉字拆分成不同的部分,然后按照一定的规则进行编码。
五笔码输入速度快,重码较少,但需要一定的学习和练习。
3. 语音码:语音码是一种利用语音识别技术进行汉字编码的方法。
用户只需读出汉字,系统就可以将其转换成相应的编码。
语音码需要一定的技术支持,且受方言和口音影响较大。
4. 字形码:字形码是一种基于汉字字形的编码方法。
它将汉字拆分成不同的部分,然后以数字或字母的形式表示其形状。
字形码输入较慢,但重码较少,易于记忆。
除了以上几种常见的汉字编码方式,还有一些其他的编码方式,如电报码、四角号码等。
这些编码方式都有其特定的用途和优缺点。
另外,汉字编码与计算机的关系也非常密切。
在计算机中存储和处理汉字时,需要对汉字进行编码。
目前使用最广泛的汉字编码是GB2312和GBK,它们分别支持简体中文和
繁体中文。
在互联网上传输汉字时,通常使用UTF-8编码,它支持多种语言和字符集。
汉字的编码方式以及相应的关系

汉字的编码方式以及相应的关系汉字的编码方式是汉字在计算机中的表示方法,即将汉字转化为二进制码以便计算机识别和处理。
在汉字的编码方式中,最常用的有GBK、GB2312、Unicode、UTF-8等。
1. GBK(国标码或扩展码)GBK是中国国家标准(GB2312)的扩展,使用两个字节表示一个汉字,因此可以表示包括简体汉字、繁体汉字、日文汉字在内的全部汉字字符。
GBK编码方式采用统一的编码标准,保证了不同计算机之间的汉字编码的兼容性。
2. GB2312(国标码)GB2312是中国国家标准的第一代汉字编码方式,使用两个字节表示一个汉字。
GB2312只包含了中华人民共和国境内的汉字和一些常用的符号、拉丁字母等。
GB2312的编码方式已经比较古老且局限性较大,不能涵盖所有汉字字符。
3. Unicode(统一码)Unicode是一种全球通用的字符编码标准,旨在为世界上几乎所有的书写系统都提供一个唯一的数字代码。
它使用两个字节(16位)表示一个字符,可以表示世界上几乎所有的字符,包括汉字。
Unicode是一种通用的编码方式,具有国际性和兼容性。
4. UTF-8(Unicode转化格式-8位)UTF-8是一种用于Unicode的可变长度字符编码,它可以使用一至四个字节表示一个字符,根据不同的字符而变化字节长度。
UTF-8编码方式兼容ASCII码,对于表示ASCII字符的部分,其字节和ASCII码完全相同,因此在ASCII字符范围内,UTF-8编码和ASCII码是相同的。
汉字编码方式之间的关系:- GB2312和GBK是中国国家标准,GB2312是GBK的子集,GBK是GB2312的扩展。
GBK编码方式在GB2312的基础上增加了更多的字符,以满足更广泛的需求,可以兼容GB2312。
- Unicode是全球通用的字符编码标准,与GB2312和GBK是不同的编码方式,Unicode可以表示更多的字符,并且具有兼容性和国际性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
输入码、区位码、国标码与机内码
我们知道,键盘是当前微机的主要输入设备,输入码就是使用英文键盘输入汉字时的编码。
目前,我国已推出的输入码有数百种,但用户使用较多的约为十几种,按输入码编码的主要依据,大体可分为顺序码、音码、形码、音形码四类,如“保”字,用全拼,输入码为码为“BAO”,用区位码,输入码为“1703”,用五笔字型则输入码为“WKS”。
计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。
我国国家标准局于1981年5月颁布了《信息交换用汉字编码字符集──基本集》,代号为GB2312-80,共对6763个汉字和682个图形字符进行了编码,其编码原则为:汉字用两个字节表示,每个字节用七位码(高位为0),国家标准将汉字和图形符号排列在一个94行94列的二维代码表中,每两个字节分别用两位十进制编码,前字节的编码称为区码,后字节的编码称为位码,此即区位码,如在二维代码表中处于17区第3位,区位码即为“1703 ”。
(教材附页可找到)
国标码并不等于区位码,它是由区位码稍作转换得到,其转换方法为:先将十进制区码和位码转换为十六进制的区码和位码,这样就得了一个与国标码有一个相对位置差的代码,再将这个代码的第一个字节和第二个字节分别加上20H,就得到国标码,相当于如果不转换的话,在两个字节上分别加上32即可。
如:“保”字的国标码为3123H,它是经过下面的转换得到的:1703D->1103H->+20H->3123H。
国标码是汉字信息交换的标准编码,但因其前后字节的最高位为0,与ASCII码发生冲突,如“保”字,国标码为31H和23H,而西文字符“1”和“#”的SCII也为31H和23H,现假如内存中有两个字节为31H和23H,这到底是一个汉字,还是两个西文字符“1”和“#”?于是就出现了二义性,显然,国标码是不可能在计算机内部直接采用的,于是,汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上128,即将两个字节的最高位由0改1,其余7位不变,也就是如果国标码是16进制的,直接加上8080H即可。
如:由上面我们知道,“保”字的国标码为3123H,前字节为00110001B,后字节为00100011B,高位改1为10110001B和10100011B 即为B1A3H,因此,“保”字的机内码就是B1A3H。
显然,汉字机内码的每个字节都大于128,这就解决了与西文字符的ASCII码冲突的问题。
如上所述,汉字输入码、区位码、国标码与机内码都是汉字的编码形式,它们之间有着千丝万缕的联系,但其间的区别也是不容忽视的。
公式总结:
1.先将区位码的区号和位号分别转换为16进制
如“保”字区位码十进制1703转换成16进制形式1103H
2.区位码+ 2020H =国标码
3.国标码+ 8080H =机内码。