损连接性又保持函数依赖的分解算法
关系模式分解的无损连接和保持函数依赖

关系模式分解的无损连接和保持函数依赖一、引言关系模式是关系数据库中的核心元素之一,它描述了数据的结构和关系。
在设计关系数据库时,我们常常需要对关系模式进行分解,以满足数据库的需求。
本文将讨论关系模式分解的无损连接和保持函数依赖的相关概念和方法。
二、关系模式分解关系模式分解是将一个关系模式拆分成多个较小的关系模式的过程。
在分解关系模式时,我们需要考虑两个重要的性质:无损连接和保持函数依赖。
2.1 无损连接无损连接是指在关系模式分解后,通过对分解后的关系进行连接操作能够恢复原始关系模式。
换句话说,无损连接要求分解后的关系能够完整地保留原始关系中的所有信息。
2.2 保持函数依赖保持函数依赖是指在关系模式分解后,分解后的关系中依然能够保持原始关系中的函数依赖关系。
函数依赖是指一个属性或者属性集合的值决定了另一个属性或者属性集合的值。
三、关系模式分解的方法关系模式分解有多种方法,下面介绍三种常用的方法:自然连接、垂直分解和水平分解。
3.1 自然连接自然连接是指通过公共属性将两个或多个关系模式进行连接,得到一个具有完整信息的新关系模式。
自然连接的特点是能够保持原始关系中的所有信息和函数依赖。
3.2 垂直分解垂直分解是指根据属性集合的划分,将一个关系模式分解成多个关系模式。
垂直分解的优点是能够消除冗余数据,提高查询效率。
但是需要注意的是,垂直分解可能会造成关系丢失或信息损失。
3.3 水平分解水平分解是指将一个关系模式的元组进行水平划分,得到多个关系模式。
水平分解的特点是能够提高并发性能和容错性。
但是需要注意的是,水平分解可能会造成查询的复杂性增加和数据的分布不均衡。
四、关系模式分解的应用关系模式分解在实际的数据库设计中有着广泛的应用。
下面介绍两个例子以说明关系模式分解的应用。
4.1 学生课程关系考虑一个学生选课系统,其中包含学生和课程两个关系模式。
学生关系模式包括学生ID、姓名和年龄等属性,课程关系模式包括课程ID、课程名称和教师名称等属性。
规范化无损分解及保持函数依赖

AB BC CD
a1
a2
b13 a3 a3
b14 b24 a4
b 21 a 2 b31 b32
无损分解的测试方法
(2)把表格看成模式R的一个关系,反复检查F中每个FD在表格中是否成立, 若不成立,则修改表格中的值。修改方法如下: 对于F中一个FD X Y ,如果表格中有两行在X值上相等,在Y值上不相等, ai 那么把这两行在Y值上也改成相等的值。如果Y值中有一个是 ,那么另一 aj aj bij 个也改成 ;如果没有 ,那么用其中一个 替换另一个值(尽量把下标 ij改成较小的数)。一直到表格不能修改为止。 (3)若修改的最后一张表格中有一行全 是a,即 a1a 2 a n ,那么称ρ 相对于F 是无损分解,否则称有损分解。 A B C D
分解成3NF模式集既无损 又保持函数依赖的方法
① 对于关系模式R和R上成立的FD集F,先求出F的最小依赖集,然后再把最小依 赖集中那些左部相同的FD用合并性合并起来。 ② 对最小依赖集中每个FD X→Y去构成一个模式XY。 ③ 在构成的模式集中,如果每个模式都不包含R的候选键,那么把候选键作为一 个模式放入模式集中。
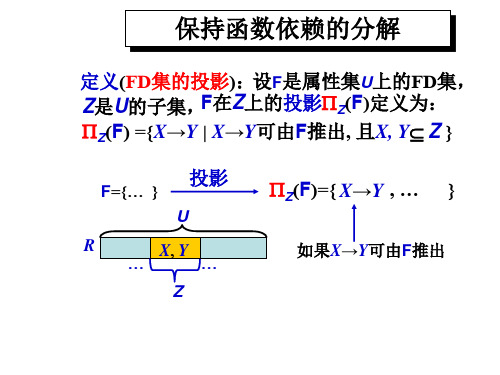
保持函数依赖的模式分解
设关系模式R<U,F>被分解为若干个关系模式 R1<U1,F1>,R2<U2,F2>,…,Rn<Un,Fn> (其中U=U1∪U2∪…∪Un,且不存在Ui Uj,Fi为F 在Ui上的投影),若F所逻辑蕴含的函数依赖一定
也由分解得到的某个关系模式中的函数依赖Fi所逻
辑蕴含,则称关系模式R的这个分解是保持函数依
, Rk 是R
例:设关系模式R(ABCD),R分解成 {AB, BC, CD} 。如果R上成立的函数依赖 集 F1 {B A, C D},那么ρ 相对于F 是否无损分解?如果R上成立的函数依赖集 1 F2 {A B, C D} 呢? (1)构建一张k行n列的表格,每 列对应一个属性 A j 1 j n ,每行 对应一个模式 R i 1 i K 。如 果 A j在 R i 中,那么在表格的第i行 第j列处填上符号 a j ,否则填上 bij。 A B C D
求无损连接和函数依赖的bc范式

求无损连接和函数依赖的bc范式在数据库设计中,BC范式是最高级别的范式,通过满足BC范式的要求,可以使数据库的关系完全符合函数依赖的规定,进而实现更优秀的数据存储与查询效率。
BC范式要求约束条件更为严格,一般只适用于复杂大型的数据库,因此需要严格按照步骤进行处理。
下面是BC范式求无损连接和函数依赖步骤:1. 将原始的数据库关系R进行拆分,得到多个关系R1、R2、R3……Rn。
2. 根据拆分得到的关系,确定它们之间的依赖关系,包括主键、外键和其他依赖关系。
如果存在冗余的依赖关系,则需要消除冗余关系。
3. 针对每个关系,分析表的属性,发现存在的函数依赖,如果有非主属性完全依赖于主属性,则需要将其单独成立一个关系。
4. 对于拆分得到的关系,如果其中存在具有相同主键的关系,则可以进行连接操作,建立联合表。
此时需要保证不会丢失任何数据,也就是数据的完整性和准确性不受影响。
5. 在保持无损连接的同时,进行函数依赖的处理,即确保每个关系的非主属性完全依赖于主属性。
如果出现违反函数依赖的情况,则需要进行冗余关系的消除。
6. 为确保BC范式的实现,可以对于ROP规则进行检验。
ROP规则是指消除冗余关系的规则,通过该规则可以确定每个关系中的唯一性数据,从而实现无重复的记录。
7. 最后,根据BC范式的要求,对每个关系进行分析和调整,保证关系中的数据是一致、不重复、无冗余、且符合查询要求的。
总结起来,求无损连接和函数依赖的BC范式就是按照以上步骤进行的,其中涉及到拆分关系、确定依赖关系、进行函数依赖的处理、建立联合表,保持无损连接和处理冗余关系等操作。
通过对每个关系和属性的分析,消除冗余关系和实现函数依赖,最终实现了关系中数据的一致性、无重复性和无冗余性,提升了数据库的查询效率和性能。
无损分解与函数依赖的判断

一:大部分是对一个关系模式分解成两个模式的考察,分解为三个以上模式时无损分解和保持依赖的判断比较复杂,考的可能性不大,因此我们只对“一个关系模式分解成两个模式”这种类型的题的相关判断做一个总结。
以下的论述都基于这样一个前提:R是具有函数依赖集F的关系模式,(R1 ,R2)是R的一个分解。
首先我们给出一个看似无关却非常重要的概念:属性集的闭包。
令α为一属性集。
我们称在函数依赖集F下由α函数确定的所有属性的集合为F下α的闭包,记为α+ 。
下面给出一个计算α+的算法,该算法的输入是函数依赖集F和属性集α,输出存储在变量result中。
算法一:result:=α;while(result发生变化)dofor each 函数依赖β→γ in F dobeginif β∈result then result:=result∪γ;end属性集闭包的计算有以下两个常用用途:·判断α是否为超码,通过计算α+(α在F下的闭包),看α+ 是否包含了R中的所有属性。
若是,则α为R的超码。
·通过检验是否β∈α+,来验证函数依赖是否成立。
也就是说,用属性闭包计算α+,看它是否包含β。
(请原谅我用∈符号来表示两个集合之间的包含关系,那个表示包含的符号我找不到,大家知道是什么意思就行了。
)看一个例子吧,2005年11月系分上午37题:● 给定关系R(A1,A2,A3,A4)上的函数依赖集F={A1→A2,A3→A2,A2→A3,A2→A4},R的候选关键字为________。
(37)A. A1 B. A1A3 C. A1A3A4 D. A1A2A3首先我们按照上面的算法计算A1+ 。
result=A1,由于A1→A2,A1∈result,所以resul t=result∪A2=A1A2由于A2→A3,A2∈result,所以result=result∪A3=A1A2A3由于A2→A4,A2∈result,所以result=result∪A3=A1A2A3A4由于A3→A2,A3∈result,所以result=result∪A2=A1A2A3A4通过计算我们看到,A1+ =result={A1A2A3A4},所以A1是R的超码,理所当然是R的候选关键字。
数据库系统原理模式分解算法

函数依赖的公理系统:设有关系模式R(U),X,Y,Z,W均是U的子集,F是R上只涉及到U 中属性的函数依赖集,推理规则如下:•自反律:如果Y X U,则X→Y在R上成立。
•增广律:如果X→Y为F所蕴涵,Z U,则XZ→YZ在R上成立。
(XZ表示X∪Z,下同)•传递律:如果X→Y和Y→Z在R上成立,则X→Z在R上成立。
以上三条为Armstrong公理系统•合并律:如果X→Y和X→Z成立,那么X→YZ成立。
•伪传递律:如果X→Y和WY→Z成立,那么WX→Z成立。
•分解律:如果X→Y和Z Y成立,那么X→Z成立。
这三条为引理注意:•函数依赖推理规则系统(自反律、增广律和传递律)是完备的。
•由自反律所得到的函数依赖均是平凡的函数依赖。
模式分解的几个重要事实:•若只要求分解具有“无损连接性”,一定可以达到4NF;•若要求分解要“保持函数依赖”,可以达到3NF,但不一定能达到BCNF;•若要求分解既要“保持函数依赖”,又要具有“无损连接性”,可以达到3NF,但不一定能达到BCNF;试分析下列分解是否具有无损联接和保持函数依赖的特点:设R(ABC),F1={A→B} 在R上成立,ρ1={AB,AC}。
首先,检查是否具有无损联接特点:第1种解法--算法4.2:(1) 构造表(2)根据A→B进行处理结果第二行全是a行,因此分解是无损联接分解。
第2种解法:(定理4.8)R1(AB)∩R2(AC)=AR2- R1=B∵A→B,∴该分解是无损联接分解。
然后,检查分解是否保持函数依赖πR1(F1)={A→B,以及按自反率推出的一些函数依赖}πR2(F1)={按自反率推出的一些函数依赖}F1被πR1(F1)所蕴涵,∴所以该分解保持函数依赖。
保持函数依赖的模式分解一、转换成3NF的保持函数依赖的分解算法:ρ={R1<U1,F1>,R2<U2,F2>,...,Rk<Uk,Fk>}是关系模式R<U,F>的一个分解,U={A1,A2,...,An},F={FD1,FD2,...,FDp},并设F是一个最小依赖集,记FDi为X i →Alj,其步骤如下:① 对R<U,F>的函数依赖集F进行极小化处理(处理后的结果仍记为F);② 找出不在F中出现的属性,将这样的属性构成一个关系模式。
具有无损联结性且保持依赖性关系模式的BCNF完备分解算法

具有无损联结性且保持依赖性关系模式的BCNF完备分解算
法
徐庆生;周行仁
【期刊名称】《楚雄师范学院学报》
【年(卷),期】1996(000)003
【摘要】本文给出一种具有完备性的合成方法,来把一个关系模式分解成具有无损性和保持依赖性的BC范式关系数据库模式,只要这个模式“本质上能作这种分解的话”;同时对这种“本质上能分解为保持某些性质的某一范式”提法进行了形式化描述;最后,讨论了这种合成法的固有复杂度。
【总页数】5页(P21-25)
【作者】徐庆生;周行仁
【作者单位】
【正文语种】中文
【中图分类】TP311.1
【相关文献】
1.若干命题联结词集合的完备性和不完备性证明 [J], 宋伟
2.无损 BCNF分解算法的改进 [J], 欧阳林艳
3.空值环境下关系模式到(N)BCNF无损连接分解 [J], 郝忠孝;魏海东
4.具有无损联结性且保持依赖性关系模式的BCNF完备分解算法 [J], 徐庆生;周行
仁
5.空值环境下关系模式无损连接分解为(N)BCNF的必要条件和算法 [J], 叶仰明因版权原因,仅展示原文概要,查看原文内容请购买。
关系模式分解的无损连接和保持函数依赖

关系模式分解的无损连接和保持函数依赖一、关系模式分解的概念关系模式分解是指将一个复杂的关系模式分解为若干个简单的关系模式的过程。
在实际应用中,由于某些原因(如性能、数据冗余等),需要将一个大型的关系模式分解成多个小型的关系模式,从而提高数据库系统的效率和可维护性。
二、无损连接和保持函数依赖在进行关系模式分解时,有两种重要的约束条件:无损连接和保持函数依赖。
无损连接是指在进行关系模式分解后,仍然能够通过连接操作得到原始数据集合。
保持函数依赖是指在进行关系模式分解后,仍然能够维护原始数据集合中所有函数依赖。
三、无损连接和保持函数依赖的定义1. 无损连接假设R是一个关系模式,R1和R2是R的两个投影。
如果存在一个连接操作J(R1,R2),使得J(R1,R2)中包含了所有R中元组,则称R1和R2对于R具有无损连接。
2. 保持函数依赖假设R是一个关系模式,F是R上的一组函数依赖集合。
如果对于F中任何一个函数依赖X→Y,都存在一个关系模式R1和R2,使得R=R1⋈R2,且X和Y分别属于R1和R2的属性集合,则称关系模式分解后,仍然能够维护原始数据集合中所有函数依赖。
四、无损连接和保持函数依赖的算法在进行关系模式分解时,需要考虑如何保证无损连接和保持函数依赖。
以下是两种常用的算法。
1. 剖析算法剖析算法是一种自顶向下的分解方法。
该方法首先将原始关系模式拆分成两个投影,并检查它们是否具有无损连接。
如果没有,则再次拆分,并重复该过程直到满足无损连接为止。
剖析算法的优点是简单易懂,容易实现。
但是缺点也很明显,即可能会产生大量冗余数据。
2. 合成算法合成算法是一种自底向上的分解方法。
该方法首先将原始关系模式拆分为多个小型关系模式,并检查它们是否能够维护原始数据集合中所有函数依赖。
如果不能,则将两个小型关系模式合并,并重复该过程直到满足保持函数依赖为止。
合成算法的优点是能够保证数据的最小化,减少数据冗余。
但是缺点也很明显,即实现难度较大。
数据库保持函数依赖的分解
解:PAB(F)={A→B}, PAC(F)={ }。 ρ保持依赖; 也是无损分解:
1A 2B 3C 1AB a1 a2 b13 2AC a1 b22 a3
1A 2B 3C 1AB a1 a2 b13 2AC a1 a2 a3
例: 分解是否保持FD集,是否无损分解
设有关系模式:R(ABC), R上的FD集为: F= { A→B, B→C }
将R分解为:ρ ={ AB, AC }, ρ保持依赖?无损分解?
解:PAB(F)={A→B}, PAC(F)={A→C}。 ρ不保持依赖(丢失B→C); 但是是无损分解:
1A 2B 3C 1AB a1 a2 b13 2AC a1 b22 a3
1A 2B 3C 1AB a1 a2 b13 2AC a1 b22 a3
总结
根据是否保持依赖、是否无损分解将分解分成四类:
无损分解 保持依赖
说明
YES
YES
最好 (不丢失数据和依赖)
YES
NO 可接受 (丢失依赖, 会导致异常)
NO
YES
不能接受(丢失数据)
NO
NO
不能接受(丢失数据)
问题:如何在保证无损和保持依赖的前提下,使分解所 得的关系模式集符合尽可能高的范式?
例: 分解是否保持FD集,是否无损分解
设有关系模式:R( N,
S,
G)
职工工号 工资级别 工资数目
R上的FD集为:
F= {
N→S, /* 每个职工只有一个工资级别 */
S →G /* 一个工资级别只有一个工资数目*/
}
将R分解为:ρ ={ NS, NG }, ρ保持依赖?无损分解?
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
求最小函数依赖集分三步:1.将F中的所有依赖右边化为单一元素此题fd={abd->e,ab->g,b->f,c->j,cj->i,g->h};已经满足2.去掉F中的所有依赖左边的冗余属性.作法是属性中去掉其中的一个,看看是否依然可以推导此题:abd->e,去掉a,则(bd)+不含e,故不能去掉,同理b,d都不是冗余属性ab->g,也没有cj->i,因为c+={c,j,i}其中包含i所以j是冗余的.cj->i将成为c->iF={abd->e,ab->g,b->f,c->j,c->i,g->h};3.去掉F中所有冗余依赖关系.做法为从F中去掉某关系,如去掉(X->Y),然后在F中求X+,如果Y在X+中,则表明x->是多余的.需要去掉.此题如果F去掉abd->e,F将等于{ab->g,b->f,c->j,c->i,g->h},而(abd)+={a,d,b,f,g,h},其中不包含e.所有不是多余的.同理(ab)+={a,b,f}也不包含g,故不是多余的.b+={b}不多余,c+={c,i}不多余c->i,g->h多不能去掉.所以所求最小函数依赖集为F={abd->e,ab->g,b->f,c->j,c->i,g->h};转换为3NF既具有无损连接性又保持函数依赖的分解算法:第一步:首先用算法1求出R的保持函数依赖的3NF分解,设为q={R1,R2,…,Rk}(这步完成后分解已经是保持函数依赖,但不一定具有保持无损连接)第二步:设X是R的码,求出p=q {R(X)}第三步:若X是q中某个Ri的子集,则在p中去掉R(X)第四步:得到的p就是最终结果例题:R(S#,SN,P,C,S,Z)F={S#→SN,S#→P,S#→C,S#→S,S#→Z,{P,C,S}→Z,Z→P,Z→C}∙第一步:求出最小FD集:F={S# →SN, S# →P,S# →C, S#→S, {P,C,S→Z, Z →P,Z →C} // S# →Z冗余,FD:最小函数依赖按具有相同左部分组:q={R1(S#,SN,P,C,S), R2(P,C,S,Z), R3(Z,P,C)}R3是R2的子集,所以去掉R3q={R1(S#,SN,P,C,S), R2(P,C,S,Z)}∙第二步:R的主码为S#,于是p=q {R(X)}={R1(S#,SN,P,C,S), R2(P,C,S,Z), R(S#)}∙第三步:因为{S#}是R1的子集,所以从p中去掉R(S#)∙第四步:p ={R1(S#,SN,P,C,S), R2(P,C,S,Z)}即最终结果判别一个分解的无损连接性举例2:已知R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。
解:用判断无损连接的算法来解。
① 构造一个初始的二维表,若“属性”属于“模式”中的属性,则填a j,否则填b ij。
② 根据A→C,对上表进行处理,由于属性列A上第1、2、5行相同均为a1,所以将属性列C上的b13、b23、b53改为同一个符号b13(取行号最小值)。
③ 根据B→C,对上表进行处理,由于属性列B上第2、3行相同均为a2,所以将属性列C上的b13、b33改为同一个符号b13(取行号最小值)。
④ 根据C→D,对上表进行处理,由于属性列C上第1、2、3、5行相同均为b13,所以将属性列D上的值均改为同一个符号a4。
⑤ 根据DE→C,对上表进行处理,由于属性列DE上第3、4、5行相同均为a4a5,所以将属性列C上的值均改为同一个符号a3。
⑥ 根据CE→A,对上表进行处理,由于属性列CE上第3、4、5行相同均为a3a5,所以将属性列A上的值均改为同一个符号a1。
⑦ 通过上述的修改,使第三行成为a1a2a3a4a5,则算法终止。
且分解具有无损连接性。
求属性集合X关于函数依赖集F的闭包X+【算法5.1】计算属性集X关于F的闭包X+。
输入:属性集X为U的子集,函数依赖集F。
输出:X+。
步骤:(1) 置初始值 A=ф,A*=X;(2) 如果A≠A*,置A=A*,否则转(4);(3) A*,置A*=A*∪Z。
全部搜索完,转(2);⊆依次检查F中的每一个函数依赖Y→Z,若Y(4) 输出A*,即为X+。
【例】已知关系模式R(A,B,C,D,E),F={AB→C,B→D,C→E,EC→B,AC→B}是函数依赖集,求(AB)+。
依算法2.1解:(1) 置初始值 A=ф,A*=AB;(2) 因A≠A*,置A=AB;(3) 第一次扫描F,找到AB→C和B→D,其左部⊆AB,故置A*=ABCD。
搜索完,转(2);(2) 因A≠A*,置A=ABCD;(3) 第二次扫描F,找到C→E和AC→B,其左部⊆ ABCD,故置A*=ABCDE。
搜索完,转(2);(2) 因A≠A*,置A=ABCDE;(3) 第三次扫描F,找到EC→B,其左部⊆ ABCDE,故置A*=ABCDE。
搜索完,转(2);(2) 因A=A*,转(4);(4) 输出A*,即(AB)+=ABCDE。
举例:已知关系模式R,U={A,B,C,D,E,G},F={AB→C,D→EG,C→A,BE→C,BC→D,CG→BD,ACD→B,CE→AG},求F的最小函数依赖集。
解1:利用算法求解,使得其满足三个条件①利用分解规则,将所有的函数依赖变成右边都是单个属性的函数依赖,得F为:F={AB→C,D→E,D→G,C→A,BE→C,BC→D,CG→B,CG→D,ACD→B,CE→A,CE→G}②去掉F中多余的函数依赖A.设AB→C为冗余的函数依赖,则去掉AB→C,得:F1={D→E,D→G,C→A,BE→C,BC→D,CG→B,CG→D,ACD→B,CE→A,CE→G}计算(AB)F1+:设X(0)=AB计算X(1):扫描F1中各个函数依赖,找到左部为AB或AB子集的函数依赖,因为找不到这样的函数依赖。
故有X(1)=X(0)=AB,算法终止。
(AB)F1+= AB不包含C,故AB→C不是冗余的函数依赖,不能从F1中去掉。
B.设CG→B为冗余的函数依赖,则去掉CG→B,得:F2={AB→C,D→E,D→G,C→A,BE→C,BC→D,CG→D,ACD→B,CE→A,CE→G}计算(CG)F2+:设X(0)=CG计算X(1):扫描F2中的各个函数依赖,找到左部为CG或CG子集的函数依赖,得到一个C→A函数依赖。
故有X(1)=X(0)∪A=CGA=ACG。
计算X(2):扫描F2中的各个函数依赖,找到左部为ACG或ACG子集的函数依赖,得到一个CG→D函数依赖。
故有X(2)=X(1)∪D=ACDG。
计算X(3):扫描F2中的各个函数依赖,找到左部为ACDG或ACDG子集的函数依赖,得到两个ACD→B和D→E函数依赖。
故有X(3)=X(2)∪BE=ABCDEG,因为X(3)=U,算法终止。
(CG)F2+=ABCDEG包含B,故CG→B是冗余的函数依赖,从F2中去掉。
C.设CG→D为冗余的函数依赖,则去掉CG→D,得:F3={AB→C,D→E,D→G,C→A,BE→C,BC→D,ACD→B,CE→A,CE→G}计算(CG)F3+:设X(0)=CG计算X(1):扫描F3中的各个函数依赖,找到左部为CG或CG子集的函数依赖,得到一个C→A函数依赖。
故有X(1)=X(0)∪A=CGA=ACG。
计算X(2):扫描F3中的各个函数依赖,找到左部为ACG或ACG子集的函数依赖,因为找不到这样的函数依赖。
故有X(2)=X(1),算法终止。
(CG)F3+=ACG。
(CG)F3+=ACG不包含D,故CG→D不是冗余的函数依赖,不能从F3中去掉。
D.设CE→A为冗余的函数依赖,则去掉CE→A,得:F4={AB→C,D→E,D→G,C→A,BE→C,BC→D,CG→D,ACD→B,CE→G}计算(CG)F4+:设X(0)=CE计算X(1):扫描F4中的各个函数依赖,找到左部为CE或CE子集的函数依赖,得到一个C→A函数依赖。
故有X(1)=X(0)∪A=CEA=ACE。
计算X(2):扫描F4中的各个函数依赖,找到左部为ACE或ACE子集的函数依赖,得到一个CE→G函数依赖。
故有X(2)=X(1)∪G=ACEG。
计算X(3):扫描F4中的各个函数依赖,找到左部为ACEG或ACEG子集的函数依赖,得到一个CG→D函数依赖。
故有X(3)=X(2)∪D=ACDEG。
计算X(4):扫描F4中的各个函数依赖,找到左部为ACDEG或ACDEG子集的函数依赖,得到一个ACD→B函数依赖。
故有X(4)=X(3)∪B=ABCDEG。
因为X(4)=U,算法终止。
(CE)F4+=ABCDEG包含A,故CE→A是冗余的函数依赖,从F4中去掉。
③去掉F4中各函数依赖左边多余的属性(只检查左部不是单个属性的函数依赖)由于C→A,函数依赖ACD→B中的属性A是多余的,去掉A得CD→B。
故最小函数依赖集为:F={AB→C,D→E,D→G,C→A,BE→C,BC→D,CG→D,CD→B,CE→G}。