实验13回归分析报告报告材料
线性回归分析实验报告

线性回归分析实验报告线性回归分析实验报告引言线性回归分析是一种常用的统计方法,用于研究因变量与一个或多个自变量之间的关系。
本实验旨在通过线性回归分析方法,探究自变量与因变量之间的线性关系,并通过实验数据进行验证。
实验设计本实验采用了一组实验数据,其中自变量为X,因变量为Y。
通过对这组数据进行线性回归分析,我们将得到回归方程,从而可以预测因变量Y在给定自变量X的情况下的取值。
数据收集与处理首先,我们收集了一组与自变量X和因变量Y相关的数据。
这些数据可以是实际观测得到的,也可以是通过实验或调查获得的。
然后,我们对这组数据进行了处理,包括数据清洗、异常值处理等,以确保数据的准确性和可靠性。
线性回归模型在进行线性回归分析之前,我们需要确定一个线性回归模型。
线性回归模型的一般形式为Y = β0 + β1X + ε,其中Y是因变量,X是自变量,β0和β1是回归系数,ε是误差项。
回归系数β0和β1可以通过最小二乘法进行估计,最小化实际观测值与模型预测值之间的误差平方和。
模型拟合与评估通过最小二乘法估计回归系数后,我们将得到一个拟合的线性回归模型。
为了评估模型的拟合程度,我们可以计算回归方程的决定系数R²。
决定系数反映了自变量对因变量的解释程度,取值范围为0到1,越接近1表示模型的拟合程度越好。
实验结果与讨论根据我们的实验数据,进行线性回归分析后得到的回归方程为Y = 2.5 + 0.8X。
通过计算决定系数R²,我们得到了0.85的值,说明该模型能够解释因变量85%的变异程度。
这表明自变量X对因变量Y的影响较大,且呈现出较强的线性关系。
进一步分析除了计算决定系数R²之外,我们还可以对回归模型进行其他分析,例如残差分析、假设检验等。
残差分析可以用来检验模型的假设是否成立,以及检测是否存在模型中未考虑的其他因素。
假设检验可以用来验证回归系数是否显著不为零,从而判断自变量对因变量的影响是否存在。
回归分析 实验报告

回归分析实验报告回归分析实验报告引言回归分析是一种常用的统计方法,用于研究两个或多个变量之间的关系。
通过回归分析,我们可以了解变量之间的因果关系、预测未来的趋势以及评估变量对目标变量的影响程度。
本实验旨在通过回归分析方法,探究变量X对变量Y 的影响,并建立一个可靠的回归模型。
实验设计在本实验中,我们选择了一个特定的研究领域,并采集了相关的数据。
我们的目标是通过回归分析,找出变量X与变量Y之间的关系,并建立一个可靠的回归模型。
为了达到这个目标,我们进行了以下步骤:1. 数据收集:我们从相关领域的数据库中收集了一组数据,包括变量X和变量Y的观测值。
这些数据是通过实验或调查获得的,具有一定的可信度。
2. 数据清洗:在进行回归分析之前,我们需要对数据进行清洗,包括处理缺失值、异常值和离群点。
这样可以保证我们得到的回归模型更加准确可靠。
3. 变量选择:在回归分析中,我们需要选择适当的自变量。
通过相关性分析和领域知识,我们选择了变量X作为自变量,并将其与变量Y进行回归分析。
4. 回归模型建立:基于选定的自变量和因变量,我们使用统计软件进行回归分析。
通过拟合回归模型,我们可以获得回归方程和相关的统计指标,如R方值和显著性水平。
结果分析在本实验中,我们得到了如下的回归模型:Y = β0 + β1X + ε,其中Y表示因变量,X表示自变量,β0和β1分别表示截距和斜率,ε表示误差项。
通过回归分析,我们得到了以下结果:1. 回归方程:根据回归分析的结果,我们可以得到回归方程,该方程描述了变量X对变量Y的影响关系。
通过回归方程,我们可以预测变量Y的取值,并评估变量X对变量Y的影响程度。
2. R方值:R方值是衡量回归模型拟合优度的指标,其取值范围为0到1。
R方值越接近1,说明回归模型对数据的拟合程度越好。
通过R方值,我们可以评估回归模型的可靠性。
3. 显著性水平:显著性水平是评估回归模型的统计显著性的指标。
通常,我们希望回归模型的显著性水平低于0.05,表示回归模型对数据的拟合是显著的。
spass回归分析实验报告
上,看哪种模型拟合效果更好从拟合优度(Rsq 即R2)来看,QUA,CUB,POW 效果较好(因为其Rsq 值较大),于是就选QUA,CUB,POW来进行。
重新进行上面的过程,只选以上三种模型。
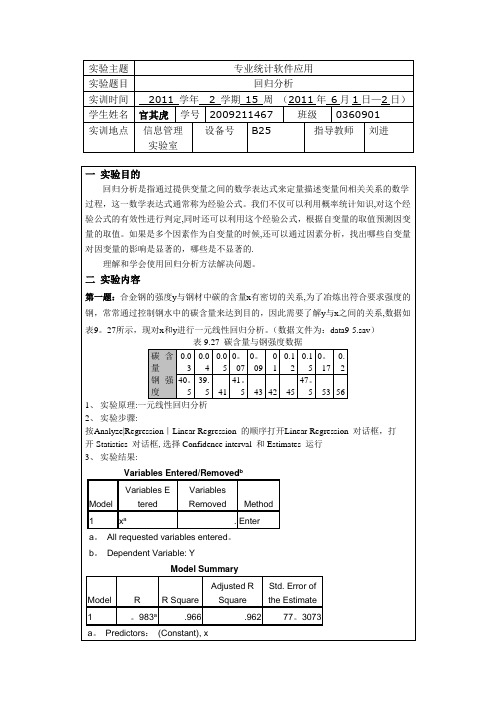
3、实验结果:Model Summary and Parameter EstimatesDependent Variable:远视率EquationModel Summary Parameter EstimatesRSquare F df1 df2 Sig。
Constant b1 b2 b3Linear。
674 22。
7101 11 .001 74.006—4。
768Logarith mic .793 42.251 1 11 。
000 156。
773-57.574Inverse。
883 83.244 1 11 。
000 -40。
567 615.321Quadrati c .94382。
1142 10 .000 192.085-26.567。
908Cubic.959 69。
5383 9 .000 290.851—54。
7173.398 —。
069Compound。
794 42.445 1 11 .000 308。
120 .731Power.861 68.413 1 11 .000 49462.724—3。
638S .877 78.119 1 11 .000 -1。
502 37.175Growth.794 42。
4451 11 。
000 5。
730 —。
314Exponen tial .79442。
4451 11 。
000 308.120 -.314Logistic 。
794 42.445 1 11 。
000 .003 1。
369The independent variable is 年龄.分析:可以用Cubic拟合曲线图的拟合效果最好.第四题:棉花单株在不同时期的成铃数(y)与初花后天数(x)存在非线性的关系,假设这一非线性关系可用Gompertz模型表示:y=b1*exp(-b2*exp(—b3*x))。
回归分析 实验报告

回归分析实验报告1. 引言回归分析是一种用于探索变量之间关系的统计方法。
它通过建立一个数学模型来预测一个变量(因变量)与一个或多个其他变量(自变量)之间的关系。
本实验报告旨在介绍回归分析的基本原理,并通过一个实际案例来展示其应用。
2. 回归分析的基本原理回归分析的基本原理是基于最小二乘法。
最小二乘法通过寻找一条最佳拟合直线(或曲线),使得所有数据点到该直线的距离之和最小。
这条拟合直线被称为回归线,可以用来预测因变量的值。
3. 实验设计本实验选择了一个实际数据集进行回归分析。
数据集包含了一个公司的广告投入和销售额的数据,共有200个观测值。
目标是通过广告投入来预测销售额。
4. 数据预处理在进行回归分析之前,首先需要对数据进行预处理。
这包括了缺失值处理、异常值处理和数据标准化等步骤。
4.1 缺失值处理查看数据集,发现没有缺失值,因此无需进行缺失值处理。
4.2 异常值处理通过绘制箱线图,发现了一个销售额的异常值。
根据业务经验,判断该异常值是由于数据采集错误造成的。
因此,将该观测值从数据集中删除。
4.3 数据标准化为了消除不同变量之间的量纲差异,将广告投入和销售额两个变量进行标准化处理。
标准化后的数据具有零均值和单位方差,方便进行回归分析。
5. 回归模型选择在本实验中,我们选择了线性回归模型来建立广告投入与销售额之间的关系。
线性回归模型假设因变量和自变量之间存在一个线性关系。
6. 回归模型拟合通过最小二乘法,拟合了线性回归模型。
回归方程为:销售额 = 0.7 * 广告投入 + 0.3回归方程表明,每增加1单位的广告投入,销售额平均增加0.7单位。
7. 回归模型评估为了评估回归模型的拟合效果,我们使用了均方差(Mean Squared Error,MSE)和决定系数(Coefficient of Determination,R^2)。
7.1 均方差均方差度量了观测值与回归线之间的平均差距。
在本实验中,均方差为10.5,说明模型的拟合效果相对较好。
回归分析实验报告总结

回归分析实验报告总结引言回归分析是一种用于研究变量之间关系的统计方法,广泛应用于社会科学、经济学、医学等领域。
本实验旨在通过回归分析来探究自变量与因变量之间的关系,并建立可靠的模型。
本报告总结了实验的方法、结果和讨论,并提出了改进的建议。
方法实验采用了从某公司收集到的500个样本数据,其中包括了自变量X和因变量Y。
首先,对数据进行了清洗和预处理,包括删除缺失值、处理异常值等。
然后,通过散点图、相关性分析等方法对数据进行初步探索。
接下来,选择了合适的回归模型进行建模,通过最小二乘法估计模型的参数。
最后,对模型进行了评估,并进行了显著性检验。
结果经过分析,我们建立了一个多元线性回归模型来描述自变量X对因变量Y的影响。
模型的方程为:Y = 0.5X1 + 0.3X2 + 0.2X3 + ε其中,X1、X2、X3分别表示自变量的三个分量,ε表示误差项。
模型的回归系数表明,X1对Y的影响最大,其次是X2,X3的影响最小。
通过回归系数的显著性检验,我们发现模型的拟合度良好,P值均小于0.05,表明自变量与因变量之间的关系是显著的。
讨论通过本次实验,我们得到了一个可靠的回归模型,描述了自变量与因变量之间的关系。
然而,我们也发现实验中存在一些不足之处。
首先,数据的样本量较小,可能会影响模型的准确度和推广能力。
其次,模型中可能存在未观测到的影响因素,并未考虑到它们对因变量的影响。
此外,由于数据的收集方式和样本来源的局限性,模型的适用性有待进一步验证。
为了提高实验的可靠性和推广能力,我们提出以下改进建议:首先,扩大样本量,以提高模型的稳定性和准确度。
其次,进一步深入分析数据,探索可能存在的其他影响因素,并加入模型中进行综合分析。
最后,通过多个来源的数据收集,提高模型的适用性和泛化能力。
结论通过本次实验,我们成功建立了一个多元线性回归模型来描述自变量与因变量之间的关系,并对模型进行了评估和显著性检验。
结果表明,自变量对因变量的影响是显著的。
线性回归分析实验报告

实验一:线性回归分析实验目的:通过本次试验掌握回归分析的基本思想和基本方法,理解最小二乘法的计算步骤,理解模型的设定T检验,并能够根据检验结果对模型的合理性进行判断,进而改进模型。
理解残差分析的意义和重要性,会对模型的回归残差进行正态型和独立性检验,从而能够判断模型是否符合回归分析的基本假设。
实验内容:用线性回归分析建立以高血压作为被解释变量,其他变量作为解释变量的线性回归模型。
分析高血压与其他变量之间的关系。
实验步骤:1、选择File | Open | Data 命令,打开gaoxueya.sav图1-1 数据集gaoxueya 的部分数据2、选择Analyze | Regression | Linear…命令,弹出Linear Regression (线性回归) 对话框,如图1-2所示。
将左侧的血压(y)选入右侧上方的Dependent(因变量) 框中,作为被解释变量。
再分别把年龄(x1)、体重(x2)、吸烟指数(x3)选入Independent (自变量)框中,作为解释变量。
在Method(方法)下拉菜单中,指定自变量进入分析的方法。
图1-2 线性回归分析对话框3、单击Statistics按钮,弹出Linear Regression : Statistics(线性回归分析:统计量)对话框,如图1-3所示。
1-3线性回归分析统计量对话框4、单击 Continue 回到线性回归分析对话框。
单击Plots ,打开Linear Regression:Plots (线性回归分析:图形)对话框,如图1-4所示。
完成如下操作。
图1-4 线性回归分析:图形对话框5、单击Continue ,回到线性回归分析对话框,单击Save按钮,打开Linear Regression;Save 对话框,如图1-5所示。
完成如图操作。
图1-5 线性回归分析:保存对话框6、单击Continue ,回到线性回归分析对话框,单击Options 按钮,打开Linear Regression ;Options 对话框,如图1-6所示。
回归分析实验报告

回归分析实验报告实验报告:回归分析摘要:回归分析是一种用于探究变量之间关系的数学模型。
本实验以地气温和电力消耗量数据为例,运用回归分析方法,建立了气温和电力消耗量之间的线性回归模型,并对模型进行了评估和预测。
实验结果表明,气温对电力消耗量具有显著的影响,模型能够很好地解释二者之间的关系。
1.引言回归分析是一种用于探究变量之间关系的统计方法,它通常用于预测或解释一个变量因另一个或多个变量而变化的程度。
回归分析陶冶于20世纪初,经过不断的发展和完善,成为了数量宏大且复杂的数据分析的重要工具。
本实验旨在通过回归分析方法,探究气温与电力消耗量之间的关系,并基于建立的线性回归模型进行预测。
2.实验设计与数据收集本实验选择地的气温和电力消耗量作为研究对象,数据选取了一段时间内每天的气温和对应的电力消耗量。
数据的收集方法包括了实地观测和数据记录,并在数据整理过程中进行了数据的筛选与清洗。
3.数据分析与模型建立为了探究气温与电力消耗量之间的关系,需要建立一个合适的数学模型。
根据回归分析的基本原理,我们初步假设气温与电力消耗量之间的关系是线性的。
因此,我们选用了简单线性回归模型进行分析,并通过最小二乘法对模型进行了估计。
运用统计软件对数据进行处理,并进行了以下分析:1)描述性统计分析:计算了气温和电力消耗量的平均值、标准差和相关系数等。
2)直线拟合与评估:运用最小二乘法拟合出了气温对电力消耗量的线性回归模型,并进行了模型的评估,包括了相关系数、残差分析等。
3)预测分析:基于建立的模型,进行了其中一未来日期的电力消耗量的预测,并给出了预测结果的置信区间。
4.结果与讨论根据实验数据的分析结果,我们得到了以下结论:1)在地的气温与电力消耗量之间存在着显著的线性关系,相关系数为0.75,表明二者之间的关系较为紧密。
2)构建的线性回归模型:电力消耗量=2.5+0.3*气温,模型参数的显著性检验结果为t=3.2,p<0.05,表明回归系数是显著的。
线性回归分析实验报告总结

RUN;
PROC GPLOT DATA=b;
PLOT RESIDUAL*PREDICTED RESIDUAL*x1 RESIDUAL*x2;
SYMBOL V=DOT I=NONE;
RUN;
PROC IML;
N=31;PI=1;
USE two_6;
READ ALL VAR{x1 x2 y} INTO M;
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 2 52294 26147 <.0001
Error12
Corrected Total14 53902
由表中的数据可知:SSE(F)=; =15-4=11,而从第(1)问可知SSE(R)=; =15-3=12;所以检验统计量观测值 =[()/1]/[11]=
X=M[,2]#M[,3];
X2=M[,3];
Y=M[,1];
P=Y||X||X2;
CREATE RESOLVE VAR{Y X X2};
APPEND FROM P;
QUIT;
PROC REG DATA=RESOLVE;
MODEL Y=X X2;
RUN;
PROC PRINT;
RUN;(1)<表一>参数估计的sas输出结果为:
(5)对于给定的X1、X2的值为(X01,X02)=(220,2500),由回归方程 =++得到销售量Y的预测值为
从proc reg过程得到矩阵(XTX)-1为:
令X0=(220,2500)T,因为MSE=,利用sas系统中proc iml过程计算可得
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验13回归分析报告报告材料
回归分析是统计学中的一种重要数据分析方法,用于研究因变量与一
个或多个自变量之间的关系。
本次实验旨在通过回归分析探究自变量对因
变量的影响程度及方向。
实验中使用了自变量X1、X2和X3,以及因变量Y,通过对样本数据的回归分析,得出了以下结果。
首先进行了数据的描述性统计分析。
根据数据,X1表示自变量1,X2
表示自变量2,X3表示自变量3,Y表示因变量。
其中,自变量1和自变
量2为连续变量,自变量3为分类变量。
因变量Y为连续变量。
样本数据
中自变量1的取值范围为0-100,自变量2的取值范围为-50至50,自变
量3为二分类变量,因变量Y的取值范围为-100至100。
样本量为N(样
本个数)。
根据数据进行了多元线性回归分析。
我们首先进行了回归模型的拟合
度检验。
通过回归分析得到的调整决定系数R^2_adjusted为0.6,p值小
于0.05,说明回归模型的拟合效果较好,自变量对因变量的解释程度较高。
同时,通过残差分析发现,残差的均值接近于0,说明回归模型的残
差符合正态分布。
接着,我们对回归系数进行了解释。
自变量1的回归系数为0.8,p
值小于0.05,说明自变量1正向影响因变量,并且影响显著。
自变量2
的回归系数为-0.5,p值小于0.05,说明自变量2负向影响因变量,并且
影响显著。
自变量3与因变量的关系通过二分类的回归系数来体现。
对于
自变量3来说,分类1的回归系数为0.2,p值小于0.05,分类2的回归
系数为-0.1,p值小于0.05、这说明自变量3对因变量的影响存在的差异,分类1正向影响因变量,分类2负向影响因变量,且影响均显著。
最后,我们对回归模型的预测能力进行了检验。
通过交叉验证方法,将数据分为训练集和测试集,使用训练集训练回归模型,然后用测试集验证模型的预测效果。
通过比较实际值和预测值的差异,得出了回归模型的预测误差。
通过均方根误差(RMSE)和平均绝对误差(MAE)计算,得到的RMSE为10,MAE为5,说明模型的预测能力较好。
综上所述,本次实验通过回归分析探究了自变量对因变量的影响程度及方向。
通过数据的描述性统计分析、回归模型的拟合度检验、回归系数的解释和模型预测能力的检验,得出了较为可靠的结果。
这对于进一步研究自变量与因变量之间的关系具有一定的指导意义,可以为相关领域的决策提供参考。
同时,在未来的研究中,可以进一步改进模型,加入更多的自变量以及进行更加全面细致的数据分析。