计量经济学第五讲 异方差 实验案例
实验六、异方差模型的检验与处理(1)
(教师演示和指导,学生模仿训练的范例)
【实验目的】
掌握异方差性的检验及处理方法
【实验内容】
建立并检验我国制造业利润函数模型
【实验方案设计】
表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。
一、检验异方差性
⒈图形分析检验
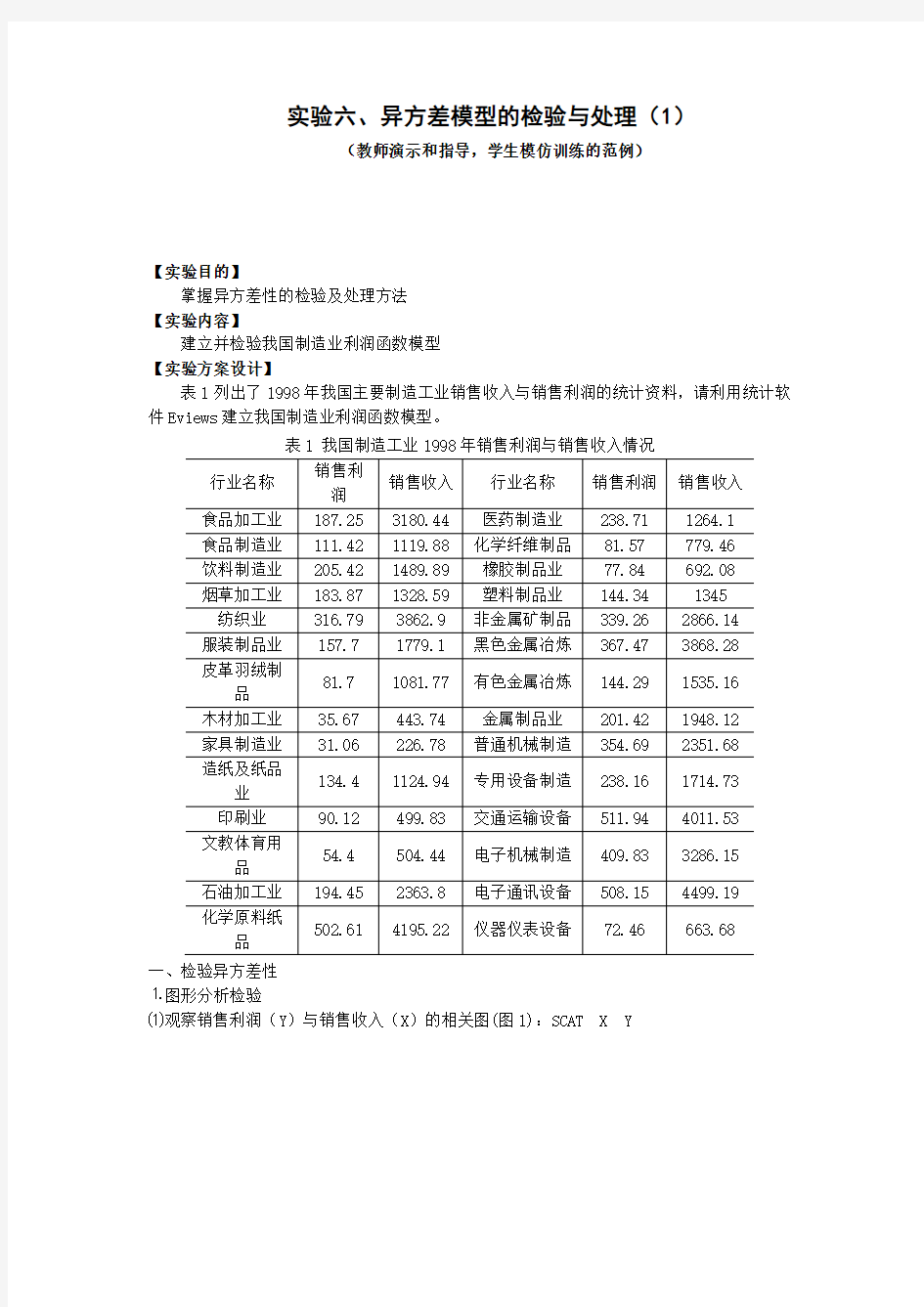
⑴观察销售利润(Y)与销售收入(X)的相关图(图1):SCAT X Y
图1 我国制造工业销售利润与销售收入相关图
从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。
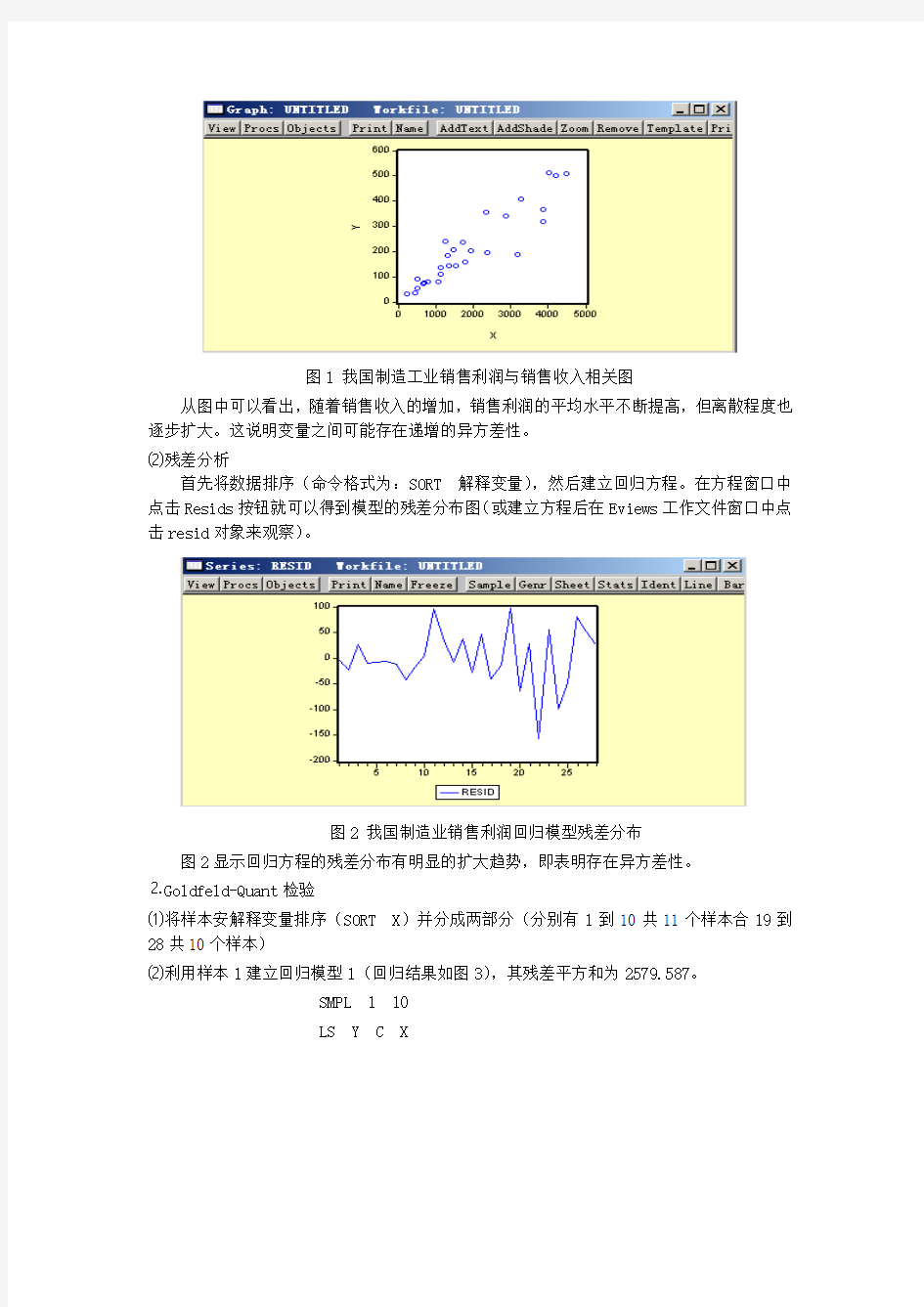
⑵残差分析
首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。
图2 我国制造业销售利润回归模型残差分布
图2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。
⒉Goldfeld-Quant检验
⑴将样本安解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本)
⑵利用样本1建立回归模型1(回归结果如图3),其残差平方和为2579.587。
SMPL 1 10
LS Y C X
图3 样本1回归结果
⑶利用样本2建立回归模型2(回归结果如图4),其残差平方和为63769.67。
SMPL 19 28 LS Y C X
图4 样本2回归结果
⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。
取
05
.0=α时,查F 分布表得
44.3)1110,1110(05.0=----F ,而
44.372.2405.0=>=F F ,所以存在异方差性
⒊White 检验
⑴建立回归模型:LS Y C X ,回归结果如图5。
图5 我国制造业销售利润回归模型
⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图6。
图6 White 检验结果
其中F 值为辅助回归模型的F 统计量值。取显著水平
05
.0=α,由于
2704.699.5)2(2205.0=<=nR χ,所以存在异方差性。实际应用中可以直接观察相伴概率
p 值的大小,若p 值较小,则认为存在异方差性。反之,则认为不存在异方差性。 ⒋Park 检验
⑴建立回归模型(结果同图5所示)。
⑵生成新变量序列:GENR LNE2=log(RESID^2)
GENR LNX=log(x)
⑶建立新残差序列对解释变量的回归模型:LS LNE2 C LNX ,回归结果如图7所示。
图7 Park 检验回归模型
从图7所示的回归结果中可以看出,LNX 的系数估计值不为0且能通过显著性检验,即
随即误差项的方差与解释变量存在较强的相关关系,即认为存在异方差性。
⒌Gleiser检验(Gleiser检验与Park检验原理相同)
⑴建立回归模型(结果同图5所示)。
⑵生成新变量序列:GENR E=ABS(RESID)
⑶分别建立新残差序列(E)对各解释变量(X、X^2、X^(1/2)、X^(-1)、 X^(-2)、 X^(-1/2))的回归模型:LS E C X,回归结果如图8、9、10、11、12、13所示。
图8
图9
图10
图11
图12
图13
由上述各回归结果可知,各回归模型中解释变量的系数估计值显著不为0且均能通过显著性检验。所以认为存在异方差性。
R确定异方差类型
⑷由F值或2
R值确定异方差的具体形式。本例中,图10所示的回Gleiser检验中可以通过F值或2
R)最大,可以据次来确定异方差的形式。
归方程F值(2
二、调整异方差性
⒈确定权数变量
根据Park检验生成权数变量:GENR W1=1/X^1.6743
根据Gleiser检验生成权数变量:GENR W2=1/X^0.5
另外生成:GENR W3=1/ABS(RESID)
GENR W4=1/ RESID ^2
⒉利用加权最小二乘法估计模型
在Eviews命令窗口中依次键入命令:
W) Y C X
LS(W=
i
或在方程窗口中点击Estimate\Option按钮,并在权数变量栏里依次输入W1、W2、W3、W4,回归结果图14、15、16、17所示。
图14
图15
图16
图17
⒊对所估计的模型再进行White检验,观察异方差的调整情况
对所估计的模型再进行White检验,其结果分别对应图14、15、16、17的回归模型(如图18、19、20、21所示)。图18、19、21所对应的White检验显示,P值较大,所以接收不存在异方差的原假设,即认为已经消除了回归模型的异方差性。图20对应的White检验
nR的值,这表示异方差性已经得到很好的解决。
没有显示F值和2
图18
图19
图20
图21
实验六、异方差模型的检验与处理(2)
(教师演示和指导,学生模仿训练的范例)
【目的及要求】
熟悉异方差检验的基本操作。
【实施环境】1、电脑1人一台。2、Eviews3.1学生版
【实验内容】
3、
序号居民储蓄个人收入
1 264 8777
2 105 9210
3 90 9954
4 131 10508
5 122 10979
6 10
7 11912
7 406 12747
8 503 13499
9 431 14269
10 588 15522
11 898 16730
12 950 17663
13 779 18575
14 819 19635
15 1222 21163
16 1702 22880
17 1578 24127
18 1654 25604
19 1400 26500
20 1829 27670
21 2200 28300
22 2017 27430
23 2105 29560
24 1600 28150
25 2250 32100
26 2420 32500
27 2570 35250
28 1720 33500
29 1900 36000
30 2100 36200
31 2300 38200
【实验方案设计】
1、以残差序列图检验异方差的存在性。
2、以残差与解释变量之间的变化趋势观察异方差的存在性。
3、以戈德菲尔德-夸特检验法WHITE检验法以及其他方法检验异方差性。
4、设法消除异方差性。
【实验过程】
需详尽记录步骤、记录、数据、程序等。
【结论】
(包括结果、分析,以及实验中存在的问题及解决方法:
全国各地区可支配收入与消费性支出异方差检验综合案例分析
全国各地区可支配收入与消费性支出异方差检验综合案例分析 小组成员:翟丽萍孙琴令穆小斌 张丹冶贵花王淏珑 指导老师:毛锦凰
2009年全国各地区城镇居民平均每人全年家庭可支配收入与消费性支出 地区 可支配消费性收入(x)支出(y) 北京26738.48 17893.30 天津21402.01 14801.35 河北14718.25 9678.75 山西13996.55 9355.10 内蒙古15849.19 12369.87 辽宁15761.38 12324.58 吉林14006.27 10914.44 黑龙江12565.98 9629.60 上海28837.78 20992.35 江苏20551.72 13153.00 浙江24610.81 16683.48 安徽14085.74 10233.98 福建19576.83 13450.57 江西14021.54 9739.99 山东17811.04 12012.73 河南14371.56 9566.99 湖北14367.48 10294.07 湖南15084.31 10828.23 广东21574.72 16857.50 广西15451.48 10352.38 海南13750.85 10086.65 重庆15748.67 12144.06 四川13839.40 10860.20 贵州12862.53 9048.29 云南14423.93 10201.81 西藏13544.41 9034.31 陕西14128.76 10706.67 甘肃11929.78 8890.79 青海12691.85 8786.52 宁夏14024.70 10280.00 新疆12257.52 9327.55
计量经济学 实验4 异方差
实验四异方差性 【实验目的】 掌握异方差性的检验及处理方法 【实验内容】 建立并检验我国制造业利润函数模型 【实验步骤】 【例1】表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。 一、检验异方差性 ⒈图形分析检验 ⑴观察销售利润(Y)与销售收入(X)的相关图(图1):SCAT X Y
图1 我国制造工业销售利润与销售收入相关图 从图中可以看出,随着销售收入X的增加,销售利润Y的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 ⑵残差分析 首先将数据排序(命令格式为:SORT X解释变量),然后建立回归方程。在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。View,Actual,Residuai 图2 我国制造业销售利润回归模型残差分布 图2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。 ⒉Goldfeld-Quant检验 ⑴将样本安解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本) ⑵利用样本1建立回归模型1(回归结果如图3),其残差平方和为2579.587。 SMPL 1 10 LS Y C X 图3 样本1回归结果 Dependent Variable: Y
Method: Least Squares Date: 11/14/13 Time: 13:37 Sample: 1 10 Included observations: 10 Variable Coefficient Std. Error t-Statistic Prob. C 15.76466 14.82022 1.063727 0.3185 X 0.085894 0.019182 4.477937 0.0021 R-squared 0.714814 Mean dependent var 77.06400 Adjusted R-squared 0.679166 S.D. dependent var 31.70225 S.E. of regression 17.95685 Akaike info criterion 8.790677 Sum squared resid 2579.587 Schwarz criterion 8.851194 Log likelihood -41.95338 F-statistic 20.05192 Durbin-Watson stat 2.280129 Prob(F-statistic) 0.002061 ⑶利用样本2建立回归模型2(回归结果如图4),其残差平方和为63769.67。 SMPL 19 28 LS Y C X 图4 样本2回归结果 Dependent Variable: Y Method: Least Squares Date: 11/14/13 Time: 13:39 Sample: 19 28 Included observations: 10 Variable Coefficient Std. Error t-Statistic Prob.
异方差完整案例分析
20世纪70年代中期,美国能源 部门试 图基于各地过去的汽油消耗量和人口变动情况 以及其他一些因素给各地区、 各州甚至 各零售点直接分配汽油。实现这种分配必须将大量因素作为各州 (各地区)的燃油消耗量(应 变量)的函数而建立模型。 而对于这样的横截面 模型,即使是估计的模型,也很可能会具有异 方差问题。 在模型中,应变量为各州的燃油消耗量,可能的解释变量包括:与各州规模大小相关 的变量(例如公路里程数、注册的机动车数量和人口),以及与各州规模大小无关的变量(例 如燃油税率和最高限速)。因为在模型中反映各州规模大小的变量不应多于一个(如果包含 过多变量容易导致多重共线性),因为有许多州的最高限速相同(但在时间序列模型中,它 将是一个有用的变量)。因此,一个合理的模型为: PCON i f (REG,TAX ) i o i REG i 2 TAX i i ( 10-20) 式中 PCON i ――第i 个州的燃油消耗量(百万 BTU ), REG i ――第i 个州的注册机动车数量(千辆), TAX i ――第i 个州的燃油税率(美分/加仑), i ――经典误差项。 我们可以认为一个州注册的汽车数量越多, 该州所消耗的燃油也越多; 而一个州的燃油 税率越高则该州的燃油消耗量越小 (10-20),得到: 二我们搜集那一时期的数据(见表 10-1 )用于估计方程 PCON i 551.7 0.1861REG i 53.59TAX i ( 10-21) (0.0117) ( 16.86) t 15.88 3.18 R 1 2 0.861 N 50 表10-1燃油消费例子中的数据 PCON UHM TAX REG POP e state 270 2.2 9 743 1136 62.335 Maine 122 2.4 14 774 948 176.52 New Hampshire 58 0.7 11 351 520 30.481 Vermont 821 20.6 9.9 3750 5750 101.87 Massachusetts 1 在方程中我们也可用TAX * REG 或者TAX * POP ( POP 代表第i 个州的人口)取代TAX 作为方程的解 释变量。我们在第7.5节中讨论虚拟变量斜率时曾介绍了一个关于交互项的更为复杂的例子。对于一个给 定的税率,它对一个大州的燃油消耗的影响要比对一个小州的影响大得多,而用反映州的规模大小的变量 乘以TAX 会使所得到的新变量(交互项)能够更好地 度量这一效应。 10.5 —个更完整的例子 让我们来看一个更完整的基于横殿面的异方差的例子。
计量经济学异方差性参考答案讲解
第五章 异方差性课后题参考答案 5.1 (1)因为22()i i f X X =,所以取221i i W X =,用2i W 乘给定模型两端,得 31232222 1i i i i i i i Y X u X X X X βββ=+++ 上述模型的随机误差项的方差为一固定常数,即 2 2221 ()()i i i i u Var Var u X X σ== (2)根据加权最小二乘法,可得修正异方差后的参数估计式为 ***12233???Y X X βββ=-- ()()( )()()( )( )** *2 ** * *222323 22 32 2 *2*2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑ ∑ ∑∑∑∑ ()()()()()()( )** *2 ** ** 232222223 3 2 *2 *2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑ ∑ ∑ ∑∑∑ 其中 2223 2***23222, , i i i i i i i i i W X W X W Y X X Y W W W = = = ∑∑∑∑∑∑ ***** *222333 i i i i i x X X x X X y Y Y =-=-=- 5.2 (1) 22222 11111 ln()ln()ln(1)1 u ln()1 Y X Y X Y u u X X X u ββββββββββ--==+≈=-∴=+ [ln()]0 ()[ln()1][ln()]11 E u E E u E u μ=∴=+=+=又 (2) [ln()]ln ln 0 1 ()11 i i i i P P i i i i P P i i E P E μμμμμμμ===?====∑∏∏∑∏∏不能推导出 所以E 1μ()=时,不一定有E 0μ(ln )= (3)对方程进行差分得: 1)i i βμμ--i i-12i i-1lnY -lnY =(lnX -X )+(ln ln
计量经济学课后答案第五章 异方差性汇总
第五章课后答案 5.1 (1)因为22()i i f X X =,所以取221i i W X =,用2i W 乘给定模型两端,得 31232222 1i i i i i i i Y X u X X X X βββ=+++ 上述模型的随机误差项的方差为一固定常数,即 2 2221 ()()i i i i u Var Var u X X σ== (2)根据加权最小二乘法,可得修正异方差后的参数估计式为 ***12233???Y X X βββ=-- ()()()() ()()() ***2*** *22232322 322*2*2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑∑∑∑∑∑ ()()( )()()( )( )** *2 ** ** 232222223 3 2 *2 *2** 2223223?i i i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-= -∑∑ ∑ ∑ ∑∑∑ 其中 2223 2***23222, , i i i i i i i i i W X W X W Y X X Y W W W = = = ∑∑∑∑∑∑ ***** *222333 i i i i i x X X x X X y Y Y =-=-=- 5.2 (1) 22222 11111 ln()ln()ln(1)1 u ln()1 Y X Y X Y u u X X X u ββββββββββ--==+≈=-∴=+ [ln()]0 ()[ln()1][ln()]11 E u E E u E u μ=∴=+=+=又 (2) [ln()]ln ln 0 1 ()11 i i i i P P i i i i P P i i E P E μμμμμμμ===?====∑∏∏∑∏∏不能推导出 所以E 1μ()=时,不一定有E 0μ(ln )= (3) 对方程进行差分得: 1)i i βμμ--i i-12i i-1lnY -lnY =(lnX -X )+(ln ln 则有:1)]0i i μμ--=E[(ln ln
异方差性的检验和补救
异方差性的检验和补救 一、研究目的和要求 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型,检验其是否存在异方差,并加以补救。 表1 我国制造工业1998年销售利润与销售收入情况 二、参数估计 EVIEWS 软件估计参数结果如下
Dependent Variable: Y Method: Least Squares Date: 06/01/16 Time: 20:16 Sample: 1 28 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 12.03349 19.51809 0.616530 0.5429 X 0.104394 0.008442 12.36658 0.0000 R-squared 0.854694 Mean dependent var 213.4639 Adjusted R-squared 0.849105 S.D. dependent var 146.4905 S.E. of regression 56.90455 Akaike info criterion 10.98938 Sum squared resid 84191.34 Schwarz criterion 11.08453 Log likelihood -151.8513 Hannan-Quinn criter. 11.01847 F-statistic 152.9322 Durbin-Watson stat 1.212781 Prob(F-statistic) 0.000000 用规范的形式将参数估计和检验结果写下 2?12.033490.104394(19.51809)(0.008442) =(0.616530) (12.36658)0.854694152.9322 i Y X t R F =+ = = 三、 检验模型的异方差 (一) 图形法 1. 相关关系图 X Y X Y 相关关系图
05 异方差性学习辅导
05 异方差性学习辅导 一、本章的基本内容 (一)基本内容 图5.1 第五章基本内容 (二)本章的教学目标 本章的教学目标是:深刻理解异方差性的实质、异方差出现的原因、异方差的出现对模型的不良影响(即异方差的后果),掌握估计和检验异方差性的基本思想和修正异方差的若干方法;能够运用所学的知识处理模型中出现的异方差问题,并要求初步掌握用EViews处理异方差的基本操作方法。
二、重点与难点分析 1、对异方差性的基本认识 由于2()()i i i i i Var u X Var Y X σ==,这里的方差度量的是被解释变量Y 的观测值围绕其条件期望的分散程度。因此对于同方差假定来说,指的是Y 的观测值围绕回归线的分散程度相同,而异方差性指的是被解释变量观测值的分散程度是随着解释变量的变化而变化的。 从设定误差角度看,模型中的随机扰动项主要代表两方面的影响:(1)被模型忽略的其他变量对被解释变量的影响 ;(2)测量误差的影响。实际上随机扰动主要代表的两方面因素都有可能随纳入模型的解释变量i X 的变化而变化,导致随机扰动的方差也随i X 的变化而变化,这种情况即称为存在异方差性。所以进一步可以把异方差性看成随机扰动项的方差是 某个解释变量的函数,22 ()()i i i Var u f X σσ== (1,2,)i n =L 。 2.为什么存在异方差时OLS 估计仍然是无偏估计? 参数OLS 估计的无偏性仅依赖于基本假定中随机误差项的零均值假定(即0)(=i u E ),以及解释变量的非随机性。事实上在第二章和第三章关于OLS 估计式无偏性的证明中并未涉及同方差性,所以异方差的存在并不影响参数估计式的无偏性。 3. 为什么存在异方差时OLS 估计式不再具有有效性? 为了便于理解出现异方差或自相关时对OLS 估计式方差的影响,以一元回归 12i i i Y X u ββ=++为例来说明。 2 2 2 222 12222 ()?()i i i i i i i i i i i i i i i i i i i i x y x Y Y x Y Y x Y x x x x x x X x x u x u x ββββ-== =- ==++=+∑∑∑∑ ∑∑∑∑∑∑∑∑ ∑∑ 222222222 2 ??()()[()][]i i i i i i x u x u Var E E E x x βββββ=-=+-=∑∑∑∑ 2 222222() 2[ ] () ()2() () i i i i j j i j i i i i j i j i j i x u x u x u E x x E u x x E u u x ≠≠+=+= ∑∑∑∑∑∑
异方差案例分析
异方差案例分析 中国农村居民人均消费支出主要由人均纯收入来决定。农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支付收入等。为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,可使用如下双对数模型: 1122ln ln ln Y X X βββμ0=+++ 其中,Y 表示农村家庭人均消费支出,X 1表示从事农业经营的收入,X 2表示其他收入。下表列出了中国2001年各地区农村居民家庭人均纯收入及消费支出的相关数据。 中国2001年各地区农村居民家庭人均纯收入与消费支出 单位:元
资料来源:《中国农村住户调查年鉴》(2002)、《中国统计年鉴》(2002)。 我们不妨假设该线性回归模型满足基本假定,采用OLS 估计法,估计结果如下: 12?ln 1.6550.3166ln 0.5084ln Y X X =++ (1.87) (3.02) (10.04) R 2=0.7831 R 2=0.7676 D.W.=1.89 F=50.53 RSS=0.8232
图1 估计结果显示,其他收入而不是从事农业经营的收入的增长,对农户消费支出的增长更具有刺激作用。下面对该模型进行异方差性检验。 1.图示法。 首先做出Y与X1、X2的散点图,如下:
图2 可见1X 基本在其均值附近上下波动,而2X 散点存在较为明显的增大趋势。 再做残差平方项2 ?i e 与1ln X 、2ln X 的散点图:
图3 图4 可见图1中离群点相对较少而图2呈现较为明显的单调递增的
异方差性。故初步判断异方差性主要是2X引起的。 2.G-Q检验 根据上述分析,首先将原始数据按X2升序排序,去掉中间7个数据,得到两个容量为12的子样本,记数据较小的样本为子样本1,数据较大的为子样本2。对子样本1进行OLS回归,结果如下: 图5 得到子样本1的残差平方和RSS1=0.064806; 再对子样本2进行OLS回归,结果如下:
计量经济学课件:第五章-异方差性汇总
第五章异方差性 本章教学要求:根据类型,异方差性是违背古典假定情况下线性回归模型建立的另一问题。通过本章的学习应达到,掌握异方差的基本概念包括经济学解释,异方差的出现对模型的不良影响,诊断异方差的方法和修正异方差的方法。经过学习能够处理模型中出现的异方差问题。 第一节异方差性的概念 一、例子 例1,研究我国制造业利润函数,选取销售收入作为解释变量,数据为1998年的食品年制造业、饮料制造业等28个截面数据(即n=28)。数据如下表,其中y表示制造业利润函数,x表示销售收入(单位为亿元)。
Y对X的散点图为 从散点图可以看出,在线性的基础上,有的点分散幅度较小,有的点分散幅度较大。因此,这种分散幅度的大小不一致,可以认为是由于销售收入的影响,使得制造业利润偏离均值的程度发生了变化,而这种偏离均值的程度大小不同是一种什么现象?如何定义?如果非线性,则属于哪类非线性,从图形所反映的特征看并不明显。 下面给出制造业利润对销售收入的回归估计。
模型的书写格式为 2 ?12.03350.1044(0.6165)(12.3666) 0.8547,..84191.34,152.9322213.4639, 146.4905 Y Y X R S E F Y s =+===== 通过变量的散点图、参数估计、残差图,可以看到模型中(随机误差)很有可能存在一种系统性的表现。 例2,改革开放以来,各地区的医疗机构都有了较快发展,不仅政府建立了一批医疗机构,还建立了不少民营医疗机构。各地医疗机构的发展状况,除了其他因素外主要决定于对医疗服务的需求量,而医疗服务需求与人口数量有关。为了给制定医疗机构的规划提供依据,分析比较医疗机构与人口数量的关系,建立卫生医疗机构数与人口数的回归模型。根据四川省2000年21个地市州医疗机构数与人口数资料对模型估计的结果如下: i i X Y 3735.50548.563?+-= (291.5778) (0.644284) t =(-1.931062) (8.340265) 785456.02=R 774146.02 =R 56003.69=F 式中Y 表示卫生医疗机构数(个),X 表示人口数量(万人)。从回归模型估计的
(完整word版)《计量经济学》各章主要知识点
第一章:绪论 1.计量经济学的学科属性、计量经济学与经济学、数学、统计学的关系; 2.计量经济研究的四个基本步骤 (1)建立模型(依据经济理论建立模型,通过模型识别、格兰杰因果关系检验、协整关系检验建立模型); (2)估计模型参数(满足基本假设采用最小二乘法,否则采用其他方法:加权最小二乘估计、模型变换、广义差分法等); (3)模型检验:经济意义检验(普通模型、双对数模型、半对数模型中的经济意义解释,见例1、例2),统计检验(T 检验,拟合优度检验、F 检验,联合检验等);计量经济学检验(异方差、自相关、多重共线性、在时间序列模型中残差的白噪声检验等); (4)模型应用。 例1:在模型中,y 某类商品的消费支出,x 收入,P 商品价格,试对模型进行经济意义检验,并解释21,ββ的经济学含义。 t t t P x y 31.0ln 25.0213.0ln -+=∧, 其中参数21,ββ都可以通过显著性检验。 经济意义检验可以通过(商品需求与收入正相关、与商品价格负相关)。 商品消费支出关于收入的弹性为0.25()/ln(25.0)/ln(11-∧ -=t t t t x x y y ); 价格增加一个单位,商品消费需求将减少31%。 例2:研究金融发展与贫富差距的关系,认为金融发展先使贫富差距加大(恶化),尔后会使贫富差距降低(好转),成为倒U 型。 贫富差距用GINI 系数表示,金融发展用(贷款余额/存款总额)表示。回归结果
为: 229.164.034.2t t t x x GINI -+=∧, 模型参数都可以通过显著性检验。 在x 的有意义的变化范围内,GINI 系数的值总是大于1,细致分析后模型变的毫无意义; 同样的模型还有:GINI 系数的值总是为负 231.1412.734.13t t t x x GINI -+-=∧。 3.计量经济学中的一些基本概念 数据的三种类型:横截面数据、时间序列数据、面板数据; 线性模型的概念;模型的解释变量与被解释变量,被解释变量为随机变量(如 果一个变量为随机变量,并与随机扰动项相关,这个变量称为内生变量),被解释变量为内生变量,有些解释变量也为内生变量。 第二章:回归模型 1.两个变量的相关关系,相关关系与随机因果关系的区别; 2.总体回归函数与线性总体回归函数; 3.一元与多元线性回归模型,回归模型的基本假设; 4.最小二乘估计的基本原理与最小二乘估计量的具体表达式,随机扰动项的方差的估计方法; 5.最小二乘估计的数值性质与最小二乘估计的统计性质,样本容量变化对统计性质的影响; 6.在回归模型中(包括对数模型)计量单位变化对模型参数估计的影响(例3); 7.样本回归直线及其性质;
R案例分析_异方差
第五章 案例分析 一、问题的提出和模型设定 为了分析不同省份或城市的交通和通讯支出的规划提供依据,分析交通和通讯支出与可支配收入的关系,建立交通和通讯支出与可支配收入的回归模型。假定交通和通讯支出与可支配收入满足线性约束,则理论模型设定为 i i i cum income u αβ=+?+ (1) 其中i cum 表示交通和通讯支出,i income 表示可支配收入。 由1999年《中国统计年鉴》得到如下数据 注:见数据文件cumexp_income.csv 二、参数估计 利用最小二乘法估计模型(1)的参数: mydata.lm <- lm(cumexp ~ income) summary(mydata.lm) R 软件输出的结果为: Call: lm(formula = cumexp ~ income) Residuals: Min 1Q Median 3Q Max -97.465 -19.986 -5.111 15.532 184.115
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -56.91798 36.20624 -1.572 0.127 income 0.05808 0.00648 8.962 1.02e-09 *** --- Signif. codes : 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 50.48 on 28 degrees of freedom Multiple R-squared: 0.7415, Adjusted R-squared: 0.7323 F-statistic: 80.32 on 1 and 28 DF, p-value: 1.021e-09 估计结果为: ?56.920.06(36.21)(0.01) cum income =-+ 20.74 ..504880.32R s e F === 括号内为标准差。 三、检验模型的异方差 (一)图示法 par(mfrow=c(1,2)) plot(cumexp ~ income, col="red") abline(mydata.lm) plot(residuals(mydata.lm)^2 ~ income,col="blue") 从上图可以看出,残差平方对解释变量X 的散点图主要分布在图形中的下三角部分,大40006000 8000200300400500 600 a.散点图及回归线income c u m e x p 4000600080000500010000200003000 0 b.残差平方的散点图 income r e s i d u a l s (m y d a t a .l m )^2
计量经济学-异方差性
计量经济学——异方差性 5.3解: (1)构建以家庭消费支出(Y)为被解释变量,家庭人均纯收入(X)为解释变量的线性回归模型: Y i=β1+β2X i+u i 建立Eviews文件,生成家庭消费支出(Y)、家庭人均纯收入(X)等数据,利用OLS方法估计模型参数,得到的回归结果如下图所示: Dependent Variable: Y Method: Least Squares Date: 11/05/14 Time: 00:56 Sample: 1 31 Included observations: 31 Variable Coefficient Std. Error t-Statistic Prob. C 179.1916 221.5775 0.808709 0.4253 X 0.719500 0.045700 15.74411 0.0000 R-squared 0.895260 Mean dependent var 3376.309 Adjusted R-squared 0.891649 S.D. dependent var 1499.612 S.E. of regression 493.6240 Akaike info criterion 15.30377 Sum squared resid 7066274. Schwarz criterion 15.39628 Log likelihood -235.2084 Hannan-Quinn criter. 15.33392 F-statistic 247.8769 Durbin-Watson stat 1.461684 Prob(F-statistic) 0.000000 即参数估计与检验的结果为 Y i=179.1916+0.719500X i (221.5775)(0.045700) t=(0.808709) (15.74411) R2=0.895260 F=247.8769 n=31 (2)利用White方法检验异方差,则White检验结果见下表: Heteroskedasticity Test: White F-statistic 7.194463 Prob. F(2,28) 0.0030 Obs*R-squared 10.52295 Prob. Chi-Square(2) 0.0052 Scaled explained SS 30.08105 Prob. Chi-Square(2) 0.0000 Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 11/05/14 Time: 01:11 Sample: 1 31 Included observations: 31 Variable Coefficient Std. Error t-Statistic Prob.
计量经济学异方差实验报告二
实验报告2 实验目的:掌握异方差的检验及处理方法。 实验容:检验家庭人均纯收入与家庭生活消费支出可能存在的异方差性。有关数据如下:其中,收入为X,家庭生活消费支出为Y。 地区家庭人均 纯收入 家庭生活 消费支出地区 家庭人均 纯收入 家庭生活 消费支出 北京9439.63 6399.27 湖北3997.48 3090 天津7010.06 3538.31 湖南3904.2 3377.38 河北4293.43 2786.77 广东5624.04 4202.32 山西3665.66 2682.57 广西3224.05 2747.47 3953.1 3256.15 海南3791.37 2556.56 辽宁4773.43 3368.16 重庆3509.29 2526.7 吉林4191.34 3065.44 四川3546.69 2747.27 4132.29 3117.44 贵州2373.99 1913.71 上海10144.62 8844.88 云南2634.09 2637.18 江苏6561.01 4786.15 西藏2788.2 2217.62 浙江8265.15 6801.6 陕西2644.69 2559.59 安徽3556.27 2754.04 甘肃2328.92 2017.21 福建5467.08 4053.47 青海2683.78 2446.5 江西4044.7 2994.49 宁夏3180.84 2528.76 山东4985.34 3621.57 新疆3182.97 2350.58 河南3851.6 2676.41 实验步骤如下: 一、建立有关模型分析异方差检验如下。 方法一、图示法。(两种) (一)、x y 相关分析 从图中可以看出,随着收入的增加,家庭生活消费支出不断的提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 建立模型: 1、从图中可以看出,x y不是简单的线性关系。建立线性回归方程如下, LS Y C X
计量经济学:异方差性
异方差性 在现实经济活动中,最小二乘法的基本假定并非都能满足,上一章介绍的多重共线性只是其中一个方面,本章将讨论违背基本假定的另一个方面——异方差性。虽然它们都是违背了基本假定,但前者属于解释变量之间存在的问题,后者是随机误差项出现的问题。本章将讨论异方差性的实质、异方差出现的原因、异方差的后果,并介绍检验和修正异方差的若干方法。 第一节异方差性的概念
一、异方差性的实质 第二章提出的基本假定中,要求对所有的i (i=1,2,…,n )都有 2 )(σ=i u Var (5.1) 也就是说i u 具有同方差性。这里的方差2σ度量的是随机误差项围绕其均值的分散程度。由于0)(=i u E ,所以等价地说,方差2σ度量的是被解释变量Y 的观测值围绕回归线 )(i Y E =ki k i X X βββ+++ 221的分散程度,同方差性实际指的是相对于回归线被解释变 量所有观测值的分散程度相同。 设模型为 n i u X X Y i ki k i i ,,2,1221 =++++=βββ (5.2) 如果其它假定均不变,但模型中随机误差项i u 的方差为 ).,,3,2,1(, )(22n i u Var i i ==σ (5.3) 则称i u 具有异方差性。 由于异方差性指的是被解释变量观测值的分散程度是随解释变量的变化而变化的,如图5.1所示,所以进一步可以把异方差看成是由于某个解释变量的变化而引起的,则 )()(2 22i i i X f u Var σσ== (5.4) 图5.1 二、产生异方差的原因
由于现实经济活动的错综复杂性,一些经济现象的变动与同方差性的假定经常是相悖的。所以在计量经济分析中,往往会出现某些因素随其观测值的变化而对被解释变量产生不同的影响,导致随机误差项的方差相异。通常产生异方差有以下主要原因: 1、模型中省略了某些重要的解释变量 异方差性表现在随机误差上,但它的产生却与解释变量的变化有紧密的关系。如果计量模型本来应当为i i i i u X X Y +++=33221βββ,假如被略去了i X 3,而采用了 *221i i i u X Y ++=ββ (5.5) 当被略去的i X 3与i X 2有呈同方向或反方向变化的趋势时,i X 3随i X 2的有规律变化会体现在(5.5)式的* i u 中。如果将某些未在模型中出现的重要影响因素归入随机误差项,而且这些影响因素的变化具有差异性,则会对被解释变量产生不同的影响,从而导致误差项的方差随之变化,即产生异方差性。在第四章已经讨论过,可以通过剔除变量的方法去避免多重共线性的影响,但是如果删除了重要的变量又有可能引起异方差性。这是在建模过程中应当引起注意的问题。 2、模型设定误差 模型的设定主要包括变量的选择和模型数学形式的确定。模型中略去了重要解释变量常常导致异方差,实际就是模型设定问题。除此而外,模型的函数形式不正确,如把变量间本来为非线性的关系设定为线性,也可能导致异方差。 3、测量误差的变化 样本数据的观测误差有可能随研究范围的扩大而增加,或随时间的推移逐步积累,也可能随着观测技术的提高而逐步减小。例如生产函数模型,由于生产要素投入的增加与生产规模相联系,在其他条件不变的情况下,测量误差可能会随生产规模的扩大而增加,随机误差项的方差会随资本和劳动力投入的增加而变化。另一方面当用时间序列数据估计生产函数时,由于抽样技术和数据收集处理方法的改进,观测误差有可能会随着时间的推移而降低。 4、截面数据中总体各单位的差异 通常认为,截面数据较时间序列数据更容易产生异方差。例如,运用截面数据研究消费和收入之间的关系时,如果采取不同家庭收入组的数据,低收入组的家庭用于购买生活必需品的比例相对较大,消费的分散程度不大,组内各家庭消费的差异也较小。高收入组的家庭有更多自由支配的收入,家庭消费有更广泛的选择范围,消费的分散程度较大,组内各家庭
计量经济学重点(简答题)
计量经济学重点(简答题) 一、什么是计量经济学?计量经济学,又称经济计量学,它是以一 定的经济理论和实际统计资料为依据,运用数学、统计学和计算机技术,通过建立计量经济学模型,定量分析经济变量之间的随机因果关系.。 二、计量经济学的研究的步骤是什么? 1)理论模型的设计 A.理论或假说的陈述; B.理论的数学模型的设定; C.理论的计量经济模型的设定。 i.把模型中不重要的变量放进随机误差项中; ii.拟定待估参数的理论期望值。 2)获取数据 数据来源:网络、统计年鉴、报纸、杂志 数据类别:时间序列数据、截面数据、混合数据、虚变量 数据。 数据要求:完整性、准确性、可比性、一致性 i.完整性:模型中包含的所有变量都必须得到相同容量 的样本观察值。 ii.准确性:统计数据或调查数据本身是准确的。
iii.可比性:数据口径问题。 iv.一致性:指母体与样本的一致性。 3)模型的参数估计:普通最小二乘法。 4)模型的检验:经济学检验;统计学检验;计量经济学检验; 模型的预测检验。 5)模型的应用:结构分析;经济预测;政策评价;经济理论的 检验与发展。 三、简述统计数据的类别? 时间序列数据、截面数据、混合数据、虚变量数据。 1)时间序列数据:按时间先后排列收集的数据。 采纳时间序列数据的注意事项: A.所选择的样本区间的经济行为一致性问题。 B.样本数据在不同样本点之间的可比性问题。 C.样本数据过于集中的问题。不能反映经济变量间的结构关 系,应增大观察区间。 D.模型的随机误差项序列相关问题。 2)截面数据:又称横向数据,是一批发生在同一时间截面上的 调查数据。研究某时点上的变化情况。 采纳截面数据的注意事项: A.样本与母体的一致性问题。 B.随机误差项的异方差问题。
EViews计量经济学实验报告-异方差的诊断及修正
实验题目 异方差的诊断与修正 一、实验目的与要求: 要求目的:1、用图示法初步判断是否存在异方差,再用White 检验异方差; 2、用加权最小二乘法修正异方差。 二、实验内容 根据1998年我国重要制造业的销售利润与销售收入数据,运用EV 软件,做回归分析,用图示法,White 检验模型是否存在异方差,如果存在异方差,运用加权最小二乘法修正异方差。 三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等) (一) 模型设定 为了研究我国重要制造业的销售利润与销售收入是否有关,假定销售利润与销售收入之间满足线性约束,则理论模型设定为: i Y =1β+2βi X +i μ 其中,i Y 表示销售利润,i X 表示销售收入。由1998年我国重要制造业的销售收入与销售利润的数据,如图1: 1988年我国重要制造业销售收入与销售利润的数据 (单位:亿元)
(二) 参数估计 1、双击“Eviews ”,进入主页。输入数据:点击主菜单中的File/Open /EV Workfile —Excel —异方差数据2.xls ; 2、在EV 主页界面的窗口,输入“ls y c x ”,按“Enter ”。出现OLS 回归结果,如图2: 估计样本回归函数 Dependent Variable: Y Method: Least Squares Date: 10/19/05 Time: 15:27 Sample: 1 28 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 12.03564 19.51779 0.616650 0.5428 X 0.104393 0.008441 12.36670 0.0000 R-squared 0.854696 Mean dependent var 213.4650 Adjusted R-squared 0.849107 S.D. dependent var 146.4895 S.E. of regression 56.90368 Akaike info criterion 10.98935 Sum squared resid 84188.74 Schwarz criterion 11.08450 Log likelihood -151.8508 F-statistic 152.9353 Durbin-Watson stat 1.212795 Prob(F-statistic) 0.000000 估计结果为: i Y ? = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670) 2R =0.854696 2R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353 这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。 2R =0.854696 , 拟合程度较好。在给定 =0.0时,t=12.36670 > )26(025.0t =2.056 ,拒 绝原假设,说明销售收入对销售利润有显著性影响。F=152.9353 > )6,21(F 05.0= 4.23 ,
异方差完整案例分析
10.5 一个更完整的例子 让我们来看一个更完整的基于横殿面的异方差的例子。20世纪70年代中期,美国能源部门试图基于各地过去的汽油消耗量和人口变动情况以及其他一些因素给各地区、各州甚至各零售点直接分配汽油。实现这种分配必须将大量因素作为各州(各地区)的燃油消耗量(应变量)的函数而建立模型。而对于这样的横截面模型,即使是估计的模型,也很可能会具有异方差问题。 在模型中,应变量为各州的燃油消耗量,可能的解释变量包括:与各州规模大小相关的变量(例如公路里程数、注册的机动车数量和人口),以及与各州规模大小无关的变量(例如燃油税率和最高限速)。因为在模型中反映各州规模大小的变量不应多于一个(如果包含过多变量容易导致多重共线性),因为有许多州的最高限速相同(但在时间序列模型中,它将是一个有用的变量)。因此,一个合理的模型为: 012(,)i i i i i PCON f REG TAX REG TAX εβββε+- =+=+++ (10-20) 式中 i PCON ——第i 个州的燃油消耗量(百万BTU ), i REG ——第i 个州的注册机动车数量(千辆), i TAX ——第i 个州的燃油税率(美分/加仑), i ε——经典误差项。 我们可以认为一个州注册的汽车数量越多,该州所消耗的燃油也越多;而一个州的燃油 税率越高则该州的燃油消耗量越小1 。我们搜集那一时期的数据(见表10-1)用于估计方程(10-20),得到: i i i TAX REG PCON 59.531861.07.551-+=∧ (10-21) (0.0117) (16.86) 15.88t = 3.18- 20.861R = 50N = 表10-1 燃油消费例子中的数据 PCON UHM TAX REG POP e state 270 2.2 9 743 1136 62.335 Maine 122 2.4 14 774 948 176.52 New Hampshire 58 0.7 11 351 520 30.481 Vermont 821 20.6 9.9 3750 5750 101.87 Massachusetts 1 在方程中我们也可用*TAX REG 或者*TAX POP (i POP 代表第i 个州的人口)取代TAX 作为方程的解 释变量。我们在第7.5节中讨论虚拟变量斜率时曾介绍了一个关于交互项的更为复杂的例子。对于一个给定的税率,它对一个大州的燃油消耗的影响要比对一个小州的影响大得多,而用反映州的规模大小的变量乘以TAX 会使所得到的新变量(交互项)能够更好地度量这一效应。