一元线性回归公式
1一元线性回归方程
i =1 n
i =1 n
2
Lxy = ∑( Xi − X ) (Yi −Y )
i=1
ˆ ˆ β0 = Y − β1 X ˆ Lxy β1 = Lxx
二、OLS回归直线的性质 回归直线的性质
ˆ (1)估计的回归直线 Yi )
(2) )
ˆ ˆ = β 0 + β 1X i
前三个条件称为G-M条件 条件 前三个条件称为
§1.2 一元线性回归模型的参数估计
普通最小二乘法( Squares) 普通最小二乘法(Ordinary Least Squares) OLS回归直线的性质 OLS回归直线的性质 OLSE的性质 OLSE的性质
一、普通最小二乘法
对于所研究的问题, 对于所研究的问题,通常真实的回归直线 E(Yi|Xi) = β0 + β1Xi 是观 测不到的。可以通过收集样本来对真实的回归直线做出估计。 测不到的。可以通过收集样本来对真实的回归直线做出估计。
Y
55 80 100 120140 160
X
二、随机误差项εi的假定条件 随机误差项
为了估计总体回归模型中的参数,需对随机误差项作出如下假定: 为了估计总体回归模型中的参数,需对随机误差项作出如下假定: 假定1: 假定 :零期望假定:E(εi) = 0。 。 假定2: 假定 :同方差性假定:Var(εi) = σ 2。 假定3: 假定 :无序列相关假定:Cov(εi, εj) = 0, (i ≠ j )。 。 假定4: 假定 : εi 服从正态分布,即εi ∼ N (0, σ 2 )。 。
以下设 x 为自变量(普通变量 Y 为因变量(随机变 普通变量) 普通变量 随机变 量) .现给定 x 的 n 个值 x1,…, xn, 观察 Y 得到相应的 n 个 值 y1,…,yn, (xi ,yi) i=1,2,…, n 称为样本点 样本点. 样本点 以 (xi ,yi) 为坐标在平面直角坐标系中描点,所得到 的这张图便称之为散点图 散点图. 散点图
第三章 一元线性回归模型

第三章 一元线性回归模型一、预备知识(一)相关概念对于一个双变量总体,若由基础理论,变量和变量之间存在因果),(i i x y x y 关系,或的变异可用来解释的变异。
为检验两变量间因果关系是否存在、x y 度量自变量对因变量影响的强弱与显著性以及利用解释变量去预测因变量x y x ,引入一元回归分析这一工具。
y 将给定条件下的均值i x i yi i i x x y E 10)|(ββ+=(3.1)定义为总体回归函数(PopulationRegressionFunction,PRF )。
定义为误差项(errorterm ),记为,即,这样)|(i i i x y E y -i μ)|(i i i i x y E y -=μ,或i i i i x y E y μ+=)|(i i i x y μββ++=10(3.2)(3.2)式称为总体回归模型或者随机总体回归函数。
其中,称为解释变量x (explanatory variable )或自变量(independent variable );称为被解释y 变量(explained variable )或因变量(dependent variable );误差项解释μ了因变量的变动中不能完全被自变量所解释的部分。
误差项的构成包括以下四个部分:(1)未纳入模型变量的影响(2)数据的测量误差(3)基础理论方程具有与回归方程不同的函数形式,比如自变量与因变量之间可能是非线性关系(4)纯随机和不可预料的事件。
在总体回归模型(3.2)中参数是未知的,是不可观察的,统计计10,ββi μ量分析的目标之一就是估计模型的未知参数。
给定一组随机样本,对(3.1)式进行估计,若的估计量分别记n i y x i i ,,2,1),,( =10,),|(ββi i x y E 为,则定义3.3式为样本回归函数^1^0^,,ββi y ()i i x y ^1^0^ββ+=n i ,,2,1 =(3.3)注意,样本回归函数随着样本的不同而不同,也就是说是随机变量,^1^0,ββ它们的随机性是由于的随机性(同一个可能对应不同的)与的变异共i y i x i y x 同引起的。
最新高教版中职数学基础模块下册10.5一元线性回归3课件PPT.ppt

回归直线方程 yˆ a bx 其中a、b是待定系数
n
xi yi nxy
b i1
,
n
xi2 nx 2
②
i 1
a y bx
用公式②来求例1中腐蚀深度 Y 对腐蚀时间x的回归直线方程.
序x
y
x2
号
1
5
6
25
2 10 10 100
y2
xy
36
30
100
100
由左表算得,x 的平均数为 510 ,
361
950
8 60 53 3600 529 1380 回归系数 b=0.304 ,它的意义是:
9 70 25 4900 625 1750 腐蚀时间 x 每增加一个单位,
10 90 29 8100
841 2610
11 120 46 1400 2116 5520 深度 Y 平均增加 0.304 个单位.
叫画做出散的点一图条.直线
110000
115500
50
40
这样的直线
30
可以画多少
20
条系呢列?1
10 哪一条最能代表变量x与Y之间的关系呢?
0
0
50
100
150
显然这样的直线还可以画出许多条,而我们希望找出 其中的一条,它能最好地反映x与Y之间的关系,这条 直线就叫回归直线,记此直线方程为:yˆ a bx ① 则①式叫做Y对x的回归直线方程,b叫做回归系数.
∑ 510 214 36750 5422 13910
例2 设对变量 x,Y 有如下观察数据:
x 151 152 153 154 156 157 158 160 160 162 163 164 Y 40 41 41 41.5 42 42.5 43 44 45 45 46 45.5
一元线性回归

由此可推测:当火灾发生地离最近的消 防 站 为 10km 时 , 火 灾 损 失 大 致 在
ˆ y 10.279 49.19 59.369(千元) 当火 ;
灾发生地离最近的消防站为 2km 时,火灾损 失大致在 20.117(千元)
三、0,1的性质
1, 线性
1
(x x ) y
为 y 关于 x 的一元线性经验回归方程 (简称为回归直
ˆ 线方程) 0 为截距, 1 为经验回归直线的斜率。 , ˆ
引进矩阵的形式:
y1 1 x1 1 0 y2 1 x2 2 设 y , X , , 1 y 1 x n n n
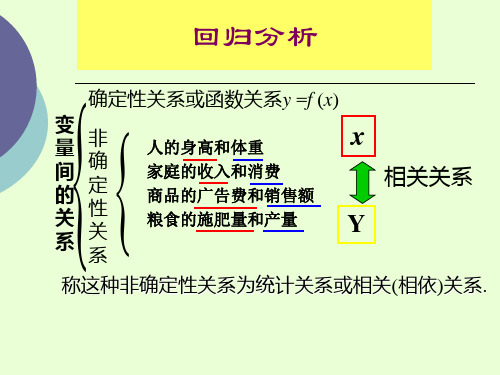
变量之间具有密切关联 而又不能由一个或某一些变 量唯一确定另外一个变量的 关系称为变量之间的相关关 系.
y
y f ( x)
y
Y f (X )
0
(a) 函数关系
x
0
(b) 统计关系
x
种类
正相关 负相关
一元相关 多元相关
线性相关 曲线相关
y
y
y
y
正相关
x
负相关
x
曲线相关
x
不相关
x
例 2 城镇居民的收入与消费支出之间有很大的关 联,居民的收入提高了,消费也随之潇洒,但居民的 收入不能完全确定消费,人们的消费支出受到不同年 龄段的消费习惯的影响,也受到不同消费理念的影响。 因此居民的收入 x 与消费支出 y 就呈现出某种不确定 性。 我们将上海市城镇居民可支配收入与支出的数据 (1985 年~2002 年)用散点图表示,可以发现居民的 收入 x 与消费支出 y 基本上呈现线性关系,但并不完 全在一条直线上。 附数据与图形。
一元线性回归模型及其假设条件

§4.2 一元线性回归模型及其假设条件 1.理论模型 y=a+bx+εX 是解释变量,又称为自变量,它是确定性变量,是可以控制的。
是已知的。
Y 是被解释变量,又称因变量,它是一个随机性变量。
是已知的。
A,b 是待定的参数。
是未知的。
2.实际中应用的模型x b a yˆˆˆ+= aˆ,b ˆ,x 是已知的,y ˆ是未知的。
回归预测方程:x b a y+= a ,b称为回归系数。
若已知自变量x 的值,则通过预测方程可以预测出因变量y 的值,并给出预测值的置信区间。
3.假设条件ε满足条件:(1)E (ε)=0;(2)D (εi )=σ2;(3)Cov (εi ,εj )=0,i ≠j ; (4) Cov (εi ,εj )=0 。
条件(1)表示平均干扰为0;条件(2)表示随机干扰项等方差;条件(3)表示随机干扰项不存在序列相关;条件(4)表示干扰项与解释变量无关。
在假定条件(4)成立的情况下,随机变量y ~N (a+bx ,σ2)。
一般情况下,ε~N (0,σ2)。
4.需要得到的结果aˆ,b ˆ,σ2§4.3 模型参数的估计 1.估计原理回归系数的精确求估方法有最小二乘法、最大似然法等多种,我们这里介绍最小二乘法。
估计误差或残差:y y e iii-=,x b a yi+=,e e y y iiiix b a ++=+=(5.3—1)误差e i 的大小,是衡量a 、b好坏的重要标志,换句话讲,模型拟合是否成功,就看残差是否达到要求。
可以看出,同一组数据,对于不同的a 、b有不同的e i ,所以,我们的问题是如何选取a 、b使所有的e i 都尽可能地小,通常用总误差来衡量。
衡量总误差的准则有:最大绝对误差最小、绝对误差的总和最小、误差的平方和最小等。
我们的准则取:误差的平方和最小。
最小二乘法:令 ()()∑∑---∑======ni ni ni ix b a y y y e i ii i Q 112212(5.3—2)使Q 达到最小以估计出a、b的方法称为最小二乘法。
一元线性回归分析

(n
2)
S2 ˆ0
2 ˆ0
:
2(n 2)
S 2 ˆ1
S2
n
(Xt X )2
t 1
(n
2)
S2 ˆ1
2 ˆ1
:
2(n 2)
所以根据t分布的定义,有
ˆ0 0 ~ t(n 2), ˆ1 1 ~ t(n 2)
Sˆ0
Sˆ1
进而得出了0的置信水平为1-区间估计为
et Yt Yˆt称为残差,与总体的误差项ut对应,n为样 本的容量。
样本回归函数与总体回归函数区别
1、总体回归线是未知的,只有一条。样本回归线是根据样本数 据拟合的,每抽取一组样本,便可以拟合一条样本回归线。
2、总体回归函数中的β0和β1是未知的参数,表现为常数。而样
本回归函数中的 ˆ0和是ˆ1 随机变量,其具体数值随所抽取
S 44.0632
Sef S
1 1 n
( X f X )2
n
45.543
( Xt X )2
t 1
所求置信区间为:(188.6565 97.6806)
回归分析的SPSS实现
“Analyze->Regression->Linear”
0
n
2 t1 Xt (Yt ˆ0 ˆ1 Xt ) 0
nˆ0
n
ˆ1
t 1
Xt
n
Yt
t 1
n
n
n
ˆ0
t 1
Xt
ˆ1
t 1
X
2 t
第十三章 一元线性回归
变量之间存在关系的两种类型: 确定性关系(函数关系) 不确定性关系(相关关系)
函数关系
1.
2.
3.
是一一对应的确定关系:一 个(或多个)确定的自变量 的值对应一个确定的因变量 的值。 y 设有两个变量 x 和 y ,变量 y 随变量 x 一起变化,并完 全依赖于 x ,当变量 x 取某 个数值时, y 依确定的关系 取相应的值,则称 y 是 x 的 函数,记为 y = f (x),其中 x 称为自变量,y 称为因变量 x 各观测点落在一条线上
l xy = ( x x)( y y ) = xy N x y
则:a = y b x
b = l xy / l xx
步骤:1、由变量x求 x来自l xx (自方差) 2、由变量y求 y,l yy 3、由x、y求l xy (协方差) 4、求a、b ˆ 5、写出方程:y = a + bx
【例】有15个学生,数学和物理成绩列于表内, 现想求一个物理成绩对数学成绩的一元回归方 程。
23 8 40 19 60 69 21 66 15 46 26 32 30 58 28 22 23 33 41 57 7 57 37 68 27 41 20 30
数学(x) 31 物理(y) 32
解:
1.
2.
3.
相关分析中,变量 x 变量 y 处于平等的地位;回 归分析中,变量 y 称为因变量,处在被解释的地 位,x 称为自变量,用于预测因变量的变化 相关分析中所涉及的变量 x 和 y 都是随机变量; 回归分析中,因变量 y 是随机变量,自变量 x 可 以是随机变量,也可以是非随机的确定变量 相关分析主要是描述两个变量之间线性关系的密 切程度;回归分析不仅可以揭示变量 x 对变量 y 的影响大小,还可以由回归方程进行预测和控制
一元线性回归
残差平方和决定系数首先看看几个定义:总体平方和TSS( total sum of squares)回归平方和RSS(regression sum of squares)残差平方和ESS(Residual sum of squares)其中,y i表示实验数据,f i表示模拟值,表示样本平均值。
决定系数(Coefficient of determination)在一定程度上反应了模型的拟合优度。
其实就是回归平方和在总体平方和中所占的比例。
因为TSS=RSS+ESSThe better the linear regression (on the right) fits the data in comparison to the simple average (on the left graph), the closer the value of R2 is to one. The areas of the blue squares represent the squared residuals with respect to the linear regression. The areas of the red squares represent the squared residuals with respect to the average value.红色区域是总体平方和,蓝色为残差平方和。
>> 为什么要用决定系数去反应拟合优度,而不用残差平方和呢?>> 因为,残差平方和与观测值的绝对大小有关,而决定系数是一个比例。
比如:有一组数据:1000,2000,35000...另一组数据:1,2,3.5...这个时候就会发现第一组数据的拟合后残差平方和会大很多,但是不见得,模型拟合优度就会差。
第三章 一元线性回归第一部分 学习指导一、本章学习目的与要求1、掌握一元线性回归的经典假设;2、掌握一元线性回归的最小二乘法参数估计的计算公式、性质和应用;3、理解拟合优度指标:决定系数R 2的含义和作用;4、掌握解释变量X 和被解释变量Y 之间线性关系检验,回归参数0β和1β的显著性检验5、了解利用回归方程进行预测的方法。
一元线性回归模型的参数估计及性质
(i 1, , n) 为用样本的到的一元线性回归函数,最小二乘法就是使
n i 1
估 计 模 型 与 真 实 模 型 之 间 偏 差 平 方 和 ( 残 差 平 方 和 i ) 达 到 最 小 时 的
ˆ ,b ˆ (b 0 1 )去估计真实参数(b0 , b1 ) 。
令
i 1
ˆ ,b ˆ ˆ ˆ ˆ i Q(b 0 1 ) ( yi yi ) ( yi b0 b1 xi )
2 2 2
i 1
ˆ b ˆ x b ˆ b ˆ x) ˆ i ) ( yi y ) ( y ˆ i y ) ( y i y ) (b i ( yi y 0 1 i 0 1 ˆ 2 ( x x ) 2 lyy (lxy ) lxx lyy (lxy ) ( yi y ) 2 b 1 i lxx (lxx ) 2 ˆ 2 (n 1) S 2 (n 1) S 2 b
②若 ei ~ N (0, 2 ) ,有
i
n 2
i 1
2
~ 2 (n 2)
③“残差” i 是随机误差的一种反应,如果在模型正确的前提下,“残差” i 应该是杂乱无章 没有规律性的,如果呈现出某种规律性,则可能是模型中某方面的假定与事实不符。
四、拟合优度——可决系数 R
2
(一般模型)
ˆ y b ˆ 也是 y 的线性组合。 ˆ x ,所以出 b ˆ 是 y 的线性组合,又 b 可以看出 b 0 0 1 i i 1
还有 ki
( xi x ) ( xi x ) ( xi x ) ( xi x ) xi 0 ; ki xi x 1. 2 2 2 i ( xi x ) ( xi x ) ( xi x ) ( xi x ) xi
一元线性回归方程中回归系数的几种确定方法
0 引 言
一元线性回归模型是统计学中回归分析预测理论的一种重要方法 ,应用于自然科学 、工程技术和经
济分析的各个领域 ,有较强的实用性·该方法的基本思想是 : 首先确定两个变量之间是否存在线性相
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一元线性回归公式
一元线性回归公式是一种基本的统计学模型,它在统计学和机器学习领域中都有广泛应用,可以用来预测和分析两个变量之间的关系。
一元线性回归的公式可以通俗地表达为:Y = +X,其中Y为因变量,X为自变量,α为截距项,β为斜率。
一元线性回归的本质就是对两个变量之间的线性关系进行拟合,同时计算出两个变量之间的斜率β和截距项α。
两个变量之间的线性关系能够概括为Y = +X,其中X是自变量,Y是因变量,α是压力,β是应力。
由于一元线性回归模型只分析两个变量之间的关系,因此该模型也称为双变量回归模型。
一元线性回归的原理是什么呢?一元线性回归的原理是使用最
小二乘法(Least Squares)来找到最佳拟合参数,以使所有样本点
和拟合曲线之间的总误差最小。
通过最小二乘法,系统可以根据输入数据自动计算出α和β参数,从而实现回归拟合。
一元线性回归公式是一种重要的统计模型,用于分析两个变量之间的关系。
它能够解决各种数量和定性难题,比如预测消费者行为、分析市场趋势等,以及帮助企业做出数据驱动的决策。
统计学家除了使用一元线性回归公式外,还可以使用多元线性回归来分析多个变量之间的关系,多元线性回归旨在更加准确地预测多元变量之间的关系,从而获得更准确的预测结果。
一元线性回归模型可以很容易地使用统计分析软件或者编程语
言实现,它是实现数据驱动的管理层面的有力武器。
此外,一元线性
回归模型在机器学习领域中也有着重要的作用,因为它可以用来训练算法,从而帮助计算机更准确地预测结果。
总的来说,一元线性回归公式是一种广泛应用的基础统计学模型,它可以帮助企业进行数据驱动的决策,也可以用于机器学习算法的训练,从而提高算法预测的准确性。